
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
DevOps обычно рассматривается в двух ипостасях:
На стыке этого у людей происходит некоторый слом, и они не понимают – ОК, есть DevOps, есть автоматизация, у нас всё это есть. Но, ребята, у нас команда из 10 человек — мы не можем, например, пилить процессинг на банк, или сервис для нашего биллинг-оператора, или что-то еще такое. 10 человек — та самая Scrum-команда, которой предлагается всё это сделать, — не могут этого технически.
У таких команд, помимо «мы так не умеем, потому что так раньше не делали», есть и другие вызовы. Михаил Бижан рассказал на конференции DevOps Conf 2019 о тех, с которыми встретилась его команда в Райффайзенбанке, и как они это решали. Михаил отвечает за автоматизацию в банке, вместе с командой внедряя инженерные практики и поддерживая инструменты автоматизации.
Раньше Михаил уже внедрял культуру DevOps в Сбербанке. Но до этого, работая на стороне интегратора (в основном на «госов») наловил кучу анти-паттернов. Потому что чем характерны госзаказчики? Годовалыми проектами, невообразимыми бюджетами и полным отсутствием намека на Agile и DevOps. Там все строго. Сначала ты пишешь ТЗ, чтобы стопка бумаги была метр от пола. Если меньше, это не ТЗ (и даже не проект) — это несерьёзно. Потом ты разрабатываешь, а если что-то не получается — виноват ты и денег не получаешь (хотя госзаказчик, скорее всего, все равно счастлив, потому что бюджет освоен и что-то формальное достигнуто).
Так что у Михаила большой опыт в том, как делать не надо. А как делать можно — понимает из чтения книг и общения с сообществом и коллегами. Как системный аналитик, Михаил не старается решить всё методами разработки, а анализирует проблему, чтобы понять её root cause и сделать так, чтобы она больше никогда не повторялась. На этом сочетании и построен доклад.

Сегодня поговорим о том, что болит у всех и всегда, и что иногда кажется невозможным — о кросс-функциональности в энтерпрайзе. Энтерпрайз — это любая компания, которая разрабатывает более, чем один IT- продукт. Если у вас языковая школа, и вы пилите в целом всё для неё, у вас вряд ли энтерпрайз. А если у вас, например, универсальный банк, где есть розничное кредитование, факторинг, кэш-менеджмент, и все это legacy, спагетти-код и прочее, — скорее всего, у вас энтерпрайз. Или если вы системный интегратор, у вас тоже может быть энтерпрайз, потому что вы пилите для большого количества заказчиков всякое счастье и используете все виды технологий, процессов в ежедневной деятельности.
Поэтому в энтерпрайзе задача создания и развития кросс-функциональных команд кажется мало выполнимой.
Есть мнение, что DevOps летает только там, где есть Agile. С одной стороны это так, с другой стороны — необязательно. Но суть Scrum-, Agile-, DevOps-, каких угодно продуктовых команд в том, что одна группа людей создает один продукт «под ключ». Это может быть сложносоставная группа из нескольких feature-teams, которых объединяет только единый бэклог, но в любом случае это единый продукт. У продуктовой команды единые цели, структура прибыли, структура затрат и один продукт:
Такое описание продуктовой команды — это краеугольный тезис, который толкает вас в дебри невозможности кросс-функциональности, потому что у любого адекватного человека начинается смех и истерика, когда ему говорят: «Ребята, вы теперь будете делать всё. У вас 20 человек в команде, делайте розничное кредитование», например. Скорее всего, после такой постановки задачи вы поинтересуетесь у коллег, где скачать заявление на увольнение, потому что неохота от руки писать.
Но вам говорят; «Спокойно, мы будем делать из вас кросс-функциональную команду, вас всему научим, всё вам дадим!» И получается примерно так:

Кросс-функциональностью что только не называют. Я встречал мнение, что это система, при которой какой-то огромный департамент с индусами каждой продуктовой команде разрабатывает всё, что не относится к логике работы самого продукта. Если нужно что-то ещё, команды опять прибегают к этому огромному департаменту. Но, по сути, это — внутренний аутсорс, когда вы примерно половину своей работы передаете какому-то «дежурному терапевту».
Все-таки обычно под кросс-функциональностью понимают тестирование, плюс разработку (иногда безопасность, если вы совсем крутые) и обязательно сопровождение (внедрение). И всё это происходит внутри одной команды, которая должна уметь заменить любого своего участника в случае чего.
С точки зрения продуктовой разработки, одним из базовых является принцип «You build — you run it». Только пока ты сам сопровождаешь то, что накодил — только тогда ты понимаешь все проблемы, которые твои клиенты, пользователи и смежные команды испытывают при работе с твоим продуктом. Об этом очень важно не забывать.
Маленький экскурс в Википедию
Обычно все говорят, что кросс-функциональность — это про t-shape. Давайте определимся с терминами:

Очень важный момент. Если мы из нашего π-shaped специалиста будем делать расческу, добавляя много ключевых экспертиз, то его госпитализируют в Кащенко (потому что он сойдет с ума). А если не сойдёт, то его экспертиза будет не такой уж глубокой, потому что человеческой жизни не хватит на то, чтобы стать экспертом во всем:

Каждый новый скилл, который вы приобретаете, и каждая новая экспертная область, с которой вы знакомитесь, должна позволять вам более эффективно выполнять свои текущие задачи. Если вы прочитали на Хабре, что ML — это круто, и решили на досуге выучить Python, то это ваше хобби. Когда у вас появятся задачи, связанные с Python или с ML, за которые вам будут платить — тогда можно говорить, что вы наращиваете горизонтальные навыки. Например, я люблю играть на гитаре, но за это в банке мне не доплачивают (к сожалению). То есть я не могу сказать, что я π-shaped в сторону игры на гитаре.
Когда мы говорим про энтерпрайз (банки, телеком и пр.), есть ряд неочевидных штук, про которые все либо никогда не задумывались, либо задумывались, но не придавали им значения до тех пор, пока им не сказали: «Ребята, вы теперь продуктовая кросс-функциональная команда!»
Продукт — это то, за что клиенты платят вашей компании. У продукта всегда есть P&L (Profits and Losses). Он отчуждаемый. Например, кредитная карта — это продукт, потому что за нее вы платите деньги банку. А банк несет за неё какие-то расходы: он ее запрограммировал, создал бизнес-модель, как-то её рекламирует, печать пластика, доставка, логистика и пр. Банку может казаться, что супер-крутая карта, сделанная из чистого золота с гравировкой лица вашей мамы или бабушки — это супер-свежая бизнес-модель, которая прямо сейчас взорвет рынок, и все придут к нему, отключившись от всех остальных банков. Но это может оказаться не так, если банк предварительно не спросит об этом у вас — клиента.
Это кажется банальностью, но очень многие продуктовые команды (и даже компании) не знают, чего хотят их клиенты. Они делают то, что хочет, например, их CEO. Вы сами можете вспомнить 100500 таких примеров:

При создании продукта вы должны не просто понимать, что нужно вашему клиенту. Вы должны знать, что хочет ваш клиент сегодня, завтра, послезавтра и в любой другой день. Специфика банковского рынка такова, что наша прибыль не будет расти, если мы будем повышать цены на услуги или наращивать комиссии. Единственный рабочий драйвер — рост клиентской базы. Но это справедливо и наоборот — демпинг не сработает. Условно, ипотека везде стоит плюс-минус 10%. Но если сегодня мы сделаем ипотеку 5%, у нас будет очень много клиентов, но у ЦБ будут серьезные вопросы. Поэтому вместо этого мы вкладываемся в маркетинг и даем клиентам какие-то другие плюшки, например хороший сервис или скидки на другие продукты. Причем давать нужно именно то, что хочет клиент — это поможет выбрать именно наш ипотечный продукт.
