
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
… и опоздал на 3 года. В идеале должно быть так: пользователь запускает браузер, и браузер показывает то, что нужно пользователю. Но пока такого не реализовали приходится пользоваться поисковыми системами. В идеале должно быть так: пользователь открывает поисковую систему, вводит поисковый запрос, и она показывает то, что нужно пользователю. Но пока кнопка «I feel lucky» не так хорошо работает (хотя в последнее время ощутимо движение в этом направлении), приходится иногда переходить по нескольким адресам со страницы поисковой выдачи.
Сценарий использования поисковых систем у меня, видимо, закреплен исторически (когда интернет был медленный): попадая на страницу поисковой выдачи, я открывал несколько вкладок в фоновом режиме, и пока остальные загружались, вполне можно было уже прочитать первую вкладку. В случае, когда находил нужную информацию на одной из вкладок, остальные приходилось закрывать вручную. Если не закрыл сразу, вкладки оставались висеть, раздувая количество открытых вкладок в браузере, которые, как правило, редко после этого закрывались.
К тому же, если переходишь на странице по ссылкам, которые открываются в новом окне, создается несколько связанных между собой (логически) вкладок. Когда находишь нужную информацию, не всегда можно вспомнить какие вкладки связаны между собой, можешь закрыть не все, что также ведет к раздуванию количества открытых вкладок.
Мне всегда нужна была кнопка «Нашел», которая бы подчищала за мной последствия поиска (назовём её «I was lucky»). После того, как окунулся в мир расширений для браузеров, я подумал, что это то, что может помочь в данном случае. Так смутно начало появляться желание написать расширение, которое бы решало мои задачи.
Расскажу вам свою историю, рассказ буду вести в хронологическом порядке, выводы могут оказаться неожиданные.
Первым делом взялся за настройку инфраструктуры: webpack + babel. И сразу же мне не понравилось, что babel дублировал в каждом модуле код для своих хелперов. Можно было настроить, чтобы он использовал объект
Время шло, а в наличии был только плагин для вебпака, который никак не решал моих задач. И каждый раз, когда я что-то искал и не закрывал вкладки, была мысль: «Хорошо бы доделать то расширение...» Желание росло и росло, и вот, в один прекрасный день, количество переросло в качество.
Самое время рассказать, в чем была основная идея:
Пользователь попадает на страницу поисковой выдачи — СЕРП, мы парсим выдачу, сохраняем себе адреса ссылок, после того, как пользователь перешел по одному из адресов, показываем ему уведомление с остальными адресами и кнопкой «Нашел», чтобы закрыть вкладки.
При переходе на страницу могут быть различные варианты. Самый простой: один запрос — один ответ от сервера (200). Самый сложный: один запрос — несколько серверных перенаправлений (3xx), после чего клиентское перенаправление (с помощью
Простой случай перехода:

Сложный случай перехода:
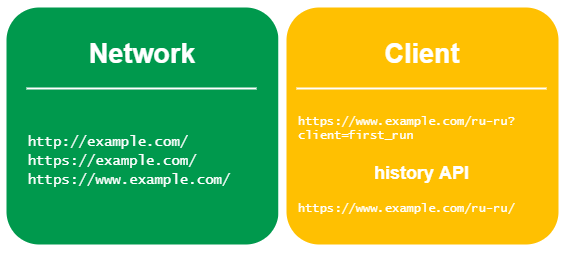
То есть сохранить адрес страницы и при переходе проверять только его не всегда достаточно. Поэтому нужно создать логический Переход, куда записывать все адреса, встретившиеся на пути, а потом проверять, что логический Переход содержит в себе сохраненный адрес. Задача понятна, но не все так прямолинейно в исполнении.
В Хроме есть два API, связанных с навигацией: webNavigation и webRequest — каждый со своими событиями. Первый — связывает переходы и UI браузера, последний — нижележащие сетевые запросы. Поэтому, если изменение адреса на странице произошло за счет history API, не будет никаких событий у последнего, а если во время сетевого запроса происходят перенаправления, то первый об этом никак не сообщает. Следовательно, нужно использовать оба АПИ, собирая по щепотке от каждого события каждого АПИ, формировать один логический Переход.
… Вернемся к моменту, когда количество переросло в качество. С начала разработки до этого момента прошло существенное количество времени: браузеры стали поддерживать es6 модули, shadow DOM и другие современные фичи. Для сборки проект переехал на Rollup, плагин в этот раз писать не пришлось. После постройки фундамента — возможности получения информации о любом переходе в любой вкладке, осталось реализовать логику парсинга поддерживаемых СЕРПов и показа уведомлений на связанных страницах.
