
Привет, Хабр и хабровчане! Меня зовут Владимир Григорьев, я директор по архитектуре Газпромбанка.
Сегодня хочу рассказать про фронт-платформу розницы Газпромбанка, в которой мы реализовали омниканальный подход для выставления продуктов в цифровых и традиционных каналах продаж. Это когда клиент начал свой путь в одном канале, продолжил в другом, а закончил в третьем — и не только пострадал при этом ни морально, ни физически, но и вообще не обнаружил проблем при переходе из одного канала в другой.
Омниканальная платформа (ОКП) — это стратегический и очень важный продукт для всей нашей розницы. Преимущества просматриваются сразу с нескольких сторон.
Для клиента
Благодаря реализации не целикового пользовательского сценария, а атомарных бизнес-операций достигается ощущение «ненавязанного» пользовательского опыта.
Во всех цифровых каналах функциональность идентична, кроме специфических особенностей канала или его интерфейса.
Доступность сервисов 24/7.
Для бизнеса
Снижение времени вывода новой функциональности за счет того, что у каждого бизнес-направления появляется возможность независимой разработки и вывода сервисов в продуктивное использование.
Возможность быстрой компоновки бизнес-процессов из четко определенных бизнес-сервисов.
Параллельное развитие бизнес-функций несколькими независимыми командами разработки. Доставка нового продукта (сервиса) до клиента сокращается до 3-х недель с того момента, когда закончено создание этого продукта или сервиса.
Для ИТ
Отсутствие коллизий с зависимостями одних сервисов от других.
Высокая степень стандартизации интерфейсов, реестра сервисов, системы мониторинга и поддержания жизнедеятельности сервисов позволяет беспрепятственно использовать различные технологические стеки.
Возможность масштабирования «на лету» сервисов которые испытывают высокую нагрузку.
Высокая степень отказоустойчивости, за счет резервирования каждого сервиса, а также наличия инструментов автоматического восстановления работоспособности сервисов, повышается до 99,9+ %.
Высокая скорость развертывания и запуска сервиса (сроки выхода на рынок сокращаются до 3-х недель).
Сейчас встретить платформу «в дикой природе» можно везде: звонок в контакт-центр, вставленная карта в банкомат, перевод денег, операции в мобильном или интернет банке — все это омниканальная платформа!

Как все устроено
Если взглянуть верхнеуровнево, то наша платформа немного напоминает слоеный пирог.
Верхний слой — слой каналов. Они могут находиться как в контуре банка, так и вне его. В каждом канале есть клиентская часть (с ней взаимодействует клиент) и бэковая (то, что развернула команда канала на своих системах и выставила API).
Ниже идет защитный слой, так называемый WAF (Web Application Firewall), с помощью которого осуществляется безопасная публикация универсальных сервисов вовне.
Слой ОКП — наша главная «начинка» этого пирога. На этом уровне реализована комплексная бизнес-логика в универсальных сервисах (УС), которые не зависят от канала. УС из данного слоя обмениваются информацией непосредственно с системами провайдеров (бэк-системами), связываясь с ними через интеграционный механизм (слой ниже) или через распределенное хранилище In Memory Data Grid по принципу cqrs. Стоит отметить, что на этом же уровне разместился Identity Provider ОКП, с помощью которого происходит аутентификация и авторизация пользователей.
Слой интеграции. Собирает отдельные простые сервисы банка в универсальную сервисную модель. Взаимодействие возможно посредством IBM MQ и через IMDG — DB Tarantool, реализованного коллегами из VK (ранее Mail Group).
Слой провайдеров сервисов. Строго говоря, это уже не ОКП, но для большего понимания и завершенности процесса пусть будет. Это бэковый слой, заключающий в себе разного рода приложения банка (учетные, справочные, платежные системы и другие), которые выступают провайдерами простых («fine grained») сервисов банка.
