
Всем привет!
Я уже рассказывал в этом блоге об организации модульной системы мониторинга для микросервисной архитектуры и о переходе с Graphite+Whisper на Graphite+ClickHouse для хранения метрик в условиях высоких нагрузок. После чего мой коллега Сергей Носков писал о самом первом звене нашей системы мониторинга — разработанном нами Bioyino, распределённом масштабируемом агрегаторе метрик.
Пришло время немного освежить информацию о том как мы готовим мониторинг в Авито — последняя наша статья была аж в далеком 2018 году, и за это время было несколько интересных изменений в архитектуре мониторинга, управлении триггерами и нотификациями, различные оптимизации данных в ClickHouse и прочие нововведения, о которых я как раз и хочу вам рассказать.

Но давайте начнем по порядку.
В далеком 2017 я показывал схему взаимодействия компонентов, актуальную на тот момент, и хотел бы продемонстрировать её еще раз, дабы вам не пришлось лишний раз переключаться по вкладкам.

С того момента произошло следующее.
Количество серверов в кластере Graphite выросло с 3 до 6.
(56 CPU 2.60GHz, 384GB RAM, 10 SSD SAS 745GB, Raid 6, 10GBit/s Net).
Мы заменили brubeck на bioyino — нашу собственную имплементацию StatsD на Rust, и даже целую статью про это написали. Правда, после выхода статьи мы подвезли в него поддержку тегов (Graphite) и Raft для выбора лидера.
Мы проработали возможность использовать bioyino в качестве StatsD-агента и разместили такие агенты рядом с инстансами монолита, а также там, где это было необходимо в k8s.
Мы наконец-то избавились от старой системы мониторинга Munin (формально она у нас ещё есть, но её данные уже нигде не используются).
Сбор данных из кластеров Kubernetes был организован через Prometheus/Federations, так как Heapster в новых версиях Kubernetes не поддержали.
Мониторинг
За два прошедших года количество принимаемых и обрабатываемых метрик выросло примерно в 9 раз.
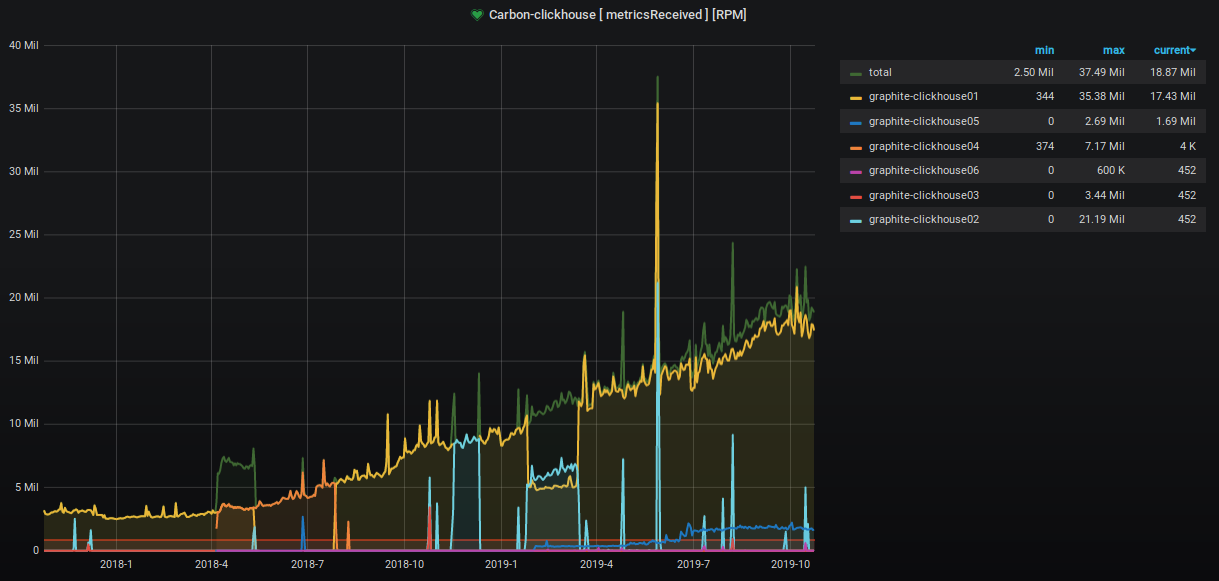
Процент занимаемого места на серверах также неумолимо ползёт вверх, и мы предпринимаем различные шаги по его понижению. Это хорошо видно на графике.