Первая задача достаточно примитивная: знаем адрес СЕРПа, лезем в содержимое страницы с помощью контент скрипта, получаем интересующие нас данные, сохраняем, ждем, когда пользователь перейдет на одну из страниц, чтобы показать ему уведомление с остальными страницами.
Для второй задачи нужна реализация самого уведомления, то что показывать на странице пользователю. И здесь тоже без контент скриптов не обойтись.
Изначально был только один обработчик (он же контроллер), отвечающий за логику при взаимодействии пользователя с поисковыми системами. После чего возникла идея почему бы не показывать уведомления на связанных вкладках, когда пользователь просто переходит по ссылкам, открываемых в новых вкладках. Пришлось переделать логику, сделав ее более универсальной. По аналогии с middleware React/Redux, можно подключать несколько обработчиков Переходов, что в будущем позволит реализовать возможность отключения/включения различных обработчиков в настройках расширения.
Так как уведомление — это панель внизу экрана, и добавляется она в разметку страницы, то скрипт на странице может получить доступ к этому элементу так же, как и к любому другому элементу на этой странице. То есть теоретически страница могла бы узнать какой поисковый запрос вы использовали, в каком поисковике и какие другие страницы вам предложены, что не очень хорошо.
На помощь приходит технология под названием shadow DOM. В вебе не рекомендуется использовать
В случае же расширения это не так. Контент скрипты и скрипты страницы живут в параллельных мирах. Скрипты со страницы не имеют доступ к объектам, определенным в контент скриптах, контент скрипты же оперируют с нативной реализацией функций DOM объектов (переопределенная функция скриптом со страницы не имеет эффекта на функцию, с которой работает контент скрипт). Соединяя эти два условия, получаем, что можно создать элемент с закрытым
В этом случае скрипт со страницы сможет получить доступ только к элементу обертке, который для него будет пустой. Он не сможет получить текст запроса или предложенные страницы. Нужно внимательно следить, чтобы в сгенерированных событиях не отдать ссылку на какой-нибудь элемент внутри уведомления или открытый текст. Поэтому в расширении в событиях используются сгенерированные id, а уже background скрипт по этому id понимает что от него требуется. Для страницы же этот id достаточно бессмысленный.
Изначально расширение разрабатывалось только для Google Chrome, но так как WebExtensions API, где-то в голове держал возможность портирования в другие браузеры. А наличие webextension-polyfill вселяло уверенность. Но как бы не так. Полифил для этого расширения принес только возможность использования chrome API с промисами.
Firefox стал разочарованием года. Несоответствие chrome API в Фаерфоксе (Bug 1543647, Bug 1595621) оказалось критичным для работоспособности расширения, можно сказать оно в этом браузере не работает (как положено).
Vivaldi был наиболее близок, но также не обошлось. Событие
В ходе написания кода логика работы показа уведомлений менялась несколько раз, каждый раз упрощаясь. В итоге получилось так, что можно было не городить огород с логическими Переходами, а отлавливать «связанные переходы» пользователя (в событии
Так же, не находясь в теме, ожидал большей совместимости с точки зрения webExtensions API. Как всегда — хорошо жить в мире современных браузеров, когда не нужна поддержка старых версий. CSS анимации прекрасная вещь: то, для чего раньше нужно было использовать js библиотеку, теперь делается в несколько строк на css. В расширениях не работают Custom elements, зато работает shadow DOM, позволяющий воспользоваться всеми его возможностями.
Сценарий использования поисковых систем у меня, видимо, закреплен исторически (когда интернет был медленный): попадая на страницу поисковой выдачи, я открывал несколько вкладок в фоновом режиме, и пока остальные загружались, вполне можно было уже прочитать первую вкладку. В случае, когда находил нужную информацию на одной из вкладок, остальные приходилось закрывать вручную. Если не закрыл сразу, вкладки оставались висеть, раздувая количество открытых вкладок в браузере, которые, как правило, редко после этого закрывались.
К тому же, если переходишь на странице по ссылкам, которые открываются в новом окне, создается несколько связанных между собой (логически) вкладок. Когда находишь нужную информацию, не всегда можно вспомнить какие вкладки связаны между собой, можешь закрыть не все, что также ведет к раздуванию количества открытых вкладок.
