Решение задач с анаграммами натолкнуло на мысль:
В найденном словаре больше 1,5 млн слов в различных формах
Можно сравнить каждое слово с каждым, но для 1,5 млн записей это долго и неоптимально.
В мире с бесконечной памятью можно сгенерировать подстроки всех перестановок каждого слова и проверить наш словарь на них
Но есть ли решение получше?
Начнем с терминологии:
Анаграмма — слово, получаемое перестановкой букв
Пример: ракета и карета
Сабанаграмма — слово, которое можно составить из букв другого слова
Пример: арка — сабанаграмма слова ракета
Задача:
Допустим наш словарь состоит из пяти хитрых слов:
ракета, карета, арка, кот, мокрота
Добавляем словарь в префиксное дерево (Trie)
Каждый узел дерева содержит пару: буква + ее количество в слове
Узлы отсортированы по алфавиту и частоте буквы в слове
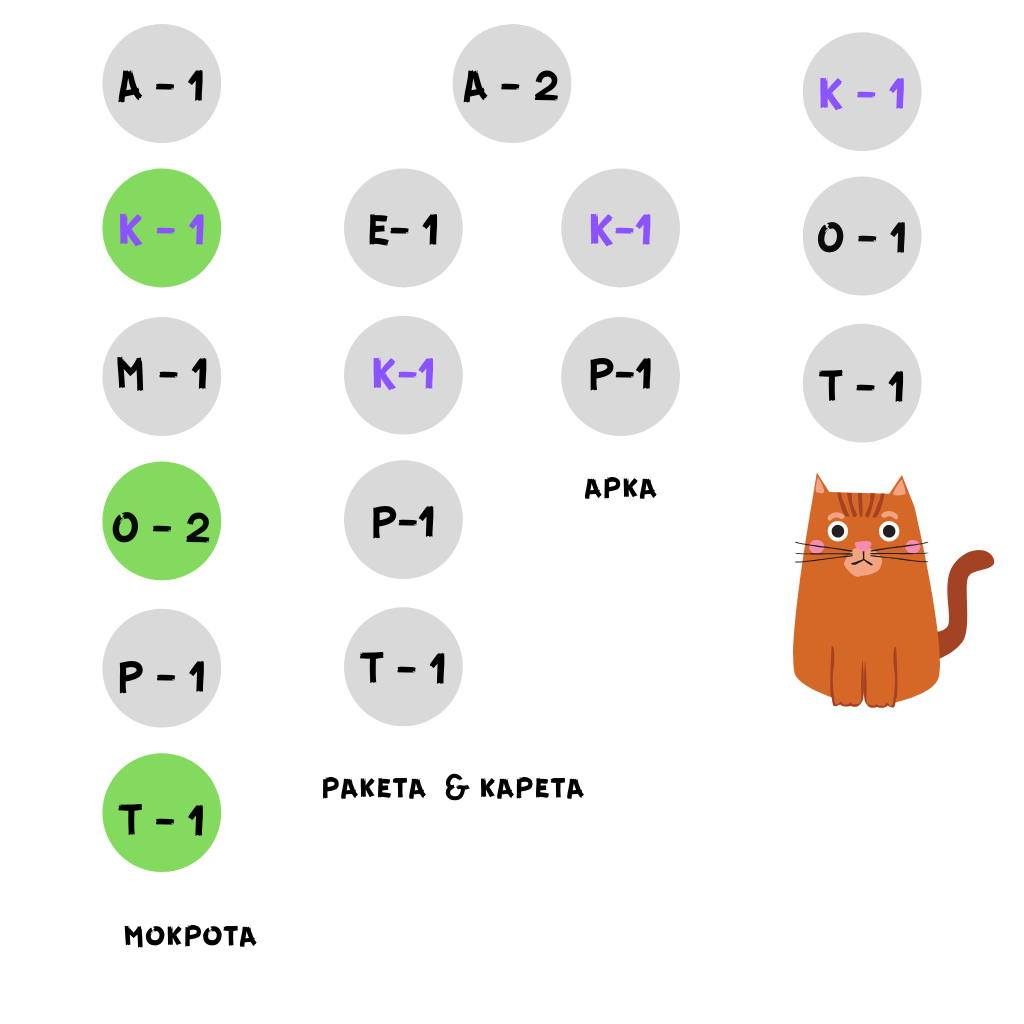
Алгоритм (в упрощенной форме):
Берем слово, н.р. кот:
Ищем узлы, начинающиеся на минимальную букву слова («к»)
(На рисунке такие узлы отмечены сиреневым)
Как только мы нашли такой узел, ищем в поддереве путь, содержащий оставшиеся буквы в нужном количестве
В слове мокрота ниже узла K-1 есть O-2 и Т-1, что для нашего слова кот достаточно
Преимущество такой структуры данных в том, что мы можем быстро выходить из поддерева, если буква узла > чем искомая буква
Проверив наш словарь, мы выяснили, что только мокрота не является анаграммой или сабанаграммой другого слова
Полная версия кода с двумя словарями и тестами
P.S.
