
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Каков наилучший способ беспроблемного увеличения параллелизма в Node.js-сервисе, который используется в продакшне? Это — вопрос, на который моей команде понадобилось ответить пару месяцев назад.
У нас запущено 4000 контейнеров Node (или «воркеров»), обеспечивающих работу нашего сервиса интеграции с банками. Сервис изначально был спроектирован так, что каждый воркер был рассчитан на обработку только одного запроса за раз. Это снижало воздействие на систему тех операций, которые могли неожиданно заблокировать цикл событий и позволяло нам игнорировать различия в использовании ресурсов различными подобными операциями. Но, так как наши мощности были ограничены одновременным выполнением лишь 4000 запросов, система не могла достойно масштабироваться. Скорость выдачи ответов на большинство запросов зависела не от мощности оборудования, а от возможностей сети. Поэтому мы могли бы улучшить систему и снизить стоимость её поддержки в том случае, если бы нашли способ надёжной параллельной обработки запросов.

Занявшись исследованием этого вопроса, мы не смогли найти хорошего руководства, в котором речь шла бы о переходе от «отсутствия параллелизма» в сервисе Node.js к «высокому уровню параллелизма». В результате мы разработали собственную стратегию перехода, которая была основана на тщательном планировании, на хороших инструментах, на средствах мониторинга и на здоровой дозе отладки. В итоге нам удалось повысить уровень параллелизма нашей системы в 30 раз. Это эквивалентно снижению затрат на поддержку системы примерно на 300 тысяч долларов в год.
Данный материал посвящён рассказу о том, как мы увеличили производительность и эффективность наших Node.js-воркеров, и о том, что мы узнали, пройдя этот путь.
Удивительным может показаться то, что мы доросли до таких размеров без использования параллелизма. Как это вышло? Лишь 10% операций по обработке данных, выполняемых средствами Plaid, инициируются пользователями, которые сидят за компьютерами и подключили свои учётные записи к приложению. Всё остальное — это операции по периодическому обновлению транзакций, которые выполняются без присутствия пользователя. В используемую нами систему балансировки нагрузки была добавлена логика, обеспечивающая приоритет запросов, выполняемых пользователями, перед запросами на обновление транзакций. Это позволило нам обрабатывать всплески активности операций доступа к API в 1000% или даже больше. Делалось это за счёт транзакций, направленных на обновление данных.
Хотя эта компромиссная схема и работала уже долгое время, в ней можно было усмотреть несколько неприятных моментов. Мы знали, что они, в конце концов, могут плохо повлиять на надёжность сервиса.
Мы решили, что лучшим способом борьбы с узкими местами приложения и повышения надёжности системы станет увеличение уровня параллелизма при обработке запросов. Мы, кроме того, надеялись на то, что, в качестве побочного эффекта, это позволит нам снизить затраты на инфраструктуру и поможет реализовать более качественные средства для наблюдения за системой. И то и другое в будущем принесло бы свои плоды.
У нас имеется собственный балансировщик нагрузки, который перенаправляет запросы к Node.js-воркерам. Каждый воркер выполняет gRPC-сервер, применяемый для обработки запросов. Воркер использует Redis для того, чтобы сообщать балансировщику нагрузки о том, что он доступен. Это означает, что добавление в систему параллелизма сводится к простому изменению нескольких строк кода. А именно, воркер, вместо того, чтобы становиться недоступным после того, как к нему поступил запрос, должен сообщать о том, что он доступен, до тех пор, пока не окажется, что он занят обработкой N поступивших к нему запросов (каждый из них представлен собственным объектом Promise).
Правда, на самом деле не всё так просто. Мы, при развёртывании обновлений системы, всегда считаем своей главной целью поддержание её надёжности. Поэтому мы не могли просто взять и, руководствуясь чем-то вроде принципа YOLO, перевести систему в режим параллельной обработки запросов. Мы ожидали, что подобное обновление системы будет особенно рискованным. Дело в том, что это непредсказуемым образом подействовало бы на использование процессора, памяти, на задержки в выполнении задач. Так как движок V8, используемый в Node.js, обрабатывает задачи в цикле событий, нашим главным опасением было то, что в результате может оказаться так, что мы выполняем в цикле событий слишком много работы и таким образом снижаем пропускную способность системы.
Для того чтобы смягчить эти риски, мы, ещё до того, как первый параллельный воркер попал в продакшн, обеспечили наличие в системе следующих инструментов и средств мониторинга:
После завершения предварительной подготовки мы создали для «параллельных воркеров» новый кластер ECS. Это были те воркеры, которые использовали флаги LaunchDarkly для динамической установки их максимального уровня параллелизма.
Наш план развёртывания системы включал в себя поэтапное перенаправление растущего объёма трафика со старого кластера на новый. В ходе этого мы собирались внимательно наблюдать за производительностью нового кластера. На каждом уровне нагрузки мы планировали повышать уровень параллелизма каждого воркера, доводя его до максимального значения, при котором не происходило увеличение длительности выполнения задач или ухудшения других показателей. Если мы сталкивались с неприятностями — мы могли, в пределах нескольких секунд, динамически перенаправить трафик на старый кластер.
Как и ожидалось, мы столкнулись с некоторыми хитрыми проблемами. Нам нужно было их исследовать и устранить для того, чтобы обеспечить правильную работу обновлённой системы. Вот здесь-то и началось самое интересное.
Когда мы приступили к развёртыванию новой системы, мы начали получать уведомления о завершении работы задач с ненулевым кодом выхода. Что ж тут сказать — многообещающее начало. Тогда мы зарылись в Kibana и нашли нужный лог:
Это напоминало последствия утечек памяти, с которыми мы уже встречались, когда процесс неожиданно завершался, выдавая похожее сообщение об ошибке. Подобное представлялось вполне ожидаемым: повышение уровня параллелизма ведёт к повышению уровня использования памяти.
Мы предположили, что помочь решить эту проблему может увеличение максимального размера кучи Node.js, который по умолчанию установлен в 1.7 Гб. Тогда мы начали запускать Node.js, устанавливая максимальный размер кучи равным 6 Гб (с использованием флага командной строки
После того, как мы решили проблему с выделением памяти, мы начали сталкиваться с плохой пропускной способностью задач на параллельных воркерах. При этом наше внимание сразу же привлёк один из графиков на панели управления. Это был отчёт о том, как процессы параллельного воркера используют кучу.
