
Привет! Я Алексей, старший системный администратор ЮMoney. Так уж вышло, что я — главный по Куберу в компании. Поэтому когда меня попросили рассказать, как мы создавали сервис Kubernetes и что у нас в итоге получилось, уговаривать меня долго не пришлось.
Зачем вообще компании может понадобиться оркестрация контейнеров? Когда приложений немного, то и задача такая, как правило, не стоит. Администраторы знают каждое приложение в лицо, живут они на небольшом числе серверов. В такой ситуации ресурсы обычно выделяются вручную.
С ростом количества приложений управлять ими вручную становится сложнее. Эта работа начинает занимать всё больший процент времени администраторов, которым, конечно же, не очень нравится рутина.
Когда-то давно у нас так и было: приложений было пара десятков, и жили они все на нескольких железных серверах без какой-либо контейнеризации. По мере роста компании и распиливания монолитов количество приложений стало расти, а сами они начали перемещаться в LXC/LXD-контейнеры. Но поскольку их всё ещё было немного, ручное управление размещением контейнеров, выделением ресурсов и сетями не было проблемой. Пока в конце концов мы не пришли к тому, что приложений у нас уже больше 160, в год добавляется ещё по 20, а живут они на 800+ LXC/LXD-контейнеров.
Для начала небольшое погружение в историю. Ещё четыре года назад, в конце 2017 – начале 2018 года, когда приложений было поменьше, около 60, и даже не все они ещё были в LXC, стало понятно, что нам нужна какая-то оркестрация контейнеров. На тот момент наряду с Kubernetes рассматривали ещё Swarm и Nomad, а последний даже подняли для нужд одного из наших подразделений (и он до сих пор жив).
Тогда-то один из Linux-админов компании и поднял тестовый кластер куба для экспериментов. От этого кластера ведут свою родословную все кластеры, живущие в нашей компании.

Кластер был инициативой снизу и делался одним сотрудником фактически на голом энтузиазме. От первой заявки на сети до появления работающего кластера прошло около года экспериментов. В этот кластер заехал созданный тем же сотрудником релизный бот, про которого отдельно подробно рассказал @dvorob в своём докладе, и... всё, больше ничего заехать не успело. Угадайте почему? Потому что закончилось всё ровно тем, чем всегда заканчиваются истории с bus_factor == 1. Конечно же, тот самый единственный и неповторимый сотрудник в один прекрасный день покинул компанию.
Созданный кластер с релизным ботом не бросили, а создали группу из трёх сотрудников, которым передали все наработки. Примерно в этот момент Кубер начал превращаться из проекта, созданного в свободное время энтузиастом, во что-то более походящее на боевую систему.
Втроём ребята проводили эксперименты и пытались нащупать подходящую нам архитектуру системы, которая должна была, насколько это возможно, соответствовать следующим требованиям:
отказоустойчивость
минимальные переделки приложений со стороны разработки
совместимость с существующей инфраструктурой: система не должна стоять особняком
масштабируемость
тиражируемость: система должна быть воспроизводима
Хотелось, чтобы в куб можно было перенести приложения нашей платёжной системы без переделки самих приложений и инфраструктуры с нуля, а для переноса приложения в кластер достаточно было бы его упаковать в докер-контейнер.
К лету 2019-го появилась первая версия технического решения, а в сентябре разработка архитектуры кластера в основном была завершена. Было решено поднять четыре кластера K8s, по два на дата-центр. Каждый кластер состоял из трёх мастер-нод, на которых крутился control-plain и etcd, двух нод-балансировщиков, на которых поднимался ingress-nginx, и произвольного числа нод для рабочих нагрузок. Единым service mesh для всех приложений компании должен был стать Consul Connect.
За сентябрь-октябрь в новые кластеры начали заезжать приложения. Вообще, бо́льшая часть платёжной системы ЮMoney написана на Java и Node.js, которые деплоятся в LXD-контейнеры. Но для начала брали приложения, которые не были связаны с ядром платёжной системы, жили на отдельных виртуалках в VmWare vCenter и не проходили через стандартный CI/CD пайплайн. Это был десяток небольших РНР-приложений, которые стояли особняком и могли быть безболезненно мигрированы в новую инфраструктуру.
Кроме PHP-приложений для заезда в кластеры куба было выбрано одно небольшое новое Node.js-приложение, которое готовилось к выезду в продакшн и не было критичным в случае простоя. Нам было важно проверить работу на одном из стандартных приложений и убедиться, что всё работает как задумано.
Примерно на этом этапе к команде, занимавшейся Кубером, присоединился я: не хватало рабочих рук, и меня с ещё одним коллегой добавили для усиления. На тот момент у меня был некоторый опыт работы с докером, но ни с Kubernetes, ни с аналогами я дела не имел.
