
Иногда бывает так:
— Приезжайте, у нас упало. Если сейчас не поднять — покажут по телевизору.
И мы едем. Ночью. На другой край страны.
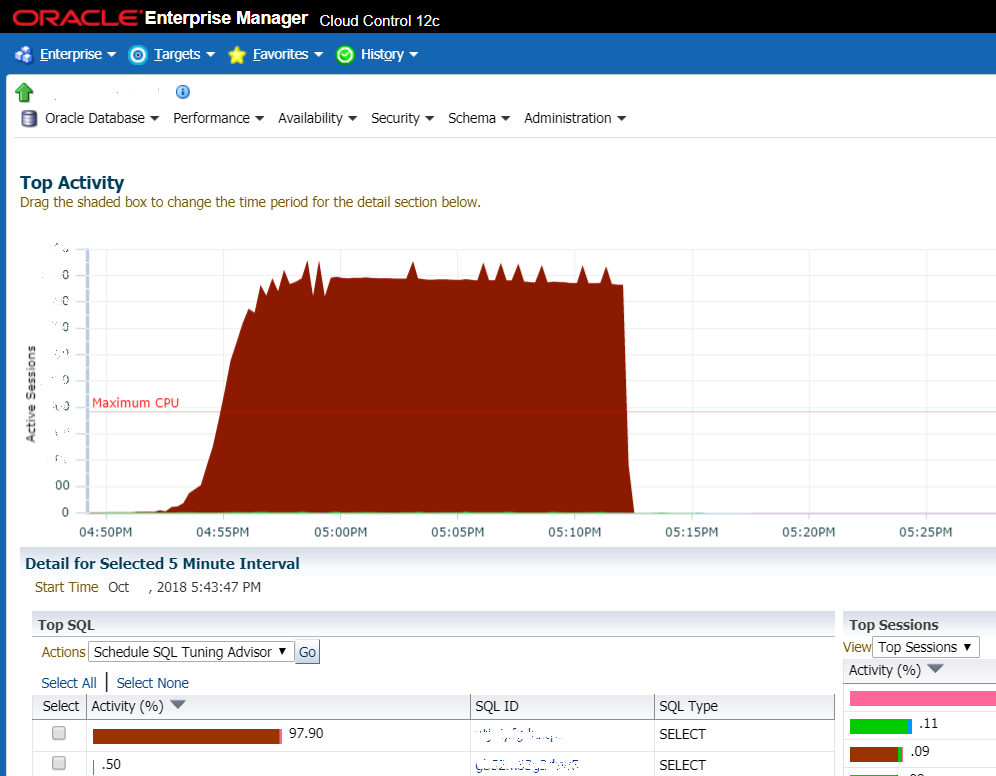
Ситуация, когда не повезло: на графике показан резкий рост нагрузки на СУБД. Очень часто это первое, на что смотрят администраторы системы и это первый признак того, что наступила жопа
Но чаще речь идёт про какие-то типовые вещи. Например, заказчик столкнулся с низкой производительностью системы документооборота. По понедельникам и вторникам система падала, они перезагружали сервер, и потом всё поднималось. Захлёбывалась база данных. Хотели докупить оборудования (что долго и дорого), позвали нас просчитать смету. Мы им посчитали смету и заодно предложили разобраться, что же именно тормозит. За три-четыре часа локализовали источник проблемы. Выяснили, что это медленные запросы в базу данных и неоптимальные схемы индексирования. Создали недостающие индексы, поковырялись с оптимизатором запросов в Оракле, некоторые проблемы потребовали изменения кода — поменяли условия поиска (без изменения функциональности), заменили часть запросов на использование предрассчитанных представлений. Если бы у них был нормальный человек по БД — могли бы сделать то же и сами. Но вместо нормального человека был аудит базы данных раз в полгода крутыми ораклистами — они выдавали общие рекомендации по настройкам и железу.
Детали немного изменены по просьбе безопасников. Есть система документооборота на сотнях промышленных объектов. Она иногда падает, и работа встаёт. То есть объекты могут работать, но ни один документ не проходит и не подписывается. А это, в частности, отгрузка сырья, зарплаты и распоряжения, что и сколько производить в смену. Каждое падение — это боль, слёзы, коньяк для ИТ-директора, потому что ему тяжело: куча потерь.
