
2 - Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Во втором разделе туториола о моделях sequence-to-sequence с использованием PyTorch и TorchText мы будем реализовывать модель из работы Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. Эта нейронная сеть позволит достичь лучшей точности при использовании только однослойной RNN как в кодере, так и в декодере.
Как и ранее, если визуальный формат поста вас не удовлетворяет, то ниже ссылки на английскую и русскую версию jupyter notebook:
Исходная версия (Open jupyter notebook In Colab)
Русская версия (Open jupyter notebook In Colab)
Введение
Напомним общую модель кодера-декодера.
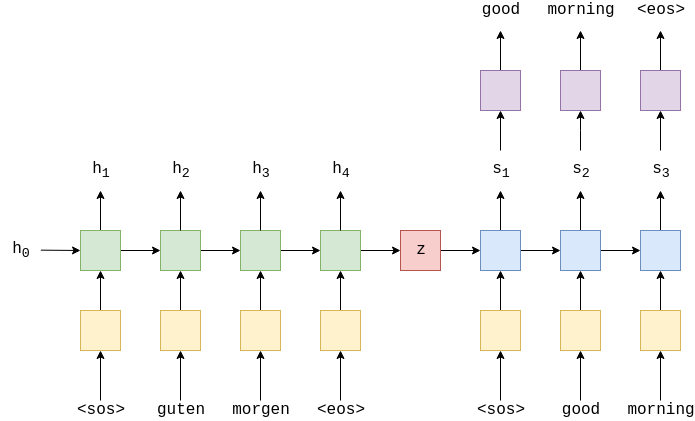
Мы используем наш кодировщик (зеленый) поверх исходной последовательности, прошедшей слой эмбеддинга (желтый), чтобы создать вектор контекста (красный). Затем мы передаём этот вектор контекста в декодер (синий) с линейным слоем (фиолетовый) для генерации целевого предложения.
В предыдущей модели мы использовали многослойную LSTM сеть в качестве кодера и декодера.

Одним из недостатков модели в прошлой части является то, что декодер пытается втиснуть большое количество информации в скрытые состояния. Во время декодирования скрытое состояние должно содержать информацию обо всей исходной последовательности, а также обо всех токенах, которые были декодированы на данный момент. Улучшив сжатие этой информации, мы сможем создать улучшенную модель!
Мы будем использовать сеть GRU (Gated Recurrent Unit) вместо LSTM (Long Short-Term Memory). Почему? В основном потому, что так авторы сделали в статье (в этой же статье была представлена GRU сеть), а также потому, что в прошлый раз мы использовали LSTM. Отличия GRU (и LSTM) от стандартных RNN подробно рассмотрены здесь. Резонный вопрос, GRU лучше LSTM? Исследование показало, что они почти одинаковы и одновременно, чем стандартные RNN.
Подготовка данных
Вся подготовка данных будет почти такой же, как и в прошлый раз, поэтому мы очень кратко опишем, что делает каждый блок кода. Более развётнутое описание смотрите в предыдущей части.
Мы импортируем PyTorch, TorchText, spaCy и несколько стандартных модулей.
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.legacy.datasets import Multi30k
from torchtext.legacy.data import Field, BucketIterator
import spacy
import numpy as np
import random
import math
import timeЗатем установите случайное начальное число для детерминированной воспроизводимости результатов.
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = TrueДля Google Colab используем следующие команды (После загрузки не забывайте перезапустите colab runtime! Наибыстрейший способ через короткую комаду: Ctrl + M + .):
!pip install -U spacy==3.0
!python -m spacy download en_core_web_sm
!python -m spacy download de_core_news_smСоздаём экземпляры наших немецких и английских spaCy моделей.
spacy_de = spacy.load('de_core_news_sm')
spacy_en = spacy.load('en_core_web_sm')Ранее мы поменяли местами исходное (немецкое) предложение, однако в статье, которую мы реализуем, они этого не делают, и мы не будем.
def tokenize_de(text):
"""
Tokenizes German text from a string into a list of strings
"""
return [tok.text for tok in spacy_de.tokenizer(text)]
def tokenize_en(text):
"""
Tokenizes English text from a string into a list of strings
"""
return [tok.text for tok in spacy_en.tokenizer(text)]Далее мы создаем токенизирующие функции. Они могут быть переданы в torchtext и будут принимать предложение в виде строки, а возвращать предложение в виде списка токенов.
SRC = Field(tokenize=tokenize_de,
init_token='<sos>',
eos_token='<eos>',
lower=True)
TRG = Field(tokenize = tokenize_en,
init_token='<sos>',
eos_token='<eos>',
lower=True)Загрузка наших данных.
train_data, valid_data, test_data = Multi30k.splits(exts = ('.de', '.en'),
fields = (SRC, TRG))Мы распечатаем пример, чтобы проверить, не перевернут ли он.
print(vars(train_data.examples[0]))Затем создаём наш словарь, преобразовав все токены, встречающиеся менее двух раз, в <unk> токены.
SRC.build_vocab(train_data, min_freq = 2)
TRG.build_vocab(train_data, min_freq = 2)Наконец, определим device и создаём наши итераторы.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')BATCH_SIZE = 128
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)Создание Seq2Seq модели
Кодер
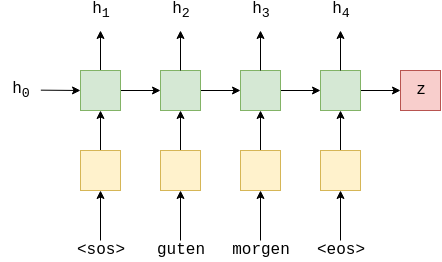
Кодер аналогичен предыдущему, но многослойный LSTM заменен на однослойный GRU. Кроме того, мы не передаем дропаут в качестве аргумента GRU, поскольку этот дропаут используется между слоями многослойной RNN. Поскольку у нас есть только один слой, PyTorch отобразит предупреждение, если мы попытаемся передать ему значение дропаута.
Еще одна вещь, которую следует отметить в отношении GRU, заключается в том, что он требует и возвращает только скрытое состояние, не нуждаясь в состоянии ячейки, как в LSTM.

