
Нам важно, чтобы Авито стабильно и надёжно работал. Но бывает, что несмотря на наши усилия, что-то ломается. Это может быть железо или какой-то архитектурный компонент под высокой нагрузкой. В этом случае важно починить возникшую проблему как можно быстрее. Для этого у нас есть развесистая система мониторинга и алертов, а также служба круглосуточных дежурных.
Помимо того, чтобы быстро восстановить работу сервиса, важно избежать повторения проблем там, где это возможно. А там, где предотвратить аварии совсем нельзя, — минимизировать ущерб как для пользователей, так и для сотрудников.
Поэтому кроме круглосуточного мониторинга у нас есть процесс разбора инцидентов. И сами пожары на проде, и работы по анализу проблем мы называем live site review или LSR. Я отвечаю за часть работ с LSR после пожаротушения и хочу поделиться нашими наработками.

Минутка контекста
Авито — большая компания. На ноябрь 2020 года у нас:
- 1134 сервиса в продакшене.
- 58 команд разработки, в каждой из которых от одной до четырёх фиче-команд поменьше.
- 200-250 релизов изменений в день.
Но я думаю, что процессы проблем-менеджмента о которых расскажу дальше, легко адаптировать к компании любого размера.
Как устроен LSR-процесс
Работу с LSR в Авито начали в 2017 году. Процесс несколько раз менялся, и сейчас выглядит так:
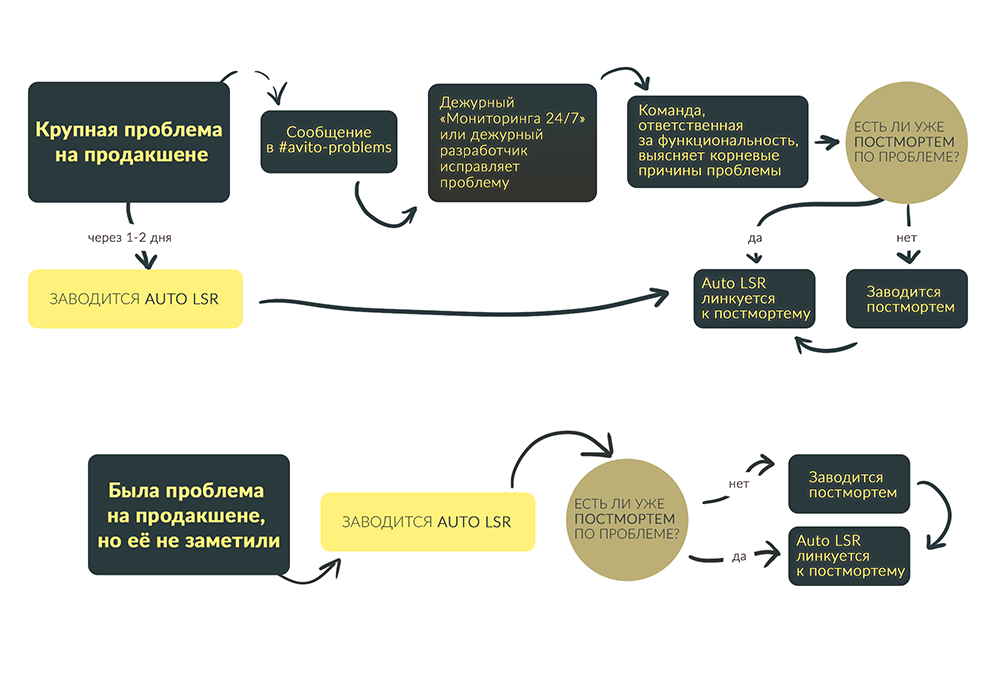
- Когда возникает проблема, дежурные видят её в системе мониторинга.
- Дежурные сами чинят проблему или привлекают ответственных от команд.
- Автоматика фиксирует в Jira продолжительность инцидента, затронутую функциональность и недополученную прибыль. Это называется Auto LSR. Автоматика же отмечает критичность инцидента в случае больших финансовых потерь или большого количества жалоб от пользователей.
- Мы заводим постмортем тикет в Jira c описанием проблемы, которая вызвала инцидент, если такого еще нет. К нему линкуются Auto LSR.
- Проводим встречу с командой и экспертами и детально разбираем проблему.
- Выполняем все нужные действия по предотвращению подобных инцидентов в будущем.
- Закрываем тикет и дополняем базу знаний.
Простые и понятные проблемы мы разбираем внутри команд или в слак-чатиках. А кросс-командные встречи проводим для серьёзных и бизнес-критичных проблем: инфраструктурных, процессных и тех, которые затронули сразу несколько команд. Встречи открытые, их анонс мы публикуем в отдельном канале, и прийти на них может любой человек в компании.
