
Друзья, добрый день!
Продолжаем серию публикаций «без купюр» о проектах, связанных с разработкой, часто с приставкой «веб». Поговорим сегодня о нагрузочном тестировании. Проблема в том, что часто ни клиент, ни руководитель проекта не понимают, зачем оно нужно, какие риски оно позволяет снизить, как его организовать и как, а это самое, думаю, сложное, интерпретировать его результаты с пользой для бизнеса. Наливаем кофе и поехали…
Дело в том, что если для удержания качества в некоторых веб-проектах еще пишут автотесты, то контролем производительности на стадии разработки мало кто занимается в принципе. Увидеть веб-проект и с автотестами и с бенчмарками кода — большая редкость. Гораздо чаще и по разумным причинам при разработке придерживаются следующих эвристик, обладающих хорошим соотношением польза-стоимость:
Эвристики часто работают хорошо, но чем больше и нагруженнее проект, тем что-то может пойти не так с экспоненциально возрастающей вероятностью.
Возьмем кеширование. При разработке часто некогда задумываться над тем, как часто кэш может перестраиваться. А зря. Если перестройка кэша, скажем, каталога товаров, занимает длительное время и кэш сбрасывается при добавлении одного товара, то от кэширования будет больше вреда, чем пользы.
Именно поэтому, кстати, не рекомендуется использовать встроенный кэш запросов MySQL, страдающий от похожей проблемы: при изменении хотя бы одной записи таблицы кэш таблицы полностью сбрасывается (представим таблицу из 100к строк и абсурдность ситуации становится очевидна).
Аналогичная ситуация с запросами к MySQL. Если запросы выполняются по индексам, то, в общем случае, запросы будут выполняться… «быстрее». Можно верить, что время выполнения таких запросов логарифмически зависит от объема данных (O(log(n))). Но на практике часто оказывается, что одни запросы влияют на другие, используя одновременно общие подсистемы БД (сортировка на диске, который начинает тормозить) и сразу предвидеть это — нельзя.
Также часто при нагрузке выявляются любопытные особенности операционной системы, в частности, переполнение диапазона исходящих клиентских портов TCP/IP, при интенсивной работе с memcached. Или apache забивается запросами на обработку картинок, т.к. при конфигурации забыли настроить их обработку кэширующим прокси-сервером nginx.
Иногда забывают установить в MySQL путь для временных таблиц на диск, отображающий данные в оперативную память ("/dev/shm"), из-за чего при возрастании нагрузки сервер БД ложится от интенсивных сортировок.
Также, при добавлении в веб-проект данных, в объеме, приближенном к боевому, запросы и алгоритмы начинают агрессивно проявлять свою «О-нотацию»: если cartesian для небольшого объема данных незаметен, то при появлении боевого объема сервер БД от напряжения становится красным.
Примеров можно привести еще массу, остановимся пока на этом. Главное понять, что нагрузочное тестирование — необходимо. Потому что заранее предусмотреть все возможные варианты «торможения» веб-системы среднего размера очень дорого, очень долго и экономически нецелесообразно.
Тут важно понять, что на самом деле покажет и вам и клиенту уровень качества веб-системы при нагрузочном тестировании. Нет ничего лучше конкретных примеров целевых показателей нагрузочного тестирования, плохих и хороших:
Как видим, выбор адекватных метрик для оценки скорости работы веб-проекта при нагрузочном тестировании — очень и очень важен. Принцип один — метрики должны быть абсолютно понятны и клиенту и вам и хорошо и ясно показывать качество. По сути, самая наглядная и правильная метрика — это распределение скорости обработки хитов по времени. Если получится такую сделать на вашем нагрузочном тестировании — будет супер. Более того, можно сравнивать 2 нагрузочных тестирования по характеру распределения времени хитов и видеть: как стало лучше и где. Визуализация — сила!
Все просто! Сейчас нарисую и покажу в прекрасной среде для аналза данных: Jupyter notebook/Python.