Директор, кстати, всего полгода как на этом месте после прошлого. А прошлый продержался год. И оба они работают на системе, которую внедрял директор три поколения назад. Второй с конца пытался внедрить свою, но не успел до увольнения. Ситуация очень реалистичная.
На первый взгляд — недостаточно производительности. Профиль нагрузки — блокировки (Wait Class «Application»). То есть конкуренция за строки. Начинаем расследовать инцидент. На каждую транзакцию пользователя открывается сессия. Она довольно быстро переходит в состояние блокировки приказа, по которому выписываются задачи и поручения на исполнение, потому что пользователь должен поставить визу «Ознакомлен» как минимум.
Последний случай — накатили новый стандарт по тому, как часто сотрудники должны проходить медицинское обследование. Кадровик верхнего уровня написала приказ и отправила по всем организациям. То есть каждому сотруднику каждого производства. Десятки тысяч пользователей получили транзакции на визу. Начали открывать приказы почти одновременно, поставили длинную цепочку блокировок в базе. Из-за не самого оптимального кода в результате случился «небольшой» overflow, и всё захлебнулось. Примерно 40 тысяч пользователей не работают. Из дублирующей схемы — только телефоны и почта. Производство не останавливается, но эффективность очень сильно падает, что вызывает конкретные финансовые потери. А потом начинаются звонки с каждого предприятия лично ИТ-директору с ором. На практике у них есть SLA, но нет ещё согласованного договора. И ситуация приобретает окончательные черты чисто русской истории.
Проблему «на скорую руку» решили путём глубокого профилирования, анализа логики блокирования объектов, исключили лишние объекты, на которые ставилась блокировка, хотя не было нужно, потому что объект не менялся (например, справочники, права доступа и т. д.). Затем за пару месяцев отрефакторили основные участки кода.
Помимо стандартных средств (треддампы, логи, метрики, AWR, данные из системных представлений и т. д.) используем и более цивильные инструменты в том числе и коммерческие.
Пример 1: медленная работа журнала сделок
На медленную работу журнала поступали жалобы от пользователей (проблема известная и частая).
Находим проблемную вьюху, дальше ищем запрос в операциях к вьюхе deal_journal_view. Выполняем поиск всех транзакций, где внутри есть такой запрос.

По каждой из операций можно посмотреть её детали и найти сам запрос с параметрами выполнения, что позволяет провести анализ работы запроса, валидацию и корректировку плана. Нашли конкретный медленный запрос.

Сами проанализировали и предложили варианты оптимизации. А уже потом для отслеживания этой группы бизнес-операций (просмотр журнала сделок) создаем Transaction Type и настраиваем алерты.

Пример 2: поиск причин медленной работы пользователя 1
От пользователя 1 поступили жалобы на медленную работу приложения. Смотрим:

Были произведены поиск всех операций пользователя и сортировка по длительности. Далее были проанализированы самые медленные операции, и были обнаружены медленные запросы во внешнюю систему (SAP).

Указали на это смежной команде, починили.
Пример 3: ещё один пользователь жалуется на медленную работу приложения
Смотрим по той же схеме. На этот раз видим большое число вызовов внешнего сервиса подписания. Оказалось, при определённых условиях, подписывали некоторые документы по два раза. Поправили.

Пример 4: когда детализации не хватает
Порой для анализа более сложных частей кода прибегаем к использованию кастомных профайлеров, позволяющих глубже изучить поведение приложения. Например, как тут: куча непонятной логики при операции логика в систему. Разобрались с логикой, добавили пару кешей, оптимизировали запросы.

Пример 5: ещё тормоза
Пользователь жаловался на медленную работу с карточками договоров.

Проанализированы медленные операции пользователя (parameter = ‘userlogin=”…”’) за одну неделю. Больше всего проблем было с поисковыми запросами по договорам, но были найдены также операции с карточкой документа. Большая часть времени уходит на создание большого количества задач по поручениям. Были найдены идентификаторы (колонка Parameter Value на скриншоте) сохраняемых задач и время их сохранения.
