Недавно мы объявили на Хабре, что начинаем принимать заявки на Яндекс.Алгоритм и другие треки чемпионата по программированию Yandex Cup. Уже много лет онлайн-соревнования Яндекса и других компаний проходят на платформе Контест. Меня зовут Павел Тыквин, я один из разработчиков Контеста. Основная задача нашей платформы — получить от участника чемпионата исходный код решения, скомпилировать и запустить этот код, прогнать тесты и вернуть результат. Звучит не очень сложно. Давайте попробуем.
Это простенькое приложение специально для экспериментов, оно ищет простые числа методом решета Эратосфена. Запустим решение 20 раз и посчитаем user time каждого исполнения.
Разброс времени исполнения до оптимизаций:
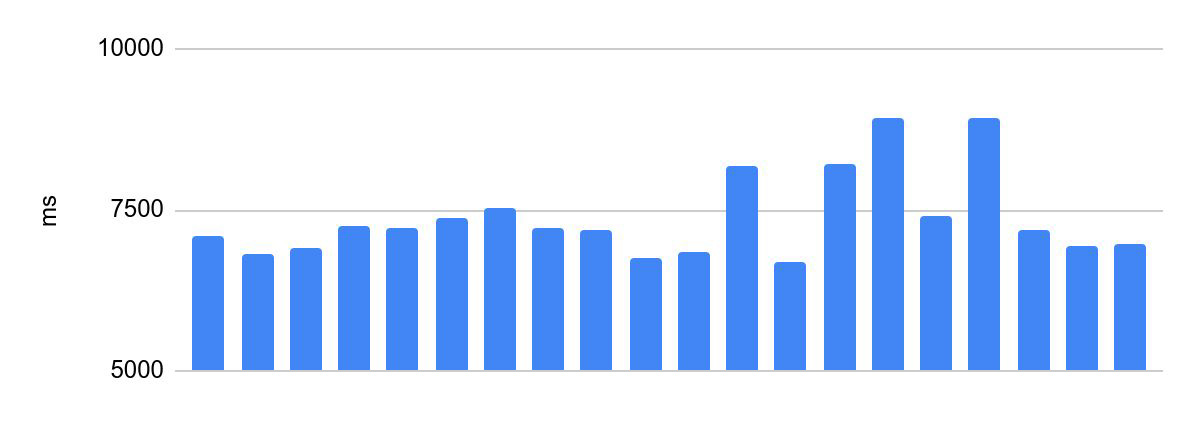
Разница между самым быстрым и самым медленным исполнением — 2230 мс.
Для олимпиадного программирования это неприемлемо. Время выполнения кода участника — один из критериев успешности его решения и одно из условий соревнования, от этого зависит распределение призовых мест. Поэтому существует важное требование к подобным системам — одинаковое время проверки одного и того же кода. Далее будем называть это консистентностью выполнения кода.
Попробуем выравнять время исполнения.
Начнем с очевидного. Процессы конкурируют за ядра, и нужно каким-то образом изолировать ядро под исполнение решения. Кроме того, с включенным Hyper Threading операционная система определяет одно физическое ядро процессора как два отдельных логических ядра. Для честной изоляции ядра нам нужно отключить Hyper Threading. Это можно сделать в настройках BIOS.
Ядро Linux из коробки поддерживает флаг запуска для изоляции ядер isolcpus. Добавим этот флаг в GRUB_CMDLINE_LINUX_DEFAULT в настройках grub: /etc/default/grub. Например:
Выполним update-grub и перезапустим систему.
Все выглядит как ожидалось — первые два ядра не используются системой:

Запустимся на изолированном ядре. Конфигурация CPU Affinity позволяет привязать процесс к конкретному ядру. Есть несколько способов это сделать. Например, запустим решение в porto-контейнере (ядро выбирается с помощью аргумента cpu_set):
Запуск с ядром, выделенным под решение, без нагрузки на соседние ядра:

Разница — 375 мс. Стало лучше, но это все равно слишком много.
Давайте попробуем провести наш тест под нагрузкой. Под какой именно? Наша задача — множеством потоков нагрузить все ядра. Это можно сделать несколькими способами:
Запуск с ядром, выделенным под решение, с нагрузкой на соседние ядра:

Разница — 1354 мс: на секунду больше, чем без нагрузки. Очевидно, нагрузка повлияла на время исполнения, несмотря на то, что мы запускались на изолированном ядре. Видно, что в определенный момент время исполнения уменьшилось. На первый взгляд это контринтуитивно: при растущей нагрузке производительность тоже увеличивается.
