
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Итак, представим. В комнате заперты 5 котов, и чтобы пойти разбудить хозяина им необходимо всем вместе договориться между собой об этом, ведь дверь они могут открыть только впятером навалившись на неё. Если один из котов – кот Шрёдингера, а остальные коты не знают о его решении, возникает вопрос: «Как они могут это сделать?»
В этой статье я простым языком расскажу вам о теоретической составляющей мира распределённых систем и принципах их работы. А также поверхностно рассмотрю главную идею, лежащую в основе Paxos'а.
Когда разработчики пользуются облачными инфраструктурами, различными базами данных, работают в кластерах из большого числа узлов, они уверены, что данные будут целостными, сохранными и всегда доступными. Но откуда гарантии?
По сути, гарантии, которые у нас есть – это гарантии поставщика. Они описаны в документации примерно следующим образом: «Этот сервис достаточно надёжный, у него есть заданный SLA, не беспокойтесь, всё будет распределённо работать, как вы и ожидаете».
Мы склонны верить в лучшее, ведь умные дяди из больших компаний заверили нас, что всё будет хорошо. Мы не задаёмся вопросом: а почему, собственно, это вообще может работать? Есть ли какое-то формальное обоснование корректности работы таких систем?
Недавно я ездил на школу по распределённым вычислениям и очень вдохновился этой темой. Лекции в школе больше напоминали занятия по математическому анализу, нежели нечто связанное с компьютерными системами. Но именно так в своё время и доказывались важнейшие алгоритмы, которыми мы пользуемся каждый день, сами того не подозревая.
В большинстве современных распределённых систем используется алгоритм консенсуса Paxos и его различные модификации. Самое крутое, что обоснованность и, в принципе, сама возможность существования этого алгоритма может быть доказана просто с помощью ручки и бумаги. При этом на практике алгоритм применяется в больших системах, работающих на огромном числе узлов в облаках.
Распределённая система – это группа компьютеров (далее будем называть их узлами), которые могут обмениваться сообщениями. Каждый отдельный узел – это некоторая автономная сущность. Узел может самостоятельно обрабатывать задачи, но чтобы взаимодействовать с другими узлами, ему нужно посылать и принимать сообщения.
Как конкретно реализованы сообщения, какие протоколы используются – это нас не интересует в данном контексте. Важно, что узлы распределённой системы могут обмениваться друг с другом данными путем отправки сообщений.
Само определение выглядит не очень сложным, но нужно учитывать, что у распределённой системы есть ряд атрибутов, которые будут важны для нас.
Синхронная модель – мы точно знаем, что есть конечная известная дельта времени, за которую сообщение гарантированно доходит от одного узла до другого. Если это время вышло, а сообщение не пришло, мы можем смело говорить, что узел вышел из строя. В такой модели мы имеем предсказуемое время ожидания.
Асинхронная модель – в асинхронных моделях мы считаем, что время ожидания конечно, но не существует такой дельты времени, после которой можно гарантировать, что узел вышел из строя. Т.е. время ожидания сообщения от узла может быть сколь угодно долгим. Это важное определение, и мы поговорим об этом дальше.
Прежде, чем формально определить понятие консенсуса, рассмотрим пример ситуации, когда он нам нужен, а именно – State Machine Replication.
У нас есть некоторый распределённый лог. Нам бы хотелось, чтобы он был консистентным и содержал идентичные данные на всех узлах распределённой системы. Когда какой-то из узлов узнает новое значение, которое он собирается записать в лог, его задачей становится предложить это значение всем остальным узлам, чтобы лог обновился на всех узлах, и система перешла в новое консистентное состояние. При этом важно, чтобы узлы договорились между собой: все узлы согласились, что предложенное новое значение корректно, все узлы это значение приняли, и только в этом случае все могут записать в лог новое значение.
Иными словами: никто из узлов не возразил, что у него есть более актуальная информация, а предлагаемое значение неверное. Договоренность между узлами и согласие о едином верном принятом значении и есть консенсус в распределённой системе. Далее мы будем говорить об алгоритмах, которые позволяют распределённой системе гарантированно достигать консенсус.

Более формально мы можем определить алгоритм достижения консенсуса (или просто алгоритм консенсуса), как некоторую функцию, которая переводит распределённую систему из состояния А в состояние Б. Причем это состояние принято всеми узлами, и все узлы могут его подтвердить. Как выясняется, эта задача совсем не такая тривиальная, как кажется на первый взгляд.
Алгоритм консенсуса должен обладать тремя свойствами, чтобы система продолжала существовать и имела какой-то прогресс в переходе из состояния в состояние:
Пока свойства алгоритма могут быть не совсем понятны. Поэтому проиллюстрируем на примере, какие стадии проходит простейший алгоритм консенсуса в системе с синхронной моделью обмена сообщениями, у которой все узлы функционируют как положено, сообщения не теряются и ничего не ломается (неужели такое и правда случается?).
Таким образом алгоритм консенсуса в простом случае состоит из четырёх шагов: propose, голосование (voting), принятие (accept), подтверждение принятия (accepted).
Если на каком-то шаге мы не смогли достичь согласия, то алгоритм запускается заново, с учётом той информации, которую предоставят узлы, отказавшиеся подтверждать предлагаемое значение.
До этого всё было гладко, ведь речь шла про синхронную модель обмена сообщениями. Но мы-то знаем, что в современном мире мы всё привыкли делать асинхронно. Как же аналогичный алгоритм работает в системе с асинхронной моделью обмена сообщениями, где мы считаем, что время ожидания ответа от узла может быть сколь угодно долгим (к слову, выход узла из строя, можно тоже рассматривать как пример, когда узел может отвечать сколь угодно долго).