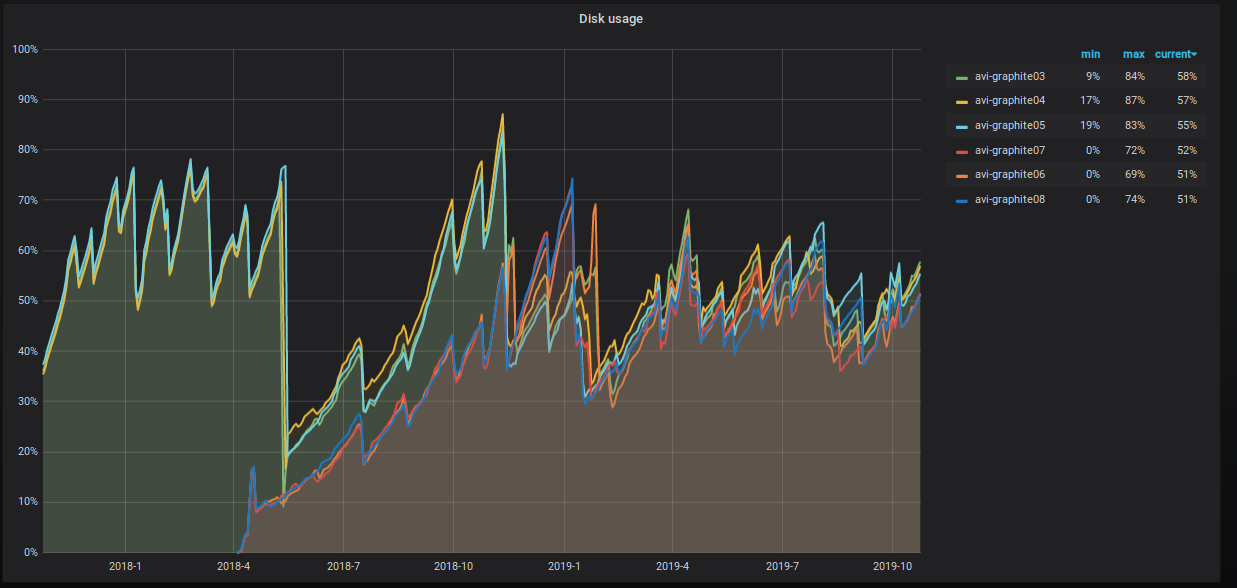
Что именно мы делаем?
- Начали применять комплексные методы сжатия на колонки с данными.
ALTER TABLE graphite.data MODIFY COLUMN Time UInt32 CODEC(Delta, ZSTD) - Продолжаем схлопывать данные старше пяти недель с тридцатисекундных интервалов до пятиминутных. Для этого у нас есть задание cron, которое раз в месяц запускает (примерно) следующую процедуру:
10 10 10 * * clickhouse-client -q "select distinct partition from system.parts where active=1 and database='graphite' and table='data' and max_date between today()-55 AND today()-35;" | while read PART; do clickhouse-client -u systemXXX --password XXXXXXX -q "OPTIMIZE TABLE graphite.data PARTITION ('"$PART"') FINAL";done- Мы расшардировали таблицы с данными. Теперь у нас три шарда по две реплики в каждом с ключом шардирования по хэшу от имени метрики. Такой подход дает нам возможность производить rollup процедуры, так как все значения по конкретной метрике находятся в пределах одного шарда, а дисковое пространство на всех шардах утилизируется равномерно.
Схема Distributed таблицы выглядит следующим образом.
CREATE TABLE graphite.data_all (
`Path` String,
`Value` Float64,
`Time` UInt32,
`Date` Date,
`Timestamp` UInt32
)
ENGINE = Distributed (
'graphite_cluster',
'graphite',
'data',
jumpConsistentHash(cityHash64(Path), 3)
) Мы также назначили пользователю "default" readonly-права и перекинули выполнение процедур записи в таблицы на отдельного пользователя systemXXX.
