

Голосовые агенты становятся все совершеннее, буквально каждый месяц появляются новые интересные наработки. Одна из них — немецкий проект по созданию детектора лжи для колл-центров. Речь идет о создании системы, которая может с высокой степенью вероятности определить, говорит звонящий в колл-центр абонент правду либо же пытается приврать/приукрасить свои утверждения или скрыть намерения.
Система базируется на специфическом дата-сете, сформированном из аудио-записей нескольких десятков преподавателей и студентов. Добровольцы участвовали в дебатах, обсуждая острые темы вроде смертной казни и платного обучения, а произносимые речи записывались на диктофон. О результатах проекта — под катом.
Модель обучали на архитектуре, которая включала сверточные нейронные сети (CNN) и долгую краткосрочную память (LSTM). Точность модели в итоге составляет 98%.
После изучения результатов проекта модель признали пригодной для анализа широкого спектра процессов обслуживания, с уклоном в коммуникацию с клиентами по телефонной связи. Разработанный алгоритм может применяться в любой ситуации, когда сотруднику колл-центра нужно знать, говорит ли клиент искренне.
Зачем? Подобное может понадобиться, например, при анализе сомнительных страховых случаев или оценки утверждений соискателя при приеме на работу. Если он будет делать ложные заявления, система сможет выявить неправду. В итоге алгоритм сможет не только снизить операционные потери сервисных компаний но и уменьшит количество неправдивых утверждений со стороны абонентов.
Подробнее о дата-сете
В отсутствие подходящего общедоступного дата-сета на немецком языке исследователи из Университета прикладных наук Ной-Ульма (HNU) собрали собственный. Для этого пришлось привлекать добровольцев. Авторы идеи решили их найти при помощи простейшего метода — раздачей информационных материалов. Листовки раздавались и расклеивались в университете и местных учебных заведениях. В итоге было отобрано 40 добровольцев в возрасте от 16 лет. Волонтерам платили подарочными картами Amazon на 10 евро — никакого другого вознаграждения не предусматривалось.
Встречи добровольцев проводились по модели дискуссионного клуба, призванной резко поляризовать мнения и вызвать сильные заявления на спорные темы. Это помогало привести к эмоциональному напряжению участников, которое может возникнуть в проблемных разговорах операторов колл-центров с клиентами по телефону.
Участникам дискуссий можно было три минуты выступать перед другими добровольцами на такие темы:
— Следует ли вернуть в Германии смертную казнь и публичные наказания?
— Следует ли в Германии взимать плату за обучение, покрывающую расходы государства?
— Следует ли легализовать в Германии употребление тяжелых наркотиков, таких как героин и метамфетамин?
— Следует ли запретить в Германии сети ресторанов, предлагающих нездоровую фаст-фуд еду, например McDonald’s или Burger King?
Обработка данных
В ходе обработки данных предпочтение отдавалось подходу автоматического распознавания речи (ASR), а не подходу НЛП (где речь анализируется на лингвистическом уровне с определением «температуры» дискуссии.
Предварительно обработанные образцы записей были проанализированы сначала при помощи Мел-кепстральных коэффициентов (MFCC). Это весьма надежный, зарекомендовавший себя ранее метод, который весьма популярен среди специалистов по анализу речи. Этот метод был впервые предложен в 1980 году. Он не требует использования значительных вычислительных мощностей и не особо требователен к качеству записей. Это особенно важно, поскольку качество аудиопотока в колл-центрах далеко не всегда можно назвать высоким.
Комбинация этих методов позволила создать весьма надежную модель обработки звука, которая вполне работоспособна без привлечения значительных ресурсов и в условиях не самого высокого качества аудиозаписей.
Последние обрабатывались еще и с использованием алгоритма быстрого преобразования Фурье (БПФ) для получения спектрального профиля каждого «аудиокадра» перед окончательной фиксацией для шкалы Мела.
Обучение, результаты и ограничения
Во время обучения извлеченные векторы признаков передаются на слой сверточной сети с распределением по времени, выравниваются и затем передаются на уровень LSTM.
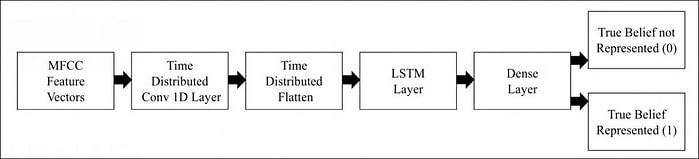
В результате обучения точность системы составила 98,91% с точки зрения распознавания намерений (т.е. когда заявленное голосом действие или намерение может не отражать реального положения вещей).
Конечно, для того, чтобы утверждать, что проект успешен на все 100%, желательно иметь более объемную исходную базу данных, т.е. дата-сет не из 40 аудиозаписей. Кроме того, любой язык специфичен и модель, обученная на немецком языке, может не подходить для работы с пользователями, которые говорят на других языках. Поэтому проект требует доработки, но его результаты и точность модели позволяют говорить о том, что модель вполне надежна.
Поделиться ссылкой:
Интересные статьи
Интересные статьи
Компания «Деловой разговор» — Титановый партнер 3СХ — осуществила расширенную интеграцию IP-АТС 3CX с Битрикс 24. Ранее уже существовали отдельные модули, решающие конкретные задачи, напр...
Я, как мне кажется, никогда не видел, чтобы какой-то вопрос вызывал такую мощную волну негатива, как дистанционное образование. По-моему, даже повышение пенсионного возраста прошло бо...

Как вы знаете, в этом году все наши чемпионаты собрались на одной платформе — All Cups (1, 2). И с 22 сентября по 16 октября на ней прошёл чемпионат по созданию дизайна мобильного при...
 с CRM Битрикс24")
Один из ключевых сценариев работы в CRM это общение с клиентом в удобном для него канале. По почте, по телефону, по SMS или в мессенджере. Особенно выделяется WhatsApp — интеграцию с ...
Доброго дня, любители Powershell.
Я люблю его, и сегодня заметил одну странность, которая мотивировала к написанию данного поста. Думаю, вам тоже будет интересно. Дело о лишнем тике. Если инте...