
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
В этой статье я расскажу о минах, заложенных под производительность, а также об их обнаружении (желательно ещё до взрыва) и обезвреживании.

Что такое мина?
Начнём с того, что лежит у истоков любого знания, — с определения. Древние говорили, что правильно назвать — значит правильно понять. Я думаю, что определение мины под производительностью лучше всего выразить его противопоставлением явной ошибке, например, такой:
String concat(String... strings) {
String result = "";
for (String str : strings) {
result += str;
}
return result;
}Даже начинающим разработчикам известно, что строки неизменяемы, а склеивание их в цикле не означает дописывание данных в хвост уже существующей строки, а создание новой строки при каждом проходе. Если вы оплошали, то не расстраивайтесь — "Идея" вас сразу же предупредит об опасности, а "Сонар" наверняка завалит вашу сборку.
А вот этот код привлечёт куда меньше внимания, да и "Идея" (до версии 2018.2) будет молчать:
Long total = 0L;
List<Long> totals = query.getResultList();
for (Long element : totals) {
total += element == null ? 0 : element;
}Проблема здесь та же самая: обёртки для простых типов неизменяемы, а значит добавление к объектному числу 5 единицы означает создание новой обёртки и запись в него числа 6.
Злую шутку здесь играет наличие в яве двух представлений некоторых типов данных — простого и объектного, а также их автоматическое преобразование средствами самого языка. Из-за этого многие начинающие разработчики думают примерно так: "Ну, исполнение как-нибудь их там само преобразует, это же просто число".
На деле не всё так просто. Возьмём бенчмарк и попробуем сложить числа указанным способом:
(size) Mode Cnt Score Error Units
wrapper 10 avgt 100 23,5 ± 0,1 ns/op
wrapper 100 avgt 100 352,3 ± 2,1 ns/op
wrapper 1000 avgt 100 4424,5 ± 25,2 ns/op
wrapper 10 avgt 100 0 ± 0 B/op
wrapper 100 avgt 100 1872 ± 0 B/op
wrapper 1000 avgt 100 23472 ± 0 B/opСравните с простым типом:
primitive 10 avgt 100 6,4 ± 0,0 ns/op
primitive 100 avgt 100 39,8 ± 0,1 ns/op
primitive 1000 avgt 100 252,5 ± 1,3 ns/op
primitive 10 avgt 100 0 ± 0 B/op
primitive 100 avgt 100 0 ± 0 B/op
primitive 1000 avgt 100 0 ± 0 B/opОтсюда выводим одно из определений мины под производительностью — это код, который не бросается в глаза, не обнаруживается (по крайней мере в то время, когда вы с ним столкнулись) статическими анализаторами, но может тормозить в некоторых использованиях. В нашем случае пока сумма не превышает 127 объекты берутся из кэша и Long всего в 4 раза медленнее чем long. Однако уже для массива размером 100 скорость ниже почти в 10 раз.
Большие мелочи
Иногда незначительное изменение, почти не меняющее смысл исполнения, в некоторых обстоятельствах становится сильным тормозом.
Предположим, у нас есть код:
// org.springframework.data.convert.CustomConversions$ConversionTargetsCache
Map<Object, TypeInformation<?>> cache = new ConcurrentHashMap<>();
private TypeInformation<?> getFromCacheOrCreate(Alias alias) {
TypeInformation<?> info = cache.get(alias);
if (info == null) {
info = getAlias.apply(alias);
cache.put(alias, info);
}
return info;
}На что похожа логика метода?
Это же ConcurrentHashMap::computeIfAbsent!