Механизмы взаимодействия с клиентом, которые позволят вам слушать и слышать его голос — это то, что любая продуктовая команда должна уметь и иметь возможность сделать by design. Это важная штука.
Ещё до Сбербанка, работая проектным менеджером, я, как и многие айтишники, дежурил по выходным. И это был отстой! Я ничего не умел делать с кодом и чувствовал себя максимально тупым и бесполезным в это время. Я сидел перед монитором с графиками только для того, чтобы в случае аварии взять такси и доехать до дома моего разработчика и позвонить в дверь, потому что он телефон не слышит. Не рекомендую!

Если бы тогда я знал то, о чём сейчас рассказываю, мы бы на берегу договорились с командой о правильной организации поддержки. Обычно в энтерпрайзе есть отдельная выделенная линия поддержки 24/7, колл-центр где-нибудь не в Москве. И любая команда должна иметь возможность с ним работать.
Как это сделать?
Допустим, я — product owner той же кредитной карты. Я могу написать условный скрипт (инструкцию в Word), отдать в 24/7 и сказать, что если на горячую линию банка будут звонить по таким-то вопросам, то звоните Пете, если по таким — то Коле, а все остальное — не наше. Это я уже наполовину молодец.
Чтобы мне стать полностью молодцом, нужно еще при каждом изменении функционала моего продукта оповещать об этом службу 24/7. Если Коля заменился на Аллу, функциональность добавилась или убавилась, колл-центр должен об этом узнавать.
Почему это важно?
Клиент – это тот, кто платит. У нас для продуктовой разработки специфично и характерно то, что все клиенто-центрично, а не IT- или CEO-центрично. Клиент хочет быстро получать всё, что ему нужно. И если у него есть проблема, он должен максимально быстро получить решение, просто позвонив или написав. Никто этого сейчас, наверное, нормально делать не умеет, но это то, к чему нужно стремиться.
Технологический долг — это то, с чем каждый из нас работает так или иначе. Это может быть автоматизацией регресса, рефакторингом старого кода, разработкой API для чужого кода и т.д. Это понятие очень широко трактуют. Я знаю компании, в которых под технологическим долгом понимают исключительно архитектурные несоответствия спецификации, но это очень узко и на мой взгляд некорректно.
Инциденты, баги, аварии прода и так далее — это то, что случается у всех. Но когда это начинает случаться часто и по одним и тем же причинам, это вызывает серьёзное раздражение. Тем не менее, мы не должны заливать эту проблему человеческими или какими угодно другими ресурсами («На 20 падений сервисов ответим наймом 20 новых DevOps-инженеров!»), нужно сесть и подумать, почему сервис падает и как сделать так, чтобы он не падал. Тогда наши инженеры могут заниматься новыми более классными штуками, например, попилотировать CI/CD инструменты, которые они еще не трогали, чтобы потом к нам прийти и сказать: «Чувак, я нашел что-то круче Jenkins»:

То есть root cause — работа с технологическим долгом, который не всегда будет вашим, кстати. Продуктовая команда в энтерпрайзе иногда вынуждена менять не свой код (например, в случае сервисной шины) для того, чтобы внедрить фичу в продакшн, изменение в функциональности и выкатить его на рынок.
Представим, что мы разрабатываем функционал выдачи кредитов в мобильном приложении. Я — product owner в розничном кредитовании с отличным отделяемым P&L. И есть ряд каналов, через которые я этот продукт продаю — сайт, iOS и Android приложения, мобильное рабочее место операциониста.
В мобильном приложении банков, как вы знаете, какой только функциональности нет — от переводов между картами до выпуска новых карт, погашения ипотек, алиментов, оплаты ЖКХ и прочего. Это круто, это XXI век:

Но я, как product owner, отвечаю только за свой продукт — за розничное кредитование. А если в мобильном приложении, например, iOS, которым пользуются миллионы людей, вдруг сбойнул текущий счет и человек просто свой баланс не видит? Он не будет, заходя в приложение, даже думать о том, чтобы взять кредит. Он скажет: «О! Где мои сто тысяч рублей?!» и будет звонить в банк и спрашивать: «Доколе?!»
Поэтому взаимодействие со смежными сервисами — это та часть жизни вашей продуктовой команды, который может вам как сильно помочь в чем-то, так и сильно помешать.
В чем он может вам помочь? Если вы делаете какие-то смежные маркетинговые компании и продвигаете их через единый канал (например, мобильное приложение), вы можете получить синергию. Например, я выпускаю функционал по розничному кредитованию и могу предложить кредит на супер-условиях для молодых семей. А команда ипотеки то же самое делает, но для пенсионеров и лиц пожилого возраста. Мы можем прекрасно скооперироваться и вывести единый релиз под эгидой социальной защищенности.
Или если вы имеете внутренний опенсорс, то часть компонентов, которые вы используете со смежными сервисами, можно переиспользовать. Например, API или графические интерфейсы. Это вообще true — никто давно уже не переписывает фронт или элементы дизайна каждый себе. Так вы сможете а) сэкономить, б) потенциально не потерять аудиторию (если что-то пойдет не так) или не вызвать волну хейта именно к вашему продукту.
Также потенциально вы можете получить совершенно неочевидные бенефиты, если будете более плотно дружить и общаться не только с клиентом, который вам платит, но и с теми людьми, которым он платит тоже. Это люди, которые “сидят” на тех же каналах с вами, в одном банке.
И наоборот. Они могут у нас увести активную аудиторию, сломать приложение, которое является каналом продажи наших услуг. Синхронизация релиз трейнов, расписания поставок, или чего угодно, что вы используете — важно.
Это частный случай смежных сервисов. Ранее упомянутая шина — одна из них.
В банках это чаще всего DWH и АБС — автоматизированные банковские системы. АБС — это монструозная конструкция, в которой делается собственно банкинг. Там происходят основные финансовые операции, генерируется отчетность ЦБ. Это мозг зверя по имени банк. А все остальные его органы с АБС так или иначе взаимодействуют. Обычно АБС в банке ровно одна, потому что больше не надо. Есть исключения, например, при объединении банков какое-то время они живут с двумя, а то и тремя АБС, но обычно это нерационально. Так же, как и в случае с процессингом.
Любая платформа — это, по сути, черепаха, на которой стоит мир. Клиенты пользуются вашими услугами – они покупают кредитку, скачивают мобильное приложение, отправляют друг другу стикеры и чатятся. Но если у вас где-нибудь умрет процессинг, всё пойдет насмарку:

С процессингом вы можете общаться, либо выпиливая из него некоторые сервисы, микросервисы и другие абстракции, либо попросить свои платформы, чтобы они сделали унифицированный канал общения всех сервисов с ними. Тогда случай, происходящий с одним продуктом, не будет аффектить на платформу, и как следствие, — на другой продукт.
Это базовая безопасность, которая позволит вам не упасть в случае падения платформы. Если в вашей компании упадет сервисная шина, ваш продукт упадет и не будет работать тоже. Если в банке упадет процессинг, через 5 часов вам позвонят из ЦБ, а через сутки заберут лицензию, каким бы банк ни был, даже №1. Это недопустимо.