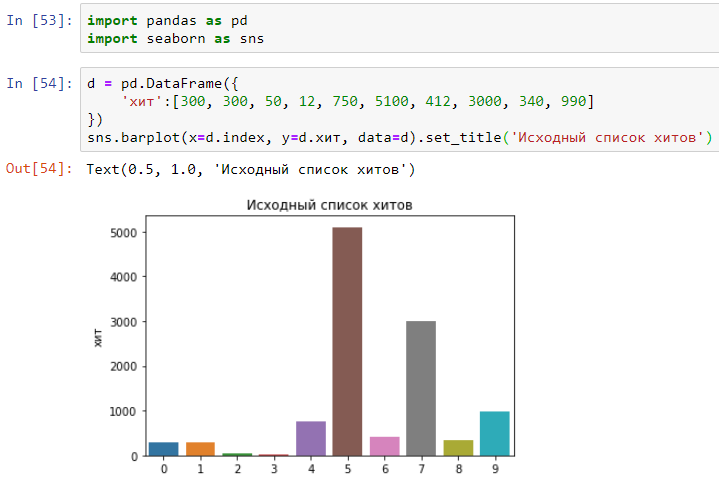
Допустим, на веб-сайт сделали 10 хитов с таким временем в миллисекундах:
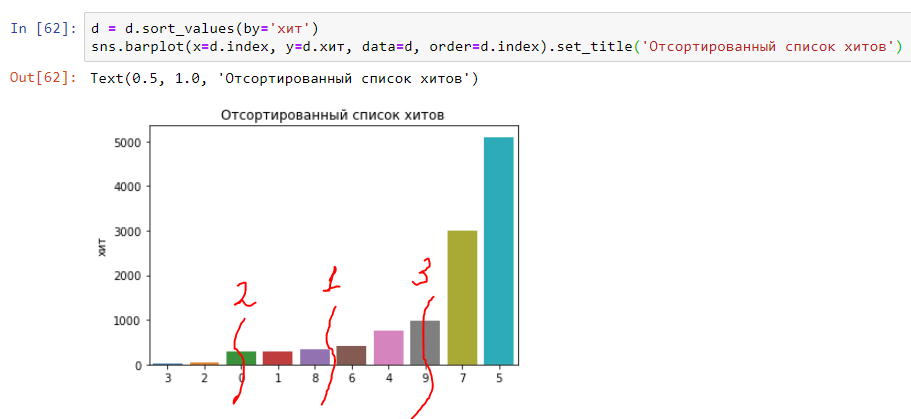
Теперь отсортируем время выполнения хитов по возрастанию:

Мы в шаге от понимания медианы, 25 и 75 перцентелей. Все просто — разделим график пополам и в середине будет «медиана» (цифра 1 на графике). Первая четверть графика будет соответствовать 25 перцентилю (цифра 2 на графике) и третья четверть будет соответствовать 75 перцентилю (цифра 3 на графике). Соответственно получаются и другие перцентили (или, как их еще называют, квантили) — 90, 95, 99 и т.п.:
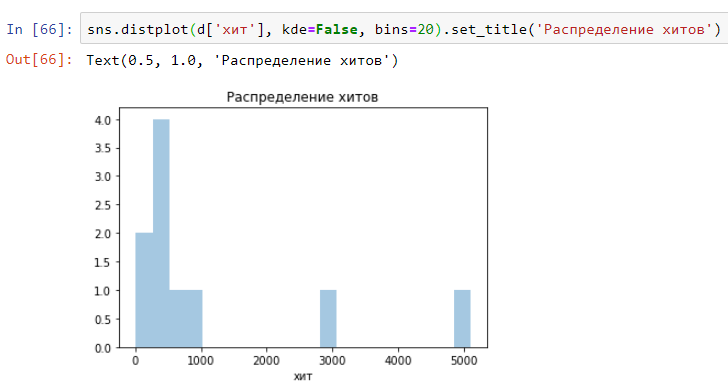
А так будет выглядеть распределение (гистограмма) по времени выполнения указанных выше хитов. Как видим, все очень наглядно и просто:
А вот так можно быстро построить распределение (гистограмму) по логу запросов нагрузочного тестирования. Модифицируйте под свой формат лога:
И получится примерно такая картина:

Надеюсь теперь все стало ясно и на свои места. Если нет, спрашивайте в комментариях.
