
Мы в ForePaaS уже какое-то время экспериментируем с DevOps — сначала в одной команде, а теперь и по всей компании. Причина проста: организация растет. Раньше у нас была всего одна команда на все случаи жизни. Она занималась архитектурой, проектированием и безопасностью продукта и быстро реагировала на любые проблемы. Сейчас мы разделились на несколько команд по специализации: фронтенд, бэкенд, разработка, эксплуатация…
Мы поняли, что наши прежние методы будут не так эффективны и нужно что-то менять, при этом сохранить скорость без ущерба для качества и наоборот.
Раньше девопсами мы называли команду, которая, по сути, делала Ops, а еще отвечала за разработки на бэкенде. Раз в неделю другие разработчики говорили команде DevOps, какие новые сервисы надо задеплоить в продакшене. Иногда это приводило к проблемам. С одной стороны, команда DevOps не очень понимала, что происходит у разработчиков, с другой — разработчики не чувствовали ответственность за свои сервисы.
В последнее время ребята из DevOps старались пробудить в разработчиках эту ответственность — за доступность, надежность и качество кода сервисов. Для начала нам надо было успокоить разработчиков, встревоженных свалившимся на них грузом. Им нужно было больше информации для диагностики возникающих проблем, так что мы решили реализовать мониторинг системы.
В этой статье мы поговорим о том, что такое мониторинг и с чем его едят, узнаем о так называемых четырех золотых сигналах и обсудим, как использовать метрики и детализацию drill-down, чтобы изучить текущие проблемы.
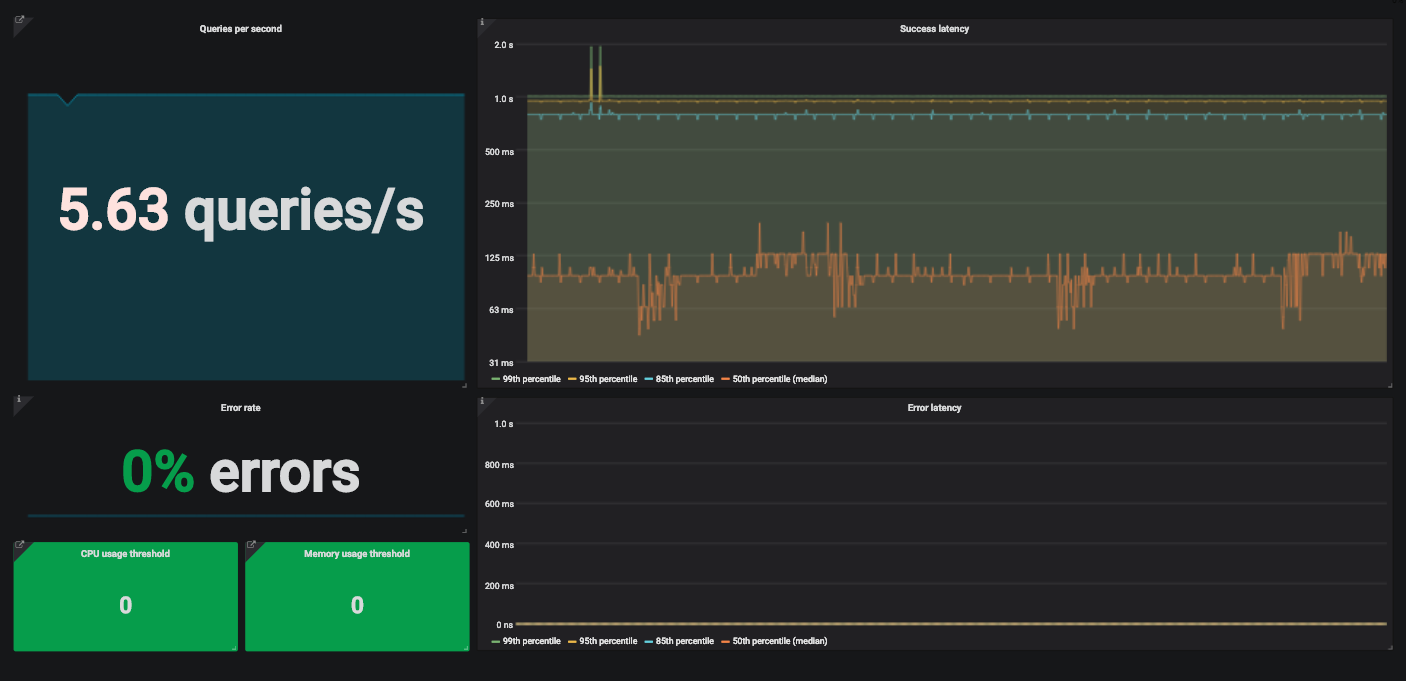
Пример панели мониторинга Grafana с четырьмя золотыми сигналами для мониторинга сервиса.