В продакшене такое поведение (когда время исполнения начинает плыть под нагрузкой) может выстрелить очень болезненно. Что такое нагрузка в данном случае? Поток решений от участников, чаще всего на крупных соревнованиях и олимпиадах.
Причина в том, что под нагрузкой включается Intel Turbo Boost — технология увеличения частоты. Отключим ее. Для своего cтенда я выключил еще и SpeedStep. Для процессора AMD нужно было бы выключить Turbo Core Cool'n'Quiet. Все перечисленное делается в BIOS, основная идея — отключить то, что автоматически управляет частотой процессора.
Запуск на изолированном ядре с отключенным Turbo Boost и нагрузкой на соседние ядра:

Выглядит неплохо, но разница все еще составляет 252 мс. И это все еще слишком много.
Мы избавились от конкуренции за ядра, стабилизировали частоту ядер — теперь на них ничто не влияет. Так откуда же разница?
Non-Uniform Memory Access, «неравномерный доступ к памяти», или Non-Uniform Memory Architecture, «архитектура с неравномерной памятью». В NUMA-системах (то есть, условно, на любом современном многопроцессорном компьютере) у каждого процессора есть локальная память, которая рассматривается как часть общей. Каждый процессор может обратиться и к своей локальной памяти, и к локальной памяти остальных процессоров (удаленной памяти). Неравномерность в том, что доступ к локальной памяти происходит заметно быстрее.
Время исполнения «гуляет» именно из-за такой неравномерности. Пофиксим ее, привязав наше исполнение к конкретной numa node. Для этого добавим numa node в конфигурацию porto-контейнера:
Запуск на изолированном ядре с отключенным Turbo Boost, конфигурацией NUMA и нагрузкой на соседние ядра:
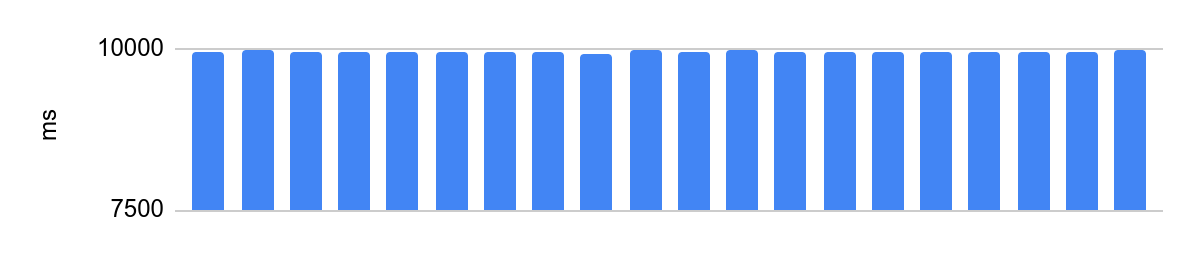
Разница — 48 мс, а среднее время выполнения решения после того, как мы отключили процессорные оптимизаций, составляет 10 с. 48 мс в масштабе 10 с — равносильно погрешности в 0,5%, очень хорошо.
У флага isolcpus есть проблема: некоторые системные потоки все равно могут schedule'иться на изолированное ядро.
Пулы
Если одна решающая машина мощнее другой, то никакие ухищрения с изоляцией ядер не помогут — в результате мы все равно получим большую разницу во времени исполнения. Поэтому нужно думать про гетерогенные среды. До сих пор мы просто не поддерживали гетерогенность — весь парк решающих машин комплектуется одинаковым железом. Но в ближайшем будущем мы начнем разделять разнородное железо на однородные пулы, и каждое соревнование будет проходить в рамках одного пула с одинаковым железом.
Переезд в облако
Новым вызовом для системы станет необходимость запускаться в Яндекс.Облаке. По нынешним меркам железные сервера — это ненадежно, переезд необходим, но важно сохранить консистентность выполнения посылок. Здесь технические возможности пока исследуются. Есть идея, что в крайних случаях на облачных машинах можно выполнять решения, не требующие строгого времени исполнения. Тем самым мы снизим нагрузку на железные машины и они будут заниматься только решениями, которые как раз требуют консистентности. Есть и другой вариант: сначала проверять посылку в облаке и, если она не уложилась в лимит времени, перепроверять на реальном железе.