Когда вы дизайните вашу кросс-функциональную (продуктовую) команду, платформа — это то, что вы должны держать в поле зрения. Вы должны уметь безопасно работать с платформой, а платформа должна уметь безопасно работать с вами.
Инфраструктурный департамент — это те обслуживающие подразделения, которые представляют сервисы командам для того, чтобы они могли пилить свои продукты — железо, сети, и так далее. При этом, сама по себе инфраструктура — это адский ад сложностей. Потому что никто снаружи не понимает, как она устроена и какие есть планы ее развития. Они говорят: «Друзья, у вас сейчас голый Docker, мы пилотируем ванильный Kubernetes, еще в январе у нас будет Tanzu, еще где-то там рядом Openshift». А потом: «Все, это мы больше не поддерживаем, переезжай вон туда». Когда и чем всё это кончится, непонятно:

Вы всегда должны понимать, что происходит и будет происходить с вашей инфраструктурой, причем под инфраструктурой я понимаю и hardware, и базовые middleware штуки, и те самые оркестраторы всего на свете, которые вы используете при работе. Вы должны знать в моменте, как их использовать, как их точно не использовать и что с ними будет дальше. Потому что это даст вам возможность не только не допустить ошибку (классика), но и потенциально получить гешефт.
Хороший пример: у нас недавно появилась новая команда, которой нужна помощь в настройке CI/CD. У нас в банке CI/CD тулой сейчас является Atlassian Bamboo. Мы могли им сказать: «Друзья, вот Atlassian Bamboo, вот SDK, вот человек, который вам поможет это настроить. Мы готовы отправить вас на наш курс CI/CD, где вам расскажут основные паттерны взаимодействия — наслаждайтесь».
Но прямо сейчас мы в банке пилотируем другие альтернативные инструменты, так как нас во многом не устраивает Bamboo. Этой команде мы объяснили, что расклад такой — прямо сейчас есть Bamboo, есть пилоты такого и такого инструментов: «Не хотите ли вы попробовать сделать на них?» Риски понятны: если пилот не пойдет, им придется все это перевезти на тот, который будем внедрять. Но мы гарантируем поддержку и поможем им перепилить, чтобы безопасно перейти на тот, который будет выбран целевым.
То есть мы им дали информацию о том, какие минусы есть у текущего инструмента и какие плюсы у потенциально будущего. И дали информацию о том, как работает наша инфраструктура, чтобы они сделали осмысленный выбор. Они сказали: «Да, кайф», и выбрали тот пилот, в котором им было бы интересно поучаствовать. Без этой информации, просто выбрав «линию партии» и продолжив на Bamboo, через пару месяцев мы бы получили волну негатива, когда поменяли бы наш CI/CD-оркестратор: «Ребята, мы два месяца назад приходили...»
Очень часто команды изобретают велосипед. Например, мне нужно выбрать инструмент оркестрации контейнеров. Я смотрю в Google какой-нибудь рейтинг от Gartner и вижу там K8S: «Нам нужен Кубер прямо сейчас!» — «Почему именно Кубер?» — «Да потому что я нагуглил, и он в каком-то рейтинге первый».
Но такой способ выбора решения не самый оптимальный. Нужно танцевать от цели. Какая у нас цель, зачем мне вообще оркестрация контейнеров? Зачем мне в принципе контейнеры? Затем, что я не хочу, чтобы каждая из команд, которые я обслуживаю (которым я служу — есть такой термин servant leadership, лидерство как служение), тратила по неделе рабочего времени одного человека на то, чтобы заполучить базовые образы, которые они потом будут в своем CI/CD конвейере использовать. Я хочу создать централизованно полный набор образов, которые будут безопасны, всех удовлетворять и прочее. Куда-то их положить, чтобы всем было хорошо, комфортно и удобно, и пусть юзают.
Поэтому целесообразно спросить тех, кто ими пользоваться будет. Клиенты — это мои команды: «Ребята, у вас какие ожидания?» Если они будут называть названия оркестраторов — это не то, что мне нужно. Мне интересны принципы, по которым они выбирают.
Один скажет, что ему нужно, чтобы работало быстро: быстро писалось и быстро читалось. Второму важно, чтобы на рынке была экспертиза представлена, потому что он ноль в этом, а ему надо брать с рынка джуниоров, которые в этом быстро разберутся (т.е. чтобы было просто). Третьему нужно, чтобы какой-нибудь PCI DSS проходил (стандарты по работе с картами Visa, Mastercard и НСПК) — особенные требования к безопасности — должен прийти аудитор и кадилом помахать: «Ваше управление контейнерами удовлетворяет требованиям PCI DSS».
Я выписываю эту критериальную таблицу и на ее основе принимаю решение, какой оркестратор мне нужен. У любой команды-потребителя сервиса должна быть возможность влиять на тот стек инструментов, который вы ей предлагаете. Я за то, чтобы люди сами определяли, что им нужно и как они хотят решать свои проблемы. А я предлагаю те решения, которые на мой взгляд удовлетворяют этим потребностям.
Конечно, у меня сбоку будет своя критериальная таблица типа: сколько это стоит, насколько просто это поддерживать, модель лицензирования и т.д. Но команды всегда дают input, что они хотят от своей инфраструктуры. Они хотят быстро, дешево, гибко — ОК, это их право. Они имеют право это требовать от нас, как от сервисных подразделений.
Вы можете сказать: «Молодец, рассказал очевидные вещи — спасибо, кэп! — а что с этим делать?» Ответ очень простой: создать в вашей компании такую среду, чтобы работать неправильно было некомфортно, слишком дорого, сложно и т.д.:

Как заставить, побудить, продать (какие угодно слова можно использовать) наши команды взаимодействовать с клиентом, чтобы они начали его слышать и слушать? Вы должны включить им голос клиента в какой-то мониторинг, либо в цели. Хоть радио в офисе повесьте с записями из отделений банка, как бабушки кричат том, что полчаса не могут пенсию снять.
Как это сделано у нас. Мы безальтернативно проводим опрос клиентов по основным банковским услугам, потом безальтернативно всем его показываем. Например, вы продаете кредитные карты, а вы дебетовые: вами довольны, а вами — нет. Люди видят результаты друг друга и понимают, что происходит не так. Их никто за это не наказывает, просто им стыдно. Когда один продукт любят, а второй нет, то вторые придут к первым и попросят рассказать секрет – что я делаю не так, что ты делаешь так, почему так происходит? Со временем эта история всегда выравнивается, потому что системы (а корпорация – это конечно система) склонны к равновесию.
Это очень долго, если у вас инертная компания, но, если вы молодые и энергичные ребята — это будет быстро. Если вам не все равно, процесс можно ускорить — ходить и пальчиком тыкать: «Смотри, у них хорошо, у тебя плохо. Не хочешь присмотреться?» Мы так делаем.
Кросс-функциональная команда умеет:
Давать тут какие-то советы на мой взгляд не нужно, потому что литературы написано более чем достаточно. Просто перестаньте додумывать за клиента, и попробуйте любым способом узнать, что он на самом деле хочет.
Помните, как раньше учили детей плавать? Вывозишь на лодке на середину реки и бросаешь в воду: «Давай, встретимся на берегу!» В переводе на нормальный язык с языка метафор это значит, что пусть команда пострадает.
