
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
TL;DR: Нет

На просторах Сети полным полно материалов, мануалов, готовых решений, сборок и прочего добра, посвященного прогнозированию цен на криптовалютные и традиционные биржевые активы, пахнущего быстрыми и легкими доходами с минимумом усилий. И хоть пишут их разные люди, с разными подходами, на разных платформах и с разными парадигмами, у них всех есть один неизменный общий атрибут — они не работают.
Почему? Давайте разбираться.
Давайте знакомиться, меня зовут Денис и, в свободное время, я занимаюсь исследованиями в области искусственного интеллекта и, в частности, искусственных нейронных сетей.
В данном материале я постараюсь описать проблемы,с которыми сталкиваются которые создают себе начинающие исследователи искусственных нейронных сетей в погоне за финансовой независимостью, тратя драгоценное время с околонулевым КПД.
Я надеюсь, что, в рамках данной статьи, получится выдержать достаточный баланс между сложностью материала и легкостью восприятия, дабы текст был в меру прост, понятен и интересен как людям, не связанным с данным поприщем, так и тем, кто давно занимается исследованиями проблем в этой отрасли. Сразу говорю, формул тут не будет, специфичной терминологии тоже по минимуму.
Я не работаю в Google. У меня нет двадцати научных степеней. Я не стажировался в NASA. Я не учился в Стэнфорде и горько сожалею об этом. Однако, я, все же, надеюсь, что понимаю, о чем говорю, когда речь идет о системах прогнозирования и, при этом, я довольно тесно связан с криптовалютным миром в общем и проектом Cardano в частности.
Разумеется, меня, как криптоэнтузиаста, занимающегося нейросетями, просто не могло не занести в туманную область применения ИИ касательно криптовалют.

Как было сказано ранее, материалов, вроде даже проработанных и, на первый взгляд, глубоких, с примерами, на эту тему столько, что глаза разбегаются. А авторы настолько уверены в том, что их эксперимент, в отличие от предыдущих нескольких сотен, успешен, что даже удивляешься, почему очередная статья не заканчивается фотографиями с «ламбой» на личном острове, а список авторов «kaggle kernels», связанных с прогнозированием цен на биткоины, не дублирует списки Forbes.
Ожидаемо, что и на Хабре есть статьи, посвященные этим вопросам. И, что интересно, независимо от места и языка публикации, все эти статьи заканчиваются примерно одинаковым текстом «Ну вот, результат вполне неплохой, все почти работает, надо просто докрутить немного гиперпараметры и все будет здорово».
И, дабы не быть голословным, вот примеры подобных статей: раз, два, три.
Идея предсказания новых цен по старым далеко не нова. На самом деле, это касается не только криптовалют. Так уж вышло, что лично мне они ближе, но, родина того, что называют «техническим анализом» — это, все-таки традиционные биржи. Те самые, где, если верить фильмам, все в дорогих костюмах, но при этом орут как девочки на концерте любимой группы.
Пытаясь увидеть будущее по прошлому, люди наизобретали огромное количество всевозможных хитрых осцилляторов, индикаторов, сигнализаторов, основанных на мат.статистике, теории вероятности и, порой, откровенной парейдолии.
Самое популярное, пожалуй, это поиск фигур. Пятнадцать минут чтения интернета и хоть сейчас на Уолл-стрит! Это ведь так просто — надо лишь на графике найти «голову Барта Симпсона», «бабочку», «флажок(не путать с клином!11)», «лазурь, падающую в вакуумную вертихвостку», построить много-много линий и, совершенно непредвзято, истолковать это в свою пользу!

У почти всех этих решений есть один небольшой, но очень плотный и тяжелый недостаток — они прекрасно фиксируют тренды...постфактум. А если что-то заявлено, как не фиксирующее, а предсказывающее, то оно трактуется настолько вольно, что десять человек, глядя на один и тот же график с одним и тем же индикатором, дадут десять независимых прогнозов. И, что характерно, хотя бы один из них, скорее всего будет прав!
Но это будет установлено тоже постфактум. А остальные просто скажут «а, ну мы по невнимательности неправильно прочитали сигналы».
Не поймите меня неправильно. Вполне допустимо, что реальный трейдер с Уолл-стрит, у которого за плечами лет 20 криков и штук 200 попыток суицида, скорее всего может наложить друг на друга пачку индикаторов и осцилляторов и, как оператор из фильма «Матрица», одним взглядом прочитать там полезные данные, сдобренные достаточно высоким мат.ожиданием успешной сделки. Я даже допускаю, что конкретно Ты, читатель, тоже так умеешь. Без капли сарказма, вполне допускаю. В конце концов зачем-то же их придумывают, улучшают, эти индикаторы…
Году к 2015 нейросети уже были у всех на слуху. Розенблатт даже не представлял, насколько они будут на слуху. Благодаря ответственным, профессиональным, разбирающимся в вопросе СМИ, человечество узнало, что нейросети — это самая что ни на есть электронная версия человеческого мозга, способная быстрее и лучше решить любую задачу, обладающая неограниченным потенциалом и вообще, вот вот и через сингулярность перемахнем прямо в светлое/мрачное будущее. Тут уж как повезет.
Но было одно «но». До поры до времени, нейросети обитали только в заповедных математических пакетах, в очень очень низкоуровневом виде, теша математиков и ученых графиками в MatLab-ах.
Но популяризация сделала свое дело и привлекла в отрасль очень много внимания разработчиков разной степени независимости. Эти самые разработчики, будучи, в отличие от обычных математиков, людьми, наделенными благородной ленью, стали изыскивать способы накинуть несколько уровней абстракции на это дело, облегчая жизнь себе и всем желающим, явив миру весьма удобный и качественный высокоуровневый инструментарий вроде Keras или FANN. В этом рвении они преуспели настолько, что довели работу с нейросетями до уровня «просто раз и работает», открыв дорогу в мир чудес и волшебства для всех желающих.
Именно чудес и волшебства, а не математики и фактов.

Нейросети стали доступны, близки и легко используемы для всех и каждого. Серьезно, реализация FANN есть даже для PHP. Более того, входит в список базовых расширений.
А Keras? В 10 строчек можно собрать рекуррентно-сверточную сеть, не понимая ни как работают свертки, ни чем отличается LSTM от GRU! Искусственный интеллект для всех и каждого! И пусть никто не уйдет обиженным!
Думаю, отчасти, самую злую шутку сыграла терминология. Как называют выходы нейросети? Ага. Predictions. Предсказания. Нейросеть предсказывает одни данные по другим. Звучит ну прямо как то, что нужно.
Руководства для высокоуровневых библиотек оберегают пользователя от сложных терминов, матриц, векторов, преобазований, дифференциальных исчислений, математических смыслов этих вот градиентов, регрессий и регуляризационных потерь.
А, самое главное, оберегают романтический образ «электронной модели человеческого мозга, способной на все» от суровой реальности, в которой нейросети — это просто аппроксиматор, являющийся, грубо говоря, не более чем эволюционным шагом на ступеньку вверх от обычного линейного классификатора.
Но это не имеет значения, когда собираешь по листингам из документации свой первый решатель для CIFAR-10, не прилагая никаких усилий, не понимая даже толком, что происходит. В уме лишь одна мысль:

Вот оно, технологическое чудо! Ты просто даешь ему на вход одни данные, на выход другие, а оно само находит связь и учится предсказывать выходы по входам. Сколько проблем можно решить! Сколько задач можно нивелировать!
Столько всего можно предсказать! Интересно, а другие люди вообще в курсе? С этим инструментарием мои возможности безграничны! БЕЗГРАНИЧНЫ!