Часто спрашивают — сколько времени должно продолжаться нагрузочное тестирование веб-проекта? Тут простая эвристика — в операционной системе нередко раз в сутки выполняются запланированные задания: бэкапы, ротация логов и т.п., поэтому время проведения нагрузочного тестирования должно быть не меньше, правильно, суток. Если веб-проект на Битрикс, то в платформе также выполняется немало запланированных в расписание заданий и желательно нагружать веб-систему не меньше суток.
Если уже есть эксплуатируемый веб-сайт, то можно, да, взять логи посещения оттуда и нагружать новую веб-систему, используя их. Но часто решают задачу нагрузки только разрабатываемой веб-системы. Для планирования распределения нагрузки часто хорошо подходит модель разделения предполагаемых цепочек посещения сайта на доли. Например:
В софте для создания нагрузки (мы часто используем Jmeter) для каждой цепочки создается столько нагрузочных потоков, чтобы, учитывая интервал между хитами в цепочке, суммарное число хитов каждой цепочки в единицу времени соотносилось как: 50%, 30%, 15%, 5%.
Расчет интервалов и нагрузочных потоков несложно сделать в Excel или на листике карандашом.
Тут важно учесть особенности жизненного цикла пользователя веб-системы. Часто пользователи авторизуются, а потом ходят по веб-сайту. Для этого в начало нагрузочной цепочки нужно поместить действия, приводящие к авторизации:
Коню ясно, что нельзя при нагрузочном тестировании дергать только одну детальную страницу каталога, поэтому полезно считывать и ротировать их список из CSV-файла:

Между хитами, разумеется, нужно делать случайные паузы — так мы ближе приблизимся к нагрузке, создаваемой реальными пользователями. Не забываем также о сохранении и возвращении на сервер значений cookies:

Глобальные переменные нагрузочных цепочек, в том числе их число потоков, настраиваются просто. Определенные глобальные переменные можно использовать затем в разных местах нагрузочных цепочек:


На практике, почти всегда, нагрузочное тестирование в первые минуты-часы обрушивает веб-систему, все начинает дымиться, затем гореть, сайт не открывается, MySQL падает в своп и не дает к себе подключиться, LA на серверах приближается к 100, разработчики начинают бегать со словами «это не должно было произойти», а сисадмины с ухмылкой обычно отвечают «справедливость в жизни есть!» и начинают пить пиво в серверной.
Но чтобы понять, почему все упало и что чинить, чтобы через сутки показать клиенту результаты «успешного» нагрузочного тестирования, необходимо предварительно включить запись основных метрик жизнедеятельности операционной системы — это легко сделать в бесплатных продуктах класса munun/cacti.
Перечислю, что происходит при коллапсе веб-системы чаще всего и как это можно исправить.
Прежде всего «забивается» запросами веб-сервер apache или php-fpm:

Чаще всего это происходит из-за коллапса MySQL — вырастает число висящих потоков запросов:

Чем это обусловлено? Часто сверху забываютзабивают ограничить число apache или потоков запросов к МySQL, что вызывает выпадение приложений из оперативной памяти в медленный своп с конвульсиями:
Тут видна внезапная активность при работе со свопом, нужно разбираться, кто выпал в своп и откуда:
Однако, иногда проблема оказывается на стороне медленной дисковой подсистемы. В этом случае резко вырастает LA и процент утилизации диска приближается к 100 (правый нижний график):


Очевидно, что я вскрыл только часть самого интересного, что может начаться с веб-проектом при нагрузочном тестировании. Но ведь главное — задать верное направление и выстроить правильный процесс. Спрашивайте в комментариях, что повылазило у вас при нагрузке, постараюсь помочь.
Обычно после 5-10 перезапусков и корректировок, нагрузочное тестирование начинает свой полет и успешно завершается. В результате у вас должен быть набор примерно таких логов для дальнейшего анализа:
Дополнительно, должы быть аналитические графики за прошедшие сутки по использованию CPU, дисков, MySQL, ОЗУ, воркеров apache и т.д. (см. выше примеры графиков munin).
