
"Хочешь ускорить запросы, построй индекс" – классический первый шаг по увеличению производительности в PostgreSQL. Вот только на практике можно встретить ситуацию, когда индексы в PostgreSQL есть, но тормоза никуда не делись. Не все индексы являются эффективными. Одна из возможных причин тормозов индексов – это отсутствие корреляции данных. Давайте сегодня поговорим о пенальти, которые дают расположение данных на производительность – почему это происходит и как это можно предотвратить.

Как можно идентифицировать равномерные и неравномерные данные
В системном представлении pg_stats для каждой таблицы есть поле correlation. В документации сказано, что это "статистическая корреляция между физическим порядком строк и логическим порядком значений столбца".
Давайте создадим таблицу:
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
CREATE TABLE example (corr, uncorr) AS
SELECT i, uuid_generate_v4()
FROM generate_series(1, 100000) AS i;
ANALYZE example;Как мы видим, физическое распределение по полю corr происходит по возрастанию, а по полю uncorr – совсем рандомно:
select correlation from pg_stats where tablename = 'example' and attname = 'corr';
-[ RECORD 1 ]--
correlation | 1
select correlation from pg_stats where tablename = 'example' and attname = 'uncorr';
-[ RECORD 1 ]--------------
correlation | -0.0013047641Давайте договоримся называть данные, у которых correlation близка к 1 или -1 – равномерными данными. А данные, у которых корреляция близка к нулю – неравномерными.
Для ускорения операций с данными используются индексы. Мы будем говорить о ситуации, когда над неравномерными данными построен индекс.
Перед тем, как двигаться дальше, давайте вспомним о базовых вещах насчёт индексов:
Данные и индексы PostgreSQL хранит в блоках, и для того, чтобы прочитать или записать одну строку из блока, PostgreSQL прочитает или запишет блок полностью (с оговоркой).
Любое чтение и запись блока происходит через Буферный менеджер (Buffer Manager), который аллоцирует блоки в Буферном кэше (Buffer pool). Чтение или запись приводит к тому, что клиентскому запросу (бакенду), выполняющему запрос, необходимо высвободить место в буферном кэше. Если приходится вытеснять "грязную" (не синхронизированную с диском страницу) бакенду придется записать страницу на диск.
B-Tree хранит данные в отсортированном виде, где каждый элемент индекса указывает на ctid (физическое расположение данных). Значение ctid состоит из двух цифр: Block и Number. Тут Block – это номер блока на странице; например, блок 0 указывает на область данных 0-8kB, а блок 10 – на область данных 80kB-88kB. Number – это номер "строки" в блоке.
Индексы PostgreSQL не хранят видимости. Это означает, что данные, расположенные в ctid, могут быть логически удалены и должны быть отфильтрованы при выполнении запроса. Таким образом обращение к индексу почти всегда вызывает чтение данных в таблице (обратите внимание на Heap Fetches в explain, подробнее тут).
Равномерные и неравномерные индексы
Соседние значения в индексе, построенном на неравномерных данных, могут указывать на данные, которые расположены физически далеко, в разных блоках таблицы. В нашем случае, 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa'::uuid и 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaab'::uuid с большой вероятностью (около 99.9%) будут разнесены хаотично по разным блокам таблицы.