Идентификация
Основными пререквизитами для создания ОКП были переход на единый IDP во всех каналах и аналитический МДМ. IDP создан на классическом для таких решений ПО OpenAM.
Клиент, вводит свои учетные данные для аутентификации, получает легкий токен (SID), далее выбирает сценарий, по которому пойдет его взаимодействие с сервисами банка (получить продукт, информацию о счете и т.д). Внутренние сервисы банка не работают с SID (он небезопасен и формируется при прямом взаимодействии с клиентом), поэтому его необходимо заменить на полноценный JWT. Подмена происходит в IDP. В самом JWT будет информация о разрешениях и запретах для этой сессии. При каждом обращении к сервису ОКП OpenIG будет прочитывать JWT, понимать, что он не скомпроментирован, и разрешать те или иные действия с собой.
При проектировании сервисов мы использовали концепцию «стаканов» — каждый сервис закрывается своим OpenIG, размещенным максимально близко к защищаемому сервису (на том же сервере/поде). При такой реализации невозможно вызвать публикуемый сервис без проверки OpenIG, так как при вызове любого сервиса сначала запрос попадает на Nginx, который переадресовывает запросы на OpenIG для проверки авторизации.
Добавлю, что если сервис является публичным и не содержит в себе информации, относящейся к категории тайн, то для вызова такого сервиса токен не нужен. Точнее, при обращении к нему проверка не будет производится. Дополнительно в целях защиты от DDos-атак должно быть прописано ограничение на nginx публикатора сервисов.
Аналитический МДМ
Следующий пререквизит — аналитический МДМ. Мастер данных по клиентам банка для розничного домена — вещь крайне необходимая и полезная.
Тема систем МДМ не нова и описана в нескольких статьях на хабре (например: https://habr.com/ru/company/navicon/blog/260927/). Если коротко, мы решили пойти по этому же пути и внедрить решение, которое бы хранило в себе «золотую запись» по клиенту. Системы, получая запрос от клиента, сначала проверяют его наличие у нас в МДМ и только после того, как он не будет найден, дергают сервис «create/update client», передавая данные определенного формата. Далее МДМ будет заниматься нормализацией этих данных, сводить несколько профилей клиента в один (если есть необходимость), создавая «золотую запись». Когда одной из систем понадобятся актуальные данные по клиенту, они знают где и как их взять.
Что происходит под капотом МДМ? На изменение каждого поля у каждой системы есть определенный вес, и если пришло два изменения одного поля по одному клиенту, то оба весовых показателя сравниваются и в «золотую запись» попадает изменение с наивысшим весом. Условно, если пришло изменение по клиенту из канала «Дашборд» (это офис обслуживания клиентов, и, следовательно, там сотрудник получил информацию напрямую от клиента), его вес будет выше, чем, например, у изменения из каналов «Экосистема» или «Партнеры», где данные не верифицировались сотрудниками или взаимодействие с клиентом было удаленным.
Если автоматически провалидировать изменения система не смогла, то на этот случай есть внимательный Data Steward. Он берет такие кейсы и отвечает на вопрос «стоит ли вносить изменения по клиенту или это новый клиент».
Когда изменения по клиенту были акцептованы и внесены, в МДМ формируется обратный поток, который сообщает информацию по этим изменениям. Все системы, где фигурирует данный клиент, получают актуальные данные. Мы используем для этих целей событийный подход, все изменения отправляем в топик Кафки, а потребители вычитывают эти изменения.
В среднем на прохождение целого пучка разных правил и процесс дедупликации уходит до трех часов. То есть с временным лагом в 3 часа мы получаем актуальную «золотую запись» по каждому клиенту банка.
Я есть КРУД
При проектировании микросервисной архитектуры мы приняли решение пойти по пути информационной нарезки сервисов (cqrs — принцип разделения запросов).
Каждый сервис обязательно должен исполнять минимум одно из действий над своей сущностью из аббревиатуры CRUD (create, read, update, delete).

