
Каждая команда в своей работе сталкивается с необходимостью внедрения новой технологии или языка программирования в проект. Иногда это внедрение проходит успешно, а иногда нет. В этой статье хотелось бы рассказать о нашем опыте использования C++/CLI.
Ожидается солнечная погода
Задание: разработать программный комплекс для моделирования различных процессов, протекающих на объектах в системах сбора, подготовки и транспортировки углеводородов. Объектами моделирования могут быть скважины (как добывающие, так и нагнетательные), трубопроводы, объекты подготовки нефти, газа и воды. В среднем каждое месторождение характеризуется более чем 100 объектами обустройства. Причём некоторые объекты имеют размерность либо по глубине, либо по длине – в несколько километров. Приемлемое время расчёта модели одного месторождения – порядка нескольких минут. Если совсем просто, то необходимо представить вот такой объект:

В виде вот такой модели – и рассчитать её характеристики.

Наработки: существующие методики, существующий проект с функциональностью, частично покрывающей задачи проекта.
Команда: программист стека .NET/WPF, программист C++, методист, руководитель проекта.
На первом этапе задача состояла в том, чтобы освоиться с уже существующей кодовой базой, понять, что и как работает, убрать всё лишнее, добавить часть нового функционала в соответствии с описанием, полученным от методистов. Небольшое замечание, которое в дальнейшем будет иметь значение: все расчёты должны быть выполнены на C++, это было связано с тем, что необходимо обеспечить:
● высокую скорость расчётов;
● последующее использование наработок в качестве подмодулей для других приложений.
Безоблачное продолжение
Уже существующий проект, на базе которого предстояло начать работать, был выполнен с использованием .NET/WPF, методики расчёта модели реализованы при помощи .NET/C# c промежуточными вызовами плюсового кода через P/Invoke. P/Invoke (для справки) – это технология, которая позволяет обращаться к структурам, обратным вызовам и функциям в неуправляемых библиотеках из управляемого кода. Т. е. примерно вот так:
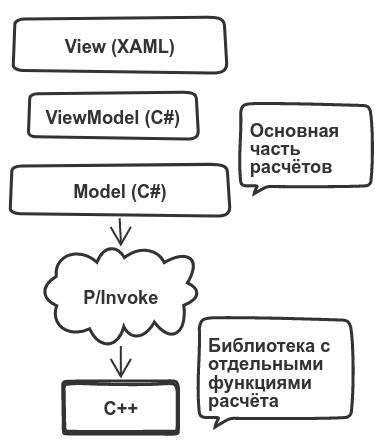
Код на C# содержал описание моделей объектов, участвующих в расчёте, а также расчёт сети объектов. За расчёт параметров отдельного объекта отвечала плюсовая часть. Время выполнения расчёта соответствовало заявленным требованиям, поэтому было решено оставить расчёт сети объектов на C# и сосредоточиться на расширении расчётов параметров самих объектов на C++.
Так как предстояло значительное увеличение количества вычисляемых параметров (и, соответственно, количества параметров, которые необходимо передавать через P/Invoke), то возник вопрос: "Использовать прежнюю схему взаимодействия с неуправляемым кодом или воспользоваться другими технологиями?".
Ключевыми критериями для выбора мы определили скорость взаимодействия и удобство использования.
В качестве альтернативы использованию P/Invoke, возникла идея использования технологии C++/CLI.
Спецификация языка C++/CLI (C++ modified for Common Language Infrastructure) была создана компанией Microsoft на замену Managed Extensions for C++. C++/CLI позволяет одновременно работать как с классами и методами языков .NET, так и с обычным кодом C++.
Приставка CLI расшифровывается как Common Language Infrastructure – это открытая спецификация (технический стандарт), разработанная Microsoft и стандартизированная ISO и Ecma, описывающая исполняемый код и среду выполнения, которая позволяет использовать несколько языков высокого уровня на различные компьютерных платформах без переписывания под конкретные архитектуры. Т. е. C++/CLI нужен вот для этого:

