
За последние несколько лет в обучении с подкреплением (reinforcement learning, RL) произошли серьезные прорывы: от первого успешного его использования в обучении по сырым пикселям до обучения Open AI роборуки, ― и для дальнейшего прогресса становятся необходимы все более сложные среды, в чем на помощь приходит Unity.
Инструмент Unity ML-Agents ― это новый плагин в игровом движке Unity, позволяющий использовать Unity как конструктор среды для обучения МО-агентов.
От игры в футбол до ходьбы, прыжков со стен и обучения ИИ собаки игре с палкой, Unity ML-Agents Toolkit предоставляет широкий спектр условий для тренировки агентов.
В этой статье мы рассмотрим, как работают МО-агенты Unity, а затем научим одного из таких агентов перепрыгивать через стены.
Unity ML-Agents ― новый плагин для игрового движка Unity, позволяющий создавать или использовать готовые среды для обучения наших агентов.
Плагин состоит из трех компонентов:

Первый ― это Среда обучения (Learning Environment), содержащая сцену Unity и элементы среды.
Второй ― Python API, в котором расположены алгоритмы RL (такие как PPO ― Proximal Policy Optimization и SAC ― Soft Actor-Critic). Мы используем этот API для запуска обучения, тестирования и т. д. Он связан со средой обучения через третий компонент ― внешний коммуникатор.
Учебный компонент состоит из различных элементов:
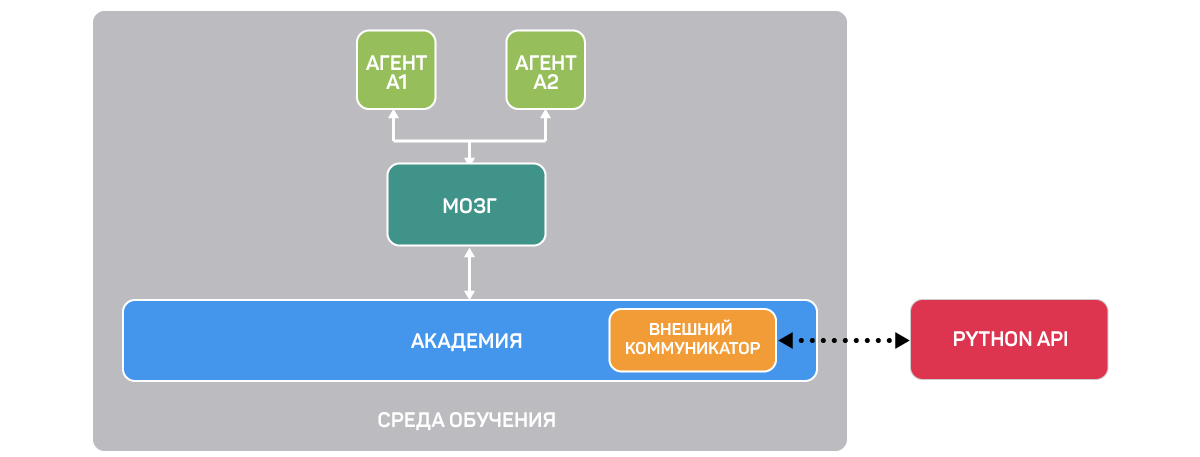
Первый агент ― актер сцены. Именно его мы будем тренировать, оптимизируя компонент под названием «мозг» (Brain), в котором записано, какие действия необходимо совершать в каждом из возможных состояний.
Третий элемент ― Академия (Academy) ― управляет агентами и процессом принятия ими решений и обрабатывает запросы от API Python. Чтобы лучше понять его роль, давайте вспомним процесс RL. Его можно представить как цикл, который работает следующим образом:

Допустим, агенту нужно научиться играть в платформер. Процесс RL в таком случае будет выглядеть так:
Этот цикл RL образует последовательность из состояния, действия и награды. Цель агента — максимизировать ожидаемое совокупное вознаграждение.