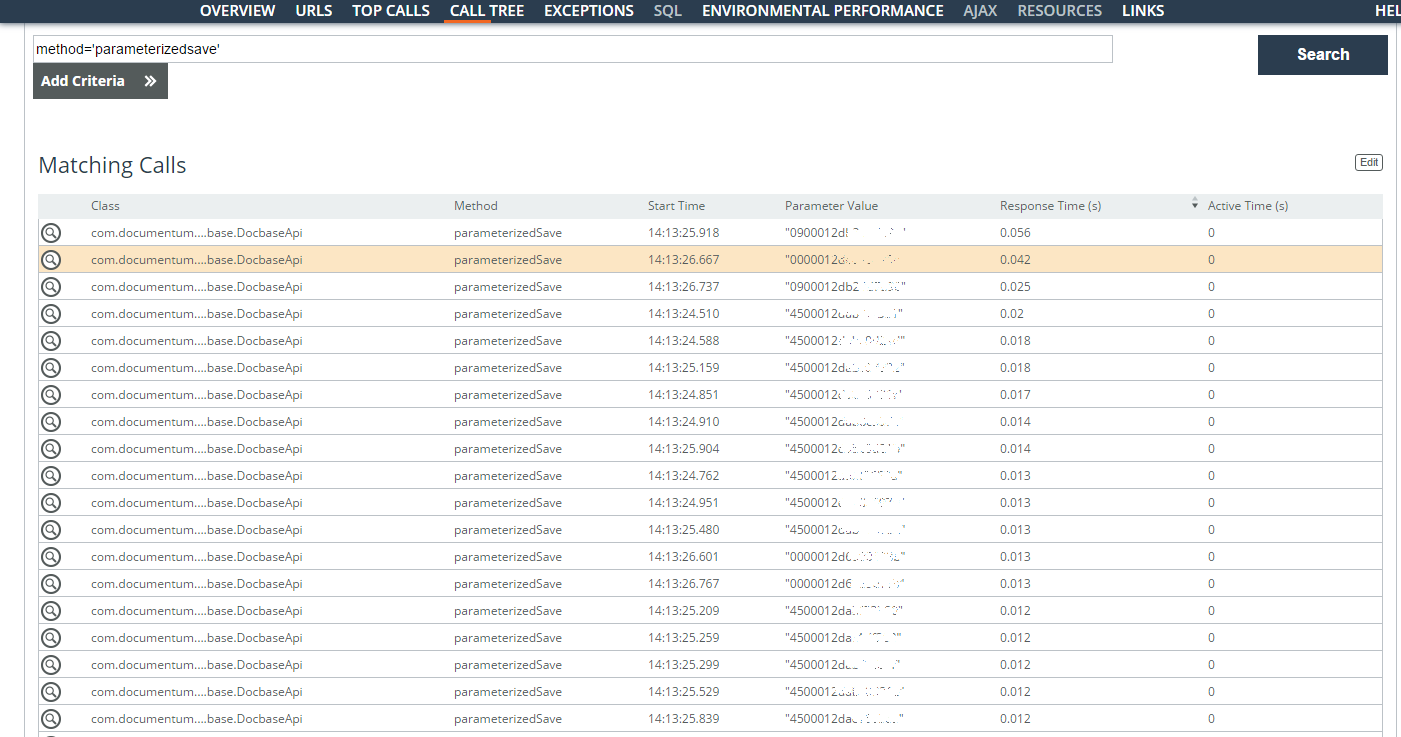
По логике — когда они могут создаваться асинхронно, но сейчас ставятся в очередь и требуют исключительных блокировок. Здесь уже нужно покопаться поглубже в архитектуре.
Нет.
И ещё раз нет.
Это всё лечение симптомов.
Правильно быстро спасти ситуацию, которая сейчас «горит». И потом поставить процессы. Редко когда люди, которые работают с системой, не понимают, что делают. Просто либо им нужно обосновать средства на уменьшение технического долга (а им никто не верит), либо поменять процессы на более современные (на что ресурсов тоже нет), либо сделать что-то ещё подобное.
В целом мы приходим с верхнего уровня и видим боль у заказчика. Дальше ловим бутылочное горлышко. Иногда это заканчивается внедрением системы мониторинга. А если заказчик понимает, что нужно менять процессы разработки ПО, то начинается стадия «долго, дорого и совсем даже не офигенно».
Мы смотрим на проектах двух-трёх, ковыряем все документы, репозитории, интервьюируем людей. Дальше готовим шаблоны новых документов, готовим процедуры, смотрим инструменты по управлению требованиями, тестированием. И помогаем внедрить. Иногда достаточно просто дать заключение, что менять, и окрылённый ИТ-директор с бумагой получает бюджет. Иногда надо прямо внедрять с кровью и слезами.