А что если накормить нейросеть свечами с криптобиржи/фондовой биржи/форекса, на выход подавая ей свечу со следующего временного промежутка? Она ведь научится тогда предсказывать новые значения по предыдущим! Ведь это то, для чего она была сделана! Нейросеть может предсказать что угодно, были бы данные, а данных по истории котировок пруд пруди! О, озарение, лишь миг, но столь прекрасный!
Потому что в реальном мире, который отличается от мира, создаваемого СМИ, это так не работает. Нейросети не являются машиной для предсказаний. Нейросети — это аппроксиматоры. Очень хорошие аппроксиматоры. Считается, что нейросети могут аппроксимировать практически что угодно. При одном лишь условии — если это «что-то» поддается аппроксимации.
И тут-то начинающий исследователь и попадается на крючок когнитивных искажений. Первая и главная ошибка в том, что исторические данные по котировкам кажутся чем-то большим, чем просто статистикой. По ним можно нарисовать столько треугольников и стрелочек постфактум, что только слепому при взгляде на это будет неочевидно, что в этом всем есть некая логика, которую просто не удалось вовремя считать. Но которую, возможно, познает Машина.
Глядя на статистику, человек видит функцию. Капкан захлопывается.
В чем вторая ошибка/когнитивное искажение? А вот в чем.
Это очень частый аргумент, который я слышу в криптосообществах, в диалогах о возможностях предсказаний чего-либо по историческим данным методами статистического анализа. С погодой работает. Суть искажения в том, что «если A работает для B, а мне кажется, что B это то же самое, что и C, то A должно работать и для C». Эдакая псевдотранзитивность, упирающаяся в недостаточное понимание процессов, лежащих в основе различий между B и C.
С тем же успехом можно полагать, например, что педали в кабине пилота самолета — это тормоз и газ при автоматической коробке передач, а вовсе не горизонтальный руль. Интуитивное восприятие некоторых вещей, к сожалению, не всегда правильное, потому что не всегда опирается на достаточно полный комплект данных о ситуации/системе/объекте. Привет, Байес! Как сам?
Давайте немножко углубимся в теорию.
Так получилось, что все процессы и события в нашей реальности можно классифицировать на две группы: стохастические и детерминистические. Покуда я усиленно стараюсь избегать муторной терминологии, давайте заменим их более простыми терминами: непредсказуемые и предсказуемые.

Как нам верно подсказывает Оби-Ван, все не так просто. Дело в том, что, в мире реальном, не теоретическом, все чуть сложнее и совершенно предсказуемых и совершенно непредсказуемых процессов просто-напросто не существует. Как максимум — есть квазипредсаказуемые и квазинепредсказуемые. Ну то есть вот почти непредсказуемые и почти предсказуемые. Почти почти, но нет.
Например, снег квазипредсказуемо падает сверху вниз. Почти в 100% наблюдаемых случаев. Но не у меня за окном кухни! Там снег идет снизу вверх ввиду особенностей воздушных потоков и формы дома. Но не всегда! Тоже почти в 100% случаев, но не всегда. Иногда у меня за окном кухни он тоже падает вниз. Казалось бы, такая простая вещь, а для одного и того же наблюдателя в двух разных случаях ведет себя совершенно по-разному, причем оба поведения являются нормальными и квазипредсказуемыми почти со 100% вероятностью, хотя полностью противоречат друг другу. Не хило? Квазипредсказуемое событие оказалось… квазинепредсказуемым? Дальше больше.
На этом моменте наш друг Байес начинает смеяться. Что насчет непредсказуемых событий? Я не буду использовать приставку «квази», хорошо? Всем и так понятно, что я ее имею ввиду. Так вот. Возьмем-ка что-то совершенно непредсказуемое. Броуновское движение? Отличный пример совершенно непредсказуемой системы. Ведь так? Давайте спросим у квантовых физиков:

Дело в том, что, теоретически, даже такую сложную систему, как броуновское движение в реальных масштабах, в теории, можно смоделировать и предсказать состояние этой системы в любой момент времени в будущем или прошлом. Теоретически. О том, сколько для этого надо расчётов, мощностей, времени и жертвоприношений Темным Богам тактично умолчим.
А еще предсказуемая, в общем случае, система, становящаяся непредсказуемой, если опустить масштаб до уровня частных случаев, на самом деле вполне предсказуема, если расширить сферу наблюдения частного случая для включения внешних факторов, получив более полное описание системы в этом самом частном случае.
Ну ведь правда, зная о специфике воздушных потоков в конкретном месте, можно легко предсказать направление полета снега. Зная специфику «рельефа» конкретного места, можно предсказать направление воздушного потока. Зная специфику местности, можно предсказать специфику рельефа. И так далее и тому подобное. При этом мы снова начали увеличивать масштаб, но теперь для конкретного события. Отделяя его от «общего» определения поведения этого события. Кто-нибудь, остановите Байеса, у него начался приступ!
Итого, что же мы получаем? Любая система является одновременно и предсказуемой и непредсказуемой в той или иной степени, разница лишь в масштабе наблюдений и полноте исходных данных, ее описывающих.
Как мы выяснили ранее, грань между предсказуемой и непредсказуемой системой крайне тонка. Но достаточно крепка, чтобы прочертить линию, разделяющую прогноз погоды и торговлю.
Как мы уже знаем, даже самая непредсказуемая система на деле состоит из вполне предсказуемых фрагментов. Чтобы ее смоделировать, достаточно спуститься до масштаба этих фрагментов, расширить сферу наблюдения, понять закономерности и аппроксимировать их, например, с помощью нейросети. Либо вывести вполне себе конкретную формулу, позволяющую рассчитывать искомые параметры.
И тут кроется главное отличие прогноза погоды от прогноза цены — масштаб максимально большого предсказуемого моделируемого компонента. Для прогноза погоды масштаб этих компонентов такой, что их ну… их видно с орбиты Земли невооруженным глазом. А что не видно, например, температуру и влажность, можно, благодаря метеостанциям, измерять в реальном времени так же по всей планете. Для торговли же сей масштаб… об этом позже.
Циклон не скажет «я устал, я ухожу», растворившись на ровном месте в непредсказуемый момент времени. Количество тепла, получаемое от Солнца конкретным полушарием планеты меняется с одной и той же закономерностью. Движение воздушных масс в планетарных масштабах не требует атомарной симуляции и вполне себе моделируется на макроуровне. Система под названием «погода», которая в масштабе конкретной точки на Земле является случайным событием, вполне себе предсказуема на более глобальных масшабах. И все равно, точность этих предсказаний оставляет желать лучшего на дистанциях более пары дней. Система хоть и предсказуема, но очень сложна, чтобы ее можно было моделировать с приемлемой точностью в любой точке времени.
И тут мы приходим еще к одному важному свойству предсказательных моделей.
Это свойство, в общем-то, довольно простое — самодостаточная система прогнозирования, или идеальная система прогнозирования, способна обходиться без внешних данных, не считая начальное состояние.
Она же идеально точная. Для предсказания свойств системы в состоянии N, ей достаточно получить собою же рассчитанные данные в состоянии N-1. А зная состояние N, можно получить N+1, +2, +m.
К таким системам можно отнести, например, любую математическую прогрессию. Зная состояние в точке отсчета и номер этой точки в ряду событий, можно легко рассчитать состояние в любой другой точке. Круто!

