
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
3D-рендеринг сцены из нескольких фотографий, определение глубины и освещения по фото, нейронный дизайнер интерьеров, генерация звука по видео и многое другое в октябрьской подборке.
Inverse Rendering 3D Lighting
Доступность: страница проекта / статья
Большинство существующих методов представления помещений по фотографиям игнорируют трехмерные свойства сцены. А для убедительного переноса света двухмерного представления недостаточно. Исследователи из Nvidia представили унифицированный метод обратного рендеринга, который формулирует трехмерное пространственно-изменяющееся освещение. Модель понимает, какое освещение в фотографии, и позволяет добавить в сцену 3D-объект, который правдоподобно отражает свет и отбрасывает тени.

ATISS
Доступность: страница проекта / статья
NVIDIA представили новую архитектуру авторегрессионного трансформатора для генерации сцены по типу помещения и плану этажа. Особенность модели в том, что она генерирует комнаты сразу в виде наборов объектов. Модель автоматически расставляет мебель с учетом функционального назначения и ограничений. Также можно указать место и габариты, а модель подскажет, какой предмет мебели подойдет.

GANcraft
Доступность: страница проекта / статья / репозиторий
Еще одна модель от NVIDIA для рендеринга фотореалистичных изображений из трехмерных блочных сцен как в игре Minecraft. В качестве входных данных принимаются блоки, которым присваиваются семантические обозначения (грязь, трава, дерево), после чего рендерятся фотореалистичные отображения сцены.

3DETR
Доступность: публикация в блоге / статья / репозиторий
Новая модель от FAIR принимает на вход трехмерную сцену, представленную в виде облака точек или набора координат, и создает трехмерные баундинг боксы для объектов в сцене. Кодировщик Transformer создает представление координат расположения и формы объекта посредством серии операций самовнимания, чтобы уловить глобальный и локальный контексты, необходимые для распознавания. Например, он может определять ножки и спинки стульев, расположенных вокруг круглого стола. Кодировщик автоматически фиксирует эти важные геометрические свойства. Такой подход поможет быстрее размечать 3D-датасеты.

ADOP
Доступность: статья / репозиторий
Новый точечный дифференцируемый пайплайн рендеринга сцен: на вход модели подаются фотографии какого-то места с разных точек обзора, а на выходе генерируется полноценная трехмерная сцена, по которой можно передвигаться с помощью камеры.

LaMa
Доступность: онлайн-демо / страница проекта / статья / репозиторий / колаб
Новая архитектура для инпейтинга, которая благодаря свертке Фурье, учитывая контекст всего изображения, а также использует большие тренировочные маски, что позволяет качественно удалять с изображений сложные объекты, даже при высоком разрешении.

