
Во времена повсеместной одержимости библиотеками и веб-фреймворками мы стали забывать радость от решения задач минимальными средствами. В этой статье, мы запилим веб-сервис на актуальную тему, используя ванильные Python и JavaScript, а также, задеплоим его в GitLab Pages. Быстро, минималистично, без лишних зависимостей, и максимально элегантно.
Вдохновившись видосом How To Tell If We're Beating COVID-19 от minutephysics, я набросал в свободное (от удаленной работы и домашних дел) время сервис, который на основе данных с Карты распространения коронавируса в России и мире от Яндекса строит графики, аналогичные тем, что на странице Covid Trends. Вот, что из этого вышло:
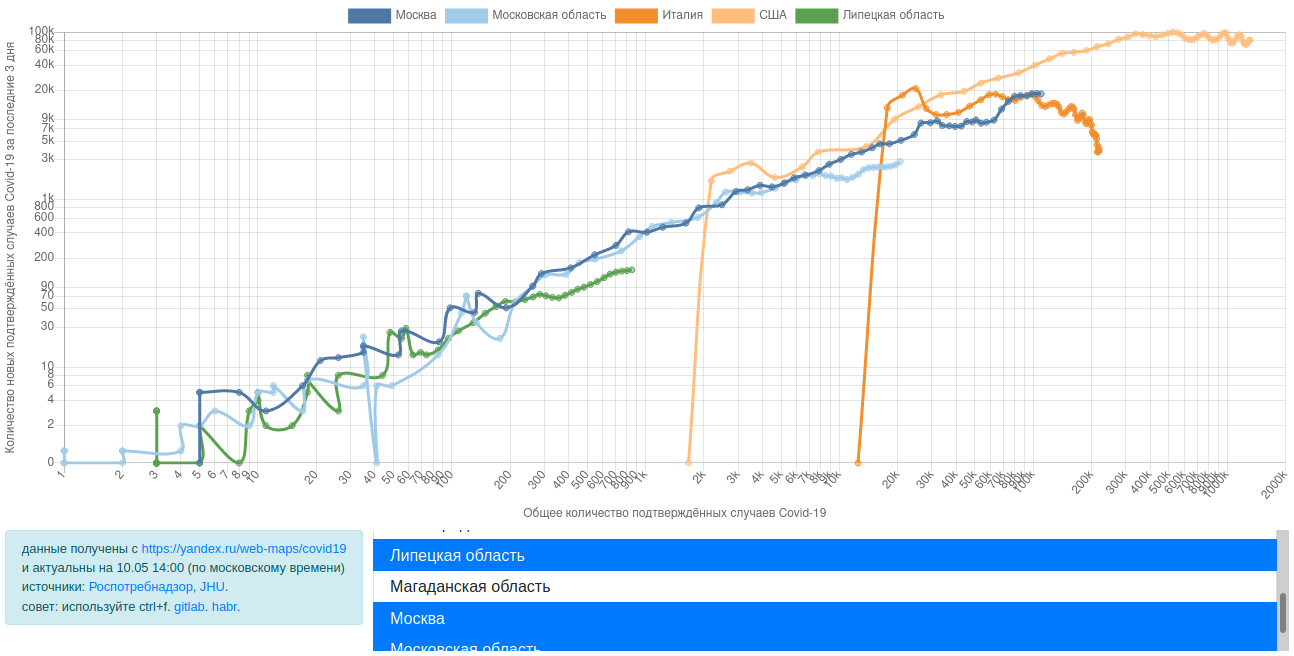
Интересно? Погнали!
Где взять данные?
Примерно в то время, когда у меня родилась идея воспроизвести графики от minutephysics для регионов России, Яндекс добавил в карту гистограммы по каждому региону.