Как реагируем на инциденты
За работоспособностью всего Авито следит команда с названием «Мониторинг 24/7». Она всегда доступна и смотрит за всеми сервисами. Если случается «взрыв на проде», эта команда первой отправляется тушить пожар и привлекает дежурных разработчиков при необходимости.
Когда сбой устранили, ответственная за функциональность команда выясняет его корневые причины, и любой участник процесса заводит постмортем тикет.
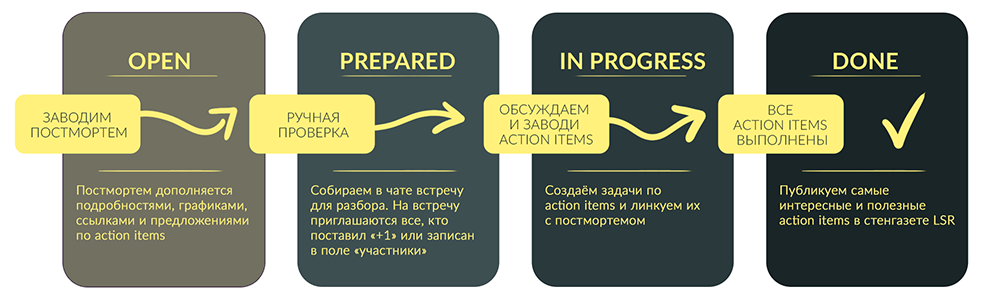
Что описываем в постмортем тикете
После того, как постмортем тикет заведен, его дополняют данными все желающие. В описание мы вносим любую информацию, которая кажется полезной. Есть единственное правило — описание должно быть таким, чтобы через полгода можно было прочитать и понять написанное. Например, если мы пишем о конкретном дне, то нужна точная дата — «22 сентября», а не «вчера». Если прикладываем ссылку на график, то следим, чтобы не потерялся таймстемп.
В постмортем тикете есть фиксированный набор полей.
Summary (обязательное) — это заголовок. Заголовок мы стараемся заполнять так, чтобы увидев его в календаре или в квартальном отчёте, можно было вспомнить, о чём идёт речь.
Description (обязательное) — здесь описываем суть проблемы, ключевую причину инцидента и любую другую информацию, которая может быть полезна при разборе. Также сюда команды пишут пожелания по разбору, например «обсудим сами внутри кластера» или «обязательно позовите на встречу Васю».
Priority (обязательное) — приоритет тикета. У нас их четыре:
- Critical — проблема из-за которой недоступен весь Авито.
- Major — проблема с высокой вероятностью повторения, недоступна часть функциональности.
- Normal — проблема с невысокой вероятностью повторения, недоступна часть функциональности.
- Minor — проблема с невысокой вероятностью повторения, недоступна часть функциональности без значимого ущерба для пользователей.
Slack link — ссылка на обсуждение инцидента в слаке. Если обсуждений было несколько в разных каналах, то в поле мы вносим наиболее ценное. Остальные в этом случае добавляем в Description.
Команда (обязательное) — проставляем сюда только одну команду, которая стала виновником торжества.
Пострадавшие сервисы — в этом поле перечисляем все сервисы, которые сломались, кроме того, где была ошибка. Поле нужно для того, чтобы видеть неявные зависимости сервисов и отмечать места, где нужно поработать над graceful degradation.
Участники — здесь указываем всех, кого стоит позвать на встречу с разбором инцидента. В их календари потом придёт приглашение.
Были ли раньше такие проблемы — когда заводится новый постмортем, в поле ставим «нет». Если происходит второй подобный инцидент, линкуем его тикет с постмортемом и меняем описание на «да».
Вероятность повторного возникновения ближайшие полгода — экспертная оценка того, кто заполняет тикет.
Action items — до проведения встречи пишем сюда идеи, предложения и пожелания по инциденту. Так при обсуждении LSR будет меньше шансов про них забыть. Во время обсуждения это поле редактируется.
Link from Helpdesk — добавляет саппорт, если были обращения пользователей.
HD count — количество пользователей, которые обратились с проблемами по инциденту в HelpDesk. Это поле заполняется и обновляется автоматически, если заполнено поле выше.
Продолжительность — абсолютное значение продолжительности инцидента в минутах.
Как разбираем инциденты на встречах
Когда пожар потушен и тикет заполнен, событие переходит в мою зону ответственности. Я внимательно смотрю на него и разбираюсь, что происходило, медленно или быстро мы нашли проблему, позвали дежурные сразу тех, кого нужно, или сначала разбудили непричастных. Я проверяю, хватило ли нам графиков для анализа ситуации, что было написано в логах.
После я создаю встречу для разбора в специальном LSR-календаре. Во встречах участвуют команды, в сервисе которых возникла проблема, те, кто её устранял, и эксперты по технологиям, в которых проявилась проблема.