Вы им говорите: «Вас 10 человек. Есть возможность работать с горячей линией 24/7, но для этого нужны скрипты, которые вы должны дать. Но вы можете этим не пользоваться — живите, как хотите!», а потом все звонки на горячую линию, когда какая-нибудь кредитка умерла, роутить прямо на product owner. В субботу ночью? ОК! В воскресенье ночью? ОК! В понедельник примерно к 5 утра он задумается о том, что же он делал в этой жизни не так, и к обеду скрипт будет в службе 24/7 — готовый и со всеми нюансами.
Тут несколько вариантов решения. Можно использовать тот же самый метод тотальной открытости, когда все видят, что одни перформят, другие нет — и смотрите, почему. А можно попытаться обосновать, что устранение технологического долга дает им измеримый бенефит.
Например, у вас и у соседней команды плюс-минус похожие продукты, но у вас стремный legacy-код, а у соседней команды — нет. В результате у вас есть некий постоянный уровень аварийности (допустим, 10 аварий в год), в отличие от той команды. Тут очень важный момент — нужно найти человека, который согласится исправить что-то один раз. Найдите конкретный legacy-фрагмент в коде и поймите, на что это влияет. Потом убедите команду это изменить и покажите цифры: «Вот у тебя было 10 аварий в год, теперь их 8! Давай сделаем дальше, и будет у тебя еще все более круто».
В структуре организаций частенько встречается некая платформенная команда, которая сидит, отгородившись отрядом лучников, скелетов, черных драконов, и никого к себе не подпускает: «Вам нужна доработка — приходите через 9 месяцев».
В этом случае мы задаём вопрос — что я могу сделать, чтобы я получил быстрее то, что я хочу? У продуктовой команды в целом таким и должно быть мышление — если вам что-то нужно, но говорят НЕТ, то узнайте, что нужно сделать, чтобы было ДА. То есть узнать, что нужно сделать, чтобы прикладная платформа внедрила изменения на своей стороне, которые нужны вам, быстрее (например, через месяц) — должны вы, как идеологи DevOps. Например, давайте сделаем API, или давайте продуктовая команда сделает изменения в платформенном коде, только чтобы все это было безопасно и т.д.
Аналогично — никаких секретов, просто человеческое общение, поиск взаимовыгодных условий совместной работы и ad hoc решение задач.
Как это бывает: приходит новая команда и говорит, что им нужны среды: «Нам нужен продакшн-сервак, у нас релиз через месяц». «Хорошо, вот заполни Excel, что конкретно ты хочешь, там всего 120 строчек». Я смотрю в эту таблицу и понимаю оттуда от силы 20 строчек, а для остальных мне нужен переводчик — человек, который знает, как их заполнять. Когда мы первый раз сказали нашей инфре, что это странно, — даже мы в этом не шарим, — то они дали нам образец, как это заполняется. С образцом я стал уметь заполнять 40 строчек из 120.
Я как потребитель постоянно говорю, что именно мне неудобно до тех пор, пока сервис не станет идеальным. Это один из принципов Agile —делаем не сразу идеально, а движемся постепенно к тому, чтобы стало хорошо, постоянно делаем лучше и лучше. Сейчас наша инфраструктура понимает, что она в первую очередь сервис, и теперь думает, как сделать жизнь своих клиентов легче.
Это шесть основных моментов, на которые, как показал опыт моей команды, нужно обращать внимание.
Если вы знаете еще какие-то вещи, которые кросс-функциональная продуктовая команда должна уметь делать со своим окружением — пишите, обсудим.
Это невероятно сложная и неблагодарная работа — всё это провернуть и претворить в жизнь. Вам будет очень тяжело, если вы встанете на этот скользкий путь. Нам было очень тяжело:

Каждый раз, когда вы говорите, что будете менять среду таким образом, чтобы она побуждала людей сделать что-то, чего они раньше не делали, это будет дико демотивировать вас и ваших людей. Вы будете выгорать и ненавидеть весь мир. Но потом (через пару лет), люди, у которых стало хорошо, скажут: «Я красавчик, я всё сделал. Ты мне помогал, я помню. Но это фигня, а вот я красавчик!»
- Инструментарий — техника, tooling, технические процессы, CI/CD и прочие штуки — авто-всё, всё как код и т.д.
- Культура — это как отдельным разработчикам прийти всем вместе к «мир, дружба, жвачка».
На стыке этого у людей происходит некоторый слом, и они не понимают – ОК, есть DevOps, есть автоматизация, у нас всё это есть. Но, ребята, у нас команда из 10 человек — мы не можем, например, пилить процессинг на банк, или сервис для нашего биллинг-оператора, или что-то еще такое. 10 человек — та самая Scrum-команда, которой предлагается всё это сделать, — не могут этого технически.
У таких команд, помимо «мы так не умеем, потому что так раньше не делали», есть и другие вызовы. Михаил Бижан рассказал на конференции DevOps Conf 2019 о тех, с которыми встретилась его команда в Райффайзенбанке, и как они это решали. Михаил отвечает за автоматизацию в банке, вместе с командой внедряя инженерные практики и поддерживая инструменты автоматизации.
Раньше Михаил уже внедрял культуру DevOps в Сбербанке. Но до этого, работая на стороне интегратора (в основном на «госов») наловил кучу анти-паттернов. Потому что чем характерны госзаказчики? Годовалыми проектами, невообразимыми бюджетами и полным отсутствием намека на Agile и DevOps. Там все строго. Сначала ты пишешь ТЗ, чтобы стопка бумаги была метр от пола. Если меньше, это не ТЗ (и даже не проект) — это несерьёзно. Потом ты разрабатываешь, а если что-то не получается — виноват ты и денег не получаешь (хотя госзаказчик, скорее всего, все равно счастлив, потому что бюджет освоен и что-то формальное достигнуто).
Так что у Михаила большой опыт в том, как делать не надо. А как делать можно — понимает из чтения книг и общения с сообществом и коллегами. Как системный аналитик, Михаил не старается решить всё методами разработки, а анализирует проблему, чтобы понять её root cause и сделать так, чтобы она больше никогда не повторялась. На этом сочетании и построен доклад.
Сегодня поговорим о том, что болит у всех и всегда, и что иногда кажется невозможным — о кросс-функциональности в энтерпрайзе. Энтерпрайз — это любая компания, которая разрабатывает более, чем один IT- продукт. Если у вас языковая школа, и вы пилите в целом всё для неё, у вас вряд ли энтерпрайз. А если у вас, например, универсальный банк, где есть розничное кредитование, факторинг, кэш-менеджмент, и все это legacy, спагетти-код и прочее, — скорее всего, у вас энтерпрайз. Или если вы системный интегратор, у вас тоже может быть энтерпрайз, потому что вы пилите для большого количества заказчиков всякое счастье и используете все виды технологий, процессов в ежедневной деятельности.
Поэтому в энтерпрайзе задача создания и развития кросс-функциональных команд кажется мало выполнимой.
Разберемся с матчастью
Что вообще такое продуктовая команда?
