

В этой статье мы исследуем важную концепцию, используемую в недавно выпущенной платформе Lighthouse 2. Wavefront path tracing, как её называют Лейн, Каррас и Аила из NVIDIA, или streaming path tracing, как она изначально называлась в магистерской диссертации ван Антверпена, играет важнейшую роль в разработке эффективных трассировщиков пути на GPU, а потенциально и трассировщиков пути на CPU. Однако она довольно контринтуитивна, поэтому для её понимания необходимо переосмыслить алгоритмы трассировки лучей.
Occupancy
Алгоритм трассировки пути на удивление прост и его можно описать всего в нескольких строках псевдокода:
vec3 Trace( vec3 O, vec3 D )
IntersectionData i = Scene::Intersect( O, D )
if (i == NoHit) return vec3( 0 ) // ray left the scene
if (i == Light) return i.material.color // lights do not reflect
vec3 R, pdf = RandomDirectionOnHemisphere( i.normal ), 1 / 2PI
return Trace( i.position, R ) * i.BRDF * dot( i.normal, R ) / pdfВходящими данными является первичный луч, проходящий из камеры через пиксель экрана. Для этого луча мы определяем ближайшее пересечение с примитивом сцены. Если пересечений нет, то луч исчезает в пустоте. В противном случае, если луч дойдёт до источника света, то мы нашли путь прохождения света между источником и камерой. Если мы найдём что-то другое, то выполняем отражение и рекурсию, надеясь, что отражённый луч всё-таки найдёт источник освещения. Заметьте, что этот процесс напоминает (обратный) путь фотона, отражающегося от поверхностей сцены.
GPU предназначены для выполнения этой задачи в многопоточном режиме. Поначалу может показаться, что трассировка лучей идеально подходит для этого. Итак, мы используем OpenCL или CUDA для создания потока для пикселя, каждый поток выполняет алгоритм, который и в самом деле работает, как задумано, и при этом довольно быстр: достаточно взглянуть на несколько примеров с ShaderToy, чтобы понять насколько быстрой может быть трассировка лучей на GPU. Но как бы то ни было, вопрос в другом: действительно ли эти трассировщики лучей максимально быстры?

У этого алгоритма есть проблема. Первичный луч может найти источник света сразу же, или после одного случайного отражения, или спустя пятьдесят отражений. Программист для CPU заметит здесь потенциальное переполнение стека; программист для GPU должен увидеть проблему занятости (occupancy). Проблема вызвана условной хвостовой рекурсией: путь может завершиться на источнике света или продолжаться дальше. Перенесём это на множество потоков: часть потоков прекратится, а другая часть продолжит работу. Через несколько отражений у нас останется несколько потоков, которым нужно продолжать вычисления, а большинство потоков будет ждать завершения работы этих последних потоков. Понятие «занятость» — это мера части потоков GPU, выполняющих полезную работу.
Проблема занятости относится и к модели выполнения SIMT устройств GPU. Потоки упорядочены в группы, например в GPU Pascal (оборудование NVidia класса 10xx) 32 потока объединяются в warp. Потоки в warp имеют общий счётчик программы: они выполняются с фиксированным шагом, поэтому каждая инструкция программы выполняется 32 потоками одновременно. SIMT расшифровывается как single instruction multiple thread («одна инструкция, много потоков»), что хорошо описывает концепцию. Для процессора SIMT код с условиями представляет сложности. Это наглядно показано в официальной документации Volta:
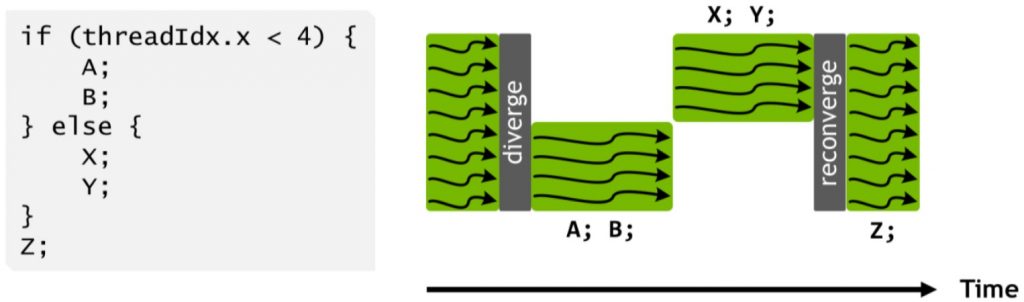
Выполнение кода с условиями в SIMT.
