
Работа по реализации компрессии WAL на разных уровнях предпринимались с самых ранних дней PostgreSQL. Некоторые из встроенных функций (wal_compression) доступны нам еще с 2016 года, и почти все инструменты резервного копирования, прежде чем помещать WAL в резервный репозиторий, выполняют его сжатие. И вот наконец настало время еще раз взглянуть на встроенный wal_compression, потому что PostgreSQL 15 есть что предложить нам. В комбинации с остальными значимыми улучшениями в архивировании WAL в PostgreSQL 15, которые мы рассматривали в предыдущих статьях (Новый модуль/библиотека WAL-архива в PostgreSQL 15 и Ускорение архивации WAL в PostgreSQL 15) мы можем добиться впечатляющих результатов.
Я не планирую рассматривать сжатие файлов сегментов WAL с помощью инструментов резервного копирования, потому что это все-таки нечто внешнее по отношению к PostgreSQL, так как это в первую очередь фича самих инструментов резервного копирования. Но даже если мы не используем никаких специализированных инструментов, мы все равно можем сжать файлы сегментов WAL в рамках процесса архивации, получив при этом очень хорошие результаты.
Давайте же разберемся, что именно PostgreSQL может предложить нам для сжатия WAL. Функция сжатия WAL внутри PostgreSQL срабатывает (если мы включим ее) при записи полных страниц в WAL, что может сэкономить много накладных расходов на ввод-вывод. Уменьшенный размер сегмента WAL дает дополнительные преимущества при репликации и резервном копировании, поскольку необходимо передавать меньше данных.
Что такое запись полных страниц?
Неопытные пользователи могут быть не в курсе, что такое «запись полных страниц» (full-page writes), ну а нам следует вспомнить, что PostgreSQL использует страницы размером 8 КБ.
postgres=# show block_size ;
block_size
------------
8192
(1 row)Но хост-машина может работать со страницами меньшего размера, скажем, 4КБ.
$ getconf PAGESIZE
4096В качестве «атомарной единицы» для операций чтения и записи PostgreSQL использует страницы размером 8 КБ. Но поскольку наша гипотетическая хост-машина имеет меньший размер страницы, она разделит страницу размером 8 КБ на две и будет рассматривать в качестве атомарных единиц уже страницы ОС. В случае внештатных ситуаций или сбоев это может вызвать проблему: одна часть страницы размером 8 КБ может быть сохранена, а другая часть может быть потеряна, поскольку хост-машина может не расценивать ее как часть исходного фрагмента. Обычно это называют «записью неполной страницы» (partial page writes) или «разорванными страницами» (torn pages).
С точки зрения базы данных такие «разорванные страницы» безусловно считаются повреждениями. Если вдруг появляется файл данных с разорванной страницей, то PostgreSQL теряет целостность страниц. Это проблема свойственна не только PostgreSQL; каждое программное обеспечение для работы с базами данных должно иметь какое-нибудь решение на этот случай. Например, MySQL/InnoDB решает эту проблему с помощью буфера двойной записи, откуда можно получить копию неповрежденной страницы при восстановлении. Подход PostgreSQL к этой проблеме немного отличается. PostgreSQL записывает копию полной страницы в WAL-журнал при первом же ее изменении после контрольной точки. Поскольку WAL часто синхронизируются, и PostgreSQL также может определить точку, к которой будет произведено восстановление, это вполне безопасное место для сохранения копии «полной страницы».
Снижение производительности из-за записи полных страниц
Как упоминалось выше, когда страница базы данных изменяется в первый раз после контрольной точки, она записывается в WAL в качестве надежной ссылки в целях обеспечения безопасности. Таким образом, во время аварийного восстановления PostgreSQL может безопасно применять непротиворечивые страницы из WAL-журналов. Но это, увы, не обходится без значительных последствий для производительности.
