
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Безопасность — это защита объектов и интересов от угроз. Когда кажется, что с ней всё хорошо, в интернете появляется много интересного: списки e-mail и телефонов из незащищённой базы данных крупных магазинов, записи колл-центров некоторых операторов, логины и пароли производителей оборудования из открытого репозитория или данные миллионов кредитных карт клиентов крупных банков.

Безопасность — это непросто. Но и ничего сложного в ней тоже нет — это множество рутинных действий: инвентаризация, мониторинг, проверка доступов, тесты, инвентаризация, контроль, мониторинг, логирование, инвентаризация и инвентаризация. В безопасности много инвентаризации. Почему так, что такое безопасность и с чего она начинается, расскажет Мона Архипова.
Мона Архипова — соучредитель и COO в sudo.su (МИРЦ) и vCISO Anna Systems. Ранее работала на различных руководящих и экспертных должностях в IT и безопасности. Всё ещё играющий бизнес-тренер.
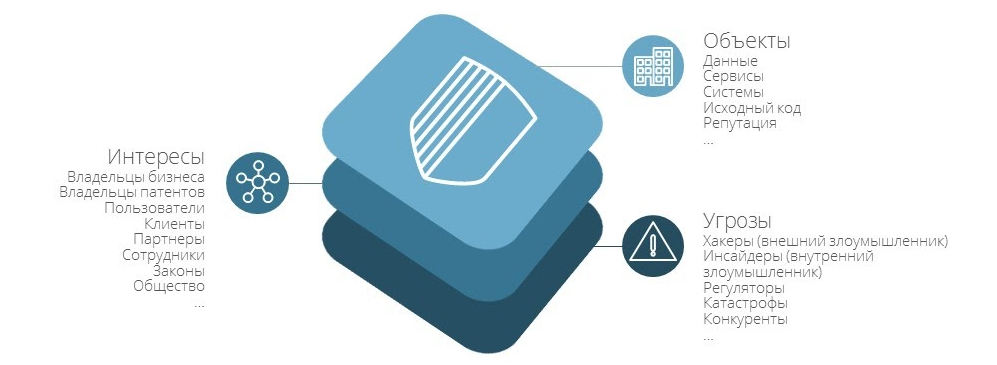
В безопасности есть несколько базовых понятий.
Объекты: данные, сервисы, системы, исходный код, репутация и другие вещи, например, корпоративная техника.
Интересы — это «заказчики» защиты: владельцы бизнесов, патентов, пользователи, партнёры, сотрудники, законы и общество. Никто не хочет, чтобы их персональные данные попали в Интернет.
Угрозы — то, от чего мы защищаем заказчиков:
Для каждого бизнеса набор угроз уникален. То, что важно для банковского сектора, не так важно, например, для IOT или промышленного производства.
В разных вариациях мониторинг есть у всех. Маленькие компании мониторят доступность сайта, а большие сотни параметров сложной инфраструктуры.
В мониторинге есть «два стула» — два разных подхода. Первый — IT-мониторинг и метрики. Эта «классика жанра» тянется с тех времён, когда не было DevOps, как отдельного направления, и работа не была сильно связана с IT. Это то, что начинают делать все: мониторят загрузку ресурсов, каналов, ошибки сервисов — всё, что связано с техникой.

Второй подход — «от бизнеса». Бизнесу не интересны графики свободной памяти, потери и миллисекунды. Ему важно, чтобы работали ключевые бизнес-процессы. К бизнес-метрикам относятся, например, мониторинг регистрации новых пользователей или смс с подтверждением входа. Мониторинг переходит на этот уровень когда бизнес приходит с вопросами, что у них что-то не работает.
Между IT-мониторингом и безопасностью легко провести аналогии. Как процессы, они похожи, поэтому мы их отслеживаем. Здесь есть несколько уровней.
Базовый мониторинг отвечает на вопрос: «Что у нас в сети?» Это обнаружение и инвентаризация всех активов: серверы, сетевое оборудование, рабочие места. Чтобы понять, как всё работает, мониторим всё, что «внутри» и что участвует в процессах.
Типы источников. Это следующий уровень после безопасности, который в IT называется «технологическим стеком». Это весь наш «зоопарк»: операционные системы, базы данных, языки, дополнительные агенты, хранилища и типизация всего для разработки новых проектов.
Системные настройки. В безопасности это уровень чуть выше — стандарты конфигурации операционных систем. Мы ищем открытые в мир дефолтные порты на уровне ОС, изучаем системные параметры, память, пароли по умолчанию и вероятные небезопасные настройки.
Настройки приложений, баз данных. В безопасности это политики безопасности приложений и сервисов — проверяем, что всё настроено по внутренним регламентам. Здесь важно отслеживать использование простых паролей, паролей по умолчанию и других небезопасных конфигов. На этом уровне заканчивается технический мониторинг.
Дальше начинается бизнес-уровень — потоки данных. По личному опыту многие считают, что они к ним не относятся. Но когда что-то не работает или скомпрометировано, нужно понимать почему и как всё было настроено.
Когда работала в QIWI, я собирала тимлидов команд, которые разрабатывают разные части процессинга. Каждую неделю мы строили диаграмму потока данных, что тимлидам не нравилось. Но встречи позволили существенно сократить время реагирования на инциденты, а специалистам дежурной смены понять, как и что у нас работает, где проблемы и как их корректно диагностировать. Безопасности же это дало понимание, что с чем взаимодействует в штатном режиме и что можно считать аномальным потоком.
Поведенческий анализ. Это метрики на уровне взаимодействия с пользователем, их редко используют. Примеры: в безопасности это UEBA — User EndPoint Behaviour Analysis, а в IT тот же Google Tag Manager, который составляет тепловую карту сайта.
Потоки данных и поведенческий анализ интересны бизнесу. Это язык, на котором разговаривают люди без глубоких технических знаний.
Погрузимся детальнее в общие процессы: как всё выстраивать с нуля и как всё построено в sudo.su.
Инвентаризация — первое с чего мы начали. Мы используем как скрипты, так и инструменты, которые отслеживают, что нового в сети, что запущено и где работает. Инвентаризация как процесс помогает наводить порядок. Но приступайте к инвентаризации только после устранения хаоса.
Например, в управлении паролями важно их регулярно менять. Это очевидная вещь и самая частая проблема. Регулярная смена паролей — это минимальная гарантия того, что инциденты не возникнут спустя два года после установки пароля. Здесь нет надежды даже на хэши. На современных мощностях перебор MD5 или коротких паролей занимает мало времени.
Логирование. Для сбора логов у нас есть центральный сервер. Российских вариантов таких решений нет, поэтому используем Splunk. Мы собираем в него как IT-логи, так и логи безопасности. IT-логи позволяют выявлять инциденты, например, с падением или долгим временем ответа. Сбор логов, например, веб-сервера помогает понять, кто нас сканирует.
Безопасная настройка. Мы её автоматизировали с помощью настроек в соответствии с нашим Hardening guide. Мы усилились выключив некоторые функции системы и удалив лишних пользователей, группы и пакеты.
База знаний. Это боль — никто не любит писать документацию, потому что скучно и «всё же и так можно посмотреть». Но она позволяет сократить время реагирования на инциденты, также как и осведомлённость сотрудников. Если в отдел безопасности или к сисадминам приходит бухгалтер и говорит, что пришло письмо с темой «Инвойс» в каком-то .exe файле, то это осведомлённость. Благодаря базе знаний бухгалтер понимает, что в непонятной ситуации следует обращаться в отдел безопасности, не открывать подозрительные файлы и не проходить по странным ссылкам.
Это базовая общая вещь. Она необходима всем, как финансовая или техническая грамотность, чтобы не носить последние сбережения в пирамиды и не заряжать банки с водой у телевизора.
Перейдем от теории к практике.
На сайте CIS Controls (Center for Internet Security) доступны базовые контроли: скачайте, посмотрите детальное описание. Всего контролей 20. Они делятся на три части: базовые, основные (сложнее) и организационные. Последние для тех, у кого безопасность уже «созрела» и выполняются первые контроли.