Мы сейчас говорили про теорию, про математику. Что значит «консенсус не может быть достигнут», переводя с математического языка на наш – инженерный? Это значит, что «не всегда может быть достигнут», т.е. существует такой кейс, при котором консенсус не достижим. А что же это за случай?
Это как раз нарушение liveness property, описанное выше. У нас нет общего согласия, и система не может иметь прогресс (не может завершиться за конечное время) в случае, когда у нас нет ответа от всех узлов. Потому что в асинхронной системе у нас нет предсказуемого времени ответа, и мы не можем знать, вышел ли узел из строя или просто долго отвечает.
Но на практике мы можем найти решение. Пусть наш алгоритм может работать долго в случае отказов (потенциально может работать бесконечно). Но в большинстве ситуаций, когда большинство узлов корректно функционируют, мы будем иметь прогресс в системе.
На практике мы имеем дело с частично синхронными моделями коммуникаций. Частичная синхронность понимается так: в общем случае у нас асинхронная модель, но формально вводится некое понятие «global stabilization time» некоего момента времени.
Этот момент времени может не наступать сколь угодно долго, но однажды он должен наступить. Прозвенит виртуальный будильник, и с этого момента мы можем предсказать дельту времени, за которую сообщения дойдут. С этого момента система из асинхронной превращается в синхронную. На практике мы имеем дело именно с такими системами.
Paxos – это семейство алгоритмов, которые решают проблему консенсуса для частично синхронных систем, при условии что какие-то узлы могут выходить из строя. Автором Paxos'а является Leslie Lamport. Он предложил формальное доказательство существования и корректности алгоритма в 1989 году.
Но доказательство оказалось отнюдь нетривиальным. Первая публикация была выпущена только в 1998 году (33 страницы) с описанием алгоритма. Как оказалось, она была крайне сложной для понимания, и в 2001 году было опубликовано пояснение к статье, которое заняло 14 страниц. Объемы публикаций приведены для того, чтобы показать, что на самом деле проблема консенсуса совсем непростая, и за подобными алгоритмами лежит огромный труд умнейших людей.
Подробный разбор работы Paxos'а потянет не на одну статью, поэтому я постараюсь очень коротко передать основную идею алгоритма. В ссылках в конце моей статьи вы найдете материалы для дальнейшего погружения в эту тему.
В алгоритме Paxos есть понятие ролей. Рассмотрим три основные (есть модификации с дополнительными ролями):
Один узел может совмещать несколько ролей в разных ситуациях.
Мы предполагаем, что у нас есть система из N узлов. И из них максимум F узлов может выходить из строя. Если F узлов выходит из строя, значит у нас в кластере должно быть, как минимум 2F + 1 узлов acceptor'ов.
Это нужно для того, чтобы у нас всегда, даже в худшей ситуации «хорошие», корректно работающие узлы имели большинство. То есть F + 1 «хороших» узлов, которые согласились, и финальное значение будет принято. В противном случае может быть ситуация, когда у нас разные локальные группы примут разное значение и не смогут между собой договориться. Поэтому нам нужно абсолютное большинство, чтобы победить в голосовании.
Алгоритм Paxos предполагает две больших фазы, которые в свою очередь разбиваются на два шага каждая:
Вот так работает алгоритм Paxos. У каждого из этих этапов есть много тонкостей, мы практически не рассмотрели различные виды отказов, проблемы множественных лидеров и многое другое, но целью данной статьи является лишь на верхнем уровне познакомить читателя с миром распределённых вычислений.
Также стоит заметить, что Paxos — не единственный в своем роде, есть и другие алгоритмы, например, Raft, но это уже тема для другой статьи.
Уровень «новичок»:
Уровень «Лесли Лэмпорт»:
В этой статье я простым языком расскажу вам о теоретической составляющей мира распределённых систем и принципах их работы. А также поверхностно рассмотрю главную идею, лежащую в основе Paxos'а.
Когда разработчики пользуются облачными инфраструктурами, различными базами данных, работают в кластерах из большого числа узлов, они уверены, что данные будут целостными, сохранными и всегда доступными. Но откуда гарантии?
По сути, гарантии, которые у нас есть – это гарантии поставщика. Они описаны в документации примерно следующим образом: «Этот сервис достаточно надёжный, у него есть заданный SLA, не беспокойтесь, всё будет распределённо работать, как вы и ожидаете».
Мы склонны верить в лучшее, ведь умные дяди из больших компаний заверили нас, что всё будет хорошо. Мы не задаёмся вопросом: а почему, собственно, это вообще может работать? Есть ли какое-то формальное обоснование корректности работы таких систем?
Недавно я ездил на школу по распределённым вычислениям и очень вдохновился этой темой. Лекции в школе больше напоминали занятия по математическому анализу, нежели нечто связанное с компьютерными системами. Но именно так в своё время и доказывались важнейшие алгоритмы, которыми мы пользуемся каждый день, сами того не подозревая.
В большинстве современных распределённых систем используется алгоритм консенсуса Paxos и его различные модификации. Самое крутое, что обоснованность и, в принципе, сама возможность существования этого алгоритма может быть доказана просто с помощью ручки и бумаги. При этом на практике алгоритм применяется в больших системах, работающих на огромном числе узлов в облаках.
