
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Robot factory by lucart
MLflow — один из самых стабильных и легких инструментов, позволяющий специалистам по Data Science управлять жизненным циклом моделей машинного обучения. Это удобный инструмент с простым интерфейсом для просмотра экспериментов и мощными средствами упаковки управления, развертывания моделей. Он позволяет работать практически с любой библиотекой машинного обучения.
Я Александр Волынский, архитектор облачной платформы Mail.ru Cloud Solutions. В прошлой статье мы рассмотрели Kubeflow. MLflow — это еще один инструмент для построения MLOps, для работы с которым не обязателен Kubernetes.
Подробно про MLOps я рассказывал в прошлой статье, сейчас лишь кратко упомяну основные тезисы.
- MLOps — это DevOps в сфере машинного обучения.
- Помогает стандартизировать процесс разработки моделей машинного обучения.
- Сокращает время выкатки моделей в продакшен.
- Включает в себя задачи трекинга моделей, версионирования и мониторинга.
Все это позволяет бизнесу получать больше пользы от моделей машинного обучения.
Итак, в ходе этой статьи мы:
- Развернем в облаке сервисы, которые выполняют роль бэкенда для MLflow.
- Установим и настроим MLflow Tracking Server.
- Развернем JupyterHub и настроим его для работы с MLflow.
- Протестируем ручное и автоматическое логирование параметров и метрик экспериментов.
- Попробуем различные способы публикации моделей.
Важно, что мы сделаем это максимально близко к продакшен-варианту. Большинство инструкций, которые есть в интернете, предлагают развернуть MLflow на локальной машине или из докер-образа. Эти варианты подойдут для ознакомления и быстрых экспериментов, но не для продакшена. Мы же будем использовать надежные облачные сервисы.
Если вы предпочитаете видеоинструкцию, то можете посмотреть вебинар «MLflow в облаке. Простой и быстрый способ вывести ML модели в продакшен».
MLflow: назначение и основные компоненты
MLflow — это Open Source-платформа, предназначенная для управления жизненным циклом моделей машинного обучения. В том числе она решает задачи воспроизведения экспериментов, публикации моделей и включает в себя центральный реестр моделей.
В отличие от Kubeflow, MLflow может работать без Kubernetes. Но при этом MLflow умеет упаковывать модели в Docker-образы, чтобы потом их можно было развернуть в Kubernetes.
MLflow состоит из нескольких компонентов.
MLflow Tracking. Это удобный UI, в котором можно просматривать артефакты: графики, примеры данных, датасеты. Также можно смотреть метрики и параметры моделей. У MLflow Tracking есть API для разных языков программирования, с помощью которого можно логировать метрики, параметры и артефакты. Поддерживаются Python, Java, R, REST.
В MLflow Tracking есть две важных концепции: runs и experiments.
- Run — это единичная итерация эксперимента. Например, вы задали параметры модели и запускаете ее на обучение. На этот единичный запуск появится новая запись в MLflow Tracking. При изменении параметров модели будет создан новый run.
- Experiment позволяет сгруппировать несколько запусков (Run) в одну сущность, чтобы их можно было удобно просматривать.
Развернуть MLflow Tracking можно в различных сценариях. Мы будем использовать самый близкий к продакшену вариант — сценарий №4 (так он называется в официальной документации MLflow).
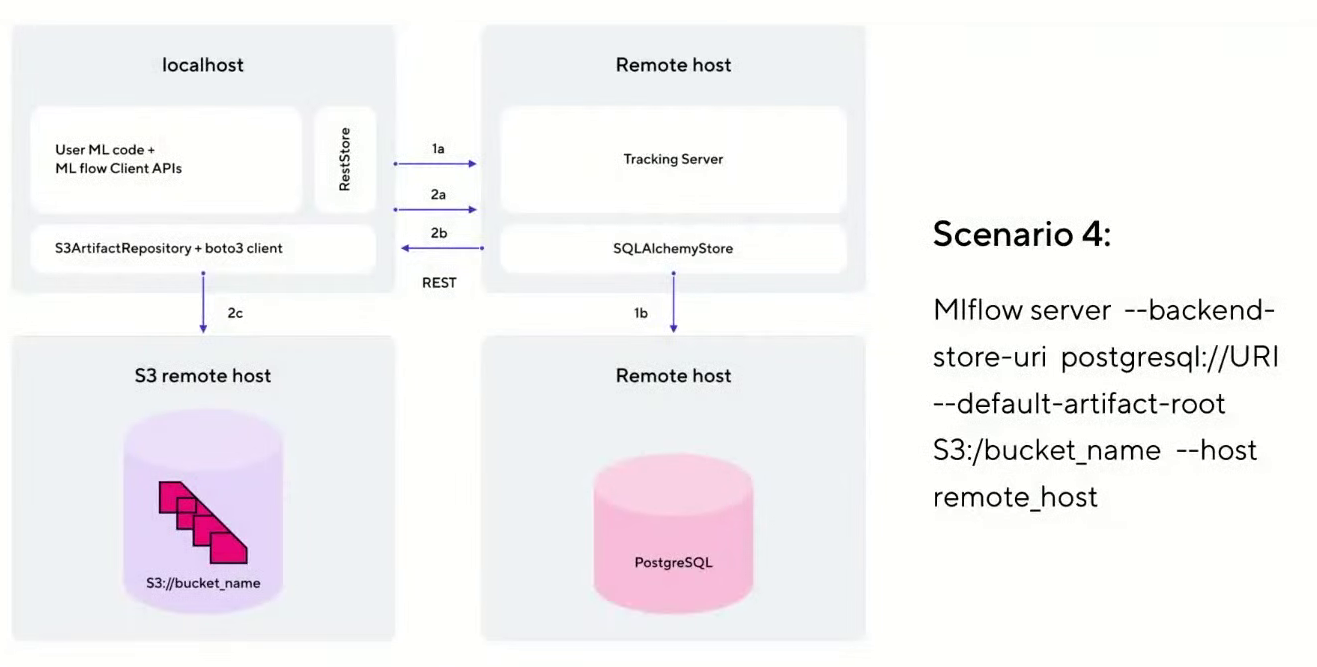
В этом варианте есть хост, на котором разворачиваются JupyterHub. Он взаимодействует с Tracking Server, размещенным на отдельной виртуальной машине в облаке. Для хранения метаданных об экспериментах используется PostgreSQL, который мы развернем как сервис в облаке. А все артефакты и модели хранятся отдельно в объектном хранилище S3.
MLflow Models. Этот компонент отвечает за упаковку, хранение и публикацию моделей. Он представляет собой концепцию flavor. Это своего рода обертка, которая позволяет использовать модель в различных инструментах и фреймворках без необходимости дополнительных интеграций. Например, можно использовать модели из Scikit-learn, Keras, TenserFlow, Spark MLlib и других фреймворков.
Также MLflow Models позволяет делать модели доступными по REST API и упаковывать их в Docker-образ для последующего использования в Kubernetes.
MLflow Registry. Этот компонент представляет собой центральный репозиторий моделей. Он включает в себя UI, который позволяет добавлять теги и описание для каждой модели. Также он позволяет сравнивать разные модели между собой, например, чтобы увидеть отличия в параметрах.
MLflow Registry управляет жизненным циклом модели. В контексте MLflow есть три стадии жизненного цикла: Staging, Production и Archived. Также есть поддержка версионности. Все это позволяет удобно управлять всей выкаткой моделей.
MLflow Projects. Это способ организации и описания кода. Каждый проект — директория с набором файлов, чаще всего это пайплайны. Каждый проект описывается отдельным файлом MLProject в формате yaml. В нем указываются имя проекта, окружение и entrypoints. Это позволяет воспроизводить эксперимент в другом окружении. Также есть CLI и API для Python.
При помощи MLflow Projects можно создавать модули, которые представляют собой некие переиспользуемые шаги. Затем эти модули можно встраивать в более сложные пайплайны, что позволяет стандартизировать их.
Инструкция по установке и настройке MLflow
Шаг 1: разворачиваем сервисы в облаке, которые выполняют роль бэкенда
Для начала мы создадим виртуальную машину, на которой развернем MLflow Tracking Server. Мы будем делать это на нашей облачной платформе Mail.ru Cloud Solutions (новые пользователи тут получают 3000 бонусных ₽ на тестирование, так что вы можете зарегистрироваться и повторить всё, что тут описано).
Перед началом работы нужно настроить сеть, сгенерировать и загрузить SSH-ключ для подключения к виртуальной машине. Вы можете самостоятельно настроить сеть по инструкции.
Заходим в панель MCS, раздел «Облачные вычисления — Виртуальные машины», и нажимаем кнопку «Добавить». Далее задаем параметры новой виртуальной машины. Для примера мы возьмем конфигурацию с 4 CPU и 8 ГБ RAM. Выберем ОС — Ubuntu 18.04.
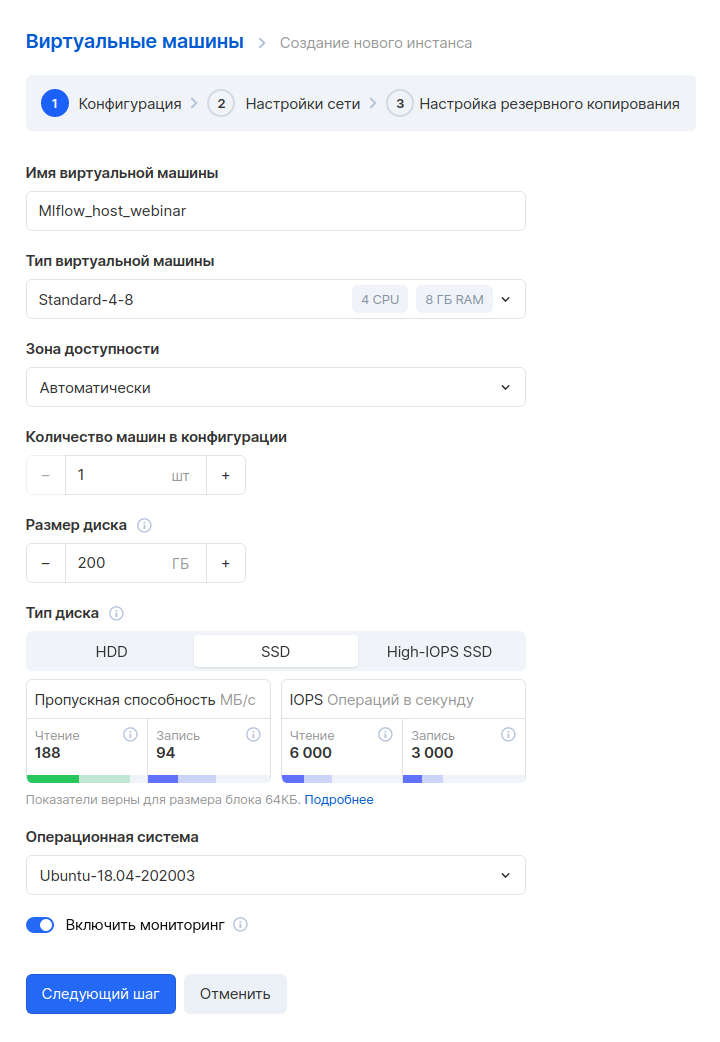
Следующий шаг — настройка сети. Так как мы уже заранее создали сеть, здесь ее нужно просто выбрать. Обратите внимание, что в настройках Firewall указано кастомное правило — only_my_ip. Этого правила нет по умолчанию, мы его создали самостоятельно, чтобы к виртуальной машине можно было подключаться только с определенного адреса. Мы рекомендуем вам сделать также, чтобы повысить безопасность. Вот инструкция, как создавать свои правила.
Также нужно назначить внешний IP, чтобы к машине можно было подключаться из интернета.
На следующем шаге задаем резервное копирование. Можно оставить настройки по умолчанию, если они вас устраивают.
Создаем инстанс и ждем несколько минут. Когда виртуальная машина будет готова, нужно будет записать ее внутренний и внешние адреса, они пригодятся далее.