80% всех проблем безопасности закрываются первыми 6 из 20. Рассмотрим их подробнее.
Чтобы понять, что защищать, нужно все пересчитать и инвентаризировать, как ПО, так и физические активы. Например, для физической безопасности важно, чтобы у вас физически не вынесли сервер, а для IT, чтобы не «утекли» данные с сервера.
Варианты инвентаризации:
Базовые настройки. При инвентаризации убедитесь, что нигде нет связки «логин-пароль» по умолчанию или слабых, вроде «admin-admin» или «root/123QWErty!». Смените, удалите и отключите все неиспользуемые сервисы. На основе инвентаризации составьте чек-листы по установке нового сервиса, например, базы данных или вашего приложения.
Контролируем инвентаризацию системой управления конфигурациями, CI/CD (через хуки) или системой мониторинга.
Мониторим: проверяем всё неучтённое, сравниваем все конфигурации по эталону и чек-листам.
Уязвимости особо актуальны для зрелых компаний. Обычно там появляется legacy — «очень важная система на которую нельзя дышать и обновлять» от которой трудно избавиться. По критичности legacy стоит на одном уровне с дефолтными логинами и паролями или не защищенной базой данных. Если у вас мало такого «исторического наследия» — самое время начать регулярное управление уязвимостями.
Проверяем патчи. Начинаем управление с изучения того, что патчим вручную или автоматизированно.
Вручную: подписываемся на maillist, security-рассылки. Для автоматизации используем сканеры безопасности. Выбора много: Openvas, Nexpose, Nessus, MBSA, как платные, так и бесплатные. Платные обновляются быстрее, бесплатные медленнее. Возможно даже вручную собирать версии пакетов и мониторить обновления, но для больших инфраструктур это плохо работает.
Создаём тестовую группу. После того, как составили список того, что хотим патчить, убеждаемся, что ничего не ломается, как с любым другим ПО и изменениями. Для этого выделяем тестовую группу на которой всё обновляем. Подтверждаем, что ничего не ломается, сервисы работают, а производительность не просела, и идём дальше.
Идём не только в продакшн, даже если «всё изолированно» и «это же тестовая среда». Мало у кого в тестовой среде исключительно тестовые данные, очищенные от чувствительной информации. Когда продакшн защищен, а тестовая среда доступна всему свету (даже если через VPN), и в ней находятся пользовательские данные, то это будет первая точка для утечки.
За тестовой средой обычно следят намного меньше (мониторинг, логи) и патчить надо всё. Тест и продакшн должны соответствовать друг другу по версии пакетов и внешним соединениям. Опять же возвращаемся к инвентаризации.
Мониторим — подтверждаем, что везде применились изменения: проверяем последние версии пакетов, версии конфигураций. Перезапускаем то, что нужно перезапустить.
Составляем список «привилегированных» пользователей. Многим неудобно регулярно менять пароли или настраивать sudo исключительно для каких-то определенных действий. Примеров в практике много, например, кто-то ведет разработку на продакшн и постоянно пускает туда разработчиков или Ops-инженеров. При этом пароли не меняются и результат всем понятен.
Чтобы этого избежать, задаем вопрос: «Кому можно?» Вопрос не только о продакшн-системах, но и о пользовательских. С внедрением будет много проблем и вопросов, вроде «Раньше я мог поставить программу, а теперь не могу», но это важно.
Регулярно проводим инвентаризацию пользователей и прав, системных пользователей и смену паролей. Если не менять пароли, то однажды они попадут к тому, кто их не должен знать. Идеально менять их с регулярностью раз в три месяца.
Требования к сложности паролей. Немного «Капитана Очевидность» — пароли вида «1111» или состоящие из букв словаря, быстро подбираются простым перебором паролей. Поэтому задавайте сложность пароля: 10 или больше символов, цифры, спецсимволы, прописные и строчные буквы. Перебор подобного хэша будет занимать много времени (но не отменяет возможность перехвата другими способами). Если менять пароль раз в три месяца, то к моменту перебора, он будет уже другой.
Находим ответственного. Вы всегда должны знать ответ на вопрос: «А кто это сделал?» У всех были инциденты с тем, когда кто-то что-то удалил. Но в случае инцидентов жёстче, желательно знать виновника. Организуйте документальное подтверждение — складывайте логи в отдельное место с более жёстким доступом к нему. Если система скомпрометирована и логи будут потеряны или удалены — всегда будет дубль.
Этот контроль относится не только к серверам, но и к мобильным рабочим станциям, ноутбукам и мобильным телефонам.
Первый шаг — типизация стека, ПО у пользователей и на продакшн. Об этом мы уже говорили.
В CIS есть готовые наборы стандартов, как на уровне ОС (Linux, Windows, Windows-сервер), так и на уровне самых популярных сетевых устройств и баз данных. По необходимости адаптируйте конфигурации под свои нужды.
«Напильник». Бездумно применять практики — плохая затея. Если скачать политику для Active Directory и внедрить её не тестируя, то на выходе будет полностью неработающий офис. Он будет требовать FIPS, чтобы рабочие станции соединились с AD. А если послушать CIS Benchmark Linux и выключить IP-forwarding, то развалится Docker.
Контролируем исполнение:
Мониторим — регулярно проверяем, что всё настроено по стандарту. У меня это происходит раз в сутки. Для больших систем желательно проверять всё за три дня. В этом помогают системы управления конфигурациями, системы мониторинга или локальные скрипты, которые просто отправляют отчёты.
Любимая тема, о которой могу говорить часами: мониторинг, логирование, чтение логов. Казалось бы, давайте всё залогируем и ничего не пропустим. Но всё не так просто.
Начинаем с типизации (см. выше). Примеров масса, я пользуюсь двумя. Для приложений — гайд Open Web Application Security Project. В нём подробно описано, что писать в логи приложения: входы, выходы, пользователи, эскалация прав. Для безопасности — чек-листы, которые указывают на то, какие типы событий обязательно надо мониторить.
Как логировать и где хранить. Иногда логов бывает слишком много. Логирование в больших системах создаёт столько логов, что нет смысла реагировать на каждое событие — они слишком сильно шумят. Перед тем, как выбирать что логировать, обращайте внимание:
Храните логи не меньше трех месяцев. Например, по стандартам платежных систем они хранятся год и больше. Иногда, ретроспектива помогает увидеть, что полгода назад начались проблемы, даже если не было инцидентов — просто мониторинг «недомониторил».
Сбор и корреляция. Иногда логи занимают слишком много места и стрелка компаса поворачивается от «Логировать всё» к «Логировать минимум». Но хранить лучше больше, чем меньше.
В оперативном доступе на быстрых носителях храните данные за месяц. Это помогает экономить ресурсы в скорости обработки — архив можно вынести на сервер помедленнее. Но всегда должна быть возможность извлечь архивные события, чтобы проверить свои гипотезы и предположения.
Базовые правила корреляции. Перебор паролей, попытка авторизации под одним логином на множество серверов, странные запросы похожие на SQL в логах веба, попытка входа под выключенной учетной записью — это базовые вещи, на которые стоит настроить оповещения и активно реагировать.
Мониторим логирование. Проверяем, чтоот всех источников поступают события и настроены оповещения.
План реагирования. В безопасности применяется чаще, чем в IT. Это иерархия: кому в какой последовательности звонить и писать. Например, в банковской сфере все знают о PSI DSS — по нему отрабатывается сценарий «утечка карт»: тестовые звонки и письма в платежную систему, тестовые ограничения периметра или локализация утечки.
Если стандартов нет — изучите, как логируют инциденты в материалах SANS. В маленькой документации они собрали множество примеров, которые помогут погрузиться в реагирование с точки зрения безопасности.
Я использую несколько инструментов в работе. Как и с любыми другими инструментами, которые вы выбираете, берите те, что вам подходят или как «исторически сложилось».