Из приведенных выше уравнений видно, что RNN и GRU идентичны. Однако внутри GRU есть несколько запорных механизмовs, которые контролируют поток информации в скрытое состояние и из него (похожий на LSTM). Опять же, для получения дополнительной информации обращайтесь сюда.

Он идентичен кодировщику общей модели seq2seq, со всей "магией", происходящей внутри GRU (зеленый).
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, dropout):
super().__init__()
self.hid_dim = hid_dim
self.embedding = nn.Embedding(input_dim, emb_dim) #no dropout as only one layer!
self.rnn = nn.GRU(emb_dim, hid_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
#src = [src len, batch size]
embedded = self.dropout(self.embedding(src))
#embedded = [src len, batch size, emb dim]
outputs, hidden = self.rnn(embedded) #no cell state!
#outputs = [src len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#outputs are always from the top hidden layer
return hiddenДекодер
Реализация данного декодер значительно отличается от декодера предыдущей модели, и в текущем декодере мы усилили сжатие некоторой информации.
GRU в декодере принимает не только целевой токен из эмбеддинга  и предыдущее скрытое состояние
и предыдущее скрытое состояние  в качестве входных данных, но также и вектор контекста
в качестве входных данных, но также и вектор контекста  .
.

Обратите внимание, как этот вектор контекста  не имеет индекса
не имеет индекса  , это означает, что мы повторно используем один и тот же вектор контекста, возвращаемый кодировщиком, для каждого временного шага в декодере.
, это означает, что мы повторно используем один и тот же вектор контекста, возвращаемый кодировщиком, для каждого временного шага в декодере.
Раньше мы предсказывали следующий токен  с линейным слоем
с линейным слоем  , используя только выход декодер верхнего уровня, скрытый на этом временном шаге
, используя только выход декодер верхнего уровня, скрытый на этом временном шаге  как
как  . Теперь мы также передаем текущий токен эмбеддинга
. Теперь мы также передаем текущий токен эмбеддинга  и вектор контекста
и вектор контекста  в линейный слой.
в линейный слой.