У нас "восьмёрка" и мы можем круто улучшить код: 6 строк заменить одной, сделав код короче и проще для понимания. Кстати, знатоки многопоточности наверняка укажут на ещё одно улучшение, которое несёт с собой ConcurrentHashMap::computeIfAbsent, но о нём чуть позже ;)
Претворим в жизнь великую мысль:
// org.springframework.data.convert.CustomConversions$ConversionTargetsCache
Map<Object, TypeInformation<?>> cache = new ConcurrentHashMap<>();
private TypeInformation<?> getFromCacheOrCreate(Alias alias) {
return cache.computeIfAbsent(alias, getAlias);
}Чтобы увидеть полный размер нажмите правой клавишей по рисунку и выберите "Открыть изображение в новой вкладке"
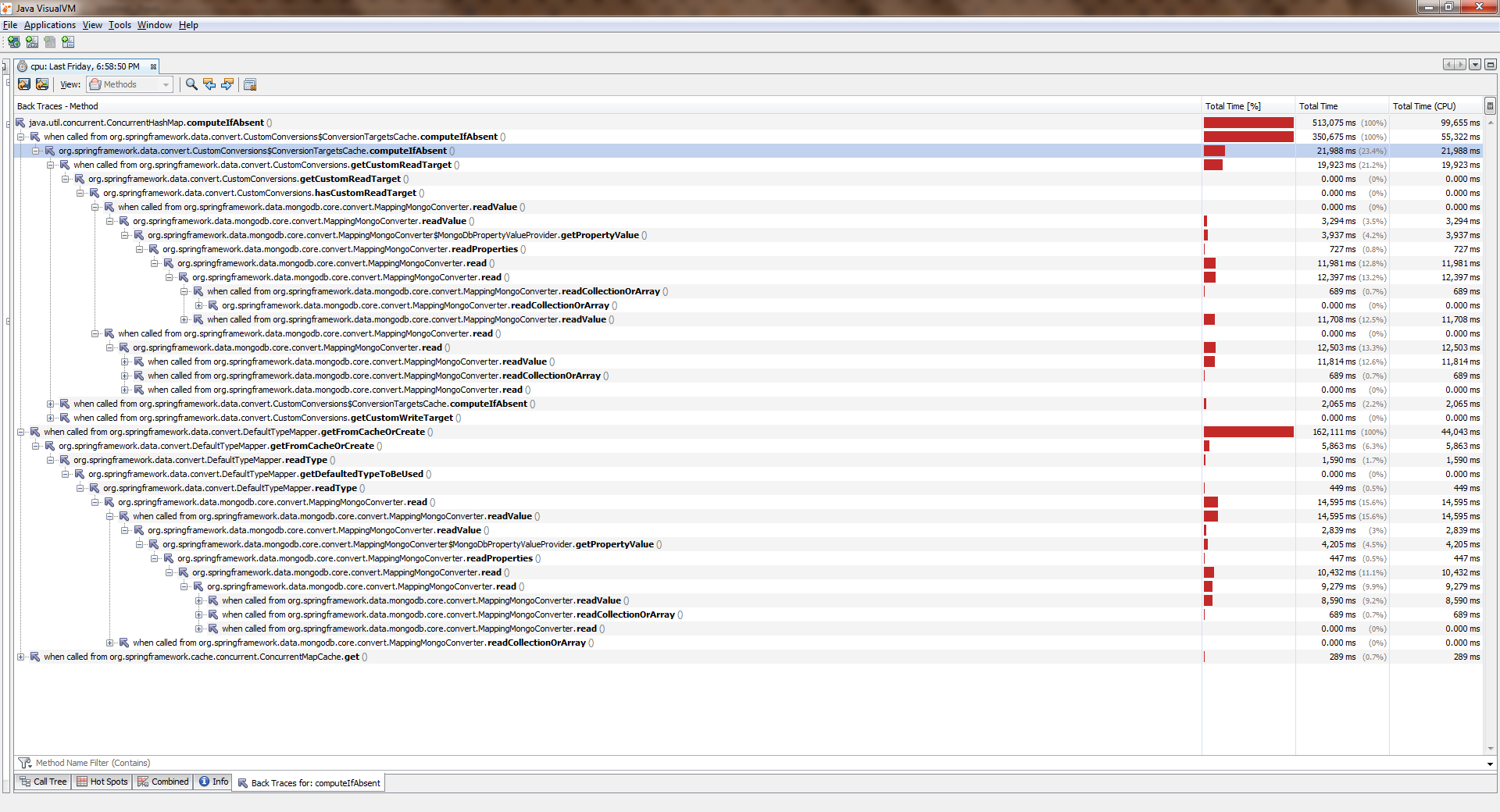
Пока приложение работало с одним потоком — всё было более-менее хорошо. Потоков стало больше и стало ощутимо хуже. Выяснилось, что ConcurrentHashMap::computeIfAbsent блокируется, при чём даже в том случае, когда ключ уже добавлен в словарь. И это стало причиной вполне себе бага в Спринг Дата Монго.