Обнаружение, аудит, патчи. Для обнаружения новых ассетов, аудита стандартов и конфигураций, установки патчей использую Nessus. Это платный и относительно дорогой продукт. Есть аналог — Openvas. Он бесплатный, но обновляется медленнее. Это форк старого Nessus в то время, как он был открыт.
Скриншоты из Nessus.
Nessus чудесен. Например, позволяет найти неподдерживаемые ОС и наглядно показывает критичность разных уязвимостей. По каждой из уязвимостей выдает короткое описание: что она делает, примеры и рекомендации по устранению (обновить пакеты или «вынуть и закопать»).
Конфиги, пользователи, стандарты, обновления. Стандартами конфигурации, пользователями и обновлениями у нас занимается Rudder.
В 1992, когда о безопасности и DevOps никто не слышал (счастливые времена), появился CFEngine. Это одна из первых систем управления конфигурациями. Rudder — это графическая надстройка над CFEngine, которая рисует красивые графики для руководителей и помогает посадить джуна «накликать стандарт конфигурации». В дашборде можно посмотреть правильность конфигураций, проверить стандарты и, везде ли они применились.
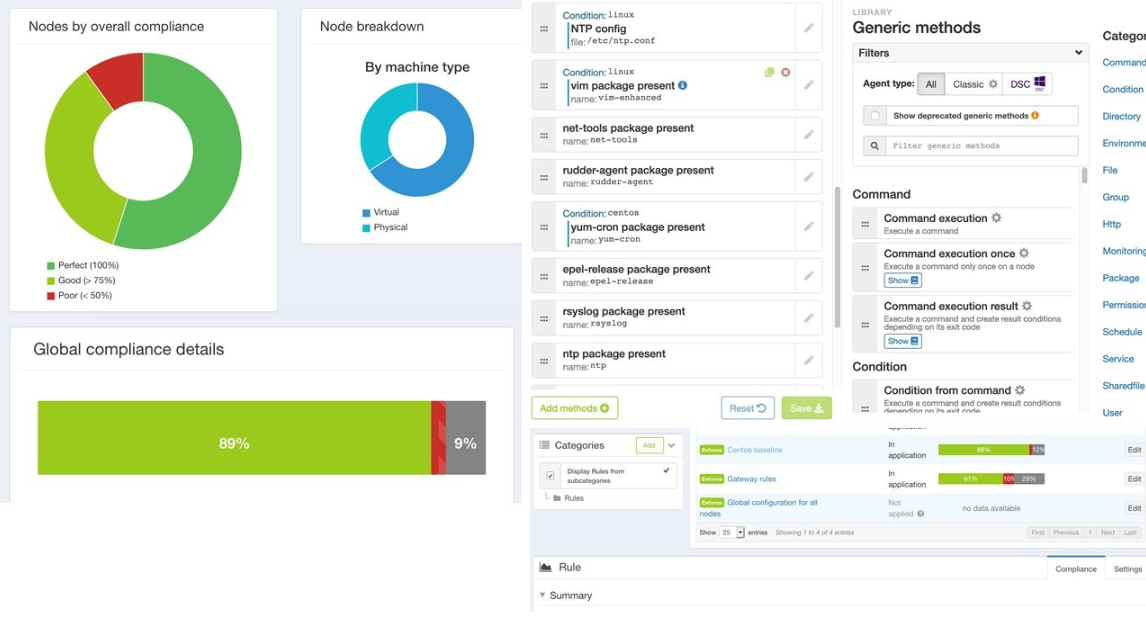
В Rudder много элементов для составления promise (конечного состояния системы) методов. Мы его используем для базовой автоматизации и мониторинга, а также чтобы показывать графики состояния конфигураций инфраструктуры нетехническим специалистам и аудиторам.
Код. Это далеко не базовый контроль. За чистотой и безопасностью кода мы следим инструментом Sonarqube: он интегрирован с нашим GitLab, за всем смотрим в динамике, а разработчики обучены как с ним работать и реагировать. Если хотите подсказки, то есть платная версия с модулями подсказок.
Это не единственный инструмент подобного рода. Есть множество аналогов анализаторов исходного кода в разных модификациях и для разных языков.
Тимлидам и руководителям будет интересно, как встроить показатели по безопасности в свою систему оценки. Общее правило при внедрении любого показателя эффективности: «Оценка должна быть качественной!».
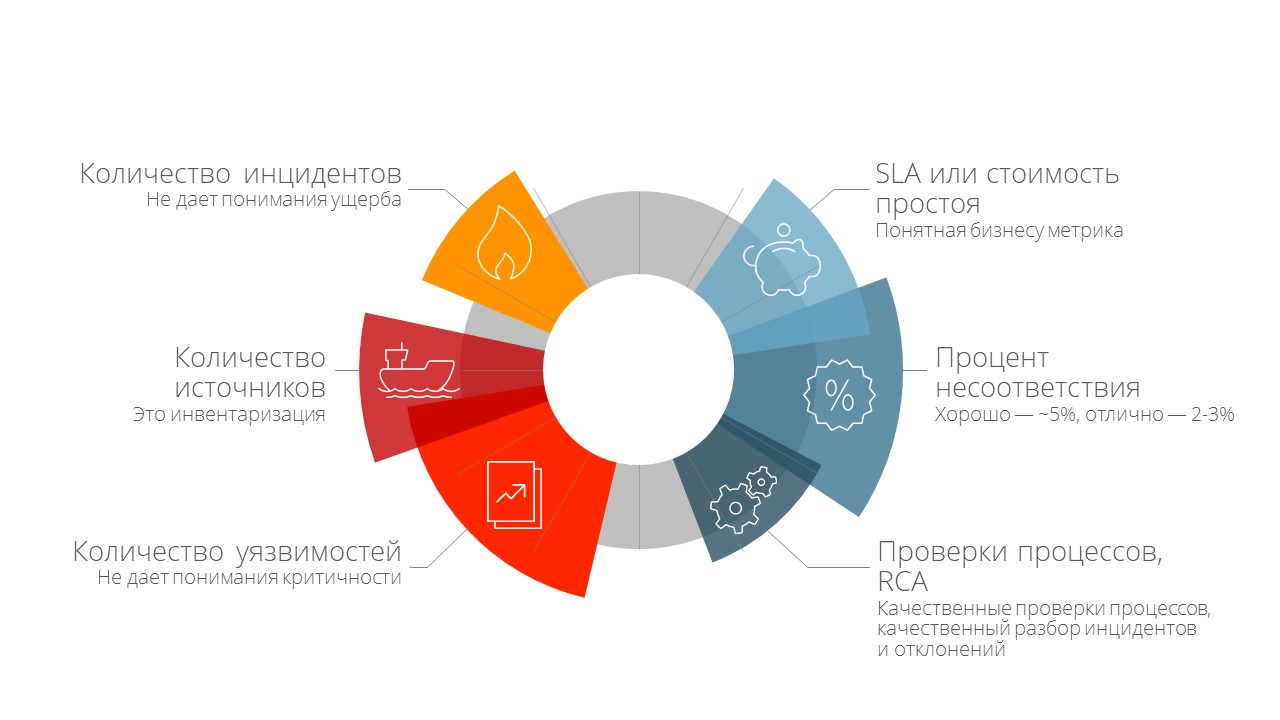
Некачественные KPI:
Качественные KPI.
SLA или стоимость простоя. SLA — для клиентов, OLA — внутреннее соглашение о качестве сервиса. Мы считаем SLA в разных вариациях, а стоимость простоя берем у финансового отдела или бизнес-подразделения. Они ответят, сколько будет стоить простой в регистрациях в течение двух минут или сбой в эквайринге на полчаса.
На ответы наложите свой SLA и получится понятная бизнес-метрика, за которую вас будут любить, холить и лелеять. Заодно для вас будет понятна цена влияния «кто выпустил этот минорчик в прод».
Процент несоответствия стандартам. Когда у нас два сервера и один из них не защищен, то процент несоответствия — 50. Очень редко встречается процент меньше 2, поэтому 5 процентов уже хорошо, а 2-3 — отлично.