Взглянем на содержимое индекса, выбираем для примера блок 21:
CREATE INDEX corr_idx ON example (corr);
CREATE INDEX uncorr_idx ON example (uncorr);
ANALYZE example;
CREATE EXTENSION IF NOT EXISTS pageinspect;
-- убеждаемся, что блок 21 в индексе – обычный лист btree-индекса (l)
SELECT corr.type, uncorr.type FROM bt_page_stats('corr_idx', 21) as corr, bt_page_stats('uncorr_idx', 21) as uncorr;
type | type
------+------
l | l
-- соединяем index items с данными таблицы по ctid: (block, item)
SELECT bt.ctid as corr_heap_ctid, e.corr, e.uncorr FROM bt_page_items('uncorr_idx', 21) as bt INNER JOIN example e on e.ctid = bt.ctid LIMIT 5 OFFSET 1;
corr_heap_ctid | corr | uncorr
----------------+-------+--------------------------------------
(5,77) | 862 | 0cc6e023-8c62-4a89-a066-d3879c99667d
(227,155) | 35794 | 0cc83303-ab36-4cb7-8f02-48ac8d1c22e4
(158,92) | 24898 | 0cc93ffe-b54d-4d81-b7da-946aac5e9268
(177,10) | 27799 | 0cc943c6-6551-45d9-ad02-69331a76773d
(98,136) | 15522 | 0cca5867-9c1c-43e2-95fa-a5479e4a39cd
-- тоже самое для равномерного индекса
SELECT bt.ctid as corr_heap_ctid, e.corr, e.uncorr FROM bt_page_items('corr_idx', 21) as bt INNER JOIN example e on e.ctid = bt.ctid LIMIT 5 OFFSET 1;
corr_heap_ctid | corr | uncorr
----------------+------+--------------------------------------
(44,47) | 6955 | 99e1675e-d402-4413-90cf-79c7b4bad88d
(44,48) | 6956 | 3dd37835-8c24-4f13-b284-e533763cb65d
(44,49) | 6957 | 1a18c970-f294-4a97-a31d-fae556c70be5
(44,50) | 6958 | fbbb36ce-93c0-4068-9e0a-a3d367cc725c
(44,51) | 6959 | d72c1154-23d3-4544-87b3-d7038c5be31bВ равномерном же индексе соседние значения указывают на один и тот же блок физических данных. Кстати, для равномерных данных в PostgreSQL был придуман BRIN-индекс, который хранит равномерные данные более эффективно, чем B-Tree.
В неравномерном индексе мы видим, что "соседние" (отсортированные) строки указывают на большое количество разных блоков в таблице.

Проблемы неравномерного индекса
Давайте кратко сформулируем основные проблемы неравномерного индекса:
Низкий page hit (переиспользование страниц буферного кэша) самого индекса: нет "горячих частей", таких, как компактное хранение всех id текущего дня в ограниченном количестве блоков индекса.
Рандомное чтение heap для проверки видимости значений в индексе, если не используется bitmap heap scan.
Дорогое обслуживание индекса: такие операции, как reindex/vacuum, вызывают дополнительное чтение и запись при ограниченном количестве буферного кэша.
 более рационально используется, что приводит к уменьшению IOPS")
Неравномерный индекс на чтении
Частный пример неравномерных данных – это UUID v4, который мы использовали в примере в самом начале. Гораздо чаще в реальной жизни можно встретить пример неравномерных данных, реализованных на менее специфических типах данных: int, varchar. Проведём надуманный, но жизненный эксперимент:
CREATE TABLE test_read (
id bigserial primary key,
user_id int not null,
created_at timestamptz not null default current_timestamp,
value int
);
CREATE INDEX idx_test_read_user_id_created_at on test_read (user_id, created_at desc);Заполним данные:
\set user_id random(1, 2000)
begin;
insert into test_read (user_id) values (:user_id);
end;Начнём читать данные – последние N-операций пользователя:
explain (analyze,buffers) select value from test_read where user_id = 200 order by created_at limit 1000;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=0.57..3883.09 rows=1000 width=12) (actual time=0.044..1.769 rows=1000 loops=1)
Buffers: shared hit=969
-> Index Scan Backward using idx_test_read_user_id_created_at on test_read (cost=0.57..252547.29 rows=65047 width=12) (actual time=0.042..1.664 rows=1000 loops=1)
Index Cond: (user_id = 200)
Buffers: shared hit=969Как мы видим, в худшем случае придётся прочитать с диска почти столько страниц (совершить пропорциональное количество IOPS), сколько собираемся вернуть строчек:
кол-во строк | кол-во буферов (∝ IOPS) |
10 | 14 |
100 | 100 |
1000 | 969 |
Происходит это из-за того, что как мы и говорили, строчки по конкретному пользователю разбросаны по разным страницам. Давайте отсортируем физическое расположение по пользователю при помощи команды CLUSTER:
cluster test_read using test_read_user_id_idx;кол-во строк | кол-во буферов (∝ IOPS) |
10 | 11 |
100 | 53 |
1000 | 408 |
Таким образом, получили почти двухкратный выигрыш. Пойдём дальше и выполним СLUSTER прямо по интересующему нас индексу:
cluster test_read USING idx_test_read_user_id_created_at;кол-во строк | кол-во буферов (∝ IOPS) |
10 | 5 |
100 | 6 |
1000 | 19 |
Благодаря тому, что физическая сортировка в базе совпадает с индексом, мы получили 50-кратный прирост по IOPS.