Убедиться в этом можно с помощью простого измерения ("восьмёрка"). Вот его вывод:
Benchmark Mode Cnt Score Error Units
1 thread
computeIfAbsent avgt 20 19,405 ± 0,411 ns/op
getAndPut avgt 20 4,578 ± 0,045 ns/op
2 threads
computeIfAbsent avgt 20 66,492 ± 2,036 ns/op
getAndPut avgt 20 4,454 ± 0,110 ns/op
4 threads
computeIfAbsent avgt 20 155,975 ± 8,850 ns/op
getAndPut avgt 20 5,616 ± 2,073 ns/op
6 threads
computeIfAbsent avgt 20 203,188 ± 10,547 ns/op
getAndPut avgt 20 7,024 ± 0,456 ns/op
8 threads
computeIfAbsent avgt 20 302,036 ± 31,702 ns/op
getAndPut avgt 20 7,990 ± 0,144 ns/opМожно ли это однозначно считать ошибкой разработчиков? По моему скромному мнению — нет, нельзя. В документации сказано:
Some attempted update operations on this map by other threads may be blocked while computation is in progress, so the computation should be short and simple, and must not attempt to update any other mappings of this map
Иными словами ConcurrentHashMap::computeIfAbsent закрывает от внешнего мира ячейку, содержащую ключ (в отличие от ConcurrentHashMap::get), что в общем случае верно, так как позволяет увернуться от гонки при одновременном вызове метода из разных потоков, когда ключ ещё не добавлен.
С другой стороны, в наиболее распространённом режиме работы вычисление значения и связывание его с ключом происходит только при первом обращении, а все последующие обращения только возвращают ранее рассчитанное значение. Посему имеет смысл изменить логику таким образом, чтобы блокировка выставлялась только при изменении. Это было сделано здесь.
В более свежих изданиях (>8) ConcurrentHashMap::computeIfAbsent стал шустрее:
JDK 11
Benchmark Mode Cnt Score Error Units
1 thread
computeIfAbsent avgt 20 6,983 ± 0,066 ns/op
getAndPut avgt 20 5,291 ± 1,220 ns/op
2 threads
computeIfAbsent avgt 20 7,173 ± 0,249 ns/op
getAndPut avgt 20 5,118 ± 0,395 ns/op
4 threads
computeIfAbsent avgt 20 7,991 ± 0,447 ns/op
getAndPut avgt 20 5,270 ± 0,366 ns/op
6 threads
computeIfAbsent avgt 20 11,919 ± 0,865 ns/op
getAndPut avgt 20 7,249 ± 0,199 ns/op
8 threads
computeIfAbsent avgt 20 14,360 ± 0,892 ns/op
getAndPut avgt 20 8,511 ± 0,229 ns/opОбратите внимание на коварство этого примера: смысловое содержание почти не изменилось, ведь на первый взгляд мы всего-лишь использовали более продвинутый синтаксис. При этом пока приложение работает в одну нить, пользователь почти не чувствует разницы! Вот так вроде бы безобидные изменения подкладывают свинью мину под нашу производительность.
Не всегда ConcurrentHashMap::computeIfAbsent взаимозаменяем с выражением getAndPut, потому что ConcurrentHashMap::computeIfAbsent является атомарной операцией. В этом же коде
private TypeInformation<?> getFromCacheOrCreate(Alias alias) {
TypeInformation<?> info = cache.get(alias);
if (info == null) {
info = getAlias.apply(alias);
cache.put(alias, info);
}
return info;
}из-за отсутствия внешней синхронизации появляется гонка. Если функция, передаваемая в ConcurrentHashMap::computeIfAbsent для заданного ключа всегда возвращает одно и то же значения, то это "безопасная" гонка, самое большее, что нам грозит — это вычисление одного и того же значения 2 и более раз. Если же таких гарантий нет, то механическая замена чревата поломкой приложения. Будьте осторожны!
Эти руки ничего не меняли
Бывает и так, что код вообще не меняется, но внезапно начинает тормозить.