Pose with Style
Доступность: страница проекта
Модель позволяет одновременно отрисовывать целевую персону в новых заданных позах и в другой одежде по одному изображению. На вход подается фотография человека, после чего связка алгоритмов, включающая StyleGAN и DensePose, преобразовывает исходное изображение и генерирует скрытые из виду области.
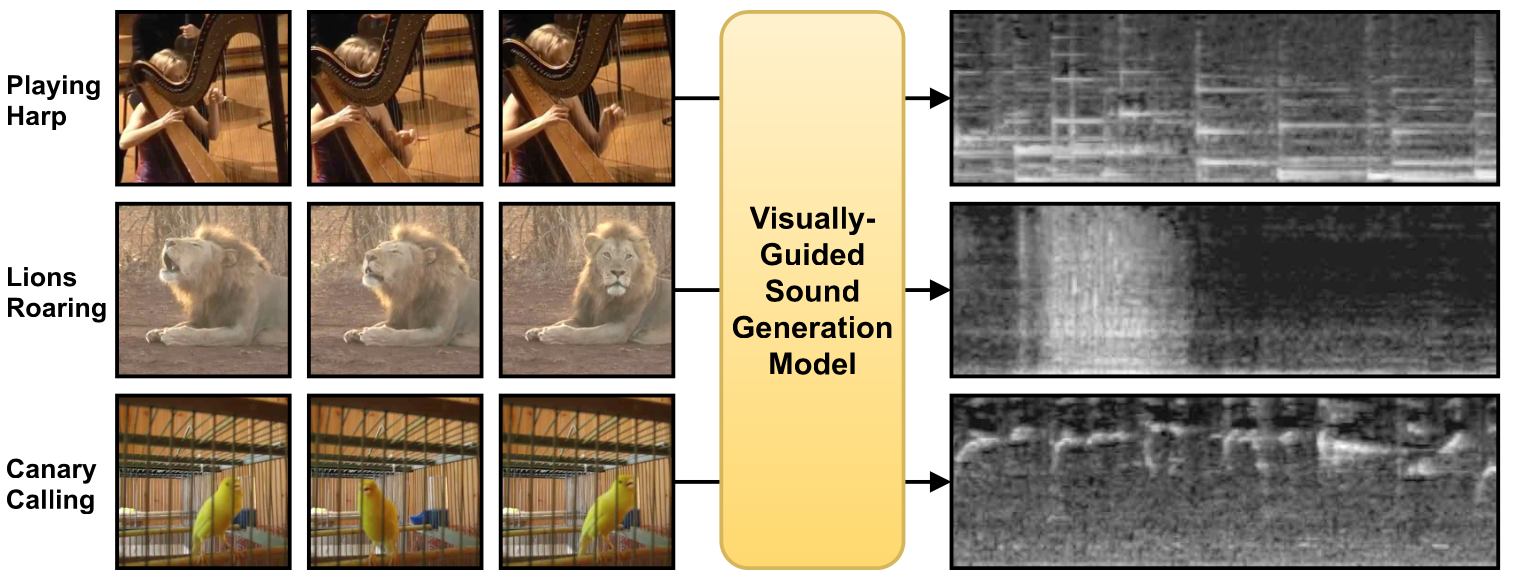
SpecVQGAN
Доступность: страница проекта / статья / репозиторий / колаб
Модель анализирует видео на входе и синтезирует подходящий звук. В отличие от других похожих моделей, она справляется с генерацией звуков продолжительностью более 10 секунд. Такое решение в перспективе поможет звукорежиссерам тратить меньше времени на поиск подходящих звуков для видео.
Keypoint Communities
Доступность: онлайн демо / статья / репозиторий
Модель обнаруживает координаты 133 ключевых точек на людях или объектах для выявления позы человека, расположения рук и пальцев, а также эмоций по мимическим морщинам на лице. Примечательно, что этот метод также позволяет определять расположение автомобилей.

HeadGAN
Доступность: страница проекта / статья
Метод HeadGAN выполняет one-shot реконструкцию лица (то есть, по данным, не участвовавшим в обучении), полностью передавая выражение лица и позу головы из движущегося кадра в целевое изображение. Кроме того, модель можно применять для редактирования с помощью графического редактора.

Layered Neural Atlases
Доступность: сайт проекта / статья / репозиторий
Нейросеть преобразует видео в набор многослойных двухмерных атласов, где каждому пикселю присваивается координата, что дает согласованную параметризацию всего видео вместе с соответствующим значением альфа. Получаются интерпретируемые атласы, что облегчает редактирование. Изменения, применяемые к одному видеокадру, автоматически и последовательно сопоставляются с исходными видеокадрами с сохранением окклюзии, деформации и других сложных эффектов сцены, таких как тени и отражения.

HandAR
Доступность: статья / репозиторий
Новый метод, реконструкция кистей рук по RGB изображению через три этапа: предсказания положения суставов кисти; предсказание грубой сетки кисти; совмещение грубой сетки и отступа сетки. Благодаря этому модель работает в режиме реального времени с высокой точностью.

В октябре стали доступны:
исходный код нейросети Alias-Free GAN от NVIDIA из июньской подборки. Оказалось, что это StyleGAN3;
веб-интерфейс для STyleGanNada из августовского выпуска;