Несложно догадаться, что существует высокая вероятность слишком большого количества полностраничных записей сразу после контрольной точки. Это наглядно отражено в тестах производительности PostgreSQL в виде "Пилообразной кривой”, наблюдаемой Вадимом в своих тестах:
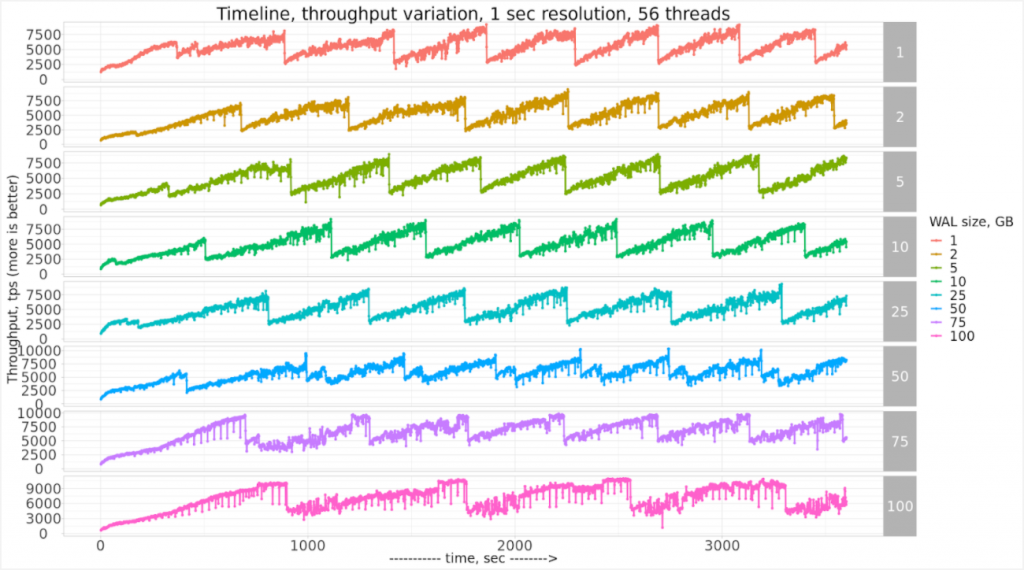
Как мы видим, после каждой контрольной точки производительность внезапно падает (из-за интенсивной записи в WAL) и постепенно восстанавливается ровно до следующей контрольной точки.
Компрессия полных страниц: последние улучшения
PostgreSQL 14 и старше
Полные страницы достаточно велики и хорошо заполнены данными, чтобы их сжатие перед записью в сегменты WAL имело смысл. Эта возможность появилась еще в PostgreSQL 9.5; он использует встроенную реализацию LZ-сжатия, часто называемую «pglz». Но она оказалась не слишком популярной из-за накладных расходов процессора. Так что это не лучшая практика с точки зрения оптимизации. Те пользователи, которые после анализа своей рабочей нагрузки все-таки решили задействовать сжатие полных страниц, могут просто включить параметр wal_compression (во всех поддерживаемых версиях PostgreSQL) и как суперпользователь просигнализировать об этом серверу.
ALTER SYSTEM SET wal_compression=ON;
SELECT pg_reload_conf();PostgreSQL 15+
Современные алгоритмы компрессии стали предлагать гораздо лучшее сжатие при меньшем количестве тактов процессора. Lz4 хороший тому пример. В PostgreSQL 15 тот же параметр wal_compression теперь может принимать значения pglz, lz4, и zstd, наряду со стандартными on и off, которые оставили в целях обратной совместимости. Логические эквивалентные значения, такие как on, true, yes и 1 эквивалентны «pglz».
В отличие от pglz, встроенного в библиотеку сжатия PostgreSQL, новые фичи возможности предоставляются внешними библиотеками. Поэтому они должны быть включены во время сборки с помощью флагов конфигурации –with-lz4 и –with-zstd для lz4 и zstd соответственно.