Имея эти артефакты, вы можете, используя простой awk-скрипт в начале поста, построить распределения (гистограммки) по этим логам и посчитать число и типы HTTP-ошибок. По сути, вы можете сформировать очень емкий и полезный для бизнеса и принятия решений отчет об успешности нагрузочного тестирования примерно такого содержания:
Но, скажу честно, если импорт-экспорт сделать аккуратно, по совести, то нагрузочное тестирование и при таких условиях покажет приемлемые для бизнеса цифры.
Кстати да, мы не осветили этот момент. Из банальных причин обычно всплывает отсутствие балансировки между nginx — apache — mysql воркерами. Т.е. воркеры сверху не ограничивают, в результате в apache может подняться сразу 500 воркеров (каждый иногда по 100 МБ) и на MySQL прийдут сразу 500 потоков с запросами — что вызовет всплеск HTTP 50х ошибок и возможный коллапс.
Тут рекомендуется ограничить число apache/php-fpm воркеров до числа, умещающегося в ОЗУ и, аналогично, ограничить число потоков на MySQL, для защиты от переполнения доступной оперативной памяти. Идея проста — пусть клиенты ждут перед nginx, немного может замедляясь на асинхронных и неблокирующих TCP/IP сокетах, чем «ломятся» сразу в apache/MySQL.
Из более неприятных причин тут может быть segfault PHP. В этом случае необходимо включить сбор coredump и с помощью gdb посмотреть, почему это происходит. В большинстве случаев через обновление/конфигурацию PHP проблему удается обойти.
Ходят упорные слухи, что современный фронтэнд для веба так активно зажил своей жизнью, что классическое нагрузочное тестирование бэкэнда, приведенное в данном посте, уже не закрывает всех возможных рисков зависания построения веб-страницы в «потрохах» Angular/React/Vue.js — поэтомуне используйте тяжелый и непрозрачный, плохо тестируемый фронтэнд можно, при необходимости, адаптировать нагрузочные цепочки и к такой ситуации.
В любом случае, если результаты нагрузочного тестирования бэкэнда показали хорошие цифры, а веб-сайт продолжает тормозить в браузере, уже понятно, кого «бить по наглой рыжей морде» :-)
Если серьезно, то в ближайших постах мы надеемся осветить и эту важную тему.
Итого — нет ничего сложного в организации и проведении полезного для разработки и бизнеса нагрузочного тестирования веб-системы.
Нагрузочное тестирование, грамотно организованное, нужно проводить всегда — иначе есть риск нарваться на крупные неприятности при боевой эксплуатации, которые не получится устранить и за несколько суток.
Для проведения нагрузочного тестирования важно привлекать не только разработчиков, но и экспертов по операционным системам и железу — опытных системных администраторов, и тогда проблемы «выпадения в своп» или «переполнения локального диапазона IP-адресов» не вызовут кровотечения из глаз и обмороков.
Удачи, друзья и задавайте вопросы в комментариях!
Продолжаем серию публикаций «без купюр» о проектах, связанных с разработкой, часто с приставкой «веб». Поговорим сегодня о нагрузочном тестировании. Проблема в том, что часто ни клиент, ни руководитель проекта не понимают, зачем оно нужно, какие риски оно позволяет снизить, как его организовать и как, а это самое, думаю, сложное, интерпретировать его результаты с пользой для бизнеса. Наливаем кофе и поехали…
Зачем нужно нагрузочное тестирование веб-проекта?
Дело в том, что если для удержания качества в некоторых веб-проектах еще пишут автотесты, то контролем производительности на стадии разработки мало кто занимается в принципе. Увидеть веб-проект и с автотестами и с бенчмарками кода — большая редкость. Гораздо чаще и по разумным причинам при разработке придерживаются следующих эвристик, обладающих хорошим соотношением польза-стоимость:
- запросы к MySQL (дальше будем приводить в пример эту популярную базу данных) идут через достаточно адекватное API, использующее индексы (хотя как именно используются индексы планировщиком, какова их кардинальность, мы не видим)
- результаты выполнения запросов к БД и тяжелых кусков кода — кэшируются
- разработчик 3.14 раза проверил построение веб-страницы в браузере и если на «глаз» не тормозит, то все ОК
Эвристики часто работают хорошо, но чем больше и нагруженнее проект, тем что-то может пойти не так с экспоненциально возрастающей вероятностью.