Когда некое условие истинно для некоторых потоков в warp, ветви оператора if-сериализуются. Альтернативой подходу «все потоки выполняют одно и то же» является «некоторые потоки отключены». В блоке if-then-else средняя занятость warp будет равна 50%, если только у всех потоков не будет согласованности относительно условия.
К сожалению, код с условиями в трассировщике лучей встречается не так редко. Лучи теней испускаются, только если источник освещения не находится за точкой затенения, разные пути могут сталкиваться с разными материалами, интегрирование методом «русской рулетки» может уничтожить или оставить путь в живых, и так далее. Выясняется, что occupancy становится основным источником неэффективности, и без чрезвычайных мер её предотвратить не так уж просто.
Streaming Path Tracing
Алгоритм streaming path tracing (потоковой трассировки пути) разработан для устранения корневой причины проблемы занятости. Streaming path tracing разделяет алгоритм трассировки пути на четыре этапа:
- Сгенерировать
- Продлить
- Затенить
- Соединить
Каждый этап реализуется как отдельная программа. Поэтому вместо выполнения полного трассировщика пути как одной программы GPU («ядра», kernel) нам придётся работать с четырьмя ядрами. Кроме того, как мы скоро увидим, они выполняются в цикле.
Этап 1 («Сгенерировать») отвечает за генерацию первичных лучей. Это простое ядро, создающее начальные точки и направления лучей в количестве, равном количеству пикселей. Выходными данными этого этапа являются большой буфер лучей и счётчик, сообщающий следующему этапу количество лучей, которое нужно обработать. Для первичных лучей эта величина равна ширине экрана, умноженной на высоту экрана.
Этап 2 («Продлить») — это второе ядро. Оно выполняется только после того, как этап 1 будет завершён для всех пикселей. Ядро считывает буфер, сгенерированный на этапе 1, и пересекает каждый луч со сценой. Выходными данными этого этапа становится результат пересечения для каждого луча, сохраняемый в буфере.
Этап 3 («Затенить») выполняется после полного завершения этапа 2. Он получает результат пересечения с этапа 2 и вычисляет модель затенения для каждого пути. Эта операция может генерировать новые лучи или не создавать их, в зависимости от того, завершился ли путь. Пути, порождающие новый луч (путь «продлевается») записывает новый луч («отрезок пути») в буфер. Пути, непосредственно сэмплирующие источники освещения («явное сэмплирование освещения» или «вычисление следующего события») записывают луч тени во второй буфер.
Этап 4 («Соединить») трассирует лучи тени, сгенерированные на этапе 3. Это похоже на этап 2, но с важным отличием: лучам тени достаточно найти любое пересечение, в то время как продлевающим лучам нужно было найти ближайшее пересечение. Поэтому для этого создано отдельное ядро.
После завершения этапа 4 у нас получится буфер, содержащий лучи, продлевающие путь. Взяв эти лучи, мы переходим к этапу 2. Продолжаем делать это, пока не останется продлевающих лучей или пока не достигнем максимального количества итераций.
Источники неэффективности
Озабоченный производительностью программист увидит в такой схеме алгоритмов streaming path tracing множество опасных моментов:
- Вместо единственного вызова ядра у нас теперь есть по три вызова на итерацию, плюс ядро генерации. Вызовы ядер означают определённое повышение нагрузки, поэтому это плохо.
- Каждой ядро считывает огромный буфер и записывает огромный буфер.
- CPU должен знать, сколько потоков нужно порождать для каждого ядра, поэтому GPU должен сообщать CPU, сколько лучей было сгенерировано на этапе 3. Перемещение информации из GPU в CPU — это плохая идея, а оно требуется как минимум один раз на итерацию.
- Как этап 3 записывает лучи в буфер, не создавая при этом повсюду пробелы? Он ведь не использует для этого атомарный счётчик?
- Количество активных путей всё равно снижается, так как же эта схема вообще может помочь?
Начнём с последнего вопроса: если мы передадим в GPU миллион задач, он не породит миллион потоков. Истинное количество выполняемых одновременно потоков зависит от оборудования, но в общем случае выполняются десятки тысяч потоков. Только при падении нагрузки ниже этого числа мы заметим проблемы занятости, вызванные малым количеством задач.
Также беспокойство вызывает масштабный ввод-вывод буферов. Это и в самом деле сложность, но не такая серьёзная, как можно ожидать: доступ к данным сильно предсказуем, особенно при записи в буферы, поэтому задержка не вызывает проблем. На самом деле, для такого типа обработки данных и были в первую очередь разработаны GPU.