Качественные проверки процессов и качественный разбор инцидентов и отклонений (RCA — Root Cause Analysis). Проводите регулярно — полезно не только для безопасности, но и для IT. Проверки и выяснение корня инцидентов позволяют поднять уровень сервиса и повышают осведомленность коллег о том, что вы работаете и регулярно проводите разбор полетов.
Это касается всех инцидентов, как обычных, так и связанных с безопасностью. Многие забивают на RCA, но его проведение без серьезного внешнего инцидента по результатам внутреннего регулярного процесса позволяет устранять системные проблемы. Они будут возникать все меньше и меньше.
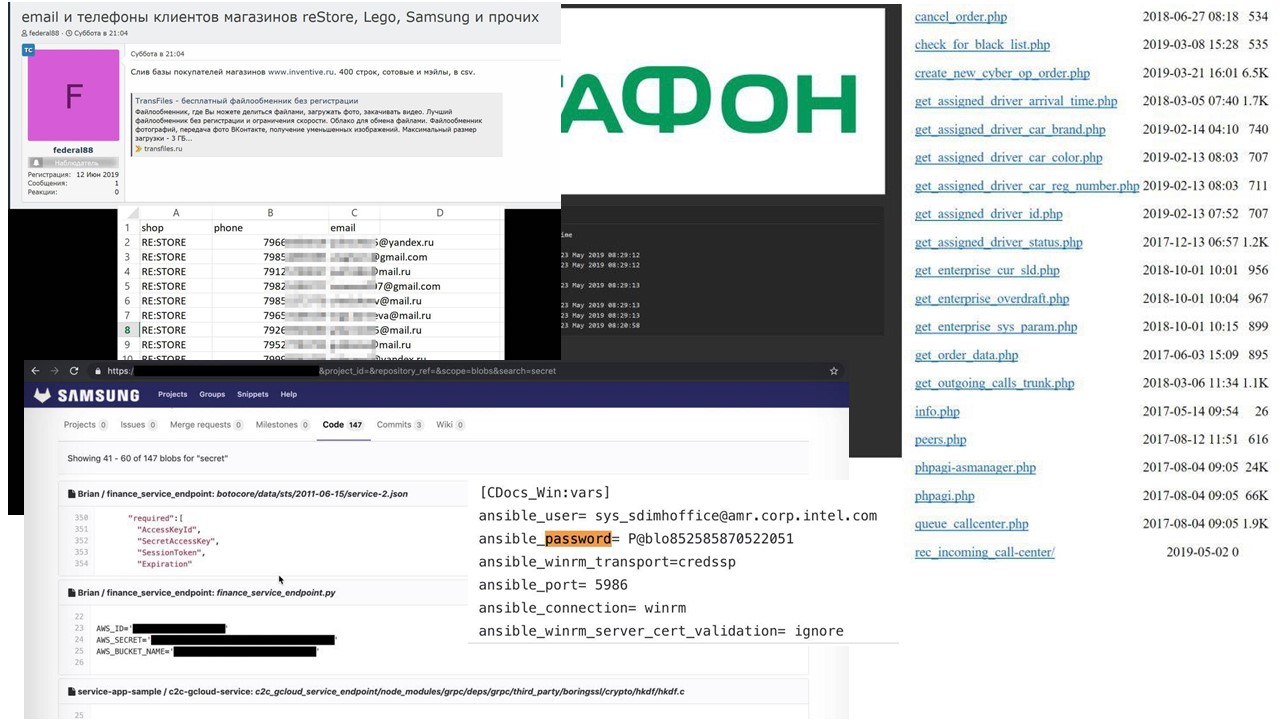
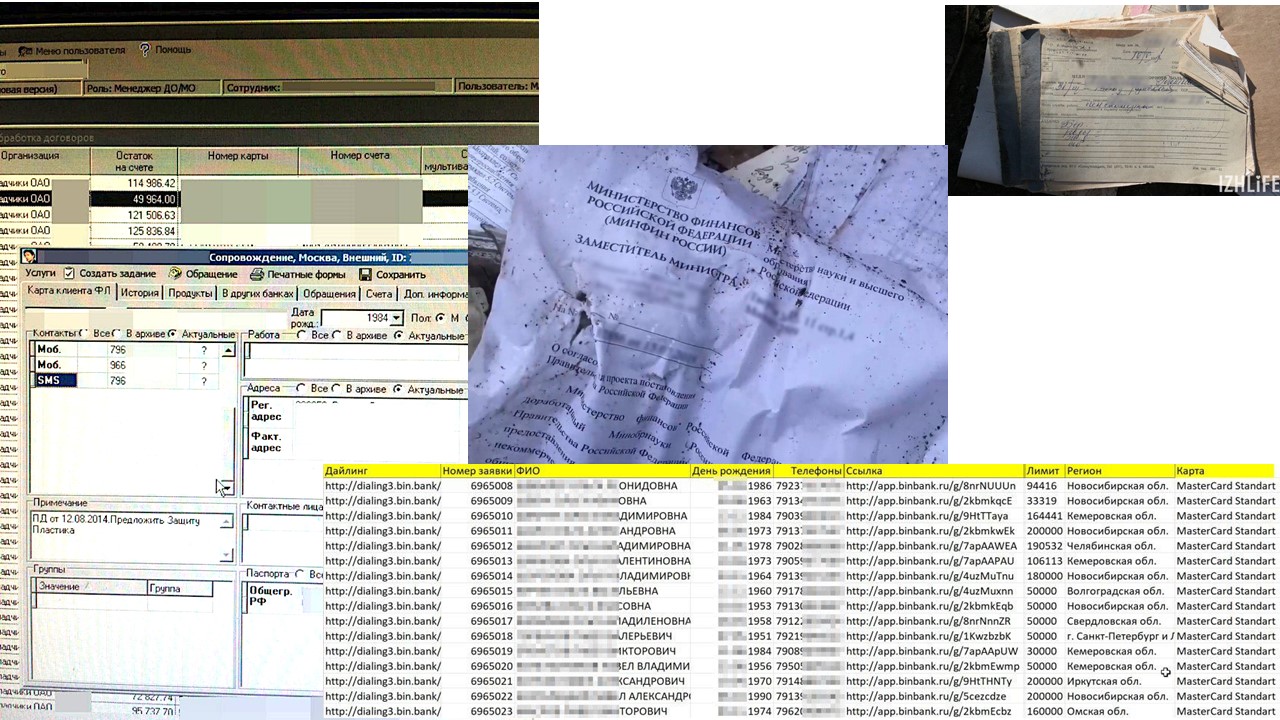
Мой друг ведет telegram-канал @dataleak об утечках данных. Он регулярно публикует позорные случаи: списки e-mail и телефонов из незащищённой базы данных магазинов ReStore, записи колл-центра МегаФон, логины и пароли Intel, которые хранятся в открытом репозитории.
Иногда утечки никак не связаны с IT. Например, когда документы просто выкидывают на помойку или выкладывают Excel-таблицу в Google Drive без каких-то ограничений.
В идеале, нужно учиться на чужих ошибках и заниматься безопасностью заранее. Но насадить безопасность нельзя. Невозможно заставить людей заниматься безопасностью, пока они не потеряют свои данные или бизнес. Люди делятся на тех, кто еще не делает бэкапы и тех, кто уже делает. С безопасностью так же: компании делятся на тех, кого еще не ломали и тех, кого уже ломали.
Но это не задача одного безопасника — сказать, как надо одинаково делать всем, и бегать проверять. Хороших специалистов мало, а бизнесов разных размеров — много.
После это выступления мы предложили Моне Архиповой вступить в Программный комитет DevOpsConf. Мы немного расспросили ее о том, как это произошло, чем интересно и каково по обе стороны.
— Мона Архипова: Когда мне предложили присоединиться к ПК DevOps Conf, я подумала и решила: «А почему бы и нет?» У меня большой опыт выступлений и подготовки к ним. Помощь другим спикерам — логичное развитие моих навыков. К тому же, я помогала запускать несколько конференций и раньше, поэтому это не первый опыт в Программных комитетах — уже было понятно, что делать.