В официальных сборках из дистрибутива Percona эти флаги конфигурации включены уже в процессе сборки. Но пакеты/бинарники из других репозиториев или исходный код можно посмотреть, как показано ниже. Прежде чем пытаться что-то использовать, никогда не будет лишним сначала хотя бы взглянуть на это.
/usr/pgsql-15/bin/pg_config | grep "zstd|lz4"
CONFIGURE = '--enable-rpath' '--prefix=/usr/pgsql-15' '--includedir=/usr/pgsql-15/include' '--mandir=/usr/pgsql-15/share/man' '--datadir=/usr/pgsql-15/share' '--libdir=/usr/pgsql-15/lib' '--with-lz4' '--with-extra-version= - Percona Distribution' '--with-zstd' '--with-icu' '--with-llvm' '--with-perl' '--with-python' '--with-tcl' '--with-tclconfig=/usr/lib64' '--with-openssl' '--with-pam' '--with-gssapi' '--with-includes=/usr/include' '--with-libraries=/usr/lib64' '--enable-nls' '--enable-dtrace' '--with-uuid=e2fs' '--with-libxml' '--with-libxslt' '--with-ldap' '--with-selinux' '--with-systemd' '--with-system-tzdata=/usr/share/zoneinfo' '--sysconfdir=/etc/sysconfig/pgsql' '--docdir=/usr/pgsql-15/doc' '--htmldir=/usr/pgsql-15/doc/html' 'CFLAGS=-O2 -g -pipe -Wall -Werror=format-security -Wp,-D_FORTIFY_SOURCE=2 -Wp,-D_GLIBCXX_ASSERTIONS -fexceptions -fstack-protector-strong -grecord-gcc-switches -specs=/usr/lib/rpm/redhat/redhat-hardened-cc1 -specs=/usr/lib/rpm/redhat/redhat-annobin-cc1 -m64 -mtune=generic -fasynchronous-unwind-tables -fstack-clash-protection -fcf-protection' 'LDFLAGS=-Wl,--as-needed' 'LLVM_CONFIG=/usr/bin/llvm-config' 'CLANG=/usr/bin/clang' 'PKG_CONFIG_PATH=:/usr/lib64/pkgconfig:/usr/share/pkgconfig' 'PYTHON=/usr/bin/python3'
LIBS = -lpgcommon -lpgport -lselinux -lzstd -llz4 -lxslt -lxml2 -lpam -lssl -lcrypto -lgssapi_krb5 -lz -lreadline -lpthread -lrt -ldl -lmПочему мы сжимаем только полные страницы?
WAL-записи генерируются для каждого отдельного процесса, а показатель задержки очень важен для транзакций. Таким образом, скоординированные усилия по сжатию WAL-записей несколькими сеансами могут не принести большой пользы. Но есть такие области, как индексация или массовая загрузка данных, которые потенциально могут выиграть от сжатия WAL, если такая функция будет включена в будущем.
Краткий обзор вариантов сжатия
Когда речь идет о сжатии, автоматически встает вопрос об экономии на операциях ввода-вывода. Как мы знаем, сжатие происходит за счет повышения нагрузки на процессор. Моя цель — быстро проверить, будет ли какая-то видимая польза при уже и так высокой загрузке ЦП и есть ли какое-либо неблагоприятное (негативное) влияние на общий TPS.
При большом количестве полностраничных записей экономия существенная. Я также мог бы искусственно активировать контрольные точки, чтобы увидеть конечный эффект на общую генерацию WAL.