Что такое мониторинг?
Мониторинг — это создание, сбор, объединение и использование метрик, которые позволяют получить представление о состоянии системы.
Для мониторинга системы нам нужна информация о ее программных и аппаратных компонентах. Такую информацию можно получить через метрики, собранные с помощью специальной программы или инструментирования кода.
Инструментирование — это изменение кода таким образом, чтобы можно было измерить его производительность. Мы добавляем код, который не влияет на функции самого продукта, а просто вычисляет и предоставляет метрики. Допустим, мы хотим измерить задержку запроса. Добавляем код, который посчитает, сколько времени нужно сервису, чтобы обработать полученный запрос.
Созданную таким образом метрику нужно еще собрать и объединить с другими. Эта задача обычно решается с помощью Metricbeat для сбора и Logstash для индексирования метрик в Elasticsearch. Потом эти метрики можно использовать в своих целях. Обычно этот стек дополняет Kibana, которая визуализирует данные, индексированные в Elasticsearch.
Зачем мониторить?
Мониторить систему нужно по разным причинам. Мы, например, следим за текущим статусом системы и его вариациями, чтобы генерировать оповещения и заполнять панели мониторинга. Получая оповещение, мы ищем причины сбоя на панели мониторинга. Иногда мониторинг используют для сравнения двух версий сервисов или анализа долгосрочных трендов.
Что мониторить?
В книге Site Reliability Engineering есть полезная глава про мониторинг распределенных систем, где описан подход Google, основанный на отслеживании «четырех золотых сигналов» (Four Golden Signals).

Beyer, B., Jones C., Murphy, N. & Petoff, J. (2016) Site Reliability Engineering. How Google runs production systems. O’Reilly. Бесплатная онлайн-версия: https://landing.google.com/sre/sre-book/toc/index.html
- Задержка — сколько времени занимает обработка запроса. Мы отдельно отслеживаем задержки при успешном выполнении и при ошибке. Успешное выполнение — это очевидная метрика, но и ошибки хотелось бы получать быстрее.
- Трафик — общая картина загруженности сервиса запросами. Для API это число запросов в секунду. Для стримингового сервиса с музыкой это объем данных, передаваемый в секунду.
- Ошибки. Ошибки могут быть явными (например, 500-е коды ошибок) или неявными. Неявная ошибка — это когда мы получаем ответ, но не с тем содержимым или со слишком большой задержкой.
- Насыщенность, или загруженность, нашего сервиса. Сколько еще нагрузки он выдержит? Обычно сервис ограничен ресурсами процессора или памяти. За этими ограничениями надо следить. В базе данных, например, нужно отслеживать свободное пространство.
Как мониторить?
Возьмем, например, стек технологий. Обычно мы выбираем популярные стандартные инструменты вместо кастомных решений. Кроме случаев, когда доступного функционала нам недостаточно. Большинство сервисов мы деплоим в средах Kubernetes и инструменируем код, чтобы получать метрики о каждом кастомном сервисе. Чтобы собрать эти метрики и подготовить их для Prometheus, мы используем одну из клиентских библиотек Prometheus. Там есть клиентские библиотеки почти для всех популярных языков. В документации можно узнать все необходимое, чтобы написать свою библиотеку.