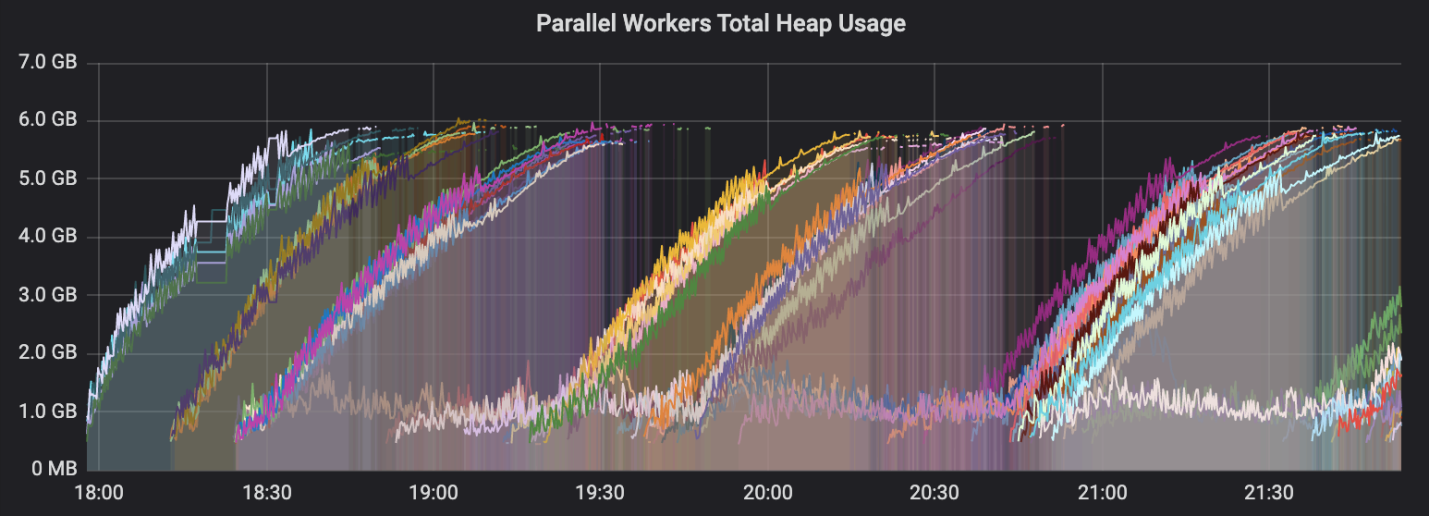
Использование кучи
Некоторые из кривых этого графика непрерывно шли вверх — до тех пор, пока не превращались, на уровне максимального размера кучи, в почти горизонтальные линии. Это нам очень не понравилось.
Мы использовали системные метрики в Prometheus для того, чтобы исключить из причин подобного поведения системы утечку файлового дескриптора или сетевого сокета. Наше наиболее адекватное предположение заключалось в том, что сборка мусора не выполнялась для старых объектов достаточно часто. Это могло бы приводить к тому, что по мере обработки задач воркер накапливал бы всё больше и больше памяти, выделенной под уже ненужные объекты. Мы предположили, что работа системы, в ходе которой её пропускная способность ухудшается, выглядит так:
Мы приступили к поиску в нашем коде операций, выполнение которых производится по принципу «сделали и забыли». Их ещё называют «плавающими промисами» («floating promise»). Это было просто — достаточно было найти строки, в которых было отключено правило линтера no-floating-promises. Наше внимание привлёк один метод. Он выполнял вызов
Нам хотелось проверить гипотезу, в соответствии с которой подобные плавающие промисы были главным источником неприятностей. Если не выполнять эти вызовы, которые не влияли на правильность работы системы, сможем ли мы улучшить скорость выполнения задач? Вот как выглядели сведения об использовании кучи после того, как мы временно избавились от вызовов
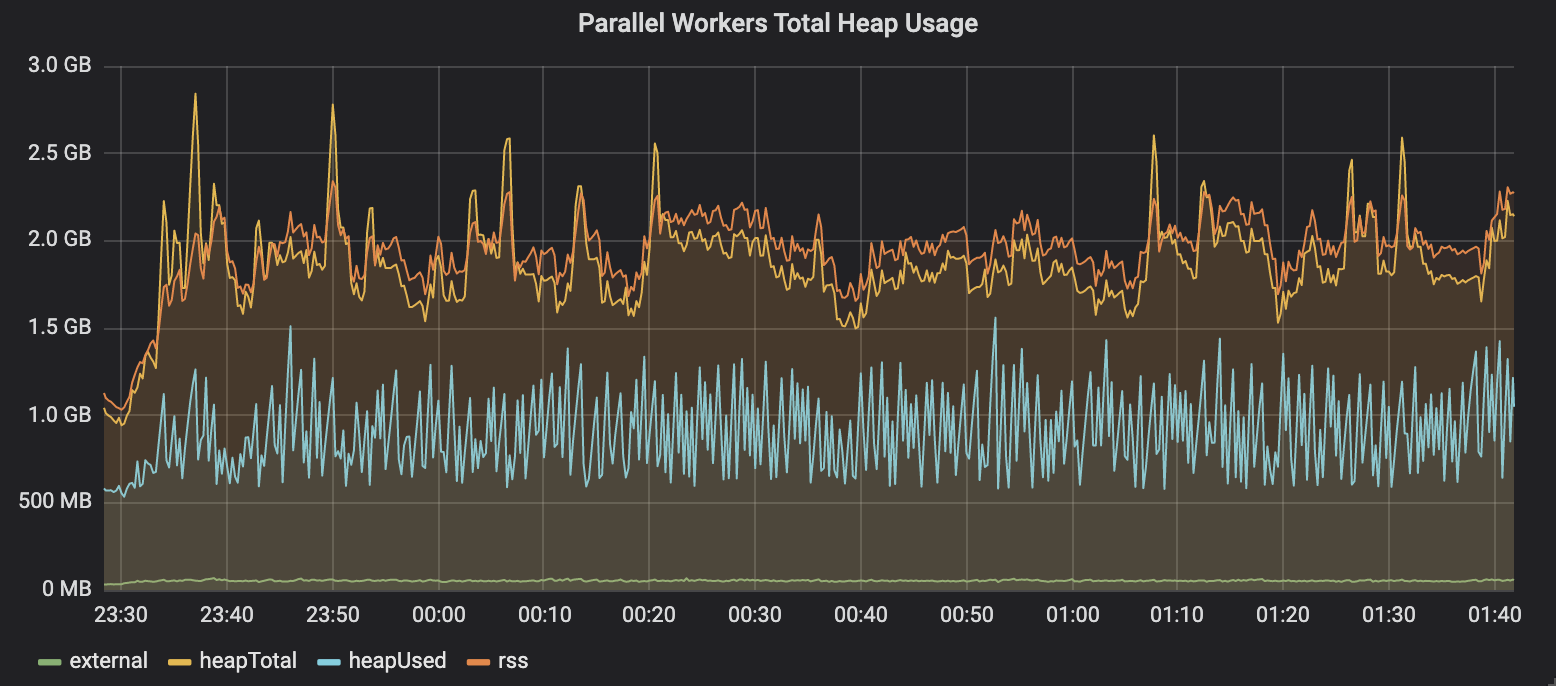
Использование кучи после отключения postTaskDebugging
Получилось! Теперь уровень использования кучи в параллельных воркерах остаётся стабильным на протяжении длительного периода времени.
Возникало такое ощущение, что в системе, по мере завершения задач, постепенно накапливались «долги» вызовов
Мы начали задаваться вопросом о том, что делало эти плавающие промисы столь медленными. Нам не хотелось совсем убирать из кода
Решив, что воспользуемся подобным решением проблемы лишь в крайнем случае, мы начали размышлять об оптимизации кода. Как ускорить эту операцию?