Возьмем кеширование. При разработке часто некогда задумываться над тем, как часто кэш может перестраиваться. А зря. Если перестройка кэша, скажем, каталога товаров, занимает длительное время и кэш сбрасывается при добавлении одного товара, то от кэширования будет больше вреда, чем пользы.
Именно поэтому, кстати, не рекомендуется использовать встроенный кэш запросов MySQL, страдающий от похожей проблемы: при изменении хотя бы одной записи таблицы кэш таблицы полностью сбрасывается (представим таблицу из 100к строк и абсурдность ситуации становится очевидна).
Аналогичная ситуация с запросами к MySQL. Если запросы выполняются по индексам, то, в общем случае, запросы будут выполняться… «быстрее». Можно верить, что время выполнения таких запросов логарифмически зависит от объема данных (O(log(n))). Но на практике часто оказывается, что одни запросы влияют на другие, используя одновременно общие подсистемы БД (сортировка на диске, который начинает тормозить) и сразу предвидеть это — нельзя.
Также часто при нагрузке выявляются любопытные особенности операционной системы, в частности, переполнение диапазона исходящих клиентских портов TCP/IP, при интенсивной работе с memcached. Или apache забивается запросами на обработку картинок, т.к. при конфигурации забыли настроить их обработку кэширующим прокси-сервером nginx.
Иногда забывают установить в MySQL путь для временных таблиц на диск, отображающий данные в оперативную память ("/dev/shm"), из-за чего при возрастании нагрузки сервер БД ложится от интенсивных сортировок.
Также, при добавлении в веб-проект данных, в объеме, приближенном к боевому, запросы и алгоритмы начинают агрессивно проявлять свою «О-нотацию»: если cartesian для небольшого объема данных незаметен, то при появлении боевого объема сервер БД от напряжения становится красным.
Примеров можно привести еще массу, остановимся пока на этом. Главное понять, что нагрузочное тестирование — необходимо. Потому что заранее предусмотреть все возможные варианты «торможения» веб-системы среднего размера очень дорого, очень долго и экономически нецелесообразно.
Как определить целевые показатели нагрузочного тестирования?
Тут важно понять, что на самом деле покажет и вам и клиенту уровень качества веб-системы при нагрузочном тестировании. Нет ничего лучше конкретных примеров целевых показателей нагрузочного тестирования, плохих и хороших:
- Сделан 1 млн. хитов. Среднее время построения веб-страницы = 1 сек. Что это показывает? Да ничего. Сколько длилось нагрузочное тестирование? Время выполнения отдельного запроса может быть как 1 мс, так и 600 секунд и непонятно, в каких пропорциях чего больше. И сколько было ошибок при этом (ответ nginx в стиле «Ошибка 50х») — тоже непонятно :-)
- Сделан 1 млн. хитов. Медиана времени построения веб-страницы = 1 сек, число HTTP-ошибок — 0.5% Что это показывает? Пока еще немного полезного, но уже получше. Долю неадекватных ошибок, которое может словить клиент, мы уже знаем, что прекрасно и можно начать готовиться и сходить в аптеку. Медиана — более устойчивая к «выбросам» метрика, чем среднее (более «робастная» оценка), поэтому она, несомненно, лучше средней арифметической. Но давайте сделаем метрики еще полезнее.
- За сутки сделан 1 млн. хитов. 25% хитов сделаны менее, чем за 10 мс, 50% хитов сделаны менее, чем за 1 сек (это и есть медиана или 50 процентиль), 75% хитов сделаны менее, чем за 1.5 сек, 95% хитов сделаны менее, чем за 5 сек и число HTTP-ошибок — 0.5% Самое то! Долю неадекватных ошибок, которое может словить клиент, мы видим, но также мы видим доли запросов, которые выполняются более определенного порога.