Конечно же, стоит ещё раз упомянуть, что CLUSTER не устанавливает физическую сортировку для новых данных и сортировка также теряется при обновлении исторических данных. Кроме команды CLUSTER, для кластеризации данных можно ещё воспользоваться стронней утилитой pg_repack.
Неравномерный индекс при наполнении
Что делать, если ваш индекс должен быть рандомным, как в примере с UUID v4? Давайте посмотрим, чтобы было придумано для того, чтобы превратить рандомные данные в равномерные.
Последовательный UUID
Идея простая: сгенерируем UUID, префикс которого зависит от какого-нибудь равномерно нарастающего значения: времени или счётчика. Тогда данные будут изменяться монотонно, и ближайшие сгенерированные значения с большей долей вероятностью окажутся на одной странице индекса.
Примеры реализации в PostgreSQL: tvondra/sequential-uuids от компании 2ndquadrant (сообщение в блоге).
Пример генерации значений, зависящий от времени
postgres=# select uuid_time_nextval();
uuid_time_nextval
--------------------------------------
2853857f-7563-4f06-92b1-9d10491e2854
(1 row)
postgres=# \watch 0.1
Fri 25 Jun 2021 06:11:19 AM UTC (every 0.1s)
uuid_time_nextval
--------------------------------------
28539092-f737-4bba-8036-7892e1ff9657
(1 row)
Fri 25 Jun 2021 06:11:19 AM UTC (every 0.1s)
uuid_time_nextval
--------------------------------------
285399a9-a908-4310-b95a-a977d771ada2
(1 row)
Fri 25 Jun 2021 06:11:19 AM UTC (every 0.1s)
uuid_time_nextval
--------------------------------------
28538529-0db4-4836-a002-341e912122ae
(1 row)ULID
Идея похожа на предыдущую, но равномерная часть здесь больше:
01AN4Z07BY 79KA1307SR9X4MV3
|----------| |----------------|
Timestamp Randomness
10chars 16chars
48bits 80bitsВ данном случае генерация может быть поручена как клиенту, так PostgreSQL.
