
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Введение
Развертывание Apache Spark в Kubernetes, вместо использования управляемых сервисов таких как AWS EMR, Azure Databricks или HDInsight, может быть обусловлено экономической эффективностью и переносимостью. Подробнее о миграции с AWS EMR в K8s вы можете прочитать в этой статье.
Однако при уходе с управляемых сервисов возникает ряд проблем. И, вероятно, самая большая из них — потеря мониторинга и алертинга. Например, в AWS EMR есть действительно мощные встроенные инструменты мониторинга в виде CloudWatch, Ganglia, CloudTrail и YARN history server. В этой статье рассмотрим реализацию мониторинга для Apache Spark в Kubernetes с помощью Prometheus и Grafana.
Задача
Обеспечение работоспособности Apache Spark в production при обработке больших объемов данных— действительно сложная задача. Много чего может пойти не так: может упасть executor, увеличиться задержка внешних источников данных, ухудшится производительность из-за изменения входных данных или кода и др. Для решения всех этих проблем необходимо проактивно в реальном времени отслеживать необходимые метрики. Некоторые из этих метрик включают в себя:
Использование ресурсов: количество ядер, процессорное время, используемая память, максимальный объем выделенной памяти, используемое место на диске.
Spark task: количество активных / упавших / завершенных задач, максимальная / средняя / минимальная длительность задач.
Spark shuffling: объем чтения / записи shuffle-операций.
Spark scheduler: количество активных / упавших / завершенных заданий.
Spark streaming: количество приемников (receiver), количество запущенных / упавших / завершенных пакетов, количество полученных / обработанных записей, среднее время обработки записи.
Пользовательские метрики: за специфичными метриками приложения необходимо также следить наряду с системными.
Решение
Prometheus — один из самых популярных инструментов мониторинга Kubernetes. Децентрализованный, с открытым исходным кодом, с большим комьюнити и член Cloud Native Computing Foundation. Prometheus хранит данные в виде временных рядов (time series). Для запросов используется PromQL, а для визуализации Grafana или встроенный браузер.
Шаг 1. Настройка sink
Для мониторинга Spark 2.x можно было использовать комбинацию встроенных JmxSink и JmxExporter, но в Spark 3.0 появился новый sink — PrometheusServlet. Преимущества PrometheusServlet по сравнению с JmxSink и JmxExporter очевидны: устраняется зависимость от внешнего JAR, для мониторинга используется тот же сетевой порт, на котором уже находится Spark, можно использовать Prometheus Service Discovery в Kubernetes.
Для того, чтобы включить новый sink, добавьте в проект файл metrics.properties (если его еще нет).

Добавьте в metrics.properties следующую конфигурацию:
# Example configuration for PrometheusServlet
# Master metrics - http://localhost:8080/metrics/master/prometheus/
# Worker metrics - http://localhost:8081/metrics/prometheus/
# Driver metrics - http://localhost:4040/metrics/prometheus/
# Executors metrics - http://localhost:4040/metrics/executors/prometheus
*.sink.prometheusServlet.class=org.apache.spark.metrics.sink.PrometheusServlet
*.sink.prometheusServlet.path=/metrics/prometheus
master.sink.prometheusServlet.path=/metrics/master/prometheus
applications.sink.prometheusServlet.path=/metrics/applications/prometheusШаг 2: Развертывание приложения
Spark-приложение развертывается в K8s через Docker-образ. Ниже приведен пример Dockerfile с многоэтапной сборкой (multi-stage). Первый этап — компиляция и сборка Spark-приложения на scala с помощью SBT, второй — базовый образ Spark, а последний — сборка окончательного образа. На последнем этапе копируем metrics.properties в папку /opt/spark/conf/.