Конфигурация кластера Graphite в ClickHouse выглядит следующим образом.
<remote_servers>
<graphite_cluster>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>graphite-clickhouse01</host>
<port>9000</port>
<user>systemXXX</user>
<password>XXXXXX</password>
</replica>
<replica>
<host>graphite-clickhouse04</host>
<port>9000</port>
<user>systemXXX</user>
<password>XXXXXX</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>graphite-clickhouse02</host>
<port>9000</port>
<user>systemXXX</user>
<password>XXXXXX</password>
</replica>
<replica>
<host>graphite-clickhouse05</host>
<port>9000</port>
<user>systemXXX</user>
<password>XXXXXX</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>graphite-clickhouse03</host>
<port>9000</port>
<user>systemXXX</user>
<password>XXXXXX</password>
</replica>
<replica>
<host>graphite-clickhouse06</host>
<port>9000</port>
<user>systemXXX</user>
<password>XXXXXX</password>
</replica>
</shard>
</graphite_cluster>
</remote_servers>Помимо нагрузки на запись, выросло количество запросов на чтение данных из Graphite. Эти данные используются для:
- обработки триггеров и формирования алертов;
- отображения графиков на мониторах в офисе и экранах ноутбуков и ПК растущего числа сотрудников компании.
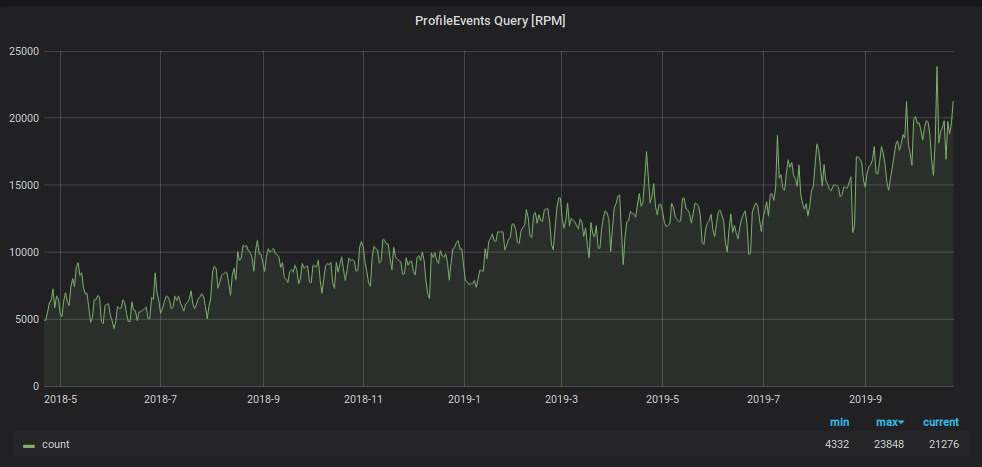
Чтобы мониторинг не утонул под этой нагрузкой, мы использовали ещё один хак: данные за последние два дня мы храним в отдельной «маленькой» табличке, и все читающие запросы за последние два дня мы отправляем туда, снижая нагрузку на основную шардированную таблицу. Так же для этой «маленькой» таблички мы применили реверсивную схему хранения метрик, что значительно ускорило поиск находящихся в ней данных и организовали для неё дневное партиционирование. Cхема этой таблички выглядит следующим образом.
CREATE TABLE graphite.data_reverse (
`Path` String,
`Value` Float64,
`Time` UInt32 CODEC(Delta(4), ZSTD(1)),
`Date` Date,
`Timestamp` UInt32
)
ENGINE = ReplicatedGraphiteMergeTree (
'/clickhouse/tables/{cluster}/data_reverse',
'{replica}',
'graphite_rollup'
) PARTITION BY Date
ORDER BY (Path, Time)
SETTINGS index_granularity = 4096Чтобы направлять в неё данные, мы добавили в конфигурационный файл приложения carbon-clickhouse новую секцию.
[upload.graphite_reverse]
type = "points-reverse"
table = "graphite.data_reverse"
threads = 2
url = "http://systemXXX:XXXXXXX@localhost:8123/"
timeout = "60s"
cache-ttl = "6h0m0s"
zero-timestamp = trueЧтобы удалять партиции старше двух дней, мы написали задание cron. Оно выглядит примерно так.