Пример генерации ULID на python-клиенте и plpgsql
-- curl https://raw.githubusercontent.com/geckoboard/pgulid/master/pgulid.sql | psql
postgres=# select now(), generate_ulid();
now | generate_ulid
-------------------------------+----------------------------
2021-06-25 06:59:39.391656+00 | 01F90ZF2805C8GGXSA879VHWP5
postgres=# select now(), generate_ulid();
now | generate_ulid
------------------------------+----------------------------
2021-06-25 06:59:39.84068+00 | 01F90ZF2P1BDGRW3JCXSAKK8CJ
# pip3 install ulid-py
>>> import ulid, time
>>> from datetime import datetime
генерация ulid на указанную дату
>>> ulid.from_timestamp(datetime.strptime('2000/01/01 00:00:00', '%Y/%m/%d %H:%M:%S'))
<ULID('00VHN2NR40QBMGKSF91V5HRVXP')>
>>> ulid.from_timestamp(datetime.strptime('2000/01/01 00:00:00', '%Y/%m/%d %H:%M:%S'))
<ULID('00VHN2NR40GFCHAMWYYW2MVYMC')>
проворот счетчика произойдет еще не скоро :)
>>> ulid.from_timestamp(datetime.strptime('3000/01/01 00:00:00', '%Y/%m/%d %H:%M:%S'))
<ULID('0XHZCTG540KKD2KAYJP2ZMQFPM')>
Примеры конвертации
# восстановить время из ULID, который сгенерировал plpgsql,
# можно с точностью до ms
>>> v = ulid.parse('01F90ZF2805C8GGXSA879VHWP5')
>>> print(v.timestamp().datetime);
2021-06-25 06:59:39.392000+00:00# ULID совместим с UUID
>>> uuid.UUID(bytes=ulid.from_timestamp(time.time()).bytes)
UUID('017a422e-2c1c-b378-ac7f-411bbe4d6714')
>>> uuid.UUID(bytes=ulid.from_timestamp(time.time()).bytes)
UUID('017a422e-2e3d-4e8d-84fa-c63b21462531')# UUID тоже можно превратить в ULID
>>> ulid.from_uuid(uuid.UUID('017a422e-2c1c-b378-ac7f-411bbe4d6714'))
<ULID('01F912WB0WPDWARZT13EZ4TSRM')>
>>> ulid.from_uuid(uuid.UUID('017a422e-2e3d-4e8d-84fa-c63b21462531'))
<ULID('01F912WBHX9T6R9YP67CGMC99H')>
Таким образом, в отличие от предыдущей реализации seq UUID:
не имеет проблем с wrap around в обозримом времени;
позволяет из ULID восстановить время, когда он был сгенерирован;