FROM openjdk:8 AS build
# Env variables
ENV SCALA_VERSION 2.12.12
ENV SBT_VERSION 1.2.8
# Install Scala
## Piping curl directly in tar
RUN \
curl -fsL https://downloads.typesafe.com/scala/$SCALA_VERSION/scala-$SCALA_VERSION.tgz | tar xfz - -C /root/ && \
echo >> /root/.bashrc && \
echo "export PATH=~/scala-$SCALA_VERSION/bin:$PATH" >> /root/.bashrc
# Install sbt
RUN \
curl -L -o sbt-$SBT_VERSION.deb https://dl.bintray.com/sbt/debian/sbt-$SBT_VERSION.deb && \
dpkg -i sbt-$SBT_VERSION.deb && \
rm sbt-$SBT_VERSION.deb && \
apt-get update && \
apt-get install sbt && \
sbt sbtVersion && \
mkdir project && \
echo "scalaVersion := \"${SCALA_VERSION}\"" > build.sbt && \
echo "sbt.version=${SBT_VERSION}" > project/build.properties && \
echo "case object Temp" > Temp.scala && \
sbt compile && \
echo "done with compiling, starting deletion" && \
rm -rf project && \
rm -f build.sbt && \
rm -f Temp.scala && \
rm -rf target && \
echo "done with deletion" && \
mkdir -p /spark/ && \
echo "created spark directory" && \
curl -sL https://archive.apache.org/dist/spark/spark-3.0.1/spark-3.0.1-bin-hadoop3.2.tgz|gunzip| tar x -C /spark/ && \
echo "curled spark" && \
#rm /spark/spark-3.0.1-bin-hadoop3.2/jars/kubernetes-*-4.1.2.jar && \
echo "starting with wget" && \
wget https://repo1.maven.org/maven2/io/fabric8/kubernetes-model-common/4.4.2/kubernetes-model-common-4.4.2.jar -P /spark/spark-3.0.1-bin-hadoop3.2/jars/ && \
wget https://repo1.maven.org/maven2/io/fabric8/kubernetes-client/4.4.2/kubernetes-client-4.4.2.jar -P /spark/spark-3.0.1-bin-hadoop3.2/jars/ && \
wget https://repo1.maven.org/maven2/io/fabric8/kubernetes-model/4.4.2/kubernetes-model-4.4.2.jar -P /spark/spark-3.0.1-bin-hadoop3.2/jars/ && \
echo "done with wget"
# Define working directory
WORKDIR /opt/input
# Project Definition layers change less often than application code
COPY app/build.sbt ./
WORKDIR /opt/input/project
# COPY project/*.scala ./
COPY app/project/build.properties ./
COPY app/project/*.sbt ./
WORKDIR /opt/input
RUN sbt reload
# Copy rest of application
COPY app ./
RUN sbt testCoverage
RUN SBT_OPTS="-Xms2048M -Xmx2048M -Xss1024M -XX:MaxMetaspaceSize=2048M" sbt 'set test in assembly := {}' clean assembly
FROM openjdk:8-alpine AS spark
# install python
ENV PYTHONUNBUFFERED=1
RUN apk add --update --no-cache python3 && ln -sf python3 /usr/bin/python
RUN python3 -m ensurepip
RUN pip3 install --no-cache --upgrade pip setuptools
ARG spark_home=/spark/spark-3.0.1-bin-hadoop3.2
RUN set -ex && \
apk upgrade --no-cache && \
apk add --no-cache bash tini libc6-compat gcompat linux-pam nss && \
mkdir -p /opt/spark && \
mkdir -p /opt/spark/work-dir && \
touch /opt/spark/RELEASE && \
rm /bin/sh && \
ln -sv /bin/bash /bin/sh && \
echo "auth required pam_wheel.so use_uid" >> /etc/pam.d/su && \
chgrp root /etc/passwd && chmod ug+rw /etc/passwd
COPY --from=build ${spark_home}/jars /opt/spark/jars
COPY --from=build ${spark_home}/bin /opt/spark/bin
COPY --from=build ${spark_home}/sbin /opt/spark/sbin
COPY --from=build ${spark_home}/kubernetes/dockerfiles/spark/entrypoint.sh /opt/
FROM spark AS final
ENV SPARK_HOME /opt/spark
RUN mkdir /opt/spark/conf
COPY scripts/entrypoint.sh /tmp/
COPY app/src/main/resources/log4j.properties /opt/spark/conf/
COPY app/src/main/resources/metrics.properties /opt/spark/conf/
COPY --from=build /opt/input/target/scala-2.12/legion-streaming-assembly-0.2.jar /opt/spark/jars
WORKDIR /opt/spark/work-dir
RUN wget https://archive.apache.org/dist/kafka/2.2.1/kafka_2.12-2.2.1.tgz
RUN tar -xzf kafka_2.12-2.2.1.tgz
RUN chmod +x /tmp/entrypoint.sh
ENTRYPOINT "/tmp/entrypoint.sh"Шаг 3: Пользовательские метрики
Для каждого приложения наступает момент, когда требуется получить от него какие-то специфические метрики: время выполнения определенных методов, ключевая статистика о внутреннем состоянии, проверка работоспособности приложения и т. д. Для этого должна быть возможность инструментирования приложения и передачи метрик в Prometheus. Это можно сделать с помощью java-библиотеки Dropwizard Metrics. Например, метрику можно реализовать следующим образом (исходный код):
package org.apache.spark.metrics.source
import com.codahale.metrics._
object LegionMetrics {
val metrics = new LegionMetrics
}
class LegionMetrics extends Source {
override val sourceName: String = "LegionCommonSource"
override val metricRegistry: MetricRegistry = new MetricRegistry
val runTime: Histogram = metricRegistry.histogram(MetricRegistry.name("legionCommonRuntime"))
val totalEvents: Counter = metricRegistry.counter(MetricRegistry.name("legionCommonTotalEventsCount"))
val totalErrors: Counter = metricRegistry.counter(MetricRegistry.name("legionCommonTotalErrorsCount"))
}Теперь эту метрику можно вызвать из любой точки вашего кода и обновить счетчики (counter), гистограммы (histogram), шкалы (gauge) или таймеры (timer). Все метрики автоматически становятся доступны через HTTP.