В логике работы
Из логов Kibana было понятно, что загрузка данных на S3, даже если их объём невелик, занимает много времени. Мы изначально не думали о том, что сокеты могут стать узким местом системы, так как стандартный HTTPS-агент Node.js устанавливает параметр maxSockets в значение
Так как мы довели воркер до состояния, когда в нём, в конкурентном режиме, выполнялось более 50 задач, шаг загрузки и стал узким местом: он предусматривал ожидание освобождения сокета для выгрузки данных на S3. Мы улучшили время загрузки данных, внеся следующее изменение в код инициализации клиента S3:
Улучшения кода, касающиеся S3, позволили замедлить рост размеров кучи, но они не привели к полному решению проблемы. Тут была ещё одна явная неприятность: в соответствии с нашими метриками, шаг сжатия данных в вышерассмотренном коде однажды длился 4 минуты. Это было гораздо дольше, чем обычное время выполнения задачи, которое составляет 4 секунды. Не веря своим глазам, не понимая того, как это может занять 4 минуты, мы решили воспользоваться локальными бенчмарками и оптимизировать медленный блок кода.
Сжатие данных состоит из трёх этапов (тут, для ограничения использования памяти, применяются потоки Node.js). А именно, на первом этапе генерируются строковые JSON-данные, на втором данные сжимаются с использованием zlib, на третьем — преобразуются в кодировку base64. Мы подозревали, что источником проблем может быть используемая нами сторонняя библиотека для формирования JSON-строк — bfj. Мы написали скрипт, который исследует производительность разных библиотек для формирования строковых JSON-данных, использующих потоки (соответствующий код можно найти здесь). Оказалось, что используемый нами пакет Big Friendly JSON оказался совсем не дружелюбным. Только взгляните на результаты пары измерений, полученных в ходе эксперимента:
Удивительные результаты. Даже в простом тесте пакет bfj оказался в 5 раз медленнее, чем другой пакет, JSONStream. Выяснив это, мы быстро поменяли bfj на JSONStream и тут же увидели значительный рост производительности.
После того, как мы решили проблемы с памятью, мы начали обращать внимание на отличие во времени, необходимом на обработку задач одного типа между обычными и параллельными воркерами. Сравнение это было совершенно правомерным, по его результатам мы могли судить об эффективности новой системы. Так, если соотношение между обычными и параллельными воркерами равнялось бы примерно 1, это давало бы нам уверенность в том, что мы можем спокойно перенаправлять трафик на эти воркеры. Но во время первых запусков системы соответствующий график в панели управления Grafana выглядел так, как показано ниже.
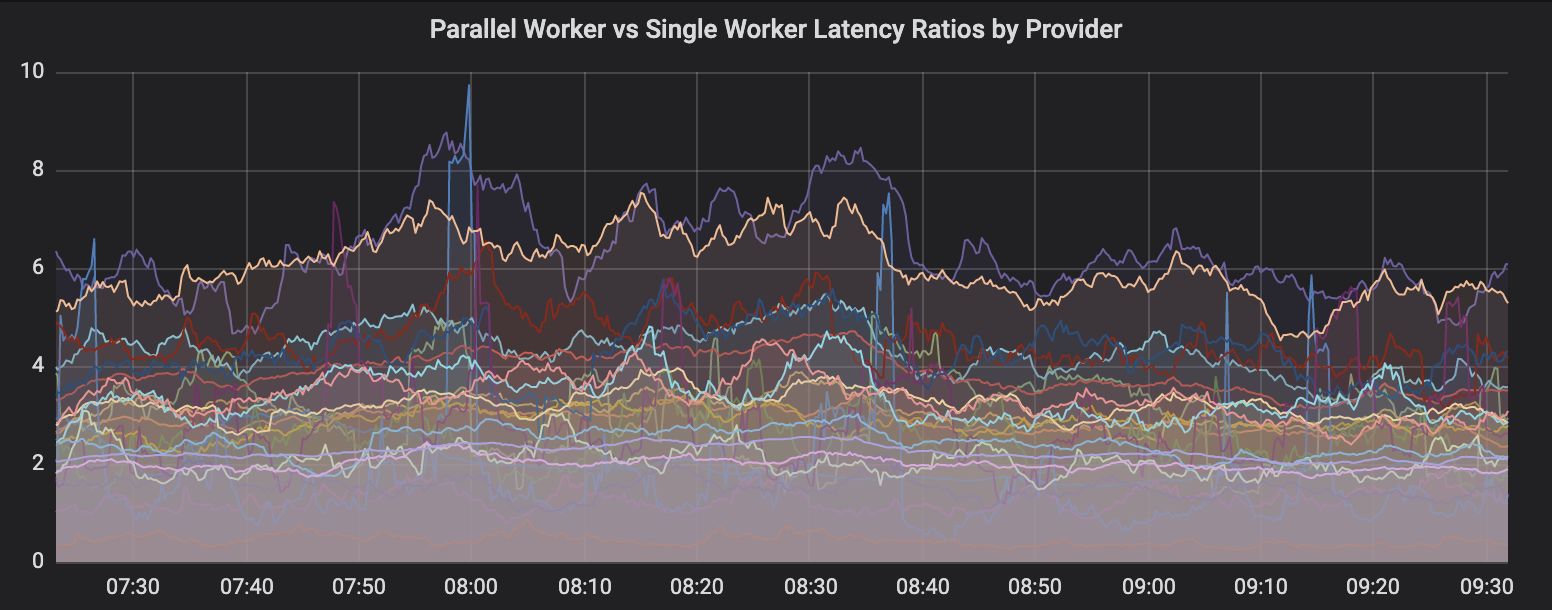
Соотношение времени выполнения задач обычными и параллельными воркерами
Обратите внимание на то, что иногда показатель находится в районе 8:1, и это при том, что средний уровень распараллеливания задач сравнительно низок и находится в районе 30. Мы знали о том, что решаемые нами задачи, касающиеся взаимодействия с банками, не создают большой нагрузки на процессоры. Нам было известно и то, что наши «параллельные» контейнеры не были в чём-то ограничены. Не зная о том, где искать причину проблемы, мы пошли читать материалы по оптимизации Node.js-проектов. Несмотря на малое количество подобных статей, мы наткнулись на этот материал, в котором речь идёт о достижении 600 тысяч конкурентных вебсокет-соединений в процессе Node.js.