Далее создадим базу данных. Заходим в раздел «Базы данных» и нажимаем кнопку «Добавить». Выбираем PostgreSQL 12 в конфигурации Master-slave.
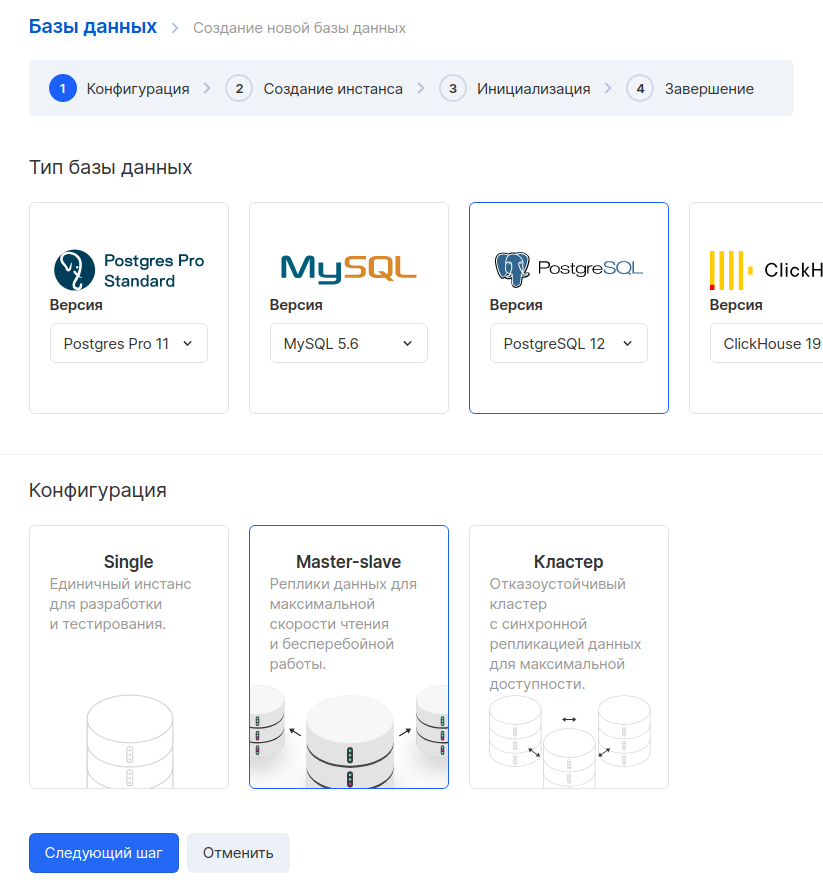
На следующем шаге задаем параметры виртуальной машины. Для примера мы взяли конфигурацию с 1 CPU и 2 ГБ RAM. Внешний IP можно не назначать, потому что к этой машине мы будем обращаться только из внутренней сети. Важно выбрать ту же самую сеть, которую мы выбирали для виртуальной машины с Tracking Server.

