
Кому интересна тема про сверточные нейронные сети, сможет найти тут вопросы по использованию Google Colab.
Сверточные нейтронные сети - специальная архитектура искусственных нейронных сетей, предложенная Яном Лекуном в 1988 году и нацеленная на эффективное распознавание образов, входит в состав технологий глубокого обучения.
Я использовала Google Colab, чтобы провести анализ и классификацию пупиллограмм, а сверточные нейтронные сети служили инструментом распознавания исходных данных.
Пуппилограмма - временной ряд, описывающий диаметр зрачка, который может быть представлен в виде графика.
Текст будет разделен на 4 главы для лучшего понимания происходящего. Третья и четвертая глава будет относиться непосредственно к классификации изображений с помощью сверточных нейтронных сетей. Первая и вторая глава показывает реальный пример использования классификации изображений, чтобы привнести вклад в системы общественной безопасности.
1. Оценка функционального состояния человека в системах общественной безопасности
1.1 Понятие и виды функциональных состояний человека
Функциональное состояние выражается в характеристиках и качествах эффективности трудовой деятельности человека. Существует несколько функциональных состояний человека, такие как утомляемость, монотония, психическое пресыщение и напряженность. Каждое из этих состояний снижает работоспособность и влечет за собой ошибки в работе или ставит под угрозу безопасность как самого человека, так и общества.
Утомляемость является одним из распространённых факторов снижения работоспособности человека, приводящее к нарушению точности, координации, увеличению времени реакции, ошибок в работе, ухудшению внимания. Утомляемость возникает из-за длительной и интенсивной рабочей нагрузки.
Монотония появляется у человека при выполнении им однообразной, монотонной работы, что является причиной появления безразличия и раздражительности, сказывающейся на негативном отношении к работе. Как следствие возникает сонливость, пропадает способность принятия быстрых решений, однако данные явления исчезают, когда человек выполняет профессиональную деятельность в среде без внешних раздражителей. Монотония больше связана с торможением психической сферы, а психическое пресыщение с возбуждением в эмоционально-мотивационной сфере.
Психическое пресыщение возникает после состояния монотонии, если работа в этой сфере деятельности не прекращается. В редких случаях возникает до состояния монотонии (из-за слабой нервной системы).
Напряженность связана с эмоциональными переживаниями, стрессом на работе. Причиной напряжённости может быть дефицит времени на выполнение поставленных задач. Такая деятельность влечет за собой нестабильное состояние человека, ошибки в проделанной работе.
1.2 Пупиллометрия как эффективный метод оценки функционального состояния человека
Методика, которая заключается в бесконтактном определении динамики размера зрачка при его реакции на свет, называется пупиллометрия. Данная методика измерения зрачка используется в медицинской сфере, однако осуществляется такое измерение с помощью фонарика, что приводит к неточностям при ручной оценке.
Технические средства компьютерного зрения могут использовать пупиллометрию в медицине, безопасности жизнедеятельности, в системах общественной и транспортной безопасности. Немало важно, что результаты пупиллометрии могут подтвердить признаки алкогольного или наркотического опьянения, поэтому можно сократить риски потенциальной угрозы.
Обычно зрачок реагирует на яркий свет сужаясь, диаметр зрачка уменьшается, чтобы защитить глаз от яркости света. При тусклом свете зрачок расширяется, чтобы пропускать больше света, соответственно диаметр зрачка увеличивается. При наркотическом опьянении диаметр зрачка будет заметно выше нормы. В состоянии наркотического или алкогольного опьянения зрачок человека будет медленно реагировать на вспышку света или реакция будет минимальная. В состоянии усталости, монотонии, напряженности, психического пресыщения зрачок будет медленно реагировать на свет.
Алгоритмы компьютерного зрения позволяют оценить функциональное состояние человека с помощью пупиллометрии. Для оценки ФС человека можно использовать видеокамеры. Реакция зрачка будет представлена временным рядом в каждый момент времени, отражающем диаметр зрачка при видеофиксации.
1.3 Использование сверточных нейронных сетей для анализа и классификации графического изображения
Пупиллограммы должны быть обработаны для дальнейшего анализа. Необходимо устранить шумы, пропущенные значения и аномалии для более гладкого графика. Однако при сглаживании могут быть утрачены важные для классификации свойства, поэтому используется ручной подход разметки выборок, в данном случае для классификации на норму и отклонение (суть классификации).
Для классификации изображений используются сверточные нейронные сети, которые эффективно распознают образы. Данная сеть использует некоторые особенности зрительного анализатора. В зрительной коре были открыты простые клетки, реагирующие на прямые линии под разными углами, и сложные клетки, реакция которых связана с активацией определённого набора простых клеток. Сложные клетки распознают более сложные образы, складывающиеся из простых линий, являющихся абстракцией. (Крон Д. Глубокое обучение в картинках. Визуальный гид по искусственному интеллекту.)
Архитектура сверточной нейронной сети представляет собой: входной слой (INPUT), сверточный слой (Convolutional), функция активации, уровень пула (Pooling), а также полносвязный уровень (FC).
Процесс свертки происходит на фильтре RGB (три канала). Исходное изображение, где каждый пиксель имеет значение яркости от 0 до 255 в зависимости от насыщенности определенного цвета, является входным сигналом. Всего подготавливается три матрицы по каждому из трех цветов. Также образуется ядро свертки или кернел (kernel), представляющий из себя матрицу, чаще всего 3х3 (может быть любая нечетная матрица). Данное ядро свертки заполняется сначала случайными значениями, чтобы определить в каком направлении составлять карту признаков. Карта признаков — это набор признаков после одной операции свертки. Значения, которые заполнились в ядре свертки, определят, на каком признаке сконцентрировать внимание. Для каждой из трех матриц по цветам будет свой кернел (kernel). Фильтр – это коллекция кернелов. Фильтр позволяет выделять характерные участки на изображении в соответствии с конфигурацией весовых коэффициентов. Данное понятие фильтра применяется для свертки, осуществляющейся по нескольким каналам.
Если сумма значений в матрице фильтра будет равна 1, то изображение по яркости будет неизменным до и после фильтрации, однако резкость изображения будет больше. Если результирующее значение будет больше 1, то яркость изображения будет увеличена. В случае, когда сумма значений меньше 1, аналогично, изображение становится темнее. Если 0, изображение будет темным, однако не черным. Фильтр может искать края, объекты, которые будут яркими в вертикальном, горизонтальном положении, по диагонали, а также во всех направлениях, это зависит от расположения результирующих значений в кернеле. Фильтры могут делать размытие, рельеф и т. Д. Однако, если отфильтрованная структура содержит отрицательные числа, числа больше 255, то числа урезаются до значений от 0 до 255.
Процесс свертки с одним каналом представлен на рисунке 1. Свертка происходит путем смещения ядра слева направо и перемножением исходной матрицы и ядра свертки, каждое число накладывается на ядро и перемножается, после этого значения в полученной матрице складываются. Как показано на рисунке 1 после перемножения матриц и сложения получилось число -8, которое заносится в другую матрицу, то есть матрицу после свертки. Данный квадрат смещается на одно значение с шагом (stride) 1 и так инвариантно (выполняется одна и та же линейная операция в каждой позиции изображения). Получается матрица меньшая, чем исходная. Матрица заполняется в карту признаков.

Для одного канала формирование карты признаков представлено на рисунке 2. Так происходит один слой свертки. Карты признаков передаются в следующий слой свертки и инвариантно.

Процесс свертки для 3D изображения происходит сложнее. В RGB формируется три канала, каждый по цвету, в которых образуются меньшие матрицы изображения (рисунок 3).

Далее происходит формирование одного канала суммированием трех матриц версий изображений в один канал (рисунок 4).

Для выходного канала добавляется смещение (bias) (рисунок 5).

Выходной канал формирует карту признаков для 3D изображения. Однако, на выходе карты признаков становятся меньшего размера, чтобы этого избежать для использования данных карт в следующей свертке, применяется отступ (padding) (рисунок 6).

Края матрицы заполняются нулями, чтобы при новой свертке важные пиксели могли дальше участвовать в следующей свертке.
Практически во всех сверточных нейронных сетях используется функция активации ReLu. Данная функция активации подключается к сверточному слою, чтобы все отрицательные значения не передавались следующему слою.
Также существует слой пула (Pooling). Применяется для выбора доминирующих признаков. Происходит сжатие изображения в два раза. Распространенные сжатия: Max Pooling, Average Pooling (рисунок 7). Сжатие Max Pooling происходит посредством выбора максимального значения в блоках пикселей. Average Pooling выбирает усредняет значение в блоках пикселей. Еще есть сжатие Min Pooling, выбирается меньшее из блоков, однако это применяется реже.

Пулинг применяется для предотвращения переобучения. Пулинг является субдискретизацией - выделение важных признаков предыдущего слоя и сокращение размерности слоев сети.
Сеть, состоящая из нескольких слоев искусственных нейронов, называется сетью глубокого обучения. В роли скрытого слоя (hidden) используется плотный (dense) слой, также данный слой называют полносвязный (FC), потому что все его нейроны могут получать информацию от каждого из нейронов в предыдущего слоя.
Структура сверточной сети представлена на рисунке 8.