1 12 * * * clickhouse-client -q "select distinct partition from system.parts where active=1 and database='graphite' and table='data_reverse' and max_date<today()-2;" | while read PART; do clickhouse-client -u systemXXX --password XXXXXXX -q "ALTER TABLE graphite.data_reverse DROP PARTITION ('"$PART"')";doneЧтобы читать из таблицы данные, в конфигурационном файле graphite-clickhouse добавили секцию:
[[data-table]]
table = "graphite.data_reverse"
max-age = "48h"
reverse = trueВ результате мы имеем таблицу с 100% данных, реплицированных на все шесть серверов, которые обрабатывают всю читающую нагрузку от запросов с окном менее двух суток (а таких у нас 95%). А также мы имеем шардированную таблицу с 1/3 данных на каждом шарде, обеспечивающую чтение всех исторических данных. И пусть таких запросов кратно меньше, нагрузка от них значительно выше.
Что же происходит с CPU?! В результате роста объемов записываемых и читаемых данных в кластере Graphite, выросла и суммарная CPU-нагрузка на серверы. Выглядит она примерно так.
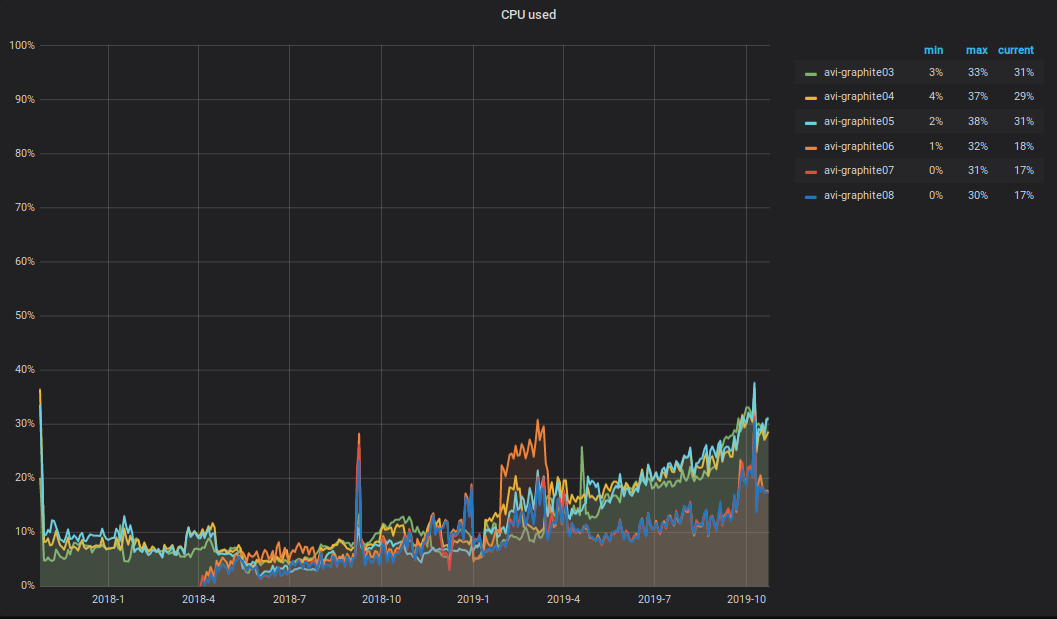
Хочется обратить внимание на следующий нюанс: половина CPU уходит на парсинг и первичную обработку метрик в carbon-c-realy (v3.2 от 2018-09-05, отвечает за транспорт метрик), который размещен на трёх серверах из шести. Как видно по графику, именно эти три сервера и находятся в ТОПе.
Алертинг
В качестве системы алертинга у нас по-прежнему Moira и написанный под неё moira-client. Для гибкого управления триггерами, нотификациями и эскалациями, мы используем декларативное описание, которое назвали alert.yaml. Оно генерируется автоматически при создании сервиса через PaaS (подробнее об этом можно почитать в статье Вадима Мадисона «Что мы знаем о микросервисах») и размещается в его репозитории. Для работы с alert.yaml мы сделали обвязку над moira-client и назвали её alert-autoconf (планируем заопенсорсить). В сборке сервиса в TeamCity есть шаг с экспортом триггеров и нотификаций в Moira через alert-autoconf. При коммите изменений в alert.yaml запускаются автотесты, которые проверяют валидность yaml-файла, а также делают запросы в Graphite по каждому шаблону метрик с целью проверить их корректность.