Сбор статистики
Даже после всех ухищрений процессоры неизбежно будут троттлить. Чтобы снизить негативный эффект, будем выполнять решения параллельно, сравнивать результаты и, если они расходятся, запускать перепроверку. Кроме того, если одна из решающих машин постоянно деградирует, это повод вывести ее из обслуживания и разобраться с причинами.
У Контеста есть особенность — может показаться, что все сводится к простому запуску кода и получению результата. В статье я приоткрыл лишь один небольшой аспект этого процесса. Нечто подобное есть на каждом слое сервиса.
#include <iostream>
using namespace std;
int main()
{
int n = 500000000;
int *a = new int[n + 1];
for (int i = 0; i <= n; i++)
a[i] = i;
for (int i = 2; i * i <= n; i++)
{
if (a[i]) {
for (int j = i*i; j <= n; j += i) {
a[j] = 0;
}
}
}
delete[] a;
return 0;
}Это простенькое приложение специально для экспериментов, оно ищет простые числа методом решета Эратосфена. Запустим решение 20 раз и посчитаем user time каждого исполнения.
Описание тестового стенда
i7-8750H @ 2,20 ГГц
32 ГБ RAM
OС:
Ubuntu 18.04.4
5.3.0-53-generic
32 ГБ RAM
OС:
Ubuntu 18.04.4
5.3.0-53-generic
Разброс времени исполнения до оптимизаций:
Разница между самым быстрым и самым медленным исполнением — 2230 мс.
Для олимпиадного программирования это неприемлемо. Время выполнения кода участника — один из критериев успешности его решения и одно из условий соревнования, от этого зависит распределение призовых мест. Поэтому существует важное требование к подобным системам — одинаковое время проверки одного и того же кода. Далее будем называть это консистентностью выполнения кода.
Попробуем выравнять время исполнения.
Изоляция ядер
Начнем с очевидного. Процессы конкурируют за ядра, и нужно каким-то образом изолировать ядро под исполнение решения. Кроме того, с включенным Hyper Threading операционная система определяет одно физическое ядро процессора как два отдельных логических ядра. Для честной изоляции ядра нам нужно отключить Hyper Threading. Это можно сделать в настройках BIOS.
Ядро Linux из коробки поддерживает флаг запуска для изоляции ядер isolcpus. Добавим этот флаг в GRUB_CMDLINE_LINUX_DEFAULT в настройках grub: /etc/default/grub. Например:
GRUB_CMDLINE_LINUX_DEFAULT="... isolcpus=0,1"Выполним update-grub и перезапустим систему.
Все выглядит как ожидалось — первые два ядра не используются системой:
Запустимся на изолированном ядре. Конфигурация CPU Affinity позволяет привязать процесс к конкретному ядру. Есть несколько способов это сделать. Например, запустим решение в porto-контейнере (ядро выбирается с помощью аргумента cpu_set):
portoctl exec test command='sudo stress.sh' cpu_set=0Офтоп: для запуска решений в продакшене мы используем QEMU-KVM. Porto-контейнер используется в статье, чтобы было проще показать.
Запуск с ядром, выделенным под решение, без нагрузки на соседние ядра:
Разница — 375 мс. Стало лучше, но это все равно слишком много.
Тюним перфоманс
Давайте попробуем провести наш тест под нагрузкой. Под какой именно? Наша задача — множеством потоков нагрузить все ядра. Это можно сделать несколькими способами:
- Написать простое приложение, которое создаст много потоков и начнет считать что-нибудь в каждом из них.
- Выполнить команду:
cat /dev/zero | pbzip2 -c > /dev/null. pbzip2 здесь — это многопоточная реализация bzip2. - Или можно установить утилиту stress и дать нагрузку командой
stress --cpu 12.
Запуск с ядром, выделенным под решение, с нагрузкой на соседние ядра:
Разница — 1354 мс: на секунду больше, чем без нагрузки. Очевидно, нагрузка повлияла на время исполнения, несмотря на то, что мы запускались на изолированном ядре. Видно, что в определенный момент время исполнения уменьшилось. На первый взгляд это контринтуитивно: при растущей нагрузке производительность тоже увеличивается.
В продакшене такое поведение (когда время исполнения начинает плыть под нагрузкой) может выстрелить очень болезненно. Что такое нагрузка в данном случае? Поток решений от участников, чаще всего на крупных соревнованиях и олимпиадах.
