

Приходя в продукт, который развивается больше десятка лет, совершенно не удивительно встретить в нем устаревшие технологии. Но что если через полгода вы должны держать нагрузку в 10 раз выше, а цена падений увеличится в сотни раз? В этом случае вам необходим крутой Highload Engineer. Но за неимением горничной такового, решать проблему доверили мне. В первой части статьи я расскажу, как мы переезжали с Redis на Redis-cluster, а во второй части дам советы, как начать пользоваться кластером и на что обратить внимание при эксплуатации.
Выбор технологии
Так ли плох отдельный Redis (standalone redis) в конфигурации 1 мастер и N слейвов? Почему я называю его устаревшей технологией?
Нет, Redis не так плох… Однако, есть некоторые недочеты которые нельзя игнорировать.
Во-первых, Redis не поддерживает механизмы аварийного восстановления после падения мастера. Для решения этой проблемы мы использовали конфигурацию с автоматическим перекидыванием VIP-ов на новый мастер, сменой роли одного из слейвов и переключением остальных. Этот механизм работал, но назвать его надежным решением было нельзя. Во первых, случались ложные срабатывания, а во вторых, он был одноразовым, и после срабатывания требовались ручные действия по взводу пружины.
Во-вторых, наличие только одного мастера приводило к проблеме шардирования. Приходилось создавать несколько независимых кластеров «1 мастер и N слейвов», затем вручную разносить базы по этим машинам и надеяться, что завтра одна из баз не распухнет настолько, что её придется выносить на отдельный инстанс.
Какие есть варианты?
- Самое дорогое и богатое решение — Redis-Enterprise. Это коробочное решение с полной технической поддержкой. Несмотря на то, что оно выглядит идеальным с технической точки зрения, нам не подошло по идеологическим соображениям.
- Redis-cluster. Из коробки есть поддержка аварийного переключения мастера и шардирования. Интерфейс почти не отличается от обычной версии. Выглядит многообещающе, про подводные камни поговорим далее.
- Tarantool, Memcache, Aerospike и другие. Все эти инструменты делают примерно то же самое. Но у каждого есть свои недостатки. Мы решили не класть все яйца в одну корзину. Memcache и Tarantool мы используем для других задач, и, забегая вперед, скажу, что на нашей практике проблем с ними было больше.
Специфика использования
Давайте взглянем, какие задачи мы исторически решали Redis’ом и какую функциональность использовали:
- Кеш перед запросами к удаленным сервисам вроде 2GIS | Golang
GET SET MGET MSET "SELECT DB"
- Кеш перед MYSQL | PHP
GET SET MGET MSET SCAN "KEY BY PATTERN" "SELECT DB"
- Основное хранилище для сервиса работы с сессиями и координатами водителей | Golang
GET SET MGET MSET "SELECT DB" "ADD GEO KEY" "GET GEO KEY" SCAN
Как видите, никакой высшей математики. В чём же тогда сложность? Давайте разберем отдельно по каждому методу.
| Метод | Описание | Особенности Redis-cluster | Решение |
|---|---|---|---|
| GET SET | Записать/прочитать ключ | ||
| MGET MSET | Записать/прочитать несколько ключей | Ключи будут лежать на разных нодах. Готовые библиотеки умеют делать Multi-операции только в рамках одной ноды | Заменить MGET на pipeline из N GET операций |
| SELECT DB | Выбрать базу, с которой будем работать | Не поддерживает несколько баз данных | Складывать всё в одну базу. Добавить к ключам префиксы |
| SCAN | Пройти по всем ключам в базе | Поскольку у нас одна база, проходить по всем ключам в кластере слишком затратно | Поддерживать инвариант внутри одного ключа и делать HSCAN по этому ключу. Или отказаться совсем |
| GEO | Операции работы с геоключом | Геоключ не шардируется | |
| KEY BY PATTERN | Поиск ключа по паттерну | Поскольку у нас одна база, будем искать по всем ключам в кластере. Слишком затратно | Отказаться или поддерживать инвариант, как и в случае со SCAN-ом |
Redis vs Redis-cluster
Что мы теряем и что получаем при переходе на кластер?
