
Недавно исследователи из GoogleAI показали свой поход к задаче трекинга руки и определения жестов в реальном времени. Я как раз занимался подобной задачей и потому решил разобраться с тем как они подошли к решению, какие технологии они использовали, и как добились хорошей точности при риал тайм работе на мобильном устройстве. Также запустил модель на android и протестировал в реальных условиях.
Распознавание рук является достаточно нетривиальной задачей, которая в то же время широко востребована. Эту технологию можно использовать в приложениях дополнительной реальности для взаимодействия с виртуальными объектами. Также это может быть основой для понимания языка жестов или для создания интерфейсов управления с помощью жестов

Естественное восприятие рук в реальном времени является реальным вызовом для компьютерного зрения, руки часто перекрывают себя или друг друга (перекрещивание пальцев или рукопожатие). В то время как лица имеют высококонтрастные узоры, например, в области глаз и рта, отсутствие таких признаков в руках затрудняет надежное обнаружение только по их визуальным признакам.
Руки постоянно находятся в движение, меняют углы наклона и перекрывают друг друга. Для приемлемого пользовательского опыта нужно чтобы распознавание работало с высоким FPS(25+). К тому же все это должно работать на мобильных устройствах, что добавляет к требованиям по скорости, также ограничения по ресурсам.
Они реализовали технологию точного отслеживания рук и пальцев с помощью машинного обучения (ML). Программа определяет 21 ключевую точку руки в 3D пространстве (высоту, длину и глубину) и на основание этих данных классифицирует жесты которые показывает рука. Все это на основание всего одного фрейма видео, работает в реальном времени на мобильных устройствах и масштабируется на несколько рук.
Подход реализован с помощью MediaPipe - кроссплатформенный фреймворк с открытым кодом для построения пайплайнов обработки данных (видео, аудио, временные ряды). Что-то наподобие Deepstream от Nvidia, только с кучей фичей и кроссплатформенностью.
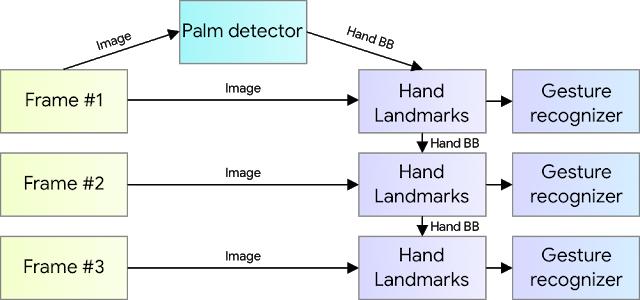
Решение состоит из 3 основных моделей работающих вместe:
Детектор ладони (BlazePalm)
Модель для определения ключевых точек на руке
Алгоритм распознавания жестов
Архитектура похожая на ту, которую используют при задаче pose estimation. Предоставляя точно обрезанное и выровненное изображение руки, значительно уменьшается потребность в аугментации данных (повороты, трансляции и масштабирование) и вместо этого модель может сконцентрироваться на точности предсказания координат.
Для нахождения ладони используется модель называемая BlazePalm - single shot detector (SSD) модель оптимизированная под работу на мобильном устройстве в реальном времени.
В исследование GoogleAI натренировали детектор ладони вместо детектора всей руки (palm - основа ладони без пальцев). Преимущество такого подхода в том, что распознать ладонь или кулак проще чем руку всю руку с жестикулирующими пальцами, к тому же ладонь может быть выделена используя квадратные bounding boxes (анкоры) игнорируя соотношения сторон, и таким образом сокращая количество требуемых анкоров в 3–5 раза
Также использовался экстрактор фич Feature Pyramid Networks for Object Detection (FPN) для лучшего понимания контекста изображения даже для небольших объектов
В качестве loss функции был взят focal loss который хорошо справляется с дисбалансом классов возникающего при генерации большого количества анкоров.
Классическая кросс-энтропия: CE(pt) = -log(pt )
Фокал лосс: FL(pt) =-(1-pt) log(pt)
Подробнее про Focall loss можно почитать в отличном пейпере от Facebook AI Research (рекомендовано к прочтению)
Используя вышеперечисленные техники было достигнуто средней точности (Average Precision) 95.7%. При использовании простой кросс-энтропии и без FPN - 86.22%.
После того как детектор ладони определил на всем изображение позицию ладони, регион сдвигается на определенный коэффициент вверх и расширяется, чтобы охватить всю руку. Дальше на обрезанном изображение решается задача регрессии - определяется точное положение 21 точки в 3D пространстве.
Для тренировки было вручную размечено 30 000 реальных изображений. Также была сделана реалистичная 3D модель руки с помощью которой сгенерировали еще искусственных примеров на разных фонах.

Вверху: реальные изображения рук с размеченными ключевыми точками. Внизу: искусственные изображения руки сделанные с помощью 3D модели
Для распознавания жестов был использован простой алгоритм, который по ключевым точкам руки определяет состояние каждого пальца (например изогнутый или прямой). Затем все эти состояния сопоставляются с имеющимся набором жестов. Этот простой, но эффективный метод позволяет распознавать базовые жесты с неплохим качеством.