Также сервисы с бизнес-логикой должны быть отделены от сервисов технических (core services). У этих сервисов разные команды, разные биоритмы, и развиваются они по разному.
Например, технический сервис более статичен и обеспечивает оркестрацию запросов с фронта к сервисам с бизнес-логикой (продуктовым сервисам). В свою очередь, сервис с бизнес-логикой может релизиться хоть каждый день, что не повлияет на работу всей платформы. Добавляя новые сервисы в ландшафт, мы не усложняем логику всей системы.
Очевидно, что такой подход вносит некоторые ограничения для команд, которые хотят использовать нашу платформу, но плюсов гораздо больше, чем ограничений.
Если порассуждать и рассмотреть альтернативные подходы (например, один из наиболее известных — шаблон «Разбиение по бизнес-возможностям»), вырисовываются такой вполне реальный риск.
Допустим, мы разрабатываем сервис «Получение карты клиентом» для главной страницы мобильного и интернет-банка. Через некоторое время приходит команда кредитных карт, которая хочет переиспользовать этот сервис для подачи заявки на кредитную карту. Но им необходимо добавить несколько полей, например «Сумма», «Место работы» клиента и так далее. Нам это уже не так актуально, мы отправляем эту задачу в «бэклог бэклогов» и спокойно идем есть печеньки.
Очевидно, команде кредитных карт такой подход не по душе, и они форкают наш сервис, добавляя нужную функциональность. В итоге в омниканальной платформе плюс один сервис (так и вижу, как где-то в параллельной вселенной будущего времени сидит и плачет архитектор ОКП). Далее другая команда проводит аналогичный форк — и так еще несколько раз. В какой-то момент количество данных сервисов становится невыносимо большим, а некоторые, возможно, даже дублируют функциональность на 99%. Все эти сервисы опираются на одну и ту же сущность в учетной системе, и когда они начинают эволюционировать и развиваться, команды могут легко забыть, с чего все начиналось. И, конечно, нелегко понять, какая команда и как именно использует свой сервис. Все это усложняет и удорожает нашу платформу.
Именно для того, чтобы избежать хаотичного раздувания платформы и усложнения ландшафта, мы вычленили ряд core services.
Core services
Подача заявки клиентом в любом канале.
Когда продуктовый сервис производит онбординг (разворачивается на нашей ОКП), он сразу получает возможность выставлять информацию о своем продукте во всех каналах, подключенных в ОКП.
Платформа, в свою очередь, фиксирует каждое заявление клиента и хранит три года. Если клиент не закончил заполнение заявки, мы напомним ему об этом. А если клиент начал заполнение в одном канале и по каким-то причинам не отправил заявку на исполнение, то он может вернуться к заполнению этой заявки в любом другом доступном для него канале, пока этот черновик будет существовать (черновик — это незаполненное и не отправленное на исполнение заявление).
Информация о клиенте и его продуктах
Создаем и редактируем эту информацию. Добываем данные о клиенте и его продуктах по определенным стандартам, кэшируем данные. Системы-провайдеры данных не перегружены частыми обращениями, и у них нет необходимости обкладываться адаптерами для каждой новой «нестандартной системы».
Технические функции.
Авторизация и аутентификация клиента.
Мониторинг и логирование.
Служебные сервисы: медиаконтент, управление фичами, оповещение о недоступности и т.д.
Командам не нужно тратить ресурс на организацию нефункциональных требований, все это на себя берет платформа ОКП, где уже взрощена экспертиза по этим направлениям.
Коммуникация с клиентом
Взаимодействие реализуется по основным каналам взаимодействия. СМС/Push/Mail. Все это доступно «из коробки» продуктовым сервисам, которые выполняют условия онбординга:
Единый формат данных для всех сервисов-потребителей. (шесть нормальных форм — https://habr.com/ru/post/254773/)
Стандартный шаблон сервисов для наполнения бизнес-логикой.