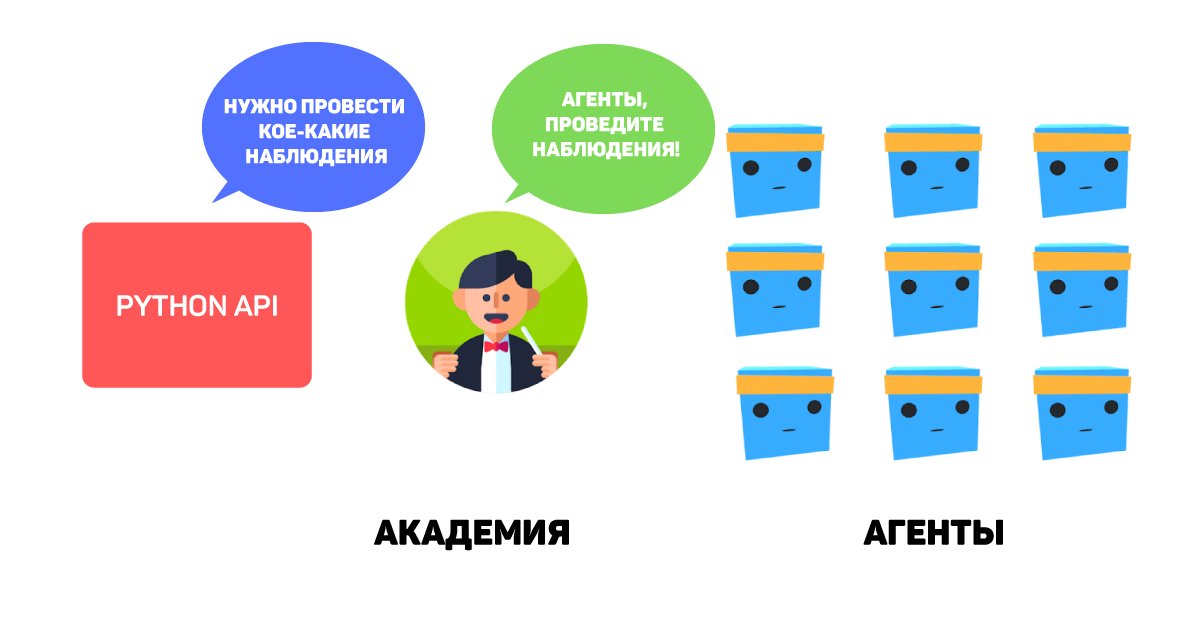
Таким образом, Academy отправляет инструкции агентам и обеспечивает синхронизацию в их выполнении, а именно:
Теперь, когда мы знаем, как работают агенты Unity, обучим такового прыгать через стены.
Уже обученные модели также можно скачать на GitHub.
Цель этой среды ― научить агента доходить до зеленой плитки.
Рассмотрим три случая:
1. Стен нет, и нашему агенту нужно просто дойти до плитки.

2. Агенту нужно научиться прыгать, чтобы достичь зеленой плитки.

3. Самый сложный случай: стена слишком высока, чтобы агент мог ее перепрыгнуть, поэтому ему нужно сначала запрыгнуть на белый блок.

Научим агента двум сценариям поведения в зависимости от высоты стены:
Так будет выглядеть система вознаграждений:

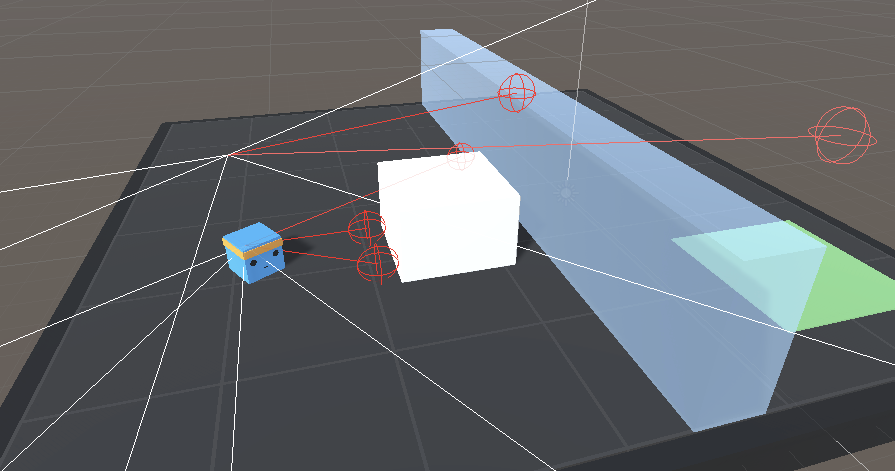
В своих наблюдениях мы используем не обычный кадр, а 14 рейкастов, каждый из которых может обнаружить 4 возможных объекта. В данном случае рейкасты можно воспринимать как лазерные лучи, способные определить, проходят ли они через объект.
Также будем использовать в своей программе глобальную позицию агента.