2. Получение исходных пупиллограмм и подготовка выборок для анализа
2.1 Получение исходных пупиллограмм
Исходные пупиллограммы были получены с помощью программного комплекса определения функционального состояния опьянения человека по зрачковой реакции на световое импульсное воздействие (рисунок 9). Программный комплекс состоит из источника регистрации (камеры), источника освещения (инфракрасной и белой подсветки) и блока диагностики (компьютер). Для получения исходных данных производилась трех или четырехсекундная видеозапись с подачей в начале записи кратковременного светового импульса, выводилась полученная при анализе изображений глаз человека пупиллограмма правого и левого глаза с надписью «Норма» или «Отклонение». Нормой может считаться зрачковая реакция здорового человека, а отклонением - все остальное. Данный комплекс был представлен на международном форуме Digital Week 2021. Исходные данные были взяты с форума и вручную распределены на норму и отклонение, чтобы избежать ошибок, аномалий и шумов при анализе и классификации в сверточных нейронных сетях. Неточности могли произойти в алгоритме сглаживания пупиллограмм. Всего было получено 384 изображения, из которых состояние нормы составили - 118 изображений, отклонения – 266.

2.2 Описание графических изображений пупиллограмм
Пупиллограмма – это временной ряд, описывающий диаметр зрачка при световом воздействии, который может быть представлен в виде графика (рисунок 10).

На данном рисунке представлен график нормальной реакции зрачка на изменение освещенности. Данные параметры зрачковой реакции берутся за основу функционального состояния человека в программном комплексе, представленном выше:
ДН - диаметр начальный
ДМ - диаметр минимальный
ДПС - диаметр половинного сужения
ДК - диаметр конечный
АС - амплитуда сужения
ЛВ - латентное время реакции
ВС - время сужения
ВР - время расширения
ВПС - время половинного сужения
ВПР - время половинного расширения
СС - скорость сужения
СР - скорость расширения
Важными параметрами являются скорость сужения и скорость расширения. Эталонный график нормальной реакции зрачка представлен на рисунке 10. Графики людей в состоянии опьянения, усталости будут отличаться от графиков людей в нормальном состоянии (выборка отклонений составила больше всего изображений). Необходимо правильно интерпретировать графики, поэтому вручную были отобраны и распределены графики изображений, которые являлись выборкой программного комплекса (норма и отклонение). В программном комплексе уже был классификатор, однако графики классификации необходимо было еще раз просмотреть для создания выборки и проверить на ошибки классификации .
Программный комплекс не учитывал, что часть исследуемых людей пользуются линзами, поэтому выборка содержала такие результаты, которые показывают отклонение из-за преломления света, проходящего через линзу при видеофиксации. Наличие длинных ресниц осложняет распознавание диаметра зрачка, что являлось причиной отклонения зрачковой реакции, поэтому выборка с результатом «отклонение» была значительно больше и составила 266 изображений из 384 общей выборки.
Способ проверки выборки нормы и отклонения был ручной. Чтобы определить состояние усталости, можно представить пример графика зрачковой реакции, когда человек в похожих испытаниях был без сна несколько часов (рисунок 11).

График наркотического опьянения можно определить согласно следующим параметрам: острая интоксикации опиатами уменьшает ДН в 2 раза, АС в 5 раз, СС и СР уменьшается в 2-3 раза, увеличение ЛВ на 15% и более, временные показатели увеличатся, при героиновой интоксикации уменьшение в два раза и более ДН и ДК, уменьшение АС и увеличение ЛВ. СС и СР увеличиваются. При алкогольном опьянении реакция на свет вялая, зрачки либо увеличены, либо сильно сужены, происходит увеличение времени реакции.
2.3 Разметка пупиллограмм по видам функционального состояния человека
Графики изображений пупиллограмм после обработки в программном комплексе представляют собой графики изображений, в которых по вертикали отображается диаметр зрачка от 0 до 1, по горизонтали – номер кадра (фрейма) от 0 до 100 кадров. Пупиллограммы разделены на норму и отклонение (рисунок 12–13).


2.4 Подготовка обучающей и тестовой выборок для анализа
Выборка состоит из 384 изображения, из который норма - 118 изображений, отклонение - 266. Изображения нормы и отклонения были поделены на тестовые данные и проверочные данные.
Тестовые данные разделены приблизительно на 80% из всех изображений, а проверочные – на 20%. Норма в обучающей выборке составляет 86 изображений, в тестовой – 32 изображения. Отклонение в обучающей выборке составляет 236 изображений, в тестовой – 30 изображений.
Выборка тестовой и обучающей выборки при подготовке представлена на рисунке 14. В каждой папке есть файлы нормы и отклонения (рисунок 15). В папках изображения должны содержать числовую последовательность (рисунок 16).



Такие числовые последовательности принимает сверточная нейронная сеть для классификации.
3. Классификации пупиллограмм в облачной среде Google Colab
3.1 Описание облачной среды Google Colab
Облачная среда Google Colab является подходящей площадкой для работы студентов и специалистов в области ИИ (искусственного интеллекта). В Google Colaboratory (Colab) существует возможность выполнять код на языке Python, оставлять заметки к коду. Весь перечень действий происходит в браузере, где файлом с наработанными материалами можно поделиться с помощью сохранения данного файла и дальнейшей загрузки выбранного файла в другой учетной записи. Также в выбранной среде есть возможность пользоваться GPU (графическим ускорителем), с помощью которого происходит быстрое обучение нейронных сетей и выполнение кода. Для моделей испытаний сверточных нейронных сетей будут использованы библиотеки Tensorflow и Pytorch. TensorFlow — это библиотека для глубокого обучения, Keras (библиотека) как frontend для TensorFlow (т. е. работает поверх TensorFlow). PyTorch используется для компьютерного зрения и обработки естественного языка. В данной облачной среде все наработки сохраняются на Google диске в папке желтого цвета Colaboratory, которая создает при первом использовании среды, файлы в этой папке будут иметь расширение .ipynb. В Google Colab, чтобы начать работать в среде, необходимо нажать «Файл» и «Создать блокнот» (рисунок 17).

Далее происходит создание файла, которому можно задать необходимое название (рисунок 18). В данном файле есть ячейки, в которые осуществляется запись кода, работа со средой происходит при нажатии кнопок «+Код» - код или «+Текст» - текст. Запуск на компиляцию кода необходим в каждой ячейке.

Загрузка блокнота происходит, в случае нажатия «Файл» и «Загрузить блокнот» и ручного перемещения файла. По этой причине оптимальным способом обмена кода и загрузки наработок является работа с другого аккаунта (рисунок 19). Разработка моделей сверточных нейронных сетей будет происходить на языке программирования Python.

3.2 Выбор моделей сверточных нейронных сетей для анализа и классификации пупиллограмм
В библиотеке Keras есть список моделей глубокого обучения, которые можно импортировать с обученными весами и использовать для классификации изображений (рисунок 20). Однако, обученные веса в выбранных моделях использоваться не будут, чтобы обучить модели самостоятельно.

Для того, чтобы использовать модель, необходимо провести предобработку изображений, которые будут поступать в модель и обучаться. Предобработка может производиться с помощью класса ImageGenerator, содержащего стандартизации выборочную и функциональную, случайные сдвиги, вращение, изменение порядка размеров и т. д. Также для обучения и работы модели необходима настройка полносвязных нейронных слоев и проведение дальнейшего исследования при компиляции модели. На этапе компиляции модели можно применять разные функции потерь, оптимизаторы, метрики, подходящие к данной модели и дающие хорошую точность обучения. Модель учится ассоциировать данные изображения и метрики, а также делать прогноз обучающей и тестовой выборки. На выходе модель должна выводить функцию потерь и точность обучения по эпохам, а также графики этих показателей для мониторинга работы системы.
Для исследования были выбраны модели VGG16, VGG19, ResNet34, InceptionV3, Xception. ResNet34 реализована с помощью библиотеки PyTorch, а остальные модели с помощью TensorFlow.
3.3 Реализация выбранных сверточных нейронных сетей для анализа и классификации пупиллограмм
В Google Colab работа со сверточными нейронными сетями с использованием датасета начинается с подключения данного блокнота к Google диску (рисунок 21). На рисунках 21–46 реализация кода происходила с помощью библиотеки TensorFlow.

Следующий этап – предобработка изображения. Необходимо получить изображения из Google диска для использования их в обучении моделей (рисунок 23–24). Должен быть правильный путь до папок, в противном случае обучение модели не будет происходить. Для проверки путей используется команда !ls /начало пути/ . На рисунках 23–30 происходит реализация моделей VGG16 и VGG19.
Для использования библиотек или методов, необходимо их импортировать (рисунок 22).



На данном этапе необходимо создать DataFrame для предобработки изображений (рисунок 25). DataFrame является табличной формой восприятия данных.


После компиляции (сборки) (рисунок 25) изображения уже будут упорядочены, отклонение будет иметь значение 1, а норма 0 в двух папках (обучающая и тестовая выборки) (рисунок 26).
Также можно посмотреть, как будут выглядеть изображения, которые будут обучаться (рисунок 27–29).



Данные должны разбиваться на пакеты (batch), чтобы изображения обрабатывались быстрее. Если во время тестирования данные не будут перетасовываться (shuffle=False), иначе (shuffle=True). Также необходимо указать класс, которому будут принадлежать изображения. В данном случае класс (class_mode='categorical') (рисунок 30). Такая модификация класса подойдет для моделей VGG16, VGG19, Xception. Бинарный класс подойдет для моделей ResNet34 и InceptionV3. Входной размер изображения для каждой модели свой. Размер изображения можно посмотреть в документации к моделям. Данный размер можно изменять, однако для большей точности классификации можно оставить исходный. Размер пакета можно менять до 128.

Предварительная обработка изображения для моделей InceptionV3 и Xception будет показана на рисунке 31–32. Для всех выбранных моделей кроме Xception размер изображения 224х224, а Xception – 299х299.