В частности, наше внимание привлекло использование флага
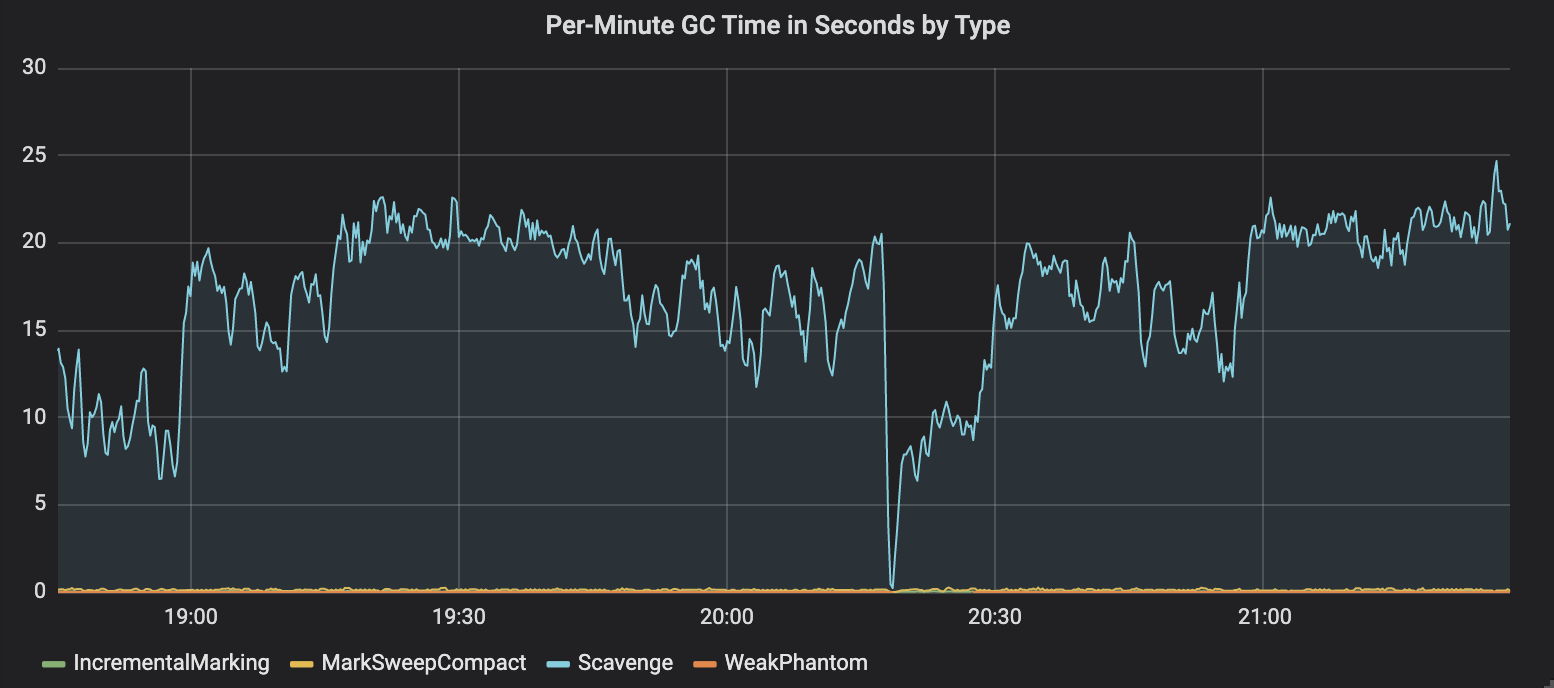
Анализ времени, уходящего на сборку мусора
Возникало такое ощущение, что наши процессы тратили около 30% времени на выполнение сборки мусора с использованием алгоритма Scavenge. Тут мы не собираемся описывать технические подробности, касающиеся различных типов сборки мусора в Node.js. Если вам данная тема интересна — взгляните на этот материал. Суть алгоритма Scavenge заключается в том, что сборка мусора запускается часто для очистки памяти, занимаемой маленькими объектами в области кучи Node.js, называемой «new space».
Итак, оказалось, что в наших Node.js-процессах сборка мусора запускается слишком часто. Можно ли отключить сборку мусора V8 и запускать её самостоятельно? Есть ли способ снижения частоты вызова сборки мусора? Оказалось, что первое из вышеупомянутого сделать нельзя, а вот последнее — можно! Мы можем просто увеличить размер области «new space», повысив лимит области «semi space» в Node.js с использованием флага командной строки
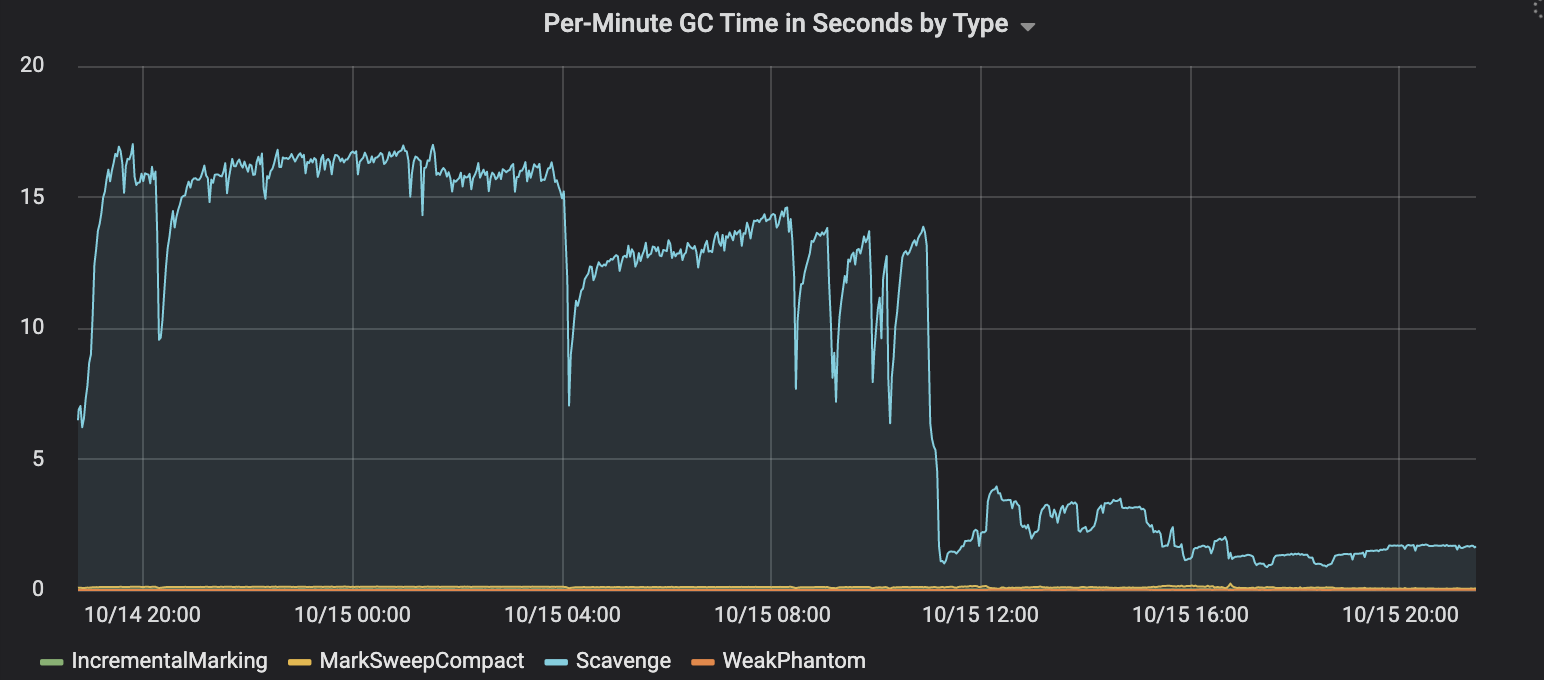
Результаты оптимизации процедуры сборки мусора
Ещё одна победа! Увеличение области «new space» привело к сильному сокращению объёма времени, уходящего на сборку мусора с использованием алгоритма Scavenge — с 30% до 2%.