- Недостатки: теряем функциональность нескольких баз.
- Если мы хотим хранить в одном кластере логически не связанные данные, придется делать костыли в виде префиксов.
- Теряем все операции «по базе», такие как SCAN, DBSIZE, CLEAR DB и т.п.
- Multi-операции стали значительно сложнее в реализации, потому что может требоваться обращение к нескольким нодам.
- Достоинства:
- Отказоустойчивость в виде аварийного переключения мастера.
- Шардирования на стороне Redis.
- Перенос данных между нодами атомарно и без простоев.
- Добавление и перераспределение мощностей и нагрузок без простоев.
Я бы сделал вывод, что если вам не нужно обеспечивать высокий уровень отказоустойчивости, то переезд на кластер того не стоит, т.к это может быть нетривиальной задачей. Но если изначально выбирать между отдельной версией и кластерной, то стоит выбирать кластер, так как он ничем не хуже и в дополнение снимет с вас часть головной боли
Подготовка к переезду
Начнем с требований к переезду:
- Он должен быть бесшовным. Полная остановка сервиса на 5 минут нас не устраивает.
- Он должен быть максимально безопасным и постепенным. Хочется иметь какой-то контроль над ситуацией. Бухнуть сразу всё и молиться над кнопкой отката мы не желаем.
- Минимальные потери данных при переезде. Мы понимаем, что переехать атомарно будет очень сложно, поэтому допускаем некоторую рассинхронизацию между данными в обычном и кластерном Redis.
Обслуживание кластера
Перед самым переездом следует задуматься о том, а можем ли мы поддерживать кластер:
- Графики. Мы используем Prometheus и Grafana для графиков загрузки процессоров, занятой памяти, количества клиентов, количества операций GET, SET, AUTH и т.п.
- Экспертиза. Представьте, что завтра под вашей ответственностью будет огромный кластер. Если он сломается, никто, кроме вас, починить его не сможет. Если он начнет тормозить — все побегут к вам. Если нужно добавить ресурсы или перераспределить нагрузку — снова к вам. Чтобы не поседеть в 25, желательно предусмотреть эти случаи и проверить заранее, как технология поведет себя при тех или иных действиях. Поговорим об этом подробнее в разделе «Экспертиза».
- Мониторинги и оповещения. Когда кластер ломается, об этом хочется узнать первым. Тут мы ограничились оповещением о том, что все ноды возвращают одинаковую информацию о состоянии кластера (да, бывает и по-другому). А остальные проблемы быстрее заметить по оповещениям сервисов-клиентов Redis.
Переезд
Как будем переезжать:
- В первую очередь, нужно подготовить библиотеку для работы с кластером. В качестве основы для версии на Gо мы взяли go-redis и немного изменили под себя. Реализовали Multi-методы через pipeline-ы, а также немного поправили правила повторения запросов. С версией для PHP возникло больше проблем, но в конечном счете мы остановились на php-redis. Недавно они внедрили поддержку кластера, и на наш взгляд она выглядит хорошо.
- Далее нужно развернуть сам кластер. Делается это буквально в две команды на основе конфигурационного файла. Подробнее настройку обсудим ниже.
- Для постепенного переезда мы используем dry-mode. Так как у нас есть две версии библиотеки с одинаковым интерфейсом (одна для обычной версии, другая для кластера), ничего не стоит сделать обертку, которая будет работать с отдельной версией и параллельно дублировать все запросы в кластер, сравнивать ответы и писать расхождения в логи (в нашем случае в NewRelic). Таким образом, даже если при выкатке кластерная версия сломается, наш production это не затронет.
- Выкатив кластер в dry-режиме, мы можем спокойно смотреть на график расхождений ответов. Если доля ошибок медленно, но верно движется к некоторой небольшой константе, значит, всё хорошо. Почему расхождения всё равно есть? Потому что запись в отдельной версии происходит несколько раньше, чем в кластере, и за счет микролага данные могут расходиться. Осталось только посмотреть на логи расхождений, и если все они объяснимы неатомарностью записи, то можно идти дальше.