Если это сторонний опенсорс-сервис, мы обычно берем экспортеры, предложенные сообществом. Экспортеры — это код, который собирает метрики из сервиса и форматирует их для Prometheus. Обычно они используются с сервисами, которые не генерируют метрики в формате Prometheus.
Мы отправляем метрики по пайплайну и храним их в Prometheus в виде временных рядов. Кроме того, мы используем kube-state-metrics в Kubernetes, чтобы собирать и отправлять метрики в Prometheus. Затем мы можем создавать дашборды и алерты в Grafana, используя запросы к Prometheus. Вдаваться в технические детали мы здесь не будем, поэкспериментируйте с этим инструментами сами. У них подробная документация, вы легко разберетесь.
Для примера давайте рассмотрим простой API, который получает трафик и обрабатывает полученные запросы с помощью других сервисов.
Задержка
Задержка — это время, которое занимает обработка запроса. Мы отдельно измеряем задержку для успешно выполненных запросов и для ошибок. Мы не хотим, чтобы эта статистика смешивалась.
Обычно учитывается общая задержка, но не всегда это хороший выбор. Лучше отслеживать распределение задержки, потому что оно больше соответствует требованиям к доступности. Доля запросов, которые обрабатываются быстрее заданного порога, — это распространенный показатель уровня обслуживания (SLI). Вот пример целевого уровня обслуживания (SLO) для этого SLI:
«В течение 24 часов 99% запросов должны обрабатываться быстрее, чем за 1 секунду»
Самый наглядный способ представить метрики задержки — график временных рядов. Мы помещаем метрики в бакеты, и экспортеры собирают их каждую минуту. Таким образом можно рассчитать n-квантили для задержек сервисов.
Если 0 < n < 1, а на графике представлено q значений, n-квантиль этого графика равен значению, которое не превышает n*q из q значений. То есть медианный, 0,5-квантиль графика с числом записей x равен значению, которое не превышает половина из x записей.
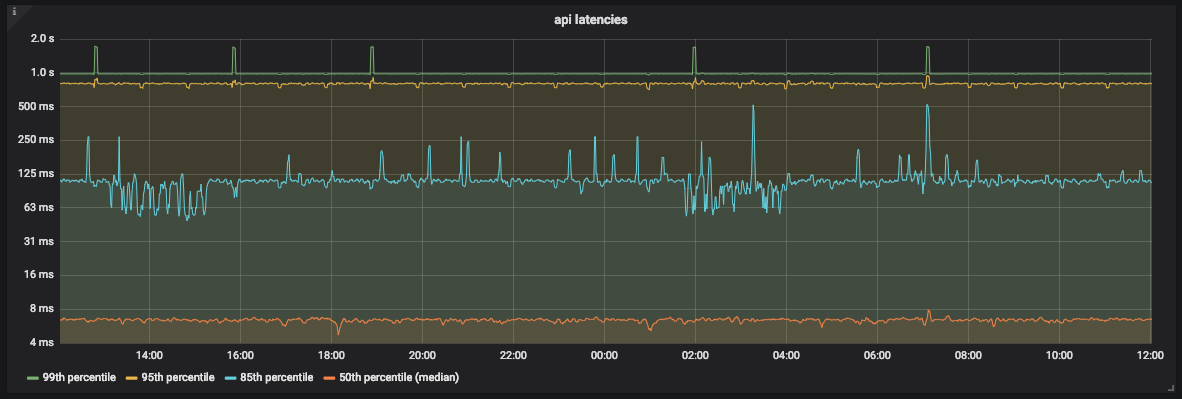
График задержек для API
Как видно на графике, большую часть времени API обрабатывает 99% запросов меньше, чем за 1 секунду. Однако есть и пики в районе 2 секунд, которые не соответствуют нашему SLO.
Раз мы используем Prometheus, нужно очень аккуратно выбирать размер бакета. Prometheus допускает линейный и экспоненциальный размер бакета. Не важно, что мы выберем, если учитываются погрешности оценки.