Есть мнение, что DevOps летает только там, где есть Agile. С одной стороны это так, с другой стороны — необязательно. Но суть Scrum-, Agile-, DevOps-, каких угодно продуктовых команд в том, что одна группа людей создает один продукт «под ключ». Это может быть сложносоставная группа из нескольких feature-teams, которых объединяет только единый бэклог, но в любом случае это единый продукт. У продуктовой команды единые цели, структура прибыли, структура затрат и один продукт:
Такое описание продуктовой команды — это краеугольный тезис, который толкает вас в дебри невозможности кросс-функциональности, потому что у любого адекватного человека начинается смех и истерика, когда ему говорят: «Ребята, вы теперь будете делать всё. У вас 20 человек в команде, делайте розничное кредитование», например. Скорее всего, после такой постановки задачи вы поинтересуетесь у коллег, где скачать заявление на увольнение, потому что неохота от руки писать.
Но вам говорят; «Спокойно, мы будем делать из вас кросс-функциональную команду, вас всему научим, всё вам дадим!» И получается примерно так:
Кросс-функциональностью что только не называют. Я встречал мнение, что это система, при которой какой-то огромный департамент с индусами каждой продуктовой команде разрабатывает всё, что не относится к логике работы самого продукта. Если нужно что-то ещё, команды опять прибегают к этому огромному департаменту. Но, по сути, это — внутренний аутсорс, когда вы примерно половину своей работы передаете какому-то «дежурному терапевту».
Все-таки обычно под кросс-функциональностью понимают тестирование, плюс разработку (иногда безопасность, если вы совсем крутые) и обязательно сопровождение (внедрение). И всё это происходит внутри одной команды, которая должна уметь заменить любого своего участника в случае чего.
С точки зрения продуктовой разработки, одним из базовых является принцип «You build — you run it». Только пока ты сам сопровождаешь то, что накодил — только тогда ты понимаешь все проблемы, которые твои клиенты, пользователи и смежные команды испытывают при работе с твоим продуктом. Об этом очень важно не забывать.
Маленький экскурс в Википедию
Обычно все говорят, что кросс-функциональность — это про t-shape. Давайте определимся с терминами:
- Монофункциональность (i-shape). От греческого μόνος — один. Допустим, я — разработчик Java: я умею писать на Java и больше ничего не умею и уметь не хочу (причем очень воинственно). Даже если умею, ни за что об этом не расскажу, потому что мне платят за то, что я пишу код на Java. Я — i-shaped, узконаправленный моноспециалист, я творец, пишу код, если вы против — до свидания!
- Полифункциональность (t-shape). От древнегреческого πολύς — многочисленный. Это когда я становлюсь менее агрессивным Java-кодером и говорю: «ОК, я могу еще тесты написать. Не себе, потому что это будет странно, а, например, — тебе» Или, например, я понимаю, как работает инфраструктура, на которой мой продукт функционирует, и могу там скрипты позапускать, пописать, повидоизменять. То есть я в целом имею представление о том, как работает весь ландшафт, в котором мой код существует, и в случае чего хотя бы пойму, что там не так работает. А если я совсем крут, то я могу еще что-нибудь поправить.
- Омнифункциональность (π-shape). От латинского omnis — каждый, всякий. Это достаточно новая в нашей индустрии штука. Ее называют π-shape, расческа-shape, как угодно-shape. Суть в том, что у вас вертикальных палочек с core-экспертизой становится больше — ты не просто крутой Java-разработчик, но ты еще крутой DevOps-инженер. Например, ты очень хорошо представляешь, как работает твой CI/CD, в идеале ты его еще и сам создал под свой Java-проект, ты молодец, ты — π-shaped!
Это не значит, что все умеют всё
Очень важный момент. Если мы из нашего π-shaped специалиста будем делать расческу, добавляя много ключевых экспертиз, то его госпитализируют в Кащенко (потому что он сойдет с ума). А если не сойдёт, то его экспертиза будет не такой уж глубокой, потому что человеческой жизни не хватит на то, чтобы стать экспертом во всем:
Каждый новый скилл, который вы приобретаете, и каждая новая экспертная область, с которой вы знакомитесь, должна позволять вам более эффективно выполнять свои текущие задачи. Если вы прочитали на Хабре, что ML — это круто, и решили на досуге выучить Python, то это ваше хобби. Когда у вас появятся задачи, связанные с Python или с ML, за которые вам будут платить — тогда можно говорить, что вы наращиваете горизонтальные навыки. Например, я люблю играть на гитаре, но за это в банке мне не доплачивают (к сожалению). То есть я не могу сказать, что я π-shaped в сторону игры на гитаре.
В энтерпрайзе команда должна уметь делать неочевидные вещи
Когда мы говорим про энтерпрайз (банки, телеком и пр.), есть ряд неочевидных штук, про которые все либо никогда не задумывались, либо задумывались, но не придавали им значения до тех пор, пока им не сказали: «Ребята, вы теперь продуктовая кросс-функциональная команда!»
Взаимодействие с клиентом
Продукт — это то, за что клиенты платят вашей компании. У продукта всегда есть P&L (Profits and Losses). Он отчуждаемый. Например, кредитная карта — это продукт, потому что за нее вы платите деньги банку. А банк несет за неё какие-то расходы: он ее запрограммировал, создал бизнес-модель, как-то её рекламирует, печать пластика, доставка, логистика и пр. Банку может казаться, что супер-крутая карта, сделанная из чистого золота с гравировкой лица вашей мамы или бабушки — это супер-свежая бизнес-модель, которая прямо сейчас взорвет рынок, и все придут к нему, отключившись от всех остальных банков. Но это может оказаться не так, если банк предварительно не спросит об этом у вас — клиента.
Это кажется банальностью, но очень многие продуктовые команды (и даже компании) не знают, чего хотят их клиенты. Они делают то, что хочет, например, их CEO. Вы сами можете вспомнить 100500 таких примеров:
При создании продукта вы должны не просто понимать, что нужно вашему клиенту. Вы должны знать, что хочет ваш клиент сегодня, завтра, послезавтра и в любой другой день. Специфика банковского рынка такова, что наша прибыль не будет расти, если мы будем повышать цены на услуги или наращивать комиссии. Единственный рабочий драйвер — рост клиентской базы. Но это справедливо и наоборот — демпинг не сработает. Условно, ипотека везде стоит плюс-минус 10%. Но если сегодня мы сделаем ипотеку 5%, у нас будет очень много клиентов, но у ЦБ будут серьезные вопросы. Поэтому вместо этого мы вкладываемся в маркетинг и даем клиентам какие-то другие плюшки, например хороший сервис или скидки на другие продукты. Причем давать нужно именно то, что хочет клиент — это поможет выбрать именно наш ипотечный продукт.
Механизмы взаимодействия с клиентом, которые позволят вам слушать и слышать его голос — это то, что любая продуктовая команда должна уметь и иметь возможность сделать by design. Это важная штука.
Горячая линия 24/7
Ещё до Сбербанка, работая проектным менеджером, я, как и многие айтишники, дежурил по выходным. И это был отстой! Я ничего не умел делать с кодом и чувствовал себя максимально тупым и бесполезным в это время. Я сидел перед монитором с графиками только для того, чтобы в случае аварии взять такси и доехать до дома моего разработчика и позвонить в дверь, потому что он телефон не слышит. Не рекомендую!
Если бы тогда я знал то, о чём сейчас рассказываю, мы бы на берегу договорились с командой о правильной организации поддержки. Обычно в энтерпрайзе есть отдельная выделенная линия поддержки 24/7, колл-центр где-нибудь не в Москве. И любая команда должна иметь возможность с ним работать.
Как это сделать?