Основной секрет быстрого инференса в реальном времени скрывается в одной важной оптимизации. Детектор ладони, который занимает больше всего времени, запускается только при необходимости (довольно редко). Это достигается путем вычисления положения руки на следующем кадре базируясь на предыдущих ключевых точках руки.
Для устойчивости такого подхода к модели определения ключевых точек добавили еще один выход - скаляр, который показывает насколько модель уверена в том, что на обрезанном изображение присутствует рука и что она правильно развернута. Когда значение уверенности падает ниже определенного порога - запускается детектор ладони и применяется ко всему кадру.
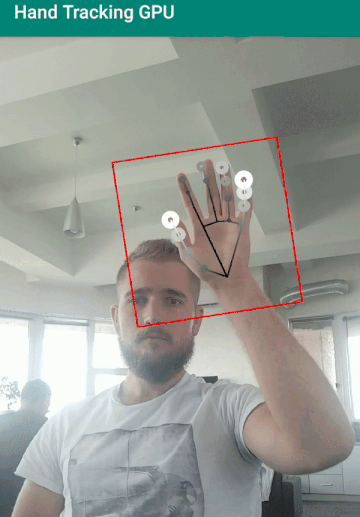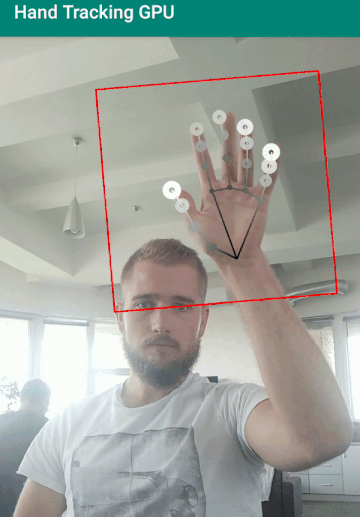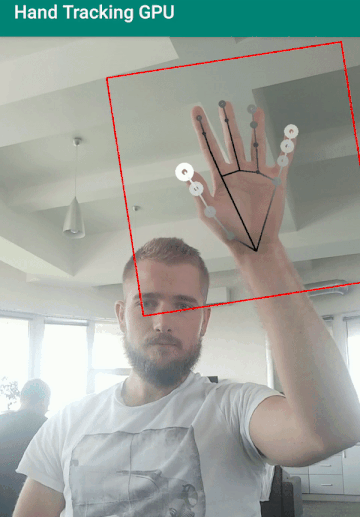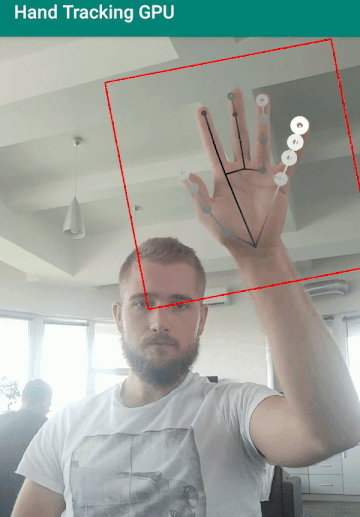
Я запустил это решение на android девайсе (Xiaomi Redmi Note 5) для теста в реальных условиях. Модель ведет себя хорошо, правильно мапит скелет руки и высчитывает глубину при приличном количестве кадров в секунду.

Из минусов можно отметить то как начинает проседать точность и скорость при постоянном движение руки по фрейму. Это вызвано тем, что модели постоянно приходится перезапускать детектор, так как она теряет положение руки при движении. Если вам больше важна скорость нахождения двигающейся руки чем определение жестов - вам стоит поискать другие подходы.

Также случаются некоторые проблемы когда рука пересекается с лицом или подобными сложными фонами. В остальном отличная работа от GoogleAI, это большой вклад в будущее развитие технологии.
Статья на GoogleAI Blog
Github mediapipe Hand Tracking
Почему это важно?
Распознавание рук является достаточно нетривиальной задачей, которая в то же время широко востребована. Эту технологию можно использовать в приложениях дополнительной реальности для взаимодействия с виртуальными объектами. Также это может быть основой для понимания языка жестов или для создания интерфейсов управления с помощью жестов
В чем сложность?
Естественное восприятие рук в реальном времени является реальным вызовом для компьютерного зрения, руки часто перекрывают себя или друг друга (перекрещивание пальцев или рукопожатие). В то время как лица имеют высококонтрастные узоры, например, в области глаз и рта, отсутствие таких признаков в руках затрудняет надежное обнаружение только по их визуальным признакам.
Руки постоянно находятся в движение, меняют углы наклона и перекрывают друг друга. Для приемлемого пользовательского опыта нужно чтобы распознавание работало с высоким FPS(25+). К тому же все это должно работать на мобильных устройствах, что добавляет к требованиям по скорости, также ограничения по ресурсам.
Что сделали в GoogleAI?