В C++/CLI, прежде всего, нам показалось привлекательной возможность вызова уже написанного на плюсах кода при помощи управляемых оберток для существующих классов на С++. Сравнительный тест скорости вызова плюсового кода при помощи C++/CLI и P/Invoke, как ни странно, также показал уменьшение времени расчёта при использовании первого.
Вызовов P/Invoke на тот момент было совсем немного и поэтому в короткий срок нам удалось перейти на использование новой технологии. Стандартный вариант использования C++/CLI в нашем проекте выглядел примерно вот так:
public ref class DeviceBaseClr : public IDisposable, public Figures::Models::IItemBase
{
#pragma region Поля и свойства
protected:
/// <summary>
/// C++ unmanaged объект декоратора
/// </summary>
DeviceBase* obj_;
#pragma endregion
#pragma region IItemBase
public:
virtual IState^ GetState(DateTime date);
virtual IState^ SetState(DateTime date, IState^ state);
#pragma endregion
#pragma region Конструкторы
public:
DeviceBaseClr(IStateFactory^ stateFactory);
virtual ~DeviceBaseClr();
protected:
!DeviceBaseClr();
#pragma endregion
};
} // Simtep::Diagrams
#endif // _DEVICEBASECLR_H_
Предполагаемая архитектура приложения, выполненного в соответствии с парадигмой MVVM, выглядела следующим образом:

Тучи сгущаются
На следующем этапе развития проекта, по мере наращивания функционала, мы начали сталкиваться с некоторыми проблемами.
Во-первых, появилась необходимость вызова расчётов реализованных на C# внутри неуправляемого кода (и, кстати, да – C++/CLI и это позволяет делать тоже).
Во-вторых, нам пришлось опустить часть модели в неуправляемую часть из-за того, что возникла необходимость использования сторонних библиотек, реализованных на С++.
После этих изменений архитектура приложения приобрела следующий вид:

В результате возникли как технические проблемы:
● Мы не могли просто подключать сторонние библиотеки на C++ (имеются в виду библиотеки с расчётами предоставленные нашими коллегами из параллельных проектов), нужно было пересобирать их из исходного кода, используя специальные директивы для CLI.
● Существует отдельный синтаксис LINQ для CLI, его возможности ограничены по сравнению с обычным, например, в нём нет лямбда-выражений, писать отдельные методы каждый раз – не очень удобно.
● Отсутствие возможности использовать «умные» указатели.
● Постоянно возникали вопросы при использовании контейнеров, например при попытке добавления в коллекцию, созданную на стороне неуправляемого кода, объекта, созданного на стороне .NET.
● Управление памятью, например, что будет, если для одного нативного объекта вдруг создастся две обёртки на CLI, и в какой-то момент будет освобождена сборщиком мусора?
● При организации взаимодействия нужно быть готовым к тому, что для каждого объекта придётся писать обёртку. И их может потребоваться очень много.
● Логика классов может усложняться, что неизбежно ведёт к усложнению обёрток.
● Как уже было сказано выше, рано или поздно возникает необходимость обратного использования управляемого кода в неуправляемом. C++/CLI позволяет это сделать, при этом увеличивается сложность проекта.
Так и вопросы организационного характера:
● C++/CLI – это всё-таки ещё один язык программирования. Т. е. если к вам в команду добавляется джуниор с базовыми знаниями по C++, нужно учитывать, что ему необходимо влиться в предметную область, чуть подтянуть свой уровень владения C++ и плюс ко всему выучить ещё один язык программирования. Ну и, соответственно, ошибки можно сделать как в нативном коде, так и в обёртке.
● Программистам C# будет тяжело в случае необходимости внести изменения в обёртку.
По мере развития проекта мы стали замечать, что большая часть времени уходит не на расширение функционала, а именно на изучение самого C++/CLI, особенностей его синтаксиса и поддержание кода именно обёрток. Разумеется, к обычным ошибкам, сопутствующим процессу разработки, добавились ошибки, возникающие на стыке C# и C++/CLI.
Возможно, мы бы продолжали поддерживать и развивать проект в таком виде, если бы не ещё одна проблема, которая стала критической, а именно – мы перестали укладываться в ограничения по времени выполнения расчёта модели. Это случилось не в один день, просто каждая итерация по расширению функционала вносила свой вклад в общее время расчёта. Если при старте проекта мы рассчитывали лишь простые параметры по объекту, то расчётное ядро значительно увеличилось в размерах:

