
Сегодня мы хотим поделиться нашими компетенциями и знаниями в области машинного обучения в графике и показать, как технологии позволяют упростить многие процессы, при этом не заменяя, а дополняя деятельность человека.
Эта статья будет интересна разработчикам, дизайнерам и всем, кто интересуется новыми разработками в сфере ИИ и ML (предыдущую часть читайте на Medium).

Заметка от партнера IT-центра МАИ и организатора магистерской программы “VR/AR & AI” — компании PHYGITALISM.
Почему именно ML в графике?
Все больше людей говорит о замене человеческого труда искусственным интеллектом (AI – Artificial Intelligence) и о всеобъемлющей оптимизации процессов, и как результат создается ложное представление о роли моделей ИИ в нашей жизни (часто негативное). Однако, машинное обучение и нейронные сети могут быть отдельным инструментом, который помогает человеку, а не замещает его. Эта концепция IA (Intelligence Amplification) предполагает, что технологии помогают нам по-новому посмотреть на привычные рутинные задачи, найти новые креативные подходы и генерировать идеи.

Наиболее ярко этот подход отражается в работе с графикой. Нейронные сети упрощают сложные задачи, в которых специалистам приходится работать с 2D и 3D-данными, и уже сейчас можно за считанные минуты создавать совершенно новые концепты, изменять лицо человека на фотографии и переносить предмет напрямую в 3D-движок по фотографии.
В этой статье мы хотели бы поделиться нашими знаниями и компетенциями в области использования нейронных сетей в графике, а также дать рекомендации по их использованию каждому человеку, не только дизайнерам и 3D-специалистам.

Говоря о задачах, которые нейронные алгоритмы позволяют решать в работе с графикой, их можно поделить на несколько групп: работа с изображениями и видео, 2D-to-3D и работа с 3D-данными.
Мы также собрали все нейронные сети и инструменты, о которых говорили в статьях, в одной табличке:

Ознакомиться с таблицей вы можете здесь: https://airtable.com/shrErY92edbs8JgUQ/tbl1dYTDO3zghBrsz
Работа с изображениями и видео
В этом направлении появляется очень много новых экспериментов, приложений и инструментов, которые помогают быстрее и качественнее работать с фото, артами, анимациями и видео, автоматизируя рутинные и долгие задачи.
Генерация: создание и анимация изображений
Первое, о чем мы хотели бы рассказать – это как нейронные сети позволяют создавать изображения. Используя датасеты с набором определенных образов или объектов, можно сгенерировать реалистичные фотографии машин, например, и даже людей. Сеть StyleGAN отлично подходит для этого, так как в ней можно получить качественный результат даже при генерировании фотографий людей.

Такой инструмент полезен для поиска вдохновения, подбора образов и получения необычных концептов. Мы экспериментировали с этой нейросетью в проекте с ARTLIFE для оживления одной из картин. Нами были сгенерированы стилизованные лица и далее мы создали анимацию, в итоге создавался плавный эффект перехода:


Улучшенный StyleGAN2 уже генерирует более качественные изображения, но более захватывающими являются интеграции этой сети с другими алгоритмами – в итоге могут получится визуализации клипов и креативных идей, когда нейронная сеть уже предобучена на датасете. Мы постарались визуализировать “Плачу на техно” на WikiArt, и получилось довольно необычно:

Еще более впечатляющими являются результаты работы сети Alias-Free GAN, в которой значительно уменьшилось количество артефактов, и теперь генерация идей и анимации становятся все круче:

Добавляя немного необычности и вариативности в StyleGAN2, исследователи экспериментировали с анимированием людей – это еще один способ не просто поиска вдохновения и референсов, в этом можно найти свой стиль графики, хоть иногда результат получается пугающим:

Любая анимация и видео позволяют работать с вниманием – с помощью различных эффектов можно концентрировать зрителя на самом важном, и в целом люди вовлекаются гораздо больше при просмотре видео (минимум на 22% больше). Нейронные сети здесь помогают всем художникам и дизайнерам, так как позволяют создавать необычные арт-работы. В частности, с помощью EbSynth можно переносить движения человека или животного на картины.