В ПК хотела решить три задачи:
В Программном комитете мне интересен процесс подбора спикеров, обсуждение форматов. Я занимаюсь темой безопасности и далеко не все спикеры могут адаптировать доклады под аудиторию без нашей «очевидной всем» security-специфики. Это привносит дополнительную сложность. Готовить свой доклад было проще — опыт Ops всегда со мной и я всё ещё «играющий тренер».
В текущей ситуации неопределённости с массовыми мероприятиями участие в ПК становится ещё интереснее :).
Безопасность — это непросто. Но и ничего сложного в ней тоже нет — это множество рутинных действий: инвентаризация, мониторинг, проверка доступов, тесты, инвентаризация, контроль, мониторинг, логирование, инвентаризация и инвентаризация. В безопасности много инвентаризации. Почему так, что такое безопасность и с чего она начинается, расскажет Мона Архипова.
Мона Архипова — соучредитель и COO в sudo.su (МИРЦ) и vCISO Anna Systems. Ранее работала на различных руководящих и экспертных должностях в IT и безопасности. Всё ещё играющий бизнес-тренер.
Что такое безопасность
Безопасность — защита объектов и интересов от угроз.Это относится, как к кибербезопасности, так и к обычной физической.
В безопасности есть несколько базовых понятий.
Объекты: данные, сервисы, системы, исходный код, репутация и другие вещи, например, корпоративная техника.
Интересы — это «заказчики» защиты: владельцы бизнесов, патентов, пользователи, партнёры, сотрудники, законы и общество. Никто не хочет, чтобы их персональные данные попали в Интернет.
Угрозы — то, от чего мы защищаем заказчиков:
- хакеры — внешние угрозы;
- инсайдеры — внутренние;
- регуляторы, которые периодически отзывают лицензии у банков из-за взломов и потерь персональных данных клиентов;
- катастрофы: пожары, отключения электричества, затопления;
- конкуренты.
Для каждого бизнеса набор угроз уникален. То, что важно для банковского сектора, не так важно, например, для IOT или промышленного производства.
Безопасность — это просто (нет).Безопасность простирается от забора с пропускным режимом и колючей проволокой до PR-коммуникаций. О направлениях безопасности можно долго рассказывать, но мы попробуем понять, как внедрить процессы безопасности в IT-составляющую бизнеса. Начнём с того, что есть как у больших корпораций, так и у маленьких компаний — с мониторинга.
Мониторинг
В разных вариациях мониторинг есть у всех. Маленькие компании мониторят доступность сайта, а большие сотни параметров сложной инфраструктуры.
В мониторинге есть «два стула» — два разных подхода. Первый — IT-мониторинг и метрики. Эта «классика жанра» тянется с тех времён, когда не было DevOps, как отдельного направления, и работа не была сильно связана с IT. Это то, что начинают делать все: мониторят загрузку ресурсов, каналов, ошибки сервисов — всё, что связано с техникой.
Второй подход — «от бизнеса». Бизнесу не интересны графики свободной памяти, потери и миллисекунды. Ему важно, чтобы работали ключевые бизнес-процессы. К бизнес-метрикам относятся, например, мониторинг регистрации новых пользователей или смс с подтверждением входа. Мониторинг переходит на этот уровень когда бизнес приходит с вопросами, что у них что-то не работает.
Отслеживаем процессы
Между IT-мониторингом и безопасностью легко провести аналогии. Как процессы, они похожи, поэтому мы их отслеживаем. Здесь есть несколько уровней.
Базовый мониторинг отвечает на вопрос: «Что у нас в сети?» Это обнаружение и инвентаризация всех активов: серверы, сетевое оборудование, рабочие места. Чтобы понять, как всё работает, мониторим всё, что «внутри» и что участвует в процессах.
Типы источников. Это следующий уровень после безопасности, который в IT называется «технологическим стеком». Это весь наш «зоопарк»: операционные системы, базы данных, языки, дополнительные агенты, хранилища и типизация всего для разработки новых проектов.
Системные настройки. В безопасности это уровень чуть выше — стандарты конфигурации операционных систем. Мы ищем открытые в мир дефолтные порты на уровне ОС, изучаем системные параметры, память, пароли по умолчанию и вероятные небезопасные настройки.
Настройки приложений, баз данных. В безопасности это политики безопасности приложений и сервисов — проверяем, что всё настроено по внутренним регламентам. Здесь важно отслеживать использование простых паролей, паролей по умолчанию и других небезопасных конфигов. На этом уровне заканчивается технический мониторинг.
Дальше начинается бизнес-уровень — потоки данных. По личному опыту многие считают, что они к ним не относятся. Но когда что-то не работает или скомпрометировано, нужно понимать почему и как всё было настроено.
Когда работала в QIWI, я собирала тимлидов команд, которые разрабатывают разные части процессинга. Каждую неделю мы строили диаграмму потока данных, что тимлидам не нравилось. Но встречи позволили существенно сократить время реагирования на инциденты, а специалистам дежурной смены понять, как и что у нас работает, где проблемы и как их корректно диагностировать. Безопасности же это дало понимание, что с чем взаимодействует в штатном режиме и что можно считать аномальным потоком.
Поведенческий анализ. Это метрики на уровне взаимодействия с пользователем, их редко используют. Примеры: в безопасности это UEBA — User EndPoint Behaviour Analysis, а в IT тот же Google Tag Manager, который составляет тепловую карту сайта.
Потоки данных и поведенческий анализ интересны бизнесу. Это язык, на котором разговаривают люди без глубоких технических знаний.
Общие процессы
Погрузимся детальнее в общие процессы: как всё выстраивать с нуля и как всё построено в sudo.su.
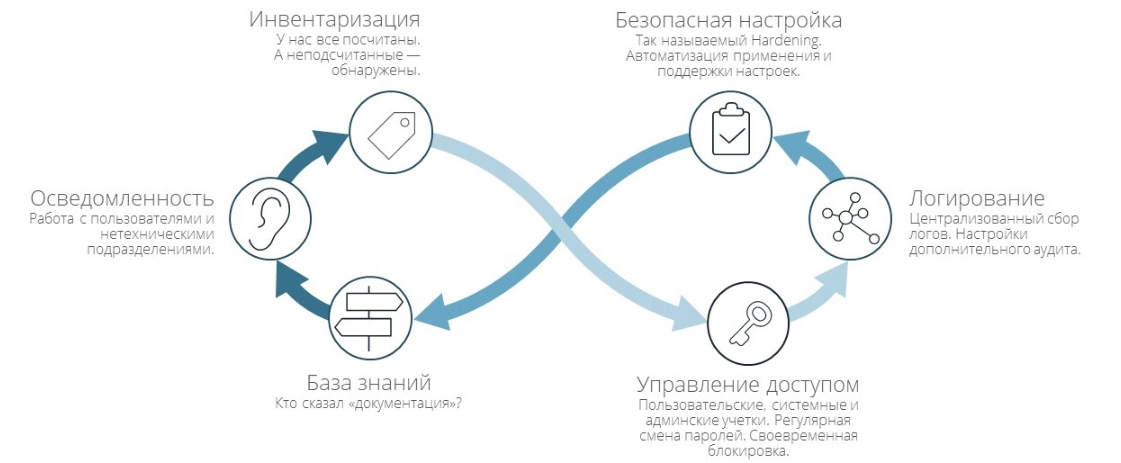
Инвентаризация — первое с чего мы начали. Мы используем как скрипты, так и инструменты, которые отслеживают, что нового в сети, что запущено и где работает. Инвентаризация как процесс помогает наводить порядок. Но приступайте к инвентаризации только после устранения хаоса.
Автоматизация хаоса приводит только к автоматизированному хаосу.Управление доступами. Примеры процессов: заведение новых записей и удаление старых, регулярная смена паролей. Важно помнить, что должен оставаться «след аудита» в трекерах или системах управления знаниями. По следу можно понять кому и на каком основании предоставлен доступ.