После того, как была проделана вся эта работа, результат нас устраивал. Задачи, выполняемые в параллельных воркерах, при 20-кратном распараллеливании работы, функционировали почти так же быстро, как те которые выполнялись по отдельности, в отдельных воркерах. Нам казалось, что мы справились со всеми «узкими местами», но мы пока ещё не знали, выполнение каких именно операций замедляет систему в продакшне. Так как в системе уже не осталось мест, которые совершенно очевидно нуждались в оптимизации, мы решили заняться исследованием того, как воркеры пользуются ресурсами процессора.
На основе данных, собранных на одном из наших параллельных воркеров, был создан пламенный график. В нашем распоряжении оказалась аккуратная визуализация, с которой мы могли поработать на локальной машине. Да, вот интересная деталь: размер этих данных составил 60 Мб. Вот что мы увидели, поискав по слову
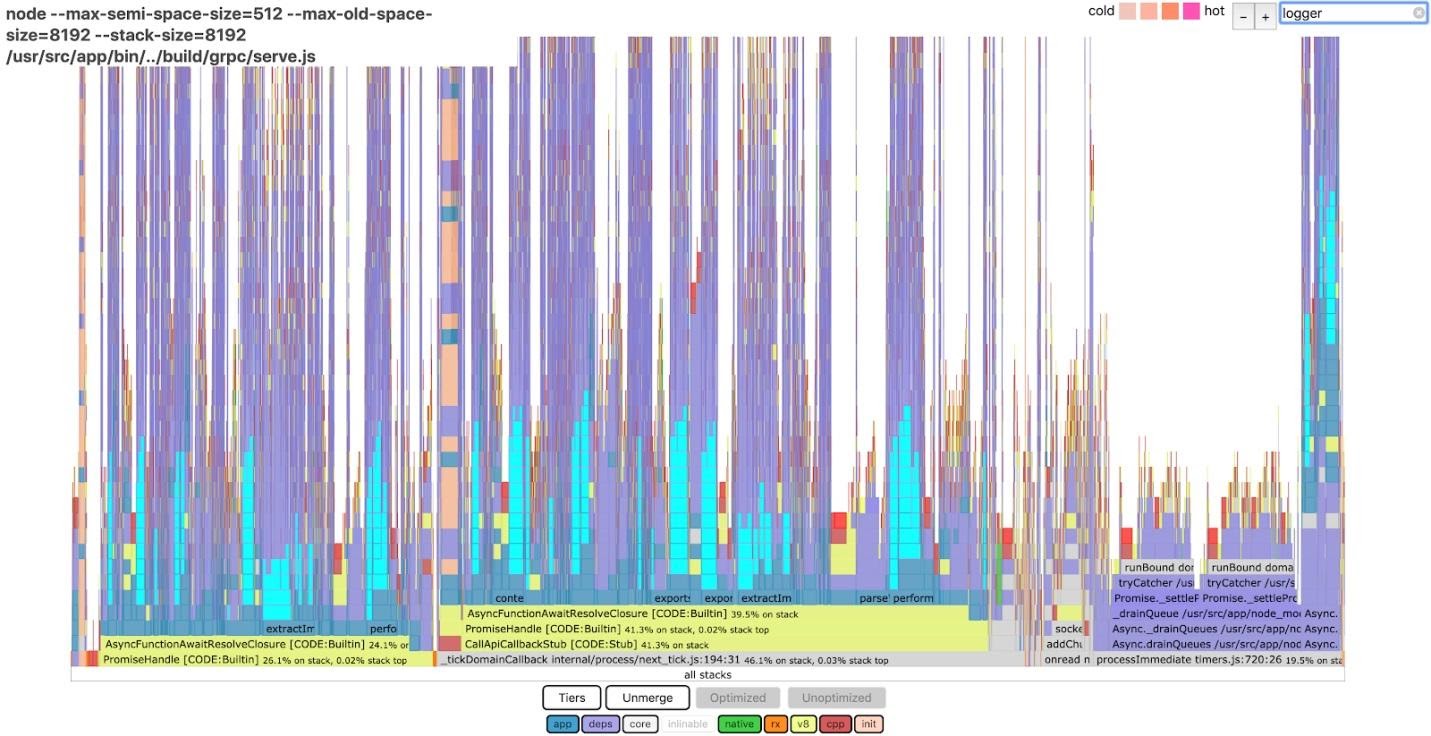
Анализ данных средствами 0x
Сине-зелёные области, выделенные в столбцах, указывают на то, что по меньшей мере 15% процессорного времени было потрачено на генерирование лога воркера. Мы, в итоге, смогли уменьшить это время на 75%. Правда, рассказ о том, как мы это сделали, тянет на отдельную статью. (Подсказка: мы пользовались регулярными выражениями и немало поработали со свойствами).
После этой оптимизации мы смогли параллельно обрабатывать в одном воркере до 30 задач, не вредя производительности системы.
Переход на параллельные воркеры позволил сократить ежегодные расходы на EC2 примерно на 300 тысяч долларов и сильно упростил архитектуру системы. Теперь мы используем в продакшне примерно в 30 раз меньше контейнеров, чем раньше. Наша система более устойчива к задержкам обработки исходящих запросов и к пикам запросов к API, приходящих от пользователей.
Занимаясь параллелизацией нашего сервиса интеграции с банками, мы узнали много нового:
Уважаемые читатели! Как вы оптимизируете свои Node.js-проекты?

У нас запущено 4000 контейнеров Node (или «воркеров»), обеспечивающих работу нашего сервиса интеграции с банками. Сервис изначально был спроектирован так, что каждый воркер был рассчитан на обработку только одного запроса за раз. Это снижало воздействие на систему тех операций, которые могли неожиданно заблокировать цикл событий и позволяло нам игнорировать различия в использовании ресурсов различными подобными операциями. Но, так как наши мощности были ограничены одновременным выполнением лишь 4000 запросов, система не могла достойно масштабироваться. Скорость выдачи ответов на большинство запросов зависела не от мощности оборудования, а от возможностей сети. Поэтому мы могли бы улучшить систему и снизить стоимость её поддержки в том случае, если бы нашли способ надёжной параллельной обработки запросов.
Занявшись исследованием этого вопроса, мы не смогли найти хорошего руководства, в котором речь шла бы о переходе от «отсутствия параллелизма» в сервисе Node.js к «высокому уровню параллелизма». В результате мы разработали собственную стратегию перехода, которая была основана на тщательном планировании, на хороших инструментах, на средствах мониторинга и на здоровой дозе отладки. В итоге нам удалось повысить уровень параллелизма нашей системы в 30 раз. Это эквивалентно снижению затрат на поддержку системы примерно на 300 тысяч долларов в год.
Данный материал посвящён рассказу о том, как мы увеличили производительность и эффективность наших Node.js-воркеров, и о том, что мы узнали, пройдя этот путь.
Почему мы решили вложить силы в параллелизм?