- Теперь можно переключить dry-mode в обратную сторону. Писать и читать будем из кластера, а дублировать в отдельную версию. Зачем? В течение следующей недели хочется понаблюдать за работой кластера. Если вдруг выяснится, что в пике нагрузки есть проблемы, или мы что-то не учли, у нас всегда есть аварийный откат на старый код и актуальные данные в благодаря dry-mode.
- Осталось отключить dry-mode и демонтировать отдельную версию.
Экспертиза
Сначала кратко об устройстве кластера.
В первую очередь, Redis — key-value хранилище. В качестве ключа используются произвольные строки. В качестве значений могут использоваться числа, строки и целые структуры. Последних великое множество, но для понимания общего устройства нам это не важно.
Следующий после ключей уровень абстракции — слоты (SLOTS). Каждый ключ принадлежит одному из 16 383 слотов. Внутри каждого слота может быть сколько-угодно ключей. Таким образом, все ключи распадаются на 16 383 непересекающихся множеств.
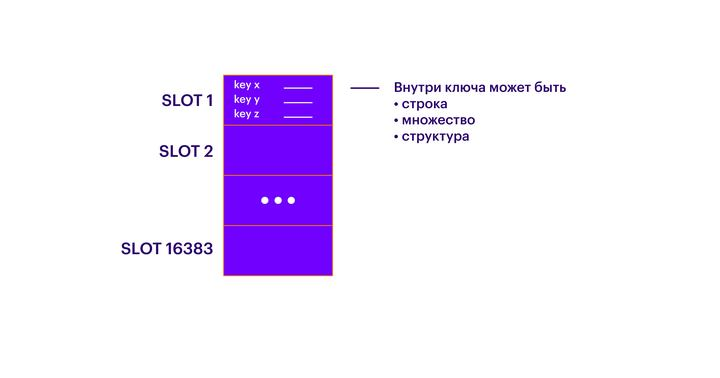
Далее, в кластере должно быть N мастер-нод. Каждую ноду можно представлять как отдельный инстанс Redis, который знает всё о других нодах внутри кластера. Каждая мастер-нода содержит некоторое количество слотов. Каждый слот принадлежит только одной мастер-ноде. Все слоты нужно распределить между нодами. Если какие-то слоты не распределены, то хранящиеся в них ключи будут недоступны. Каждую мастер-ноду имеет смысл запускать на отдельной логической или физической машине. Также стоит помнить, что каждая нода работает только на одном ядре, и если вы хотите запустить на одной логической машине несколько экземпляров Redis, то убедитесь, что они будут работать на разных ядрах (мы не пробовали так делать, но в теории все должно работать). По сути, мастер-ноды обеспечивают обычное шардирование, и большее количество мастер-нод позволяет масштабировать запросы на запись и чтение.
После того, как все ключи распределены по слотам, а слоты раскиданы по мастер-нодам, к каждой мастер-ноде можно добавить произвольное количество слейв-нод. Внутри каждой такой связки «мастер-слейв» будет работать обычная репликация. Cлейвы нужны для масштабирования запросов на чтение и для аварийного переключения в случае выхода из строя мастера.

Теперь поговорим об операциях, которые лучше бы уметь делать.
Обращаться к системе мы будем через Redis-CLI. Поскольку у Redis нет единой точки входа, выполнять следующие операции можно на любой из нод. В каждом пункте отдельно обращаю внимание на возможность выполнения операции под нагрузкой.
- Первое и самое главное, что нам понадобится: операция cluster nodes. Она возвращает состояние кластера, показывает список нод, их роли, распределение слотов и т.п. Дополнительные сведения можно получить с помощью cluster info и cluster slots.
- Хорошо бы уметь добавлять и удалять ноды. Для этого есть операции cluster meet и cluster forget. Обратите внимание, что cluster forget необходимо применить к КАЖДОЙ ноде, как к мастерам, так и к репликам. А cluster meet достаточно вызвать лишь на одной ноде. Такое различие может обескураживать, так что лучше узнать о нем до того, как запустили кластер в эксплуатацию. Добавление ноды безопасно выполняется в бою и никак не затрагивает работу кластера (что логично). Если же вы собираетесь удалить ноду из кластера, то следует убедиться, что на ней не осталось слотов (иначе вы рискуете потерять доступ ко всем ключам на этой ноде). Также не удаляйте мастер, у которого есть слейвы, иначе будет выполняться ненужное голосование за нового мастера. Если на нодах уже нет слотов, то это небольшая проблема, но зачем нам лишние выборе, если можно сначала удалить слейвы.