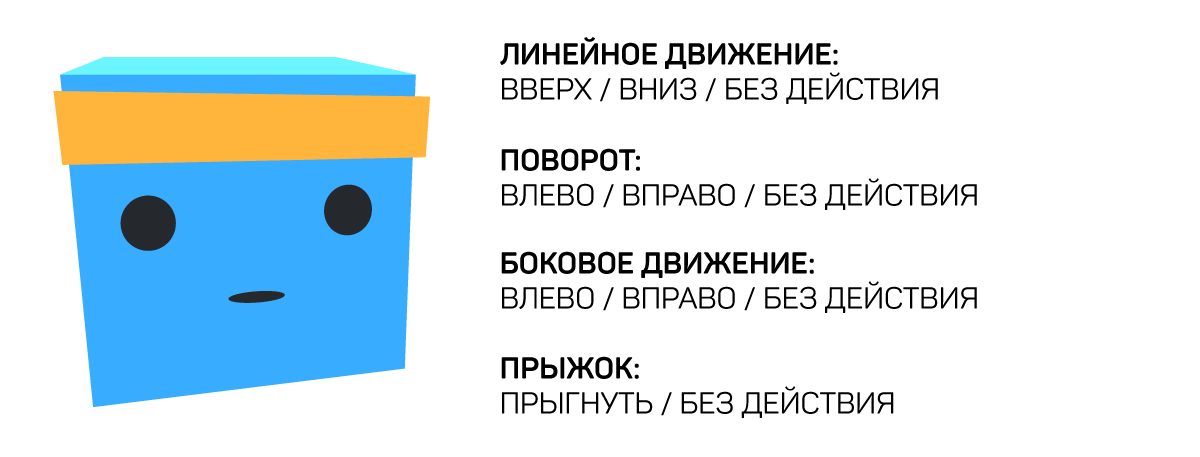
В нашем пространстве возможны четыре варианта действий:
Цель ― достичь зеленой плитки со средним вознаграждением 0,8.
Прежде всего, откроем проект UnitySDK.
Среди примеров нужно найти и открыть сцену WallJump.
Как можно увидеть, на сцене располагается множество агентов, каждый из которых берется из одного и того же префаба, и у всех у них один и тот же «мозг».

Как и в случае классического глубокого обучения с подкреплением (Deep Reinforcement Learning), после того как мы запустили несколько экземпляров игры (например, 128 параллельных сред), теперь мы просто копируем и вставляем агентов, чтобы иметь больше различных состояний. И поскольку мы хотим обучить нашего агента с нуля, в первую очередь нам нужно удалить у агента «мозг». Для этого необходимо перейти в папку prefabs и открыть Prefab.
Далее в иерархии Prefab нужно выбрать агента и перейти в настройки.
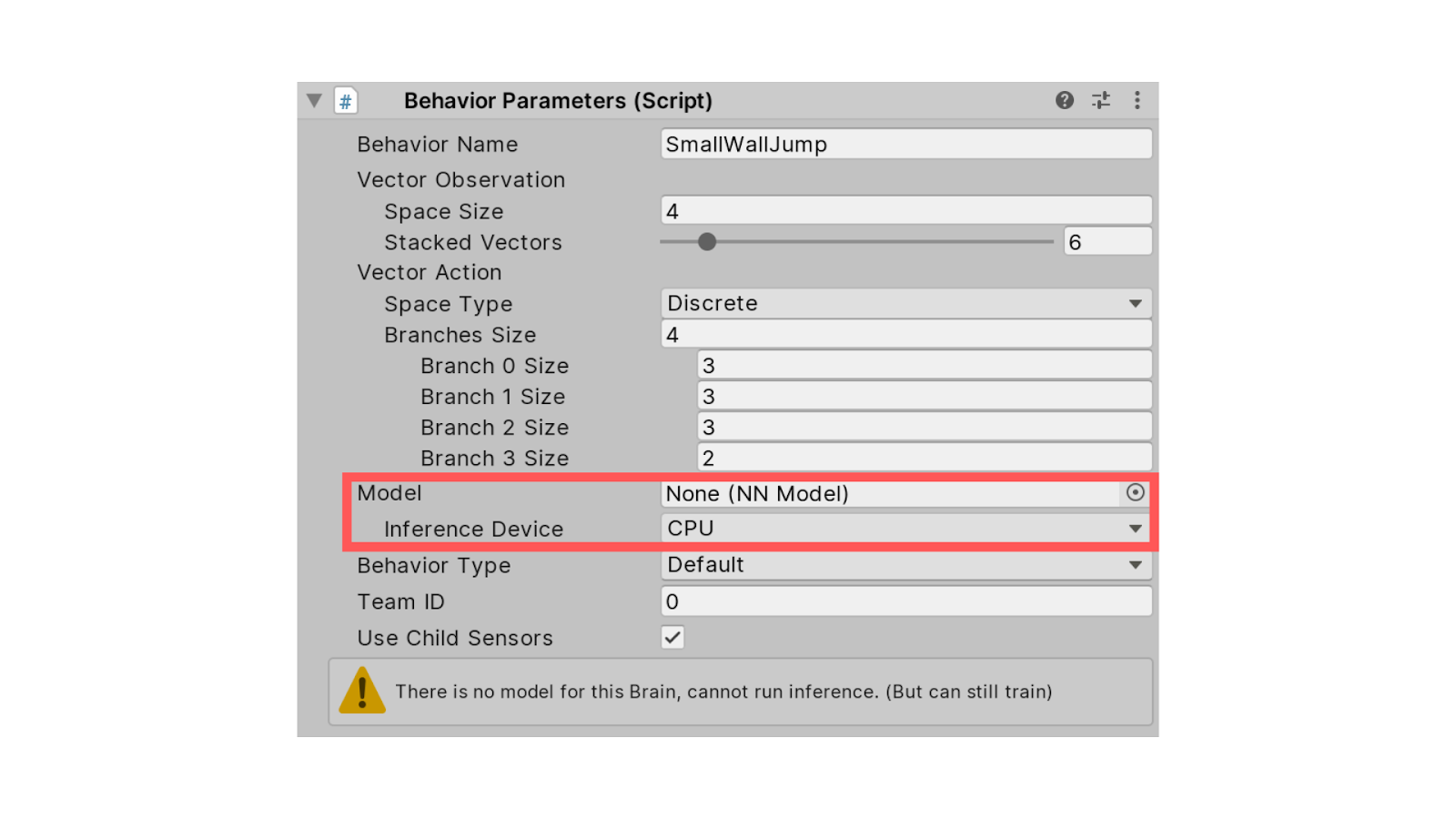
В параметрах поведения (Behavior Parameters) нужно удалить модель. Если в нашем распоряжении несколько графических процессоров, можно использовать Inference Device из CPU в качестве GPU.