Болью может оказаться что угодно, начиная от неправильного выбора архитектуры до каких-то особенностей рабочего процесса. Вот эти примеры — именно про дичь в процессах в разных компаниях по стране.
Что касается оптимизации приложений со стороны базы данных — вот характерный пример. Есть медицинская система (одна из тех, кто падал). Позвали нас смотреть. Мы пришли, когда они уже отключили все модули, кроме документооборота врачей, чтобы хоть как-то анализы ходили и запись через регистратуру была. Онлайн-запись, в частности, была среди отключённых модулей. Удалось починить всё за одну неделю. Изначально заказчик думал, что проблемы — на прикладном слое: там отказы по тайм-ауту, зависшие потоки. Мы выяснили, что проблема — с базой данных. Там были сложная структура, куча секционирования по дням и месяцам. Оказалось, забыли про пару индексов, разработчики не до конца знали, во что это превратится со временем, — и вот результат. Примерно тот же набор операций плюс ограничения поиска (когда надо выгрузить что-то в диапазоне дат, хорошо бы искать между этими датами, а не по всей базе).
Понятно, что не всегда такая оптимизация решает задачу. Например, (по архитектуре) энергетический сектор: заказчик просит посмотреть, что с зависаниями системы. А там при сдаче всё летало, но через пару лет документов стало куда больше, и всё приятно затормозило. Заказчик посидел с секундомером на рабочем месте оператора и сказал: вот такая операция занимает сейчас 31 секунду, хотим 3. Вот эта — 40 секунд, хотим 2. И так далее. Понятно, что так измерять не очень правильно, но задача достаточно конкретна и может быть легко представлена в виде объективных критериев. Сделали не всё, на «уборку» ушло в общей сложности около полугода. По большей части переводили логику на асинхронное исполнение, часть баз меняли на noSQL, ставили поисковый движок Солар, на одном участке понадобилось выделить самую горячую базу данных и сделать её in-memory. В итоге закрыли около 90 % потребностей, но кое-где не смогли уменьшить задержки. Это работа сторонних библиотек, физические ограничения платформы и так далее. Всё это отслеживали мониторингом и смогли чётко доказать, где именно и что тормозит.
Мы используем разное мониторинговое ПО для быстрого поиска тормозящих процессов и оптимизации по ним. ИТ-команда одного из крупных заказчиков посмотрела, как мы это делаем, и попросила внедрить это на одном из объектов как постоянный инструмент. ОК, обложили мониторингом все процессы и узлы, кастомизировали их систему под задачи, почти четыре месяца работали, но сделали набор инструментов для их поддержки. А там 80 тысяч пользователей, есть первая и вторая линии внутри и третья часто — у подрядчиков или тоже внутри.
На второй линии стоит как раз этот набор инструментов. Сейчас примерно в 50 % случаев они используют мониторинг для диагностики, поиска узких мест и причин зависаний, чтобы свои же разработчики могли посмотреть, понять и оптимизировать. Очень много времени поддержки экономится на быстром выявлении причины проблемы. После пилота масштабировались по транзакциям. Именно это заняло четыре месяца: на любое действие есть бизнес-операция. Открытие карточки документа — бизнес-операция. Подписание в системе документооборота — бизнес-операция. Выгрузка отчёта или поиск — тоже. 1 500 таких бизнес-операций за четыре месяца описано, чтобы понять, где и что работает. Мониторинг до этого видел http-вызовы и видит вызываемые методы и функции, видит конкретные запросы. До этого только разработчики понимали, что это согласование договора или поиск. Чтобы система мониторинга показывала релевантные данные для разных линий поддержки и для бизнеса, мы настроили все эти связки.

Бизнес ещё и начал нарезать отчёты самостоятельно по ИТ-развитию. Больше по логам там никто не ковыряется особо.
Кстати, про всё то, зачем вообще нужны системы класса APM, и как их выбрать, мы будем рассказывать на вебинаре 1 октября.