Казалось бы, всё идёт хорошо, но пушной полярный лис подкрался к нам с неожиданного направления. По разным причинам буквально за два месяца все три старых куберовца покидают проект. Вот так нежданно-негаданно в начале 2020 года команда Кубера осталась без людей, которые создавали этот сервис.
На какое-то время о развитии пришлось забыть. Мы забрали в команду ещё одного перспективного сотрудника, но экспертизы катастрофически не хватало. Втроём мы с трудом успевали решать текущие проблемы в довольно сыром сервисе.
Особенно много проблем доставлял Consul Connect, который постоянно терял связность между своими «дата-центрами» (не нашими физическими дата-центрами, а внутренними логическими сущностями Консула).

Каждый кластер куба был отдельным «дата-центром» и отваливался от основного ДЦ по любому чиху. Следствием была потеря связности между приложением Node.js внутри кластера и компонентами снаружи. Очень подозреваю, что мы просто не сумели правильно приготовить connect, экспертизы по Consul у нас на тот момент было ещё меньше, чем по Куберу.
В конечном итоге спустя месяц терзаний мы вернули Node.js-приложение на наши стандартные LXD-рельсы, выпилили Consul Connect, более-менее стабилизировали работу кластеров куба и задумались над новой архитектурой кластеров.
Поскольку у предыдущей архитектуры оказался фатальный недостаток, надо было придумать на её основе что-то новое, но без коннекта. И тут совпали два события. Во-первых, я изучил возможности сетевого плагина Calico в плане обмена сетевыми маршрутами к подам через BGP и получил от наших сетевиков принципиальное ОК на возможность осуществить пиринг с их оборудованием. А во-вторых, в недрах команды DevOps родился проект по созданию service discovery на основе HAProxy+Consul.
Локальный HAProxy на каждой ноде приложения и без того использовался в компании для балансировки запросов приложения к другим частям платёжной системы. Фактически на нём был построен такой прото-service mesh, управлявшийся через Ansible. Для превращения в полноценный service mesh не хватало как раз обнаружения сервисов, которое и решили сделать на основе Consul.
Из этих двух фактов родилась новая концепция архитектуры кластера, в первую очередь – сетевой архитектуры. В «новом прекрасном Кубере будущего» мы отказывались от Ingress-контроллеров, добавляли к каждому поду sidecar с Consul-агентом и направляли трафик снаружи кластера напрямую в поды приложений. Кроме sidecar с агентом, для взаимодействия с внешними относительно кластера сервисами в поды приложений добавился sidecar с HAProxy.
На сетевом уровне поды каждого приложения оказывались в своей /24 сети для возможности управления сетевыми доступами снаружи кластера. Это важное соответствие существующей инфраструктуре, так как в её основе лежит сегментация на сетевом уровне.
На реализацию этих идей в проде ушёл почти год: кластеры на новой сетевой архитектуре запустились в дев-среде в начале 2021-го. И дело не только в переходе на новый service discovery. Пандемия, локдаун и переход на удалёнку в то время имели максимальный приоритет, так что задачи по BGP-пирингу между сетевой инфраструктурой и кластерами K8s были отложены до лучших времён. Вишенкой на торте стал процесс смены названия компании в середине года, затянувший все свободные ресурсы.
За прошедший год концепция успела немного мутировать. Было решено оставить только два кластера в продакшн – по одному на ДЦ. В прошлом такое решение не было бы отказоустойчивым, поскольку входящий трафик терминировался исключительно в том же ДЦ, куда прилетал изначально. Мы решили эту проблему, и количество кластеров стало возможно уменьшить без ущерба для отказоустойчивости: при проблемах с кластером в одном ДЦ запросы полетят во второй.
К концу февраля я вывел из эксплуатации один из старых кластеров и пересоздал его на новой сетевой архитектуре. Замаячила финишная прямая...
И в этот момент закралась мысль, что экспертиза в готовке Кубера ограничивается исключительно нашим опытом с нашими же кластерами. Есть неиллюзорная вероятность совершить глобальный факап просто за счёт того, что мы не сталкивались n большими и серьёзно нагруженными кластерами. Чтобы уменьшить вероятность таких проблем, мы запросили аудит от компании Флант, профессионально занимающихся внедрением и поддержкой Kubernetes.
Ребята практически под микроскопом рассмотрели нашу архитектуру и процессы и показали себя настоящими профессионалами. Пользуясь случаем, хочу лично поблагодарить @distolи @jamboза прекрасные часы в Zoom и фирменное «Сложилось!».