А еще это ответ на вопрос, почему точность прогноза погоды драматически падает на большой дистанции во времени. Заглядывая в будущее, мы строим прогноз, опираясь не на реальное состояние системы, а на спрогнозированное. Причем, не со 100% точностью, к сожалению. В итоге мы получаем эффект накопления ошибки прогнозирования. А ведь это при том, что нам известны почти все значимые «переменные» и описание системы можно назвать практически «полным».
А с котировками все обстоит гораздо хуже. Дело в том, что при прогнозировании погоды, почти все получаемые и прогнозируемые данные являются одновременно и причиной и следствием событий. Следствием событий предыдущего шага, причиной событий следующего шага. Более того, те значимые данные и события, что не являются одновременно и причиной и следствием, скорее всего являются просто причиной и несут мощную полезную нагрузку. Например, количество тепла, получаемое от Солнца в момент времени. И это неизменно. Именно это повышает показатель самодостаточности таких прогнозов. Следствие перетекает в причину для событий на следующем шаге. Это вполне себе немарковский процесс, который можно описать дифференциальными уравнениями.
В то время как статистика котировок — это, преимущественно либо только последствия, либо 50\50. Рост котировок может спровоцировать дальнейший рост котировок и стать причиной. А может не спровоцировать и не стать причиной. А может спровоцировать фиксацию прибыли и, как следствие, падение цены. Исторические данные на биржах выглядят солидно. Объемы, цены, «стаканы», столько цифр! Абсолютное большинство которых ни на что не годятся, являясь лишь результатом, эхом, событий и причин, лежащих далеко за плоскостью этой статистики. На совершенно ином масштабе. В совершенно иной сфере охвата.
При моделировании будущих котировок мы опираемся лишь на последствия событий в разы более сложных, чем просто процентное отклонение объема закупки. Цена не формирует сама себя. Ее нельзя продифференцировать саму по себе. Если рынок выразить как метафоричное озеро, то биржевый график это лишь рябь на воде. Может быть это ветер подул, может камень в воду бросили, может рыба плеснула, может Годзилла прыгает в 200 километрах на батуте. Мы видим лишь рябь. Но по этой ряби пытаемся спрогнозировать силу ветра через 4 дня, количество камней, которое кинут в воду через месяц, настроение рыбы послезавтра или, быть может, направление, в котором пойдет Годзилла, когда устанет прыгать. Подойдет ближе и снова развернет батут — рябь станет сильнее! Ловим тренд, хоп хоп хоп!

Это очень важный момент:
К сожалению, масштаб максимально возможного моделируемого компонента системы, в случае с рынком, сводится к человеку. Даже не к человеку, а к его психофизическому состоянию, от которого зависит реакция на поведение рынка, и который, этой самой реакцией будет сам влиять на рынок. Та самая причина, перетекающая в следствие! Только моделировать придется тысячи, если не миллионы уникальных, индивидуальных людей. С личными проблемами, переживаниями, гормональным фоном, взаимодействиями, повседневной активностью.
И речь не только о трейдерах на рынке в глобальном масштабе. Речь еще и о людях, стоящих за конкретными проектами. Речь о проблемах и успехах проектов в будущем. Речь о важных событиях в том же будущем. Событиях, порой, крайне непредсказуемых. Получается, что для того, чтобы предсказать будущее, нам нужно знать будущее.

Итого, нам требуется сфера обозреваемых условий, которая нам совершенно недоступна. Масштаб симуляции, который для нас совершенно недостижим.
Ну, то есть, в теории, конечно, достижим. Броуновское движение, в теории, тоже вполне себе моделируемая и предсказуемая система, помните? Тогда вспомните и цену практической реализации такого моделирования. Эта цена непомерно выше, чем процесс кормления нейросети биржевыми свечками. По крайней мере на момент написания этой статьи.
Действительно. В самом начале этой статьи были приведены графики с крайне высокой точностью прогнозирования, граничащей, местами со 100%.
Что видите? Присмотритесь внимательнее. Прекрасное совпадение, не так ли? Идеально, просто идеально. А на первом и втором графиках нейросеть натурально опережает котировки на шаг вперед!
Помните, я упоминал высокоуровневые библиотеки для работы с нейросетями, а потом это не получило в тексте статьи никакого развития? Теперь получит. Широкая доступность чего бы то ни было, непременно снижает планку подготовки среднестатистического пользователя. С нейросетями происходит то же самое. «Kaggle kernels» тому показатель. Любой не узкопрофильный раздел просто утопает в тоннах решений, авторы которых, в подавляющем большинстве, понятия не имеют, что вообще делают. А снизу каждое решение подпирается столпами хвалебных комментариев от людей, разбирающихся в вопросе еще меньше. «Отличная работа, то, что надо!», «Я так давно искал подходящее для моих задач ядро, вот оно! А как им пользоваться?» и так далее.
Отыскать среди этого что-то действительно интересное и красивое очень, очень сложно.

Ведь время на шкале X движется вправо, а предсказание, в идеале, должно быть получено до наступления события.
Нас всех радует, когда наша нейросеть проявляет признаки сходимости. Но есть нюансы. В программировании как таковом, есть правило «запустилось не значит заработало». Когда мы только начинаем изучать программирование, нас безмерно радует сам факт того, что компилятор/интерпретатор сумел понять то, что мы ему подсунули и не закидал нас ошибками. На этом уровне становления мы считаем, что ошибки в программе бывают только синтаксические.
В проектировании нейросетей все то же самое. Только вместо компиляции — сходимость. Сошлось — не значит обучилось именно тому, что нам нужно. Так чему же оно обучилось?
Неопытный исследователь, глядя на такие красивые графики, скорее всего, возликует. А вот более менее опытный, насторожится, ведь вариантов тут не так много:
Как думаете, какой вариант ближе к реальности? К сожалению, не третий. Да, сеть действительно обучилась. Она действительно поразительно точно выдает результаты, но почему?
Хотя искусственные нейронные сети и не являются «электронной моделью человеческого мозга», некоторые свойства «разума» они все же проявляют. В основном это «лень» и «хитрость». Причем одновременно. И это не последствия зарождающегося в паре сотен «нейронов» самосознания. Это последствия того, что за популистским термином «обучение» на самом деле кроется термин «оптимизация».
Нейросеть — не студент, который учится, пытаясь понять то, что мы ему втолковываем, по крайней мере на момент написания этой статьи. Нейросеть — это набор весов, значения которых надо подогнать или оптимизировать таким образом, чтобы свести к минимуму ошибку результата нейросети относительно эталонного результата.
Мы даем нейросети задачу, а потом просим ее «сдать экзамен». Согласно результатам «экзамена» мы решаем, насколько она успешна, справедливо полагая, что в процессе подготовки к «экзамену», наша сеть приобрела достаточный багаж знаний, умений и опыта.
Видите подвох? Нет? Да вот же он, на поверхности! В то время, как ваша цель заключается в обучении нейросети полезным, с вашей точки зрения, навыкам, ее цель — лишь сдать экзамен.