Ещё пара примеров. Крупный иностранный банк с представительствами в России. Мы поддерживаем Oracle DB и Oracle Weblogic. В системе наблюдалось постепенное снижение производительности, бизнес-операции выполнялись медленнее, работа операционистов становилась всё менее эффективной, а в периоды импортов и синхронизаций с НСИ всё зависало конкретно. В таких случаях мы используем стандартные средства Java и Oracle для сбора данных: собираем треддампы, анализируем их в бесплатных сервисах или используем самописные инструменты анализа, смотрим AWR, трассируем выполнение SQL-запросов, анализируем планы и статистику выполнения. В итоге помимо стандартных вещей типа оптимизации состава индексов, корректировки планов запросов, предложили внедрить секционирование, разделив данные. Получилось два сегмента: исторические (оставили их на HDD) и операционные — разместили на SSD. До этого было довольно сложно понять, какие данные к чему относятся, потому что в исторические всё же надо было регулярно спускаться, причём как на длинных отчётах, так и в обычных операциях. В итоге правильного разделения больше 98 % основных операций не лезли в медленные исторические данные. Что важно, здесь обошлось без влезания в код системы. Бывает, что некоторые наши рекомендации требуют внесения изменения в прикладной код, который поддерживается не нами, — тогда обычно договариваемся.
Второй пример: международный производитель в области легкой промышленности и вообще FMCG-сегмента. Час простоя основного сайта стоит около 20 миллионов рублей. Рядовая нагрузка на базу — 200 AS (active sessions) c пиками до 800-1000. Нередка ситуация, когда оптимизатору запросов срывает голову, планы начинают плыть не в лучшую сторону, начинается дикая конкуренция за буферный кеш. От этого не застрахован никто, но снизить вероятность можно: в течение двух месяцев наблюдали за системой, анализируя профиль нагрузки, по ходу тушили возникающие пожары, корректируя схемы индексирования и секционирования, логику обработки данных со стороны PL/SQL кода. Тут нужно понимать, что в живой, развивающейся системе подобный аудит проводить нужно регулярно, хоть нагрузочное тестирование и помогает, но не всегда. И компании проводят аудит, приглашая сторонних ораклистов, но редко кто из них опускается на уровень бизнес-логики и готов копаться в данных, взаимодействуя с разработчиками. Мы же это делаем.
Ну и хочу сказать, что далеко не всегда проблема в отсутствии регулярной уборки или правильной поддержки. Часто проблемы бывают в процессах.
Потому что бизнес любит решения, а не процессы. Это основная причина.
Вторая в том, что не все могут выделить ресурсы на поиск бутылочного горлышка в приложении, особенно, если это third-party приложении. И далеко не всегда в одной команде есть люди, обладающие нужными компетенциями. Вот сейчас у нас в команде системный инженер, сетевые инженеры, спецы по Oracle и 1С, люди, которые умеют оптимизировать Java, фронтэнд.
Ну и если вам интересно погрузиться в детали, то 1 октября будет наш вебинар про то, что можно сделать заранее, до того, как всё упадёт. И вот моя почта для вопросов — sstrelkov@croc.ru.
— Приезжайте, у нас упало. Если сейчас не поднять — покажут по телевизору.
И мы едем. Ночью. На другой край страны.
Ситуация, когда не повезло: на графике показан резкий рост нагрузки на СУБД. Очень часто это первое, на что смотрят администраторы системы и это первый признак того, что наступила жопа
Но чаще речь идёт про какие-то типовые вещи. Например, заказчик столкнулся с низкой производительностью системы документооборота. По понедельникам и вторникам система падала, они перезагружали сервер, и потом всё поднималось. Захлёбывалась база данных. Хотели докупить оборудования (что долго и дорого), позвали нас просчитать смету. Мы им посчитали смету и заодно предложили разобраться, что же именно тормозит. За три-четыре часа локализовали источник проблемы. Выяснили, что это медленные запросы в базу данных и неоптимальные схемы индексирования. Создали недостающие индексы, поковырялись с оптимизатором запросов в Оракле, некоторые проблемы потребовали изменения кода — поменяли условия поиска (без изменения функциональности), заменили часть запросов на использование предрассчитанных представлений. Если бы у них был нормальный человек по БД — могли бы сделать то же и сами. Но вместо нормального человека был аудит базы данных раз в полгода крутыми ораклистами — они выдавали общие рекомендации по настройкам и железу.
