
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Всегда при работе с речью встает несколько очень "простых" вопросов, для решения которых нет большого количества удобных, открытых и простых инструментов: детекция наличия голоса (или музыки), детекция наличия цифр и классификация языков.
Для решения задачи детекции голоса (Voice Activity Detector, VAD) существует довольно популярный инструмент от Google — webRTC VAD. Он нетребовательный по ресурсам и компактный, но его основной минус состоит в неустойчивости к шуму, большом числе ложноположительных срабатываний и невозможности тонкой настройки. Понятно, что если переформулировать задачу не в детекцию голоса, а в детекцию тишины (тишина — это отсутствие и голоса и шума), то она решается весьма тривиальными способами (порогом по энергии, например), но с теми же минусами и ограничениями. Что самое неприятное — зачастую такие решения являются хрупкими и какие-то хардкодные пороги не переносятся на другие домены.
Изначально мы хотели сделать простой и быстрый внутренний инструмент для себя и наших партнеров для детекции произнесенных чисел без привлечения полноценного STT (фишка изначально была именно в портативности засчет использования современных фреймворков типа PyTorch и ONNX), но в итоге оказалось, что можно сделать не только детектор чисел, но и качественный, быстрый и портативный VAD и классификатор языков, который и опубликовали бесплатно для всех желающих тут под лицензией MIT. За подробностями прошу под кат.
Основные фишки нашего решения
Что же умеет делать наш "VAD"?
- Именно сам VAD — находит в аудио участки, где люди говорят;
- Number detector — находит в аудио участки, где люди произносят цифры;
- Language classifier — классифицирует языки;
- Это все сейчас работает на 4 языках (Русский, Английский, Немецкий, Испанский), но с высокой степенью вероятности именно сам VAD будет работать и на других родственных им языках (небольшой квест для Хабра — если вы говорите на каком-то экзотическом языке, запишите свой голос, прогоните VAD и поделитесь результатом!);
Основные "фишки" на данный момент:
- Поддержка 4 языков;
- Именно VAD сильно выигрывает у WebRTC по качеству;
- Натренирован на огромных речевых и шумовых корпусах;
- Ест мало ресурсов и памяти, работает на 1 потоке процессора;
- Его скорости достаточно для edge и мобильных применений;
- Построен на базе современных и портативных технологий (PyTorch, ONNX);
- В отличие от WebRTC скорее является детектором голоса, а не детектором тишины;
- Мы выложили чекпойнты как для PyTorch (JIT), так и для ONNX;
Возможные применения
- Детекция конца фразы;
- Подготовка и очистка голосовых корпусов;
- Часть пайплайна для анонимизации речевых корпусов (по-хорошему еще надо уметь искать имена, но это совсем другая проблема, и она довольно специфична для решаемой задачи и требует наличия и тонкой настройки STT);
- Детекция наличия голоса для применения на мобильных и edge устройствах;
- Компактность и наличие ONNX позволяет запускать его с большим количеством доступных бекендов;
- VAD кушает данные с частотой дискретизации 16 kHz, но он научен не бояться и данных с 8 kHz;
Примеры
Вообще мы постарались привести основные примеры использования в интерактивном ноутбучке в colab и в самом репозитории. Все их выписывать в статью смысла нет, давайте просто перечислим самые важные и приведем самый простой пример:
- Все примеры есть как для PyTorch так и для ONNX;
- Для самого важного алгоритма — VAD — мы привели примеры как для работы с целыми отдельными файлами, так и для однопоточного / многопоточного стриминга;
- Для остальных — приведены только примеры по работе с отдельными файлами. Но имея VAD уже несложно длинные файлы разделить на короткие;
- Примеры специально приводятся в виде простейшего тулкита, который легко будет адаптировать на свой язык с минимальными усилиями (обработка целых файлов тривиальна, стриминг в 1 поток несложный, несколько потоков немного сложноват из-за механизма окон);
Самый просто пример, где мы натравливаем VAD на файл:
import torch
torch.set_num_threads(1)
model, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad',
model='silero_vad',
force_reload=True)
(get_speech_ts,
_, read_audio,
_, _, _) = utils
files_dir = torch.hub.get_dir() + '/snakers4_silero-vad_master/files'
wav = read_audio(f'{files_dir}/en.wav')
speech_timestamps = get_speech_ts(wav, model,
num_steps=4)
print(speech_timestamps)Как работает VAD
Тут кратко опишем, как данные кормятся в VAD. Для остальных алгоритмов заинтересовавшиеся просто найдут информацию в коде.