Любой ценой. Любыми средствами. Пожалуй, все же, с некоторыми студентами у нее больше общего, чем было заявлено двумя абзацами ранее…
Так как же сдать пресловутый экзамен?
Первый вариант в списке возможных причин такой невероятной точности. Почти любой начинающий исследователь искусственных нейронных сетей непременно знает, что чем больше в ней нейронов, тем лучше. А, еще лучше, когда в ней много много слоев.
Но не учитывает тот факт, что количество нейронов и слоев увеличивает не только потенциал сети в области «абстрактного мышления», но и объем ее памяти. Особенно это касается рекуррентных сетей, ибо их объем памяти воистину чудовищен.
В итоге, в процессе оптимизации, окажется, что самым оптимальным вариантом сдачи экзамена является… обычная зубрежка или «переобученность», «overfitting». Сеть просто выучит все «правильные ответы» наизусть. Совершенно не понимая принципы, по которым они образуются. В итоге, при испытаниях сети на выборке данных, которую она никогда прежде не видела, сеть начинает нести чушь.
По этой причине, для обучения глубоких/широких сетей нужно гораздо больше данных, нужна регуляризация, нужен контроль над минимальным порогом ошибки, который должен быть мал, но не слишком. А, еще лучше, найти правильный баланс между размером сети и качеством решения задачи.
Хорошо. Учтем. Лишние слои выбросим. Архитектуру упростим. Всякие разные хитрые приемы внедрим. Теперь заработает? Не факт. Ведь номер два в списке легких вариантов сдачи экзамена:
Поскольку зачет нейросеть получает не за процесс, а за результат, процесс, которым она добивается этого результата, может несколько отличаться от того, какой подразумевал разработчик. Это один из самых подлых моментов работы с этими прекрасными зверями — когда сеть научилась, но не тому.
Когда вы видите графики с предсказаниями курса, идеально повторяющие реальный курс, задумайтесь, чему вы научили нейросеть? Сверхточно предсказывать цены? А может быть просто повторять их как попугайчик?
Будьте уверены, что сеть, которая имеет почти 100% точность на обучающей выборке и такую же на тестовой, просто повторяет все, что видит. Сети, у которых график предсказаний смещен на один шаг во времени вправо(примеры графиков 1 и 2), просто повторяют значение цены с прошлого шага, которое им передается в новый. Графики, конечно, выглядят очень обнадеживающе, и почти идеально совпадают, но предсказательной силы в них нет. Озвучить сегодня вчерашнюю цену вы в состоянии и самостоятельно, для этого не нужно учиться в Хогвартсе или полировать Палантир, не так ли?
Но это если подавать им значения с прошлого шага, сравнивая со значением шага текущего. Порой люди просто подают значение с текущего шага, сравнивая его с шагом следующим. В таком случае мы получаем красивые графики, совпадающие с оригинальными почти идеально (примеры графиков 3 и 4).
Иногда можно увидеть графики, совпадающие не идеально, более мягкие, как бы сглаженные, интерполированные. Это, обычно, явный признак работы рекуррентной сети, которая пытается увязывать новый результат с предыдущим (пример графика 3).
Общее у всех этих результатов только одно — нейросеть научилась сдавать экзамен на 5 с плюсом. Но она не научилась решать поставленную перед ней задачу тем способом, каким требовалось и не несет никакой практической пользы для исследователя. Совсем как студент, но уже со шпаргалкой, да?
Почему сеть повторяет предыдущие значения, а не пытается генерировать новые? Да просто-напросто в ходе обучения она приходит к резонному выводу, что, обычно, ближайшая к следующей точка на графике — это предыдущая. Да, величина ошибки при этом плавает, но она, на большой выборке, стабильно меньше, чем величина ошибки при попытке предсказать следующее состояние в квазислучайном процессе.
Нейросети умеют отлично обобщать. Обобщение подобного рода — отличное решение поставленной задачи.
Увы, сколько не крути гиперпараметры, будущее для нее не откроется. График не сместится на один шаг назад во времени. Да, Грааль так близко, но так далеко.

В точку. Конечно же она существует. Но ключевой момент в том, что это алгоритмическая торговля это не то же самое, что алгоритмическое прорицательство. Алгоритмическая торговля основана на том, что торговая система анализирует рынок в текущий момент времени, принимая решение об открытии и закрытии сделки, исходя из большого количества объективных параметров и косвенных признаков.
Да, это, технически, тоже попытка предугадать поведение рынка, но, в отличие от предсказаний на дни и месяцы вперед, торговая система пытается работать на максимально допустимых малых промежутках времени.
Помните про прогноз погоды? Помните, что его точность драматически падает на большой дистанции? Это работает в обе стороны. Чем дистанция короче, тем точность выше. Вы, глядя в окно, даже не будучи метеорологом, сможете предсказать, какая температура воздуха будет через секунду, верно?
Но как это работает? Разве это не противоречит всему, что было сказано? А как же рябь на воде, как же нехватка данных? Как же Годзилла, в конце-концов!?
Но нет, тут нет противоречий. Покуда торговый бот работает на очень малых промежутках времени, действительно малых, от минуты до долей секунды, в зависимости от типа, ему не надо знать будущее и не надо иметь полное представление о рынке. Ему достаточно понимать, как работает система, находящаяся вокруг него. В каких обстоятельствах в ней лучше открывать сделку, в каких закрывать. Торговый бот работает на настолько малом масштабе, что его сфера обзора способна покрыть достаточное количество факторов для принятия успешного решения на приемлемо короткой дистанции. И знать для этого глобальное состояние системы ему совершенно не нужно.
Статья получилась большая. Больше, чем я рассчитывал. Надеюсь, она будет для кого-то полезной и поможет сэкономить время тому, кто решил попытать счастье в поисках Святого Грааля Торговли.
Давайте выделим основные тезисы:
Спасибо всем, кто дочитал до конца!
P.S. Нет, это не статья про «фундаментальный анализ VS технический». Это статья про «чудес не бывает».
На просторах Сети полным полно материалов, мануалов, готовых решений, сборок и прочего добра, посвященного прогнозированию цен на криптовалютные и традиционные биржевые активы, пахнущего быстрыми и легкими доходами с минимумом усилий. И хоть пишут их разные люди, с разными подходами, на разных платформах и с разными парадигмами, у них всех есть один неизменный общий атрибут — они не работают.
Почему? Давайте разбираться.
Вступление
Давайте знакомиться, меня зовут Денис и, в свободное время, я занимаюсь исследованиями в области искусственного интеллекта и, в частности, искусственных нейронных сетей.
В данном материале я постараюсь описать проблемы,
Я надеюсь, что, в рамках данной статьи, получится выдержать достаточный баланс между сложностью материала и легкостью восприятия, дабы текст был в меру прост, понятен и интересен как людям, не связанным с данным поприщем, так и тем, кто давно занимается исследованиями проблем в этой отрасли. Сразу говорю, формул тут не будет, специфичной терминологии тоже по минимуму.
Я не работаю в Google. У меня нет двадцати научных степеней. Я не стажировался в NASA. Я не учился в Стэнфорде и горько сожалею об этом. Однако, я, все же, надеюсь, что понимаю, о чем говорю, когда речь идет о системах прогнозирования и, при этом, я довольно тесно связан с криптовалютным миром в общем и проектом Cardano в частности.
Разумеется, меня, как криптоэнтузиаста, занимающегося нейросетями, просто не могло не занести в туманную область применения ИИ касательно криптовалют.
Суть проблемы
Как было сказано ранее, материалов, вроде даже проработанных и, на первый взгляд, глубоких, с примерами, на эту тему столько, что глаза разбегаются. А авторы настолько уверены в том, что их эксперимент, в отличие от предыдущих нескольких сотен, успешен, что даже удивляешься, почему очередная статья не заканчивается фотографиями с «ламбой» на личном острове, а список авторов «kaggle kernels», связанных с прогнозированием цен на биткоины, не дублирует списки Forbes.
Ожидаемо, что и на Хабре есть статьи, посвященные этим вопросам. И, что интересно, независимо от места и языка публикации, все эти статьи заканчиваются примерно одинаковым текстом «Ну вот, результат вполне неплохой, все почти работает, надо просто докрутить немного гиперпараметры и все будет здорово».
И, обязательно, графики, на которых нейросеть идеально указывает цену, типа таких: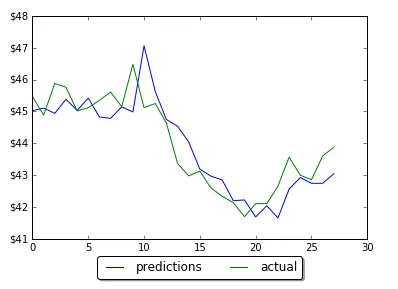
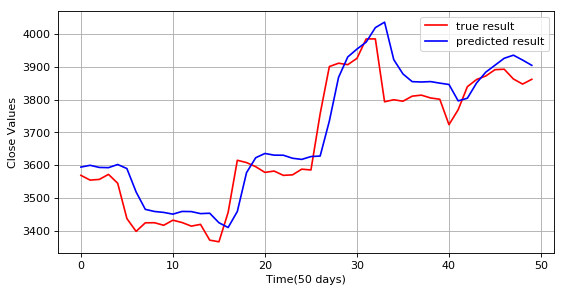