Данные хранятся прямо в теле страницы, что оказалось крайне удобно. Я испытываю какое-то особое удовольствие, когда получается элегантно решить задачу без внешних зависимостей, так что, для такого простого случая как наш, монструозные парсеры и библиотека requests идут лесом. Только встроенные средства языка, только хардкор (не такой уж и хардкор, в стандартной библиотеке есть всё, что надо, и всё крайне удобно):
from urllib.request import urlopen
from html.parser import HTMLParser
import json
class Covid19DataLoader(HTMLParser):
page_url = "https://yandex.ru/web-maps/covid19"
def __init__(self):
super().__init__()
self.config_found = False
self.config = None
def load(self):
with urlopen(self.page_url) as response:
page = response.read().decode("utf8")
self.feed(page)
return self.config['covidData']
def handle_starttag(self, tag, attrs):
if tag == 'script':
for k, v in attrs:
if k == 'class' and v == 'config-view':
self.config_found = True
def handle_data(self, data):
if self.config_found and not self.config:
self.config = json.loads(data)Как поместить данные на страницу?
Данные получены, следующая задача — поместить их в нужное место HTML-странички, чтобы показать через Chart.js. В веб-фреймворках для этого используются шаблонизаторы, но нам не нужны никакие шаблонизаторы кроме string.Template:
def get_html(covid_data):
template_str = open(page_path, 'r', encoding='utf-8').read()
template = Template(template_str)
page = template.substitute(
covid_data=json.dumps(covid_data),
data_info=get_info(covid_data)
)
return pageА по пути page_path лежит примерно такое:
<!DOCTYPE html>
<html>
<head><!-- ... --></head>
<body>
<!-- ... -->
<div>$data_info</div>
<script type="text/javascript">
let covid_data = $covid_data
// ...
</script>
</body>
</html>Профит! Данные инжектятся в страничку! Можно отправлять в браузер!
Как зайти на страничку?
Вот. Простейший веб сервер на чистейшем Python:
from http.server import BaseHTTPRequestHandler
from lib.data_loader import Covid19DataLoader
from lib.page_maker import get_html
class Handler(BaseHTTPRequestHandler):
def do_GET(self):
if self.path == '/':
self.send_response(200)
self.send_header('Content-Type', 'text/html')
self.end_headers()
try:
response = get_html(Covid19DataLoader().load())
self.wfile.write(response.encode('utf-8'))
except Exception as e:
self.send_error(500)
print(f'{type(e).__name__}: {e}')
else:
self.send_error(404)Не рекомендуется для продакшна, но для продакшна у нас будет GitLab Pages, не переключайте канал вкладку!
Внимательный читатель кода мог заметить, что данные качаются при каждом запросе, что ну совсем не подходит для продакшна, да и для медленного дачного Интернета не очень.
Решение: кэширование в файл. Для инвалидации кэша просто удаляем файл (например, из cron). Проще не придумать, и ведь работает!
Данные для правильных графиков
Как завещал Aatish Bhatia, по оси Y должно быть количество новых случаев заражения за последнюю неделю, а по оси X — общее количество заражённых на момент времени.
Только мы возьмём не за неделю, а за 3 дня, чтобы график был более чувствительным и быстрее отражал ситуацию. Вопрос "Какое окно брать?" мною детально не исследовался, если Вам кажется, что лучше взять подлиннее, и колебания графика туда-сюда (которые наблюдаются в данных за последнюю неделю) только мешают, пишите в коменты!
from datetime import timedelta
from functools import reduce
y_axis_window = timedelta(days=3).total_seconds()
def get_cases_in_window(data, current_time):
window_open_time = current_time - y_axis_window
cases_in_window = list(filter(lambda s: window_open_time <= s['ts'] < current_time, data))
return cases_in_window
def differentiate(data):
result = [data[0]]
for prev_i, cur_sample in enumerate(data[1:]):
result.append({
'ts': cur_sample['ts'],
'value': cur_sample['value'] - data[prev_i]['value']
})
return result
def get_trend(histogram):
trend = []
new_cases = differentiate(histogram)
for sample in histogram:
current_time = sample['ts']
total_cases = sample['value']
new_cases_in_window = get_cases_in_window(new_cases, current_time)
total_new_cases_in_window = reduce(lambda a, c: a + c['value'], new_cases_in_window, 0)
trend.append({'x': total_cases,'y': total_new_cases_in_window})
return trend
def get_trends(data_items):
return { area['name']: get_trend(area['histogram']) for area in data_items }Фронтэнд
Тут нет ничего, чем я хотел бы поделиться (разве что восторгом от CSS Grid, который впервые попробовал), так как разбираюсь во фронтэнде хуже всего. Прошу поправить меня мёржреквестом, если я где-то накосячил. Вот код.