Text-to-image – создание изображений по текстовому описанию
Мы также протестировали CLIP модель вместе с BigGAN – такая связка позволяет генерировать изображения по текстовому описанию. И вот что у нас получилось для нескольких входных фраз.
")
Вдохновиться подобными рисунками можно в твиттер аккаунте этого эксперимента.
Почти с таким же названием StyleCLIP тоже позволяет поэкспериментировать с преобразованием текста в изображения, но здесь упор идет на обработку и редактуру уже существующих фотографий, а не генерацию новых:
")
Есть, кстати, множество других нейронных сетей для генерации изображений по тексту, например, DALL-E. Принцип работы в ней такой же – по вводимому тексту генерируется несколько изображений, что можно использовать для вдохновения и поиска новых идей, а также служить референсами для будущих артов :)

Редактирование: перенос стиля для видео
Нейронные сети позволяют значительно упростить работу при обработке фото и видео. Например, в процессе создания любого предмета искусства иногда появляется желание посмотреть на всё под новым углом – мы рассказывали о нейронных сетях pix2pix и StyleTransfer, полюбившиеся дизайнерами для задач быстрого переноса стиля по изображению-референсу. Среди крутых инструментов в web, которые легко использовать, можем еще отметить Arbitrary Style Transfer и Deep Dream Generator.
Приятно видеть, что их развитие идет дальше. Например, перенос стиля прямо в режиме камеры – можно весь мир превратить в мазки кисти:

А вот еще похожее применение переноса стиля. На изображении выделяются границы с помощью OpenCV, и полученные участки (по аналогии c NVIDIA GauGAN) используются для генерации изображения. Вот так можно поменять окружение вокруг вас в мир живописи:

Обработка изображений и видео
Adobe Sensei
Крупные компании-гиганты все больше смотрят в сторону ИИ и применения нейросетей для работы с графикой. Так, Adobe Sensei, набор инструментов и API с использованием нейросетей встроен в продукты Adobe – Lightroom и Photoshop.
В Lightroom есть инструмент Enhance Details для улучшения качества изображений: после обучения системы на датасете с более миллиарда снимков качество фотографий повышалось до 30%. А также программа предлагает оптимальные варианты коррекции снимков с настройками контрастности, яркости, насыщенности и т.д.

Для улучшения качества изображений также была недавно разработана BSRGAN, и стоит заметить, что результаты она дает впечатляющие, хоть и немного “мыльные” в некоторых местах:

В Photoshop есть полезный инструмент для обработки фотографий Content Aware Fill – с его помощью можно убрать нежелательные элементы на любом изображении.
Neural Filters можно использовать для наложения разных эффектов, например, для переноса стиля (прям как в StyleTransfer, описанной в предыдущей статье), или небольшого омоложения человека на фото :)

А здесь есть небольшое видео, в котором наглядно показана работа фильтров:
Face Aware Liquify подойдет идеально тем, кто хочет поэкспериментировать с обработкой портрета человека и немного (или много) поменять лицо (а еще он также работает на видео!):
И это еще не все – выделять объекты теперь максимально просто с помощью Object Selection Tool. Чтобы получить выделенную маску с человеком, животным, одеждой, машиной и любым объектом, достаточно воспользоваться этим инструментом и выделить нужную область с помощью лассо или обычного прямоугольного выделения, и программа сама определяет объект (и сохраняет достаточно много времени):
Видеоредактор Foundry NUKE 13 также включает несколько инструментов с ML для работы с видео: добавление/удаление пыли и грязи на видео, ретушь, которая применяется к объектам, а не отдельным кадрам, увеличение разрешения, удаление размытия движений.
Работа с фоном на изображениях и видео
Обработка видео занимает очень много времени, и как было отмечено выше, во многих редакторах есть инструменты, значительно упрощающие этот процесс. Здесь же хотим обратить внимание на приложения, которые максимально быстро и просто помогают добавить фантастичности к видео – это Castle in the Sky (SkyAR). Алгоритм автоматически рассчитывает, где находится небо и заменяет его нужным эффектом.