Мы к ним еще вернемся в дальнейшем и рассмотрим внимательно.
Мы к ним еще вернемся в дальнейшем и рассмотрим внимательно.
И, дабы не быть голословным, вот примеры подобных статей: раз, два, три.
С чего все началось
Идея предсказания новых цен по старым далеко не нова. На самом деле, это касается не только криптовалют. Так уж вышло, что лично мне они ближе, но, родина того, что называют «техническим анализом» — это, все-таки традиционные биржи. Те самые, где, если верить фильмам, все в дорогих костюмах, но при этом орут как девочки на концерте любимой группы.
Пытаясь увидеть будущее по прошлому, люди наизобретали огромное количество всевозможных хитрых осцилляторов, индикаторов, сигнализаторов, основанных на мат.статистике, теории вероятности и, порой, откровенной парейдолии.
Самое популярное, пожалуй, это поиск фигур. Пятнадцать минут чтения интернета и хоть сейчас на Уолл-стрит! Это ведь так просто — надо лишь на графике найти «голову Барта Симпсона», «бабочку», «флажок(не путать с клином!11)», «лазурь, падающую в вакуумную вертихвостку», построить много-много линий и, совершенно непредвзято, истолковать это в свою пользу!
У почти всех этих решений есть один небольшой, но очень плотный и тяжелый недостаток — они прекрасно фиксируют тренды...постфактум. А если что-то заявлено, как не фиксирующее, а предсказывающее, то оно трактуется настолько вольно, что десять человек, глядя на один и тот же график с одним и тем же индикатором, дадут десять независимых прогнозов. И, что характерно, хотя бы один из них, скорее всего будет прав!
Но это будет установлено тоже постфактум. А остальные просто скажут «а, ну мы по невнимательности неправильно прочитали сигналы».
Не поймите меня неправильно. Вполне допустимо, что реальный трейдер с Уолл-стрит, у которого за плечами лет 20 криков и штук 200 попыток суицида, скорее всего может наложить друг на друга пачку индикаторов и осцилляторов и, как оператор из фильма «Матрица», одним взглядом прочитать там полезные данные, сдобренные достаточно высоким мат.ожиданием успешной сделки. Я даже допускаю, что конкретно Ты, читатель, тоже так умеешь. Без капли сарказма, вполне допускаю. В конце концов зачем-то же их придумывают, улучшают, эти индикаторы…
Современные проблемы требуют современных решений!
Году к 2015 нейросети уже были у всех на слуху. Розенблатт даже не представлял, насколько они будут на слуху. Благодаря ответственным, профессиональным, разбирающимся в вопросе СМИ, человечество узнало, что нейросети — это самая что ни на есть электронная версия человеческого мозга, способная быстрее и лучше решить любую задачу, обладающая неограниченным потенциалом и вообще, вот вот и через сингулярность перемахнем прямо в светлое/мрачное будущее. Тут уж как повезет.
Но было одно «но». До поры до времени, нейросети обитали только в заповедных математических пакетах, в очень очень низкоуровневом виде, теша математиков и ученых графиками в MatLab-ах.
Но популяризация сделала свое дело и привлекла в отрасль очень много внимания разработчиков разной степени независимости. Эти самые разработчики, будучи, в отличие от обычных математиков, людьми, наделенными благородной ленью, стали изыскивать способы накинуть несколько уровней абстракции на это дело, облегчая жизнь себе и всем желающим, явив миру весьма удобный и качественный высокоуровневый инструментарий вроде Keras или FANN. В этом рвении они преуспели настолько, что довели работу с нейросетями до уровня «просто раз и работает», открыв дорогу в мир чудес и волшебства для всех желающих.
Именно чудес и волшебства, а не математики и фактов.
Рождение легенды
Нейросети стали доступны, близки и легко используемы для всех и каждого. Серьезно, реализация FANN есть даже для PHP. Более того, входит в список базовых расширений.
А Keras? В 10 строчек можно собрать рекуррентно-сверточную сеть, не понимая ни как работают свертки, ни чем отличается LSTM от GRU! Искусственный интеллект для всех и каждого! И пусть никто не уйдет обиженным!
Думаю, отчасти, самую злую шутку сыграла терминология. Как называют выходы нейросети? Ага. Predictions. Предсказания. Нейросеть предсказывает одни данные по другим. Звучит ну прямо как то, что нужно.
Руководства для высокоуровневых библиотек оберегают пользователя от сложных терминов, матриц, векторов, преобазований, дифференциальных исчислений, математических смыслов этих вот градиентов, регрессий и регуляризационных потерь.
А, самое главное, оберегают романтический образ «электронной модели человеческого мозга, способной на все» от суровой реальности, в которой нейросети — это просто аппроксиматор, являющийся, грубо говоря, не более чем эволюционным шагом на ступеньку вверх от обычного линейного классификатора.
Но это не имеет значения, когда собираешь по листингам из документации свой первый решатель для CIFAR-10, не прилагая никаких усилий, не понимая даже толком, что происходит. В уме лишь одна мысль:
Ну что сказать, ну что сказать, устроены так люди...
Вот оно, технологическое чудо! Ты просто даешь ему на вход одни данные, на выход другие, а оно само находит связь и учится предсказывать выходы по входам. Сколько проблем можно решить! Сколько задач можно нивелировать!
Столько всего можно предсказать! Интересно, а другие люди вообще в курсе? С этим инструментарием мои возможности безграничны! БЕЗГРАНИЧНЫ!
А что если накормить нейросеть свечами с криптобиржи/фондовой биржи/форекса, на выход подавая ей свечу со следующего временного промежутка? Она ведь научится тогда предсказывать новые значения по предыдущим! Ведь это то, для чего она была сделана! Нейросеть может предсказать что угодно, были бы данные, а данных по истории котировок пруд пруди! О, озарение, лишь миг, но столь прекрасный!
А почему бы и нет?
Потому что в реальном мире, который отличается от мира, создаваемого СМИ, это так не работает. Нейросети не являются машиной для предсказаний. Нейросети — это аппроксиматоры. Очень хорошие аппроксиматоры. Считается, что нейросети могут аппроксимировать практически что угодно. При одном лишь условии — если это «что-то» поддается аппроксимации.
И тут-то начинающий исследователь и попадается на крючок когнитивных искажений. Первая и главная ошибка в том, что исторические данные по котировкам кажутся чем-то большим, чем просто статистикой. По ним можно нарисовать столько треугольников и стрелочек постфактум, что только слепому при взгляде на это будет неочевидно, что в этом всем есть некая логика, которую просто не удалось вовремя считать. Но которую, возможно, познает Машина.
Глядя на статистику, человек видит функцию. Капкан захлопывается.
В чем вторая ошибка/когнитивное искажение? А вот в чем.
А с погодой работает!
Это очень частый аргумент, который я слышу в криптосообществах, в диалогах о возможностях предсказаний чего-либо по историческим данным методами статистического анализа. С погодой работает. Суть искажения в том, что «если A работает для B, а мне кажется, что B это то же самое, что и C, то A должно работать и для C». Эдакая псевдотранзитивность, упирающаяся в недостаточное понимание процессов, лежащих в основе различий между B и C.