После полуторамесячного аудита оказалось, что с конфигурацией самого по себе куба у нас всё более-менее ОК. А вот от идеи затащить в кластер наш самопальный service mesh нам крайне настойчиво порекомендовали отказаться и использовать вместо этого Istio – популярное решение, поддерживаемое хорошим комьюнити.
Игнорировать мнение экспертов было бы глупо, к тому же Istio изящнее решал проблемы межкластерного взаимодействия. Так что с апреля закипела работа по переезду на рельсы Istio внутри кластеров Кубера.
На RnD, тесты и интеграцию с уже существующим service discovery на HAProxy+Consul ушло несколько месяцев. Поначалу была идея затащить в Istio service mesh вообще все наши сервисы как в кубе, так и снаружи, но мы встретили непреодолимые проблемы при попытке включения в mesh хостов на Windows. К тому же, само решение по добавлению в mesh внешних относительно кластера хостов было явно сыровато. И раз уж всё равно придётся изобретать механизм для связи с хостами на Windows, решили, что точно такой же механизм отлично сработает и с Linux-хостами.
Таким образом у нас получилось два service discovery. Один снаружи куба – на Consul, другой внутри – на CoreDNS. При этом фактически у нас получился единый гибридный service mesh: приложения могут прозрачно ходить друг в друга независимо от того, где они расположены.
Вот как это устроено.
В репозитории приложения находится файл description.yml, где описаны все сервисы, к которым приложению нужен доступ. В очень сокращённом виде он выглядит так:
application:
name: app-name
endpoints:
- name: endpoint-name
app: other-app
port:
prod: httpsВнутри кластера K8s:
Поды CoreDNS мы расположили на мастерах и настроили на них hostNetwork. Так DNS кластера оказался доступен снаружи.
Для приложений, работающих в кластере, создаём Headless-сервисы в дополнение к обычным ClusterIP, чтобы иметь возможность получать IP-адреса подов по DNS.
Каждое приложение в кластере K8s живёт в собственном namespace.
Если у приложения в description.yml указаны внешние относительно кластера сервисы, при деплое такого приложения в его namespace создаются ServiceEntry, endpoint’ы для которых берутся из Consul и выглядят примерно так:
apiVersion: networking.istio.io/v1beta1
kind: ServiceEntry
metadata:
name: entry-name
namespace: app-namespace
spec:
endpoints:
- address: port-name.app-name.service.consul.domain
exportTo:
- .
hosts:
- app-name.virtual-namespace.svc
location: MESH_EXTERNAL
ports:
- name: https-app-name
number: 1234
protocol: HTTPS
resolution: DNSИмя хоста для ServiceEntry внешних сервисов задаётся такое же, как если бы они были внутри кластера: service.namespace.svc. Когда (если) этот сервис переедет в Кубер, достаточно будет удалить ServiceEntry, чтобы перенаправить трафик.
Для приложений, живущих в LXC/LXD-контейнерах или виртуалках:
на хосте устанавливается Consul agent, который регистрирует его в консуле и делает частью service mesh,
также устанавливается HAProxy
при деплое приложения для HAProxy генерируется конфигурация, исходя из значений в description.yml,
HAProxy динамически отслеживает изменения благодаря использованию директивы server-template.
listen app_name_port_name
bind 127.0.0.1:1234 tfo
mode tcp
option tcp-check
default-server inter 2000 fall 2 rise 2
server-template app-name-port-name-active 32 _app-name._port-name.service.dc1.consul.domain check init-addr none
server-template app-name-port-name-backup 32 _app-name._port-name.service.dc2.consul.domain check init-addr none backup
server-template k8s-app-name-port-name-active 10 _port-name._tcp.headless-service.namespace.svc.cluster-in-same-dc.domain check resolve-opts init-addr none
server-template k8s-app-name-port-name-backup 10 _port-name._tcp.headless-service.namespace.svc.cluster-in-other-dc.domain check resolve-opts init-addr none backup
На Nginx+ балансировщиках для приложений, живущих в Kubernetes, поднимаются апстримы, смотрящие на SRV-записи в DNS кластеров куба, примерно такого вида:
upstream k8s-app-name-http {
...
server headless-service.namespace.svc.cluster-in-same-dc.domain max_fails=0 fail_timeout=10s service=_port-name._tcp resolve;
server headless-service.namespace.svc.cluster-in-other-dc.domain max_fails=0 fail_timeout=10s service=_port-name._tcp resolve backup;
}Итого в августе 2021-го наконец-то была окончательно закончена разработка архитектуры кластера. А в сентябре приложения, уже жившие в K8s, переехали из старых кластеров в новые. Сегодня из LXC в кластер куба наконец-то начали переезжать компоненты на Java.