Как опубликовать сервис?
Я очень люблю Docker, и первый вариант, который мне пришёл на ум — склонировать репозиторий на свой VPS, позвать docker-compose up --build -d, настроить cron на удаление кэш-файла (хотя постойте, какой крон внутри контейнера?? ладно, потом разберёмся...), и, вопреки предупреждениям о том, что http.server не для продакшна, открыть порт во внешку. А потом натравить GitLab CI на обновление сервиса по ssh (я сто раз уже так делал).
Но тут я заметил, что страничка, отправляемая в браузер, весьма статична.
Это позволяет её просто выгрузить в файл и захостить бесплатно в GitLab Pages:
import os
from lib.data_loader import Covid19DataLoader
from lib.data_processor import get_trends
from lib.page_maker import get_html
page_dir = 'public'
page_name = 'index.html'
print('Updating Covid-19 data from Yandex...')
raw_data = Covid19DataLoader().load()
print('Calculating trends...')
trends = get_trends(raw_data['items'])
page = get_html({'raw_data': raw_data, 'trends': trends})
if not os.path.isdir(page_dir):
os.mkdir(page_dir)
page_path = os.path.join(page_dir, page_name)
open(page_path, 'w', encoding='utf-8').write(page)
print(f'Page saved as "{page_path}"')Для того, чтобы опубликовать страничку по симпатичному адресу https://himura.gitlab.io/covid19, достаточно написать следующий .gitlab-ci.yml:
image: python
pages:
stage: deploy
only: [ master ]
script:
- python ./get_static_html.py
artifacts:
paths: [ public ]А обновлять через Pipeline Schedules:
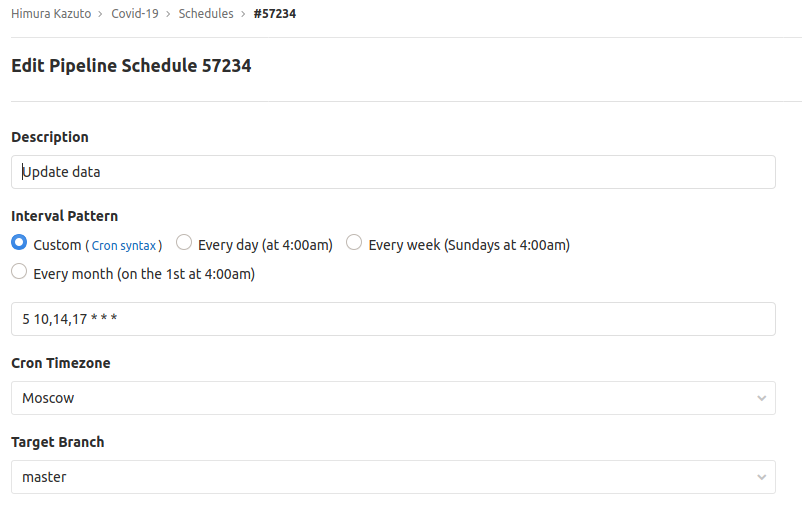
Результат работы выглядит как-то так:

А результат деплоймента — как на КДПВ:
Всё?
Кодснипеты в статье немного упрощены, а весь реальный код в репозитории на GitLab: https://gitlab.com/himura/covid19
Я почти уверен, что много чего упустил, так как на весь код и статью в сумме было потрачено примерно 2 рабочих дня. Пожалуйста, давайте вместе что-нибудь улучшим в этом MVP, если Вам кажется, что что-то не так. Пишите комментарии, пишите баги, а лучше всего — пишите мёржреквесты. В числе known issues:
- Добавить даты в тултип точкам
- Добавить мобильную версию (с css grid должно быть радикально просто)
- Убедиться, что математика работает как надо
Надеюсь, статья была интересна и/или полезна, а также очень надеюсь, что вскоре мы все будем наблюдать, как линии графиков устремятся вниз.
Будьте здоровы и не вносите в свой код зависимостей, без которых можно обойтись!