С тем же успехом можно полагать, например, что педали в кабине пилота самолета — это тормоз и газ при автоматической коробке передач, а вовсе не горизонтальный руль. Интуитивное восприятие некоторых вещей, к сожалению, не всегда правильное, потому что не всегда опирается на достаточно полный комплект данных о ситуации/системе/объекте. Привет, Байес! Как сам?
Давайте немножко углубимся в теорию.
Хаос и Закон
Так получилось, что все процессы и события в нашей реальности можно классифицировать на две группы: стохастические и детерминистические. Покуда я усиленно стараюсь избегать муторной терминологии, давайте заменим их более простыми терминами: непредсказуемые и предсказуемые.
Как нам верно подсказывает Оби-Ван, все не так просто. Дело в том, что, в мире реальном, не теоретическом, все чуть сложнее и совершенно предсказуемых и совершенно непредсказуемых процессов просто-напросто не существует. Как максимум — есть квазипредсаказуемые и квазинепредсказуемые. Ну то есть вот почти непредсказуемые и почти предсказуемые. Почти почти, но нет.
Например, снег квазипредсказуемо падает сверху вниз. Почти в 100% наблюдаемых случаев. Но не у меня за окном кухни! Там снег идет снизу вверх ввиду особенностей воздушных потоков и формы дома. Но не всегда! Тоже почти в 100% случаев, но не всегда. Иногда у меня за окном кухни он тоже падает вниз. Казалось бы, такая простая вещь, а для одного и того же наблюдателя в двух разных случаях ведет себя совершенно по-разному, причем оба поведения являются нормальными и квазипредсказуемыми почти со 100% вероятностью, хотя полностью противоречат друг другу. Не хило? Квазипредсказуемое событие оказалось… квазинепредсказуемым? Дальше больше.
На этом моменте наш друг Байес начинает смеяться. Что насчет непредсказуемых событий? Я не буду использовать приставку «квази», хорошо? Всем и так понятно, что я ее имею ввиду. Так вот. Возьмем-ка что-то совершенно непредсказуемое. Броуновское движение? Отличный пример совершенно непредсказуемой системы. Ведь так? Давайте спросим у квантовых физиков:
Дело в том, что, теоретически, даже такую сложную систему, как броуновское движение в реальных масштабах, в теории, можно смоделировать и предсказать состояние этой системы в любой момент времени в будущем или прошлом. Теоретически. О том, сколько для этого надо расчётов, мощностей, времени и жертвоприношений Темным Богам тактично умолчим.
А еще предсказуемая, в общем случае, система, становящаяся непредсказуемой, если опустить масштаб до уровня частных случаев, на самом деле вполне предсказуема, если расширить сферу наблюдения частного случая для включения внешних факторов, получив более полное описание системы в этом самом частном случае.
Ну ведь правда, зная о специфике воздушных потоков в конкретном месте, можно легко предсказать направление полета снега. Зная специфику «рельефа» конкретного места, можно предсказать направление воздушного потока. Зная специфику местности, можно предсказать специфику рельефа. И так далее и тому подобное. При этом мы снова начали увеличивать масштаб, но теперь для конкретного события. Отделяя его от «общего» определения поведения этого события. Кто-нибудь, остановите Байеса, у него начался приступ!
Итого, что же мы получаем? Любая система является одновременно и предсказуемой и непредсказуемой в той или иной степени, разница лишь в масштабе наблюдений и полноте исходных данных, ее описывающих.
При чем тут прогноз погоды и торговля на бирже?
Как мы выяснили ранее, грань между предсказуемой и непредсказуемой системой крайне тонка. Но достаточно крепка, чтобы прочертить линию, разделяющую прогноз погоды и торговлю.
Как мы уже знаем, даже самая непредсказуемая система на деле состоит из вполне предсказуемых фрагментов. Чтобы ее смоделировать, достаточно спуститься до масштаба этих фрагментов, расширить сферу наблюдения, понять закономерности и аппроксимировать их, например, с помощью нейросети. Либо вывести вполне себе конкретную формулу, позволяющую рассчитывать искомые параметры.
И тут кроется главное отличие прогноза погоды от прогноза цены — масштаб максимально большого предсказуемого моделируемого компонента. Для прогноза погоды масштаб этих компонентов такой, что их ну… их видно с орбиты Земли невооруженным глазом. А что не видно, например, температуру и влажность, можно, благодаря метеостанциям, измерять в реальном времени так же по всей планете. Для торговли же сей масштаб… об этом позже.
Циклон не скажет «я устал, я ухожу», растворившись на ровном месте в непредсказуемый момент времени. Количество тепла, получаемое от Солнца конкретным полушарием планеты меняется с одной и той же закономерностью. Движение воздушных масс в планетарных масштабах не требует атомарной симуляции и вполне себе моделируется на макроуровне. Система под названием «погода», которая в масштабе конкретной точки на Земле является случайным событием, вполне себе предсказуема на более глобальных масшабах. И все равно, точность этих предсказаний оставляет желать лучшего на дистанциях более пары дней. Система хоть и предсказуема, но очень сложна, чтобы ее можно было моделировать с приемлемой точностью в любой точке времени.
И тут мы приходим еще к одному важному свойству предсказательных моделей.
Самодостаточность или автономность предсказаний
Это свойство, в общем-то, довольно простое — самодостаточная система прогнозирования, или идеальная система прогнозирования, способна обходиться без внешних данных, не считая начальное состояние.
Она же идеально точная. Для предсказания свойств системы в состоянии N, ей достаточно получить собою же рассчитанные данные в состоянии N-1. А зная состояние N, можно получить N+1, +2, +m.
К таким системам можно отнести, например, любую математическую прогрессию. Зная состояние в точке отсчета и номер этой точки в ряду событий, можно легко рассчитать состояние в любой другой точке. Круто!
А еще это ответ на вопрос, почему точность прогноза погоды драматически падает на большой дистанции во времени. Заглядывая в будущее, мы строим прогноз, опираясь не на реальное состояние системы, а на спрогнозированное. Причем, не со 100% точностью, к сожалению. В итоге мы получаем эффект накопления ошибки прогнозирования. А ведь это при том, что нам известны почти все значимые «переменные» и описание системы можно назвать практически «полным».
А что насчет котировок?
А с котировками все обстоит гораздо хуже. Дело в том, что при прогнозировании погоды, почти все получаемые и прогнозируемые данные являются одновременно и причиной и следствием событий. Следствием событий предыдущего шага, причиной событий следующего шага. Более того, те значимые данные и события, что не являются одновременно и причиной и следствием, скорее всего являются просто причиной и несут мощную полезную нагрузку. Например, количество тепла, получаемое от Солнца в момент времени. И это неизменно. Именно это повышает показатель самодостаточности таких прогнозов. Следствие перетекает в причину для событий на следующем шаге. Это вполне себе немарковский процесс, который можно описать дифференциальными уравнениями.