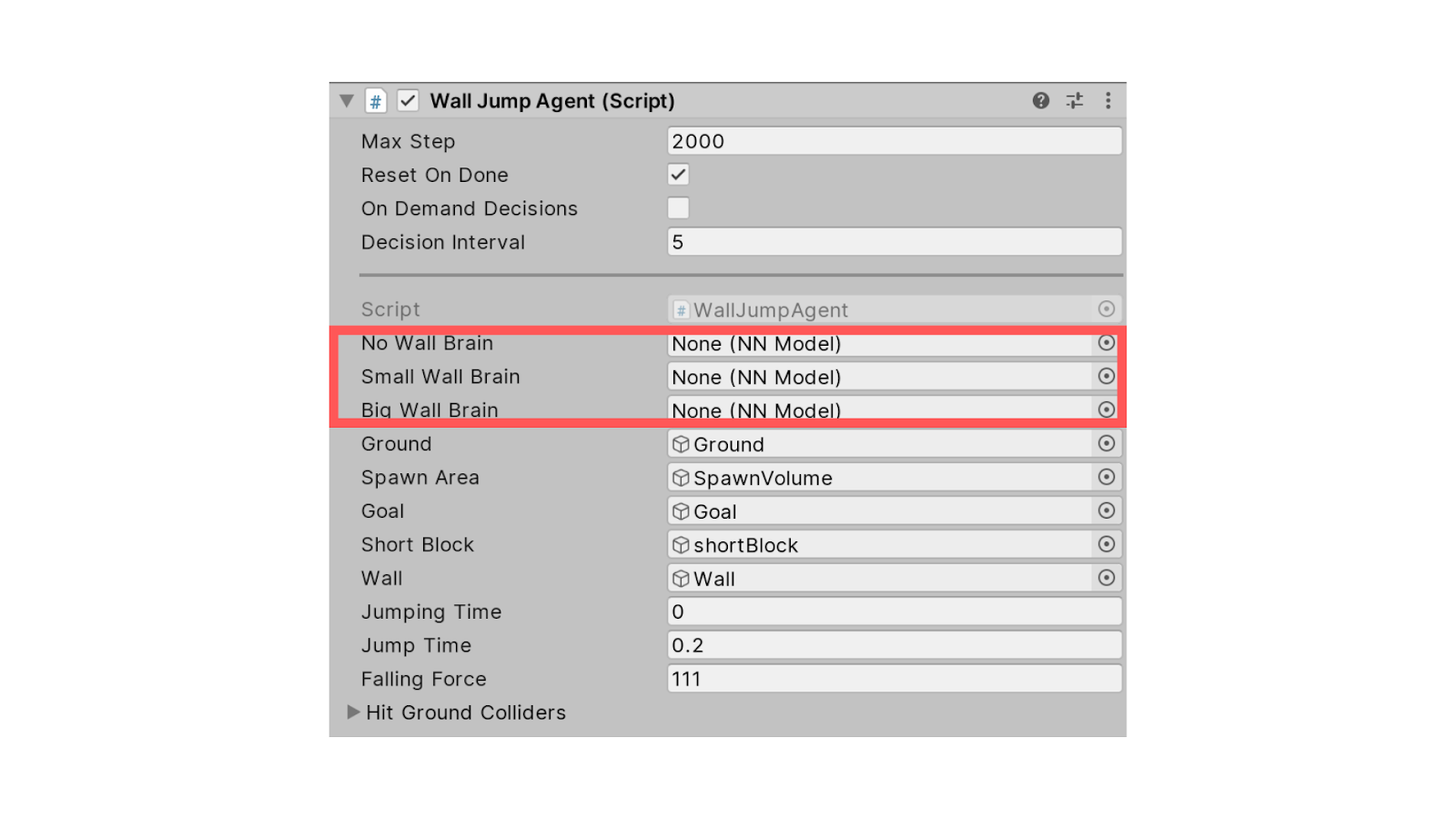
В компоненте Wall Jump Agent необходимо удалить Brains для случая с отсутствием стен, а также для низких и высоких стен.