Этап подключения моделей (рисунок 33–34). Необходимо ранее импортировать выбранную модель или как показано на рисунке 35. Веса в данных моделях импортироваться не будут, потому что обучаться модель будет самостоятельно, команда - (include_top=False). Так как будет применена фильтрация RGB, в команде input_shape= (224,224,3) тройка будет означать фильтрацию.




Следующим этапом будет подключение метрик (рисунок 37). Подробнее о метриках будет приведено в главе 3.4.

Далее происходит прикрепление полносвязного слоя к сети и методы настойки модели сети (рисунок 38). Метод GlobalAveragePooling2D() переводит слой в 1D формат, а также в отличие от метода Flatten(), выполняющего те же функции, происходит сопротивление переобучению сверточной нейронной сети. Для моделей VGG16 и VGG19 реализовано три глубоких слоя Dense, в которых количество искусственных нейронов на первом слое должно быть большим, для большей точности моделей. Функции активации relu подходят для первых двух глубоких слоев моделей, а на третьем слое лучше использовать функцию активации softmax или sigmoid.Класс model группирует слои в объект с элементами обучения и вывода. На выходе будут метрики и посчитанное обратное распространение ошибки сверточных нейронных сетей VGG16/VGG19 через категориальную кросс - энтропию. Оптимизатор для данных сверточных нейронных сетей Adam или SGD (стохастичный градиентный спуск) со скоростью обучения 0.001. Также создается отчет summary о параметрах обучения модели (количество обучаемых и необучаемых параметров).

Для моделей InceptionV3 и Xception процесс прикрепления полносвязного слоя представлен на рисунках 39–40. В модели InceptionV3 используется метод Flatten(), а также метод Dropout(), который исключает какую-то часть искусственных нейронов, избегая переобучения. На третьем слое глубокого обучения количество искусственных нейронов составляет 1, потому что класс обучения был бинарный, а в других моделях категориальный. Для первого слоя глубокого обучения не требуется большое количество искусственных нейронов. На третьем слое глубокого обучения лучше использовать функцию активации sigmoid. Функция оптимизации Adam, Nadam, Adamax со скоростью обучения 0.001 подходит для улучшения точности модели InceptionV3 (рисунок 39).

Для модели Xception используется GlobalAveragePoling2D(), два слоя глубокого обучения, функция активации на втором слое softmax, оптимизатор Adam со скоростью обучения 0.001 для большей точности данной модели (рисунок 40).

Для того, чтобы создать графики и вывести результат работы модели, необходимо вести запись логов (файл с информацией об обучении модели) (рисунок 41).

Тренировка моделей на разном количестве эпох и размерах пакетов происходит с помощью метода fit(), а также ведется запись лога (рисунок 42).

Качество и точность обучения моделей сопровождается графиками Accuracy (рисунок 43), функцией обратного распространения ошибки Loss (рисунок 43), графиком F1Score – среднее гармоничное точности и полноты (рисунок 44), графиком Precision – предсказание (рисунок 45), графиком Recall – полнота (рисунок 45) и графиком AUC – качество моделей (рисунок 46). Подробнее о метриках в главе 3.4. Полный код будет представлен ниже.

")
 и Recall (полнота)")
")
Модель ResNet34 была реализована с помощью библиотеки PyTorch. Импортирование библиотек представлено на рисунке 47, предобработка изображений на рисунке 48, создание модели на рисунке 49, обучение модели на рисунках 50–51, а создание графиков модели на рисунке 52. Полный код модели будет представлен ниже.






3.4 Выбор метрики для оценки сверточных нейронных сетей
Матрица ошибок
Метрики основаны на истинно положительных (TP), истинно отрицательных (TN), ложно положительных (FP) и ложно отрицательных (FN) исходах (рисунок 53).

Accuracy
Метрика точности показывает количество положительных исходов класса к общему количеству исходов (рисунок 54).

Метрика accuracy не учитывает соотношения ложных срабатываний. В данном исследовании соотношение нормы и отклонения изображений графиков пупиллограмм как в тестовой, так и в проверочной выборке не равна, поэтому точность не будет учитываться как правильная метрика для моделей.
Precision
Данная метрика «точность» показывает количество истинно положительных (TP) исходов из всего набора положительных исходов (рисунок 55).
")
Данная метрика определяет количество истинно положительных исходов (TP) среди всех исходов класса, которые были определены в качестве положительного (рисунок 56).

Точность (precision) и полнота (recall) используются в совокупности при оценке большинства алгоритмов.
Полнота может обнаруживать данный класс, а точность отличать этоткласс от других классов. Данные метрики применимы в условиях несбалансированных выборок.
F1-Score

Данная метрика является средним гармоническим для получения оценки результатов (рисунок 57).
AUC (Area Under Curve)
Данная метрика показывает вероятность ситуации распознавания случайного экземпляра негативного класса в качестве позитивного класса. Метрикой, определяющей точность моделей в классификации выбрана метрика F1Score.
3.5 Выводы
В данной главе описана разработка пяти сверточных нейронных сетей: четырёх с помощью библиотеки TensorFlow (VGG16, VGG19, Xception, InceptionV3) и одной с помощью библиотеки PyTorch (ResNet34).
Разработка сверточных нейронных сетей происходила на языке программирования Python. Данные модели обучены без применения обученных весов, чтобы сверточные нейронные сети различной архитектуры обучались с нуля. Также описаны и выбраны метрики для оценки качества разработанных моделей и точности классификации. F1Score стала метрикой, определяющей точность классификации всех моделей в исследовании. Данная метрика выбрана по причине несбалансированности выборки. Метрика определяет точность всей модели, является средним гармоническим метрик точности (precision) и полноты (recall). По метрикам, которые описаны в главе, построены графики с помощью библиотеки matplotlib. Данные для построения графиков были взяты из логов записей в моделях или были записаны в список (list) на протяжении обучения моделей (зависит от способа разработки). Необходимо принимать во внимание график функции потерь Loss.
С помощью данных моделей можно производить обучение сверточных нейронных сетей для классификации изображений, а с помощью метрик и графиков можно проводить анализ полученных результатов сверточных нейронных сетей. Результаты исследования приведены в 4 главе.
4. Проведение исследований и оценка эффективности разработанной системы
4.1 Применение функции активации для оценки эффективности разработанной системы
Нейронная сеть находит зависимости между входными и выходными данными при обучении, сеть состоит из нейронов (узлов сети), которые могут быть соединены различными способами. Данные комбинации строят различные архитектуры сетей. Нейрон хранит определенный диапазон значений. На вход нейронной сети подаются значения в большом количестве, а на выходе нейрон выдает лишь одно. Формула нейрона представлена на рисунке 58.

В данной формуле w является весом на i-том входе, х является входными значением на i-том входе, а b – смещением. Результат этой формулы передается в функцию активации (возбуждение нейрона). Данная функция восприминает нейрон либо активированным, либо нейроном, которого можно игронировать. Функция активации приводит вектор градиента в заданном диапазоне в вектор вероятности.
В таблице 1 представлены различные функции активации и принадлежащая им формула.

Три первые функции активации являются классическими элементами для построения различных архитектур, следующие пять функций являются уже современными вариантами для построения нейронных сетей, а последний вариант функции активации, которая является дополнением к построению таких архитектур (выходной слой) (Таблица 1).
Логистическим сигмоидом σ также называют сигмоидную функцию активации. Данная функция является гладкой монотонно возрастающей нелинейной функцией. Сигмоидная функция обладает всеми свойствами, необходимыми для нелинейности: ограничена, стремится к нулю при х→-∞ и к единице при х→∞, везде дифференцируема, существует производная.Нелинейность данной функции позволяет из набора таких функций построить многослойную сеть. Логистический сигмоид σ не насыщается от сильных сигналов и усиливает слабые.
Гиперболический тангенс tanh по свойствам имеет схожесть с логистическим сигмоидом σ: непрерывен, ограничен (однако, стремится к единице при х→-∞), существует производная. Для функции σ ноль является точкой насыщения, а для tanh ноль – это нестабильная промежуточная точка, потому от нуля можно менять аргумент в любую сторону.
Ступенчатая функция использовалась в ранних конструкциях перцептронов. Один перцептрон со ступенчатой функцией активации можно обучить, однако сеть с несколькими уровнями ступенчатой активации не будет строиться, по этой причине производная от ступени равна нулю (в нуле не определена).
ReLU- нейроны эффективнее σ - нейронов и tanh – нейронов. Такая структура активации гораздо точнее отражает происходящее с настоящими нейронами в человеческом мозге. Данную функцию активации чаще всего используют при создании глубоких нейронных сетей. Форма функции ReLU определяется уравнением α = max(0, x). ReLU состоит из двух линейных функций, объединение которых формирует в нелинейность. Нелинейность позволяет моделям аппроксимировать любую нелинейную функцию.
Функции активации Leaky ReLU, Parameterized ReLU, ELU являются производными от ReLU.
Функция активации Softsign похожа на функцию активации гиперболический тангенс tanh. Диапазон возвращаемых значений от -1 до 1, а производная данной функции в нуле не определена. Вычисление производной проблематично, а для применения метода обратного распространения (метод вычисления градиента - вектор частных производных функции потерь по весам) сложных функций) важна быстрота нахождения производной, поэтому данная функция редко используется для глубокого обучения нейронных сетей.
Такая же функция активации, которая редко используется - SoftPlus. Данная функция похожа на функцию активации ReLU. Функция сложна для вычислений, поэтому и реже используется в глубоком обучении нейронных сетей.
Функция Softmax чаще всего используется как выход классификатора для представления распределения вероятности n классов.
Для реализации системы была выбрана функция активации ReLU (используется после скрытого слоя), а для выходного слоя лучше использовать функцию активации Softmax, также можно попробовать Sigmoid (Сигмоидная функция активации). Модели, которые имеют бинарный класс, при реализации на выходном слое используют функцию активации Sigmoid и дают результаты с высокой точностью, а для моделей категориального класса – функция активации Softmax. Модель ResNet34 показывала высокие результаты и без выходного слоя после слоев с функцией активации ReLU.
Книга 1 / Книга 2 / Книга 3
4.2 Роль размерности пакетов в исследовании об эффективности разработанной системы
Сверточные нейронные сети при использовании пакетов стабилизируются, а также повышается производительность сети. В глубоком обучении нейронных сетей с разделением входных данных используется слово «пакет» или «батч» (batch), а при обучении моделей используется параметр batch_size. Размерность пакета является гиперпараметром модели. Общая схема процесса обучения нейронной сети представлена на рисунке 59.