Представьте, что перед нами стоит задача переложить элементы массива в коллекцию. Наиболее логичным будет использовать готовый метод Collection::addAll, да вот незадача — он принимает коллекцию:
public interface Collection<E> extends Iterable<E> {
boolean addAll(Collection<? extends E> c);
}Самый простой выход — завернуть массив в Arrays::asList. Получится что-то вроде
boolean addItems(Collection<T> collection) {
T[] items = getArray();
return collection.addAll(Arrays.asList(items));
}В ходе вычитки заботящиеся о производительности коллеги наверняка укажут нам, что в этом коде есть сразу две проблемы:
- заворачивание массива в список (лишний объект)
- создание итератора (ещё один лишний объект) и проход по нему
В самом деле, в опорной реализации Collection::addAll мы увидим вот это:
public abstract class AbstractCollection<E> implements Collection<E> {
public boolean addAll(Collection<? extends E> c) {
boolean modified = false;
for (E e : c) {
if (add(e))
modified = true;
}
return modified;
}
}Таки здесь создаётся итератор и элементы перебираются с его помощью. Поэтому опытные товарищи предлагают своё решение:
boolean addItems(Collection<T> collection) {
T[] items = getArray();
return Collections.addAll(collection, items);
}Внутри код, вполне справедливо кажущийся более производительным:
public static <T> boolean addAll(Collection<? super T> c, T... elements) {
boolean result = false;
for (T element : elements)
result |= c.add(element);
return result;
}Во-первых, не создаётся итератор. Во-вторых, проход идёт в обычном счётном цикле, к тому же массивы хорошо ложатся в кэши, его элементы расположены в памяти последовательно (значит будет мало кэш-миссов), а доступ к ним по индексу очень быстрый. Ну и список-обёртка тоже не создаётся. Звучит веско и обоснованно.
Наконец, коллеги приводят ultima ratio regum: документацию. А там серым по белому (или зелёным по чёрному) сказано:
/**
* ...
* The behavior of this convenience method is identical to that of
* c.addAll(Arrays.asList(elements)), but this method is likely
* to run significantly faster under most implementations. <----
* @since 1.5
*/
@SafeVarargs
public static <T> boolean addAll(Collection<? super T> c, T... elements) {
//...
}Т. е. сами разработчики (а кому верить, как не им?) пишут, что для большинства реализаций утилитный метод работает значительно быстрее. И он действительно быстрее. Иногда.
Убедиться в этом поможет бенчмарк, который мы запустим для HashSet-а на "восьмёрке":
Benchmark (collection) (size) Mode Cnt Score Error Units
addAll HashSet 10 avgt 100 155,2 ± 2,8 ns/op
addAll HashSet 100 avgt 100 1884,4 ± 37,4 ns/op
addAll HashSet 1000 avgt 100 17917,3 ± 298,8 ns/op
collectionsAddAll HashSet 10 avgt 100 136,1 ± 0,8 ns/op
collectionsAddAll HashSet 100 avgt 100 1538,3 ± 31,4 ns/op
collectionsAddAll HashSet 1000 avgt 100 15168,6 ± 289,4 ns/opПохоже, что более опытные товарищи оказались правы. Почти.
В более поздних изданиях (например, в 11) блеск утилитного метода несколько потускнеет:
Benchmark (collection) (size) Mode Cnt Score Error Units
addAll HashSet 10 avgt 100 143,1 ± 0,6 ns/op
addAll HashSet 100 avgt 100 1738,4 ± 7,3 ns/op
addAll HashSet 1000 avgt 100 16853,9 ± 101,0 ns/op
collectionsAddAll HashSet 10 avgt 100 132,1 ± 1,1 ns/op
collectionsAddAll HashSet 100 avgt 100 1661,1 ± 7,1 ns/op
collectionsAddAll HashSet 1000 avgt 100 15450,9 ± 93,9 ns/opВидно, что ни о каком "значительно быстрее" речь не идёт. А если мы повторим опыт для ArrayList-a, то окажется, что утилитный метод начинает сильно проигрывать (чем дальше — тем сильнее):
Benchmark (collection) (size) Mode Cnt Score Error Units
JDK 8
addAll ArrayList 10 avgt 100 38,5 ± 0,5 ns/op
addAll ArrayList 100 avgt 100 188,4 ± 7,0 ns/op
addAll ArrayList 1000 avgt 100 1278,8 ± 42,9 ns/op
collectionsAddAll ArrayList 10 avgt 100 62,7 ± 0,7 ns/op
collectionsAddAll ArrayList 100 avgt 100 495,1 ± 2,0 ns/op
collectionsAddAll ArrayList 1000 avgt 100 4892,5 ± 48,0 ns/op
JDK 11
addAll ArrayList 10 avgt 100 26,1 ± 0,0 ns/op
addAll ArrayList 100 avgt 100 161,1 ± 0,4 ns/op
addAll ArrayList 1000 avgt 100 1276,7 ± 3,7 ns/op
collectionsAddAll ArrayList 10 avgt 100 41,6 ± 0,0 ns/op
collectionsAddAll ArrayList 100 avgt 100 492,6 ± 1,5 ns/op
collectionsAddAll ArrayList 1000 avgt 100 6792,7 ± 165,5 ns/opНичего неожиданного здесь нет, ArrayList построен вокруг массива, поэтому разработчики дальновидно переопределили метод Collection::addAll:
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
modCount++;
int numNew = a.length;
if (numNew == 0)
return false;
Object[] elementData;
final int s;
if (numNew > (elementData = this.elementData).length - (s = size))
elementData = grow(s + numNew);
System.arraycopy(a, 0, elementData, s, numNew); <--- переносим данные пачкой
size = s + numNew;
return true;
}Теперь вернёмся к нашим минам. Предположим, что мы всё же приняли предложенное на вычитке решение и оставили этот код:
boolean addItems(Collection<T> collection) {
T[] items = getArray();
return Collections.addAll(collection, items);
}До поры до времени всё хорошо, но после добавления нового функционала метод иногда становится горячим и начинает тормозить. Открываем исходники — код не менялся. Объём данных тот же. А производительность сильно просела. Это ещё одна разновидность мин.
Расчехляем отладчик и находим прекрасное:

Обратите внимание: мы не меняли алгоритм, объём обрабатываемых данных не изменился, но изменилась их природа и в нашем коде завелась проблема производительности:
Java 8 Java 11
размер
addAll 10 56,9 25,2 ns/op
collectionsAddAll 10 352,2 142,9 ns/op
addAll 100 159,9 84,3 ns/op
collectionsAddAll 100 4607,1 3964,3 ns/op
addAll 1000 1244,2 760,2 ns/op
collectionsAddAll 1000 355796,9 364677,0 ns/opНа больших массивах разница между Collections::addAll и Collection::addAll составляет скромных 500 раз. Дело в том, что COWList не просто расширяет существующий массив, а создаёт новый при каждом добавлении элементов:
public boolean add(E e) {
synchronized (lock) {
Object[] es = getArray();
int len = es.length;
es = Arrays.copyOf(es, len + 1); <---- привет сборщику мусора
es[len] = e;
setArray(es);
return true;
}
}Кто виноват?
https://bugs.openjdk.java.net/browse/JDK-8193031
http://cr.openjdk.java.net/~martin/webrevs/jdk/Collections-addAll/
Основная проблема здесь в том, что метод Collections::addAll принимает интерфейс, при этом у метода addAll нет тела. Нет тела — нет дела, поэтому документация написана исходя из реализации, существующей в AbstractCollection::addAll, которая является обобщённым алгоритмом, применимым для всех коллекций. Это означает, что более конкретные реализации структур данных, находящиеся на более низком уровне абстракции, могут изменять это поведение.
Collection::addAll – верхний уровень
AbstractCollection::addAll – средний уровень <--- описано в документации
ArrayList::addAll
HashSet::addAll – нижний уровень <--- тут может быть что угодно
COWList::addAllЕщё об абстракциях
Раз уж мы заговорили об уровнях абстракции, то расскажу об одном примере из жизни.
Давайте сравним эти два способа сохранения энного количество сущностей в базу:
@Transactional
void save(int n) {
for (int i = 0; i < n; i++) {
SimpleEntity e = new SimpleEntity();
repository.save(e);
}
}
@Transactional
void _save(int n) {
for (int i = 0; i < n; i++) {
SimpleEntity e = new SimpleEntity();
repository.saveAndFlush(e);
}
}На первый взгляд, производительность обоих способов не должна особо отличаться, ведь
- в обоих случаях в базу будет сохранено одинаковое количество сущностей
- если ключ берётся из последовательности, то количество обращение будет одинаковым
- объём передаваемых данных одинаков
Обратимся к методу SimpleJpaRepository::saveAndFlush:
@Transactional
public <S extends T> S save(S entity) {
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
@Transactional
public <S extends T> S saveAndFlush(S entity) {
S result = save(entity);
flush();
return result;
}
@Transactional
public void flush() {
em.flush();
}Стрёмным местом здесь является метод flush(). Почему стрёмным? Как мне кажется, его раскрытие в интерфейсе JpaRepository было ошибкой разработчиков. Попробую обосновать свою мысль. Обычно этот метод вообще не используется разработчиком, т. к. вызов EntityManager::flush привязан к завершению транзакции, управляемой Спрингом:
// управление сессией передано каркасу
@Transactional
public void method() { <-- скрытый Session::open
/*.*/
} <-- скрытый Session::flushОбратите внимание: EntityManager — это часть спецификации JPA, реализованный в Хибернейте в виде сессии (интерфейс Session и класс SessionImpl, соответственно). Спринг Дата — это каркас, работающий поверх ORM-а, в данном случае — поверх Хибернейта. Получается, что метод JpaRepository::saveAndFlush даёт нам доступ к нижним уровням API, хотя задача фреймворка как раз в сокрытии низкоуровневых подробностей (ситуация чем-то похожа на историю с Unsafe в JDK).