Допустим, я — product owner той же кредитной карты. Я могу написать условный скрипт (инструкцию в Word), отдать в 24/7 и сказать, что если на горячую линию банка будут звонить по таким-то вопросам, то звоните Пете, если по таким — то Коле, а все остальное — не наше. Это я уже наполовину молодец.
Чтобы мне стать полностью молодцом, нужно еще при каждом изменении функционала моего продукта оповещать об этом службу 24/7. Если Коля заменился на Аллу, функциональность добавилась или убавилась, колл-центр должен об этом узнавать.
Почему это важно?
Клиент – это тот, кто платит. У нас для продуктовой разработки специфично и характерно то, что все клиенто-центрично, а не IT- или CEO-центрично. Клиент хочет быстро получать всё, что ему нужно. И если у него есть проблема, он должен максимально быстро получить решение, просто позвонив или написав. Никто этого сейчас, наверное, нормально делать не умеет, но это то, к чему нужно стремиться.
Технологический долг и инциденты
Технологический долг — это то, с чем каждый из нас работает так или иначе. Это может быть автоматизацией регресса, рефакторингом старого кода, разработкой API для чужого кода и т.д. Это понятие очень широко трактуют. Я знаю компании, в которых под технологическим долгом понимают исключительно архитектурные несоответствия спецификации, но это очень узко и на мой взгляд некорректно.
Инциденты, баги, аварии прода и так далее — это то, что случается у всех. Но когда это начинает случаться часто и по одним и тем же причинам, это вызывает серьёзное раздражение. Тем не менее, мы не должны заливать эту проблему человеческими или какими угодно другими ресурсами («На 20 падений сервисов ответим наймом 20 новых DevOps-инженеров!»), нужно сесть и подумать, почему сервис падает и как сделать так, чтобы он не падал. Тогда наши инженеры могут заниматься новыми более классными штуками, например, попилотировать CI/CD инструменты, которые они еще не трогали, чтобы потом к нам прийти и сказать: «Чувак, я нашел что-то круче Jenkins»:
То есть root cause — работа с технологическим долгом, который не всегда будет вашим, кстати. Продуктовая команда в энтерпрайзе иногда вынуждена менять не свой код (например, в случае сервисной шины) для того, чтобы внедрить фичу в продакшн, изменение в функциональности и выкатить его на рынок.
Взаимодействие со смежными сервисами
Представим, что мы разрабатываем функционал выдачи кредитов в мобильном приложении. Я — product owner в розничном кредитовании с отличным отделяемым P&L. И есть ряд каналов, через которые я этот продукт продаю — сайт, iOS и Android приложения, мобильное рабочее место операциониста.
В мобильном приложении банков, как вы знаете, какой только функциональности нет — от переводов между картами до выпуска новых карт, погашения ипотек, алиментов, оплаты ЖКХ и прочего. Это круто, это XXI век:
Но я, как product owner, отвечаю только за свой продукт — за розничное кредитование. А если в мобильном приложении, например, iOS, которым пользуются миллионы людей, вдруг сбойнул текущий счет и человек просто свой баланс не видит? Он не будет, заходя в приложение, даже думать о том, чтобы взять кредит. Он скажет: «О! Где мои сто тысяч рублей?!» и будет звонить в банк и спрашивать: «Доколе?!»
Поэтому взаимодействие со смежными сервисами — это та часть жизни вашей продуктовой команды, который может вам как сильно помочь в чем-то, так и сильно помешать.
В чем он может вам помочь? Если вы делаете какие-то смежные маркетинговые компании и продвигаете их через единый канал (например, мобильное приложение), вы можете получить синергию. Например, я выпускаю функционал по розничному кредитованию и могу предложить кредит на супер-условиях для молодых семей. А команда ипотеки то же самое делает, но для пенсионеров и лиц пожилого возраста. Мы можем прекрасно скооперироваться и вывести единый релиз под эгидой социальной защищенности.
Или если вы имеете внутренний опенсорс, то часть компонентов, которые вы используете со смежными сервисами, можно переиспользовать. Например, API или графические интерфейсы. Это вообще true — никто давно уже не переписывает фронт или элементы дизайна каждый себе. Так вы сможете а) сэкономить, б) потенциально не потерять аудиторию (если что-то пойдет не так) или не вызвать волну хейта именно к вашему продукту.
Также потенциально вы можете получить совершенно неочевидные бенефиты, если будете более плотно дружить и общаться не только с клиентом, который вам платит, но и с теми людьми, которым он платит тоже. Это люди, которые “сидят” на тех же каналах с вами, в одном банке.
И наоборот. Они могут у нас увести активную аудиторию, сломать приложение, которое является каналом продажи наших услуг. Синхронизация релиз трейнов, расписания поставок, или чего угодно, что вы используете — важно.
Прикладные платформы
Это частный случай смежных сервисов. Ранее упомянутая шина — одна из них.
В банках это чаще всего DWH и АБС — автоматизированные банковские системы. АБС — это монструозная конструкция, в которой делается собственно банкинг. Там происходят основные финансовые операции, генерируется отчетность ЦБ. Это мозг зверя по имени банк. А все остальные его органы с АБС так или иначе взаимодействуют. Обычно АБС в банке ровно одна, потому что больше не надо. Есть исключения, например, при объединении банков какое-то время они живут с двумя, а то и тремя АБС, но обычно это нерационально. Так же, как и в случае с процессингом.
Любая платформа — это, по сути, черепаха, на которой стоит мир. Клиенты пользуются вашими услугами – они покупают кредитку, скачивают мобильное приложение, отправляют друг другу стикеры и чатятся. Но если у вас где-нибудь умрет процессинг, всё пойдет насмарку:
С процессингом вы можете общаться, либо выпиливая из него некоторые сервисы, микросервисы и другие абстракции, либо попросить свои платформы, чтобы они сделали унифицированный канал общения всех сервисов с ними. Тогда случай, происходящий с одним продуктом, не будет аффектить на платформу, и как следствие, — на другой продукт.
Это базовая безопасность, которая позволит вам не упасть в случае падения платформы. Если в вашей компании упадет сервисная шина, ваш продукт упадет и не будет работать тоже. Если в банке упадет процессинг, через 5 часов вам позвонят из ЦБ, а через сутки заберут лицензию, каким бы банк ни был, даже №1. Это недопустимо.
Когда вы дизайните вашу кросс-функциональную (продуктовую) команду, платформа — это то, что вы должны держать в поле зрения. Вы должны уметь безопасно работать с платформой, а платформа должна уметь безопасно работать с вами.
Инфраструктура
Инфраструктурный департамент — это те обслуживающие подразделения, которые представляют сервисы командам для того, чтобы они могли пилить свои продукты — железо, сети, и так далее. При этом, сама по себе инфраструктура — это адский ад сложностей. Потому что никто снаружи не понимает, как она устроена и какие есть планы ее развития. Они говорят: «Друзья, у вас сейчас голый Docker, мы пилотируем ванильный Kubernetes, еще в январе у нас будет Tanzu, еще где-то там рядом Openshift». А потом: «Все, это мы больше не поддерживаем, переезжай вон туда». Когда и чем всё это кончится, непонятно:
Вы всегда должны понимать, что происходит и будет происходить с вашей инфраструктурой, причем под инфраструктурой я понимаю и hardware, и базовые middleware штуки, и те самые оркестраторы всего на свете, которые вы используете при работе. Вы должны знать в моменте, как их использовать, как их точно не использовать и что с ними будет дальше. Потому что это даст вам возможность не только не допустить ошибку (классика), но и потенциально получить гешефт.