Мы также решили поэкспериментировать и заменили небо рядом с нашим штабом на Маяковской :)

Хорошее приложение для экспериментов и вдохновения, которое не требует никаких усилий. Такую механику замены неба, кстати, используют некоторые приложения для проецирования и изучения звездного неба (например, SkyGuide).

Есть еще полезные модели для удаления фона – в нашем проекте для фестиваля современного искусства Artlife Fest мы проводим много экспериментов с нейронными сетями (о чем вы можете почитать в наших статьях тут и тут). Для того, чтобы сделать эффект вылета в дополненной реальности на одной из картин, мы использовали сразу несколько нейронок – Let’s Enhance для повышения детализации домиков и RemoveBG для удаления фона и упрощения дальнейшей работы.

Оба сайта доступны любому и бесплатны, поэтому можете попробовать их в любое время, и в целом такие инструменты очень нужны для тех, кто постоянно обрабатывает фотографии.

Обработка видео в real-time
Обработка видео в режиме реального времени очень актуальна для удаленных встреч с вебкамерой, к которым мы все уже привыкли. NVIDIA представила новую SDK-платформу – NVIDIA Maxine, в которую интегрировано несколько нейронных сетей, улучшающих онлайн-встречи: повышение качества видео, удаление артефактов и шумов на видео, наложение виртуального фона, трекинг лица, оценка позы человека, удаление аудиошумов и посторонних звуков на видео.

Вдохновение: работа с референсами
Поиск референсов и вдохновения – это неотъемлемая часть работы с графикой.
В Adobe Lightroom, как и во многих других приложениях, можно также автоматически проставлять теги к фотографиям. Есть даже специальные системы визуального поиска, основанные на искусственном интеллекте – не беря в расчет Google Поиск, есть система Same Energy, которой пользуются многие дизайнеры для вдохновения и поиска референсов. Это отличный пример того, как простой и удобный инструмент доступен любому дизайнеру и специалисту, и в основе которого заложены сложные алгоритмы.

Похожий инструмент, основанный на Deep Learning – умная база данных MyMind, которую может использовать каждый для сохранения и быстрого поиска идей.

Не можем не упомянуть алгоритм PinSage, который работает в Pinterest – это эффективная рекомендательная система, которая по эффективности сравнивается с другими алгоритмами deep learning, лежащими в основе подобных систем, и помогает подобрать наиболее точные референсы к постам.
Инструменты от Adobe, Same Energy и MyMind – это идеальный пример того, как нейронные сети упрощают работу с изображениями и видео, при этом нам не обязательно разбираться в сложных алгоритмах для их применения, а достаточно только кликать мышкой.
Image-to-text – анализ изображений и объектов на них
Можно как вдохновляться тому, как нейронные сети видят наш мир, так и с их помощью посмотреть на привычное под новым углом.
Модель CLIP от OpenAI, обучаясь на парах (картинка, текст), способна предсказывать наиболее вероятное текстовое описание для изображения. Если у вас есть много картинок и нужно представить обобщающую информацию о них, такая сеть прекрасно для этого пойдет (хоть и есть небольшие погрешности в виде “банан=сладкий перец”)) Недавно, кстати, представили ruCLIP, которая дает русские описания к изображениям :)

Преобразование 2D в 3D
Следующее перспективное направление использования нейронных сетей в работе с графикой – это создание и редактирование 3D-моделей по изображениям и видео.
Редактирование: прибавляем объем к изображению и видео
Мы уже рассказывали о таких интересных инструментах, как KenBurns, которые позволяют создавать анимации и эффекты объема на изображениях. И с момента последнего апдейта появилось немало новых разработок. Хотим отметить модель Nerfies из семейства NRF, с ее помощью можно создать так называемое пространственное селфи:

Сняв небольшое видео на смартфон, вы можете сделать из него крутое анимированное селфи и по желанию добавить визуальные эффекты:
Похожий инструмент для создания 3D-селфи – работа Relightable 3D Head Portraits from a Smartphone Video, где также по видео создается 3D-портрет из облака точек:
И еще одна работа в области пространственных фотографий – Near-Instant Capture of High-Resolution Facial Geometry and Reflection. Этот проект 2016 года до сих пор остается эталоном в качестве восстановления текстур и геометрии лица (здесь играет важную роль играет специальная фотограмметрическая установка, которую используют авторы). Более подробно о работе этой сети – в статье на Хабре.