Таким образом, наш декодер теперь выглядит примерно так:

Обратите внимание, начальное скрытое состояние  по-прежнему является вектором контекста
по-прежнему является вектором контекста  , поэтому при генерации первого токена мы фактически вводим два идентичных вектора контекста в GRU.
, поэтому при генерации первого токена мы фактически вводим два идентичных вектора контекста в GRU.
Как эти два изменения уменьшают сжатие информации? Гипотетически скрытым состояниям декодер  больше нет необходимости содержать информацию об исходной последовательности, поскольку она всегда доступна в качестве входных данных. Таким образом, они должены содержать только информацию о том, какие токены они уже сгенерировали. Передача
больше нет необходимости содержать информацию об исходной последовательности, поскольку она всегда доступна в качестве входных данных. Таким образом, они должены содержать только информацию о том, какие токены они уже сгенерировали. Передача  в линейный уровень (через эмбеддинг
в линейный уровень (через эмбеддинг  ) означает, что этот уровень может напрямую видеть входной токен, без необходимости получать информацию о нём из скрытого состояния.
) означает, что этот уровень может напрямую видеть входной токен, без необходимости получать информацию о нём из скрытого состояния.
Однако эта гипотеза — всего лишь гипотеза, невозможно определить, как модель на самом деле использует предоставленную ей информацию (не слушайте никого, кто говорит иначе). Тем не менее это хорошая догадка, и результаты, кажется, указывают на то, что эта модификации является хорошей идеей!
В рамках реализации мы передадим  и
и  в GRU объединив их вместе, так что входные размеры в GRU были
в GRU объединив их вместе, так что входные размеры в GRU были emb_dim + hid_dim (поскольку вектор контекста будет иметь размер hid_dim). Линейный слой принимает  ,
,  и
и  объединения их вместе, поэтому входные размеры теперь
объединения их вместе, поэтому входные размеры теперь emb_dim + hid_dim*2. Мы также не передаем значение дропаута в GRU, поскольку оно используется только на входном уровене.
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, dropout):
super().__init__()
self.hid_dim = hid_dim
self.output_dim = output_dim
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.GRU(emb_dim + hid_dim, hid_dim)
self.fc_out = nn.Linear(emb_dim + hid_dim * 2, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, context):
#input = [batch size]
#hidden = [n layers * n directions, batch size, hid dim]
#context = [n layers * n directions, batch size, hid dim]
#n layers and n directions in the decoder will both always be 1, therefore:
#hidden = [1, batch size, hid dim]
#context = [1, batch size, hid dim]
input = input.unsqueeze(0)
#input = [1, batch size]
embedded = self.dropout(self.embedding(input))
#embedded = [1, batch size, emb dim]
emb_con = torch.cat((embedded, context), dim = 2)
#emb_con = [1, batch size, emb dim + hid dim]
output, hidden = self.rnn(emb_con, hidden)
#output = [seq len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#seq len, n layers and n directions will always be 1 in the decoder, therefore:
#output = [1, batch size, hid dim]
#hidden = [1, batch size, hid dim]
output = torch.cat((embedded.squeeze(0), hidden.squeeze(0), context.squeeze(0)),
dim = 1)
#output = [batch size, emb dim + hid dim * 2]
prediction = self.fc_out(output)
#prediction = [batch size, output dim]
return prediction, hiddenSeq2Seq модель
Соединяя кодировщик и декодер, получаем:

Снова, в этой реализации нам нужно обеспечить одинаковые скрытые размеры в кодировщике и декодере.
Кратко пройдемся по всем этапам:
тензор
outputsсоздан для хранения всех прогнозов
исходная последовательность
 подается в кодировщик для получения вектора контекста
подается в кодировщик для получения вектора контекста contextначальное скрытое состояние декодера установлено как вектор
context
мы используем
<sos>в качестве входных токеновinput
затем декодируем в цикле:
передача входного токена
 , предыдущего скрытого состояния
, предыдущего скрытого состояния  , и вектора контекста
, и вектора контекста  в декодер
в декодерполучение прогноза
 и нового скрытого состояния
и нового скрытого состояния 
Затем мы решаем, собираемся ли мы использовать обучение с принуждением или нет, устанавливая следующий вход соответствующим образом (либо следующий истинный токен в целевой последовательности, либо самый вероятный следующий токен)
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
assert encoder.hid_dim == decoder.hid_dim, \
"Hidden dimensions of encoder and decoder must be equal!"
def forward(self, src, trg, teacher_forcing_ratio = 0.5):
#src = [src len, batch size]
#trg = [trg len, batch size]
#teacher_forcing_ratio is probability to use teacher forcing
#e.g. if teacher_forcing_ratio is 0.75 we use ground-truth inputs 75% of the time
batch_size = trg.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
#tensor to store decoder outputs
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
#last hidden state of the encoder is the context
context = self.encoder(src)
#context also used as the initial hidden state of the decoder
hidden = context
#first input to the decoder is the <sos> tokens
input = trg[0,:]
for t in range(1, trg_len):
#insert input token embedding, previous hidden state and the context state
#receive output tensor (predictions) and new hidden state
output, hidden = self.decoder(input, hidden, context)
#place predictions in a tensor holding predictions for each token
outputs[t] = output
#decide if we are going to use teacher forcing or not
teacher_force = random.random() < teacher_forcing_ratio
#get the highest predicted token from our predictions
top1 = output.argmax(1)
#if teacher forcing, use actual next token as next input
#if not, use predicted token
input = trg[t] if teacher_force else top1
return outputs
Обучение модели Seq2Seq
Остальная часть этого раздела очень похожа на аналогичную часть из предыдущей части.
Мы инициализируем наш кодер, декодер и модель seq2seq (поместив его на графический процессор, если он у нас есть). Как и раньше, размеры эмбеддинга и величина дропаута могут быть разными для кодера и декодера, но скрытые размеры должны оставаться такими же.
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
ENC_EMB_DIM = 256
DEC_EMB_DIM = 256
HID_DIM = 512
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, DEC_DROPOUT)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Seq2Seq(enc, dec, device).to(device)Затем мы инициализируем наши параметры. В исходной статье говорится, что параметры инициализируются из нормального распределения со средним значением 0 и стандартным отклонением0 .01, т.е.  .
.
В ней также говорится, что мы должны инициализировать повторяющиеся параметры специальным образом, однако для простоты мы инициализируем их в виде  .
.
def init_weights(m):
for name, param in m.named_parameters():
nn.init.normal_(param.data, mean=0, std=0.01)
model.apply(init_weights)Распечатываем количество параметров.
Несмотря на то, что у нас есть только однослойная RNN для нашего кодера и декодера, на самом деле у нас есть больше параметры, чем в предыдущей модели. Это связано с увеличенным размером входов в GRU и линейный слой. Однако это незначительное увеличение параметров не приводит увеличению времени обучения (~3 секунд на дополнительную эпоху).
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')Мы инициализируем наш оптимизатор.
optimizer = optim.Adam(model.parameters())Мы также инициализируем функцию потерь, игнорируя потерю на токенах <pad>.
TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]
criterion = nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX)Затем мы создаем цикл обучения ...
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output = model(src, trg)
#trg = [trg len, batch size]
#output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
#trg = [(trg len - 1) * batch size]
#output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)...и цикл оценки, не забывая установить модель в режим eval и выключить обучение с принуждением.
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output = model(src, trg, 0) #turn off teacher forcing
#trg = [trg len, batch size]
#output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
#trg = [(trg len - 1) * batch size]
#output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)Мы также определим функцию, которая вычисляет, сколько времени занимает эпоха.
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secsЗатем мы обучаем нашу модель, сохраняя параметры, которые дают нам наименьшие потери при проверке.
N_EPOCHS = 10
CLIP = 1
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut2-model.pt')
print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')Наконец, мы тестируем модель на тестовой выборке, используя эти «лучшие» параметры.
model.load_state_dict(torch.load('tut2-model.pt'))
test_loss = evaluate(model, test_iterator, criterion)
print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')Если посмотреть на выигрыш в тесте, то видно улучшение производительность по сравнению с предыдущей моделью. Это довольно хороший признак того, что эта архитектура модели что-то делает лучше! Ослабление сжатия информации кажется неплохим подходом, и в следующем разделе мы пойдём по этому пути еще дальше с помощью внимания.