Лайтовая иллюстрация того, о чем пойдёт речь дальше: задача двух генералов
Давайте для разминки разберем задачу двух генералов.
У нас есть две армии – рыжая и белая. Белые войска базируются в осаждённом городе. Рыжие войска во главе с генералами А1 и А2 располагаются по двум сторонам от города. Задача рыжих – напасть на белый город и победить. Однако войско каждого рыжего генерала в отдельности меньше войска белых.
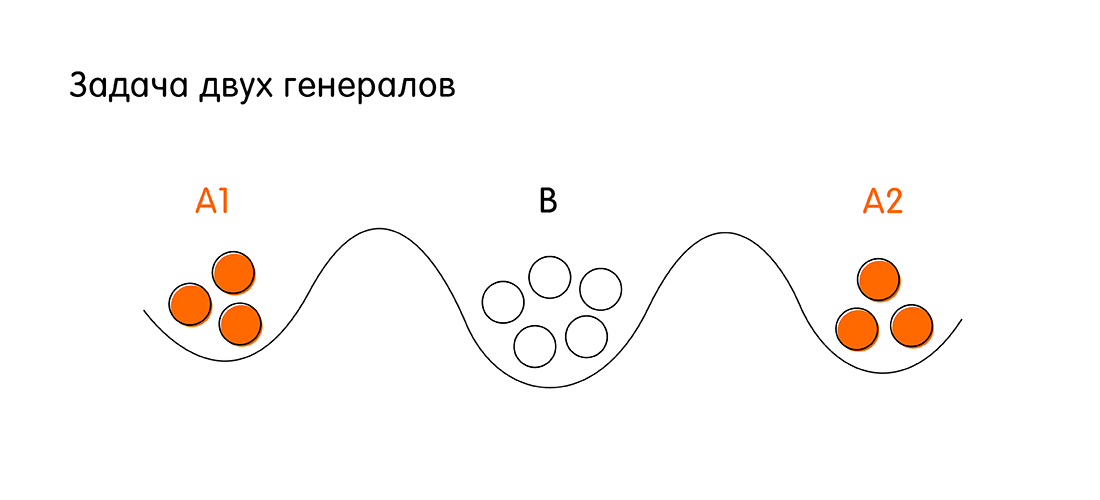
Условия победы для рыжих: оба генерала должны напасть одновременно, чтобы иметь численное преимущество над белыми. Для этого генералам А1 и А2 нужно договориться друг с другом. Если каждый будет нападать по отдельности, рыжие проиграют.
Чтобы договориться, генералы А1 и А2 могут посылать друг к другу гонцов через территорию белого города. Гонец может успешно добраться до союзного генерала или может быть перехваченным противником. Вопрос: есть ли такая последовательность коммуникаций между рыжими генералами (последовательность отправки гонцов от А1 к А2 и наоборот от А2 к А1), при которой они гарантировано договорятся о нападении в час Х. Здесь, под гарантиями понимается, что оба генерала будут иметь однозначное подтверждение, что союзник (другой генерал) точно атакует в назначенное время X.
Предположим, что А1 посылает гонца к А2 с посланием: «Давай нападем сегодня в полночь!». Генерал А1 не может напасть без подтверждения от генерала А2. Если гонец от А1 дошёл, то генерал А2 посылает подтверждение с сообщением: «Да, давай сегодня завалим белых». Но теперь генерал А2 не знает, дошёл его гонец или нет, у него нет гарантий, будет ли нападение одновременным. Теперь уже генералу А2 опять нужно подтверждение.
Если расписывать их коммуникацию дальше, выяснится следующее: сколько бы ни было циклов обмена сообщениями, нет способа гарантированно уведомить обоих генералов о том, что их сообщения получены (при условии, что любой из гонцов может быть перехвачен).
Задача двух генералов – это отличная иллюстрация очень простой распределённой системы, где есть два узла с ненадёжной коммуникацией. Значит у нас нет 100% гарантии того, что они синхронизируются. Про подобные проблемы только в более крупном масштабе далее в статье.
У нас есть две армии – рыжая и белая. Белые войска базируются в осаждённом городе. Рыжие войска во главе с генералами А1 и А2 располагаются по двум сторонам от города. Задача рыжих – напасть на белый город и победить. Однако войско каждого рыжего генерала в отдельности меньше войска белых.
Условия победы для рыжих: оба генерала должны напасть одновременно, чтобы иметь численное преимущество над белыми. Для этого генералам А1 и А2 нужно договориться друг с другом. Если каждый будет нападать по отдельности, рыжие проиграют.
Чтобы договориться, генералы А1 и А2 могут посылать друг к другу гонцов через территорию белого города. Гонец может успешно добраться до союзного генерала или может быть перехваченным противником. Вопрос: есть ли такая последовательность коммуникаций между рыжими генералами (последовательность отправки гонцов от А1 к А2 и наоборот от А2 к А1), при которой они гарантировано договорятся о нападении в час Х. Здесь, под гарантиями понимается, что оба генерала будут иметь однозначное подтверждение, что союзник (другой генерал) точно атакует в назначенное время X.
Предположим, что А1 посылает гонца к А2 с посланием: «Давай нападем сегодня в полночь!». Генерал А1 не может напасть без подтверждения от генерала А2. Если гонец от А1 дошёл, то генерал А2 посылает подтверждение с сообщением: «Да, давай сегодня завалим белых». Но теперь генерал А2 не знает, дошёл его гонец или нет, у него нет гарантий, будет ли нападение одновременным. Теперь уже генералу А2 опять нужно подтверждение.