Как это бывает
Детали немного изменены по просьбе безопасников. Есть система документооборота на сотнях промышленных объектов. Она иногда падает, и работа встаёт. То есть объекты могут работать, но ни один документ не проходит и не подписывается. А это, в частности, отгрузка сырья, зарплаты и распоряжения, что и сколько производить в смену. Каждое падение — это боль, слёзы, коньяк для ИТ-директора, потому что ему тяжело: куча потерь.
Директор, кстати, всего полгода как на этом месте после прошлого. А прошлый продержался год. И оба они работают на системе, которую внедрял директор три поколения назад. Второй с конца пытался внедрить свою, но не успел до увольнения. Ситуация очень реалистичная.
На первый взгляд — недостаточно производительности. Профиль нагрузки — блокировки (Wait Class «Application»). То есть конкуренция за строки. Начинаем расследовать инцидент. На каждую транзакцию пользователя открывается сессия. Она довольно быстро переходит в состояние блокировки приказа, по которому выписываются задачи и поручения на исполнение, потому что пользователь должен поставить визу «Ознакомлен» как минимум.
Последний случай — накатили новый стандарт по тому, как часто сотрудники должны проходить медицинское обследование. Кадровик верхнего уровня написала приказ и отправила по всем организациям. То есть каждому сотруднику каждого производства. Десятки тысяч пользователей получили транзакции на визу. Начали открывать приказы почти одновременно, поставили длинную цепочку блокировок в базе. Из-за не самого оптимального кода в результате случился «небольшой» overflow, и всё захлебнулось. Примерно 40 тысяч пользователей не работают. Из дублирующей схемы — только телефоны и почта. Производство не останавливается, но эффективность очень сильно падает, что вызывает конкретные финансовые потери. А потом начинаются звонки с каждого предприятия лично ИТ-директору с ором. На практике у них есть SLA, но нет ещё согласованного договора. И ситуация приобретает окончательные черты чисто русской истории.
Проблему «на скорую руку» решили путём глубокого профилирования, анализа логики блокирования объектов, исключили лишние объекты, на которые ставилась блокировка, хотя не было нужно, потому что объект не менялся (например, справочники, права доступа и т. д.). Затем за пару месяцев отрефакторили основные участки кода.
Как ищутся такие участки кода?
Помимо стандартных средств (треддампы, логи, метрики, AWR, данные из системных представлений и т. д.) используем и более цивильные инструменты в том числе и коммерческие.
Пример 1: медленная работа журнала сделок
На медленную работу журнала поступали жалобы от пользователей (проблема известная и частая).
Находим проблемную вьюху, дальше ищем запрос в операциях к вьюхе deal_journal_view. Выполняем поиск всех транзакций, где внутри есть такой запрос.
По каждой из операций можно посмотреть её детали и найти сам запрос с параметрами выполнения, что позволяет провести анализ работы запроса, валидацию и корректировку плана. Нашли конкретный медленный запрос.
Сами проанализировали и предложили варианты оптимизации. А уже потом для отслеживания этой группы бизнес-операций (просмотр журнала сделок) создаем Transaction Type и настраиваем алерты.
Пример 2: поиск причин медленной работы пользователя 1
От пользователя 1 поступили жалобы на медленную работу приложения. Смотрим:
Были произведены поиск всех операций пользователя и сортировка по длительности. Далее были проанализированы самые медленные операции, и были обнаружены медленные запросы во внешнюю систему (SAP).
Указали на это смежной команде, починили.
Пример 3: ещё один пользователь жалуется на медленную работу приложения
Смотрим по той же схеме. На этот раз видим большое число вызовов внешнего сервиса подписания. Оказалось, при определённых условиях, подписывали некоторые документы по два раза. Поправили.
Пример 4: когда детализации не хватает
Порой для анализа более сложных частей кода прибегаем к использованию кастомных профайлеров, позволяющих глубже изучить поведение приложения. Например, как тут: куча непонятной логики при операции логика в систему. Разобрались с логикой, добавили пару кешей, оптимизировали запросы.
Пример 5: ещё тормоза
Пользователь жаловался на медленную работу с карточками договоров.
Проанализированы медленные операции пользователя (parameter = ‘userlogin=”…”’) за одну неделю. Больше всего проблем было с поисковыми запросами по договорам, но были найдены также операции с карточкой документа. Большая часть времени уходит на создание большого количества задач по поручениям. Были найдены идентификаторы (колонка Parameter Value на скриншоте) сохраняемых задач и время их сохранения.