Мне всегда нужна была кнопка «Нашел», которая бы подчищала за мной последствия поиска (назовём её «I was lucky»). После того, как окунулся в мир расширений для браузеров, я подумал, что это то, что может помочь в данном случае. Так смутно начало появляться желание написать расширение, которое бы решало мои задачи.
Расскажу вам свою историю, рассказ буду вести в хронологическом порядке, выводы могут оказаться неожиданные.
Первый шаг на пути
Первым делом взялся за настройку инфраструктуры: webpack + babel. И сразу же мне не понравилось, что babel дублировал в каждом модуле код для своих хелперов. Можно было настроить, чтобы он использовал объект
babelHelper, но тогда файл с кодом babelHelper нужно было подключать в конфигурации webpack. Хранить такой файл в проекте и указывать его в entry было некрасиво, я сделал плагин для вебпака, который выполнял это за меня автоматически. Потратив много сил на первый шаг и написав ещё немного кода для самого расширения, я немного притормозил.Плагин
webpack-babel-external-helpers-2:
www.npmjs.com/package/webpack-babel-external-helpers-2
www.npmjs.com/package/webpack-babel-external-helpers-2
Фундамент
Время шло, а в наличии был только плагин для вебпака, который никак не решал моих задач. И каждый раз, когда я что-то искал и не закрывал вкладки, была мысль: «Хорошо бы доделать то расширение...» Желание росло и росло, и вот, в один прекрасный день, количество переросло в качество.
Самое время рассказать, в чем была основная идея:
Пользователь попадает на страницу поисковой выдачи — СЕРП, мы парсим выдачу, сохраняем себе адреса ссылок, после того, как пользователь перешел по одному из адресов, показываем ему уведомление с остальными адресами и кнопкой «Нашел», чтобы закрыть вкладки.
При переходе на страницу могут быть различные варианты. Самый простой: один запрос — один ответ от сервера (200). Самый сложный: один запрос — несколько серверных перенаправлений (3xx), после чего клиентское перенаправление (с помощью
<meta/> или javascript), сверху ещё и history API. И комбинации между ними, как правило, большинство сайтов попадает в эту категорию.Простой случай перехода:
Сложный случай перехода:
То есть сохранить адрес страницы и при переходе проверять только его не всегда достаточно. Поэтому нужно создать логический Переход, куда записывать все адреса, встретившиеся на пути, а потом проверять, что логический Переход содержит в себе сохраненный адрес. Задача понятна, но не все так прямолинейно в исполнении.
В Хроме есть два API, связанных с навигацией: webNavigation и webRequest — каждый со своими событиями. Первый — связывает переходы и UI браузера, последний — нижележащие сетевые запросы. Поэтому, если изменение адреса на странице произошло за счет history API, не будет никаких событий у последнего, а если во время сетевого запроса происходят перенаправления, то первый об этом никак не сообщает. Следовательно, нужно использовать оба АПИ, собирая по щепотке от каждого события каждого АПИ, формировать один логический Переход.
Немного деталей
Как указано в документации, события для
Интересующие события
Но между собой события wR и wN не имеют определенного порядка (на аналогичных стадиях запроса), т.е. в каких-то случаях
webNavigation (wN) выполняются в следующем порядке:onBeforeNavigate -> onCommitted -> onDOMContentLoaded -> onCompleted
Интересующие события
webRequest (wR):onBeforeRequest -> [onBeforeRedirect -> onBeforeRequest]* -> onCompleted | onErrorOccurred
Но между собой события wR и wN не имеют определенного порядка (на аналогичных стадиях запроса), т.е. в каких-то случаях
wN.onBeforeNavigate может выполниться раньше wR.onBeforeRequest, в каких-то наоборот. Что немного усложняет логику работы.Для этих АПИ нужно указывать соответствующие разрешения в манифесте расширения, а посему при установке расширения, пользователю будет выдаваться пугающий текст о возможностях расширения.Развитие
… Вернемся к моменту, когда количество переросло в качество. С начала разработки до этого момента прошло существенное количество времени: браузеры стали поддерживать es6 модули, shadow DOM и другие современные фичи. Для сборки проект переехал на Rollup, плагин в этот раз писать не пришлось. После постройки фундамента — возможности получения информации о любом переходе в любой вкладке, осталось реализовать логику парсинга поддерживаемых СЕРПов и показа уведомлений на связанных страницах.
Первая задача достаточно примитивная: знаем адрес СЕРПа, лезем в содержимое страницы с помощью контент скрипта, получаем интересующие нас данные, сохраняем, ждем, когда пользователь перейдет на одну из страниц, чтобы показать ему уведомление с остальными страницами.