Ещё один аспект, с которым GPU очень хорошо справляются — это атомарные счётчики, что довольно неожиданно для программистов, работающих в мире CPU. Для z-буфера требуется быстрый доступ, и поэтому реализация атомарных счётчиков в современных GPU чрезвычайно эффективна. На практике атомарная операция записи столь же затратна, как некэшированная запись в глобальную память. Во многих случаях задержка будет замаскирована масштабным параллельным выполнением в GPU.
Остаются два вопроса: вызовы ядер и двухсторонняя передача данных для счётчиков. Последний и в самом деле представляет собой проблему, поэтому нам необходимо ещё одно архитектурное изменение: постоянные потоки (persistent threads).
Последствия
Прежде чем углубляться в подробности, мы рассмотрим последствия использования алгоритма wavefront path tracing. Во-первых, скажем про буферы. Нам нужен буфер для вывода данных этапа 1, т.е. первичных лучей. Для каждого луча нам необходимы:
- Точка начала луча (ray origin): три значения float, то есть 12 байт
- Направление луча (ray direction): три значения float, то есть 12 байт
На практике лучше увеличить размер буфера. Если хранить по 16 байт для начала и направления луча, то GPU сможет считывать их за одну 128-битную операцию считывания. Альтернативой является 64-битная операция считывания с последующей 32-битной операцией для получения float3, что почти в два раза медленнее. То есть для экрана 1920×1080 мы получаем: 1920x1080x32=~64 МБ. Также нам понадобится буфер для результатов пересечения, созданных ядром «Продлить». Это ещё по 128 бит на элемент, то есть 32 МБ. Далее, ядро «Затенить» может создать до 1920×1080 продлений пути (верхний предел), и мы не можем записывать их в буфер, из которого считываем. То есть ещё 64 МБ. И, наконец, если наш трассировщик пути испускает лучи тени, то это ещё один буфер на 64 МБ. Просуммировав всё, мы получаем 224 МБ данных, и это только для алгоритма фронта волны. Или около 1 ГБ при разрешении 4K.
Здесь нам нужно привыкнуть к ещё одной особенности: памяти у нас в избытке. Может показаться. что 1 ГБ — это много, и существуют способы снижения этого числа, но если подойти к этому реалистично, то к тому времени, когда нам действительно понадобится трассировать пути в 4K, использование 1 ГБ на GPU с 8 ГБ будет меньшей из наших проблем.
Более серьёзной, чем требования к памяти, проблемой станут последствия для алгоритма рендеринга. Пока я предполагал, что нам нужно генерировать один продлевающий луч и, возможно, по одному лучу тени для каждого потока в ядре «Затенить». Но что если мы хотим выполнить Ambient Occlusion, использовав 16 лучей на пиксель? 16 лучей AO нужно хранить в буфере, но, что ещё хуже, они появятся только в следующей итерации. Похожая проблема возникает при трассировке лучей в стиле Уиттеда: испускание луча тени для нескольких источников освещения или разделение луча при столкновении со стеклом реализовать почти невозможно.
С другой стороны, wavefront path tracing решает проблемы, которые мы перечислили в разделе «Occupancy»:
- На этапе 1 все потоки без условий создают первичные лучи и записывают их в буфер.
- На этапе 2 все потоки без условий пересекают лучи со сценой и записывают результаты пересечения в буфер.
- На этапе 3 мы начинаем вычисление результатов пересечений с занятостью 100%.
- На этапе 4 мы обрабатываем непрерывный список лучей тени без пробелов.
Ко времени, когда мы вернёмся на этап 2 с оставшимися в живых лучами с длиной в 2 отрезка, у нас снова получился компактный буфер лучей, гарантирующий при запуске ядра полную занятость.
Кроме того, имеется и дополнительное преимущество, которое не стоит недооценивать. Код в четырёх отдельных этапах изолирован. Каждое ядро может использовать все доступные ресурсы GPU (кэш, общую память, регистры) без учёта других ядер. Это может позволить GPU выполнять код пересечения со сценой в большем количестве потоков, потому что этот код не требует такого большого количества регистров, как код затенения. Чем больше потоков, тем лучше можно спрятать задержки.
Полная занятость, улучшенная маскировка задержек, потоковая запись: все эти преимущества непосредственно связаны с возникновением и природой платформы GPU. Для GPU алгоритм wavefront path tracing очень естественен.
Стоит ли оно того?