Данная схема представляет собой процесс обучения нейронной сети методом SGD (стохастический градиентный спуск). Данные делятся на пакеты, пакеты передаются через сверточную нейронную сеть, происходит сравнение истинных значений «ӯ» с полученными «y», а также вычисляется функция стоимости (функция потерь) «С», в обратном распространении вычисляются градиенты и происходит корректировка параметров «w» (вес) и «b» (смещение).
При использовании батчей большого размера оценка градиента функции потерь будет точнее, а при использовании батчей меньшего размера оценки градиентов могут искажаться, время обучения будет больше.
В основном размерность пакетов выбирается как значения степени числа два. Первое значение во избежание маленькой размерности берется число 32, однако брать значения размерности батчей больше 128 не рекомендуется, потому что произойдет локальный минимум (экстремум).
В разработанной системе исследовалась основная размерность пакетов: 32, 64, 128. Для модели VGG16 подходила разная размерность пакетов (32,64,128) для высокой точности классификации, для модели VGG19 тоже подходили такие размерности для высокой точности, однако 64 – размерность пакета была оптимальной. В модели InceptionV3 оптимальной была размерность пакета 32. В модели Xception – 32 или 20. Для модели ResNet34 подходила размерность пакетов кратная 5, т. е. 50, 75 и 100.
4.3 Влияние полносвязных слоев на модели сверточных нейронных сетей
Полносвязный слой (FC – fully connected) связан с термином плотный слой (dense). Плотный слой – слой, в котором все искусственные нейроны могут получать информацию от предыдущего слоя с искусственными нейронами (сеть имеет полный набор связей). Данные слои нелинейно рекомбинируют информацию, которая получена от предыдущего слоя.
В реализованных моделях использовались два или три плотных слоя. Первые слои являются компонентом извлечения признаков, а последний слой классификатором.
Для модели VGG16 было необходимо три плотных слоя. В первом слое глубина должна быть высокой, т. е. количество искусственных нейронов должно быть большим, например 4096 или 2048. Во втором слое количество искусственных нейронов должно быть гораздо меньше, при исследовании было выявлено количество 256 или 128 нейронов, которые давали оптимальные результаты. На последнем третьем плотном слое количество искусственных нейронов должно быть равно двум. Для модели VGG19 все аналогично, только оптимальными параметрами на первом слоя является 4096, на втором – 256, на третьем – 2.
В модели InceptionV3 также три плотных слоя. Первый слой не должен быть глубоким, поэтому оптимальные значения были: для первого слоя 64 искусственных нейрона, для второго – 64 нейрона, для третьего 1.
Для модели Xception требовалось всего два плотных слоя. Первый слой содержал 512 искусственных нейронов, а второй – 2.
В модели ResNet34 три плотных слоя. Первый слой содержит 1024 искусственных нейрона, второй – 512, третий - 2. Данные числа не подвергались изменению, потому что модель давала результаты точности свыше 0.98. Модель ResNet34 отличается от других моделей, потому что реализована на библиотеке PyTorch, а не на TensorFlow, поэтому на третьем слое видны отличия в количестве искусственных нейронов (нет явного класса бинарный, категориальный).
4.4 Использование оптимизатора для оценки моделей сверточных нейронных сетей
Функции стоимости или функции потерь производят оценку, насколько истинные значение ӯ равно полученному значению y (рисунок 59), то есть насколько ошибочен прогноз. Существует метрика loss (функция потерь), с помощью которой можно отслеживать ошибки сети.
Оптимизаторами являются методы стохастического градиентного спуска (SGD) и обратного распространения ошибки, а объединение данных методов является ведущим подходом в минимизации потерь в глубоком обучении нейронных сетей .
В таблице 2 представлены оптимизаторы, которые являются стандартными для библиотек TensorFlow и PyTorch.

Для исследования были применены все данные оптимизаторы (реализация всех оптимизаторов есть в двух библиотеках), однако в документации к библиотекам приведенные выше оптимизаторы предоставлены в ограниченном количестве (Таблица 2).
В таблице 3 приведены названия моделей и оптимизаторов, с помощью которых модели сверточных нейронных сетей показали оптимальные результаты по данному исследованию.

Скорость обучения является гиперпараметром, который показывает, насколько быстро происходит обучение модели. Оптимальные значения скорости обучения от 0,1 до 0,001 (данные значения можно применять на этапах обучения моделей). В случае, когда значение при обучении будет слишком большим, то оптимизатор не будет замечать важные параметры, т. е. действовать хаотично. Если значение при обучении будет слишком маленьким, то затраты времени на обучение будут увеличены.
В данном исследовании к оптимизаторам были применены различные скорости обучения. Для моделей VGG16, VGG19, InceptionV3, Xception оптимальной была скорость обучения 0,001, а для модели ResNet34 – 0,0001.
Также для модели ResNet34 с оптимизатором SGD был применен параметр momentum (импульс), который ускоряет векторы градиентов. Диапазон параметра от 0 до 1. Для данного оптимизатора хорошие результаты исследования были как при 0 значении импульса, так и при значении 0,9.
4.5 Размерность изображения как критерий оценки эффективности разработанной системы
Для каждой модели сверточной нейронной сети в документации был прописан входной размер пикселей (размерность изображений). Модели VGG16, VGG19, ResNet34 имели входную размерность 224х224, а InceptionV3 и Xception – 299х299. Данная размерность является размерностью, при которой модели были разработаны с сочетанием параметров, дающих высокую точность оценки эффективности системы. Однако, для исследования данный параметр размерности был изменяемым.
Для модели VGG16 были применены входные размерности пикселей (128х128, 224х224, 320х320). Оптимальными размерностями были 224х224 и 320х320. Для данной модели удалось подобрать параметры, которые при увеличении размерности давали бы результаты с высокой точностью классификации. К модели VGG19 также были применены различные размерности, хорошие результаты исследования давали размерности 224х224 и 320х320, однако высокая точность классификации проявлялась при размерности 224х224. На данном этапе исключилась размерность 128х128.
Для модели ResNet34 оптимальной размерностью была 224х224, а при 320х320 модель давала плохие результаты. В InceptionV3 по ошибке было принято считать базовой размерностью 224х224, а не 299х299, поэтому в данной модели входные размерности были 224х224 и 320х320. Оптимальной размерностью была 224х224, а для модели Xception - 299х299.
4.6 Выводы с результатами исследований разработанной системы
В данном исследовании было проведено около 400 испытаний. По каждой модели был выделен ряд гиперпараметров, категорий, с помощью которых были достигнуты высокие результаты классификации сверточных нейронных сетей (Таблица 4).
Таблица 4 – Категории высокой точности классификации
Название модели | Глубина на слоях | Оптимизатор | Скорость обучения | Размерность изображения | Функция активации на выходном слое | Размерность пакетов | Количество эпох |
VGG16 | 2048/128/2 4096/256/2 | Adam | 0,001 | 224х224 | Softmax | 32 64 128 | От 10 До 20 |
VGG19 | 4096/256/2 4096/128/2 2048/128/2 2048/256/2 | Adam | 0,001 | 224x224 | Softmax Sigmoid | 32 64 128 | 15 |
InceptionV3 | 64/64/1 1024/128/1 | Adamax Adam Nadam | 0,001 | 224x224 | Sigmoid | 32 | 10 20 |
ResNet34 | 1024/512/2 | Adam SGD Adamax | 0,0001 | 224x224 | - | 50 75 100 | 10 |
Xception | 512/2 | Adam | 0,001 | 299x299 | Softmax | 20 32 | 10 |
F1Score стала метрикой, определяющей точность классификации всех моделей в исследовании, поэтому в таблице 5 представлен рейтинг моделей по результатам испытаний.
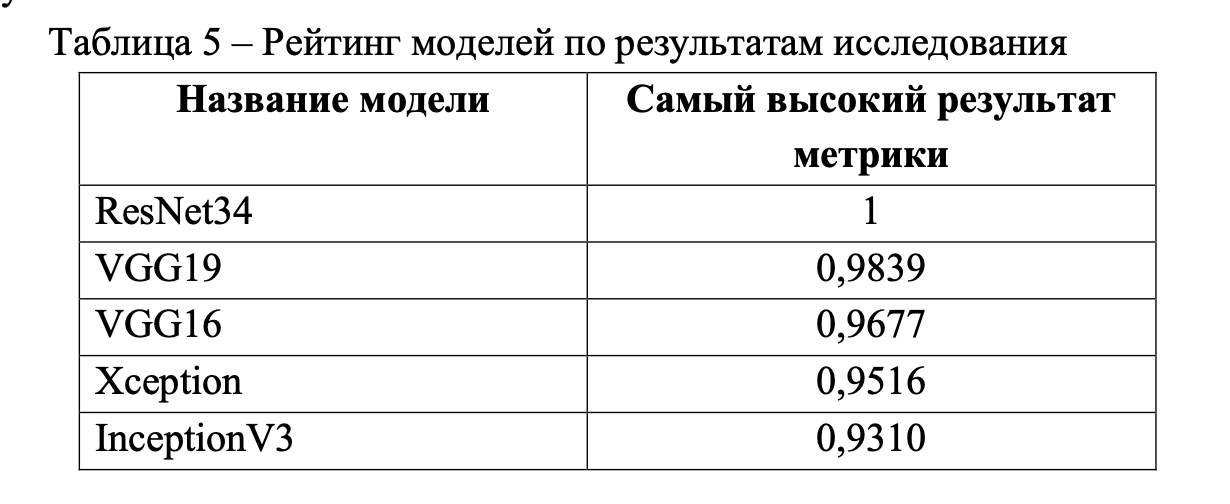
Для каждой модели были отобраны три примера из всей совокупности примеров по результатам точности метрики на последней эпохе и динамике результатов метрики на графике (тестовая выборка). Модели с данными представлены в таблицах 6–10. К каждому номеру примера предоставлены графики метрик, однако определяющая метрика F1Score и функция потерь loss. На графиках красным цветом отмечена линия обучающей выборки (Training), а синим – тестовой (Validation).
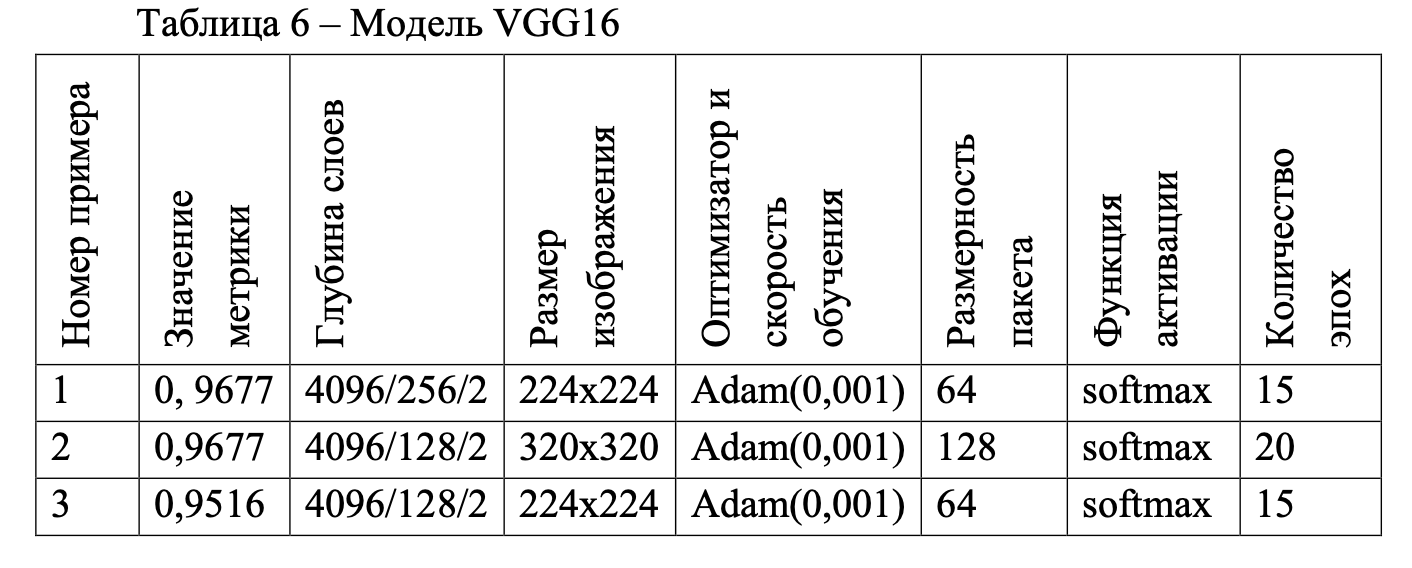
На рисунках 60–62 представлены графики по порядку номера примера в таблице 6.