Если расписывать их коммуникацию дальше, выяснится следующее: сколько бы ни было циклов обмена сообщениями, нет способа гарантированно уведомить обоих генералов о том, что их сообщения получены (при условии, что любой из гонцов может быть перехвачен).
Задача двух генералов – это отличная иллюстрация очень простой распределённой системы, где есть два узла с ненадёжной коммуникацией. Значит у нас нет 100% гарантии того, что они синхронизируются. Про подобные проблемы только в более крупном масштабе далее в статье.
Вводим понятие распределённых систем
Распределённая система – это группа компьютеров (далее будем называть их узлами), которые могут обмениваться сообщениями. Каждый отдельный узел – это некоторая автономная сущность. Узел может самостоятельно обрабатывать задачи, но чтобы взаимодействовать с другими узлами, ему нужно посылать и принимать сообщения.
Как конкретно реализованы сообщения, какие протоколы используются – это нас не интересует в данном контексте. Важно, что узлы распределённой системы могут обмениваться друг с другом данными путем отправки сообщений.
Само определение выглядит не очень сложным, но нужно учитывать, что у распределённой системы есть ряд атрибутов, которые будут важны для нас.
Атрибуты распределённых систем
- Concurrency – возможность возникновения одновременных или конкурентных событий в системе. Более того, мы будем считать, что события, произошедшие на двух разных узлах, потенциально конкурентные до тех пор, пока у нас нет чёткого порядка возникновения этих событий. А, как правило, у нас его нет.
- Отсутствие глобальных часов. У нас нет чёткого порядка событий в силу отсутствия глобальных часов. В обычном мире людей мы привыкли к тому, что у нас есть часы и время абсолютно. Всё меняется, когда речь заходит о распределённых системах. Даже у сверхточных атомных часов есть дрифт, и возможны ситуации, когда мы не можем сказать, какое из двух событий произошло раньше. Поэтому полагаться на время мы тоже не можем.
- Независимый отказ узлов системы. Есть ещё одна проблема: что-то может пойти не так просто потому, что наши узлы не вечны. Может выйти из строя жёсткий диск, перезагрузиться виртуалка в облаке, может моргнуть сеть и сообщения потеряются. Более того, возможны ситуации, когда узлы работают, но при этом работают против системы. Последний класс проблем даже получил отдельное название: проблема византийских генералов. Самый популярный пример распределённой системы с такой проблемой – это Blockchain. Но сегодня мы не будем рассматривать этот особый класс проблем. Нас будут интересовать ситуации, в которых просто один или несколько узлов могут выходить из строя.
- Модели коммуникации (модели обмена сообщениями) между узлами. Мы уже выяснили, что узлы общаются путем обмена сообщениями. Есть две известные модели обмена сообщениями: синхронная и асинхронная.
Модели коммуникации между узлами в распределённых системах
Синхронная модель – мы точно знаем, что есть конечная известная дельта времени, за которую сообщение гарантированно доходит от одного узла до другого. Если это время вышло, а сообщение не пришло, мы можем смело говорить, что узел вышел из строя. В такой модели мы имеем предсказуемое время ожидания.
Асинхронная модель – в асинхронных моделях мы считаем, что время ожидания конечно, но не существует такой дельты времени, после которой можно гарантировать, что узел вышел из строя. Т.е. время ожидания сообщения от узла может быть сколь угодно долгим. Это важное определение, и мы поговорим об этом дальше.
Понятие консенсуса в распределённых системах
Прежде, чем формально определить понятие консенсуса, рассмотрим пример ситуации, когда он нам нужен, а именно – State Machine Replication.
У нас есть некоторый распределённый лог. Нам бы хотелось, чтобы он был консистентным и содержал идентичные данные на всех узлах распределённой системы. Когда какой-то из узлов узнает новое значение, которое он собирается записать в лог, его задачей становится предложить это значение всем остальным узлам, чтобы лог обновился на всех узлах, и система перешла в новое консистентное состояние. При этом важно, чтобы узлы договорились между собой: все узлы согласились, что предложенное новое значение корректно, все узлы это значение приняли, и только в этом случае все могут записать в лог новое значение.
Иными словами: никто из узлов не возразил, что у него есть более актуальная информация, а предлагаемое значение неверное. Договоренность между узлами и согласие о едином верном принятом значении и есть консенсус в распределённой системе. Далее мы будем говорить об алгоритмах, которые позволяют распределённой системе гарантированно достигать консенсус.
Более формально мы можем определить алгоритм достижения консенсуса (или просто алгоритм консенсуса), как некоторую функцию, которая переводит распределённую систему из состояния А в состояние Б. Причем это состояние принято всеми узлами, и все узлы могут его подтвердить. Как выясняется, эта задача совсем не такая тривиальная, как кажется на первый взгляд.
Свойства алгоритма консенсуса
Алгоритм консенсуса должен обладать тремя свойствами, чтобы система продолжала существовать и имела какой-то прогресс в переходе из состояния в состояние:
- Agreement – все корректно работающие узлы должны принять одно и то же значение (в статьях это свойство также встречается как safety property). Все узлы, которые сейчас функционируют (не вышли из строя и не потеряли связь с остальными) должны прийти к соглашению и принять некое финальное общее значение.
Здесь важно понимать, что узлы в рассматриваемой нами распределённой системе хотят договориться. То есть мы сейчас говорим про системы, у которых просто может что-то отказать (например, отказать какой-то узел), но в этой системе точно нет узлов, которые намеренно работают против других (задача византийских генералов). За счет этого свойства система остается консистентной. - Integrity — если все корректно работающие узлы предлагают одно и то же значение v, значит каждый корректно работающий узел должен принять это значение v.