На следующем шаге нужно сгенерировать имя БД, пользователя и пароль. Хорошей практикой является создавать для каждого сервиса отдельную БД и отдельного пользователя.
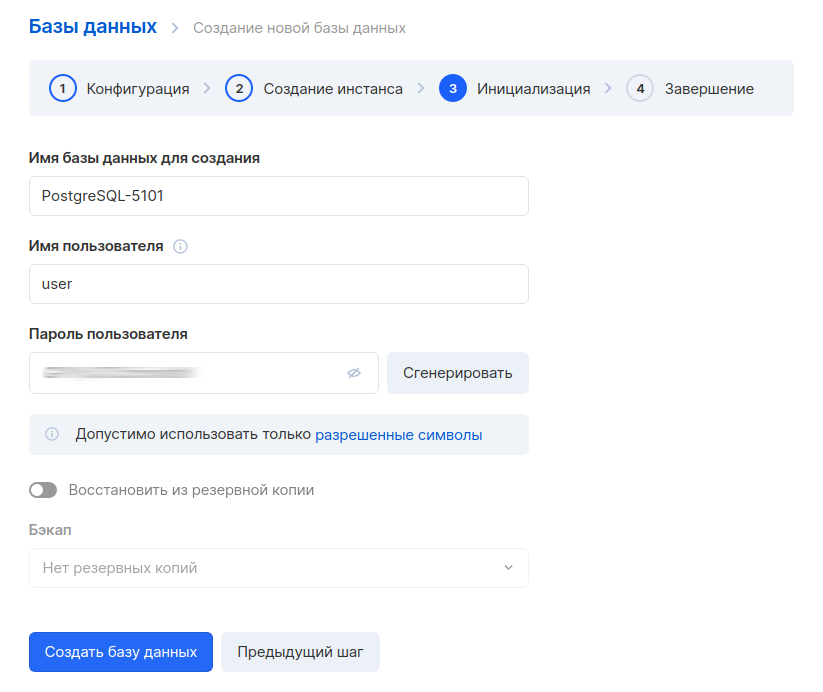
После создания БД также нужно записать внутренний адрес. Он понадобится для настройки соединения c MLflow.
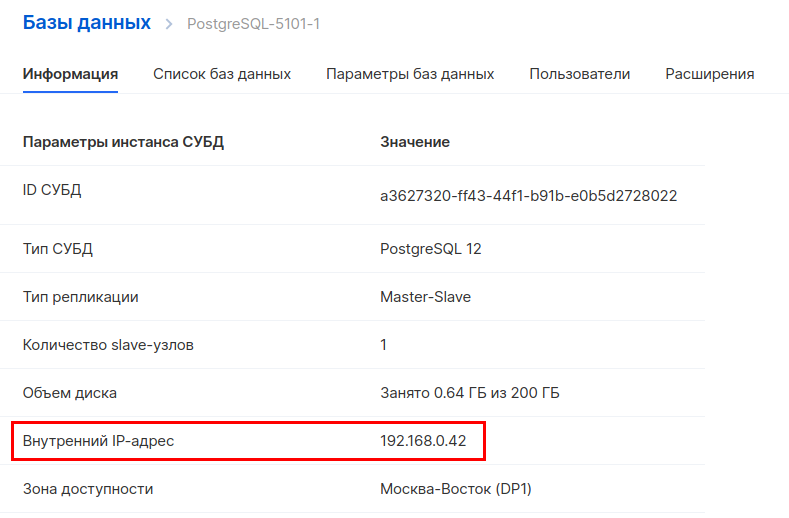
Далее нужно создать в объектном хранилище новый бакет. Переходим в раздел «Объектное хранилище — Бакеты» и создаем новый бакет. При создании указываем имя и тип — Hotbox.

Создадим внутри бакета директорию. Для этого заходим в него и нажимаем «Создать папку». По умолчанию в инструкции MLflow используется название папки artifacts, поэтому мы будем использовать такое же название.
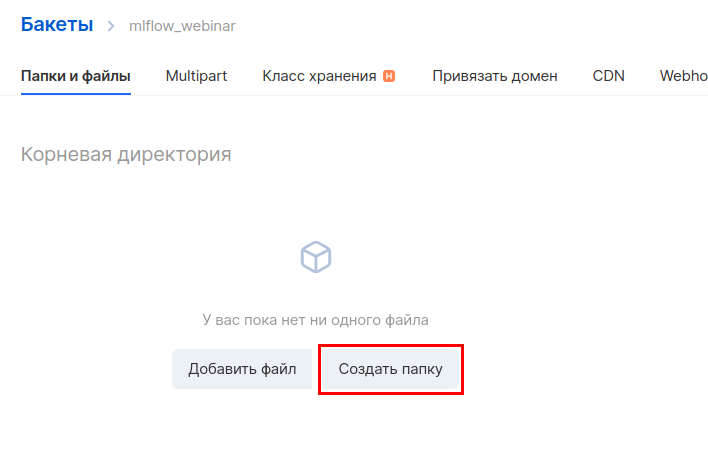
Далее необходимо создать отдельный аккаунт для доступа к этому бакету. В разделе «Объектное хранилище» заходим в подраздел «Аккаунты» и нажимаем «Добавить аккаунт».
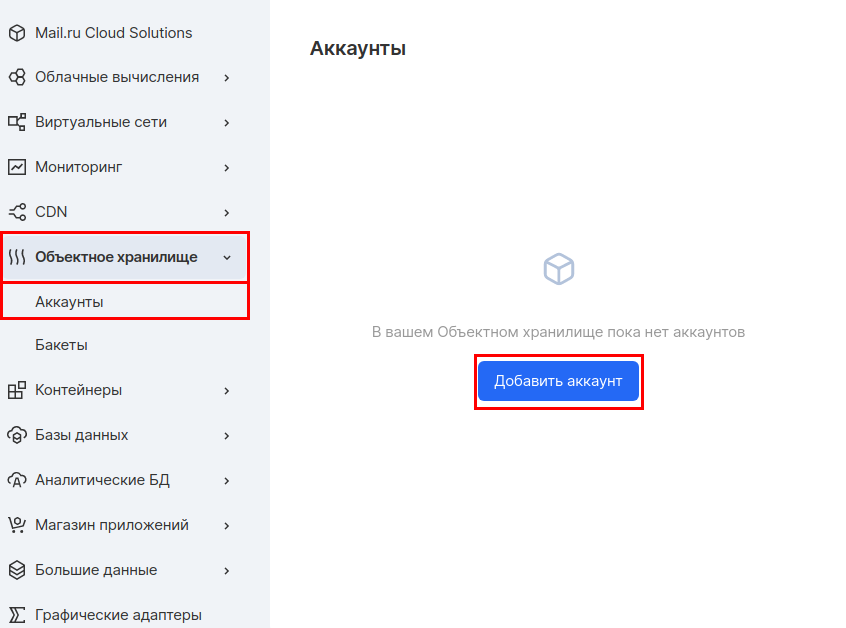
Мы будем использовать имя аккаунта — mlflow_webinar. После создания запишите Access Key ID и Secret Key. Особенно важен Secret Key, потому что его больше нельзя будет увидеть, и в случае потери придется пересоздавать.

Все, мы подготовили инфраструктуру для бэкенда.
Все сервисы находятся в одной виртуальной сети. Поэтому для взаимодействия между ними мы будем везде использовать внутренние адреса. Если вы хотите обращаться по внешним адресам, вам нужно правильно настроить Firewall.
Шаг 2: устанавливаем и настраиваем MLflow Tracking Server на выделенной VM
Подключаемся по SSH на виртуальную машину, которую мы создали в самом начале. Вот инструкция, как это сделать.
Сначала установим conda, это пакетный менеджер для Python, R и других языков.
curl -O https://repo.anaconda.com/archive/Anaconda3-2020.11-Linux-x86_64.sh
bash Anaconda3-2020.11-Linux-x86_64.sh
exec bashДалее создадим и активируем отдельное окружение для MLflow.
conda create -n mlflow_env
conda activate mlflow_envУстанавливаем необходимые библиотеки:
conda install python
pip install mlflow
pip install boto3
sudo apt install gcc
pip install psycopg2-binaryДалее нужно создать переменные окружения для доступа к S3. Открываем файл на редактирование:
sudo nano /etc/environmentИ задаем в нем переменные. Вместо REPLACE_WITH_INTERNAL_IP_MLFLOW_VM вам нужно подставить адрес вашей виртуальной машины:
MLFLOW_S3_ENDPOINT_URL=https://hb.bizmrg.com
MLFLOW_TRACKING_URI=http://REPLACE_WITH_INTERNAL_IP_MLFLOW_VM:8000MLflow взаимодействует с S3 при помощи библиотеки boto3, которая по умолчанию ищет credentials в папке ~/.aws. Поэтому нам нужно создать файл:
mkdir ~/.aws
nano ~/.aws/credentialsВ этот файл запишем credentials для доступа к S3, которые мы получили после создания бакета:
[default]
aws_access_key_id = REPLACE_WITH_YOUR_KEY
aws_secret_access_key = REPLACE_WITH_YOUR_SECRET_KEYВ завершение применяем настройки окружения:
conda activate mlflow_envТеперь можно запускать Tracking Server. Подставьте в команду свои параметры подключения к PostgreSQL и S3:
mlflow server --backend-store-uri postgresql://pg_user:pg_password@REPLACE_WITH_INTERNAL_IP_POSTGRESQL/db_name --default-artifact-root s3://REPLACE_WITH_YOUR_BUCKET/REPLACE_WITH_YOUR_DIRECTORY/ -h 0.0.0.0 -p 8000
MLflow запущен:

Теперь откроем графический интерфейс и проверим, что все работает как надо. Для этого нужно зайти на внешний IP-адрес виртуальной машины с MLflow Tracking Server, порт 8000. В нашем случае это будет 37.139.41.57:8000
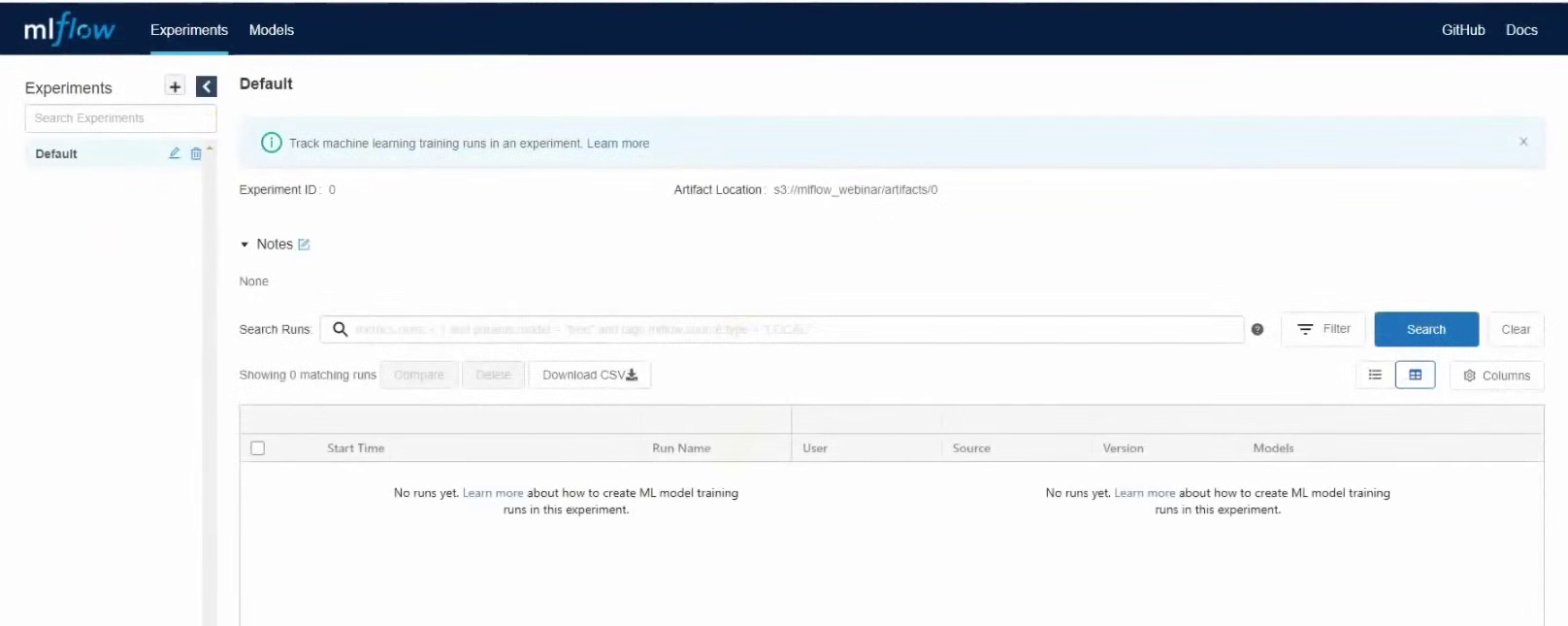
MLflow запущен
Но сейчас в нашей схеме есть небольшая проблема. Сервер работает до тех пор, пока запущен терминал. Если закрыть терминал, MLflow остановится. Также он не перезапустится автоматически, если мы перезагрузим сервер. Чтобы это исправить, мы будем запускать MLflow сервер в виде systemd-сервиса.
Итак, создадим две директории для хранения логов и ошибок:
mkdir ~/mlflow_logs/
mkdir ~/mlflow_errors/Затем создадим service-файл:
sudo nano /etc/systemd/system/mlflow-tracking.service
Далее добавляем в него код. Не забудьте подставить свои параметры подключения к БД и S3, как вы это делали при запуске сервера вручную:
[Unit]
Description=MLflow Tracking Server
After=network.target
[Service]
Environment=MLFLOW_S3_ENDPOINT_URL=https://hb.bizmrg.com
Restart=on-failure
RestartSec=30
StandardOutput=file:/home/ubuntu/mlflow_logs/stdout.log
StandardError=file:/home/ubuntu/mlflow_errors/stderr.log
User=ubuntu
ExecStart=/bin/bash -c 'PATH=/home/ubuntu/anaconda3/envs/mlflow_env/bin/:$PATH exec mlflow server --backend-store-uri postgresql://PG_USER:PG_PASSWORD@REPLACE_WITH_INTERNAL_IP_POSTGRESQL/DB_NAME --default-artifact-root s3://REPLACE_WITH_YOUR_BUCKET/REPLACE_WITH_YOUR_DIRECTORY/ -h 0.0.0.0 -p 8000'
[Install]
WantedBy=multi-user.targetТеперь запускаем сервис, активируем автозагрузку при старте системы и проверяем, что сервис работает:
sudo systemctl daemon-reload
sudo systemctl enable mlflow-tracking
sudo systemctl start mlflow-tracking
sudo systemctl status mlflow-trackingВидим, что сервис запустился:
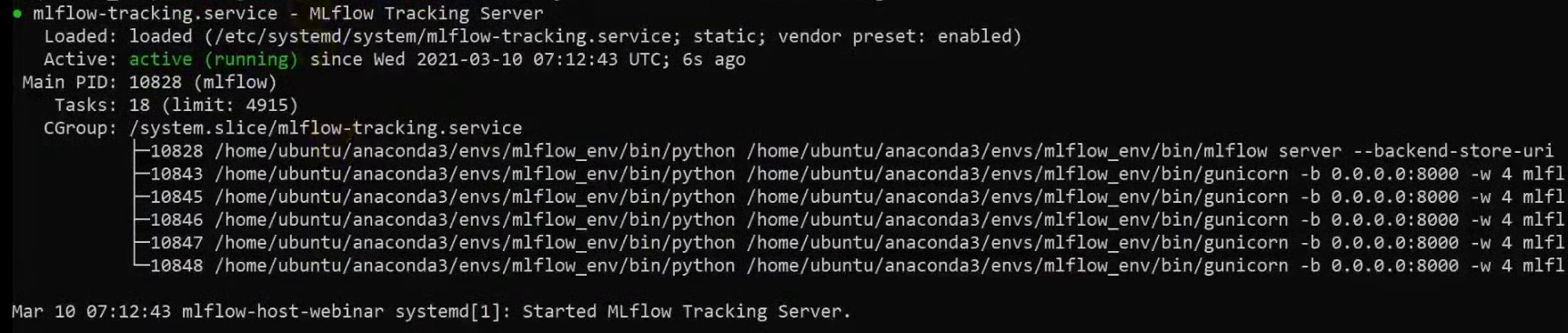
Кроме того, мы можем проверить логи, там тоже все хорошо:
head -n 95 ~/mlflow_logs/stdout.log