Как видим, выбор адекватных метрик для оценки скорости работы веб-проекта при нагрузочном тестировании — очень и очень важен. Принцип один — метрики должны быть абсолютно понятны и клиенту и вам и хорошо и ясно показывать качество. По сути, самая наглядная и правильная метрика — это распределение скорости обработки хитов по времени. Если получится такую сделать на вашем нагрузочном тестировании — будет супер. Более того, можно сравнивать 2 нагрузочных тестирования по характеру распределения времени хитов и видеть: как стало лучше и где. Визуализация — сила!
Ничего не понятно: перцентили, медианы, квантили, чертили, распределение ...
Все просто! Сейчас нарисую и покажу в прекрасной среде для аналза данных: Jupyter notebook/Python.
Допустим, на веб-сайт сделали 10 хитов с таким временем в миллисекундах:
Теперь отсортируем время выполнения хитов по возрастанию:
Мы в шаге от понимания медианы, 25 и 75 перцентелей. Все просто — разделим график пополам и в середине будет «медиана» (цифра 1 на графике). Первая четверть графика будет соответствовать 25 перцентилю (цифра 2 на графике) и третья четверть будет соответствовать 75 перцентилю (цифра 3 на графике). Соответственно получаются и другие перцентили (или, как их еще называют, квантили) — 90, 95, 99 и т.п.:
А так будет выглядеть распределение (гистограмма) по времени выполнения указанных выше хитов. Как видим, все очень наглядно и просто:
А вот так можно быстро построить распределение (гистограмму) по логу запросов нагрузочного тестирования. Модифицируйте под свой формат лога:
#!/bin/bash
TOTAL=`cat /var/log/nginx.access.log | wc -l`
echo "Total:" $TOTAL
cat /var/log/nginx.access.log | awk -F'->' '{ $2=$2*1000; zone = int($2/100)*100; hits[zone]++; } \
END {for (z in hits) {printf("%8s ms: %8s,%6.2f% ",z,hits[z],hits[z]/total*100);{s="";a=0;while(a++<int(hits[z]/total*100)) s=s"*";print s} } }' \
total="$TOTAL" - | sort -n
И получится примерно такая картина:
Надеюсь теперь все стало ясно и на свои места. Если нет, спрашивайте в комментариях.
Время проведения нагрузочного тестирования
Часто спрашивают — сколько времени должно продолжаться нагрузочное тестирование веб-проекта? Тут простая эвристика — в операционной системе нередко раз в сутки выполняются запланированные задания: бэкапы, ротация логов и т.п., поэтому время проведения нагрузочного тестирования должно быть не меньше, правильно, суток. Если веб-проект на Битрикс, то в платформе также выполняется немало запланированных в расписание заданий и желательно нагружать веб-систему не меньше суток.
Планирование распределения нагрузки
Если уже есть эксплуатируемый веб-сайт, то можно, да, взять логи посещения оттуда и нагружать новую веб-систему, используя их. Но часто решают задачу нагрузки только разрабатываемой веб-системы. Для планирования распределения нагрузки часто хорошо подходит модель разделения предполагаемых цепочек посещения сайта на доли. Например:
- Главная — Новости — Детальная новости = 50%
- Главная — Обзор каталога — Детальная каталога = 30%
- Детальная каталога — Обзор каталога — Детальная каталога = 15%
- Результаты поиска — Детальная каталога = 5%
В софте для создания нагрузки (мы часто используем Jmeter) для каждой цепочки создается столько нагрузочных потоков, чтобы, учитывая интервал между хитами в цепочке, суммарное число хитов каждой цепочки в единицу времени соотносилось как: 50%, 30%, 15%, 5%.
Расчет интервалов и нагрузочных потоков несложно сделать в Excel или на листике карандашом.