Хороший пример: у нас недавно появилась новая команда, которой нужна помощь в настройке CI/CD. У нас в банке CI/CD тулой сейчас является Atlassian Bamboo. Мы могли им сказать: «Друзья, вот Atlassian Bamboo, вот SDK, вот человек, который вам поможет это настроить. Мы готовы отправить вас на наш курс CI/CD, где вам расскажут основные паттерны взаимодействия — наслаждайтесь».
Но прямо сейчас мы в банке пилотируем другие альтернативные инструменты, так как нас во многом не устраивает Bamboo. Этой команде мы объяснили, что расклад такой — прямо сейчас есть Bamboo, есть пилоты такого и такого инструментов: «Не хотите ли вы попробовать сделать на них?» Риски понятны: если пилот не пойдет, им придется все это перевезти на тот, который будем внедрять. Но мы гарантируем поддержку и поможем им перепилить, чтобы безопасно перейти на тот, который будет выбран целевым.
То есть мы им дали информацию о том, какие минусы есть у текущего инструмента и какие плюсы у потенциально будущего. И дали информацию о том, как работает наша инфраструктура, чтобы они сделали осмысленный выбор. Они сказали: «Да, кайф», и выбрали тот пилот, в котором им было бы интересно поучаствовать. Без этой информации, просто выбрав «линию партии» и продолжив на Bamboo, через пару месяцев мы бы получили волну негатива, когда поменяли бы наш CI/CD-оркестратор: «Ребята, мы два месяца назад приходили...»
Танцуем от цели
Очень часто команды изобретают велосипед. Например, мне нужно выбрать инструмент оркестрации контейнеров. Я смотрю в Google какой-нибудь рейтинг от Gartner и вижу там K8S: «Нам нужен Кубер прямо сейчас!» — «Почему именно Кубер?» — «Да потому что я нагуглил, и он в каком-то рейтинге первый».
Но такой способ выбора решения не самый оптимальный. Нужно танцевать от цели. Какая у нас цель, зачем мне вообще оркестрация контейнеров? Зачем мне в принципе контейнеры? Затем, что я не хочу, чтобы каждая из команд, которые я обслуживаю (которым я служу — есть такой термин servant leadership, лидерство как служение), тратила по неделе рабочего времени одного человека на то, чтобы заполучить базовые образы, которые они потом будут в своем CI/CD конвейере использовать. Я хочу создать централизованно полный набор образов, которые будут безопасны, всех удовлетворять и прочее. Куда-то их положить, чтобы всем было хорошо, комфортно и удобно, и пусть юзают.
Поэтому целесообразно спросить тех, кто ими пользоваться будет. Клиенты — это мои команды: «Ребята, у вас какие ожидания?» Если они будут называть названия оркестраторов — это не то, что мне нужно. Мне интересны принципы, по которым они выбирают.
Один скажет, что ему нужно, чтобы работало быстро: быстро писалось и быстро читалось. Второму важно, чтобы на рынке была экспертиза представлена, потому что он ноль в этом, а ему надо брать с рынка джуниоров, которые в этом быстро разберутся (т.е. чтобы было просто). Третьему нужно, чтобы какой-нибудь PCI DSS проходил (стандарты по работе с картами Visa, Mastercard и НСПК) — особенные требования к безопасности — должен прийти аудитор и кадилом помахать: «Ваше управление контейнерами удовлетворяет требованиям PCI DSS».
Я выписываю эту критериальную таблицу и на ее основе принимаю решение, какой оркестратор мне нужен. У любой команды-потребителя сервиса должна быть возможность влиять на тот стек инструментов, который вы ей предлагаете. Я за то, чтобы люди сами определяли, что им нужно и как они хотят решать свои проблемы. А я предлагаю те решения, которые на мой взгляд удовлетворяют этим потребностям.
Конечно, у меня сбоку будет своя критериальная таблица типа: сколько это стоит, насколько просто это поддерживать, модель лицензирования и т.д. Но команды всегда дают input, что они хотят от своей инфраструктуры. Они хотят быстро, дешево, гибко — ОК, это их право. Они имеют право это требовать от нас, как от сервисных подразделений.
Как все это сделать?
Вы можете сказать: «Молодец, рассказал очевидные вещи — спасибо, кэп! — а что с этим делать?» Ответ очень простой: создать в вашей компании такую среду, чтобы работать неправильно было некомфортно, слишком дорого, сложно и т.д.:
Взаимодействие с клиентом
Как заставить, побудить, продать (какие угодно слова можно использовать) наши команды взаимодействовать с клиентом, чтобы они начали его слышать и слушать? Вы должны включить им голос клиента в какой-то мониторинг, либо в цели. Хоть радио в офисе повесьте с записями из отделений банка, как бабушки кричат том, что полчаса не могут пенсию снять.
Как это сделано у нас. Мы безальтернативно проводим опрос клиентов по основным банковским услугам, потом безальтернативно всем его показываем. Например, вы продаете кредитные карты, а вы дебетовые: вами довольны, а вами — нет. Люди видят результаты друг друга и понимают, что происходит не так. Их никто за это не наказывает, просто им стыдно. Когда один продукт любят, а второй нет, то вторые придут к первым и попросят рассказать секрет – что я делаю не так, что ты делаешь так, почему так происходит? Со временем эта история всегда выравнивается, потому что системы (а корпорация – это конечно система) склонны к равновесию.
Это очень долго, если у вас инертная компания, но, если вы молодые и энергичные ребята — это будет быстро. Если вам не все равно, процесс можно ускорить — ходить и пальчиком тыкать: «Смотри, у них хорошо, у тебя плохо. Не хочешь присмотреться?» Мы так делаем.