На разборах постмортемов мы оцениваем влияние инцидента на работу компании, смотрим на проблему с разных сторон и вырабатываем по ней решение. Если предотвратить возникновение проблемы в будущем невозможно, то придумываем, как уменьшить потери от её возникновения. Обычно я заранее обозначаю повестку встречи, и мы идём по списку подготовленных вопросов.
Вот список типовых вопросов, которые стоит обсудить при разборе LSR:
- В чём была проблема и какова её первопричина? Если это баг в коде, то полезно посмотреть на процессы тестирования и понять почему его не поймали. Если сбой произошёл из-за возросшей нагрузки, то стоит подумать про регулярное нагрузочное тестирование.
- Как быстро и откуда узнали о проблеме? Можно ли узнавать быстрее? Возможно, нужны дополнительные мониторинги или алерты. Или стоит отдать отдать имеющиеся команде мониторинга 24/7.
- Как быстро смогли понять, в чём именно проблема? Возможно, стоит почистить Sentry или добавить логирование.
- Затронула ли проблема основную функциональность сайта и можно ли уменьшить такое влияние? Например, если сломался счётчик количества объявлений, то страницы сайта ломаться не должны. Тут стоит подумать про graceful degradation.
- Может ли проблема повториться в других модулях или компонентах системы? Что сделать, чтобы этого не произошло? Например, актуализировать таймауты, добавить обработку долгого ответа.
- Есть ли платформенное решение, которое помогает избегать таких проблем? Возможно пора начать им пользоваться? В решении таких проблем часто помогают тестохранилка или PaaS.
- Может ли необходимые для решения проблемы действия сделать команда или нужен отдельный проект, объединяющий несколько команд?
Основная ценность, которую мы получаем от встреч — это action items, то есть действия, направленные на то, чтобы проблема не возникала в дальнейшем или чтобы мы раньше её замечали и быстрее чинили. Это могут быть как правки в коде, так и проекты по улучшения инструментов или процессов, предложения новых best practices и информационные рассылки на всю инженерную команду.
Хорошие action items:
- могут быть задачей или проектом, но не процессом;
- всегда имеют ответственного и ожидаемый срок завершения;
- будут сделаны в ближайшие полгода.
Плохие action items:
- похожи на высказывания Капитана Очевидность, например: «нужно лучше тестировать» или «перестать делать глупые баги»;
- точно не будут сделаны в ближайшие полгода.
Мы договариваемся о кусочках, которые надо сделать обязательно, и таких, которые сделать желательно. Когда action items сформулированы, мы заносим их в Jira — это тикеты в разных проектах, слинкованные с постмортемом. В начале описания необязательных задач ставим вопросительный знак, чтобы их можно было сразу отличить. По остальным считаем, что их желательно сделать в течение месяца. Чтобы это работало, я отдельно слежу за выполнением всех action items и периодически прохожусь с напоминаниями по людям, которым они назначены.
Как ведём базу знаний
Самые интересные или общественно полезные постмортемы и список рекомендаций по ним я вношу в базу знаний. Я их отбираю вручную и раз в две недели публикую в общем канале разработки под заголовком «стенгазета LSR». Все выпуски стенгазеты также собраны в Сonfluence, чтобы можно было быстро найти, как решались те или иные инциденты.
Благодаря стенгазете многие делают исправления в своих сервисах до того, как они сломались. В итоге LSR с одними и теми же причинами в разных командах становится заметно меньше.
А ещё по LSR можно строить любопытную аналитику
Кроме того у нас есть много графиков по LSR: по причинам, виновникам, пострадавшим сервисам, продолжительности, времени возникновения, времени суток. В них я ищу тренды и совпадения. Например, если какой-то сервис падает при любой неисправности любого стороннего сервиса, стоит поработать над его стабильностью: переделать, где возможно, обращения на асинхронные, добавить graceful degradation, может быть, увеличить пул ресурсов.
Лирическое заключение
Проблем-менеджемент в Авито — часть контроля качества. А в контроле качества есть два основополагающих вопроса: когда начать тестировать и когда закончить тестировать. Если по поводу того, когда начать, существует много разных подходов, то с тем, когда закончить, всё ещё сложнее.
Протестировать абсолютно всё нереально, поэтому в какой-то момент надо сказать, что мы протестировали достаточно хорошо, и остановиться. А что такое «достаточно хорошо»? Если в релизе нашли 100 багов — это достаточно? А если из багов 20 критичных, 50 средних, а остальные некритичные — это достаточно хорошо или недостаточно? Проблема в том, что ответ на самом деле зависит не от того, сколько багов нашли, а от того, сколько не нашли тестировщики, но заметят пользователи.
С помощью LSR я считаю те баги, которые помешали пользователям. Мы получаем некую финальную точку в контроле качества, с которой видно весь цикл разработки как он есть. И сразу становится понятно, куда прийти с отверткой и подкрутить.