На рисунках 63–65 представлены графики по порядку номера примера в таблице 7.



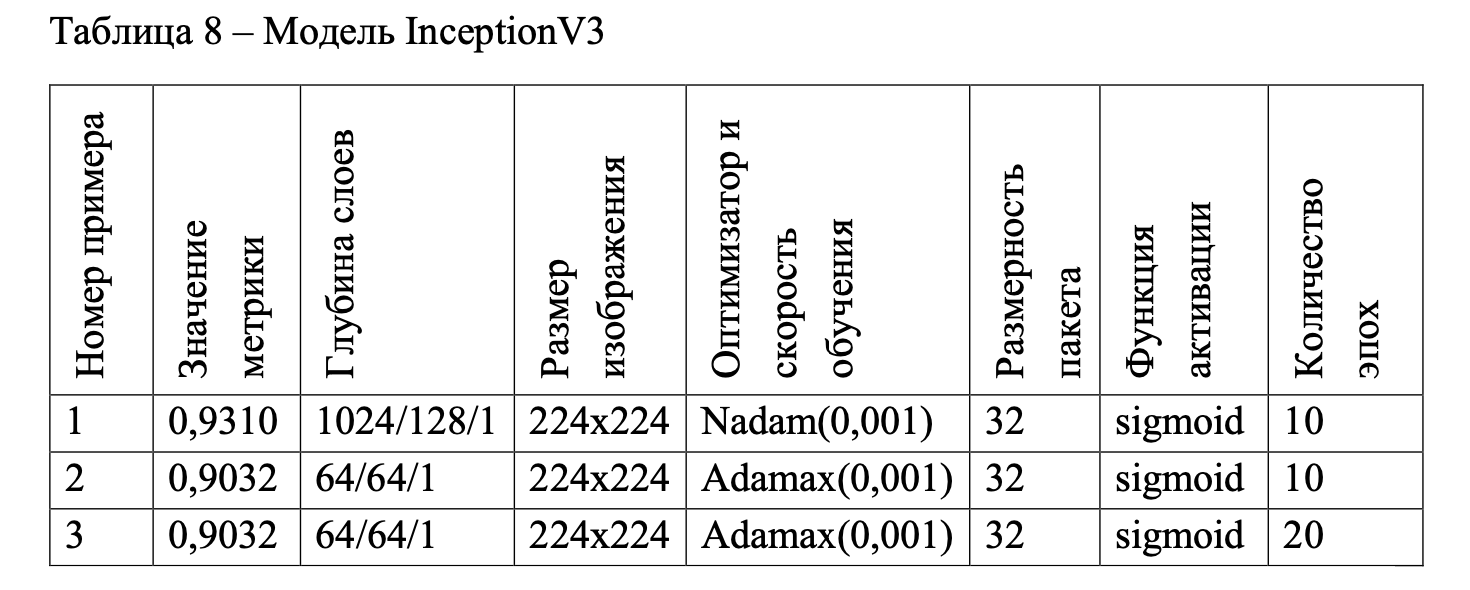
На рисунках 66–68 представлены графики по порядку номера примера в таблице 8.



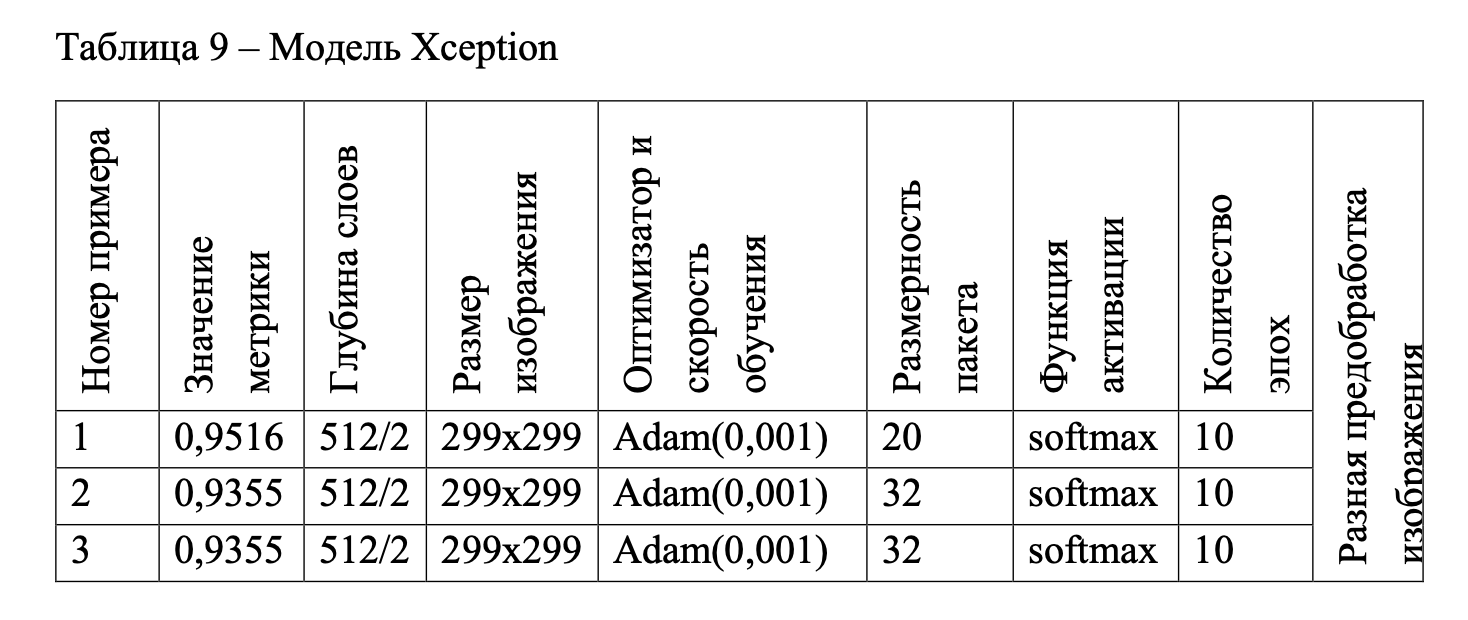
Для модели Xception дополнительно изменялась предобработка изображения. Для первого значения метрики в таблице 9 предобработка изображения была (rescale= 1. /255, horizontal_flip = True, fill_mode = «nearest», shear_range = 0.1, zoom_range = 0.2, rotation_range=3, width_shift_range = 0.1, height_shift_range = 0.1) , для второго значения такие же параметры, однако размерность пакета 32 вместо 20, а для третьего значения предобработка только (rescale= 1. /255, horizontal_flip = True) с размерностью пакета 32.
На рисунках 69–71 представлены графики по порядку номера примера в таблице 9.