Удивительным может показаться то, что мы доросли до таких размеров без использования параллелизма. Как это вышло? Лишь 10% операций по обработке данных, выполняемых средствами Plaid, инициируются пользователями, которые сидят за компьютерами и подключили свои учётные записи к приложению. Всё остальное — это операции по периодическому обновлению транзакций, которые выполняются без присутствия пользователя. В используемую нами систему балансировки нагрузки была добавлена логика, обеспечивающая приоритет запросов, выполняемых пользователями, перед запросами на обновление транзакций. Это позволило нам обрабатывать всплески активности операций доступа к API в 1000% или даже больше. Делалось это за счёт транзакций, направленных на обновление данных.
Хотя эта компромиссная схема и работала уже долгое время, в ней можно было усмотреть несколько неприятных моментов. Мы знали, что они, в конце концов, могут плохо повлиять на надёжность сервиса.
- Пики запросов к API, приходящих от клиентов, становились всё выше и выше. Мы беспокоились о том, что огромный всплеск активности способен истощить возможности наших воркеров по обработке запросов.
- Внезапный рост задержек при выполнении запросов к банкам тоже приводил к уменьшению ёмкости воркеров. Из-за того, что в банках используются самые разные инфраструктурные решения, мы устанавливали весьма консервативные тайм-ауты для исходящих запросов. В результате на выполнение операции по загрузке неких данных могло уйти несколько минут. Если бы случилось так, что задержки при выполнении множества запросов к банкам вдруг сильно выросли бы, оказалось бы, что множество воркеров попросту застряли бы, ожидая ответов.
- Развёртывание в ECS стало слишком медленным, и даже хотя мы улучшили скорость развёртывания системы, нам не хотелось продолжать увеличивать размер кластера.
Мы решили, что лучшим способом борьбы с узкими местами приложения и повышения надёжности системы станет увеличение уровня параллелизма при обработке запросов. Мы, кроме того, надеялись на то, что, в качестве побочного эффекта, это позволит нам снизить затраты на инфраструктуру и поможет реализовать более качественные средства для наблюдения за системой. И то и другое в будущем принесло бы свои плоды.
Как мы вводили в строй обновления, заботясь о надёжности
▍Инструменты и мониторинг
У нас имеется собственный балансировщик нагрузки, который перенаправляет запросы к Node.js-воркерам. Каждый воркер выполняет gRPC-сервер, применяемый для обработки запросов. Воркер использует Redis для того, чтобы сообщать балансировщику нагрузки о том, что он доступен. Это означает, что добавление в систему параллелизма сводится к простому изменению нескольких строк кода. А именно, воркер, вместо того, чтобы становиться недоступным после того, как к нему поступил запрос, должен сообщать о том, что он доступен, до тех пор, пока не окажется, что он занят обработкой N поступивших к нему запросов (каждый из них представлен собственным объектом Promise).
Правда, на самом деле не всё так просто. Мы, при развёртывании обновлений системы, всегда считаем своей главной целью поддержание её надёжности. Поэтому мы не могли просто взять и, руководствуясь чем-то вроде принципа YOLO, перевести систему в режим параллельной обработки запросов. Мы ожидали, что подобное обновление системы будет особенно рискованным. Дело в том, что это непредсказуемым образом подействовало бы на использование процессора, памяти, на задержки в выполнении задач. Так как движок V8, используемый в Node.js, обрабатывает задачи в цикле событий, нашим главным опасением было то, что в результате может оказаться так, что мы выполняем в цикле событий слишком много работы и таким образом снижаем пропускную способность системы.
Для того чтобы смягчить эти риски, мы, ещё до того, как первый параллельный воркер попал в продакшн, обеспечили наличие в системе следующих инструментов и средств мониторинга:
- Уже используемый нами стек ELK обеспечивал нас достаточным объёмом логируемой информации, которая могла пригодиться для быстрого выяснения того, что происходит в системе.
- Мы добавили в систему несколько метрик Prometheus. В том числе — следующие:
- Размер кучи V8, полученный с помощью
process.memoryUsage(). - Сведения об операциях по сборке мусора, полученные с помощью пакета gc-stats.
- Данные о времени выполнения задач, сгруппированные по типу операций, касающихся интеграции с банками, и по уровню параллелизма. Это было нужно нам для надёжного измерения того, как параллелизм влияет на пропускную способность системы.
- Размер кучи V8, полученный с помощью
- Мы создали панель управления Grafana, предназначенную для изучения степени воздействия параллелизма на систему.
- Для нас была чрезвычайно важна возможность изменения поведения приложения без необходимости повторного развёртывания сервиса. Поэтому мы создали набор флагов LaunchDarkly, предназначенных для управления различными параметрами. При таком подходе подбор параметров воркеров, рассчитанный на то, чтобы они достигали бы максимального уровня параллелизма, позволил нам быстро проводить эксперименты и находить наилучшие параметры, тратя на это считанные минуты.
- Для того чтобы узнать о том, как различные части приложения нагружают процессор, мы встроили в продакшн-сервис средства сбора данных, на основе которых строились пламенные графики.
- Мы использовали пакет 0x из-за того, что средства Node.js легко было интегрировать в наш сервис, и из-за того, что итоговая HTML-визуализация данных поддерживала поиск и давала нам хороший уровень детализации.
- Мы добавили в систему режим профилирования, когда воркер запускался с включенным пакетом 0x и при выходе записывал итоговые данные в S3. Потом мы могли загрузить нужные нам логи из S3 и просмотреть их локально, используя команду вида
0x --visualize-only ./flamegraph. - Мы, в некий промежуток времени, запускали профилирование лишь для одного воркера. Профилирование увеличивает потребление ресурсов и снижает производительность, поэтому нам хотелось бы ограничить эти негативные эффекты единственным воркером.
▍Начало развёртывания
После завершения предварительной подготовки мы создали для «параллельных воркеров» новый кластер ECS. Это были те воркеры, которые использовали флаги LaunchDarkly для динамической установки их максимального уровня параллелизма.
Наш план развёртывания системы включал в себя поэтапное перенаправление растущего объёма трафика со старого кластера на новый. В ходе этого мы собирались внимательно наблюдать за производительностью нового кластера. На каждом уровне нагрузки мы планировали повышать уровень параллелизма каждого воркера, доводя его до максимального значения, при котором не происходило увеличение длительности выполнения задач или ухудшения других показателей. Если мы сталкивались с неприятностями — мы могли, в пределах нескольких секунд, динамически перенаправить трафик на старый кластер.
Как и ожидалось, мы столкнулись с некоторыми хитрыми проблемами. Нам нужно было их исследовать и устранить для того, чтобы обеспечить правильную работу обновлённой системы. Вот здесь-то и началось самое интересное.
Развернуть, исследовать, повторить
▍Увеличение максимального размера кучи Node.js
Когда мы приступили к развёртыванию новой системы, мы начали получать уведомления о завершении работы задач с ненулевым кодом выхода. Что ж тут сказать — многообещающее начало. Тогда мы зарылись в Kibana и нашли нужный лог:
FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed - Javascript heap out of memory
1: node::Abort()
2: node::FatalException(v8::Isolate*, v8::Local, v8::Local)
3: v8::internal::V8::FatalProcessOutOfMemory(char const*, bool)
4: v8::internal::Factory::NewFixedArray(int, v8::internal::PretenureFlag)Это напоминало последствия утечек памяти, с которыми мы уже встречались, когда процесс неожиданно завершался, выдавая похожее сообщение об ошибке. Подобное представлялось вполне ожидаемым: повышение уровня параллелизма ведёт к повышению уровня использования памяти.