После этого можно начать обучать своего агента с нуля.
Для своего первого обучения просто изменим общее число шагов обучения для двух сценариев поведения: SmallWallJump и BigWallJump. Так мы сможем достичь цели всего за 300 тысяч шагов. Для этого в config / trainer config.yaml изменим max_steps на 3e5 для случаев SmallWallJump и BigWallJump.

Чтобы обучить нашего агента, будем использовать PPO (Proximal Policy Optimization). Алгоритм включает в себя накопление опыта взаимодействия с окружающей средой и использование его для обновления политики принятия решений. После ее обновления предыдущие события отбрасываются, а последующий сбор данных осуществляется уже на условиях обновленной политики.
Итак, сначала при помощи API Python нам нужно вызвать внешний коммуникатор, чтобы он дал Academy команду к запуску агентов. Для этого необходимо открыть терминал, где находится ml-agents-master, и набрать в нем:
Эта команда попросит запустить сцену Unity. Для этого нужно нажать ► в верхней части редактора.
Наблюдать за тренировками своих агентов можно в Tensorboard при помощи следующей команды:
Когда обучение закончится, нужно переместить сохраненные файлы моделей, содержащиеся в ml-agents-master / models, в UnitySDK / Assets / ML-Agents / examples / WallJump / TFModels. Затем снова откроем редактор Unity и выберем сцену WallJump, где откроем готовый объект WallJumpArea.
После этого выберем агента и в его параметрах поведения перетащим файл SmallWallJump.nn в Model Placeholder.
Также переместим:
После этого нажмем кнопку ► в верхней части редактора и готово! Алгоритм настройки обучения агентов завершен.
Лучший способ обучения ― постоянно пытаться привнести что-то новое. Теперь, когда мы уже добились хороших результатов, попробуем поставить некоторые гипотезы и проверить их.
Итак, мы знаем, что:
Идея этого эксперимента заключается в том, что, если мы увеличим скидку, уменьшив гамму с 0,99 до 0,95, приоритетным для агента станет краткосрочное вознаграждение ― что, возможно, поможет ему быстрее приблизиться к оптимальной политике поведения.
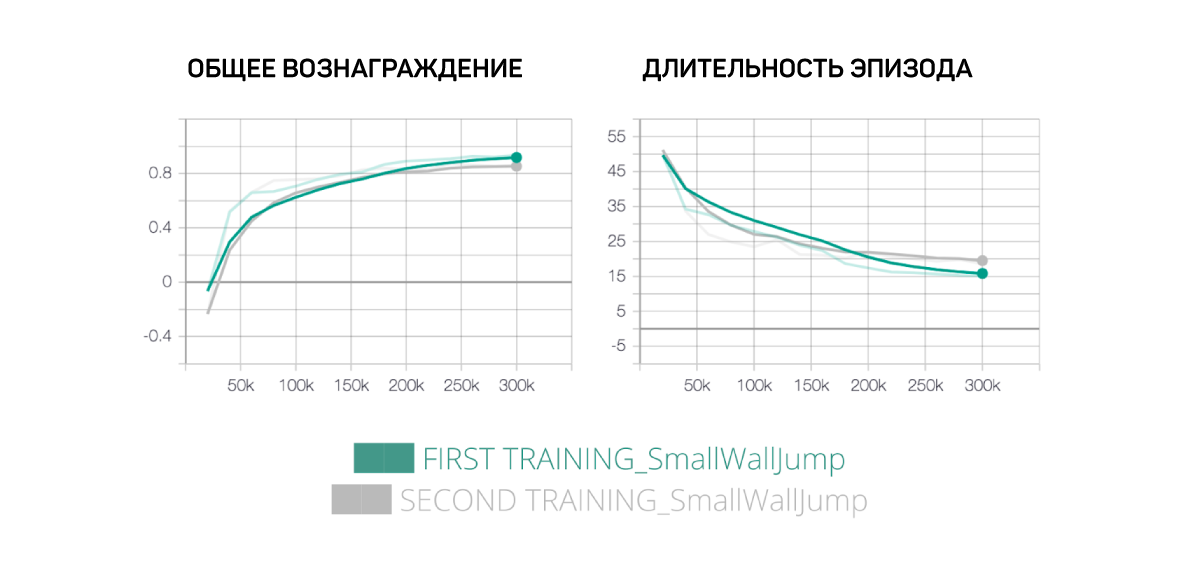
Что интересно, в случае прыжка через невысокую стену агент будет стремиться к тому же результату. Это можно объяснить тем, что данный случай довольно простой: агенту нужно лишь двигаться к зеленой плитке и при необходимости прыгать, если впереди находится стена.