Разная предобработка изображения


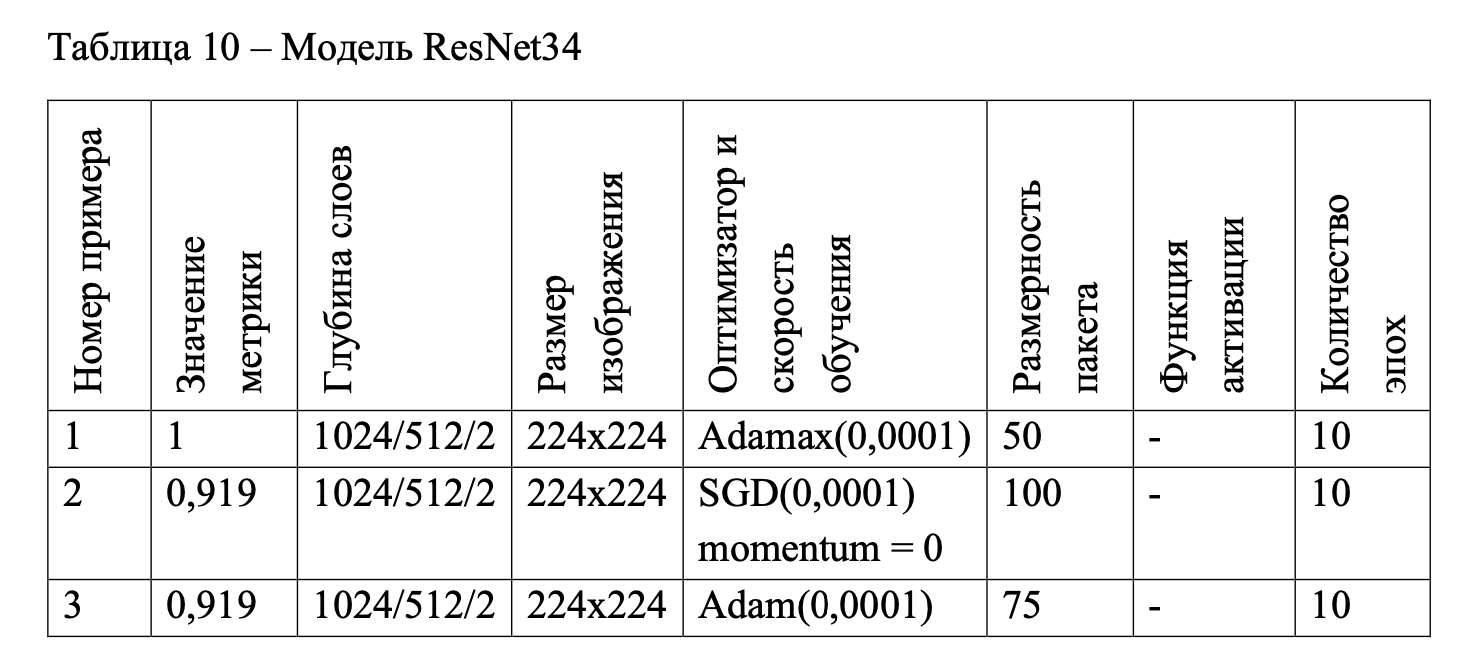
На рисунках 73, 75, 77 представлены графики по порядку номера примера в таблице 10. Также приведены этапы обучения данных примеров, так как реализация модели ResNet34 отличалась от других ранее приведенных моделей, были реализованы только метрики F1Score и Accuracy, поэтому с функцией потерь loss можно ознакомиться на рисунках обучения 72, 74, 76.