Кстати, есть такое приложение Bellus 3D, которое можно использовать, чтобы восстановить геометрию головы с помощью iOS устройств – этакая альтернатива этим нейронным сетям.
Приятно видеть, что все больше людей начинает мыслить в 3D-формате (даже обычные фотографии лица становятся объемными). Еще одна работа, на которую мы обратили внимание – это Neural Scene Flow Fields. С помощью этой модели можно создавать динамические сцены по видео. Эффект достаточно похож на KenBurns, но поскольку мы работаем с видео, на выходе получаются довольно интересные анимации:
NeRF in the Wild – отличный пример того, как нейронные сети позволяют сделать привычные фотографии необычными, добавляя эффект пролета.
Чтобы получить качественный результат нужно загрузить несколько фотографий объекта с разного ракурса, и на выходе получается небольшая анимация. Этот подход намного упрощает работу, если нужно быстро сделать gif, а видео для конвертации просто нет.

В целом, во многом перспективность 2D-to-3D зависит от развития нейронного рендеринга.
Нейронный рендеринг: создание сцен и воссоздание моделей по фотографиям
NeRF – это большое семейство алгоритмов для синтеза новых видов сцен из ее произвольных изображений. Недавно это семейство пополнилось алгоритмом NeRF for Dynamic Scenes, который расширяет область применения NeRF до динамических сцен.
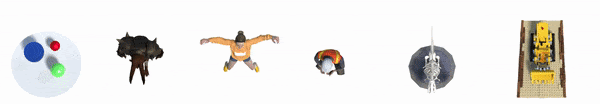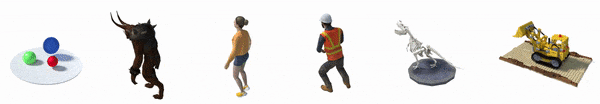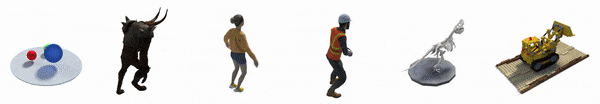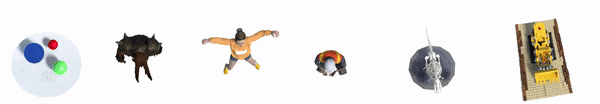

Благодаря такому подходу D-NeRF может рендерить новые изображения, управляя как обзором камеры, так и динамикой объекта, таким образом, движением объекта. А в результате AR, VR, игровая и киноиндустрии имеют еще один мощный инструмент для рендеринга.
Тем временем появилась еще другая модель, которая ориентирована на задачу перерисовки тела – A-NeRF: Surface-free Human 3D Pose Refinement via Neural Rendering.

Как и большинство подобных моделей, она может быть использована для более точной перерисовки модели человека в 3D и дальнейшей работы с ней.
Генерация: создание 3D-объекта по фотографии
Возможно, одно из самых популярных направлений во внедрении нейронных сетей в работе с графикой – это создание 3D-объекта по фотографии и видео, который используется для дальнейшей работы: от обработки моделей для интеграции в игры до прямого переноса в дополненную реальность. Здесь опять выделяется NVIDIA с разработкой GANverse3D. С ее помощью можно не только создавать 3D-объект, но и управлять им в виртуальной среде: добавлять свет, оживлять и даже сегментировать. На этом видео показано, как работает модель для переноса автомобилей по одной фотографии:
Результаты, конечно, впечатляющие, но как и во многих подобных моделях на выходе может получиться как и качественный 3D объект, так и не совсем :) Но не может не радовать наличие таких разработок от передовых компаний.
Быстрое создание объекта по фотографии становится всё более доступным для всех, так как подобный функционал внедряется прямо в мобильные приложения. Среди тех что мы тестировали, можем отметить Smoothie3D. Чтобы создать трехмерную модель с текстурами, нужно просто обвести контур на изображении.