Снова открываем веб-интерфейс и видим, что MLflow сервер работает. Все, MLflow Tracking Server установлен и готов к работе.
Шаг 3: разворачиваем JupyterHub в облаке и настраиваем его для работы с MLflow
Мы будем разворачивать JupyterHub на отдельной виртуальной машине, чтобы потом этот хост можно было предоставить командам дата-инженеров или дата-саентистов. Так они смогут работать с JupyterHub, но не смогут повлиять на работу сервера MLflow. Мы воспользуемся нашим сервисом «Машинное обучение в облаке», который позволяет быстро получить готовое к работе окружение с установленным JupyterHub, conda и другими полезными инструментами.
В панели MCS заходим в раздел «Машинное обучение» и создаем среду для обучения.
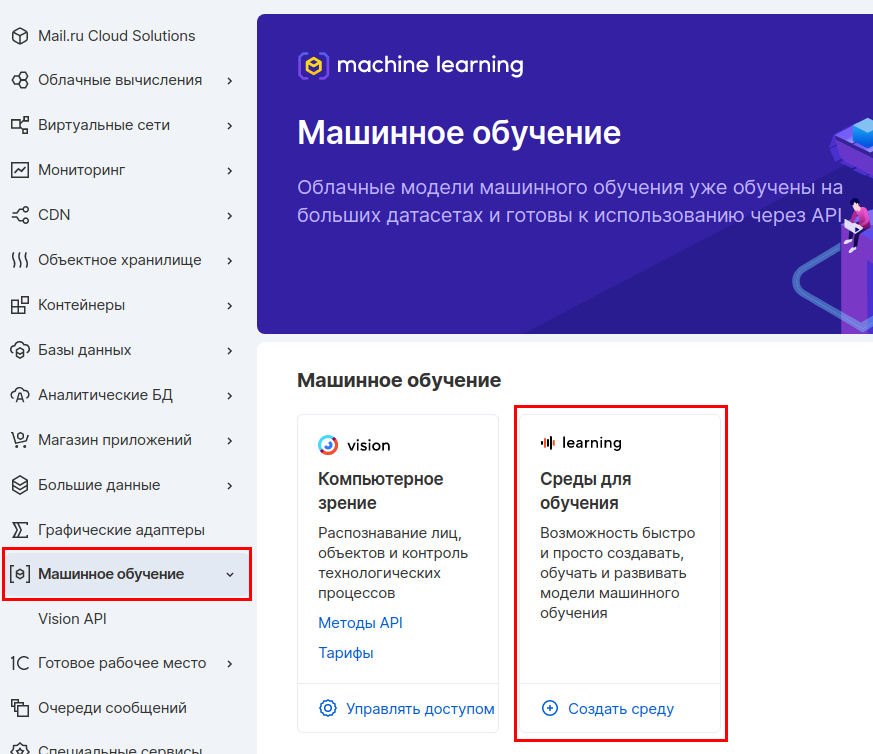
Выбираем параметры виртуальной машины. Мы возьмем 4 CPU и 8 ГБ RAM.
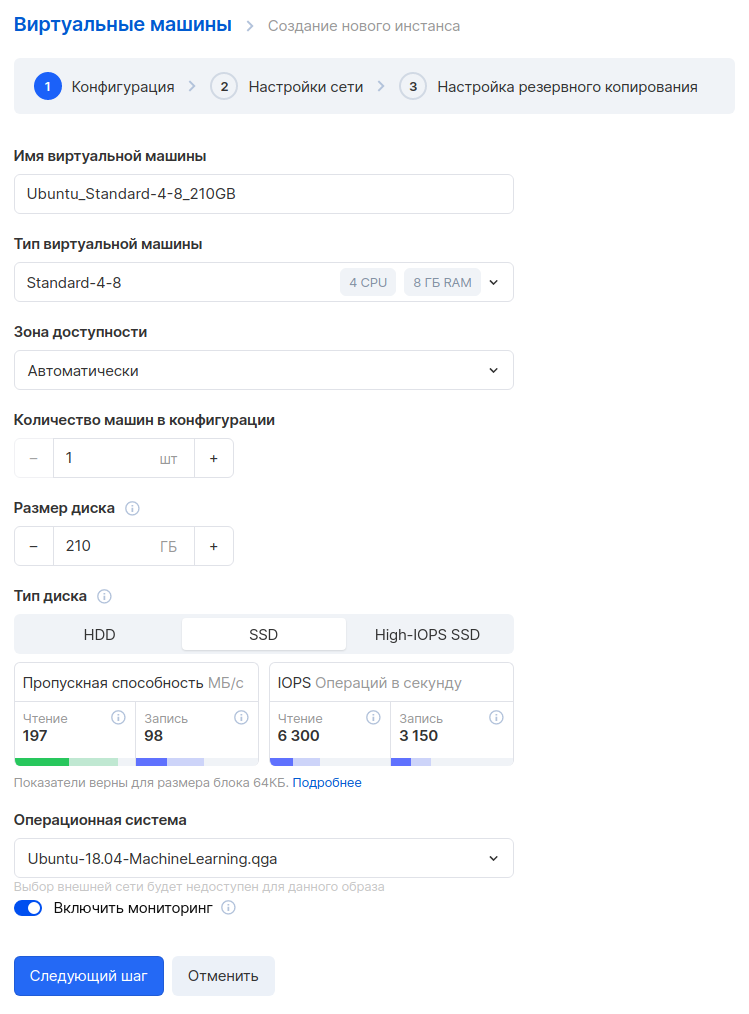
На следующем шаге настраиваем сеть. Проверьте, что сеть выбрана та же самая, чтобы эта машина могла общаться с остальными серверами по внутренней сети. Выберите опцию «Назначить внешний IP», чтобы позже мы смогли подключиться к этой машине из интернета.

На последнем шаге нужно настроить резервное копирование. Можете оставить опции по умолчанию.
После того, как виртуальная машина создастся, необходимо записать ее внешний IP-адрес: он нам пригодится позже.

Теперь подключаемся к этой машине по SSH и активируем установленный JupyterHub. Мы будем пользоваться утилитой tmux, чтобы можно было отключаться от экрана и запускать другие команды.
tmux
jupyter-notebook --ip '*'Использование tmux — не продуктовое решение. Сейчас мы так сделаем в рамках тестового проекта, а для продуктовых решений рекомендуем использовать systemd, как мы это делали для запуска MLflow Tracking Server.
После активации JupyterHub в консоли будет URL, по которому нужно зайти и залогиниться в JupyterHub. В эту строку необходимо подставить внешний IP-адрес виртуальной машины.

Переходим по этому адресу и видим интерфейс JupyterHub:
Теперь нам нужно оставить сервер работать, но при этом выполнять другие команды. Поэтому мы отключимся от этого инстанса терминала и оставим его работать в фоновом режиме. Для этого нужно нажать комбинацию клавиш ctrl + b d.
Непосредственная загрузка артефактов в artefact storage будет выполняться именно с этого хоста. Поэтому нам нужно настроить взаимодействие JupyterHub как с MLflow, так и с S3. Сначала зададим несколько переменных окружения. Откроем файл /etc/environment:
sudo nano /etc/environmentИ запишем в него адрес Tracking Server и Endpoint для S3:
MLFLOW_TRACKING_URI=http://REPLACE_WITH_INTERNAL_IP_MLFLOW_VM:8000
MLFLOW_S3_ENDPOINT_URL=https://hb.bizmrg.comТакже нам нужно снова создать credentials для доступа к S3. Создадим файл и директорию:
mkdir .aws
nano ~/.aws/credentialsЗапишем туда Access Key и Secret Key:
[default]
aws_access_key_id = REPLACE_WITH_YOUR_KEY
aws_secret_access_key = REPLACE_WITH_YOUR_SECRET_KEYТеперь установим MLflow, чтобы использовать его клиентскую часть. Для этого создадим отдельное окружение и отдельный kernel:
conda create -n mlflow_env
conda activate mlflow_env
conda install python
pip install mlflow
pip install matplotlib
pip install sklearn
pip install boto3
conda install -c anaconda ipykernel
python -m ipykernel install --user --name ex --display-name "Python (mlflow)"Шаг 4: логируем параметры и метрики экспериментов
Теперь будем непосредственно работать с кодом. Снова заходим в веб-интерфейс JupyterHub, запускаем терминал и клонируем репозиторий:
git clone https://github.com/stockblog/webinar_mlflow/ webinar_mlflow
Далее открываем файл mlflow_demo.ipynb и последовательно запускаем ячейки.
В ячейке №3 мы будем тестировать ручное логирование параметров и метрик. В ячейке явно указаны параметры, которые хотим залогировать. Запускаем ячейку и после того, как она отработает, переходим в интерфейс MLflow. Тут видим, что создался новый эксперимент — Manual_logging.