В то время как статистика котировок — это, преимущественно либо только последствия, либо 50\50. Рост котировок может спровоцировать дальнейший рост котировок и стать причиной. А может не спровоцировать и не стать причиной. А может спровоцировать фиксацию прибыли и, как следствие, падение цены. Исторические данные на биржах выглядят солидно. Объемы, цены, «стаканы», столько цифр! Абсолютное большинство которых ни на что не годятся, являясь лишь результатом, эхом, событий и причин, лежащих далеко за плоскостью этой статистики. На совершенно ином масштабе. В совершенно иной сфере охвата.
При моделировании будущих котировок мы опираемся лишь на последствия событий в разы более сложных, чем просто процентное отклонение объема закупки. Цена не формирует сама себя. Ее нельзя продифференцировать саму по себе. Если рынок выразить как метафоричное озеро, то биржевый график это лишь рябь на воде. Может быть это ветер подул, может камень в воду бросили, может рыба плеснула, может Годзилла прыгает в 200 километрах на батуте. Мы видим лишь рябь. Но по этой ряби пытаемся спрогнозировать силу ветра через 4 дня, количество камней, которое кинут в воду через месяц, настроение рыбы послезавтра или, быть может, направление, в котором пойдет Годзилла, когда устанет прыгать. Подойдет ближе и снова развернет батут — рябь станет сильнее! Ловим тренд, хоп хоп хоп!
Это очень важный момент:
Самодостаточность прогнозируемой модели, основанной лишь на наблюдаемых последствиях, стремится к нулю по мере роста количества факторов, находящихся вне обозреваемой сферы связанных с ними событий.Иными словами, вы не сможете смоделировать систему достаточно хорошо, не имея достаточно полное ее описание.
К сожалению, масштаб максимально возможного моделируемого компонента системы, в случае с рынком, сводится к человеку. Даже не к человеку, а к его психофизическому состоянию, от которого зависит реакция на поведение рынка, и который, этой самой реакцией будет сам влиять на рынок. Та самая причина, перетекающая в следствие! Только моделировать придется тысячи, если не миллионы уникальных, индивидуальных людей. С личными проблемами, переживаниями, гормональным фоном, взаимодействиями, повседневной активностью.
И речь не только о трейдерах на рынке в глобальном масштабе. Речь еще и о людях, стоящих за конкретными проектами. Речь о проблемах и успехах проектов в будущем. Речь о важных событиях в том же будущем. Событиях, порой, крайне непредсказуемых. Получается, что для того, чтобы предсказать будущее, нам нужно знать будущее.
Итого, нам требуется сфера обозреваемых условий, которая нам совершенно недоступна. Масштаб симуляции, который для нас совершенно недостижим.
Ну, то есть, в теории, конечно, достижим. Броуновское движение, в теории, тоже вполне себе моделируемая и предсказуемая система, помните? Тогда вспомните и цену практической реализации такого моделирования. Эта цена непомерно выше, чем процесс кормления нейросети биржевыми свечками. По крайней мере на момент написания этой статьи.
Но как же графики?
Действительно. В самом начале этой статьи были приведены графики с крайне высокой точностью прогнозирования, граничащей, местами со 100%.
Давайте посмотрим на них снова:
Что видите? Присмотритесь внимательнее. Прекрасное совпадение, не так ли? Идеально, просто идеально. А на первом и втором графиках нейросеть натурально опережает котировки на шаг вперед!
Помните, я упоминал высокоуровневые библиотеки для работы с нейросетями, а потом это не получило в тексте статьи никакого развития? Теперь получит. Широкая доступность чего бы то ни было, непременно снижает планку подготовки среднестатистического пользователя. С нейросетями происходит то же самое. «Kaggle kernels» тому показатель. Любой не узкопрофильный раздел просто утопает в тоннах решений, авторы которых, в подавляющем большинстве, понятия не имеют, что вообще делают. А снизу каждое решение подпирается столпами хвалебных комментариев от людей, разбирающихся в вопросе еще меньше. «Отличная работа, то, что надо!», «Я так давно искал подходящее для моих задач ядро, вот оно! А как им пользоваться?» и так далее.
Отыскать среди этого что-то действительно интересное и красивое очень, очень сложно.
<оголтелый снобизм>
В итоге у нас есть такое явление, как люди, легко оперирующие довольно сложным математическим аппаратом, но не умеющие читать графики.
</оголтелый снобизм>
Ведь время на шкале X движется вправо, а предсказание, в идеале, должно быть получено до наступления события.
Просто гиперпараметры еще не подкручены
Нас всех радует, когда наша нейросеть проявляет признаки сходимости. Но есть нюансы. В программировании как таковом, есть правило «запустилось не значит заработало». Когда мы только начинаем изучать программирование, нас безмерно радует сам факт того, что компилятор/интерпретатор сумел понять то, что мы ему подсунули и не закидал нас ошибками. На этом уровне становления мы считаем, что ошибки в программе бывают только синтаксические.
В проектировании нейросетей все то же самое. Только вместо компиляции — сходимость. Сошлось — не значит обучилось именно тому, что нам нужно. Так чему же оно обучилось?
Неопытный исследователь, глядя на такие красивые графики, скорее всего, возликует. А вот более менее опытный, насторожится, ведь вариантов тут не так много:
- Сеть явно переобучена (пере- в значении «избыточно», а не «повторно»)
- Сеть эксплуатирует изъян в методике обучения
- Сеть аппроксимировала Биржевый Грааль и способна предсказать состояние рынка в любом моменте времени, «разжав» бесконечный график из всего одной свечи
Как думаете, какой вариант ближе к реальности? К сожалению, не третий. Да, сеть действительно обучилась. Она действительно поразительно точно выдает результаты, но почему?
Хотя искусственные нейронные сети и не являются «электронной моделью человеческого мозга», некоторые свойства «разума» они все же проявляют. В основном это «лень» и «хитрость». Причем одновременно. И это не последствия зарождающегося в паре сотен «нейронов» самосознания. Это последствия того, что за популистским термином «обучение» на самом деле кроется термин «оптимизация».
Нейросеть — не студент, который учится, пытаясь понять то, что мы ему втолковываем, по крайней мере на момент написания этой статьи. Нейросеть — это набор весов, значения которых надо подогнать или оптимизировать таким образом, чтобы свести к минимуму ошибку результата нейросети относительно эталонного результата.
Мы даем нейросети задачу, а потом просим ее «сдать экзамен». Согласно результатам «экзамена» мы решаем, насколько она успешна, справедливо полагая, что в процессе подготовки к «экзамену», наша сеть приобрела достаточный багаж знаний, умений и опыта.