Это самый простой и интуитивно понятный подход, позволяющий рисовать фигуры и улучшать их текстурами и фотографиями. Затем модель можно экспортировать в разных форматах или повзаимодействовать с ней в дополненной реальности :)
Для создания 3D-объектов можно также использовать GAN2Shape. Для использования этой сети в работе не нужно выставлять 2D-ключевые точки, 3D-аннотации или описывать формы объектов, она достаточно успешно восстанавливает 3D-формы с высокой точностью для человеческих лиц, кошек, автомобилей и зданий.

В итоге с помощью GAN2Shape можно получить высококачественную 3D-модель с возможностью вращать объект и управлять освещением – очень полезные свойства при работе в 3D-движках.
В задаче восстановления 3D объекта по нескольким снимкам также появилась новая архитектура 3D Volume Transformer (VoIT) (подробнее в этой работе). Если кратко, то она позволяет извлекать связь между изображениями и учитывать их взаимосвязь, что дает лучшие результаты при 2D-to-3D реконструкции.

Pose estimation – воссоздание модели человека
Для распознавания человеческих движений и их представления в 3D мы ранее рассматривали Vibe и PiFU. Чтобы сделать наиболее удобным перенос из 2D в 3D, мы собрали веб-сервис, где можно выбрать разрешение и быстро загрузить любую фотографию.

Кстати, не так давно мы провели целое мероприятие, посвященное 3D в анализе человеческого тела и открыли запись для просмотра всем желающим :)
В этот раз хотели бы остановиться на модели ACTOR. Она позволяет генерировать одновременно всю последовательность поз, что приводит к более консистентной генерации движения и отсутствию усреднения позы со временем.

Такую модель можно использовать для генерации синтетического датасета, а еще для автоматической анимации действий игровых персонажей, что незаменимо при работе с игровой графикой.
Исследователи NVIDIA тоже представили свой подход KAMA, который напрямую из изображения оценивает 3D координаты 26 ключевых точек тела и восстанавливает параметрическую модель, которая достаточно точно отражает движения.
Все больше становится актуален безмаркерный 3D захват движения человека. Представленный алгоритм от MPI-INF, Facebook Reality Labs и Valeo.ai повышает плавность и физическое правдоподобие поз, улавливает более быстрые движения и более точен по реконструкции, что означает приближение качественной реконструкции 3D из видео и фото.

О других инструментах для 2D-to-3D реконструкции мы рассказали в этой статье, где описали самые популярные и качественные способы создания модели по фотографии.
Работа с 3D-данными
В сегодняшней работе художников зачастую приходится сталкиваться с задачами по 3D-данным, которые могут быть значительно упрощены с помощью нейронных сетей и современных автоматизированных инструментов (например, плагин RCVS для поиска похожих 3D-объектов или Eyek для текстуризации объектов в Blender).
Анализ: сегментация элементов 3D-объекта
Мы уже упоминали в наших статьях работу 3D-SIS в области Instance Segmentation – сеть, позволяющую не только определять тип объекта, но и делить его на составные части. В области Part Segmentation вышло новое исследование Neural Parts. Эта модель более геометрически точна, более семантически последовательна и показывает больше деталей (такие как большие пальцы, ноги, крылья, шины и т.д.).
Такие нейронные сети будут полезны для анализа 3D-объектов или их группировки по определенным критериями, то есть смогут облегчить работу с большими базами 3D-данных.
Редактирование: восстановление объектов после сканирования
При сканировании объектов с помощью RGB-D камеры или других устройств, пространство и объекты часто представляются в виде облаков точек, и на их корректное и полное воссоздание в 3D может занять много времени. Для решения и ускорения этой задачи можно применять нейронные сети, например, HyperPocket, которая дополняет облака точек на основе GAN-моделей.

Редактирование: стилизация 3D-моделей
Благодаря нейронным сетям можно превращать трехмерные грубые воксельные формы с низким разрешением в объекты с высоким разрешением и детализацией, которые будут трансформироваться под определенный стиль (стиль в данном случае – это геометрические детали). Этот подход используется в DECOR-GAN, где за основу берется “код стиля” растений, а сами модели меняются в зависимости от выбранного “кода”. В этом видео, кстати, показано еще применение этого подхода для стилизации машин и стульев.