Структура нагрузочной цепочки
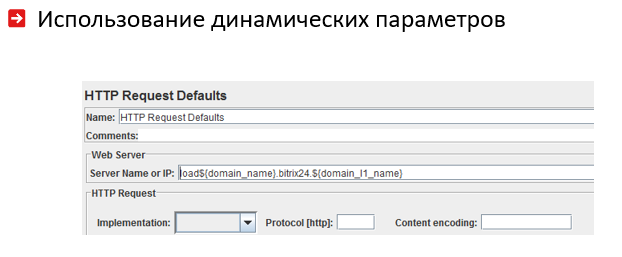
Тут важно учесть особенности жизненного цикла пользователя веб-системы. Часто пользователи авторизуются, а потом ходят по веб-сайту. Для этого в начало нагрузочной цепочки нужно поместить действия, приводящие к авторизации:
Коню ясно, что нельзя при нагрузочном тестировании дергать только одну детальную страницу каталога, поэтому полезно считывать и ротировать их список из CSV-файла:
Между хитами, разумеется, нужно делать случайные паузы — так мы ближе приблизимся к нагрузке, создаваемой реальными пользователями. Не забываем также о сохранении и возвращении на сервер значений cookies:
Глобальные переменные нагрузочных цепочек, в том числе их число потоков, настраиваются просто. Определенные глобальные переменные можно использовать затем в разных местах нагрузочных цепочек:
Как сделать так, чтобы нагрузочное тестирование благополучно закончилось?
На практике, почти всегда, нагрузочное тестирование в первые минуты-часы обрушивает веб-систему, все начинает дымиться, затем гореть, сайт не открывается, MySQL падает в своп и не дает к себе подключиться, LA на серверах приближается к 100, разработчики начинают бегать со словами «это не должно было произойти», а сисадмины с ухмылкой обычно отвечают «справедливость в жизни есть!» и начинают пить пиво в серверной.
Но чтобы понять, почему все упало и что чинить, чтобы через сутки показать клиенту результаты «успешного» нагрузочного тестирования, необходимо предварительно включить запись основных метрик жизнедеятельности операционной системы — это легко сделать в бесплатных продуктах класса munun/cacti.
Перечислю, что происходит при коллапсе веб-системы чаще всего и как это можно исправить.
Прежде всего «забивается» запросами веб-сервер apache или php-fpm:
Чаще всего это происходит из-за коллапса MySQL — вырастает число висящих потоков запросов:
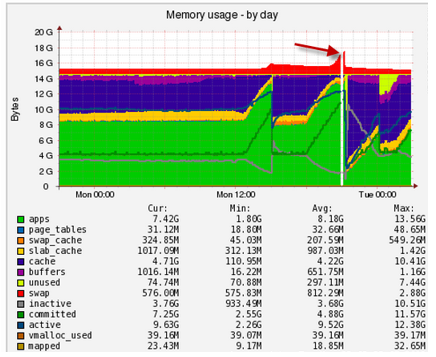
Чем это обусловлено? Часто сверху забывают
Тут видна внезапная активность при работе со свопом, нужно разбираться, кто выпал в своп и откуда:
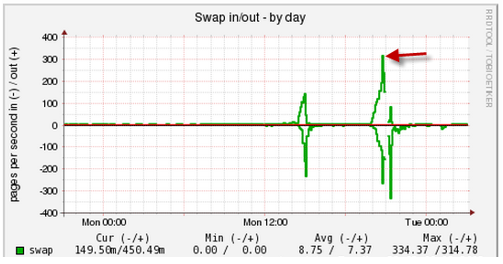
Однако, иногда проблема оказывается на стороне медленной дисковой подсистемы. В этом случае резко вырастает LA и процент утилизации диска приближается к 100 (правый нижний график):
Очевидно, что я вскрыл только часть самого интересного, что может начаться с веб-проектом при нагрузочном тестировании. Но ведь главное — задать верное направление и выстроить правильный процесс. Спрашивайте в комментариях, что повылазило у вас при нагрузке, постараюсь помочь.
Интерпретация результатов нагрузочного тестирования
Обычно после 5-10 перезапусков и корректировок, нагрузочное тестирование начинает свой полет и успешно завершается. В результате у вас должен быть набор примерно таких логов для дальнейшего анализа:
- лог запросов к nginx с временем запроса клиента (в данном случае это будет нагрузочный софт), временем проксирования от nginx к apache/php-fpm
- лог ошибок nginx
- лог запросов apache/php-fpm с временем обработки запроса и статусом HTTP-ответа
- лог ошибок apache/php-fpm
- лог медленных запросов MySQL
- лог ошибок MySQL
Дополнительно, должы быть аналитические графики за прошедшие сутки по использованию CPU, дисков, MySQL, ОЗУ, воркеров apache и т.д. (см. выше примеры графиков munin).