В конце концов Кубер в ЮMoney стал выглядеть так:
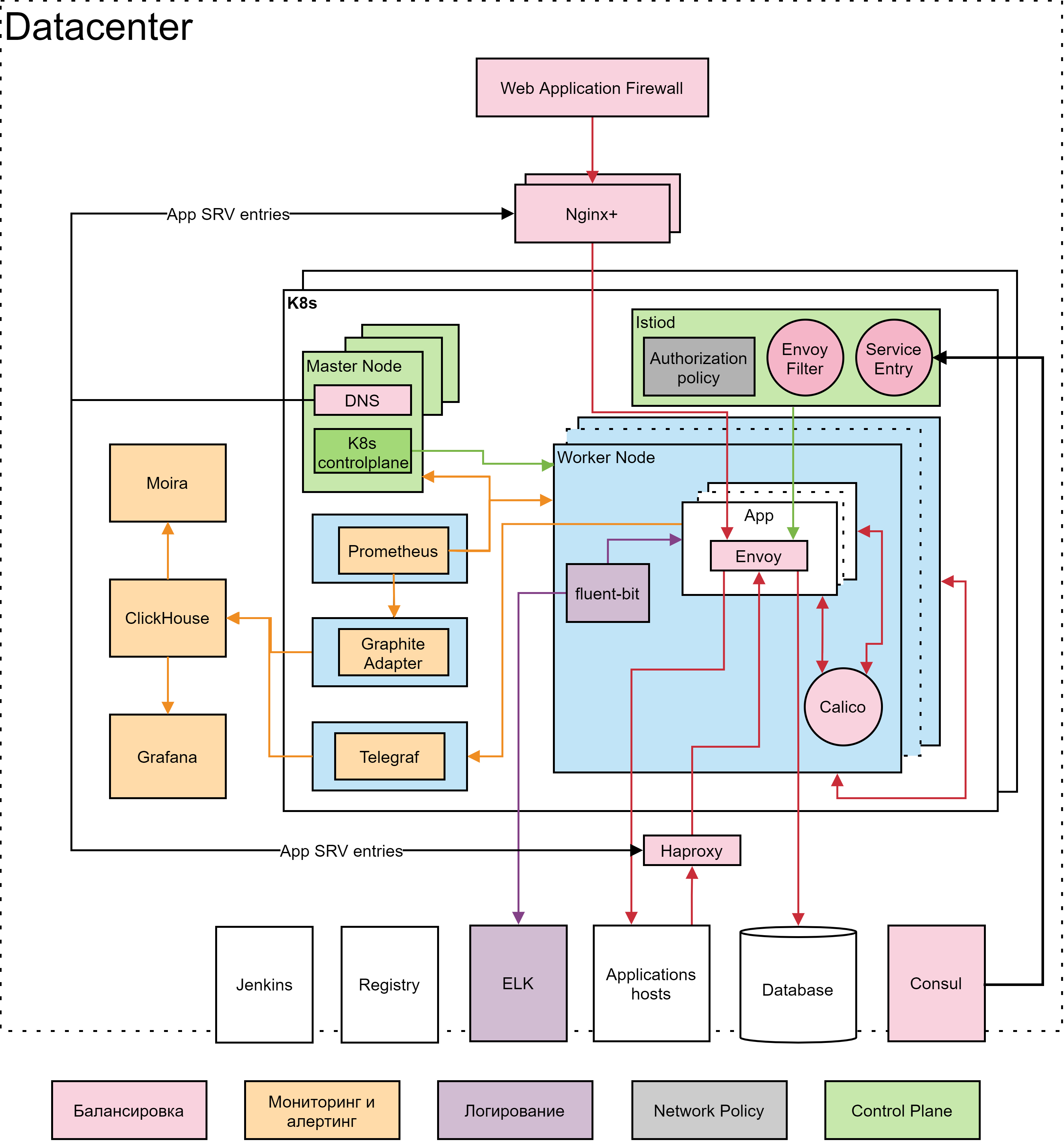
Таким образом, на то, чтобы довести сервис Kubernetes до продакшн-уровня у нас ушло порядка двух лет. Это цена, которую пришлось заплатить за безболезненный перенос приложений из легаси-инфраструктуры, за органичное встраивание Кубера в существующую систему. Насколько такой подход оправдан, каждая компания должна решать сама.
Возможно, в других случаях было бы эффективнее развернуть новую инфраструктуру на K8s с нуля, но на наших объёмах это почти невозможно. Поэтому мы вложились в то, чтобы предусмотреть все нюансы взаимодействий существующих приложений и подготовку рабочих механизмов, вместо того, чтобы поднять новый красивый Кубер с дефолтными настройками и сказать разработке: «Заезжайте!»
Сейчас мы на пороге великой миграции из LXC в Kubernetes. Ждите продолжения через год-другой.