- Аудио разделяется на кусочки длиной например 250 мс. Можно конечно порезать и короче, но по нашему опыту все паузы менее 100 мс являются малозначимыми и получается очень много шума, если пытаться поделить по 30-50мс. По просьбам интересующихся мы также привели график зависимости качества от длины кусочка тут (мы сравнили 100 мс и 250 мс);
- VAD держит в памяти прошлый кусочек (или нули в начале стрима);
- Эти кусочки по 500 мс (или по 200 мс) делятся на 4 или 8 окон внахлест и модель применяется к каждому такому окну;
- Вероятности выдаваемые моделью усредняются по всем таким окнам;
- Дальше эта вероятность используется, чтобы или "войти" в речь или из нее "выйти". Базовые оптимальные гипер-параметры приведены в коде примеров;
Скорость и задержка
Все замеры скорости мы делали на 1 потоке процессора AMD Ryzen Threadripper 3960X. Для этого мы использовали такие настройки:
torch.set_num_threads(1) # pytorch
ort_session.intra_op_num_threads = 1 # onnx
ort_session.inter_op_num_threads = 1 # onnxПодробнее вы можете просто посмотреть в коде, но задежка зависит от следующих параметров:
- num_steps — число таких окон "внахлест";
- number of audio streams — число одновременно обрабатываемых потоков аудио;
- По сути получается, что модель всегда видит батч длины равной num_steps * number of audio streams;
Получаются такие задержки:
| Batch size | Pytorch latency, ms | Onnx latency, ms |
|---|---|---|
| 2 | 9 | 2 |
| 4 | 11 | 4 |
| 8 | 14 | 7 |
| 16 | 19 | 12 |
| 40 | 36 | 29 |
| 80 | 64 | 55 |
| 120 | 96 | 85 |
| 200 | 157 | 137 |
Попробуем теперь измерить пропускную способность в секундах аудио, обрабатываемых за одну секунду на 1 потоке процессора:
| Batch size | num_steps | Pytorch model RTS | Onnx model RTS |
|---|---|---|---|
| 40 | 4 | 68 | 86 |
| 40 | 8 | 34 | 43 |
| 80 | 4 | 78 | 91 |
| 80 | 8 | 39 | 45 |
| 120 | 4 | 78 | 88 |
| 120 | 8 | 39 | 44 |
| 200 | 4 | 80 | 91 |
| 200 | 8 | 40 | 46 |
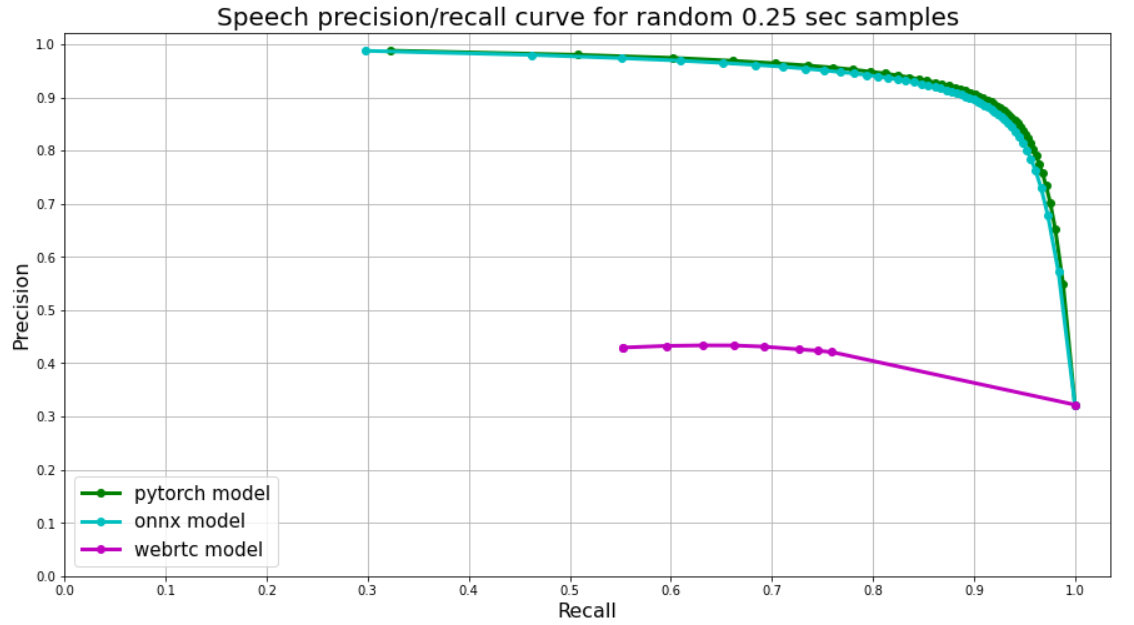
Качество
По логике процесса, описанного выше, мы измеряли качество нашего VAD по сути просто присваивая некую усредненную вероятность каждому кусочку аудио и сравнивая ее с истинными метками. Но как добавить к сравнению WebRTС, он же выдает просто 0 или 1?
WebRTC принимает на вход фреймы аудио и отдает 0 или 1. По-умолчанию используется длина фрейма в 30 мс, то есть каждый кусочек аудио в 250 мс мы делится примерно на 8 таких фреймов. Это неидеально, но мы просто интерпретируем среднее из таких 0 и 1 как вероятность.
В итоге получается вот такой результат:
Тонкая настройка и остальные алгоритмы
Как упоминалось выше, наш VAD также обладает тем преимуществом, что его можно более тонко настраивать используя более очевидные параметры. Инструкцию по такой настройке, примеры и описания работы остальных алгоритмов вы можете найти в репозитории нашего проекта. Пропускная способность и задержка других алгоритмов примерно сравнима с VAD.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
А вы когда-либо использовали VAD?
-
100,0%Да1
-
0,0%Нет0
А вы когда-либо использовали ONNX?
-
100,0%Да1
-
0,0%Нет0
Если вы использовали VAD, то где?
-
100,0%В бекенде1
-
0,0%На фронтенде0
-
0,0%На мобиле0
-
0,0%На edge или IOT устройствах0
-
100,0%В скриптах по обработке датасетов1
-
0,0%Посмотреть ответ / не использовал0