- Если нужно насильно поменять местами мастер и слейв, то подойдет команда cluster failover. Вызывая её в бою, нужно понимать, что в течение выполнения операции мастер будет недоступен. Обычно переключение происходит менее, чем за секунду, но не атомарно. Можете рассчитывать, что часть запросов к мастеру в это время завершится с ошибкой.
- Перед удалением ноды из кластера на ней не должно оставаться слотов. Перераспределять их лучше с помощью команды cluster reshard. Слоты будут перенесены с одного мастера, на другой. Вся операция может занимать несколько минут, это зависит от объема переносимых данных, однако процесс переноса безопасный и на работе кластера никак не сказывается. Таким образом, все данные можно перенести с одной ноды на другую прямо под нагрузкой, и не беспокоиться об их доступности. Однако есть и тонкости. Во-первых, перенос данных сопряжен с определенной нагрузкой на ноду получателя и отправителя. Если нода получателя уже сильно загружена по процессору, то не стоит нагружать её ещё и приемом новых данных. Во-вторых, как только на мастере-отправителе не останется ни одного слота, все его слейвы тут же перейдут к мастеру, на который эти слоты были перенесены. И проблема в том, что все эти слейвы разом захотят синхронизировать данные. И вам еще повезет, если это будет частичная, а не полная синхронизация. Учитывайте это, и сочетайте операции переноса слотов и отключения/переноса слейвов. Или же надейтесь, что у вас достаточный запас прочности.
- Что делать, если при переносе вы обнаружили, что куда-то потеряли слоты? Надеюсь, эта проблема вас не коснется, но если что, есть операция cluster fix. Она худо-бедно раскидает слоты по нодам в случайном порядке. Рекомендую проверить её работу, предварительно удалив из кластера ноду с распределенными слотами. Поскольку данные в нераспределенных слотам и так недоступны, беспокоиться о проблемах с доступностью этих слотов уже поздно. В свою очередь на распределенные слоты операция не повлияет.
- Еще одна полезная операция — monitor. Она позволяет в реальном времени видеть весь список запросов, идущих на ноду. Более того, по ней можно сделать grep и узнать, есть ли нужный трафик.
Также стоит упомянуть о процедуре аварийного переключения мастера. Если коротко, то она есть, и, на мой взгляд, прекрасно работает. Однако не стоит думать, что если выдернуть шнур из розетки на машине с мастер-нодой, Redis тут же переключится и клиенты не заметят потери. На моей практике переключение происходит несколько секунд. В течение этого времени часть данных будет недоступна: обнаруживается недоступность мастера, ноды голосуют за нового, слейвы переключаются, данные синхронизируются. Лучший способ убедиться самостоятельно в том, что схема рабочая, это провести локальные учения. Поднимите кластер на своем ноутбуке, дайте минимальную нагрузку, сымитируйте падение (например, заблокировав порты), оцените скорость переключения. На мой взгляд, только поиграв таким образом день-два, можно быть уверенным в работе технологии. Ну, или понадеяться, что софт, которым пользуется половина интернета, наверняка работает.
Конфигурация
Зачастую, конфигурация — первое, что нужно для начала работы с инструментом., А когда всё заработало, конфиг и трогать не хочется. Необходимы определенные усилия, чтобы заставить себя вернуться к настройкам и тщательно их прошерстить. На моей памяти у нас было как минимум два серьезных факапа из-за невнимательности к конфигурации. Обратите особое внимание на следующие пункты:
- timeout 0
Время, через которое закрываются неактивные соединения (в секундах). 0 — не закрываются
Не каждая наша библиотека умела корректно закрывать соединения. Отключив эту настройку, мы рискуем упереться в лимит по количеству клиентов. С другой стороны, если такая проблема есть, то автоматический разрыв потерянных соединений замаскирует её, и мы можем не заметить. Кроме того, не стоит включать эту настройку при использовании persist-соединений. - Save x y & appendonly yes
Сохранение RDB-снепшота.