Имея эти артефакты, вы можете, используя простой awk-скрипт в начале поста, построить распределения (гистограммки) по этим логам и посчитать число и типы HTTP-ошибок. По сути, вы можете сформировать очень емкий и полезный для бизнеса и принятия решений отчет об успешности нагрузочного тестирования примерно такого содержания:
В течение суток сделан 1 млн. хитов. 25% хитов сделаны менее, чем за 50 мс, 50% хитов сделаны менее, чем за 0.5 сек (медиана), 75% хитов сделаны менее, чем за 1 сек, 95% хитов сделаны менее, чем за 5 сек, число ошибок HTTP — 0.01%. Тестовые данные: каталог, пользователи, новости, статьи были залиты в объеме, приближенном к ожидаемому.Это уже хороший и понятный отчет о нагрузочном тестировании веб-системы. Для любителей острой боли еще можно рекомендовать при нагрузочном тестировании включить ежеминутный импорт-экспорт данных на веб-сайт из систем класса SAP, 1C и т.п. и синхронные соединения по TCP/IP сокетам с внешними сервисами курсов, скажем, криптовалют :-)Один разработчик — застрелился.
Нагрузочные цепочки:
Главная — Новости — Детальная новости = 50%
Главная — Обзор каталога — Детальная каталога = 30%
Детальная каталога — Обзор каталога — Детальная каталога = 15%
Результаты поиска — Детальная каталога = 5%
Графики использования ресурсов серверов:
…
Но, скажу честно, если импорт-экспорт сделать аккуратно, по совести, то нагрузочное тестирование и при таких условиях покажет приемлемые для бизнеса цифры.
Откуда берутся ошибки при нагрузочном тестировании?
Кстати да, мы не осветили этот момент. Из банальных причин обычно всплывает отсутствие балансировки между nginx — apache — mysql воркерами. Т.е. воркеры сверху не ограничивают, в результате в apache может подняться сразу 500 воркеров (каждый иногда по 100 МБ) и на MySQL прийдут сразу 500 потоков с запросами — что вызовет всплеск HTTP 50х ошибок и возможный коллапс.
Тут рекомендуется ограничить число apache/php-fpm воркеров до числа, умещающегося в ОЗУ и, аналогично, ограничить число потоков на MySQL, для защиты от переполнения доступной оперативной памяти. Идея проста — пусть клиенты ждут перед nginx, немного может замедляясь на асинхронных и неблокирующих TCP/IP сокетах, чем «ломятся» сразу в apache/MySQL.
Из более неприятных причин тут может быть segfault PHP. В этом случае необходимо включить сбор coredump и с помощью gdb посмотреть, почему это происходит. В большинстве случаев через обновление/конфигурацию PHP проблему удается обойти.
Что осталось за кадром
Ходят упорные слухи, что современный фронтэнд для веба так активно зажил своей жизнью, что классическое нагрузочное тестирование бэкэнда, приведенное в данном посте, уже не закрывает всех возможных рисков зависания построения веб-страницы в «потрохах» Angular/React/Vue.js — поэтому
В любом случае, если результаты нагрузочного тестирования бэкэнда показали хорошие цифры, а веб-сайт продолжает тормозить в браузере, уже понятно, кого «бить по наглой рыжей морде» :-)
Если серьезно, то в ближайших постах мы надеемся осветить и эту важную тему.
Итоги и выводы
Итого — нет ничего сложного в организации и проведении полезного для разработки и бизнеса нагрузочного тестирования веб-системы.
Нагрузочное тестирование, грамотно организованное, нужно проводить всегда — иначе есть риск нарваться на крупные неприятности при боевой эксплуатации, которые не получится устранить и за несколько суток.
Для проведения нагрузочного тестирования важно привлекать не только разработчиков, но и экспертов по операционным системам и железу — опытных системных администраторов, и тогда проблемы «выпадения в своп» или «переполнения локального диапазона IP-адресов» не вызовут кровотечения из глаз и обмороков.
Удачи, друзья и задавайте вопросы в комментариях!