Наилучший результат показала модель ResNet34 с точностью 1, далее по убыванию представлены точности других моделей: VGG19 - 0,9839, VGG16 - 0,9677, Xception - 0,9516, InceptionV3 - 0,9310.
Самое интересное это код
VGG16/VGG19
from google.colab import
drive drive.mount('/content/drive')
!pip install tensorflow-addons import tensorflow_addons as tfa import tensorflow as tf
from tensorflow import keras import numpy as np
import os
import pandas as pd
import matplotlib.pyplot as plt import seaborn as sns
from tensorflow.keras.applications.vgg16 import VGG16, preprocess_input
from tensorflow.keras.applications.vgg19 import VGG19
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import SGD, Adam,Adadelta,Adagrad,Adamax,Nadam,Ftrl from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.metrics import Precision, Recall
from tensorflow_addons.metrics import F1Score
from keras.models import Model
from keras.layers import Flatten, Dense, GlobalAveragePooling2D import glob
train_path = "/content/drive/MyDrive/Данные/train/"
test_path = "/content/drive/MyDrive/Данные/test/"
norma_train_set = (glob.glob(f"{train_path}/Норма/*.png"))
print(f"{len(norma_train_set)}")
norma_test_set = (glob.glob(f"{test_path}/Норма/*.png"))
print(f"{len(norma_test_set)}")
deviation_train_set = (glob.glob(f"/content/drive/MyDrive/Данные/train/{'Отклонение '}/*.png"))
print(f"{len(deviation_train_set)}")
deviation_test_set = (glob.glob(f"/content/drive/MyDrive/Данные/test/Отклонение/*.png"))
print(f"{len(deviation_test_set)}")
class_name = {0:"norma", 1:"deviation"}
X_train = pd.DataFrame(columns=["path", "target"])
for path in deviation_train_set:
s = pd.Series([path, 1], index=["path", "target"])
X_train = X_train.append(s, ignore_index=True)
for path in norma_train_set:
s = pd.Series([path, 0], index=["path", "target"])
X_train = X_train.append(s, ignore_index=True) print(X_train)
class_name2 = {0:"norma", 1:"deviation"}
Y_test = pd.DataFrame(columns=["path", "target"])
for path in deviation_test_set:
s = pd.Series([path, 1], index=["path", "target"])
Y_test = Y_test.append(s, ignore_index=True)
for path in norma_test_set:
s = pd.Series([path, 0], index=["path", "target"])
Y_test = Y_test.append(s, ignore_index=True) print(Y_test)
from keras.preprocessing.image import load_img
import random
num = random.randint(0, len(X_train.index))
img = load_img(X_train["path"][num], target_size=(224,224))
plt.axis("off")
plt.title(class_name[X_train["target"][num]])
plt.imshow(img)
from keras.preprocessing.image import load_img
import random
num = random.randint(0, len(Y_test.index))
img = load_img(X_train["path"][num], target_size=(224,224))
plt.axis("off")
plt.title(class_name[Y_test["target"][num]])
print(plt.imshow(img))
print(X_train.shape)
print(Y_test.shape)
X_train["target"] = [str(val) for val in X_train["target"]]
Y_test["target"] = [str(val) for val in Y_test["target"]]
X_train.shape, Y_test.shape
batch_size, target_size = 128, (320,320)
train_datagen = ImageDataGenerator(preprocessing_function=preprocess_input)
test_datagen = ImageDataGenerator(preprocessing_function=preprocess_input)
train_generator = train_datagen.flow_from_dataframe(dataframe=X_train,x_col="path",y_col="target",target_size=target_size,batch_size=batch_si ze,class_mode='categorical')
test_generator = test_datagen.flow_from_dataframe(dataframe=Y_test,x_col="path",y_col="target",target_size=target_size,batch_size=batch_size ,class_mode='categorical',shuffle=False)
#ВЫБРАТЬ МОДЕЛЬ
vgg = VGG16(include_top=False, input_shape=(224,224,3))
vgg.trainable = False
vgg.summary(), vgg.layers
#ВЫБРАТЬ МОДЕЛЬ
vgg = VGG19(include_top=False, input_shape=(320,320,3))
vgg.trainable = False
vgg.summary(), vgg.layers
METRICS = [
keras.metrics.TruePositives(name='tp'), keras.metrics.FalsePositives(name='fp'), keras.metrics.TrueNegatives(name='tn'), keras.metrics.FalseNegatives(name='fn'),
keras.metrics.BinaryAccuracy(name='accuracy'),
keras.metrics.Precision(name='precision'),
keras.metrics.Recall(name='recall'),
keras.metrics.AUC(name='auc'),
tfa.metrics.F1Score(num_classes=2, average="micro", threshold = 0.5,name = 'F1Score'), tfa.metrics.FBetaScore(num_classes=2, average="micro", threshold = 0.5,name = 'FBetaScore'),
]
from keras.layers import Dropout
for l in vgg.layers:
l.trainable = False
x = GlobalAveragePooling2D()(vgg.output) x = Dense(units=4096, activation="relu")(x)
x = Dense(units=256, activation="relu")(x)
x = Dense(units=2, activation="softmax")(x)
cnn = Model(inputs=vgg.input, outputs=x)
cnn.compile(optimizer = tf.keras.optimizers.Adam(learning_rate=0.001), loss = 'categorical_crossentropy', metrics = [METRICS])
cnn.summary()
#для 16 слоев модели
#model_dir = "content/drive/MyDrive/Данные/"
#file_name = "deviation_norma_vgg16-best-model"
#modelfile = f"{model_dir}/{file_name}.h5"
#logfile = f"{model_dir}/{file_name}_training.log"
#if not os.path.exists(model_dir):
#os.makedirs(model_dir) #для 19 слоев модели
model_dir = "content/drive/MyDrive/Данные/"
file_name = "deviation_norma_vgg19-best-model"
modelfile = f"{model_dir}/{file_name}.h5"
logfile = f"{model_dir}/{file_name}_training1.log"
if not os.path.exists(model_dir):
os.makedirs(model_dir)
model_chpo = keras.callbacks.ModelCheckpoint(modelfile)
csv_logger = keras.callbacks.CSVLogger(logfile)
callbacks_list = [model_chpo,csv_logger]
epochs = 15
cnn.fit(train_generator,
epochs=epochs, validation_data=test_generator, batch_size=batch_size, callbacks=callbacks_list)
def plot_accuracy_loss(file_name):
import pandas as pd
log_data = pd.read_csv(file_name) acc = log_data['accuracy']
val_acc = log_data['val_accuracy'] loss = log_data['loss']
val_loss = log_data['val_loss'] import matplotlib.pyplot as plt plt.style.use('ggplot') plt.figure(figsize=(16, 8)) plt.subplot(1, 2, 1)
plt.plot(log_data['epoch'], acc, label='Training Accuracy') plt.plot(log_data['epoch'], val_acc, label='Validation Accuracy') plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(log_data['epoch'], loss, label='Training Loss') plt.plot(log_data['epoch'], val_loss, label='Validation Loss') plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
return plt.show()
plot_accuracy_loss(logfile)
def plot_f1(file_name):
import pandas as pd
log_data = pd.read_csv(file_name)
F1Score = log_data['F1Score']
val_F1Score = log_data['val_F1Score']
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.figure(figsize=(18, 10))
plt.subplot(1, 2, 1)
plt.plot(log_data['epoch'], F1Score, label='Training F1Score') plt.plot(log_data['epoch'], val_F1Score, label='Validation F1Score') plt.legend(loc='lower right')
plt.title('Training and Validation F1Score')
return plt.show()
plot_f1(logfile)
def plot_recallandPrecision(file_name):
import pandas as pd
log_data = pd.read_csv(file_name)
Recall = log_data['recall']
val_Recall = log_data['val_recall']
Precision = log_data['precision']
val_Precision = log_data['val_precision']
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plt.plot(log_data['epoch'], Recall, label='Training Recall') plt.plot(log_data['epoch'], val_Recall, label='Validation Recall') plt.legend(loc='lower right')
plt.title('Training and Validation Recall')
plt.subplot(1, 2, 2)
plt.plot(log_data['epoch'], Precision, label='Training Precision') plt.plot(log_data['epoch'], val_Precision, label='Validation Precision') plt.legend(loc='lower right')
plt.title('Training and Validation Precision')
return plt.show()
plot_recallandPrecision(logfile)
def plot_AUC(file_name):
import pandas as pd
log_data = pd.read_csv(file_name) AUC = log_data['auc']
val_AUC = log_data['val_auc']
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plt.plot(log_data['epoch'], AUC, label='Training AUC') plt.plot(log_data['epoch'], val_AUC, label='Validation AUC') plt.legend(loc='lower right')
plt.title('Training and Validation AUC')
return plt.show()
plot_AUC(logfile)ResNet34
from google.colab import drive
drive.mount('/content/drive/')
import torch
import torch.nn as nn
import torchvision
import os
import numpy as np
import shutil
import random
import torch.nn.functional as F import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data import Dataset
from torchvision import transforms, datasets, models import torchvision.models as models
import tensorflow as tf
import time
from functools import partial
from dataclasses import dataclass
from collections import OrderedDict
from sklearn.metrics import f1_score
import matplotlib.pyplot as plt
from termcolor import colored, cprint
random_state = 1
torch.manual_seed (random_state)
torch.cuda.manual_seed(random_state)
torch.cuda.manual_seed_all(random_state)
np.random.seed(random_state)
batch_size = 50
num_workers = 2
use_gpu = torch.cuda.is_available()
PATH='/content/drive/MyDrive/model.pt'
data_transform = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
train_dataset = datasets.ImageFolder(root='/content/drive/MyDrive/Данные/train/', transform=data_transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size,
shuffle=True, num_workers=num_workers)
test_dataset = datasets.ImageFolder(root='/content/drive/MyDrive/Данные/test/', transform=data_transform)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers) len(test_loader)
len(train_loader)
print(train_loader)
print(test_loader)
print(train_dataset)
print(len(train_dataset))
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) self.maxpool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 53 * 53, 1024) self.fc2 = nn.Linear(1024, 512)
self.fc3 = nn.Linear(512, 2)
def forward(self, x):
x = self.maxpool(F.relu(self.conv1(x))) x = self.maxpool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 53 * 53)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x)) x = self.fc3(x)
return x
net = torchvision.models.resnet34(3,2)
if use_gpu:
net = net.cuda()
cirterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.0001, momentum=0.0) epochs = 10
f1_score_train_list = [0,]
f1_score_test_list = [0,]
acc_list = [0,]
loss_list =[0,]
def train():
for epoch in range(epochs):
running_loss = 0.0
train_correct = 0
train_total = 0
f1_score_train = 0
#print(len(train_loader))
for i, data in enumerate(train_loader, 0):
inputs, train_labels = data
if use_gpu:
inputs, labels = Variable(inputs.cuda()), Variable(train_labels.cuda())
else:
inputs, labels = Variable(inputs), Variable(train_labels)
optimizer.zero_grad()
outputs = net(inputs)
_, train_predicted = torch.max(outputs.data, 1) train_correct += (train_predicted == labels.data).sum()
loss = cirterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_total += train_labels.size(0)
f1_score_train = f1_score(labels.cpu().data, train_predicted.cpu(),average='micro')
f1_score_train_list.append(round(f1_score_train,3)) correct = 0
test_loss = 0.0
test_total = 0
test_total = 0
f1_score_test = 0
net.eval()
for data in test_loader:
images, labels = data
if use_gpu:
images, labels = Variable(images.cuda()), Variable(labels.cuda())
else:
images, labels = Variable(images), Variable(labels)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
loss = cirterion(outputs, labels)
test_loss += loss.item()
test_total += labels.size(0)
correct += (predicted == labels.data).sum()
f1_score_test = f1_score(labels.cpu().data, predicted.cpu(),average='micro')