Для второй задачи нужна реализация самого уведомления, то что показывать на странице пользователю. И здесь тоже без контент скриптов не обойтись.
Изначально был только один обработчик (он же контроллер), отвечающий за логику при взаимодействии пользователя с поисковыми системами. После чего возникла идея почему бы не показывать уведомления на связанных вкладках, когда пользователь просто переходит по ссылкам, открываемых в новых вкладках. Пришлось переделать логику, сделав ее более универсальной. По аналогии с middleware React/Redux, можно подключать несколько обработчиков Переходов, что в будущем позволит реализовать возможность отключения/включения различных обработчиков в настройках расширения.
Приватность
Так как уведомление — это панель внизу экрана, и добавляется она в разметку страницы, то скрипт на странице может получить доступ к этому элементу так же, как и к любому другому элементу на этой странице. То есть теоретически страница могла бы узнать какой поисковый запрос вы использовали, в каком поисковике и какие другие страницы вам предложены, что не очень хорошо.
На помощь приходит технология под названием shadow DOM. В вебе не рекомендуется использовать
closed mode при создании shadowRoot, потому что в этом нет большого смысла (все равно придется хранить ссылку на элемент shadowRoot где-нибудь, если хочется иметь к нему доступ программно; так же можно переопределить функцию attachShadow, чтобы она создавала shadowRoot в открытом режиме, и тогда скрипты подгруженные после переопределения уже будут пользоваться новой версией функции). В случае же расширения это не так. Контент скрипты и скрипты страницы живут в параллельных мирах. Скрипты со страницы не имеют доступ к объектам, определенным в контент скриптах, контент скрипты же оперируют с нативной реализацией функций DOM объектов (переопределенная функция скриптом со страницы не имеет эффекта на функцию, с которой работает контент скрипт). Соединяя эти два условия, получаем, что можно создать элемент с закрытым
shadowRoot, сохранив ссылку на него в переменной.В этом случае скрипт со страницы сможет получить доступ только к элементу обертке, который для него будет пустой. Он не сможет получить текст запроса или предложенные страницы. Нужно внимательно следить, чтобы в сгенерированных событиях не отдать ссылку на какой-нибудь элемент внутри уведомления или открытый текст. Поэтому в расширении в событиях используются сгенерированные id, а уже background скрипт по этому id понимает что от него требуется. Для страницы же этот id достаточно бессмысленный.
Трудности перевода
Изначально расширение разрабатывалось только для Google Chrome, но так как WebExtensions API, где-то в голове держал возможность портирования в другие браузеры. А наличие webextension-polyfill вселяло уверенность. Но как бы не так. Полифил для этого расширения принес только возможность использования chrome API с промисами.
Firefox стал разочарованием года. Несоответствие chrome API в Фаерфоксе (Bug 1543647, Bug 1595621) оказалось критичным для работоспособности расширения, можно сказать оно в этом браузере не работает (как положено).
Vivaldi был наиболее близок, но также не обошлось. Событие
wN.onCreatedNavigationTarget не возникает, когда пользователь открывает ссылку средней кнопкой мыши или через Shift|Ctrl + левая кнопка мыши, вместо этого в событии wN.onCommitted transitionType == 'start_page', чего нет в chrome API, из-за этого не во всех случаях расширение работает правильно. Так же в Вивальди не работают горячие клавиши для расширений. Что является киллер-фичей в данном случае в Хроме, позволяет намного быстрее переходить по вкладкам и закрывать их, без необходимости использования для этого мышки.Заключение
В ходе написания кода логика работы показа уведомлений менялась несколько раз, каждый раз упрощаясь. В итоге получилось так, что можно было не городить огород с логическими Переходами, а отлавливать «связанные переходы» пользователя (в событии
wN.onCommitted есть флаг transitionType, который указывает из-за чего был переход, во многих случаях он равен «link», означающее что пользователь перешел по ссылке), что значительно бы упростило код и работало во многих случаях, но не во всех.Так же, не находясь в теме, ожидал большей совместимости с точки зрения webExtensions API. Как всегда — хорошо жить в мире современных браузеров, когда не нужна поддержка старых версий. CSS анимации прекрасная вещь: то, для чего раньше нужно было использовать js библиотеку, теперь делается в несколько строк на css. В расширениях не работают Custom elements, зато работает shadow DOM, позволяющий воспользоваться всеми его возможностями.
Расширение
Само расширение можно скачать из chrome web store: Handy Search