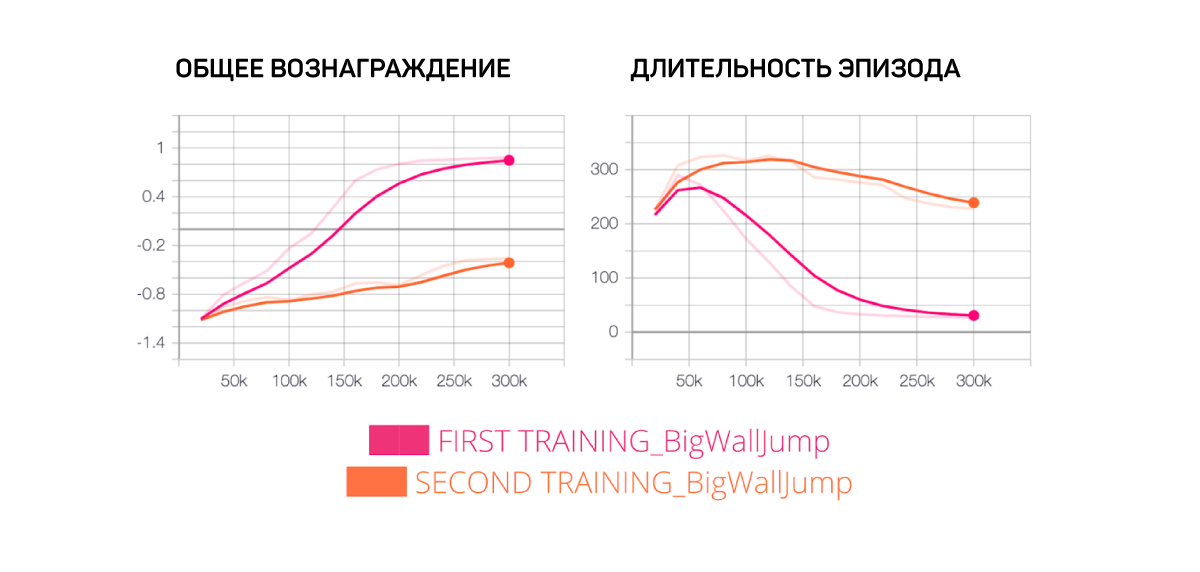
С другой стороны, в случае с Big Wall Jump это работает хуже, поскольку наш агент больше заботится о краткосрочной награде и поэтому не понимает, что ему нужно забраться на белый блок, чтобы перепрыгнуть через стену.
Напоследок выдвинем гипотезу о том, станет ли наш агент умнее, если мы увеличим сложность нейронной сети. Для этого увеличим размер скрытого уровня с 256 до 512.
И обнаружим, что в этом случае новый агент работает хуже, чем наш первый агент. Это означает, что нам нет смысла увеличивать сложность нашей сети, потому что иначе увеличится и время обучения.
Итак, мы обучили агента перепрыгивать через стены, и сегодня на этом все. Напомним, что для сравнения результатов обученные модели можно скачать по ссылке.

Инструмент Unity ML-Agents ― это новый плагин в игровом движке Unity, позволяющий использовать Unity как конструктор среды для обучения МО-агентов.
От игры в футбол до ходьбы, прыжков со стен и обучения ИИ собаки игре с палкой, Unity ML-Agents Toolkit предоставляет широкий спектр условий для тренировки агентов.
В этой статье мы рассмотрим, как работают МО-агенты Unity, а затем научим одного из таких агентов перепрыгивать через стены.
Что же такое Unity ML-Agents?
Unity ML-Agents ― новый плагин для игрового движка Unity, позволяющий создавать или использовать готовые среды для обучения наших агентов.
Плагин состоит из трех компонентов:
Первый ― это Среда обучения (Learning Environment), содержащая сцену Unity и элементы среды.
Второй ― Python API, в котором расположены алгоритмы RL (такие как PPO ― Proximal Policy Optimization и SAC ― Soft Actor-Critic). Мы используем этот API для запуска обучения, тестирования и т. д. Он связан со средой обучения через третий компонент ― внешний коммуникатор.
Из чего состоит среда обучения
Учебный компонент состоит из различных элементов:
Первый агент ― актер сцены. Именно его мы будем тренировать, оптимизируя компонент под названием «мозг» (Brain), в котором записано, какие действия необходимо совершать в каждом из возможных состояний.