Prometheus не дает для квантиля точное значение. Он определяет, в каком бакете находится квантиль, а затем использует линейную интерполяцию и вычисляет примерное значение.
Трафик
Чтобы измерить трафик для API, нужно подсчитать, сколько запросов он получает каждую секунду. Поскольку мы собираем метрики раз в минуту, точно значение для конкретной секунды мы не получим. Зато можем рассчитать среднее число запросов в секунду с помощью функций rate и irate в Prometheus.
Чтобы отобразить эту информацию, мы используем панель Grafana SingleStat. На ней можно просмотреть текущее среднее число запросов в секунду и тренды.

Пример панели Grafana SingleStat с числом запросов, которое наш API получает в секунду
Если число запросов в секунду внезапно изменится, мы это увидим. Если за несколько минут трафик сократится в два раза, мы поймем, что возникла проблема.
Ошибки
Долю явных ошибок рассчитать легко — делим ответы HTTP 500 на общее число запросов. Как и для трафика, здесь мы используем усредненное значение.
Интервал нужно выбрать такой же, как для трафика. Так будет проще отслеживать трафик с ошибками на одной панели.
Допустим, за последние пять минут доля ошибок составляет 10% и API обрабатывает 200 запросов в секунду. Легко посчитать, что, в среднем, возникало по 20 ошибок в секунду.
Насыщенность
Для мониторинга насыщенности нужно определить ограничения сервиса. Для нашего API мы начали с измерения ресурсов и процессора, и памяти, потому что не знали, что влияет больше. Механизмы Kubernetes и kube-state-metrics позволяют получать эти метрики для контейнеров.
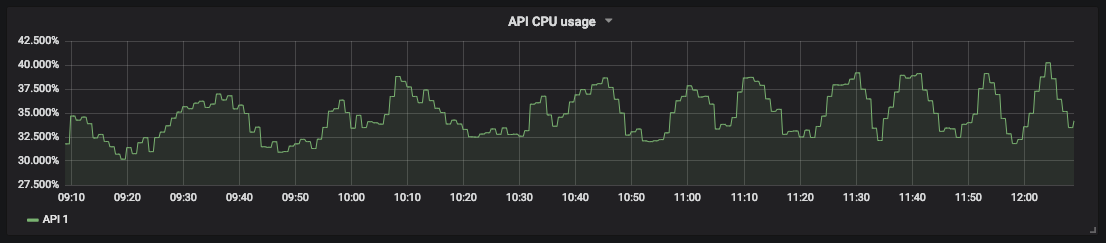
График использования ресурсов ЦП для нашего API
Измерение насыщенности позволяет прогнозировать простои и планировать ресурсы. Например, для хранилища базы данных можно измерять свободное место на диске и скорость его заполнения, чтобы понять, когда нужно принимать меры.
Детализированные панели для мониторинга распределенных сервисов
Давайте рассмотрим другой сервис. Например, распределенный API, который действует как прокси для других сервисов. У этого API несколько инстансов в разных регионах и несколько конечных точек. Каждая из них зависит от своего набора сервисов. Вскоре становится довольно сложно читать графики с десятками рядов. Нам нужна возможность мониторить систему целиком, а в случае необходимости обнаруживать отдельные сбои.