Любимый нами GauGAN, который помогает создавать концепты, трансформируя грубые скетчи в фотореалистичные изображения, приобрел 3D-формат, а именно – GANcraft. Эта модель показывает, как обычные кубы из Minecraft могут превращаться в красочные детализированные сцены.

Пока что модель находится на стадии разработки, и связка с Minecraft сужает поле применения, но уже виден прогресс – возможно, в скором времени мы увидим больше подобных инструментов, когда по простейшим моделям в 3D сцене будут генерироваться целые миры в высоком качестве.
Генерация: audio-to-3D
Одной из самых сложных задач при работе в 3D (особенно при разработке VR) – это реалистичная мимика при разговоре. Facebook Labs постарались подойти к решению этой проблемы с помощью обучения модели MeshTalk информации об эмоциях.

Исследователи смогли достичь высокоточного движения губ, правдоподобной анимации всего лица, в частности моргания и движения бровей. Этот подход стал новой ступенькой на пути к повышению иммерсивности VR, к упрощению задачи создания реалистичных моделей человека в 3D.
Как нейронные сети используются в играх
Мы уже не один раз говорили о нейросетях от NVIDIA, которые помогают в работе с графикой – GauGAN, например, и многие усилия компании нацелены на создание продуктов для игровой индустрии, в которой многие смотрят на качество картинки. NVIDIA DLSS, технология рендеринга на базе ИИ, улучшает производительность и качество графики в играх так, что значительно повышается FPS. Жалко, что работает она только на видеокартах GeForce RTX.

В контексте игр многие разработки касаются также самого игрового процесса, а именно – генерации уровней, симуляции, тестирования игр. Собрали некоторые подобные нейронные сети в табличку:

На стыке обработки графики с помощью нейронных сетей и игр есть интересный проект Enhancing Photorealism Enhancement. В нем графика игры GTA V преобразовывается в более реалистичную на основе нейронного рендеринга, в результате обучения на целом ряде фотографий городских пейзажей:

Подобные проекты приобретают все большую значимость, так как они двигают вперед развитие уровня графики и скорости ее обработки для различных устройств, и в перспективе такая стилизация и облачный стриминг позволят приблизить эру фиджитала с AR/VR-приложениями с реалистичной графикой.
Стоит отметить, что 3D, ML и XR становятся все ближе – мы недавно протестили проект с разметкой данных в облаке точек с помощью VR, получился довольно интересный опыт:
Выводы
Мы много изучаем нейронные сети и как их можно применять в графике и не только. Ниже мы зафиксировали перспективные задачи, о которых мы рассказали в статье и для которых можно использовать нейронные сети

Отдельно хотели бы выделить область 3D ML, которая двигает сочетание цифрового и физического, создавая продуктивную среду для работы и креатива. Среди задач, в которых перспективно развивается это направление:
– поиск 3D объектов (в этой области мы даже создали плагин для Blender – RCVS);
– генерация 3D-данных (например, мы создали сотни промышленных труб с различными дефектами для обучения нейронки для выявления дефектов – почитать можно тут);
– анимирование 3D объектов (можете почитать о плагине Morphle, который делает плавную анимацию перехода одного объекта в другой – настоящий метаморфоз!);
– автоматический редактор отсканированных объектов в 3D и удаление артефактов;
– и многое другое.
В скором времени выпустим whitepaper, в котором более подробно расскажем о направлении 3D ML, поэтому следите за обновлениями :)
Все источники указаны в тексте, а также благодарим авторов этих статей:
https://dtf.ru/promo/688429-msi-creator?fbclid=IwAR2itgl0FcA4rygaInly2NWVZ0J_bgj4127mpsizwcJL7j6fiYmVa60t4Ww
https://neurohive.io/ru/novosti/kak-ispolzovat-nejroseti-dlya-razrabotki-igr/
https://neurohive.io/ru/novosti/primenenie-ml-metodov-dlya-zadach-razrabotki-igr/