Единые конвенции по разработки сервисов, библиотеки (springboot, hibernate, apache commons, swagger, java-jwt, log4j, liquibase, apache.pdfbox, lombok, Junit, redux*, react*, isomorphic-fetch).
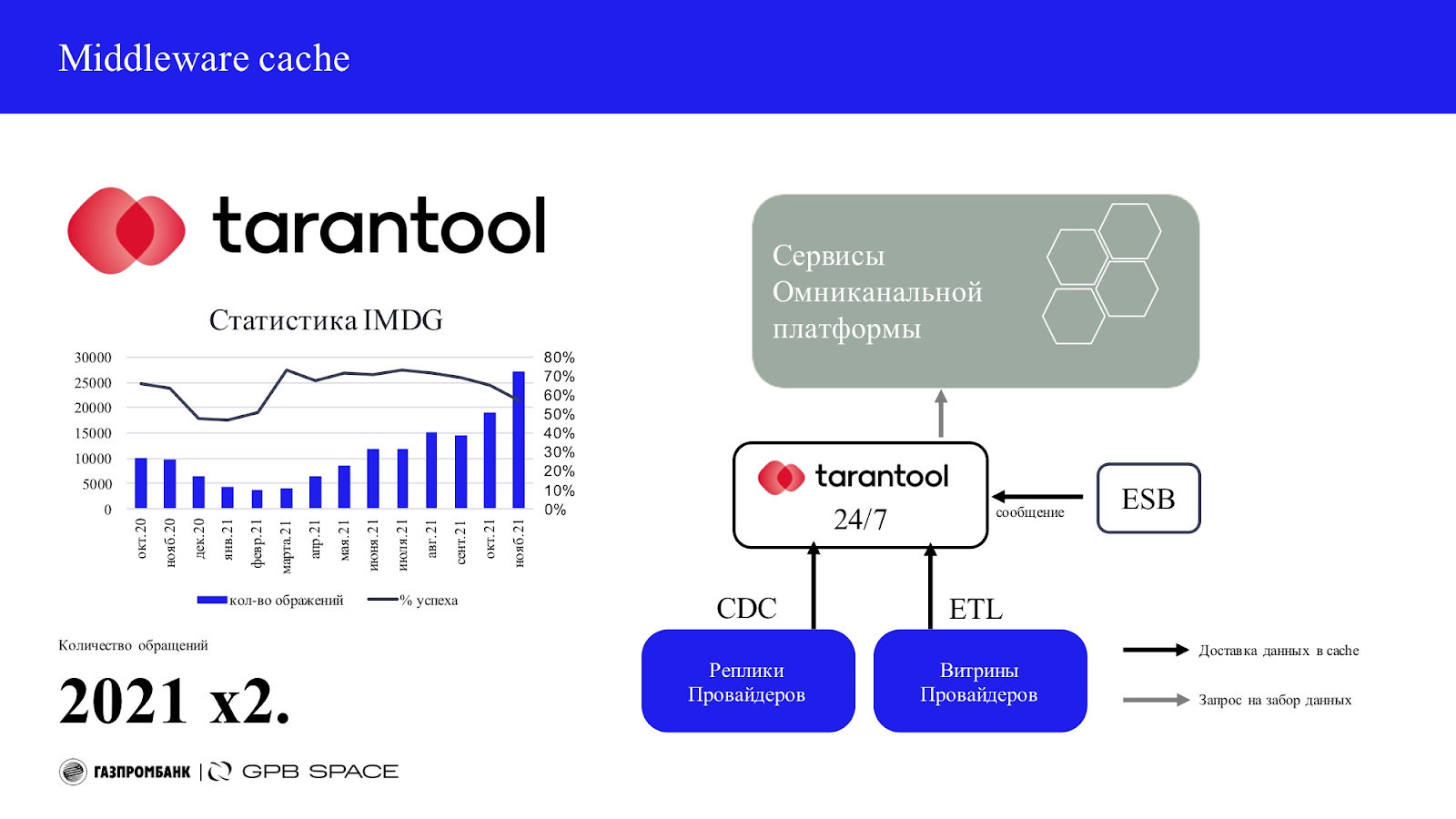
Middleware Cache
Для доступности информации в наших дистанционных каналах 24/7 мы используем middleware cache. Это in Memory Data Grid — БД Tarantool.
