На одной конференции мне задали вопрос (спасибо Александру!): как сделать стрим в PostgreSQL? Представьте, что имеется bytea и вы к нему хотите что-то дописать. Люди столкнулись с тем, что на это в PostgreSQL тратится гигантское время и растет WAL-трафик.
Расскажу, что с этим возможно сделать — это будет еще один пример оптимизации TOAST (о чем я недавно писал), на на этот раз — для быстрой записи потока бинарных данных. На самом деле мой коллега, Никита Глухов, за несколько часов сделал расширение, которое «вылечило» проблему, и мы даже успели рассказать про это на сессии блиц-докладов на PGConf.Online 2021.

Appendable bytea: мотивационный пример
Предположим, что у нас имеется 100 Мб bytea:
CREATE TABLE test (data bytea);
ALTER TABLE test ALTER COLUMN data SET STORAGE EXTERNAL;
INSERT INTO test SELECT repeat('a', 100000000)::bytea data;
Мы добавляем 1 байт:
EXPLAIN (ANALYZE, BUFFERS, COSTS OFF)
UPDATE test SET data = data || 'x'::bytea;И видим, что на это тратится больше секунды!

Это связано с тем, о чем я рассказывал про TOAST в первой части статьи — 100 Мб копируется в WAL и в хранение. На этом примере мы серьезно задумались, и у нас появился челлендж — как же сделать так, чтобы можно было стримить в Postgres?
Дело в том, что TOAST не оптимизирован под частичное обновление, все данные должны сначала собраться из чанков, потом разжаться для модифицикаций в памяти (это все называется deTOAST), после чего они должны обратно сжаться, «нарезаться» на чанки и записаться на диск с новым OID.
Поэтому мы решили сделать специальный формат данных (в PostgreSQL это называется datum — то, что передается функцией и т.д.), который состоит из TOAST pointer и inline буфера, используемый для TOAST. Оператор конкатенации || не делает deTOAST, а просто добавляет данные в этот inline буфер. Если размер inline данных превышает 2KB, то происходит TOAST, но только изменившихся данных, при этом неизменившиеся чанки используются для всех версий:
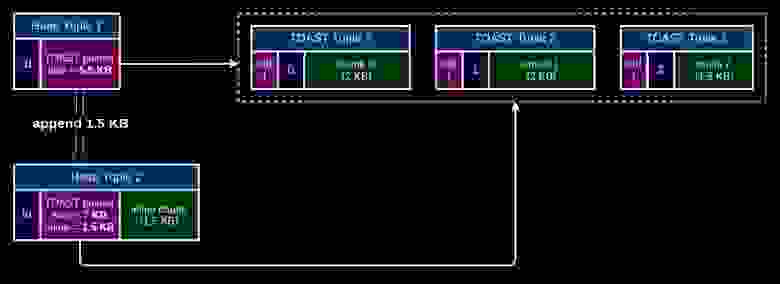
И если вы хотите добавить что-то, это сохраняется это в inline tuple:

Видим, что у TOAST pointer размер 5,5 Кб, это размер трех чанков (TOAST Tuple1, TOAST Tuple2, TOAST Tuple3). Мы добавили маленькое хранение — то, чего не хватает до 2 Кб — просто для того, чтобы вы могли записать именно туда. И тогда все ускоряется. Когда размер становится больше, мы делаем новый чанк, а старые сохраняем на месте:
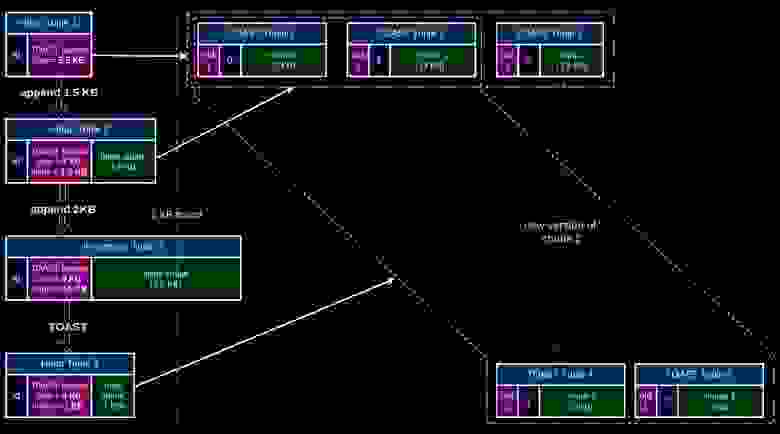
В результате мы получаем выигрыш: на таком простом примере вместо 14 чанков мы работаем с 7 чанками — сокращение в 2 раза:

Но это примитивный пример. На том же реальном примере мы получаем ускорение в 2750 раз:

То есть стрим занимает меньше миллисекунды! При этом размер таблицы остается тем же самым (примерно 100 Мб), а WAL сгенерился всего 143 байта вместо 100 Мб и нет никаких дополнительных ненужных чтений блоков. Это хороший мотивирующий пример, который показывает, как можно чуть-чуть изменить TOAST. Однако давайте посмотрим, как это работает в PostgreSQL сейчас.
Appendable bytea: что в PostgreSQL есть сейчас
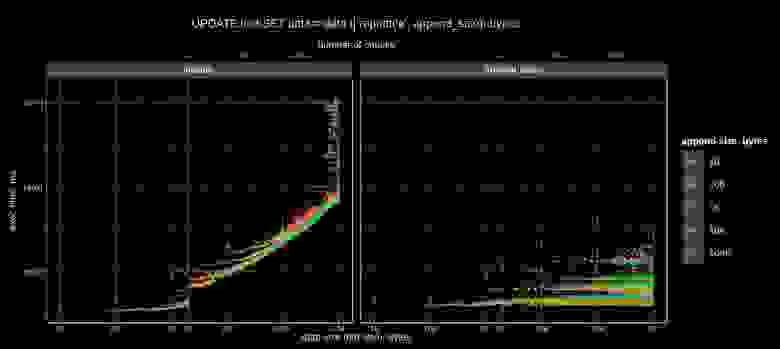
Посмотрим на график. По оси X — размер данных. Разные цвета — это количество append size, то есть, сколько вы добавляете к этому размеру: 10, 100 байт, и т.д. до 1 Мб (∝ — знак пропорциональности):

Слева показано, как это происходит в PostgreSQL сейчас. Время выполнения запроса пропорционально размеру JSONB и добавленному кусочку, и зависит оно только от размера того, что вы добавляете. По-моему, очень красиво.
На следующем графике показан трафик WAL, который тоже стал значительно красивее.

А теперь давайте действительно сделаем стрим.
Appendable bytea: STREAM
У нас строка имеет размер 0, давайте его добьем до 1 Мб маленькими апдейтами, например, по 10 байт:
UPDATE test SET data = data || repeat('a', append_size)::bytea WHERE id = 0; COMMIT;Мы решили использовать pg_stat_statements, чтобы вытаскивать время, количество блоков и размер WAL. В старом PostgreSQL мы сразу уперлись в производительность. Дело в том, что 1 Мб мы выбрали неслучайно — когда вы начинаете апдейтить от 100 Кб и больше, то таблица растет очень круто и место на ноутбуке начинает вылетать. Если вы будете апдейтить 10-байтными кусочками, вам придется это сделать много тысяч раз. Таблица и WAL «распухнут» , поэтому мы ограничились только 1 МБ.
И вот справа вы можете увидеть, каким стал тот же стрим с Appendable bytea:
То есть это открывает большие перспективы. В PostgreSQL действительно вполне можно стримить, если использовать наши оптимизации.
Здесь показано, как растет размер WAL. Справа он зависит только от размера добавляемого куска, а слева — от самой строки.
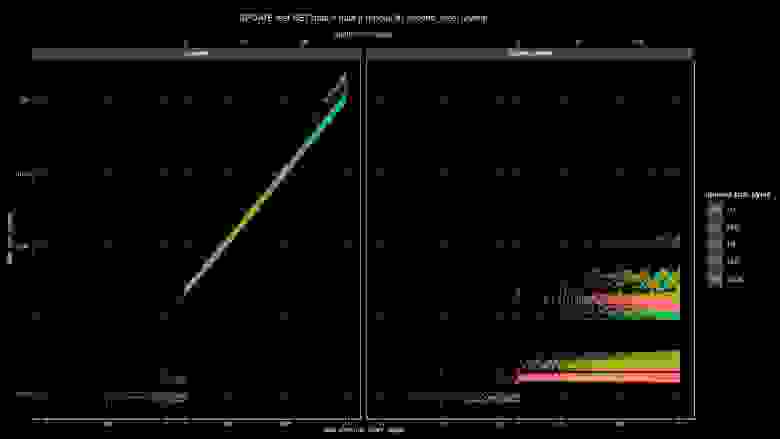
Мы посчитали скорость (Мб/с) для оригинального постгреса (слева) и с оптимизацией. Слева мы ограничились случаем, когда мы добавляем 10-байтные кусочки, иначе всё будет слишком медленно. Мы видим, что скорость очень быстро падает с 1 Мб/с до 1 Кб/с, полоса совсем маленькая. Справа мы видим, что производительность дописывания не зависит от размера данных для любых размеров добавлений, и можно предсказать, что если мы хотим занять полосу 20 Мб/с, то надо апдейтить килобайтными чанками и деградации производительности не будет.

Вместо Заключения
В этой серии статей я рассказал про возможности улучшения PostgreSQL для эффективного хранения больших значений на примере популярного типа данных JSONB и быстрого дописывания бинарных данных. PostgreSQL славится своей расширяемостью, поэтому логично ее расширить и на TOAST — так чтобы хранение больших значений было datatype aware.
Мы предложили серию патчей, реализующих API для TOAST (см. Pluggable TOAST), на основе которого можно разрабатывать TOAST, оптимизированный для определенного типа данных. Например, все описанные оптимизации для JSONB можно реализовать в виде расширения. Надеемся закоммитить все это для следующей версии PG15.
Видео моего выступления на Saint HighLoad++ 2021:
Конференция HighLoad++ Foundation 2022 пройдет 17 и 18 марта в Москве в Крокус Экспо. — 1 февраля. Планируйте свое участие, расписание и полный список тем с тезисами уже на сайте.
Наш доклад с коллегами — Pluggable TOAST or One TOAST fits ALL — будет логичным продолжением того, что я рассказал в этой серии статей. Билеты можно купить здесь.
До встречи на конференции!