Например, в управлении паролями важно их регулярно менять. Это очевидная вещь и самая частая проблема. Регулярная смена паролей — это минимальная гарантия того, что инциденты не возникнут спустя два года после установки пароля. Здесь нет надежды даже на хэши. На современных мощностях перебор MD5 или коротких паролей занимает мало времени.
Логирование. Для сбора логов у нас есть центральный сервер. Российских вариантов таких решений нет, поэтому используем Splunk. Мы собираем в него как IT-логи, так и логи безопасности. IT-логи позволяют выявлять инциденты, например, с падением или долгим временем ответа. Сбор логов, например, веб-сервера помогает понять, кто нас сканирует.
Логирование — это «база» в IT-безопасности.Складывайте всё в отдельное хранилище. Когда случится инцидент, вся предыстория будет лежать в безопасном месте.
Безопасная настройка. Мы её автоматизировали с помощью настроек в соответствии с нашим Hardening guide. Мы усилились выключив некоторые функции системы и удалив лишних пользователей, группы и пакеты.
Меньше настроек — меньше векторов атак.Есть много готовых примеров по безопасной настройке различных ОС. Мы автоматизировали применение этих настроек, но подстроили стандарты под себя. При «слепом» применении стандартов можно получить кирпич вместо работающего продакшна.
База знаний. Это боль — никто не любит писать документацию, потому что скучно и «всё же и так можно посмотреть». Но она позволяет сократить время реагирования на инциденты, также как и осведомлённость сотрудников. Если в отдел безопасности или к сисадминам приходит бухгалтер и говорит, что пришло письмо с темой «Инвойс» в каком-то .exe файле, то это осведомлённость. Благодаря базе знаний бухгалтер понимает, что в непонятной ситуации следует обращаться в отдел безопасности, не открывать подозрительные файлы и не проходить по странным ссылкам.
Это базовая общая вещь. Она необходима всем, как финансовая или техническая грамотность, чтобы не носить последние сбережения в пирамиды и не заряжать банки с водой у телевизора.
Перейдем от теории к практике.
Базовый набор контролей безопасности
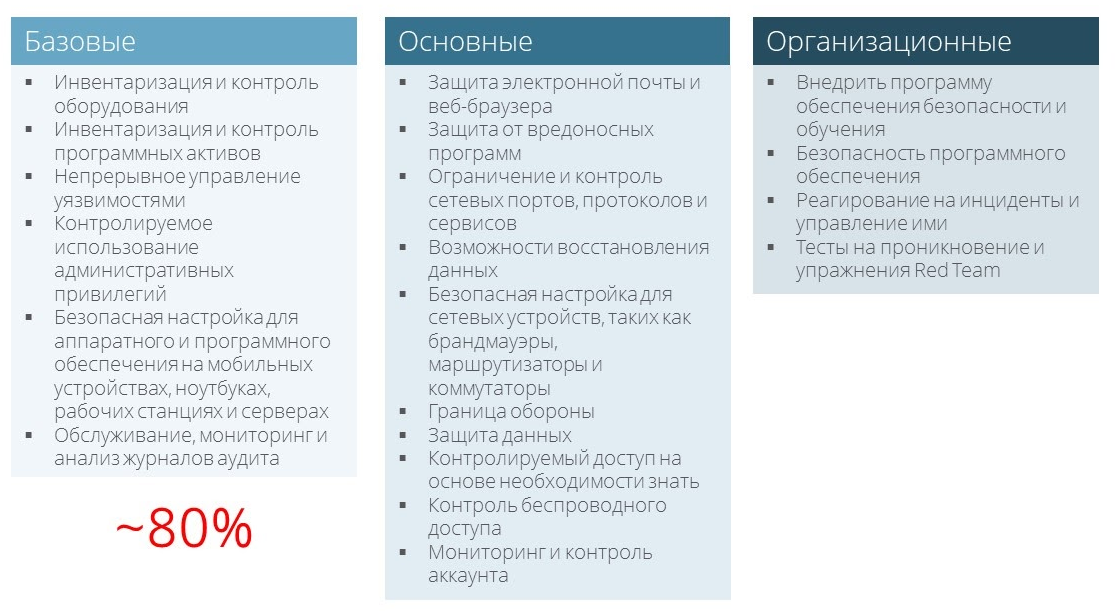
На сайте CIS Controls (Center for Internet Security) доступны базовые контроли: скачайте, посмотрите детальное описание. Всего контролей 20. Они делятся на три части: базовые, основные (сложнее) и организационные. Последние для тех, у кого безопасность уже «созрела» и выполняются первые контроли.
80% всех проблем безопасности закрываются первыми 6 из 20. Рассмотрим их подробнее.
Инвентаризация
Чтобы понять, что защищать, нужно все пересчитать и инвентаризировать, как ПО, так и физические активы. Например, для физической безопасности важно, чтобы у вас физически не вынесли сервер, а для IT, чтобы не «утекли» данные с сервера.
Варианты инвентаризации:
- запустить nmap/masscan, который будет проверять периметр и внутренние сети;
- автоматизировать регистрацию в системе мониторинга, чтобы получать оповещения, когда появляется что-то новое;
- CMDB — вариант для сильных духом и тех, у кого инфраструктура относительно статична;
- организационно: хотя бы обычным списком серверов в Excel или заявками на установку/вывод из эксплуатации в Jira.
Базовые настройки. При инвентаризации убедитесь, что нигде нет связки «логин-пароль» по умолчанию или слабых, вроде «admin-admin» или «root/123QWErty!». Смените, удалите и отключите все неиспользуемые сервисы. На основе инвентаризации составьте чек-листы по установке нового сервиса, например, базы данных или вашего приложения.
Контролируем инвентаризацию системой управления конфигурациями, CI/CD (через хуки) или системой мониторинга.
Мониторим: проверяем всё неучтённое, сравниваем все конфигурации по эталону и чек-листам.
Управление уязвимостями
Уязвимости особо актуальны для зрелых компаний. Обычно там появляется legacy — «очень важная система на которую нельзя дышать и обновлять» от которой трудно избавиться. По критичности legacy стоит на одном уровне с дефолтными логинами и паролями или не защищенной базой данных. Если у вас мало такого «исторического наследия» — самое время начать регулярное управление уязвимостями.
Проверяем патчи. Начинаем управление с изучения того, что патчим вручную или автоматизированно.
Вручную: подписываемся на maillist, security-рассылки. Для автоматизации используем сканеры безопасности. Выбора много: Openvas, Nexpose, Nessus, MBSA, как платные, так и бесплатные. Платные обновляются быстрее, бесплатные медленнее. Возможно даже вручную собирать версии пакетов и мониторить обновления, но для больших инфраструктур это плохо работает.
Создаём тестовую группу. После того, как составили список того, что хотим патчить, убеждаемся, что ничего не ломается, как с любым другим ПО и изменениями. Для этого выделяем тестовую группу на которой всё обновляем. Подтверждаем, что ничего не ломается, сервисы работают, а производительность не просела, и идём дальше.
Идём не только в продакшн, даже если «всё изолированно» и «это же тестовая среда». Мало у кого в тестовой среде исключительно тестовые данные, очищенные от чувствительной информации. Когда продакшн защищен, а тестовая среда доступна всему свету (даже если через VPN), и в ней находятся пользовательские данные, то это будет первая точка для утечки.
За тестовой средой обычно следят намного меньше (мониторинг, логи) и патчить надо всё. Тест и продакшн должны соответствовать друг другу по версии пакетов и внешним соединениям. Опять же возвращаемся к инвентаризации.
Мониторим — подтверждаем, что везде применились изменения: проверяем последние версии пакетов, версии конфигураций. Перезапускаем то, что нужно перезапустить.
Контроль использования административных привилегий
Составляем список «привилегированных» пользователей. Многим неудобно регулярно менять пароли или настраивать sudo исключительно для каких-то определенных действий. Примеров в практике много, например, кто-то ведет разработку на продакшн и постоянно пускает туда разработчиков или Ops-инженеров. При этом пароли не меняются и результат всем понятен.