Третий элемент ― Академия (Academy) ― управляет агентами и процессом принятия ими решений и обрабатывает запросы от API Python. Чтобы лучше понять его роль, давайте вспомним процесс RL. Его можно представить как цикл, который работает следующим образом:
Допустим, агенту нужно научиться играть в платформер. Процесс RL в таком случае будет выглядеть так:
- Агент получает состояние S0 из среды — это будет первым кадром нашей игры.
- На основании состояния S0 агент выполняет действие A0 и смещается вправо.
- Среда переходит в новое состояние S1.
- Агент получает награду R1 за то, что он не мертв (Позитивная награда +1).
Этот цикл RL образует последовательность из состояния, действия и награды. Цель агента — максимизировать ожидаемое совокупное вознаграждение.
Таким образом, Academy отправляет инструкции агентам и обеспечивает синхронизацию в их выполнении, а именно:
- Сбор наблюдений;
- Выбор действия в соответствии с заложенными инструкциями;
- Выполнение действия;
- Сброс в том случае, если количество шагов исчерпано или цель достигнута.
Учим агента прыгать через стены
Теперь, когда мы знаем, как работают агенты Unity, обучим такового прыгать через стены.
Уже обученные модели также можно скачать на GitHub.
Среда для обучения прыжкам на стену
Цель этой среды ― научить агента доходить до зеленой плитки.
Рассмотрим три случая:
1. Стен нет, и нашему агенту нужно просто дойти до плитки.
2. Агенту нужно научиться прыгать, чтобы достичь зеленой плитки.
3. Самый сложный случай: стена слишком высока, чтобы агент мог ее перепрыгнуть, поэтому ему нужно сначала запрыгнуть на белый блок.
Научим агента двум сценариям поведения в зависимости от высоты стены:
- SmallWallJump в случаях без стен или при малой высоте стены;
- BigWallJump в случае с высокими стенами.
Так будет выглядеть система вознаграждений:
В своих наблюдениях мы используем не обычный кадр, а 14 рейкастов, каждый из которых может обнаружить 4 возможных объекта. В данном случае рейкасты можно воспринимать как лазерные лучи, способные определить, проходят ли они через объект.
Также будем использовать в своей программе глобальную позицию агента.
В нашем пространстве возможны четыре варианта действий:
Цель ― достичь зеленой плитки со средним вознаграждением 0,8.
Итак, приступим!
Прежде всего, откроем проект UnitySDK.
Среди примеров нужно найти и открыть сцену WallJump.
Как можно увидеть, на сцене располагается множество агентов, каждый из которых берется из одного и того же префаба, и у всех у них один и тот же «мозг».
Как и в случае классического глубокого обучения с подкреплением (Deep Reinforcement Learning), после того как мы запустили несколько экземпляров игры (например, 128 параллельных сред), теперь мы просто копируем и вставляем агентов, чтобы иметь больше различных состояний. И поскольку мы хотим обучить нашего агента с нуля, в первую очередь нам нужно удалить у агента «мозг». Для этого необходимо перейти в папку prefabs и открыть Prefab.
Далее в иерархии Prefab нужно выбрать агента и перейти в настройки.
В параметрах поведения (Behavior Parameters) нужно удалить модель. Если в нашем распоряжении несколько графических процессоров, можно использовать Inference Device из CPU в качестве GPU.
В компоненте Wall Jump Agent необходимо удалить Brains для случая с отсутствием стен, а также для низких и высоких стен.
После этого можно начать обучать своего агента с нуля.
Для своего первого обучения просто изменим общее число шагов обучения для двух сценариев поведения: SmallWallJump и BigWallJump. Так мы сможем достичь цели всего за 300 тысяч шагов. Для этого в config / trainer config.yaml изменим max_steps на 3e5 для случаев SmallWallJump и BigWallJump.
Чтобы обучить нашего агента, будем использовать PPO (Proximal Policy Optimization). Алгоритм включает в себя накопление опыта взаимодействия с окружающей средой и использование его для обновления политики принятия решений. После ее обновления предыдущие события отбрасываются, а последующий сбор данных осуществляется уже на условиях обновленной политики.
Итак, сначала при помощи API Python нам нужно вызвать внешний коммуникатор, чтобы он дал Academy команду к запуску агентов. Для этого необходимо открыть терминал, где находится ml-agents-master, и набрать в нем:
mlagents-learn config/trainer_config.yaml — run-id=”WallJump_FirstTrain” — trainЭта команда попросит запустить сцену Unity. Для этого нужно нажать ► в верхней части редактора.
Наблюдать за тренировками своих агентов можно в Tensorboard при помощи следующей команды:
tensorboard — logdir=summariesКогда обучение закончится, нужно переместить сохраненные файлы моделей, содержащиеся в ml-agents-master / models, в UnitySDK / Assets / ML-Agents / examples / WallJump / TFModels. Затем снова откроем редактор Unity и выберем сцену WallJump, где откроем готовый объект WallJumpArea.