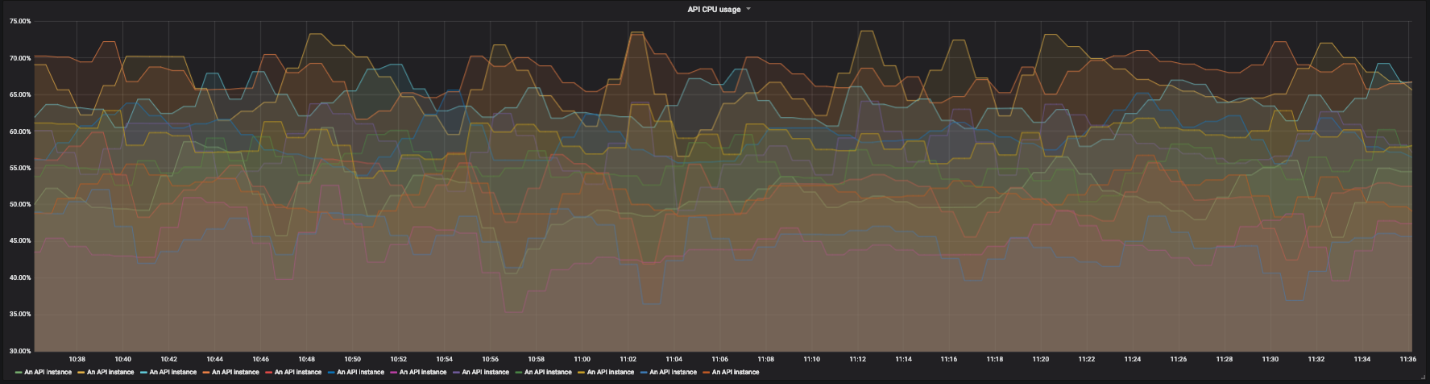
График использования ресурсов ЦП для 12 инстансов нашего API
Для этого мы используем панели мониторинга с детализацией. На каждом экране одной панели мы видим глобальное представление системы и можем нажимать на отдельные элементы, чтобы изучить детали. Для насыщенности мы используем не графики, а просто цветные прямоугольники, показывающие использование ресурсов процессора и памяти. Если использование ресурсов превышает заданный порог, прямоугольник становится оранжевым.

Индикаторы использования процессора и памяти для инстансов API
Нажимаем на прямоугольник, переходим к деталям и видим несколько цветных прямоугольников, обозначающих разные инстансы API.

Индикаторы использования процессора для инстансов API
Если проблема только у одного инстанса, можем нажать на прямоугольник и узнать еще больше подробностей. Тут мы видим регион инстанса, полученные запросы и так далее.

Детализированное представление состояния инстанса API. Слева направо, сверху вниз: регион провайдера, имя хоста инстанса, дата последнего перезапуска, число запросов в секунду, использование ресурсов процессора, использование ресурсов памяти, общее число запросов на путь и общий процент ошибок на путь.
То же самое делаем с процентом ошибок — нажимаем и смотрим процент ошибок для каждой конечной точки API, чтобы понять, где проблема — в самом API или сервисах, с которыми он связан.
То же самое мы сделали для задержек успешных запросов и ошибок, хотя здесь есть нюансы. Главная цель — убедиться, что с сервисом все в порядке в глобальном масштабе. Проблема в том, что у API много разных конечных точек, каждая из которых зависит от нескольких сервисов. У каждой конечной точки свои задержки и свой трафик.
Хлопотно настраивать отдельные SLO (и SLA) для каждой конечной точки сервиса. У некоторых конечных точек номинальная задержка будет выше, чем у других. В этом случае может понадобиться рефакторинг. Если требуются отдельные SLO, нужно разделить целый сервис на сервисы поменьше. Возможно, мы увидим, что охват нашего сервиса был слишком широким.
Мы решили, что лучше всего мониторить общую задержку. Возможность детализации просто позволяет изучить проблему, когда отклонения задержки настолько большие, что привлекают внимание.
Заключение
Мы уже некоторое время используем эти методы для мониторинга систем и заметили, что уменьшилось количество времени, затрачиваемого на обнаружение проблем и среднее время до восстановления (MTTR). Детализация позволяет найти фактическую причину глобальной проблемы, и для нас эта возможность многое изменила.
Другие команды разработчиков тоже стали применять эти методы и видят в них только преимущества. Теперь они не просто несут ответственность за работу своих сервисов. Они пошли еще дальше и могут определять, как изменения в коде влияют на поведение сервисов.
Четыре золотых сигнала не решают вообще все проблемы, но очень помогают с самыми распространенными из них. Почти не приложив усилий, мы смогли существенно улучшить мониторинг и сократить MTTR. Добавляйте столько метрик, сколько нужно, лишь бы среди них было четыре золотых сигнала.