Чтобы этого избежать, задаем вопрос: «Кому можно?» Вопрос не только о продакшн-системах, но и о пользовательских. С внедрением будет много проблем и вопросов, вроде «Раньше я мог поставить программу, а теперь не могу», но это важно.
Унификация прав, удаление избыточного доступа и лишних встроенных групп и пользователей помогает минимизировать проблемы, связанные с утечкой учётных данных.Идентифицируем всех пользователей. Вы всегда должны знать ответ на вопрос кто это. Для этого проводите инвентаризацию системных учетных записей: сервисных и пользовательских. Особенно, если они настроены не по стандарту, а с псевдонимами или никнеймами. Вам нужно четко понимать, кто такой «Vasya1992».
Регулярно проводим инвентаризацию пользователей и прав, системных пользователей и смену паролей. Если не менять пароли, то однажды они попадут к тому, кто их не должен знать. Идеально менять их с регулярностью раз в три месяца.
Требования к сложности паролей. Немного «Капитана Очевидность» — пароли вида «1111» или состоящие из букв словаря, быстро подбираются простым перебором паролей. Поэтому задавайте сложность пароля: 10 или больше символов, цифры, спецсимволы, прописные и строчные буквы. Перебор подобного хэша будет занимать много времени (но не отменяет возможность перехвата другими способами). Если менять пароль раз в три месяца, то к моменту перебора, он будет уже другой.
Находим ответственного. Вы всегда должны знать ответ на вопрос: «А кто это сделал?» У всех были инциденты с тем, когда кто-то что-то удалил. Но в случае инцидентов жёстче, желательно знать виновника. Организуйте документальное подтверждение — складывайте логи в отдельное место с более жёстким доступом к нему. Если система скомпрометирована и логи будут потеряны или удалены — всегда будет дубль.
Безопасная конфигурация всех устройств
Этот контроль относится не только к серверам, но и к мобильным рабочим станциям, ноутбукам и мобильным телефонам.
Первый шаг — типизация стека, ПО у пользователей и на продакшн. Об этом мы уже говорили.
В CIS есть готовые наборы стандартов, как на уровне ОС (Linux, Windows, Windows-сервер), так и на уровне самых популярных сетевых устройств и баз данных. По необходимости адаптируйте конфигурации под свои нужды.
«Напильник». Бездумно применять практики — плохая затея. Если скачать политику для Active Directory и внедрить её не тестируя, то на выходе будет полностью неработающий офис. Он будет требовать FIPS, чтобы рабочие станции соединились с AD. А если послушать CIS Benchmark Linux и выключить IP-forwarding, то развалится Docker.
Разрабатывайте собственные стандарты конфигурации.В них входят дополнительные специфические требования: завести дополнительных пользователей или группы, поставить дополнительные пакеты. Всё документируйте, чтобы новый человек мог настроить любое оборудование по стандартам.
Контролируем исполнение:
- централизованно управляем конфигурациями;
- запрещаем неавторизованные изменения, в том числе в документации, в стандартах конфигурации;
- откатываем несогласованные изменения.
Мониторим — регулярно проверяем, что всё настроено по стандарту. У меня это происходит раз в сутки. Для больших систем желательно проверять всё за три дня. В этом помогают системы управления конфигурациями, системы мониторинга или локальные скрипты, которые просто отправляют отчёты.
Логирование, мониторинг, анализ логов
Любимая тема, о которой могу говорить часами: мониторинг, логирование, чтение логов. Казалось бы, давайте всё залогируем и ничего не пропустим. Но всё не так просто.
Начинаем с типизации (см. выше). Примеров масса, я пользуюсь двумя. Для приложений — гайд Open Web Application Security Project. В нём подробно описано, что писать в логи приложения: входы, выходы, пользователи, эскалация прав. Для безопасности — чек-листы, которые указывают на то, какие типы событий обязательно надо мониторить.
Как логировать и где хранить. Иногда логов бывает слишком много. Логирование в больших системах создаёт столько логов, что нет смысла реагировать на каждое событие — они слишком сильно шумят. Перед тем, как выбирать что логировать, обращайте внимание:
- на длину сообщения, если используете Syslog;
- если используете собственные приложения для передачи логов — смотрите по чек-листу OWASP.
Храните логи не меньше трех месяцев. Например, по стандартам платежных систем они хранятся год и больше. Иногда, ретроспектива помогает увидеть, что полгода назад начались проблемы, даже если не было инцидентов — просто мониторинг «недомониторил».
Сбор и корреляция. Иногда логи занимают слишком много места и стрелка компаса поворачивается от «Логировать всё» к «Логировать минимум». Но хранить лучше больше, чем меньше.
В оперативном доступе на быстрых носителях храните данные за месяц. Это помогает экономить ресурсы в скорости обработки — архив можно вынести на сервер помедленнее. Но всегда должна быть возможность извлечь архивные события, чтобы проверить свои гипотезы и предположения.
Базовые правила корреляции. Перебор паролей, попытка авторизации под одним логином на множество серверов, странные запросы похожие на SQL в логах веба, попытка входа под выключенной учетной записью — это базовые вещи, на которые стоит настроить оповещения и активно реагировать.
Мониторим логирование. Проверяем, чтоот всех источников поступают события и настроены оповещения.
План реагирования. В безопасности применяется чаще, чем в IT. Это иерархия: кому в какой последовательности звонить и писать. Например, в банковской сфере все знают о PSI DSS — по нему отрабатывается сценарий «утечка карт»: тестовые звонки и письма в платежную систему, тестовые ограничения периметра или локализация утечки.
Если стандартов нет — изучите, как логируют инциденты в материалах SANS. В маленькой документации они собрали множество примеров, которые помогут погрузиться в реагирование с точки зрения безопасности.
Безопасность привычными инструментами
Я использую несколько инструментов в работе. Как и с любыми другими инструментами, которые вы выбираете, берите те, что вам подходят или как «исторически сложилось».
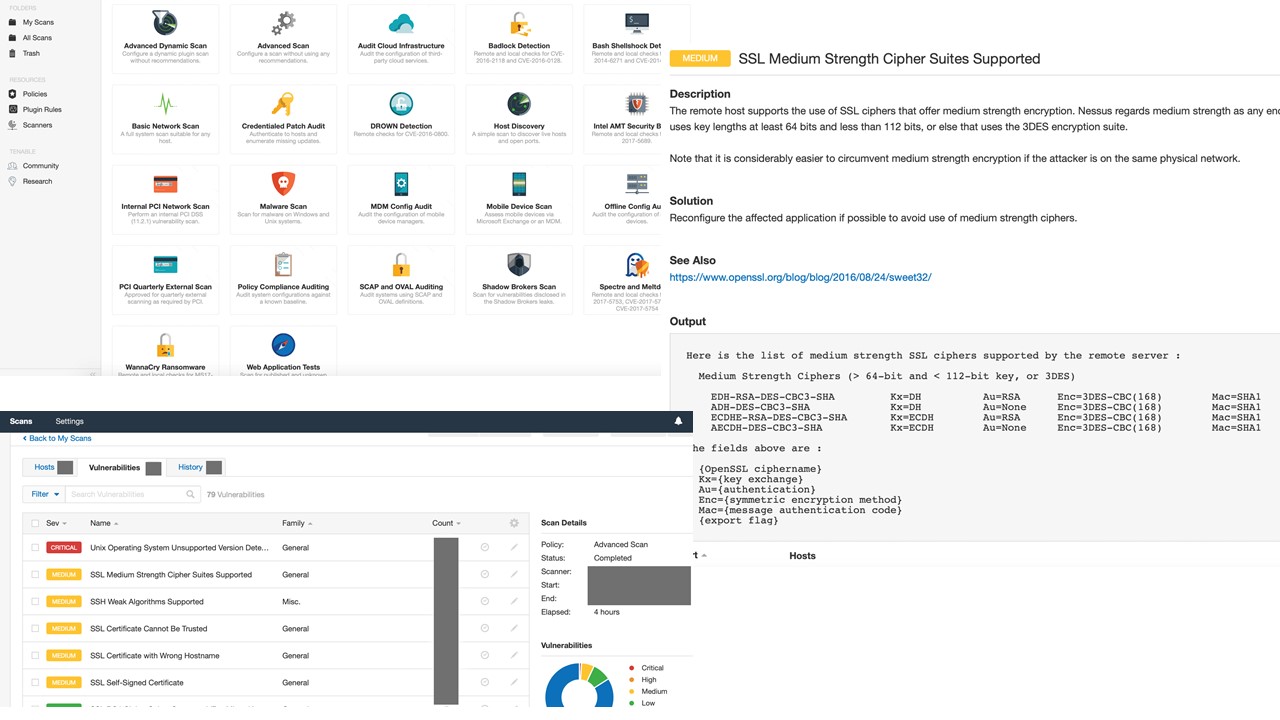
Обнаружение, аудит, патчи. Для обнаружения новых ассетов, аудита стандартов и конфигураций, установки патчей использую Nessus. Это платный и относительно дорогой продукт. Есть аналог — Openvas. Он бесплатный, но обновляется медленнее. Это форк старого Nessus в то время, как он был открыт.