После этого выберем агента и в его параметрах поведения перетащим файл SmallWallJump.nn в Model Placeholder.
Также переместим:
- SmallWallJump.nn в No Wall Brain Placeholder.
- SmallWallJump.nn в Small Wall Brain Placeholder.
- BigWallJump.nn в No Wall Brain Placeholder.
После этого нажмем кнопку ► в верхней части редактора и готово! Алгоритм настройки обучения агентов завершен.
Время экспериментов
Лучший способ обучения ― постоянно пытаться привнести что-то новое. Теперь, когда мы уже добились хороших результатов, попробуем поставить некоторые гипотезы и проверить их.
Снижение коэффициента дисконтирования до 0,95
Итак, мы знаем, что:
- Чем больше гамма, тем меньше скидка. То есть, агент больше заботится о долгосрочном вознаграждении.
- С другой стороны, чем меньше гамма, тем больше скидка. В таком случае в приоритете агента краткосрочное вознаграждение.
Идея этого эксперимента заключается в том, что, если мы увеличим скидку, уменьшив гамму с 0,99 до 0,95, приоритетным для агента станет краткосрочное вознаграждение ― что, возможно, поможет ему быстрее приблизиться к оптимальной политике поведения.
Что интересно, в случае прыжка через невысокую стену агент будет стремиться к тому же результату. Это можно объяснить тем, что данный случай довольно простой: агенту нужно лишь двигаться к зеленой плитке и при необходимости прыгать, если впереди находится стена.
С другой стороны, в случае с Big Wall Jump это работает хуже, поскольку наш агент больше заботится о краткосрочной награде и поэтому не понимает, что ему нужно забраться на белый блок, чтобы перепрыгнуть через стену.
Увеличение сложности нейронной сети
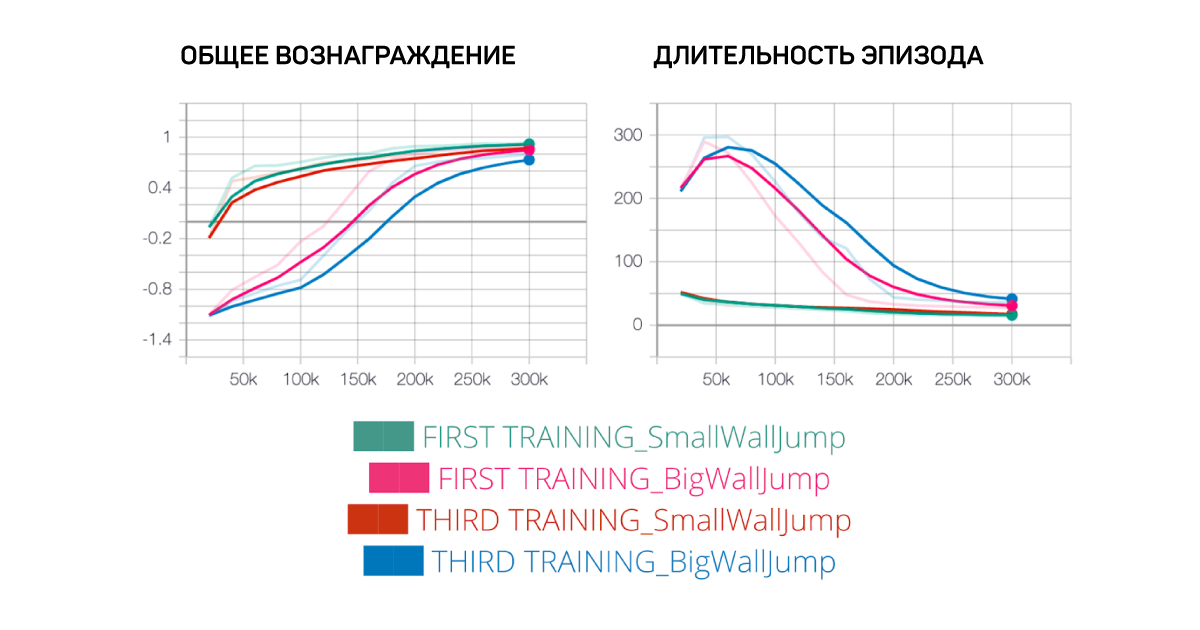
Напоследок выдвинем гипотезу о том, станет ли наш агент умнее, если мы увеличим сложность нейронной сети. Для этого увеличим размер скрытого уровня с 256 до 512.
И обнаружим, что в этом случае новый агент работает хуже, чем наш первый агент. Это означает, что нам нет смысла увеличивать сложность нашей сети, потому что иначе увеличится и время обучения.
Итак, мы обучили агента перепрыгивать через стены, и сегодня на этом все. Напомним, что для сравнения результатов обученные модели можно скачать по ссылке.