Причина в том, что под нагрузкой включается Intel Turbo Boost — технология увеличения частоты. Отключим ее. Для своего cтенда я выключил еще и SpeedStep. Для процессора AMD нужно было бы выключить Turbo Core Cool'n'Quiet. Все перечисленное делается в BIOS, основная идея — отключить то, что автоматически управляет частотой процессора.
Запуск на изолированном ядре с отключенным Turbo Boost и нагрузкой на соседние ядра:
Выглядит неплохо, но разница все еще составляет 252 мс. И это все еще слишком много.
Офтоп: заметьте, как просело среднее время исполнения — примерно на 25%. В повседневной жизни отключенные технологии — это добро.
Мы избавились от конкуренции за ядра, стабилизировали частоту ядер — теперь на них ничто не влияет. Так откуда же разница?
NUMA
Non-Uniform Memory Access, «неравномерный доступ к памяти», или Non-Uniform Memory Architecture, «архитектура с неравномерной памятью». В NUMA-системах (то есть, условно, на любом современном многопроцессорном компьютере) у каждого процессора есть локальная память, которая рассматривается как часть общей. Каждый процессор может обратиться и к своей локальной памяти, и к локальной памяти остальных процессоров (удаленной памяти). Неравномерность в том, что доступ к локальной памяти происходит заметно быстрее.
Время исполнения «гуляет» именно из-за такой неравномерности. Пофиксим ее, привязав наше исполнение к конкретной numa node. Для этого добавим numa node в конфигурацию porto-контейнера:
portoctl exec test command='stress.sh' cpu_set="node 0" cpu_set=0Запуск на изолированном ядре с отключенным Turbo Boost, конфигурацией NUMA и нагрузкой на соседние ядра:
Разница — 48 мс, а среднее время выполнения решения после того, как мы отключили процессорные оптимизаций, составляет 10 с. 48 мс в масштабе 10 с — равносильно погрешности в 0,5%, очень хорошо.
Еще немного про isolcpus
У флага isolcpus есть проблема: некоторые системные потоки все равно могут schedule'иться на изолированное ядро.
Поэтому в продакшене мы используем пропатченное ядро с расширенной функциональностью этого флага. Тем самым мы выбираем ядро с учетом флага, когда происходит scheduling потоков.
Патч самописный, сделан над ядром 3.18. В этом ядре есть макрос kthread_run, которым некоторые драйвера пользуются для запуска своих потоков. Во время запуска не производится проверка на доступные CPU, и потоки могут исполняться на любом ядре вне зависимости от настроек isolcpus.
Поэтому мы и написали патч — в нем добавлен новый аргумент запуска slave_cpus и несколько макросов, которые выбирают ядро для запуска с учетом маски из этого флага.
Поэтому мы и написали патч — в нем добавлен новый аргумент запуска slave_cpus и несколько макросов, которые выбирают ядро для запуска с учетом маски из этого флага.
Планы на будущее
Пулы
Если одна решающая машина мощнее другой, то никакие ухищрения с изоляцией ядер не помогут — в результате мы все равно получим большую разницу во времени исполнения. Поэтому нужно думать про гетерогенные среды. До сих пор мы просто не поддерживали гетерогенность — весь парк решающих машин комплектуется одинаковым железом. Но в ближайшем будущем мы начнем разделять разнородное железо на однородные пулы, и каждое соревнование будет проходить в рамках одного пула с одинаковым железом.
Переезд в облако
Новым вызовом для системы станет необходимость запускаться в Яндекс.Облаке. По нынешним меркам железные сервера — это ненадежно, переезд необходим, но важно сохранить консистентность выполнения посылок. Здесь технические возможности пока исследуются. Есть идея, что в крайних случаях на облачных машинах можно выполнять решения, не требующие строгого времени исполнения. Тем самым мы снизим нагрузку на железные машины и они будут заниматься только решениями, которые как раз требуют консистентности. Есть и другой вариант: сначала проверять посылку в облаке и, если она не уложилась в лимит времени, перепроверять на реальном железе.
Сбор статистики
Даже после всех ухищрений процессоры неизбежно будут троттлить. Чтобы снизить негативный эффект, будем выполнять решения параллельно, сравнивать результаты и, если они расходятся, запускать перепроверку. Кроме того, если одна из решающих машин постоянно деградирует, это повод вывести ее из обслуживания и разобраться с причинами.
Выводы
У Контеста есть особенность — может показаться, что все сводится к простому запуску кода и получению результата. В статье я приоткрыл лишь один небольшой аспект этого процесса. Нечто подобное есть на каждом слое сервиса.