Мы предположили, что помочь решить эту проблему может увеличение максимального размера кучи Node.js, который по умолчанию установлен в 1.7 Гб. Тогда мы начали запускать Node.js, устанавливая максимальный размер кучи равным 6 Гб (с использованием флага командной строки
--max-old-space-size=6144). Это было самым большим значением, которое подходило для наших экземпляров EC2. Такой ход, к нашему восхищению, позволил справиться с вышеописанной ошибкой, возникающей в продакшне.▍Идентификация узкого места памяти
После того, как мы решили проблему с выделением памяти, мы начали сталкиваться с плохой пропускной способностью задач на параллельных воркерах. При этом наше внимание сразу же привлёк один из графиков на панели управления. Это был отчёт о том, как процессы параллельного воркера используют кучу.
Использование кучи
Некоторые из кривых этого графика непрерывно шли вверх — до тех пор, пока не превращались, на уровне максимального размера кучи, в почти горизонтальные линии. Это нам очень не понравилось.
Мы использовали системные метрики в Prometheus для того, чтобы исключить из причин подобного поведения системы утечку файлового дескриптора или сетевого сокета. Наше наиболее адекватное предположение заключалось в том, что сборка мусора не выполнялась для старых объектов достаточно часто. Это могло бы приводить к тому, что по мере обработки задач воркер накапливал бы всё больше и больше памяти, выделенной под уже ненужные объекты. Мы предположили, что работа системы, в ходе которой её пропускная способность ухудшается, выглядит так:
- Воркер получает новую задачу и производит некие действия.
- В процессе выполнения задачи выполняется выделение памяти в куче под объекты.
- Из-за того, что некая операция, с которой работают по принципу «сделали и забыли» (тогда пока не было выяснено — какая именно) оказывается незавершённой, ссылки на объекты сохраняются даже после завершения задачи.
- Сборка мусора замедляется из-за того, что V8 приходится сканировать всё большее количество объектов в куче.
- Так как в V8 реализована система сборки мусора, работающая по схеме stop-the-world (остановка программы на время выполнения сборки мусора), новые задачи неизбежно получат меньше процессорного времени, что снижает пропускную способность воркера.
Мы приступили к поиску в нашем коде операций, выполнение которых производится по принципу «сделали и забыли». Их ещё называют «плавающими промисами» («floating promise»). Это было просто — достаточно было найти строки, в которых было отключено правило линтера no-floating-promises. Наше внимание привлёк один метод. Он выполнял вызов
compressAndUploadDebuggingPayload, не ожидая результатов. Похоже было, что такой вызов легко может продолжить ещё долго выполняться даже после того, как обработка задачи была завершена.const postTaskDebugging = async (data: TypedData) => {
const payload = await generateDebuggingPayload(data);
// Не надо ждать результатов выполнения этой операции,
// так как они не нужны для формирования ответа.
// tslint:disable-next-line:no-floating-promises
compressAndUploadDebuggingPayload(payload)
.catch((err) => logger.error('failed to upload data', err));
}Нам хотелось проверить гипотезу, в соответствии с которой подобные плавающие промисы были главным источником неприятностей. Если не выполнять эти вызовы, которые не влияли на правильность работы системы, сможем ли мы улучшить скорость выполнения задач? Вот как выглядели сведения об использовании кучи после того, как мы временно избавились от вызовов
postTaskDebugging.Использование кучи после отключения postTaskDebugging
Получилось! Теперь уровень использования кучи в параллельных воркерах остаётся стабильным на протяжении длительного периода времени.
Возникало такое ощущение, что в системе, по мере завершения задач, постепенно накапливались «долги» вызовов
compressAndUploadDebuggingPayload. Если воркер получал задачи быстрее, чем был способен «рассчитаться» по этим «долгам», тогда объекты, под которые выделялась память, не подвергались операции сборки мусора. Это приводило к заполнению кучи до самого верха, что мы и рассматривали выше, анализируя предыдущий график.Мы начали задаваться вопросом о том, что делало эти плавающие промисы столь медленными. Нам не хотелось совсем убирать из кода
compressAndUploadDebuggingPayload, так как этот вызов был чрезвычайно важен для того, чтобы наши инженеры могли бы отлаживать продакшн-задачи на своих локальных машинах. Мы, с технической точки зрения, могли бы решить проблему, ожидая результатов данного вызова и уже после этого завершая задачу, тем самым избавившись от плавающего промиса. Но это сильно увеличило бы время выполнения каждой обрабатываемой нами задачи.Решив, что воспользуемся подобным решением проблемы лишь в крайнем случае, мы начали размышлять об оптимизации кода. Как ускорить эту операцию?
▍Исправление узкого места S3
В логике работы
compressAndUploadDebuggingPayload несложно разобраться. Тут мы сжимаем отладочные данные, а они могут быть довольно большими, так как включают в себя сетевой трафик. Затем мы выгружаем сжатые данные в S3.export const compressAndUploadDebuggingPayload = async (
logger: Logger,
data: any,
) => {
const compressionStart = Date.now();
const base64CompressedData = await streamToString(
bfj.streamify(data)
.pipe(zlib.createDeflate())
.pipe(new b64.Encoder()),
);
logger.trace('finished compressing data', {
compression_time_ms: Date.now() - compressionStart,
);
const uploadStart = Date.now();
s3Client.upload({
Body: base64CompressedData,
Bucket: bucket,
Key: key,
});
logger.trace('finished uploading data', {
upload_time_ms: Date.now() - uploadStart,
);
}Из логов Kibana было понятно, что загрузка данных на S3, даже если их объём невелик, занимает много времени. Мы изначально не думали о том, что сокеты могут стать узким местом системы, так как стандартный HTTPS-агент Node.js устанавливает параметр maxSockets в значение
Infinity. Однако мы, в итоге, вчитались в документацию AWS по Node.js, и нашли кое-что для нас удивительное: клиент S3 уменьшает значение параметра maxSockets до 50. Не стоит и говорить о том, что такое поведение не назовёшь интуитивно понятным.Так как мы довели воркер до состояния, когда в нём, в конкурентном режиме, выполнялось более 50 задач, шаг загрузки и стал узким местом: он предусматривал ожидание освобождения сокета для выгрузки данных на S3. Мы улучшили время загрузки данных, внеся следующее изменение в код инициализации клиента S3:
const s3Client = new AWS.S3({
httpOptions: {
agent: new https.Agent({
// Используем произвольное большое значение для
// обеспечения параллельной загрузки данных от максимального количества задач на S3.
maxSockets: 1024 * 20,
}),
},
region,
});▍Ускорение сериализации JSON
Улучшения кода, касающиеся S3, позволили замедлить рост размеров кучи, но они не привели к полному решению проблемы. Тут была ещё одна явная неприятность: в соответствии с нашими метриками, шаг сжатия данных в вышерассмотренном коде однажды длился 4 минуты. Это было гораздо дольше, чем обычное время выполнения задачи, которое составляет 4 секунды. Не веря своим глазам, не понимая того, как это может занять 4 минуты, мы решили воспользоваться локальными бенчмарками и оптимизировать медленный блок кода.