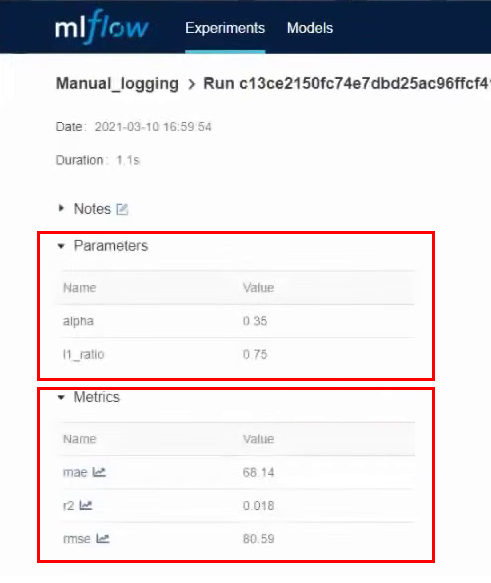
Заходим в детали этого эксперимента и видим параметры и метрики, которые мы указывали при логировании:
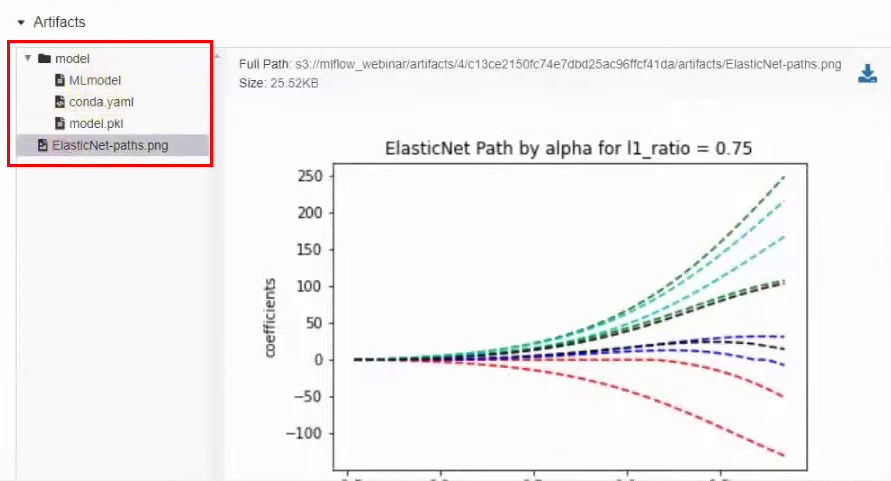
В этом же окне ниже находятся артефакты, которые связаны непосредственно с моделью, например, график:
Теперь попробуем логировать все параметры автоматически. В следующей ячейке мы используем ту же самую модель, но уже включаем автологирование. За это отвечает строка:
mlflow.sklearn.autolog(log_input_examples=True)
Нужно указать flavor, который будем использовать, в нашем случае это sklearn. Также в параметрах функции autolog мы указали log_input_examples=True. При этом будут автоматически логироваться примеры входных данных для модели: какие колонки, что они означают и как примерно выглядят входные данные. Эта информация будет находиться в артефактах. Это может пригодиться, когда команда работает над несколькими экспериментами одновременно. Потому что не всегда можно держать в уме каждую модель и все примеры данных для нее.
В этой ячейке мы убрали все строки, связанные с ручным логированием метрик и параметров. Но логирование артефактов остается в ручном режиме.
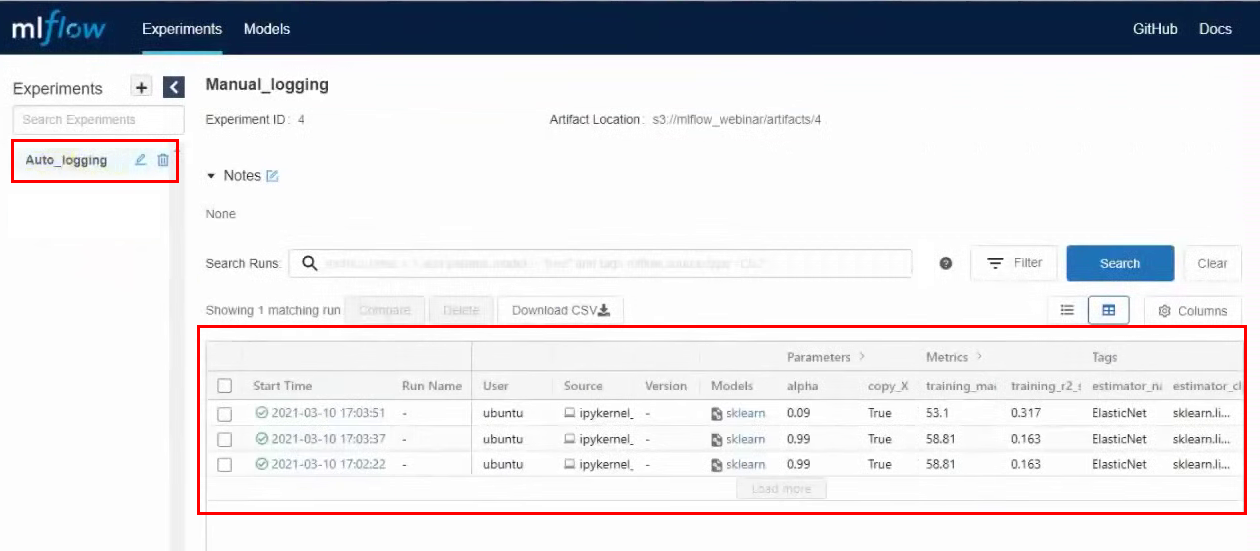
Запускаем ячейку, после ее выполнения создается новый эксперимент. Переходим в интерфейс MLflow, заходим в эксперимент Auto_logging и видим, что теперь появилось гораздо больше параметров и метрик, чем при ручном сборе:

Теперь, если мы будем менять в ячейке параметры и заново ее запускать, то в экспериментах в MLflow будут появляться строки с новыми запусками. Вот, например, мы сделали три запуска с разными параметрами:
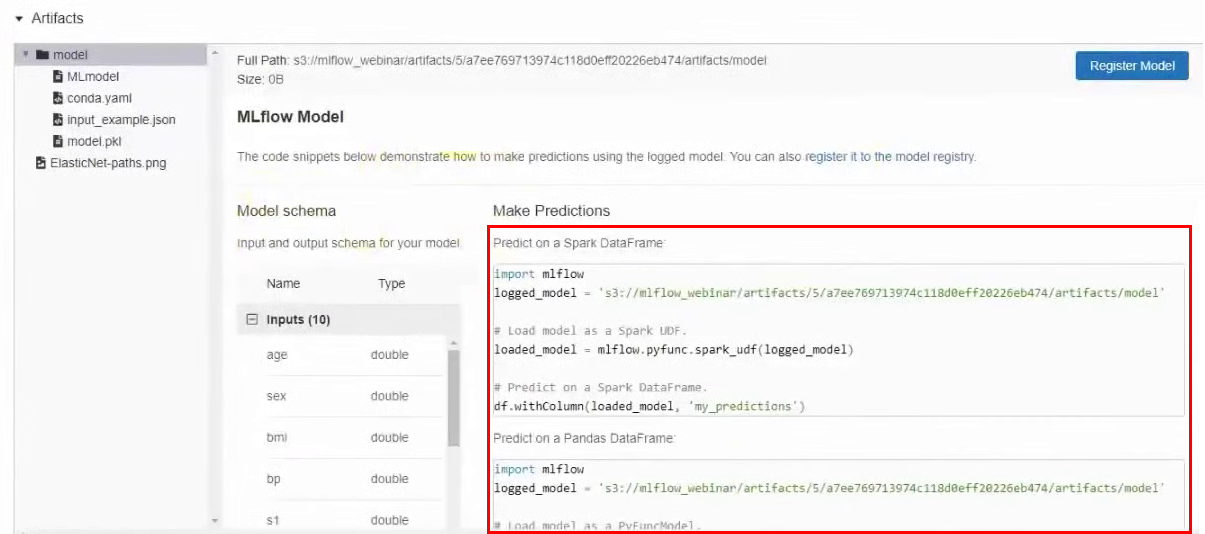
Также в артефактах можно найти пример, как использовать данную конкретную модель. Там есть путь модели в S3 и примеры для разных фреймворков.
Шаг 5: тестируем способы публикации ML-моделей
Итак, мы провели эксперименты, а теперь будем публиковать модель. Мы рассмотрим два способа, как это сделать.
Способ публикации №1: обратиться к S3-хранилищу напрямую. Копируем адрес модели в S3-хранилище и публикуем ее при помощи mlflow serve:
mlflow models serve -m s3://BUCKET/FOLDER/EXPERIMENT_NUMBER/INTERNAL_MLFLOW_ID/artifacts/model -h 0.0.0.0 -p 8001В этой команде мы указываем хост и порт, на котором модель будет доступна. Мы используем адрес 0.0.0.0, это означает текущий хост. В терминале нет ошибок — значит, модель опубликовалась:

Теперь протестируем ее. В новом окне терминала подключаемся по SSH на этот же сервер и пробуем достучаться до модели при помощи curl. Если вы используете этот же датасет, то можете полностью скопировать команду без изменений:
curl -X POST -H "Content-Type:application/json; format=pandas-split" --data '{"columns":["age", "sex", "bmi", "bp", "s1", "s2", "s3", "s4", "s5", "s6"], "data":[[0.0453409833354632, 0.0506801187398187, 0.0606183944448076, 0.0310533436263482, 0.0287020030602135, 0.0473467013092799, 0.0544457590642881, 0.0712099797536354, 0.133598980013008, 0.135611830689079]]}' http://0.0.0.0:8001/invocationsПосле выполнения команды видим результат:

Также к модели можно обратиться из интерфейса JupyterHub. Для этого запустите соответствующую ячейку, но перед этим поменяйте IP-адрес на свой.
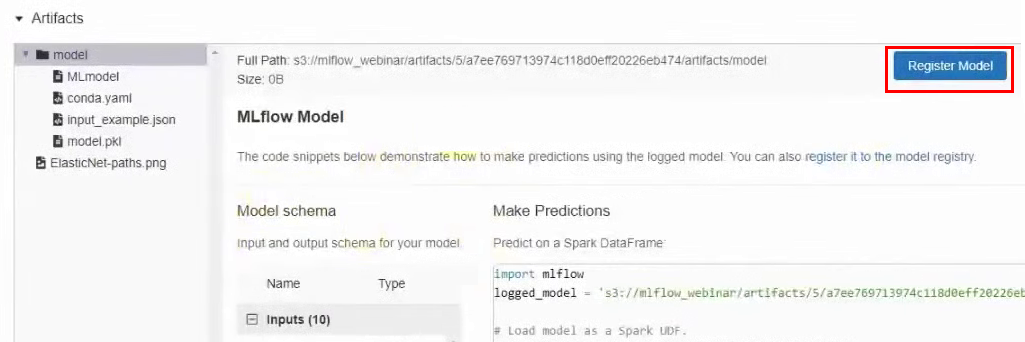
Способ публикации №2: зарегистрировать модель в MLflow. Также мы можем зарегистрировать модель в MLflow, и тогда она будет доступна через UI-интерфейс. Для этого снова переходим в результаты эксперимента, в разделе Artifacts нажимаем кнопку Register Model и в появившемся окне задаем ей имя.
Теперь в верхнем меню перейдем на вкладку Models. И видим, что в списке моделей у нас появилась новая модель:
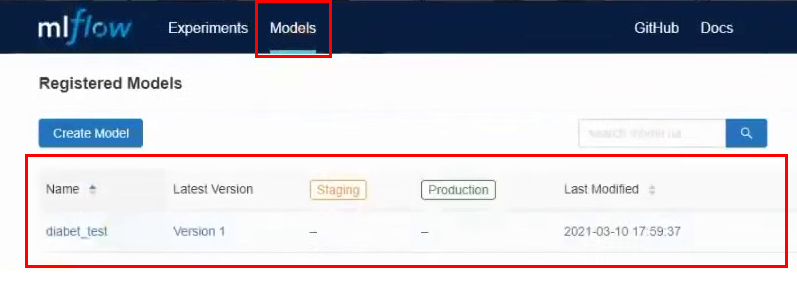
Зайдем в нее. В этом интерфейсе можно перевести модель на разные stage, посмотреть входные параметры и результаты. Также можно дать описание модели, которое будет полезно, если над ней работают несколько человек. Мы переведем нашу модель в Staging.
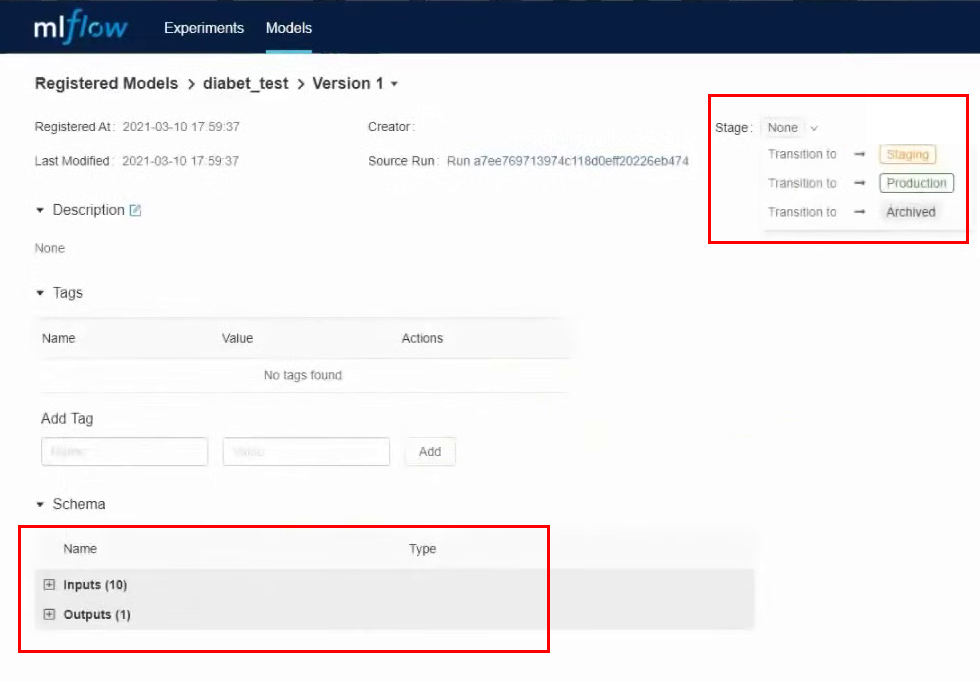
Практически все действия мы делаем через интерфейс, но точно также можно работать через API и CLI. Все эти действия можно автоматизировать: регистрацию моделей, перевод на другой stage, выкатку моделей и все остальное.
Теперь для публикации модели мы также воспользуемся командой serve, но вместо длинного пути в S3 укажем просто название модели:
mlflow models serve -m "models:/YOUR_MODEL_NAME/STAGE"
Обратите внимание, что в этот раз мы не указывали порт и модель по умолчанию опубликовалась на порту 5000:

Теперь при помощи curl пробуем достучаться до модели еще раз:
curl -X POST -H "Content-Type:application/json; format=pandas-split" --data '{"columns":["age", "sex", "bmi", "bp", "s1", "s2", "s3", "s4", "s5", "s6"], "data":[[0.0453409833354632, 0.0506801187398187, 0.0606183944448076, 0.0310533436263482, 0.0287020030602135, 0.0473467013092799, 0.0544457590642881, 0.0712099797536354, 0.133598980013008, 0.135611830689079]]}' http://0.0.0.0:5000/invocationsРезультат тот же:
Но если попробовать обратиться к модели с другого сервера, то у нас ничего не получится. Потому что сейчас модель доступна только в рамках того хоста, где она опубликована. Чтобы это исправить, опубликуем модель с параметром -h:
mlflow models serve -m "models:/YOUR_MODEL_NAME/STAGE" -h 0.0.0.0
Проверим доступ к модели с помощью той же самой ячейки в JupyterHub, но изменим порт на 5000. Модель возвращает результат. Он немного отличается от результата выше, потому что в ходе вебинара мы меняли некоторые параметры.