Разумеется, у нас возникает вопрос: оправдывает ли оптимизированная занятость ввод-вывод из буферов и затраты на вызов дополнительных ядер?
Ответ положительный, однако доказать это не так легко.
Если мы на секунду вернёмся к трассировщикам пути с ShaderToy, то увидим, что в большинстве из них используется простая и жёстко заданная сцена. Замена её на полномасштабную сцену — нетривиальная задача: для миллионов примитивов пересечение луча и сцены становится сложной проблемой, решение которой часто оставляют для NVidia (Optix), AMD( Radeon-Rays) или Intel (Embree). Ни один из этих вариантов не сможет легко заменить жёстко прописанную сцену в искусственном трассировщике лучей CUDA. В CUDA ближайший аналог (Optix) требует контроля над выполнением программы. Embree в CPU позволяет трассировать отдельные лучи из вашего собственного кода, но ценой этого становятся значительные затраты производительности: он предпочитает трассировать вместо отдельных лучей большие группы лучей.

Экран из «It's About Time», отрендеренного с помощью Brigade 1.
Будет ли wavefront path tracing быстрее своей альтернативы («мегаядра» (megakernel), как его называют Лейн с коллегами), зависит от времени, проводимого в ядрах (большие сцены и затратные шейдеры снижают относительное превышение затрат алгоритмом фронта волны), от максимального длины пути, занятости мегаядра и разницы в нагрузке на регистры на четырёх этапах. В ранней версии оригинального трассировщика пути Brigade мы обнаружили, что даже простая сцена со смешением отражающих и ламбертовых поверхностей, запущенная на GTX480, выигрывала от использования wavefront.
Streaming Path Tracing в Lighthouse 2
В платформе Lighthouse 2 есть два трассировщика пути wavefront path tracing. Первый использует для реализации этапов 2 и 4 Optix Prime (этапы пересечения лучей и сцены); во второй для реализации той функциональности используется непосредственно Optix.
Optix Prime — это упрощённая версия Optix, которая только занимается пересечением набора лучей со сценой, состоящей из треугольников. В отличие от полной библиотеки Optix, она не поддерживает пользовательского кода пересечений, и пересекает только треугольники. Однако для wavefront path tracer именно это и требуется.
Wavefront path tracer на основе Optix Prime реализован в
rendercore.cpp проекта rendercore_optixprime_b. Инициализация Optix Prime начинается в функции Init и использует rtpContextCreate. Сцена создаётся с помощью rtpModelCreate. Различные буферы лучей создаются в функции SetTarget при помощи rtpBufferDescCreate. Заметьте, чтобы для этих буферов мы предоставляем обычные указатели устройств: это значит, что их можно использовать и в Optix, и в обычных ядрах CUDA.Рендеринг начинается в методе
Render. Для заполнения буфера первичных лучей используется ядро CUDA под названием generateEyeRays. После заполнения буфера при помощи rtpQueryExecute вызывается Optix Prime. С его помощью результаты пересечений записываются в extensionHitBuffer. Заметьте, что все буферы остаются в GPU: за исключением вызовов ядер трафик между CPU и GPU отсутствует. Этап «Затенить» реализован в обычном ядре CUDA shade. Его реализация находится в pathtracer.cu.Некоторые подробности реализации
optixprime_b стоят упоминания. Во-первых, лучи тени трассируются вне цикла фронта волны. Это правильно: луч тени влияет на пиксель, только если он не перекрыт, но во всех остальных случаях его результат больше нигде не нужен. То есть луч тени является одноразовым, его можно трассировать в любой момент и в любом порядке. В нашем случае мы используем это, группируя лучи тени, чтобы окончательно трассируемый батч был как можно бОльшим. У этого есть одно неприятное последствие: при N итерациях алгоритма фронта волны и X первичных лучах верхняя граница количества лучей тени равна XN.Ещё одна деталь — это обработка различных счётчиков. Этапы «Продлить» и «Затенить» должны знать, сколько путей активно. Счётчики для этого обновляются в GPU (атомарно), а значит и используются в GPU, даже без возврата в CPU. К сожалению, в одном из случаев это невозможно: библиотеке Optix Prime необходимо знать количество трассируемых лучей. Для этого нам раз в итерацию нужно возвращать информацию счётчиков.
Заключение
В этой статье объясняется, что такое wavefront path tracing, и почему она необходима для эффективного выполнения трассировки пути на GPU. Её практическая реализация представлена в платформе Lighthouse 2, имеющей открытые исходники и доступной на Github.