Видите подвох? Нет? Да вот же он, на поверхности! В то время, как ваша цель заключается в обучении нейросети полезным, с вашей точки зрения, навыкам, ее цель — лишь сдать экзамен.
Любой ценой. Любыми средствами. Пожалуй, все же, с некоторыми студентами у нее больше общего, чем было заявлено двумя абзацами ранее…
Так как же сдать пресловутый экзамен?
Зазубрить
Первый вариант в списке возможных причин такой невероятной точности. Почти любой начинающий исследователь искусственных нейронных сетей непременно знает, что чем больше в ней нейронов, тем лучше. А, еще лучше, когда в ней много много слоев.
Но не учитывает тот факт, что количество нейронов и слоев увеличивает не только потенциал сети в области «абстрактного мышления», но и объем ее памяти. Особенно это касается рекуррентных сетей, ибо их объем памяти воистину чудовищен.
В итоге, в процессе оптимизации, окажется, что самым оптимальным вариантом сдачи экзамена является… обычная зубрежка или «переобученность», «overfitting». Сеть просто выучит все «правильные ответы» наизусть. Совершенно не понимая принципы, по которым они образуются. В итоге, при испытаниях сети на выборке данных, которую она никогда прежде не видела, сеть начинает нести чушь.
По этой причине, для обучения глубоких/широких сетей нужно гораздо больше данных, нужна регуляризация, нужен контроль над минимальным порогом ошибки, который должен быть мал, но не слишком. А, еще лучше, найти правильный баланс между размером сети и качеством решения задачи.
Хорошо. Учтем. Лишние слои выбросим. Архитектуру упростим. Всякие разные хитрые приемы внедрим. Теперь заработает? Не факт. Ведь номер два в списке легких вариантов сдачи экзамена:
Перехитрить препода
Поскольку зачет нейросеть получает не за процесс, а за результат, процесс, которым она добивается этого результата, может несколько отличаться от того, какой подразумевал разработчик. Это один из самых подлых моментов работы с этими прекрасными зверями — когда сеть научилась, но не тому.
Когда вы видите графики с предсказаниями курса, идеально повторяющие реальный курс, задумайтесь, чему вы научили нейросеть? Сверхточно предсказывать цены? А может быть просто повторять их как попугайчик?
Будьте уверены, что сеть, которая имеет почти 100% точность на обучающей выборке и такую же на тестовой, просто повторяет все, что видит. Сети, у которых график предсказаний смещен на один шаг во времени вправо(примеры графиков 1 и 2), просто повторяют значение цены с прошлого шага, которое им передается в новый. Графики, конечно, выглядят очень обнадеживающе, и почти идеально совпадают, но предсказательной силы в них нет. Озвучить сегодня вчерашнюю цену вы в состоянии и самостоятельно, для этого не нужно учиться в Хогвартсе или полировать Палантир, не так ли?
Но это если подавать им значения с прошлого шага, сравнивая со значением шага текущего. Порой люди просто подают значение с текущего шага, сравнивая его с шагом следующим. В таком случае мы получаем красивые графики, совпадающие с оригинальными почти идеально (примеры графиков 3 и 4).
Иногда можно увидеть графики, совпадающие не идеально, более мягкие, как бы сглаженные, интерполированные. Это, обычно, явный признак работы рекуррентной сети, которая пытается увязывать новый результат с предыдущим (пример графика 3).
Общее у всех этих результатов только одно — нейросеть научилась сдавать экзамен на 5 с плюсом. Но она не научилась решать поставленную перед ней задачу тем способом, каким требовалось и не несет никакой практической пользы для исследователя. Совсем как студент, но уже со шпаргалкой, да?
Почему сеть повторяет предыдущие значения, а не пытается генерировать новые? Да просто-напросто в ходе обучения она приходит к резонному выводу, что, обычно, ближайшая к следующей точка на графике — это предыдущая. Да, величина ошибки при этом плавает, но она, на большой выборке, стабильно меньше, чем величина ошибки при попытке предсказать следующее состояние в квазислучайном процессе.
Нейросети умеют отлично обобщать. Обобщение подобного рода — отличное решение поставленной задачи.
Увы, сколько не крути гиперпараметры, будущее для нее не откроется. График не сместится на один шаг назад во времени. Да, Грааль так близко, но так далеко.
Стоп. Нет нет нет. А как же алгоритмическая торговля? Она же существует!
В точку. Конечно же она существует. Но ключевой момент в том, что это алгоритмическая торговля это не то же самое, что алгоритмическое прорицательство. Алгоритмическая торговля основана на том, что торговая система анализирует рынок в текущий момент времени, принимая решение об открытии и закрытии сделки, исходя из большого количества объективных параметров и косвенных признаков.
Да, это, технически, тоже попытка предугадать поведение рынка, но, в отличие от предсказаний на дни и месяцы вперед, торговая система пытается работать на максимально допустимых малых промежутках времени.
Помните про прогноз погоды? Помните, что его точность драматически падает на большой дистанции? Это работает в обе стороны. Чем дистанция короче, тем точность выше. Вы, глядя в окно, даже не будучи метеорологом, сможете предсказать, какая температура воздуха будет через секунду, верно?
Но как это работает? Разве это не противоречит всему, что было сказано? А как же рябь на воде, как же нехватка данных? Как же Годзилла, в конце-концов!?
Но нет, тут нет противоречий. Покуда торговый бот работает на очень малых промежутках времени, действительно малых, от минуты до долей секунды, в зависимости от типа, ему не надо знать будущее и не надо иметь полное представление о рынке. Ему достаточно понимать, как работает система, находящаяся вокруг него. В каких обстоятельствах в ней лучше открывать сделку, в каких закрывать. Торговый бот работает на настолько малом масштабе, что его сфера обзора способна покрыть достаточное количество факторов для принятия успешного решения на приемлемо короткой дистанции. И знать для этого глобальное состояние системы ему совершенно не нужно.
Заключение
Статья получилась большая. Больше, чем я рассчитывал. Надеюсь, она будет для кого-то полезной и поможет сэкономить время тому, кто решил попытать счастье в поисках Святого Грааля Торговли.
Давайте выделим основные тезисы:
- У Годзиллы есть батут
- Надо понимать, как работает инструментарий, с которым вы решаете задачу
- Надо понимать границы применимости и адекватно оценивать решаемость задачи как таковую
- Важно уметь правильно интерпретировать результаты работы инструментария
- Нейросети — аппроксиматоры функций, а не предсказатели будущего
- и — это тоже функции
- Для моделирования состояния системы, нужно иметь полное или близкое к тому описание этой системы
- Статистика — лишь частичное, выборочное описание последствий работы системы
- Хорошая система прогнозирования должна быть в меру самодостаточна
- Нейросетям нельзя верить на слово, они коварны, хитры и ленивы
- Хотите, чтобы ИИ помогал в торговле? Учите его торговать
Спасибо всем, кто дочитал до конца!
P.S. Нет, это не статья про «фундаментальный анализ VS технический». Это статья про «чудес не бывает».