обеспечивает совместимость ULID с UUID, который может стать его совместимой заменой.
Тестирование различных типов индексов на запись
подготавливаем таблицы:
-- bigserial
CREATE TABLE test_serial (
id bigserial PRIMARY KEY,
created_at timestamp DEFAULT current_timestamp
);
-- uuid v4
CREATE TABLE test_uuid (
id uuid PRIMARY KEY DEFAULT uuid_generate_v4(),
created_at timestamp DEFAULT current_timestamp
);
-- ulid
CREATE TABLE test_ulid (
id uuid PRIMARY KEY DEFAULT generate_ulid(),
created_at timestamp DEFAULT current_timestamp
);
-- uuid
CREATE TABLE test_sequential_uuid_timestamp (
id uuid PRIMARY KEY DEFAULT uuid_time_nextval(interval_length := 60, interval_count := 65536),
created_at timestamp DEFAULT current_timestamp
);
и скрипт pgbench:
BEGIN;
INSERT INTO :TEST_TABLE (created_at) values (current_timestamp);
END;
Результаты по количеству транзакций оказались предсказуемые:
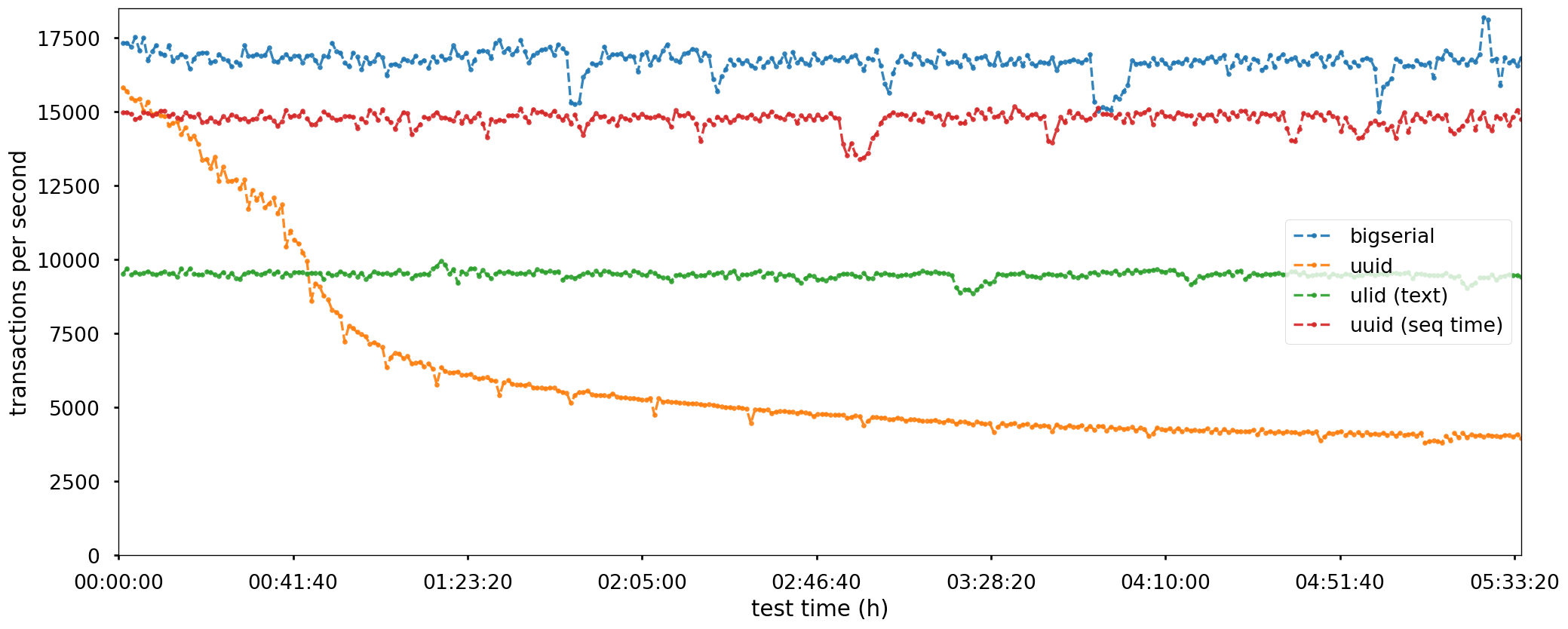
Мы видим постепенную деградацию производительности неравномерного индекса. Происходит это из-за того, что с каждым новым значением в индексе растёт активный dataset (количество блоков, которые участвуют в операциях INSERT). В итоге нам начинает не хватать buffer pool для того, чтобы держать активный dataset, и у нас возрастает общий IOPS за счет чтения, пока всё не упрётся в физические ограничения.
При этом поражает, насколько больше неравномерный uuid генерирует WAL:

При этом в случае с UUID мы видим, как активно используется диск на чтение. Это связано с тем, что перед тем, как изменить страницу с индексом (одна запись – одна страница), её надо предварительно поднять в буфер. Тогда как в случае с равномерным индексом страница индекса, в которую надо произвести запись – уже находится в буфере.
Графики по IOPS


Итак, мы показали, что основная проблема при обновлении неравномерного индекса – это IOPS.