Резюме
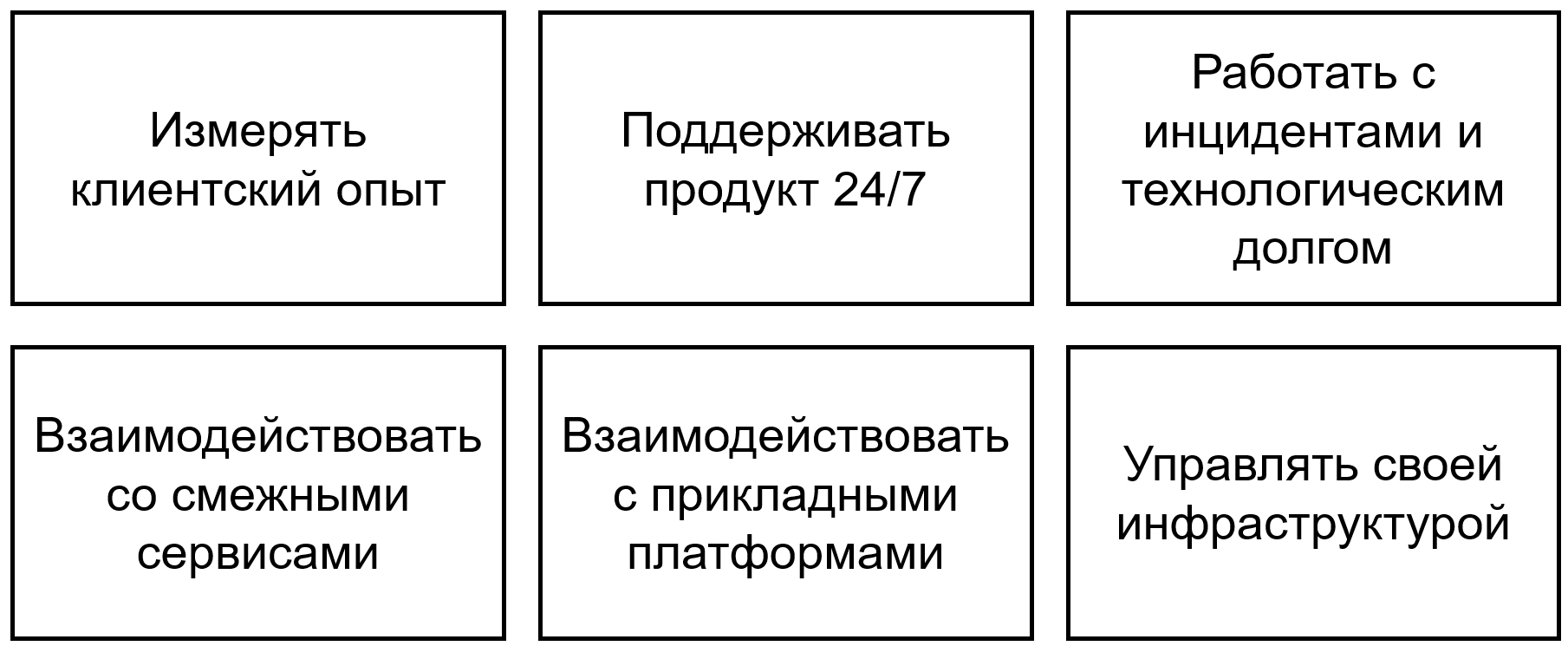
Кросс-функциональная команда умеет:
1. Измерение клиентского опыта
Давать тут какие-то советы на мой взгляд не нужно, потому что литературы написано более чем достаточно. Просто перестаньте додумывать за клиента, и попробуйте любым способом узнать, что он на самом деле хочет.
2. Поддержка продукта 24/7
Помните, как раньше учили детей плавать? Вывозишь на лодке на середину реки и бросаешь в воду: «Давай, встретимся на берегу!» В переводе на нормальный язык с языка метафор это значит, что пусть команда пострадает.
Вы им говорите: «Вас 10 человек. Есть возможность работать с горячей линией 24/7, но для этого нужны скрипты, которые вы должны дать. Но вы можете этим не пользоваться — живите, как хотите!», а потом все звонки на горячую линию, когда какая-нибудь кредитка умерла, роутить прямо на product owner. В субботу ночью? ОК! В воскресенье ночью? ОК! В понедельник примерно к 5 утра он задумается о том, что же он делал в этой жизни не так, и к обеду скрипт будет в службе 24/7 — готовый и со всеми нюансами.
3. Технологический долг и инциденты
Тут несколько вариантов решения. Можно использовать тот же самый метод тотальной открытости, когда все видят, что одни перформят, другие нет — и смотрите, почему. А можно попытаться обосновать, что устранение технологического долга дает им измеримый бенефит.
Например, у вас и у соседней команды плюс-минус похожие продукты, но у вас стремный legacy-код, а у соседней команды — нет. В результате у вас есть некий постоянный уровень аварийности (допустим, 10 аварий в год), в отличие от той команды. Тут очень важный момент — нужно найти человека, который согласится исправить что-то один раз. Найдите конкретный legacy-фрагмент в коде и поймите, на что это влияет. Потом убедите команду это изменить и покажите цифры: «Вот у тебя было 10 аварий в год, теперь их 8! Давай сделаем дальше, и будет у тебя еще все более круто».
4. Взаимодействие с прикладными платформами
В структуре организаций частенько встречается некая платформенная команда, которая сидит, отгородившись отрядом лучников, скелетов, черных драконов, и никого к себе не подпускает: «Вам нужна доработка — приходите через 9 месяцев».
В этом случае мы задаём вопрос — что я могу сделать, чтобы я получил быстрее то, что я хочу? У продуктовой команды в целом таким и должно быть мышление — если вам что-то нужно, но говорят НЕТ, то узнайте, что нужно сделать, чтобы было ДА. То есть узнать, что нужно сделать, чтобы прикладная платформа внедрила изменения на своей стороне, которые нужны вам, быстрее (например, через месяц) — должны вы, как идеологи DevOps. Например, давайте сделаем API, или давайте продуктовая команда сделает изменения в платформенном коде, только чтобы все это было безопасно и т.д.
5. Взаимодействие со смежными сервисами
Аналогично — никаких секретов, просто человеческое общение, поиск взаимовыгодных условий совместной работы и ad hoc решение задач.
6. Инфраструктура
Как это бывает: приходит новая команда и говорит, что им нужны среды: «Нам нужен продакшн-сервак, у нас релиз через месяц». «Хорошо, вот заполни Excel, что конкретно ты хочешь, там всего 120 строчек». Я смотрю в эту таблицу и понимаю оттуда от силы 20 строчек, а для остальных мне нужен переводчик — человек, который знает, как их заполнять. Когда мы первый раз сказали нашей инфре, что это странно, — даже мы в этом не шарим, — то они дали нам образец, как это заполняется. С образцом я стал уметь заполнять 40 строчек из 120.
Я как потребитель постоянно говорю, что именно мне неудобно до тех пор, пока сервис не станет идеальным. Это один из принципов Agile —делаем не сразу идеально, а движемся постепенно к тому, чтобы стало хорошо, постоянно делаем лучше и лучше. Сейчас наша инфраструктура понимает, что она в первую очередь сервис, и теперь думает, как сделать жизнь своих клиентов легче.
Это шесть основных моментов, на которые, как показал опыт моей команды, нужно обращать внимание.
Если вы знаете еще какие-то вещи, которые кросс-функциональная продуктовая команда должна уметь делать со своим окружением — пишите, обсудим.
Вместо заключения: это будет непросто
Это невероятно сложная и неблагодарная работа — всё это провернуть и претворить в жизнь. Вам будет очень тяжело, если вы встанете на этот скользкий путь. Нам было очень тяжело:
Каждый раз, когда вы говорите, что будете менять среду таким образом, чтобы она побуждала людей сделать что-то, чего они раньше не делали, это будет дико демотивировать вас и ваших людей. Вы будете выгорать и ненавидеть весь мир. Но потом (через пару лет), люди, у которых стало хорошо, скажут: «Я красавчик, я всё сделал. Ты мне помогал, я помню. Но это фигня, а вот я красавчик!»
У нас две важных новости о конференции HighLoad++ 2020. Во-первых, готово расписание конференции. Оно будет дополняться, но планировать дни 9 и 10 ноября уже возможно.
Во-вторых, HighLoad++ 2020 переезжает из Сколково в большее помещение — в Крокус Экспо. Это ещё одна мера безопасности — большая площадка позволит нам дополнительно разрядить пространство и рассредоточить слушателей.
В программе — доклады от разработчиков, CTO и основателей технологических компаний. Узнаем, какие технологии применяют в Badoo, Сбере, Tinkoff, Яндексе, Юле, Erlyvideo и в других компаниях-лидерах рынка.
Официальный телеграм-канал конференции поможет вам быть в курсе событий и изменений, а неформально обсудить можно в этом. Забронировать билет на HighLoad++ 2020 можно здесь. Встречаемся 9 и 10 ноября в Крокус Экспо!
")