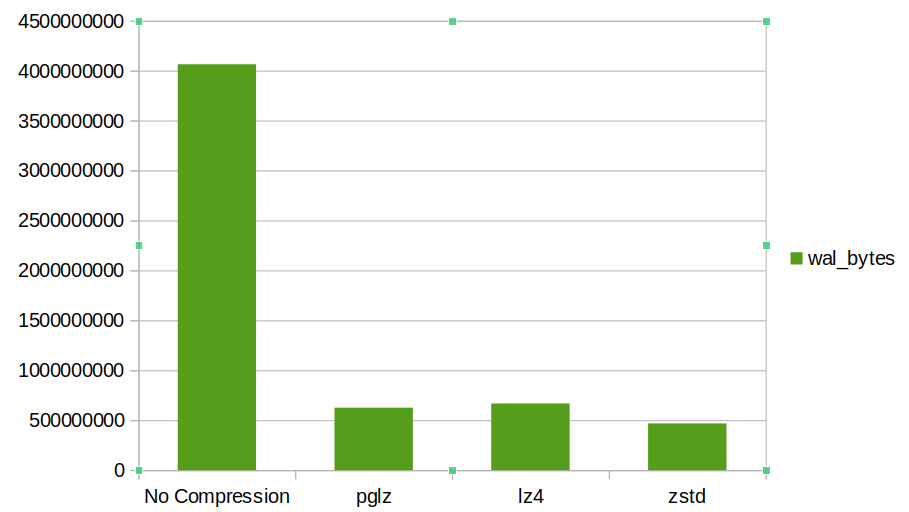
Lz4 дает сжатие, сравнимое с дефолтным pglz, при гораздо меньшей нагрузке на процессор. Zstd может обеспечить самое высокое сжатие (на 30% больше по сравнению с lz4).
В системе, которая уже находится на грани генерации слишком большого количества WAL, несжатый WAL может стать причиной гораздо большей частоты контрольных точек, что приведет к еще большей генерации WAL.
Заключение
Некоторые из ключевых моментов/выводов, к которым я пришел на основе обсуждения этой темы в сообществе, а также моих простых тестов:
Метод сжатия pglz, доступный в старой версии, был не очень эффективным. Он больше нагружает процессор и может оказать влияние на TPS для определенных рабочих нагрузок и конфигураций машины.
Современные библиотеки и алгоритмы сжатия просто превосходны. Они работают намного лучше, чем то, что было доступно в PostgreSQL (pglz) раньше.
Я не заметил никакого отрицательного влияния на TPS в моих простых тестах. Наоборот я наблюдал повышение пропускной способности на 10-15% при включенном сжатии, возможно, из-за меньшей задерки ввода-вывода.
Lz4-сжатие может быть лучшим выбором, если рабочая нагрузка базы ограничена возможностями процессора (CPU bound), потому что он мало нагружает процессор. Он способен обеспечить сжатие очень близкое к
pglzбез такой высокой нагрузки на процессор.Zstd можно выбрать, если сервера не ограничена мощностью процессора, потому что он может дать нам лучшее сжатие за счет большей нагрузки на процессор.
Косвенным преимуществом сжатия WAL является уменьшение вероятности возникновения контрольных точек из-за объема сгенерированных WAL (max_wal_size).
Фактическая польза от сжатия зависит от многих факторов: определенной частоты контрольных точек, вероятности запуска контрольных точек при генерации WAL, производительности хранилища, допустимой нагрузки на процессор, типа архитектуры процессора и многих другие факторов. С появлением этих новых опций входной барьер ощутимо снизился.
Слова предостережения
Если вы используете сжатие lz4 или zstd, убедитесь, что резервные бинарники PostgreSQL также поддерживают это. Это предупреждение в основном относится к пользователям, собирающим PostgreSQL из исходного кода.
Сегодня вечером в OTUS пройдет открытый урок, на котором глубоко погрузимся в тему резервного копирования и восстановления. Что разберем:
Задачи современных бэкапов.
Варианты бэкапов в PostgreSQL, классические и современные.
Практическое использование утилиты pg_probackup.
Также в эфире пройдет розыгрыш книги Евгения Аристова «PostgreSQL 14. Оптимизация, Kubernetes, кластера, облака». Присоединяйтесь! Записаться на открытый урок можно на странице онлайн-курса "PostgreSQL Cloud Solutions".