Попытки оптимизации кода не давали нужных результатов, помимо возросшего функционала. Причины низкой скорости расчётов крылись в следующем:
● Множественный вызов CLI. Почти на каждой строке. Это значит постоянное создание декораторов, постоянный (почти непрерывный маппинг) как в одну сторону, так и в другую.
● Использование декораторов означает их создание, т. е. постоянное выделение памяти внутри расчётного цикла.
● Цикл расчёта на стороне .NET, не позволявший осуществить многопоточный расчёт в полной мере.
● Плюс системные затраты на преобразование типов из managed в unmanaged и обратно (речь о передаче стандартных типов).
Разгон облаков
Скорость расчёта критична для нашего приложения, поэтому нам было необходимо либо дальше оптимизировать существующий код с небольшими шансами на успех, либо попытаться отделить расчёты от интерфейса и модели (заодно отказавшись от CLI) с чуть более высокими шансами. В итоге мы выбрали второе. По сути, это означало практически переписать приложение на 70 процентов заново.
Какие факторы помогали нам верить в успешность задуманного:
● сработавшаяся команда разработчиков;
● высокая степень владения кодом;
● высокая степень понимания разработчиками предметной области;
● запас времени перед сдачей этапа;
● природный оптимизм.

Новая архитектура в наших планах выглядела следующим образом:

Подобное разделение позволило бы нам избавиться от проблем с CLI и воспользоваться, наконец, в полной мере скоростью расчётов на чистом C++. Из минусов( если это можно назвать минусом) – появилась необходимость создания и поддержания эквивалентной модели на стороне С++, а также обеспечения взаимодействия между моделями.
При реализации взаимодействия был соблазн воспользоваться RabbitMQ или ZeroMQ, однако, оценивая вероятность того, что мы одновременно сумеем и переписать большую часть кода, и реализовать механизм взаимодействия на основе очереди сообщений, мы решили выбрать самый простой вариант, а именно – файловый обмен. На практике при грамотной реализации с ним возникло меньше всего проблем, в том числе и по скорости.
Переход на новую архитектуру занял у нас около 3-х месяцев, и если говорить о каких-то подводных камнях, то они были такими:
● Мы планировали завершить рефакторинг во время Х, а закончили во время 3*Х. Значительное превышение первоначальных сроков было связано с тем, что изначально в проекте были большие фрагменты кода, написанные на C#. Во время оценки времени, необходимого на переход, мы не учли того, что у нас отсутствует формализованное описание алгоритмов для этих фрагментов, а прямой перенос не всегда был возможен.
● Рефакторить 3 месяца при отсутствии навыков программирования на C++ большей части команды было тяжело.
Ожидается солнечная погода без осадков
Подводя итог, хочется сказать, что:
C++/CLI – это интересный язык программирования, и в некоторых случаях он позволяет значительно упростить жизнь. Однако прежде, чем внедрять его в свой проект, мы бы посоветовали заранее – на этапе проектирования – очертить рамки, в которых он будет использоваться. Т. е. в случае, когда он используется для обеспечения взаимодействия с нативным кодом, по нашему мнению, это должно быть либо штучное взаимодействие крупных узлов системы, либо подключение небольшого класса или функции. В противном случае вы рискуете повторить наши ошибки. Всем спасибо!
Если у кого-то есть свой опыт использования C++/CLI, то нам было бы интересно о нём узнать.
Статья Оскара Бостонова, Анатолия Землянова и Артура Лутфурахманова