Также к модели можно обращаться с помощью Python. Пример можно найти в другой ячейке.
Но в обоих вариантах публикации модели есть особенность. Модель доступна до тех пор, пока запущен терминал с командой serve. Когда мы закроем терминал или перезапустим сервер, доступ к модели пропадет. Чтобы этого избежать, мы будем публиковать модель при помощи сервиса systemd, как мы это делали для запуска MLflow Tracking Server.
Создадим новый service-файл:
sudo nano /etc/systemd/system/mlflow-model.service
И вставим в него эти команды, предварительно заменив переменные на свои.
[Unit]
Description=MLFlow Model Serving
After=network.target
[Service]
Restart=on-failure
RestartSec=30
StandardOutput=file:/home/ubuntu/mlflow_logs/stdout.log
StandardError=file:/home/ubuntu/mlflow_errors/stderr.log
Environment=MLFLOW_TRACKING_URI=http://REPLACE_WITH_INTERNAL_IP_MLFLOW_VM:8000
Environment=MLFLOW_CONDA_HOME=/home/ubuntu/anaconda3/
Environment=MLFLOW_S3_ENDPOINT_URL=https://hb.bizmrg.com
ExecStart=/bin/bash -c 'PATH=/home/ubuntu/anaconda3/envs/REPLACE_WITH_MLFLOW_ENV_OF_MODEL/bin/:$PATH exec mlflow models serve -m "models:/YOUR_MODEL_NAME/STAGE" -h 0.0.0.0 -p 8001'
[Install]
WantedBy=multi-user.targetТут есть одна новая переменная, которую мы раньше не использовали: REPLACE_WITH_MLFLOW_ENV_OF_MODEL. Это индивидуальное окружение MLflow, которое автоматически создается для каждой модели. Чтобы узнать, в каком окружении запускается ваша модель, посмотрите результат команды serve, когда вы запускали модель. Там есть этот идентификатор:

Теперь запустим и активируем этот сервис, чтобы модель публиковалась при каждом запуске хоста:
sudo systemctl daemon-reload
sudo systemctl enable mlflow-model
sudo systemctl start mlflow-modelПроверяем статус:
sudo systemctl status mlflow-model
Видим, что при запуске появилась ошибка:

На ее примере разберем, как можно находить и устранять ошибки. Чтобы понять, что вообще произошло, проверим логи. Они лежат в папке, которую мы создавали специально для логов.
head -n 95 ~/mlflow_logs/stdout.log
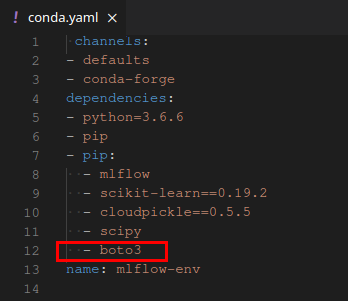
В нашем примере в самом конце лога видно, что MLflow не может найти библиотеку boto3, которая необходима для доступа к S3:

Есть два варианта варианта, как решить проблему:
- Установить библиотеку руками в окружение MLflow. Но это костыльный способ, мы не будем его рассматривать.
- Прописать библиотеку в зависимостях в yaml-файле. Этот способ мы и рассмотрим.
Нужно найти папку в бакете, в которой хранится эта модель. Для этого возвращаемся в интерфейс MLflow и в результатах эксперимента переходим в раздел с артефактами. Запоминаем путь:
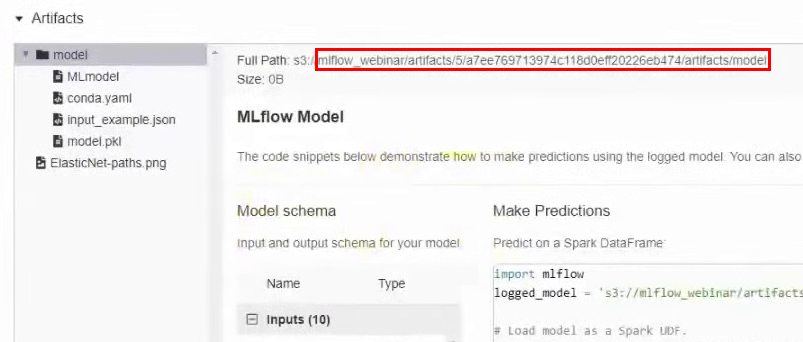
В интерфейсе MCS переходим в бакет по этому пути и скачиваем файл conda.yaml.
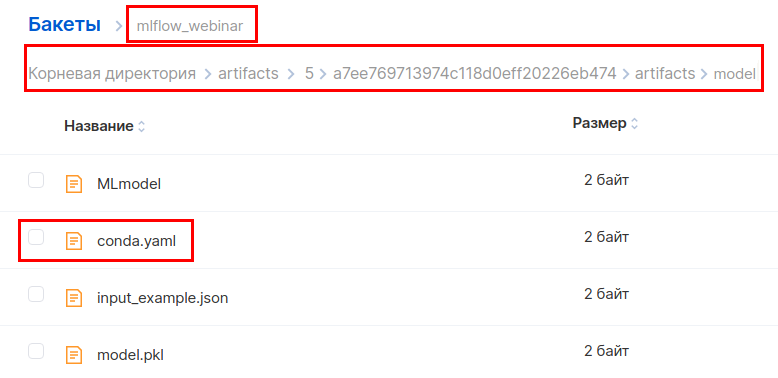
В раздел с зависимостями добавляем библиотеку boto3 и заливаем файл обратно.
Снова попробуем запустить systemd-сервис:
sudo systemctl start mlflow-model
Теперь все хорошо, модель запустилась. Можно снова попробовать достучаться до нее разными способами, как мы делали это раньше. Обратите внимание, что в качестве порта следует снова указывать 8001.
Теперь соберем докер-образ с этой моделью, чтобы ее можно было легко перенести в другое окружение. Для этого на хосте должен быть установлен докер. Мы не будем рассматривать процесс его установки, а просто дадим ссылку на официальную инструкцию.
Выполним команду:
mlflow models build-docker -m "models:/YOUR_MODEL_NAME/STAGE" -n "DOCKER_IMAGE_NAME"
В параметре -n мы указываем желаемое имя для докер-образа. Результат:

Протестируем. Запускаем контейнер, теперь модель будет доступна на порту 5001:
docker run -p 5001:8080 YOUR_MODEL_NAME
Теперь модель должна быть сразу доступна и активна. Проверим:
curl -X POST -H "Content-Type:application/json; format=pandas-split" --data '{"columns":["age", "sex", "bmi", "bp", "s1", "s2", "s3", "s4", "s5", "s6"], "data":[[0.0453409833354632, 0.0506801187398187, 0.0606183944448076, 0.0310533436263482, 0.0287020030602135, 0.0473467013092799, 0.0544457590642881, 0.0712099797536354, 0.133598980013008, 0.135611830689079]]}' http://127.0.0.1:5001/invocationsТакже можно проверить доступность из JupyterHub. При этом в терминале, где мы запускали докер-образ, видим, что запросы приходят с двух разных хостов, локального и JupyterHub:

Все, докер-образ собран, протестирован и готов к работе.
Чему мы научились
Итак, мы познакомились с MLflow и научились разворачивать его в облаке. Большинство инструкций в сети ограничиваются установкой MLflow на локальной машине. Это хорошо подходит для ознакомления и быстрых экспериментов, но точно не продакшен-вариант.
Все это возможно благодаря тому, что облачные платформы предоставляют множество готовых сервисов, которые помогают упростить и ускорить развертывание.
Если захотите сами пройти то, что описано в этой статье, подключитесь к платформе Mail.ru Cloud Solutions, новые пользователи получают там 3000 бесплатных ₽. Этого более чем достаточно, чтобы развернуть MLflow по этой статье.