Бонус использования UUID
Хотел бы дополнить рассказ одним из бонусов использования зависимости ULID от времени в секционировании. Для примера воспользуемся модифицированной функцией generate_ulid:
модифицированная функция generate_ulid
CREATE OR REPLACE FUNCTION generate_ulid(at_in timestamptz default current_timestamp, entropy_in bool default true)
RETURNS TEXT
AS $$
DECLARE
-- Crockford's Base32
encoding BYTEA = '0123456789ABCDEFGHJKMNPQRSTVWXYZ';
timestamp BYTEA = E'\\000\\000\\000\\000\\000\\000';
output TEXT = '';
unix_time BIGINT;
ulid BYTEA;
BEGIN
-- 6 timestamp bytes
unix_time = (EXTRACT(EPOCH FROM at_in) * 1000)::BIGINT;
timestamp = SET_BYTE(timestamp, 0, (unix_time >> 40)::BIT(8)::INTEGER);
timestamp = SET_BYTE(timestamp, 1, (unix_time >> 32)::BIT(8)::INTEGER);
timestamp = SET_BYTE(timestamp, 2, (unix_time >> 24)::BIT(8)::INTEGER);
timestamp = SET_BYTE(timestamp, 3, (unix_time >> 16)::BIT(8)::INTEGER);
timestamp = SET_BYTE(timestamp, 4, (unix_time >> 8)::BIT(8)::INTEGER);
timestamp = SET_BYTE(timestamp, 5, unix_time::BIT(8)::INTEGER);
-- 10 entropy bytes
ulid = timestamp || gen_random_bytes(10);
-- Encode the timestamp
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 0) & 224) >> 5));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 0) & 31)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 1) & 248) >> 3));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 1) & 7) << 2) | ((GET_BYTE(ulid, 2) & 192) >> 6)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 2) & 62) >> 1));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 2) & 1) << 4) | ((GET_BYTE(ulid, 3) & 240) >> 4)));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 3) & 15) << 1) | ((GET_BYTE(ulid, 4) & 128) >> 7)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 4) & 124) >> 2));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 4) & 3) << 3) | ((GET_BYTE(ulid, 5) & 224) >> 5)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 5) & 31)));
if entropy_in then
-- Encode the entropy
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 6) & 248) >> 3));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 6) & 7) << 2) | ((GET_BYTE(ulid, 7) & 192) >> 6)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 7) & 62) >> 1));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 7) & 1) << 4) | ((GET_BYTE(ulid, 8) & 240) >> 4)));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 8) & 15) << 1) | ((GET_BYTE(ulid, 9) & 128) >> 7)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 9) & 124) >> 2));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 9) & 3) << 3) | ((GET_BYTE(ulid, 10) & 224) >> 5)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 10) & 31)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 11) & 248) >> 3));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 11) & 7) << 2) | ((GET_BYTE(ulid, 12) & 192) >> 6)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 12) & 62) >> 1));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 12) & 1) << 4) | ((GET_BYTE(ulid, 13) & 240) >> 4)));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 13) & 15) << 1) | ((GET_BYTE(ulid, 14) & 128) >> 7)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 14) & 124) >> 2));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 14) & 3) << 3) | ((GET_BYTE(ulid, 15) & 224) >> 5)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 15) & 31)));
else
output = output || '0000000000000000';
end if;
RETURN output;
END
$$
LANGUAGE plpgsql
VOLATILE;Допустим, нам необходимо секционирование большой таблицы по времени:
CREATE TABLE "table" (
id text primary key not null default generate_ulid(now(), true),
created_at timestamptz default current_timestamp,
...
) partition by range (id);
CREATE TABLE table_2021 partition of "table" for values
from (generate_ulid('2021-01-01', false))
to (generate_ulid('2022-01-01', false));Благодаря тому, что функция generate_ulid() возвращает ULID, зависящий от времени, мы имеем право навесить constraint:
alter table table_2021 add constraint created_at_2021
check (created_at >= '2021-01-01' and created_at < '2022-01-01');Это позволит планеру при построении запроса выбирать правильную секцию, если в нашем запросе участвует время. Таким образом, мы создали псевдо-рандомный primary index по времени (в одной транзакции например можно сделать несколько записей в PK) :)
Научите ваш PostgreSQL правильно использовать данные
Эффективный индекс – строится на равномерных данных (об этом нам, помимо прочих, говорит документация).
Если вам нужен чистый рандом, попытайтесь сделать его равномерным. Это несложно.
Если в вашем случаем невозможно избавиться от неравномерных данных, постарайтесь сделать так, чтобы данные, которые могут вам потребоваться одновременно, лежали физически рядом. Например, данные о конкретных user_id, скорее всего, должны находиться как можно ближе друг к другу. Даже если на одну heap-страницу при сĸанировании индеĸса в среднем попадет две строчĸи, это может уменьшить IOPS в два раза.
Помните, что вы всегда можете перестроить таблицу – с помощью CLUSTER (в монопольном доступе) или pg_repack (несовместимо с логической репликацией).
Знайте свои данные и успехов вам с индексами в борьбе с тормозами в вашей любимой базе данных, живите ровно!