В нашем случае при использовании JpaRepository::saveAndFlush мы влезаем в низшие слои приложения, ломая тем самым кое-что.
Ломается способность Хибернейта отправлять данные пачками, кратно настройке jdbc.batch_size, которая указывается в application.yml:
spring:
jpa:
properties:
hibernate:
jdbc.batch_size: 500Работа Хибернейта построена на событиях, поэтому что при сохранении 1000 сущностей вот так
@Transactional
void save(int n) {
for (int i = 0; i < n; i++) {
SimpleEntity e = new SimpleEntity();
repository.save(e);
}
}при вызове repository.save(e) не происходит мгновенного сохранения. Вместо этого создаётся событие, которое ставится в очередь. По завершению транзакции данные сливаются при помощи EntityManager::flush, который делит вставки/обновления на пачки кратно jdbc.batch_size и создаёт из них запросы. В нашем случае jdbc.batch_size: 500, так что сохранение 1000 сущностей на деле означает лишь 2 запроса.
А вот с ручным сливом сессии на каждом проходе цикла
@Transactional
void _save(int n) {
for (int i = 0; i < n; i++) {
SimpleEntity e = new SimpleEntity();
repository.saveAndFlush(e);
}
}очередь очищается и сохранение 1000 сущностей означает 1000 запросов.
Таким образом, вмешательство в низшие слои приложения может легко стать миной, при чём не только миной производительности (см. Unsafe и его неконтролируемое применение).
Насколько сильно это тормозит? Возьмём самый лучший (для нас) случай — БД находится на том же хосте, что и приложение. Мой замер показывает такую картину:
(entityCount) Mode Cnt Score Error Units
bulkSave 10 ss 500 16,613 ± 1,714 ms/op
bulkSave 100 ss 500 31,371 ± 1,453 ms/op
bulkSave 1000 ss 500 35,687 ± 1,973 ms/op
bulkSaveUsingFlush 10 ss 500 32,653 ± 2,166 ms/op
bulkSaveUsingFlush 100 ss 500 61,983 ± 6,304 ms/op
bulkSaveUsingFlush 1000 ss 500 184,814 ± 6,976 ms/opОчевидно, что если БД находится на удалённом хосте, то затраты на передачу данных будут всё более ухудшать производительность по мере роста объёма данных.
Таким образом, работая на неправильном уровне абстракции можно легко создать мину замедленного действия. Кстати, в одной из своих предыдущих статей я рассказывал о курьёзной попытке улучшения StringBuilder-a: там меня постигла неудача как раз при попытке влезть в более абстрактный уровень кода.
Границы минных полей
Поиграем в сапёра? Найди мину:
// org.springframework.cache.interceptor.CacheAspectSupport
Object generateKey(CacheOperationContext ctx, Object result) {
Object key = ctx.generateKey(result);
Assert.notNull(key, "Null key ..." + context.metadata.operation);
// ...
return key;
} |
\ /
// org.springframework.cache.interceptor.CacheAspectSupport
|
\ /
Object generateKey(CacheOperationContext ctx, Object result) {
Object key = ctx.generateKey(result);
|
\ /
Assert.notNull(key, "Null key ..." + context.metadata.operation);
return key;
}"Издеваетесь?", — воскликнет критик, — "Да там всего-лишь склейка двух строк? Какое это имеет значение в кровавом Э.?" Позвольте обратить ваше внимание на то, что я выделил не только склейку строк, а ещё и имя класс и название метода. Ведь опасность склейки строк не в самой склейке, а в том, что происходит она в методе, создающем ключи для кэша, т. е. в определённых сценариях у нас будет очень много обращений к этому методу, а значит очень много мусорных строк.