Они реализовали технологию точного отслеживания рук и пальцев с помощью машинного обучения (ML). Программа определяет 21 ключевую точку руки в 3D пространстве (высоту, длину и глубину) и на основание этих данных классифицирует жесты которые показывает рука. Все это на основание всего одного фрейма видео, работает в реальном времени на мобильных устройствах и масштабируется на несколько рук.
Как они это сделали?
Подход реализован с помощью MediaPipe - кроссплатформенный фреймворк с открытым кодом для построения пайплайнов обработки данных (видео, аудио, временные ряды). Что-то наподобие Deepstream от Nvidia, только с кучей фичей и кроссплатформенностью.
Решение состоит из 3 основных моделей работающих вместe:
Детектор ладони (BlazePalm)
- принимает полное изображение из видео
- возвращает ориентированный bounding box (ограничивающая рамка)
Модель для определения ключевых точек на руке
- принимает обрезанную картинку руки
- возвращает 21 ключевую точку руки в 3D пространстве + показатель уверенности (подробнее далее в статье)
Алгоритм распознавания жестов
- принимает ключевые точки руки
- возвращает название жеста который показывает рука
Архитектура похожая на ту, которую используют при задаче pose estimation. Предоставляя точно обрезанное и выровненное изображение руки, значительно уменьшается потребность в аугментации данных (повороты, трансляции и масштабирование) и вместо этого модель может сконцентрироваться на точности предсказания координат.
Детектор ладони
Для нахождения ладони используется модель называемая BlazePalm - single shot detector (SSD) модель оптимизированная под работу на мобильном устройстве в реальном времени.
В исследование GoogleAI натренировали детектор ладони вместо детектора всей руки (palm - основа ладони без пальцев). Преимущество такого подхода в том, что распознать ладонь или кулак проще чем руку всю руку с жестикулирующими пальцами, к тому же ладонь может быть выделена используя квадратные bounding boxes (анкоры) игнорируя соотношения сторон, и таким образом сокращая количество требуемых анкоров в 3–5 раза
Также использовался экстрактор фич Feature Pyramid Networks for Object Detection (FPN) для лучшего понимания контекста изображения даже для небольших объектов
В качестве loss функции был взят focal loss который хорошо справляется с дисбалансом классов возникающего при генерации большого количества анкоров.
Классическая кросс-энтропия: CE(pt) = -log(pt )
Фокал лосс: FL(pt) =-(1-pt) log(pt)
Подробнее про Focall loss можно почитать в отличном пейпере от Facebook AI Research (рекомендовано к прочтению)
Используя вышеперечисленные техники было достигнуто средней точности (Average Precision) 95.7%. При использовании простой кросс-энтропии и без FPN - 86.22%.
Определение ключевых точек
После того как детектор ладони определил на всем изображение позицию ладони, регион сдвигается на определенный коэффициент вверх и расширяется, чтобы охватить всю руку. Дальше на обрезанном изображение решается задача регрессии - определяется точное положение 21 точки в 3D пространстве.
Для тренировки было вручную размечено 30 000 реальных изображений. Также была сделана реалистичная 3D модель руки с помощью которой сгенерировали еще искусственных примеров на разных фонах.
Вверху: реальные изображения рук с размеченными ключевыми точками. Внизу: искусственные изображения руки сделанные с помощью 3D модели
Распознавание жестов
Для распознавания жестов был использован простой алгоритм, который по ключевым точкам руки определяет состояние каждого пальца (например изогнутый или прямой). Затем все эти состояния сопоставляются с имеющимся набором жестов. Этот простой, но эффективный метод позволяет распознавать базовые жесты с неплохим качеством.
Оптимизации
Основной секрет быстрого инференса в реальном времени скрывается в одной важной оптимизации. Детектор ладони, который занимает больше всего времени, запускается только при необходимости (довольно редко). Это достигается путем вычисления положения руки на следующем кадре базируясь на предыдущих ключевых точках руки.
Для устойчивости такого подхода к модели определения ключевых точек добавили еще один выход - скаляр, который показывает насколько модель уверена в том, что на обрезанном изображение присутствует рука и что она правильно развернута. Когда значение уверенности падает ниже определенного порога - запускается детектор ладони и применяется ко всему кадру.
Тест в реальных условиях
Я запустил это решение на android девайсе (Xiaomi Redmi Note 5) для теста в реальных условиях. Модель ведет себя хорошо, правильно мапит скелет руки и высчитывает глубину при приличном количестве кадров в секунду.
Из минусов можно отметить то как начинает проседать точность и скорость при постоянном движение руки по фрейму. Это вызвано тем, что модели постоянно приходится перезапускать детектор, так как она теряет положение руки при движении. Если вам больше важна скорость нахождения двигающейся руки чем определение жестов - вам стоит поискать другие подходы.
Также случаются некоторые проблемы когда рука пересекается с лицом или подобными сложными фонами. В остальном отличная работа от GoogleAI, это большой вклад в будущее развитие технологии.
Статья на GoogleAI Blog
Github mediapipe Hand Tracking