- Termination – все корректно работающие узлы в конечном счете примут некоторое значение (liveness property), что позволяет алгоритму иметь прогресс в системе. Каждый отдельный корректно работающий узел, должен рано или поздно принять финальное значение и подтвердить это: «Для меня – это значение истинно, я согласен со всей системой».
Пример работы алгоритма консенсуса
Пока свойства алгоритма могут быть не совсем понятны. Поэтому проиллюстрируем на примере, какие стадии проходит простейший алгоритм консенсуса в системе с синхронной моделью обмена сообщениями, у которой все узлы функционируют как положено, сообщения не теряются и ничего не ломается (неужели такое и правда случается?).
- Всё начинается с предложения
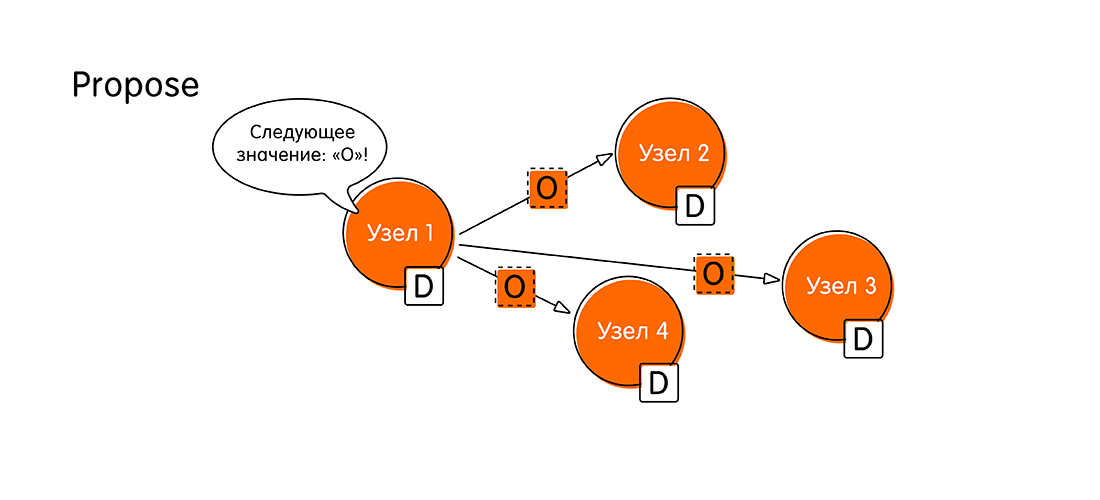
руки и сердца(Propose). Предположим, что к узлу под названием «Узел 1» подключился клиент и начал транзакцию, передав узлу новое значение – О. С этого момента «Узел 1» мы будем называть proposer. Как proposer «Узел 1» теперь должен оповестить всю систему о том, что у него есть свежие данные, и он рассылает всем остальным узлам сообщения: «Смотрите! Мне пришло значение «О», и я хочу его записать! Прошу подтвердить, что вы тоже запишите «О» в свой лог».
- Следующая стадия – голосование за предлагаемое значение (Voting). Для чего она нужна? Может так случиться, что другим узлам пришла более свежая информация, и у них есть данные по этой же транзакции.
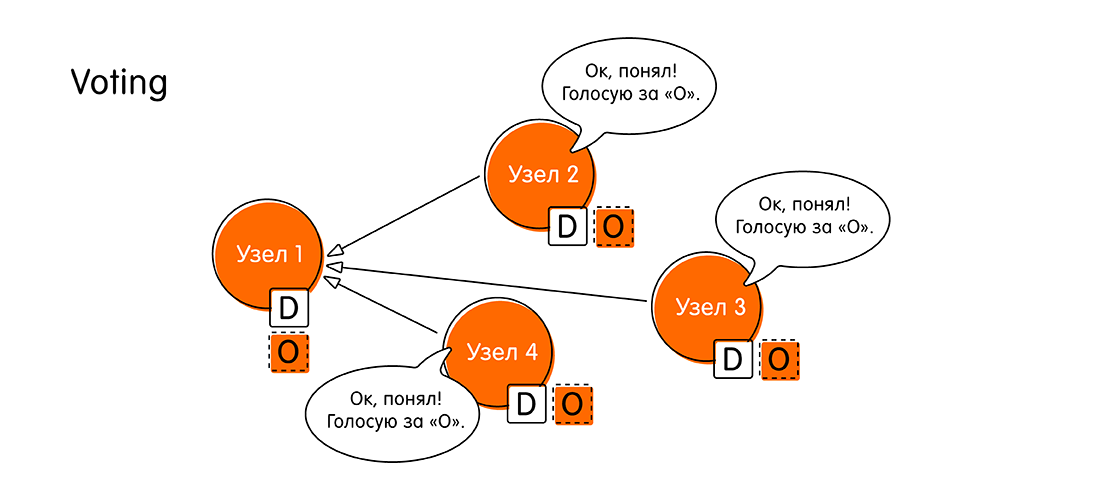
Когда узел «Узел 1» посылает свой пропоуз, остальные узлы проверяют в своих логах данные по этому событию. Если никаких противоречий нет, узлы объявляют: «Да, у меня нет других данных по этому событию. Значение «О» – это самая свежая информация, которую мы заслужили».