Этот кэш наполняется от поставщиков данных через CDC и витрины ETL. Также происходит атомарное наполнение кэша через ESB-шину.
Из-за имеющихся ограничений, для некоторых поставщиков, мы используем гибридный подход. Строим витрину на репликах систем поставщиков данных, которые, в свою очередь, наполняются через CDC. Это позволяет избежать команде IMDG более глубоко погружения в смежные системы и оставить логику наполнения витрин в зоне ответственности поставщика. Поставщик данных (бэк-система) сам подготавливает необходимые процедуры для наполнения витрины, а техническая учетная запись запускает их поочередно. После их выполнения стартует процесс обогащения кэша. В целевом виде планируем использовать CDC и только стриминг событий.
Вместе с запросом на получение клиентских данных сервису приходит директива о том, как именно их нужно достать. Основных стратегии три:
Первая и целевая для нас — зайти в кэш и проверить наличие данных. Если временной лаг по актуальности данных превышает пороговое значение, идти в АБС.
Вторая — мы не идем в АБС совсем и только проверяем кэш на наличие нужной информации (например, когда важна скорость получения данных, номер карты или продукт банка; обязательное условие при этом — данные редко изменяются).
Третья, когда мы не идем в кэш и стучимся в АБС за нужной информацией (например, запрос кодового слова клиента).
Так как системы, содержащие эти данные, высоконагружены и порой немножко легаси, невозможно обогащать актуальной информацией кэш с производственного стенда, поэтому данные идут с реплик. У такого подхода есть минусы, ведь мы получаем серьезную зависимость от самого процесса репликации. Если репликационный стенд по каким-то причинам отстанет, мы получим отставание в кэше. Не попадем во временной лаг актуальности и сильнее просадим производственный стенд по большому количеству обращений. Но такой риск перекрывается высокой производительностью.
Помимо клиентских данных в кэше находится информация по валютным курсам, которая, как мы знаем, изменяется в режиме онлайн. Для этих целей реализовано целых две очереди передачи информации в кэш: быстрая и медленная. Быстрая нужна для отдачи данных по курсам валют в режиме онлайн в дневное время, а медленная используется как резерв,а также предназначена для отдачи курсов валют в ночное время.
Потребность в кэше постоянно растет, например, актуализировать данные по картам клиентов необходимо раз в 1 минуту, а по депозитам и того чаще — раз в 15 секунд.
На графике выше мы видим, что запросы попадали в кэш в 70% случаев (от всех запросов в ОКП). Также видим трехкратный рост количественных показателей за 2021 год (левый столбец — количество обращений в тыс/мес). Актуальность кэш в нашем случае очевидна. Улучшения показателей утилизации кэш — одна из основных задач ОКП.
Tеchstack
Техстек платформы вполне стандартный для таких решений, в случае необходимости он расширяется. Мы ориентируемся на свободно распространяемое ПО .Планомерно внедряем практики CI/CD и переносим сервисы на Openshift.

В заключение
Наша платформа растет. Постоянно появляются новые сервисы и продукты. Почти 70% всех заявок на дебетовые и кредитные карты проходят через ОКП.
Проект НДБО (новый мобильный и интернет банкинг) более чем в два раза увеличит количество обращений к платформе. На данный момент мы фиксируем более 75 запросов в минуту, а новый нагрузочный профиль (+ НДБО) формируем из нагрузки свыше 160 обращений.
В этом посте я рассказал, как устроена наша омниканальная платформа в целом. Если вам интересно было бы узнать более детально про тот или иной аспект нашей ОКП, пишите в комментариях. Освещу эту тему подробнее.


")