По логике — когда они могут создаваться асинхронно, но сейчас ставятся в очередь и требуют исключительных блокировок. Здесь уже нужно покопаться поглубже в архитектуре.
Вот так всё просто: надо найти бутылочное горлышко — и всё?
Нет.
И ещё раз нет.
Это всё лечение симптомов.
Правильно быстро спасти ситуацию, которая сейчас «горит». И потом поставить процессы. Редко когда люди, которые работают с системой, не понимают, что делают. Просто либо им нужно обосновать средства на уменьшение технического долга (а им никто не верит), либо поменять процессы на более современные (на что ресурсов тоже нет), либо сделать что-то ещё подобное.
В целом мы приходим с верхнего уровня и видим боль у заказчика. Дальше ловим бутылочное горлышко. Иногда это заканчивается внедрением системы мониторинга. А если заказчик понимает, что нужно менять процессы разработки ПО, то начинается стадия «долго, дорого и совсем даже не офигенно».
Мы смотрим на проектах двух-трёх, ковыряем все документы, репозитории, интервьюируем людей. Дальше готовим шаблоны новых документов, готовим процедуры, смотрим инструменты по управлению требованиями, тестированием. И помогаем внедрить. Иногда достаточно просто дать заключение, что менять, и окрылённый ИТ-директор с бумагой получает бюджет. Иногда надо прямо внедрять с кровью и слезами.
Болью может оказаться что угодно, начиная от неправильного выбора архитектуры до каких-то особенностей рабочего процесса. Вот эти примеры — именно про дичь в процессах в разных компаниях по стране.
Что касается оптимизации приложений со стороны базы данных — вот характерный пример. Есть медицинская система (одна из тех, кто падал). Позвали нас смотреть. Мы пришли, когда они уже отключили все модули, кроме документооборота врачей, чтобы хоть как-то анализы ходили и запись через регистратуру была. Онлайн-запись, в частности, была среди отключённых модулей. Удалось починить всё за одну неделю. Изначально заказчик думал, что проблемы — на прикладном слое: там отказы по тайм-ауту, зависшие потоки. Мы выяснили, что проблема — с базой данных. Там были сложная структура, куча секционирования по дням и месяцам. Оказалось, забыли про пару индексов, разработчики не до конца знали, во что это превратится со временем, — и вот результат. Примерно тот же набор операций плюс ограничения поиска (когда надо выгрузить что-то в диапазоне дат, хорошо бы искать между этими датами, а не по всей базе).
Понятно, что не всегда такая оптимизация решает задачу. Например, (по архитектуре) энергетический сектор: заказчик просит посмотреть, что с зависаниями системы. А там при сдаче всё летало, но через пару лет документов стало куда больше, и всё приятно затормозило. Заказчик посидел с секундомером на рабочем месте оператора и сказал: вот такая операция занимает сейчас 31 секунду, хотим 3. Вот эта — 40 секунд, хотим 2. И так далее. Понятно, что так измерять не очень правильно, но задача достаточно конкретна и может быть легко представлена в виде объективных критериев. Сделали не всё, на «уборку» ушло в общей сложности около полугода. По большей части переводили логику на асинхронное исполнение, часть баз меняли на noSQL, ставили поисковый движок Солар, на одном участке понадобилось выделить самую горячую базу данных и сделать её in-memory. В итоге закрыли около 90 % потребностей, но кое-где не смогли уменьшить задержки. Это работа сторонних библиотек, физические ограничения платформы и так далее. Всё это отслеживали мониторингом и смогли чётко доказать, где именно и что тормозит.
Для чего ещё может быть нужен такой мониторинг?
Мы используем разное мониторинговое ПО для быстрого поиска тормозящих процессов и оптимизации по ним. ИТ-команда одного из крупных заказчиков посмотрела, как мы это делаем, и попросила внедрить это на одном из объектов как постоянный инструмент. ОК, обложили мониторингом все процессы и узлы, кастомизировали их систему под задачи, почти четыре месяца работали, но сделали набор инструментов для их поддержки. А там 80 тысяч пользователей, есть первая и вторая линии внутри и третья часто — у подрядчиков или тоже внутри.