Поэтому сообщение об ошибке нужно создавать только тогда, когда эта ошибка действительно будет выброшена:
// org.springframework.cache.interceptor.CacheAspectSupport
Object generateKey(CacheOperationContext ctx, Object result) {
Object key = ctx.generateKey(result);
if (key == null) {
throw new IAE("Null key ..." + context.metadata.operation);
}
// ...
return key;
}Таким образом, минные поля имеют границы — это тот объём данных, частота обращения к методу и т. п. количественные показатели, при достижении и превышении которых незначительный недостаток становится статистически значимым.
С другой стороны — это та черта, до пересечения которой усложнение кода не даёт значимого (измеримого) улучшения.
Отсюда ещё один вывод для разработчика: в большинстве случаев крохоборство — это зло, ведущее к бессмысленному усложнению кода. В 99 случаях из 100 мы ничего не выигрываем.
При этом нужно помнить, что всегда есть
Тот самый сотый случай
Вот код, который приводит в своей статье The volatile read surprise Ницан Вакарт:
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@State(Scope.Thread)
public class LoopyBenchmarks {
@Param({ "32", "1024", "32768" })
int size;
byte[] bunn;
@Setup
public void prepare() {
bunn = new byte[size];
}
@Benchmark
public void goodOldLoop(Blackhole fox) {
for (int y = 0; y < bunn.length; y++) { // good old C style for (the win?)
fox.consume(bunn[y]);
}
}
@Benchmark
public void sweetLoop(Blackhole fox) {
for (byte bunny : bunn) { // syntactic sugar loop goodness
fox.consume(bunny);
}
}
}Когда мы поставим опыт, то обнаружим удивительную разницу между двумя способами перебора массива:
Benchmark (size) Score Score error Units
goodOldLoop 32 46.630 0.097 ns/op
goodOldLoop 1024 1199.338 0.705 ns/op
goodOldLoop 32768 37813.600 56.081 ns/op
sweetLoop 32 19.304 0.010 ns/op
sweetLoop 1024 475.141 1.227 ns/op
sweetLoop 32768 14295.800 36.071 ns/opЗдесь неопытный разработчик может сделать такой очевидный и подкреплённый бенчмарками вывод: проход по массиву с помощью нового синтаксиса работает быстрее, чем счётный цикл. Это неверный вывод, ведь стоит немного изменить метод goodOldLoop:
@Benchmark
public void goodOldLoopReturns(Blackhole fox) {
byte[] sunn = bunn; // make a local copy of the field
for (int y = 0; y < sunn.length; y++) {
fox.consume(sunn[y]);
}
}и его показатели сравняются с показателями "более быстрого" метода sweetLoop:
Benchmark (size) Score Score error Units
goodOldLoopReturns 32 19.306 0.045 ns/op
goodOldLoopReturns 1024 476.493 1.190 ns/op
goodOldLoopReturns 32768 14292.286 16.046 ns/op
sweetLoop 32 19.304 0.010 ns/op
sweetLoop 1024 475.141 1.227 ns/op
sweetLoop 32768 14295.800 36.071 ns/opДело здесь в коварном Blackhole::consume:
//...
public volatile byte b1, b2;
public volatile BlackholeL2 nullBait = null;
/**
* Consume object. This call provides a side effect preventing JIT to eliminate dependent computations.
*
* @param b object to consume.
*/
public final void consume(byte b) {
if (b == b1 & b == b2) {
// SHOULD NEVER HAPPEN
nullBait.b1 = b; // implicit null pointer exception
}
}благодаря которому внутри нашего цикла внезапно нарисовался волатильный доступ, который действует подобно барьеру, запрещая компилятору некоторые перестановки и улучшения. В первой версии метода goodOldLoop компилятор вынужден загружать из памяти поле this.bunn при каждом проходе цикла, а for-each цикл делает это лишь единожды, выполняя неявное сохранение поля в местную переменную (ЕМНИП, в Java Concurrency In Practice это называется "синхронизация на стеке"). Именно этим объясняется разница в показателях.
Критически настроенный читатель скажет: "Какое значение это имеет в повседневной работе? Этот пример искусственный, Blackhole::consume — часть инфраструктуры JMH и в обычной разработке никогда не используется. И вообще, какая разница, как именно перебирать массив в реальном коде?"