В любом другом случае, узлы могут ответить «Узлу 1»: «Послушай! У меня есть более свежие данные по этой транзакции. Не «О», а кое-что получше».
На стадии голосования узлы приходят к решению: либо все принимают одно значение, либо кто-то из них голосует против, обозначив, что у него есть более свежие данные. - Если раунд голосования прошёл успешно, и все были «за», то система переходит в новую стадию – принятие значения (Accept). «Узел 1» собирает все ответы других узлов и сообщает: «Все согласились со значением «О»! Теперь я официально заявляю, что «О» – наше новое значение, единое для всех! Запишите себе в книжечку, не забудьте. Запишите в свой лог!»
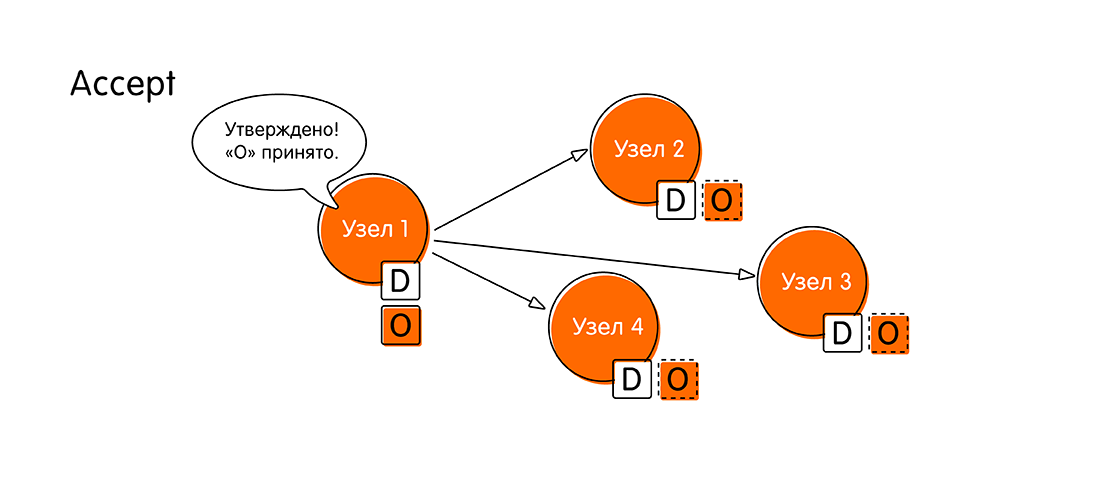
- Остальные узлы присылают подтверждение (Accepted), что они записали себе значение «О», ничего нового за это время поступить не успело (своего рода двухфазный коммит). После этого знаменательного события мы считаем, что распределенная транзакция выполнилась.
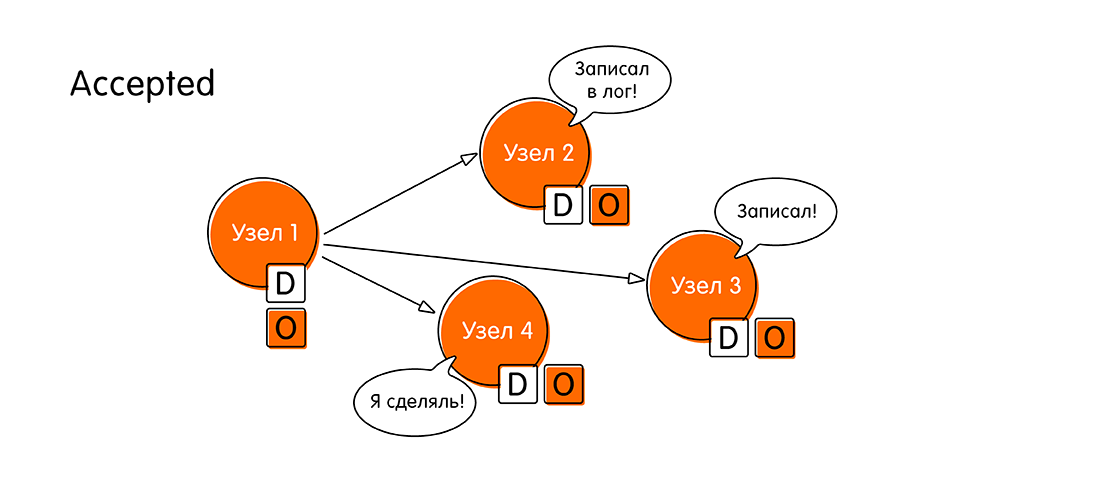
Таким образом алгоритм консенсуса в простом случае состоит из четырёх шагов: propose, голосование (voting), принятие (accept), подтверждение принятия (accepted).
Если на каком-то шаге мы не смогли достичь согласия, то алгоритм запускается заново, с учётом той информации, которую предоставят узлы, отказавшиеся подтверждать предлагаемое значение.
Алгоритм консенсуса в асинхронной системе
До этого всё было гладко, ведь речь шла про синхронную модель обмена сообщениями. Но мы-то знаем, что в современном мире мы всё привыкли делать асинхронно. Как же аналогичный алгоритм работает в системе с асинхронной моделью обмена сообщениями, где мы считаем, что время ожидания ответа от узла может быть сколь угодно долгим (к слову, выход узла из строя, можно тоже рассматривать как пример, когда узел может отвечать сколь угодно долго).
Теперь, когда мы знаем, как в принципе работает алгоритм консенсуса, вопрос к тем пытливым читателям, кто дошёл до этого места: сколько узлов в системе из N узлов с асинхронной моделью сообщений может выйти из строя, чтобы система по-прежнему могла достигать консенсуса?