Для русского словаря от 1.5 млн. осталось 242399 слов за 13 минут
Для английского словаря от 416 тыс. осталось 49251 за 45 секунд
Можно оптимизировать исходный словарь, убрав из него текущее слово если следующее с него начинается
Сколько останется слов, если удалить все анаграммы и сабанграммы из словаря русского языка
В найденном словаре больше 1,5 млн слов в различных формах
Можно сравнить каждое слово с каждым, но для 1,5 млн записей это долго и неоптимально.
В мире с бесконечной памятью можно сгенерировать подстроки всех перестановок каждого слова и проверить наш словарь на них
Но есть ли решение получше?
Начнем с терминологии:
Анаграмма — слово, получаемое перестановкой букв
Пример: ракета и карета
Сабанаграмма — слово, которое можно составить из букв другого слова
Пример: арка — сабанаграмма слова ракета
Задача:
Допустим наш словарь состоит из пяти хитрых слов:
ракета, карета, арка, кот, мокрота
Добавляем словарь в префиксное дерево (Trie)
Каждый узел дерева содержит пару: буква + ее количество в слове
Узлы отсортированы по алфавиту и частоте буквы в слове
Алгоритм (в упрощенной форме):
Берем слово, н.р. кот:
Ищем узлы, начинающиеся на минимальную букву слова («к»)
(На рисунке такие узлы отмечены сиреневым)
Как только мы нашли такой узел, ищем в поддереве путь, содержащий оставшиеся буквы в нужном количестве
В слове мокрота ниже узла K-1 есть O-2 и Т-1, что для нашего слова кот достаточно
Преимущество такой структуры данных в том, что мы можем быстро выходить из поддерева, если буква узла > чем искомая буква
Проверив наш словарь, мы выяснили, что только мокрота не является анаграммой или сабанаграммой другого слова
Код на Java
public boolean isAnagramOrSubAnagram(Word word) {
Character minCharacter = word.getMinCharacter();
Stack<TrieNode> stack = new Stack<>();
stack.add(root);
while (!stack.isEmpty()) {
TrieNode node = stack.pop();
for (Entry<TrieKey, TrieNode> entry : node.getChildren().entrySet()) {
char character = entry.getKey().getCharacter();
if (character < minCharacter) {
stack.add(entry.getValue());
} else if (character > minCharacter) {
break;
} else if (entry.getKey().getCount() >= word.getCharacterCount(minCharacter)) {
if (doesMinWordCharacterNodeContainAnagram(entry, word)) {
return true;
}
}
}
}
return false;
}
Полная версия кода с двумя словарями и тестами
P.S.
Для русского словаря от 1.5 млн. осталось 242399 слов за 13 минут
Для английского словаря от 416 тыс. осталось 49251 за 45 секунд
Можно оптимизировать исходный словарь, убрав из него текущее слово если следующее с него начинается