Чтобы отразить этот убийственный аргумент давайте внимательно посмотрим на пример:
byte[] bunn;
public void goodOldLoop(Blackhole fox) {
for (int y = 0; y < bunn.length; y++) {
fox.consume(bunn[y]);
}
}Ничего не напоминает? Точно? Что же, давайте внесём некоторые изменения:
E[] bunn;
public void forEach(Consumer<E> fox) {
for (int y = 0; y < bunn.length; y++) {
fox.consume(bunn[y]);
}
}Получился Iterable::forEach! И если открыть реализации этого метода для коллекций, работающих поверх массива, то внезапно все они используют либо сахарный цикл, либо сохранение в переменную перед проходом (все исходники из JDK 13):
//ArrayList
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
final int expectedModCount = modCount;
final Object[] es = elementData;
final int size = this.size;
for (int i = 0; modCount == expectedModCount && i < size; i++)
action.accept(elementAt(es, i));
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
//Arrays$ArrayList
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
for (E e : a) {
action.accept(e);
}
}
//CopyOnWriteArrayList
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
for (Object x : getArray()) {
@SuppressWarnings("unchecked") E e = (E) x;
action.accept(e);
}
}
//ArrayDeque
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
final Object[] es = elements;
for (int i = head, end = tail, to = (i <= end) ? end : es.length; ; i = 0, to = end) {
for (; i < to; i++)
action.accept(elementAt(es, i));
if (to == end) {
if (end != tail) throw new ConcurrentModificationException();
break;
}
}
}А помнить об этом нужно, когда вы реализовываете свою структуру данных или улучшаете уже существующую. Например, не так давно поступило предложение об улучшении Collections.nCopies()::forEach:
@Override
public void forEach(final Consumer<? super E> action) {
Objects.requireNonNull(action);
for (int i = 0; i < this.n; i++) {
action.accept(this.element);
}
}На первый взгляд в этом коде нет необходимости выполнять синхронизацию на стеке, т. к. значения полей this.n и this.element записываются только один раз при создании объекта:
private static class CopiesList<E>
extends AbstractList<E>
implements RandomAccess, Serializable {
final int n;
final E element;
CopiesList(int n, E e) {
assert n >= 0;
this.n = n;
element = e;
}Как оказалось, полагаться на это нельзя, равно как и на @Stable.
Обратите внимание: в 99 случаях из 100 совершенно неважно, как именно вы обходите массив, но всегда есть 1 случай из 100, в котором внутри цикла окажется волатильный доступ и неверное решение станет проблемой производительности. Это ещё один пример мины, срабатывающей только в особых условиях.
Водной из своих статей я показывал похожий пример разрушительного воздействия на производительность связки "цикл и volatile".
Эхо войны
Завершить статью хочу примером древнего улучшения, которое стало миной:
//java.lang.Integer
@HotSpotIntrinsicCandidate
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}Когда-то давно разработчики посчитали, что неплохо было бы кэшировать значения некоторых типов (java.lang.Integer, java.lang.Long, java.lang.Short, java.lang.Byte, java.lang.Character). Более того, это внесли в спецификацию языка, поэтому когда мы пишем
Integer intgr = Integer.valueOf(42);новый объект не создаётся.
Если мы дерзнём писать вот так:
Integer intgr = new Integer(42);то все статические анализаторы завопят про ухудшение производительности, ФайндБагз и Сонар будут заваливать сборки до тех пор, пока мы не вернёмся к каноничному Integer::valueOf вместо богомерзкого конструктора.
Спустя некоторое время были внедрены куда более крутые усовершенствования: анализ области видимости переменной и скаляризация. Их связка позволяет вместо создания объекта в куче отобразить его в виде набора полей на стеке, в тех случаях, когда объект не утекает из "родного" метода (или утекает недалеко после вклеивания тела метода в точку вызова). И внезапно оказалось, что эта оптимизация работает с конструктором и ломается, если заворачиваемое простое значение протаскивается через кэш внутри Integer::valueOf. Подробно эта история описана в докладе "Сжимай меня полностью".
На сегодня всё. Помните, что даже очень простой код в определённых условиях может быть очень и очень коварным. Надеюсь, мои примеры помогут вам в повседневной работе. Если у вас есть свои примеры, то я буду признателен, если вы поделитесь ими в комментариях.