Скриншоты из Nessus.
Nessus чудесен. Например, позволяет найти неподдерживаемые ОС и наглядно показывает критичность разных уязвимостей. По каждой из уязвимостей выдает короткое описание: что она делает, примеры и рекомендации по устранению (обновить пакеты или «вынуть и закопать»).
Конфиги, пользователи, стандарты, обновления. Стандартами конфигурации, пользователями и обновлениями у нас занимается Rudder.
В 1992, когда о безопасности и DevOps никто не слышал (счастливые времена), появился CFEngine. Это одна из первых систем управления конфигурациями. Rudder — это графическая надстройка над CFEngine, которая рисует красивые графики для руководителей и помогает посадить джуна «накликать стандарт конфигурации». В дашборде можно посмотреть правильность конфигураций, проверить стандарты и, везде ли они применились.
В Rudder много элементов для составления promise (конечного состояния системы) методов. Мы его используем для базовой автоматизации и мониторинга, а также чтобы показывать графики состояния конфигураций инфраструктуры нетехническим специалистам и аудиторам.
Код. Это далеко не базовый контроль. За чистотой и безопасностью кода мы следим инструментом Sonarqube: он интегрирован с нашим GitLab, за всем смотрим в динамике, а разработчики обучены как с ним работать и реагировать. Если хотите подсказки, то есть платная версия с модулями подсказок.
Это не единственный инструмент подобного рода. Есть множество аналогов анализаторов исходного кода в разных модификациях и для разных языков.
KPI
Тимлидам и руководителям будет интересно, как встроить показатели по безопасности в свою систему оценки. Общее правило при внедрении любого показателя эффективности: «Оценка должна быть качественной!».
Некачественные KPI:
- Количество инцидентов. Это плохой KPI, он не даёт оценки ущерба от инцидента. При желании можно сказать, что у нас 20 инцидентов в неделю, но бизнес не поймёт, что это значит.
- Количество источников данных. Это не KPI — это инвентаризация.
- Количество уязвимостей. У нас 20 тыс уязвимостей — нам закрываться или жить дальше? Этот KPI не дает понимания критичности.
Качественные KPI.
SLA или стоимость простоя. SLA — для клиентов, OLA — внутреннее соглашение о качестве сервиса. Мы считаем SLA в разных вариациях, а стоимость простоя берем у финансового отдела или бизнес-подразделения. Они ответят, сколько будет стоить простой в регистрациях в течение двух минут или сбой в эквайринге на полчаса.
На ответы наложите свой SLA и получится понятная бизнес-метрика, за которую вас будут любить, холить и лелеять. Заодно для вас будет понятна цена влияния «кто выпустил этот минорчик в прод».
Процент несоответствия стандартам. Когда у нас два сервера и один из них не защищен, то процент несоответствия — 50. Очень редко встречается процент меньше 2, поэтому 5 процентов уже хорошо, а 2-3 — отлично.
Качественные проверки процессов и качественный разбор инцидентов и отклонений (RCA — Root Cause Analysis). Проводите регулярно — полезно не только для безопасности, но и для IT. Проверки и выяснение корня инцидентов позволяют поднять уровень сервиса и повышают осведомленность коллег о том, что вы работаете и регулярно проводите разбор полетов.
Это касается всех инцидентов, как обычных, так и связанных с безопасностью. Многие забивают на RCA, но его проведение без серьезного внешнего инцидента по результатам внутреннего регулярного процесса позволяет устранять системные проблемы. Они будут возникать все меньше и меньше.
Важное правило: KPI должны быть понятны не только техническим специалистам.
Безопасность — это культура
Мой друг ведет telegram-канал @dataleak об утечках данных. Он регулярно публикует позорные случаи: списки e-mail и телефонов из незащищённой базы данных магазинов ReStore, записи колл-центра МегаФон, логины и пароли Intel, которые хранятся в открытом репозитории.
Иногда утечки никак не связаны с IT. Например, когда документы просто выкидывают на помойку или выкладывают Excel-таблицу в Google Drive без каких-то ограничений.
В идеале, нужно учиться на чужих ошибках и заниматься безопасностью заранее. Но насадить безопасность нельзя. Невозможно заставить людей заниматься безопасностью, пока они не потеряют свои данные или бизнес. Люди делятся на тех, кто еще не делает бэкапы и тех, кто уже делает. С безопасностью так же: компании делятся на тех, кого еще не ломали и тех, кого уже ломали.
Но это не задача одного безопасника — сказать, как надо одинаково делать всем, и бегать проверять. Хороших специалистов мало, а бизнесов разных размеров — много.
Безопасность — это задача каждого. Это — культура, а не функция.Вы же не моете руки только когда кто-то за этим следит?
После это выступления мы предложили Моне Архиповой вступить в Программный комитет DevOpsConf. Мы немного расспросили ее о том, как это произошло, чем интересно и каково по обе стороны.
— Мона Архипова: Когда мне предложили присоединиться к ПК DevOps Conf, я подумала и решила: «А почему бы и нет?» У меня большой опыт выступлений и подготовки к ним. Помощь другим спикерам — логичное развитие моих навыков. К тому же, я помогала запускать несколько конференций и раньше, поэтому это не первый опыт в Программных комитетах — уже было понятно, что делать.
В ПК хотела решить три задачи:
- Привнести в конференцию разнообразный корпоративный опыт в современных реалиях с современным технологическим стеком.
- Привить культуру безопасности. О культуре регулярно забывают, потому что надо же скорей-скорей проверять гипотезы и делать бизнесу и клиентам радостно, а потом — «Ой, утекло».
- Привлекать спикеров, которые знают и то, и другое: бывших программистов и сисадминов, которые перешли в ИБ, активно применяют в работе или интересуются для себя.
В Программном комитете мне интересен процесс подбора спикеров, обсуждение форматов. Я занимаюсь темой безопасности и далеко не все спикеры могут адаптировать доклады под аудиторию без нашей «очевидной всем» security-специфики. Это привносит дополнительную сложность. Готовить свой доклад было проще — опыт Ops всегда со мной и я всё ещё «играющий тренер».
В текущей ситуации неопределённости с массовыми мероприятиями участие в ПК становится ещё интереснее :).
Глубоко обсуждать DevOps-практики мы будем осенью на DevOpsConf 2020. А в ближайшее время подстегните своё профессиональное развитие на одной из двух родственных конференций Онтико:
- Онлайн-фестиваль Российские интернет-технологии (25 мая — 10 июня) поможет расширить кругозор и быстро схватить главные идеи актуальных технологий.
- Конференция TechLead Conf Online (8 и 9 июня) будет полностью посвящена инженерным практикам и процессам.
Следите за новостями в telegram-канале, рассылке и на youtube.