Правильный ответ и обоснование за спойлером.
Правильный ответ: 0. Если хотя бы один узел в асинхронной системе выходит из строя, система не сможет достичь консенсуса. Это утверждение доказано в известной в определенных кругах теореме FLP (1985, Fischer, Lynch, Paterson, ссылка на оригинал в конце статьи): «Невозможность достижения распределённого консенсуса при выходе из строя хотя бы одного узла».
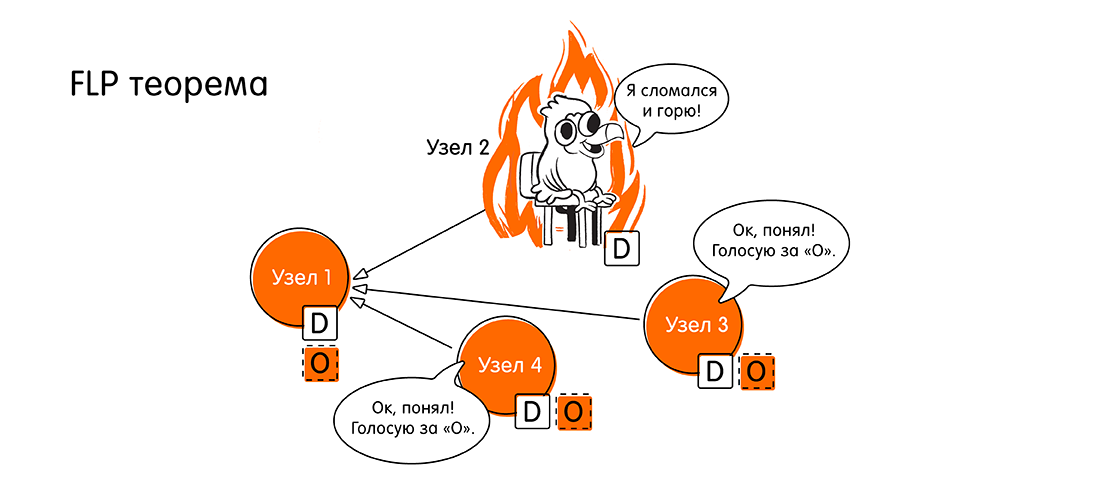
Ребята, тогда у нас проблема, мы же привыкли, что у нас всё асинхронно. А тут такое. Как дальше жить?
Ребята, тогда у нас проблема, мы же привыкли, что у нас всё асинхронно. А тут такое. Как дальше жить?
Мы сейчас говорили про теорию, про математику. Что значит «консенсус не может быть достигнут», переводя с математического языка на наш – инженерный? Это значит, что «не всегда может быть достигнут», т.е. существует такой кейс, при котором консенсус не достижим. А что же это за случай?
Это как раз нарушение liveness property, описанное выше. У нас нет общего согласия, и система не может иметь прогресс (не может завершиться за конечное время) в случае, когда у нас нет ответа от всех узлов. Потому что в асинхронной системе у нас нет предсказуемого времени ответа, и мы не можем знать, вышел ли узел из строя или просто долго отвечает.
Но на практике мы можем найти решение. Пусть наш алгоритм может работать долго в случае отказов (потенциально может работать бесконечно). Но в большинстве ситуаций, когда большинство узлов корректно функционируют, мы будем иметь прогресс в системе.
На практике мы имеем дело с частично синхронными моделями коммуникаций. Частичная синхронность понимается так: в общем случае у нас асинхронная модель, но формально вводится некое понятие «global stabilization time» некоего момента времени.
Этот момент времени может не наступать сколь угодно долго, но однажды он должен наступить. Прозвенит виртуальный будильник, и с этого момента мы можем предсказать дельту времени, за которую сообщения дойдут. С этого момента система из асинхронной превращается в синхронную. На практике мы имеем дело именно с такими системами.
Алгоритм Paxos решает проблемы консенсуса
Paxos – это семейство алгоритмов, которые решают проблему консенсуса для частично синхронных систем, при условии что какие-то узлы могут выходить из строя. Автором Paxos'а является Leslie Lamport. Он предложил формальное доказательство существования и корректности алгоритма в 1989 году.
Но доказательство оказалось отнюдь нетривиальным. Первая публикация была выпущена только в 1998 году (33 страницы) с описанием алгоритма. Как оказалось, она была крайне сложной для понимания, и в 2001 году было опубликовано пояснение к статье, которое заняло 14 страниц. Объемы публикаций приведены для того, чтобы показать, что на самом деле проблема консенсуса совсем непростая, и за подобными алгоритмами лежит огромный труд умнейших людей.
Интересно, что сам Лесли Лэмпорт в своей лекции заметил, что во второй статье-пояснении есть одно утверждение, одна строчка (не уточнил какая), которая может быть по-разному трактована. И из-за этого большое количество современных реализаций Paxos работают не совсем корректно.
Подробный разбор работы Paxos'а потянет не на одну статью, поэтому я постараюсь очень коротко передать основную идею алгоритма. В ссылках в конце моей статьи вы найдете материалы для дальнейшего погружения в эту тему.
Роли в Paxos
В алгоритме Paxos есть понятие ролей. Рассмотрим три основные (есть модификации с дополнительными ролями):
- Proposers (также могут встречаться термины: лидеры или координаторы). Это ребята, которые узнают о каком-то новом значении от пользователя и берут на себя роль лидера. Их задача запустить раунд предложения нового значения и координировать дальнейшие действия узлов. Причем Paxos допускает наличие нескольких лидеров в определённых ситуациях.