Для инфраструктурных команд, не использующих PaaS, мы организовали отдельный репозиторий под названием Alerting. В нем сделали структуру вида: Команда/Проект/alert.yaml. К каждому alert.yaml мы генерируем отдельную сборку в TeamCity, которая прогоняет тесты и пушит содержимое alert.yaml в Moira.
Таким образом все наши сотрудники могут управлять своими триггерами, нотификациями и эскалациями, используя единый подход.
Так как раньше у нас уже были триггеры, заведённые через GUI, мы реализовали возможность выгрузить их в формате yaml. Содержимое полученного yaml-документа можно вставить в alert.yaml практически без дополнительных преобразований, после чего запушить изменения в мастер. В ходе сборки alert-autoconf поймет, что такой триггер уже существует и зарегистрирует его в нашем реестре в Redis.
А ещё не так давно мы обзавелись дежурной сменой инженеров 24х7. Для того, чтобы передать триггеры им на обслуживание, достаточно в своем alert.yaml корректно заполнить описание «что делать, если ты это видишь», поставить тег [24x7] и запушить изменения в мастер. После раскатки alert.yaml'а все описанные в нем триггеры автоматически попадут под круглосуточное наблюдение смены 24х7. У — Упрощай! Красота!
Сбор бизнес-метрик
С момента выхода прошлой статьи про сбор и обработку бизнес-метрик наш bioyino стал ещё лучше.
- Вместо выбора лидера через Consul используется встроенный Raft.
- Корректно обрабатываются теги в формате Graphite.
- Появилась возможность использовать bioyino (StatsD-server) в качестве агента.
- Для подсчета уникальных значений поддерживается формат "set".
- Финальную агрегацию метрик можно делать в несколько потоков.
- Данные можно отправлять в Graphite чанками в несколько параллельных соединений.
- Исправлены все найденные баги.
Сейчас это работает так.
Мы стали активно внедрять StatsD-агенты рядом со всеми крупными крупными генераторами метрик: в контейнерах с инстансами монолита, в подах k8s рядом с сервисами, на хостах с инфраструктурными компонентами и т. д.
Statsd-агент размещается рядом с приложением. Он принимает метрики от этого приложения всё так же по UDP, но уже не используя сетевую подсистему (за счёт оптимизаций в ядре Linux). Все события предагрегируются, и собранные данные ежесекундно (интервал можно настроить) отправляются в основной кластер серверов StatsD (bioyino0[1-3]) в формате Cap’n Proto.
Дальнейшая обработка и агрегация метрик, выбор лидера в StatsD-кластере и отправка лидером метрик в Graphite практически не изменились. Про это вы можете подробно прочитать в нашей прошлой статье.
Что же касается цифр, то они следующие.