Сжатие данных состоит из трёх этапов (тут, для ограничения использования памяти, применяются потоки Node.js). А именно, на первом этапе генерируются строковые JSON-данные, на втором данные сжимаются с использованием zlib, на третьем — преобразуются в кодировку base64. Мы подозревали, что источником проблем может быть используемая нами сторонняя библиотека для формирования JSON-строк — bfj. Мы написали скрипт, который исследует производительность разных библиотек для формирования строковых JSON-данных, использующих потоки (соответствующий код можно найти здесь). Оказалось, что используемый нами пакет Big Friendly JSON оказался совсем не дружелюбным. Только взгляните на результаты пары измерений, полученных в ходе эксперимента:
benchBFJ*100: 67652.616ms
benchJSONStream*100: 14094.825msУдивительные результаты. Даже в простом тесте пакет bfj оказался в 5 раз медленнее, чем другой пакет, JSONStream. Выяснив это, мы быстро поменяли bfj на JSONStream и тут же увидели значительный рост производительности.
▍Уменьшение времени, необходимого на сборку мусора
После того, как мы решили проблемы с памятью, мы начали обращать внимание на отличие во времени, необходимом на обработку задач одного типа между обычными и параллельными воркерами. Сравнение это было совершенно правомерным, по его результатам мы могли судить об эффективности новой системы. Так, если соотношение между обычными и параллельными воркерами равнялось бы примерно 1, это давало бы нам уверенность в том, что мы можем спокойно перенаправлять трафик на эти воркеры. Но во время первых запусков системы соответствующий график в панели управления Grafana выглядел так, как показано ниже.
Соотношение времени выполнения задач обычными и параллельными воркерами
Обратите внимание на то, что иногда показатель находится в районе 8:1, и это при том, что средний уровень распараллеливания задач сравнительно низок и находится в районе 30. Мы знали о том, что решаемые нами задачи, касающиеся взаимодействия с банками, не создают большой нагрузки на процессоры. Нам было известно и то, что наши «параллельные» контейнеры не были в чём-то ограничены. Не зная о том, где искать причину проблемы, мы пошли читать материалы по оптимизации Node.js-проектов. Несмотря на малое количество подобных статей, мы наткнулись на этот материал, в котором речь идёт о достижении 600 тысяч конкурентных вебсокет-соединений в процессе Node.js.
В частности, наше внимание привлекло использование флага
--nouse-idle-notification. Могут ли наши процессы Node.js тратить так много времени на выполнение сборки мусора? Тут, очень кстати, пакет gc-stats дал нам возможность посмотреть на среднее время, уходящее на сборку мусора.Анализ времени, уходящего на сборку мусора
Возникало такое ощущение, что наши процессы тратили около 30% времени на выполнение сборки мусора с использованием алгоритма Scavenge. Тут мы не собираемся описывать технические подробности, касающиеся различных типов сборки мусора в Node.js. Если вам данная тема интересна — взгляните на этот материал. Суть алгоритма Scavenge заключается в том, что сборка мусора запускается часто для очистки памяти, занимаемой маленькими объектами в области кучи Node.js, называемой «new space».
Итак, оказалось, что в наших Node.js-процессах сборка мусора запускается слишком часто. Можно ли отключить сборку мусора V8 и запускать её самостоятельно? Есть ли способ снижения частоты вызова сборки мусора? Оказалось, что первое из вышеупомянутого сделать нельзя, а вот последнее — можно! Мы можем просто увеличить размер области «new space», повысив лимит области «semi space» в Node.js с использованием флага командной строки
--max-semi-space-size=1024. Это позволяет выполнять больше операций по выделению памяти под короткоживущие объекты до того момента, когда V8 начнёт сборку мусора. Как результат — снижается частота запуска подобных операций.Результаты оптимизации процедуры сборки мусора
Ещё одна победа! Увеличение области «new space» привело к сильному сокращению объёма времени, уходящего на сборку мусора с использованием алгоритма Scavenge — с 30% до 2%.
▍Оптимизация использования процессора
После того, как была проделана вся эта работа, результат нас устраивал. Задачи, выполняемые в параллельных воркерах, при 20-кратном распараллеливании работы, функционировали почти так же быстро, как те которые выполнялись по отдельности, в отдельных воркерах. Нам казалось, что мы справились со всеми «узкими местами», но мы пока ещё не знали, выполнение каких именно операций замедляет систему в продакшне. Так как в системе уже не осталось мест, которые совершенно очевидно нуждались в оптимизации, мы решили заняться исследованием того, как воркеры пользуются ресурсами процессора.
На основе данных, собранных на одном из наших параллельных воркеров, был создан пламенный график. В нашем распоряжении оказалась аккуратная визуализация, с которой мы могли поработать на локальной машине. Да, вот интересная деталь: размер этих данных составил 60 Мб. Вот что мы увидели, поискав по слову
logger в пламенном графике 0x.Анализ данных средствами 0x
Сине-зелёные области, выделенные в столбцах, указывают на то, что по меньшей мере 15% процессорного времени было потрачено на генерирование лога воркера. Мы, в итоге, смогли уменьшить это время на 75%. Правда, рассказ о том, как мы это сделали, тянет на отдельную статью. (Подсказка: мы пользовались регулярными выражениями и немало поработали со свойствами).
После этой оптимизации мы смогли параллельно обрабатывать в одном воркере до 30 задач, не вредя производительности системы.
Итоги
Переход на параллельные воркеры позволил сократить ежегодные расходы на EC2 примерно на 300 тысяч долларов и сильно упростил архитектуру системы. Теперь мы используем в продакшне примерно в 30 раз меньше контейнеров, чем раньше. Наша система более устойчива к задержкам обработки исходящих запросов и к пикам запросов к API, приходящих от пользователей.
Занимаясь параллелизацией нашего сервиса интеграции с банками, мы узнали много нового:
- Никогда не стоит недооценивать важность обладания низкоуровневыми метриками системы. Возможность мониторить данные, касающиеся сборки мусора и использования памяти оказала нам огромнейшую помощь при развёртывании системы и при её доработке.
- Пламенные графики — это замечательный инструмент. Теперь, когда мы научились ими пользоваться, мы можем с их помощью легко выявлять новые «узкие места» в системе.
- Понимание механизмов времени выполнения Node.js позволило нам писать более качественный код. Например, зная о том, как V8 выделяет память под объекты, и о том, как работает сборка мусора, мы увидели смысл в том, чтобы как можно обширнее применять технику повторного использования объектов. Иногда для того, чтобы лучше во всём этом разобраться, нужно поработать непосредственно с V8 или поэкспериментировать с флагами командной строки Node.js.
- Очень важно внимательно читать документацию ко всем механизмам, из которых состоит система. Мы доверяли данным по
maxSocket, найденным в документации к Node.js, но, после длительных исследований, оказалось, что в AWS стандартное поведение Node.js меняется. Пожалуй, в каждом проекте, основанном на чужой инфраструктуре, может произойти нечто подобное.
Уважаемые читатели! Как вы оптимизируете свои Node.js-проекты?