- Acceptors (Voters). Это узлы, которые голосуют за принятие или непринятие того или иного значения. Их роль очень важна, потому что именно от них зависит решение: в какое состояние перейдет (или не перейдет) система после очередного этапа алгоритма консенсуса.
- Learners. Узлы, которые просто принимают и записывают новое принятое значение, когда состояние системы изменилось. Они не принимают решения, просто получают данные и могут отдать их конечному пользователю.
Один узел может совмещать несколько ролей в разных ситуациях.
Понятие кворума
Мы предполагаем, что у нас есть система из N узлов. И из них максимум F узлов может выходить из строя. Если F узлов выходит из строя, значит у нас в кластере должно быть, как минимум 2F + 1 узлов acceptor'ов.
Это нужно для того, чтобы у нас всегда, даже в худшей ситуации «хорошие», корректно работающие узлы имели большинство. То есть F + 1 «хороших» узлов, которые согласились, и финальное значение будет принято. В противном случае может быть ситуация, когда у нас разные локальные группы примут разное значение и не смогут между собой договориться. Поэтому нам нужно абсолютное большинство, чтобы победить в голосовании.
Общая идея работы алгоритма консенсуса Paxos
Алгоритм Paxos предполагает две больших фазы, которые в свою очередь разбиваются на два шага каждая:
- Phase 1a: Prepare. На этапе подготовки лидер (proposer) сообщает всем узлам: «Мы начинаем новый этап голосования. У нас новый раунд. Номер этого раунда – n. Сейчас мы начнём голосовать». Пока он просто сообщает о начале нового цикла, но не сообщает новое значение. Задача этого этапа инициировать новый раунд и сообщить всем его уникальный номер. Номер раунда важен, это должно быть значение большее, чем все предыдущие номера голосований от всех предыдущих лидеров. Так как именно благодаря номеру раунда другие узлы в системе будут понимать, насколько свежие данные у лидера. Вероятно, у других узлов уже есть результаты голосования с намного более поздних раундов и они просто расскажут лидеру, что он отстал от жизни.
- Phase 1b: Promise. Когда узлы-acceptor'ы получили номер нового этапа голосования, возможны два исхода:
- Номер n нового голосования больше, чем номер любого из предыдущих голосований, в котором участвовал acceptor. Тогда acceptor отправляет лидеру обещание, что не будет больше участвовать ни в каких голосованиях с меньшим номером, чем n. Если acceptor уже успел за что-то проголосовать (т.е. он уже во второй фазе принял какое-то значение), то к своему обещанию он прикладывает принятое значение и номер голосования, в котором он участвовал.
- В противном случае, если acceptor уже знает о голосовании с большим номером, он может просто проигнорировать этап подготовки и не отвечать лидеру.
- Phase 2a: Accept. Лидеру нужно дождаться ответа от кворума (большинства узлов в системе) и, если нужное число ответов получено, то у него есть два варианта развития событий:
- Некоторые из acceptor'ов прислали значения, за которые они уже голосовали. В этом случае лидер выбирает значение из голосования с макcимальным номером. Назовем это значение x, и рассылает всем узлам сообщение вида: «Accept (n, x)», где первое значение – номер голосования из своего же шага Propose, а второе значение – то ради чего все собирались, т.е. значение за которое, собственно, голосуем.
- Если никто из acceptor'ов не прислал никаких значений, а просто они пообещали голосовать в этом раунде, лидер может предложить им проголосовать за свое значение, то значение, ради которого он вообще стал лидером. Назовем его y. Он рассылает всем узлам сообщение вида: «Accept (n, y)», по аналогии с предыдущим исходом.
- Phase 2b: Accepted. Далее, узлы-acceptor'ы, при получении сообщения «Accept(...)», от лидера соглашаются с ним (рассылают всем узлам подтверждение, что они согласны с новым значением) только в том случае, если они не пообещали какому-то (другому) лидеру участвовать в голосованиях с номером раунда n' > n, в противном случае они игнорируют запрос на подтверждение.
Если лидеру ответило большинство узлов, и все они подтвердили новое значение, то новое значение считается принятым. Ура! Если же большинство не набрано или есть узлы, которые отказались принимать новое значение, то всё начинается сначала.
Вот так работает алгоритм Paxos. У каждого из этих этапов есть много тонкостей, мы практически не рассмотрели различные виды отказов, проблемы множественных лидеров и многое другое, но целью данной статьи является лишь на верхнем уровне познакомить читателя с миром распределённых вычислений.
Также стоит заметить, что Paxos — не единственный в своем роде, есть и другие алгоритмы, например, Raft, но это уже тема для другой статьи.
Ссылки на материалы для дальнейшего изучения
Уровень «новичок»:
- How Does Distributed Consensus Works?, Preethi Kasireddy, blog article on Medium
- Paxos made simple. For real, Adi Kancherla, blog article on Medium
- Decentralized Thoughts, Ittai Abraham, blog
- Synchrony, Asynchrony and Partial synchrony, Ittai Abraham, blog article
Уровень «Лесли Лэмпорт»:
- Impossibility of Distributed Consensus with One Faulty Process (FLP impossibility), Fischer, Lynch and Paterson, research paper, 1985
- The Part-Time Parliament, Leslie Lamport, research paper, 1998
- Paxos made simple, Leslie Lamport, research paper, 2001