Проблемы RDB/AOF мы подробно обсудим ниже. - stop-writes-on-bgsave-error no & slave-serve-stale-data yes
Если включено, то при поломке RDB-снепшота мастер перестанет принимать запросы на изменение. Если соединение с мастером потеряно, то слейв может продолжать отвечать на запросы (yes). Или прекратит отвечать (no)
Нас не устраивает ситуация, при которой Redis превращается в тыкву. - repl-ping-slave-period 5
Через этот промежуток времени мы начнем беспокоиться о том, что мастер сломался и пора бы провести процедуру failover’a.
Придется вручную находить баланс между ложными срабатываниями и запуском failover’а. На нашей практике это 5 секунд. - repl-backlog-size 1024mb & epl-backlog-ttl 0
Ровно столько данных мы можем хранить в буфере для отвалившейся реплики. Если буфер кончится, то придется полностью синхронизироваться.
Практика подсказывает, что лучше поставить значение побольше. Причин, по которым реплика может начать отставать, предостаточно. Если она отстает, то, скорей всего, ваш мастер уже с трудом справляется, а полная синхронизация станет последней каплей. - maxclients 10000
Максимальное количество единовременных клиентов.
По нашему опыту, лучше поставить значение побольше. Redis прекрасно справляется с 10 тыс. соединений. Только убедитесь, что в системе достаточно сокетов. - maxmemory-policy volatile-ttl
Правило, по которому удаляются ключи при достижения лимита доступной памяти.
Тут важно не само правило, а понимание, как это будет происходить. Redis можно похвалить за умение штатно работать при достижении лимита памяти.
Проблемы RDB и AOF
Хотя сам Redis хранит всю информацию в оперативной памяти, также есть механизм сохранения данных на диск. А точнее, три механизма:
- RDB-snapshot — полный слепок всех данных. Устанавливается с помощью конфигурации SAVE X Y и читается как «Сохранять полный снепшот всех данных каждые X секунд, если изменилось хотя бы Y ключей».
- Append-only file — список операций в порядке их выполнения. Добавляет новые пришедшие операции в файл каждые Х секунд или каждые Y операций.
- RDB and AOF — комбинация двух предыдущих.
У всех методов есть свои достоинства и недостатки, я не буду перечислять их все, лишь обращу внимания на не очевидные, на мой взгляд, моменты.
Во-первых, для сохранения RDB-снепшота требуется вызывать FORK. Если данных много, это может повесить весь Redis на период от нескольких миллисекунд до секунды. Кроме того, системе требуется выделить память под такой снепшот, что приводит к необходимости держать на логической машине двойной запас по оперативной памяти: если для Redis выделено 8 Гб, то на виртуалке с ним должно быть доступно 16.
Во-вторых, есть проблемы с частичной синхронизацией. В режиме AOF при переподключении слейва вместо частичной синхронизации может выполняться полная. Почему так происходит, я не смог понять. Но помнить об этом стоит.
Эти два пункта уже заставляют задуматься о том, а так ли нам нужны эти данные на диске, если и так всё дублируется слейвами. Потерять данные можно только при выходе из строя всех слейвов, а это проблема уровня «пожар в ДЦ». В качестве компромисса можно предложить сохранять данные только на слейвах, но в этом случае нужно убедиться, что эти слейвы никогда не станут мастером при аварийном восстановлении (для этого есть настройка приоритета слейвов в их конфиге). Для себя мы в каждом конкретном случае думаем над тем, надо ли сохранять данные на диск, и чаще всего отвечаем «нет».
Заключение
В заключении буду надеяться, что смог дать общее представление о работе redis-cluster-а тем, кто совсем о нем не слышал, а также обратил внимание на какие-то неочевидные моменты для тех, кто уже давно им пользуется.
Спасибо за уделенное время и, как обычно, комментарии по теме приветствуются.