f1_score_test_list.append(round(f1_score_test,3))
loss_list.append(round(test_loss / test_total,3))
acc_list.append(round(float(100 * correct / test_total),3))
print(colored('epoch %d loss: %.3f acc: %.3f ','red',attrs=['underline']) % (epoch + 1, test_loss / test_total, 100 * correct /
test_total))
print(colored("f1_score_train: %.3f f1_score_test: %.3f ",'blue',attrs=['underline']) % (f1_score_train,f1_score_test)) torch.save(net, '/content/drive/MyDrive/Данные/resnet34_256.pt')
train()
import matplotlib.pyplot as plt
plt.style.use('ggplot')
fig,ax = plt.subplots(1,2,figsize=(18,9))
ax[0].plot(f1_score_train_list)
ax[0].set_title('f1_score')
ax[0].plot(f1_score_test_list)
ax[0].legend(['Training F1Score', 'Validation F1Score'],loc='lower right') ax[1].plot(acc_list)
ax[1].set_title('Accuracy')
ax[1].legend(['Accuracy'],loc='lower right')
plt.show()InceptionV3
from google.colab import drive
drive.mount('/content/drive')
import os
!pip install tensorflow-addons import tensorflow_addons as tfa import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator from tensorflow.keras import layers
from tensorflow.keras import Model
import matplotlib.pyplot as plt
from tensorflow.keras.optimizers import SGD, Adam,Adadelta,Adagrad,Adamax,Nadam,Ftrl
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.metrics import Precision, Recall
from tensorflow_addons.metrics import F1Score
from tensorflow import keras
train_datagen = ImageDataGenerator(rescale = 1./255., rotation_range = 40, width_shift_range = 0.2, height_shift_range = 0.2,shear_range = 0.2, zoom_range = 0.2, horizontal_flip = True)
test_datagen = ImageDataGenerator(rescale = 1./255.)
train_generator = train_datagen.flow_from_directory('/content/drive/MyDrive/Данные/train/',batch_size=32 , class_mode = 'binary', target_size = (224, 224))
validation_generator = test_datagen.flow_from_directory('/content/drive/MyDrive/Данные/test/', batch_size=32,class_mode = 'binary', target_size = (224, 224))
from tensorflow.keras.applications.inception_v3 import InceptionV3
base_model = InceptionV3(input_shape = (224, 224, 3), include_top = False)
base_model.trainable = False
METRICS = [
keras.metrics.TruePositives(name='tp'),
keras.metrics.FalsePositives(name='fp'),
keras.metrics.TrueNegatives(name='tn'),
keras.metrics.FalseNegatives(name='fn'),
keras.metrics.BinaryAccuracy(name='accuracy'),
keras.metrics.Precision(name='precision'),
keras.metrics.Recall(name='recall'),
keras.metrics.AUC(name='auc'),
tfa.metrics.F1Score(num_classes=2, average="micro", threshold = 0.5,name = 'F1Score'), tfa.metrics.FBetaScore(num_classes=2, average="micro", threshold = 0.5,name = 'FBetaScore'),
]
for layer in base_model.layers:
layer.trainable = False
x = layers.Flatten()(base_model.output)
x = layers.Dense(64, activation='relu')(x)
x = layers.Dropout(0.5)(x)
x = layers.Dense(64, activation='relu')(x)
x = layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.models.Model(base_model.input, x)
model.compile(optimizer = Adamax(learning_rate=0.001), loss = 'binary_crossentropy', metrics = [METRICS])
model_dir = "content/drive/MyDrive/Данные/"
file_name = "deviation_norma_inception-best-model"
modelfile = f"{model_dir}/{file_name}.h5"
logfile = f"{model_dir}/{file_name}_training2.log"
if not os.path.exists(model_dir):
os.makedirs(model_dir)
model_chpo = keras.callbacks.ModelCheckpoint(modelfile)
csv_logger = keras.callbacks.CSVLogger(logfile)
callbacks_list = [model_chpo,csv_logger]
inc_history = model.fit(train_generator, validation_data = validation_generator,batch_size=32,epochs =20 ,callbacks=callbacks_list)
def plot_accuracy_loss(file_name):
import pandas as pd
log_data = pd.read_csv(file_name)
acc = log_data['accuracy']
val_acc = log_data['val_accuracy']
loss = log_data['loss']
val_loss = log_data['val_loss']
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plt.plot(log_data['epoch'], acc, label='Training Accuracy')
plt.plot(log_data['epoch'], val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(log_data['epoch'], loss, label='Training Loss')
plt.plot(log_data['epoch'], val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
return plt.show()
plot_accuracy_loss(logfile)
def plot_f1(file_name):
import pandas as pd
log_data = pd.read_csv(file_name)
F1Score = log_data['F1Score']
val_F1Score = log_data['val_F1Score']
import matplotlib.pyplot as plt plt.style.use('ggplot')
plt.figure(figsize=(18, 10))
plt.subplot(1, 2, 1)
plt.plot(log_data['epoch'], F1Score, label='Training F1Score') plt.plot(log_data['epoch'], val_F1Score, label='Validation F1Score') plt.legend(loc='lower right')
plt.title('Training and Validation F1Score')
return plt.show()
plot_f1(logfile)
def plot_recallandPrecision(file_name):
import pandas as pd
log_data = pd.read_csv(file_name)
Recall = log_data['recall']
val_Recall = log_data['val_recall']
Precision = log_data['precision']
val_Precision = log_data['val_precision']
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plt.plot(log_data['epoch'], Recall, label='Training Recall')
plt.plot(log_data['epoch'], val_Recall, label='Validation Recall') plt.legend(loc='lower right')
plt.title('Training and Validation Recall')
plt.subplot(1, 2, 2)
plt.plot(log_data['epoch'], Precision, label='Training Precision') plt.plot(log_data['epoch'], val_Precision, label='Validation Precision') plt.legend(loc='lower right')
plt.title('Training and Validation Precision')
return plt.show()
plot_recallandPrecision(logfile)
def plot_AUC(file_name):
import pandas as pd
log_data = pd.read_csv(file_name)
AUC = log_data['auc']
val_AUC = log_data['val_auc']
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plt.plot(log_data['epoch'], AUC, label='Training AUC')
plt.plot(log_data['epoch'], val_AUC, label='Validation AUC')
plt.legend(loc='lower right')
plt.title('Training and Validation AUC')
return plt.show()
plot_AUC(logfile)Xception
from google.colab import drive
drive.mount('/content/drive/')
import os
!pip install tensorflow-addons import tensorflow_addons as tfa import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator from tensorflow.keras import layers
from tensorflow.keras import Model
import matplotlib.pyplot as plt
from tensorflow.keras.optimizers import SGD, Adam,Adadelta,Adagrad,Adamax,Nadam,Ftrl
# Оптимизатор RMSprop ограничивает колебания в вертикальном направлении
from tensorflow.keras.optimizers import RMSprop
# метрики
from tensorflow.keras.metrics import Precision, Recall
from tensorflow_addons.metrics import F1Score
from tensorflow import keras
from tensorflow.keras.applications import Xception
train_datagen = ImageDataGenerator(rotation_range=3,width_shift_range=0.1,height_shift_range=0.1,rescale=1./255,shear_range=0.1,zoom_ran ge=0.2,horizontal_flip=True,fill_mode='nearest')
test_datagen = ImageDataGenerator(rotation_range=3,width_shift_range=0.1,height_shift_range=0.1,rescale=1./255,shear_range=0.1,zoom_ran ge=0.2,horizontal_flip=True,fill_mode='nearest')
train_generator = train_datagen.flow_from_directory('/content/drive/MyDrive/Данные/train/' ,batch_size=32,class_mode='categorical', target_size = (299, 299))
validation_generator = test_datagen.flow_from_directory('/content/drive/MyDrive/Данные/test/',batch_size=32,class_mode='categorical', target_size = (299, 299))
base_model = Xception(input_shape = (299, 299, 3), include_top = False)
base_model.trainable = False
METRICS = [
keras.metrics.TruePositives(name='tp'), keras.metrics.FalsePositives(name='fp'), keras.metrics.TrueNegatives(name='tn'),
keras.metrics.FalseNegatives(name='fn'),
keras.metrics.BinaryAccuracy(name='accuracy'),
keras.metrics.Precision(name='precision'),
keras.metrics.Recall(name='recall'),
keras.metrics.AUC(name='auc'),
tfa.metrics.F1Score(num_classes=2, average="micro", threshold = 0.5,name = 'F1Score'), tfa.metrics.FBetaScore(num_classes=2, average="micro", threshold = 0.5,name = 'FBetaScore'),
]
from keras import optimizers, callbacks, regularizers
for l in base_model.layers:
l.trainable = False
x = layers.GlobalAveragePooling2D()(base_model.output)
x = layers.Dense(512, activation='relu')(x)
x = layers.Dense(2, activation='softmax')(x)
model = tf.keras.models.Model(base_model.input, x)
model.compile(optimizer=Adam(learning_rate=0.001),loss = 'categorical_crossentropy', metrics = [METRICS])
model_dir = "content/drive/MyDrive/Данные/"
file_name = "deviation_norma_xception-model"
modelfile = f"{model_dir}/{file_name}.h5"
logfile = f"{model_dir}/{file_name}_training4.log"
if not os.path.exists(model_dir):
os.makedirs(model_dir)
model_chpo = keras.callbacks.ModelCheckpoint(modelfile) #save_best_only=True) csv_logger = keras.callbacks.CSVLogger(logfile)
callbacks_list = [model_chpo,csv_logger]
inc_history = model.fit(train_generator, validation_data = validation_generator,epochs =10
,batch_size=32,callbacks=callbacks_list)
def plot_accuracy_loss(file_name):
import pandas as pd
log_data = pd.read_csv(file_name)
acc = log_data['accuracy']
val_acc = log_data['val_accuracy']
loss = log_data['loss']
val_loss = log_data['val_loss']
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plt.plot(log_data['epoch'], acc, label='Training Accuracy') plt.plot(log_data['epoch'], val_acc, label='Validation Accuracy') plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(log_data['epoch'], loss, label='Training Loss') plt.plot(log_data['epoch'], val_loss, label='Validation Loss') plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
return plt.show()
plot_accuracy_loss(logfile)
def plot_f1(file_name):
import pandas as pd
log_data = pd.read_csv(file_name)
F1Score = log_data['F1Score']
val_F1Score = log_data['val_F1Score']
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.figure(figsize=(18, 10))
plt.subplot(1, 2, 1)
plt.plot(log_data['epoch'], F1Score, label='Training F1Score') plt.plot(log_data['epoch'], val_F1Score, label='Validation F1Score') plt.legend(loc='lower right')
plt.title('Training and Validation F1Score')
return plt.show()
plot_f1(logfile)
def plot_recallandPrecision(file_name):
import pandas as pd
log_data = pd.read_csv(file_name)
Recall = log_data['recall']
val_Recall = log_data['val_recall']
Precision = log_data['precision']
val_Precision = log_data['val_precision']
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plt.plot(log_data['epoch'], Recall, label='Training Recall') plt.plot(log_data['epoch'], val_Recall, label='Validation Recall') plt.legend(loc='lower right')
plt.title('Training and Validation Recall')
plt.subplot(1, 2, 2)
plt.plot(log_data['epoch'], Precision, label='Training Precision') plt.plot(log_data['epoch'], val_Precision, label='Validation Precision') plt.legend(loc='lower right')
plt.title('Training and Validation Precision')
return plt.show()
plot_recallandPrecision(logfile)
def plot_AUC(file_name):
import pandas as pd
log_data = pd.read_csv(file_name)
AUC = log_data['auc']
val_AUC = log_data['val_auc']
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plt.plot(log_data['epoch'], AUC, label='Training AUC') plt.plot(log_data['epoch'], val_AUC, label='Validation AUC') plt.legend(loc='lower right')
plt.title('Training and Validation AUC')
return plt.show()
plot_AUC(logfile)