График полученных StatsD-событий
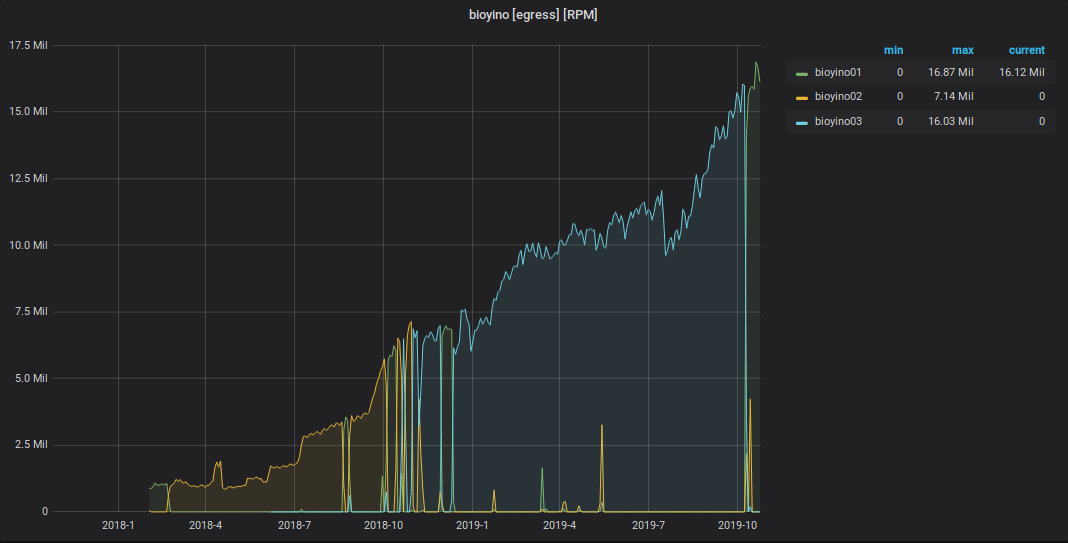

График метрик, отправленных из StatsD в Graphite
Итого
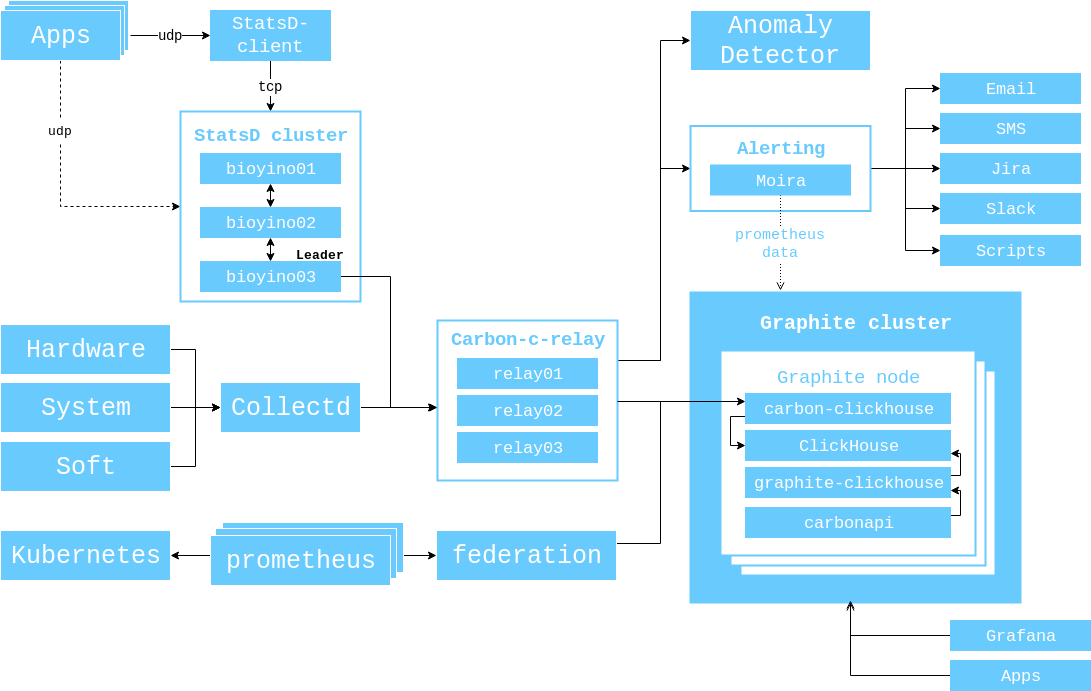
Общая схема взаимодействия компонентов мониторинга на данный момент выглядит так.
Суммарное количество значений метрик: 2 189 484 898 474.
Общая глубина хранения метрик: 3 года.
Количество уникальных имен метрик: 6 585 413 171.
Количество триггеров: 1053, они обслуживают от 1 до 15k метрик.
Планы на ближайшее будущее:
- начать переводить продуктовые сервисы на тегированную схему хранения метрик;
- добавить в кластер Graphite еще три сервера;
- подружить Moira с персистентной тканью;
- найти ещё одного разработчика в команду мониторинга.
Буду рад комментариям и вопросам здесь — пишите. А ещё я буду выступать 7 ноября на Highload++, если будете там, можем пообщаться.