LegionMetrics.metrics.totalEvents.inc(batch.count())
LegionMetrics.metrics.runTime.update(System.currentTimeMillis - start)После развертывания Spark-приложения можно перейти к driver-поду в кластере K8s и убедиться, что доступны все Spark и пользовательские метрики. Например, с помощью curl.
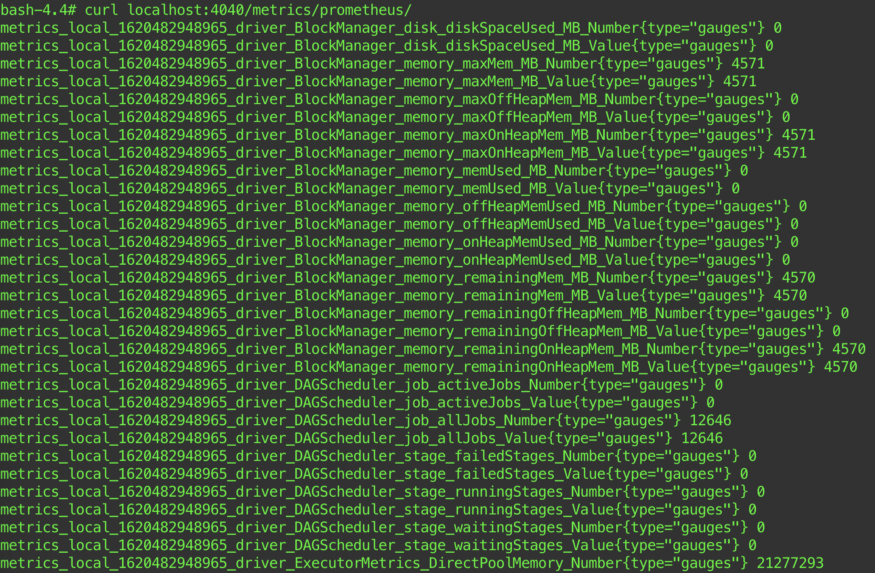
Для Spark Streaming требуется дополнительная настройка: spark.sql.streaming.metricsEnabled.
Если для spark.sql.streaming.metricsEnabled задано значение true, вы увидите дополнительные метрики: latency, processing rate, state rows, event-time watermark и т.д.
Шаг 4: Дашборды в Grafana
После развертывания Spark-приложения и настройки Prometheus можно переходить к созданию дашборда в Grafana. Создайте новый дашборд, выберите источник данных Prometheus и введите запрос.
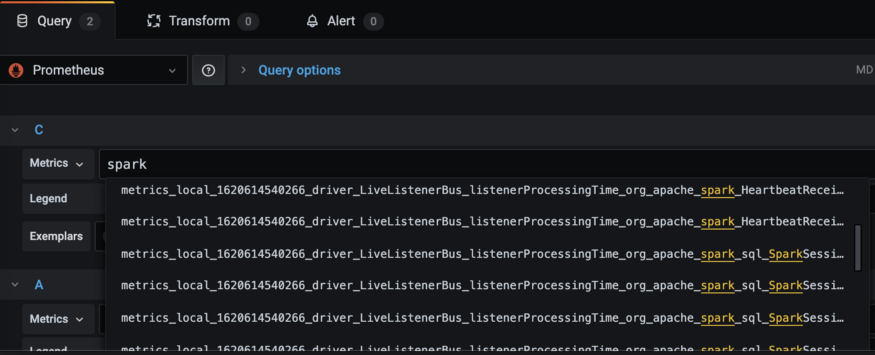
Помните, что PrometheusServlet следует соглашениям об именовании Spark 2.x вместо принятого в Prometheus. Выберите любые метрики по своему усмотрению и поместите их на дашборд.

Вы также можете использовать Prometheus Alertmanager для определения алертов о важных метриках. Например, рекомендуется сделать алерты для следующих метрик: упавшие задания, долго выполняющиеся задачи, массовый shuffle, latency vs batch interval (streaming) и т. д.
Резюме
Если вы используете Apache Spark для обработки огромных массивов данных и беспокоитесь об экономической эффективности и переносимости, то вы, вероятно, рассматриваете Kubernetes или уже используете его. Apache Spark 3 делает еще один большой шаг в сторону K8s. Реализовать мониторинг и алертинг Apache Spark в K8s стало действительно просто благодаря встроенной поддержке Prometheus, и результат сопоставим с тем функционалом, который есть в управляемых сервисах, таких как AWS EMR.
Материал подготовлен в рамках курса «Мониторинг и логирование: Zabbix, Prometheus, ELK».
Всех желающих приглашаем на demo-занятие «Системы логирования (ELK, EFK, Graylog2)». На уроке сравним различные системы логирования, присутствующих на рынке: ELK, EFK — fluentd, Graylog2. Регистрация здесь.