На второй линии стоит как раз этот набор инструментов. Сейчас примерно в 50 % случаев они используют мониторинг для диагностики, поиска узких мест и причин зависаний, чтобы свои же разработчики могли посмотреть, понять и оптимизировать. Очень много времени поддержки экономится на быстром выявлении причины проблемы. После пилота масштабировались по транзакциям. Именно это заняло четыре месяца: на любое действие есть бизнес-операция. Открытие карточки документа — бизнес-операция. Подписание в системе документооборота — бизнес-операция. Выгрузка отчёта или поиск — тоже. 1 500 таких бизнес-операций за четыре месяца описано, чтобы понять, где и что работает. Мониторинг до этого видел http-вызовы и видит вызываемые методы и функции, видит конкретные запросы. До этого только разработчики понимали, что это согласование договора или поиск. Чтобы система мониторинга показывала релевантные данные для разных линий поддержки и для бизнеса, мы настроили все эти связки.
Бизнес ещё и начал нарезать отчёты самостоятельно по ИТ-развитию. Больше по логам там никто не ковыряется особо.
Кстати, про всё то, зачем вообще нужны системы класса APM, и как их выбрать, мы будем рассказывать на вебинаре 1 октября.
В чём ещё с технической стороны бывают «затыки»?
Ещё пара примеров. Крупный иностранный банк с представительствами в России. Мы поддерживаем Oracle DB и Oracle Weblogic. В системе наблюдалось постепенное снижение производительности, бизнес-операции выполнялись медленнее, работа операционистов становилась всё менее эффективной, а в периоды импортов и синхронизаций с НСИ всё зависало конкретно. В таких случаях мы используем стандартные средства Java и Oracle для сбора данных: собираем треддампы, анализируем их в бесплатных сервисах или используем самописные инструменты анализа, смотрим AWR, трассируем выполнение SQL-запросов, анализируем планы и статистику выполнения. В итоге помимо стандартных вещей типа оптимизации состава индексов, корректировки планов запросов, предложили внедрить секционирование, разделив данные. Получилось два сегмента: исторические (оставили их на HDD) и операционные — разместили на SSD. До этого было довольно сложно понять, какие данные к чему относятся, потому что в исторические всё же надо было регулярно спускаться, причём как на длинных отчётах, так и в обычных операциях. В итоге правильного разделения больше 98 % основных операций не лезли в медленные исторические данные. Что важно, здесь обошлось без влезания в код системы. Бывает, что некоторые наши рекомендации требуют внесения изменения в прикладной код, который поддерживается не нами, — тогда обычно договариваемся.
Второй пример: международный производитель в области легкой промышленности и вообще FMCG-сегмента. Час простоя основного сайта стоит около 20 миллионов рублей. Рядовая нагрузка на базу — 200 AS (active sessions) c пиками до 800-1000. Нередка ситуация, когда оптимизатору запросов срывает голову, планы начинают плыть не в лучшую сторону, начинается дикая конкуренция за буферный кеш. От этого не застрахован никто, но снизить вероятность можно: в течение двух месяцев наблюдали за системой, анализируя профиль нагрузки, по ходу тушили возникающие пожары, корректируя схемы индексирования и секционирования, логику обработки данных со стороны PL/SQL кода. Тут нужно понимать, что в живой, развивающейся системе подобный аудит проводить нужно регулярно, хоть нагрузочное тестирование и помогает, но не всегда. И компании проводят аудит, приглашая сторонних ораклистов, но редко кто из них опускается на уровень бизнес-логики и готов копаться в данных, взаимодействуя с разработчиками. Мы же это делаем.
Ну и хочу сказать, что далеко не всегда проблема в отсутствии регулярной уборки или правильной поддержки. Часто проблемы бывают в процессах.
Зачем нужны такие услуги при живых своих разработчиках?
Потому что бизнес любит решения, а не процессы. Это основная причина.
Вторая в том, что не все могут выделить ресурсы на поиск бутылочного горлышка в приложении, особенно, если это third-party приложении. И далеко не всегда в одной команде есть люди, обладающие нужными компетенциями. Вот сейчас у нас в команде системный инженер, сетевые инженеры, спецы по Oracle и 1С, люди, которые умеют оптимизировать Java, фронтэнд.
Ну и если вам интересно погрузиться в детали, то 1 октября будет наш вебинар про то, что можно сделать заранее, до того, как всё упадёт. И вот моя почта для вопросов — sstrelkov@croc.ru.


. Готова ли система к работе с простыми пользователями? Примеры костылей")

