
Пожалуй, каждому программисту известны слова Кента Бека: «Make it work, make it right, make it fast». Сначала надо сделать так, чтобы программа работала, дальше — надо заставить её работать правильно, а уже потом можно переходить к оптимизации.
Автор статьи, перевод которой мы публикуем, говорит, что недавно он решил заняться профилированием своего опенсорсного Go-проекта Flipt. Он хотел найти в проекте код, который можно было бы без особых усилий оптимизировать и тем самым ускорить программу. В ходе профилирования он обнаружил некоторые неожиданные проблемы в популярном проекте с открытым исходным кодом, который в приложении Flipt использовался для организации маршрутизации и поддержки промежуточного ПО. В итоге удалось снизить объём памяти, выделяемой приложением в процессе работы, в 100 раз. Это, в свою очередь, привело к уменьшению количества операций по сборке мусора и улучшило общую производительность проекта. Вот как это было.
Прежде чем я мог бы приступить к профилированию, я знал, что сначала мне нужно сгенерировать большой объём трафика, поступающего в приложение, что помогло бы мне увидеть некие шаблоны его поведения. Тут я сразу же столкнулся с проблемой, так как у меня нет ничего, что использовало бы Flipt в продакшне и получало бы некий объём трафика, позволяющий оценить работу проекта под нагрузкой. В результате я обнаружил отличный инструмент для нагрузочного тестирования проектов. Это — Vegeta. Авторы проекта говорят, что Vegeta — это универсальный HTTP-инструмент для нагрузочного тестирования. Этот проект родился из необходимости нагружать HTTP-сервисы большим количеством запросов, поступающих к сервисам с заданной частотой.
Проект Vegeta оказался именно тем инструментом, который был мне нужен, так как он позволял создать непрерывный поток запросов к приложению. Этими запросами можно было «обстреливать» приложение столько, сколько нужно для того, чтобы выяснить такие показатели, как выделение/использование памяти в куче, особенности работы горутин, время, затраченное на сборку мусора.
После проведения некоторых экспериментов я вышел на следующую конфигурацию запуска Vegeta:
Эта команда запускает Vegeta в режиме
Обратите внимание на то, что сначала я решил подвергнуть испытанию конечную точку Flipt
Теперь, когда у меня появился инструмент для генерирования достаточно большого объёма трафика, мне нужно было найти способ измерения того воздействия, которое этот трафик оказывал на работающее приложение. К счастью, в Go имеется довольно хороший стандартный набор инструментов, которые позволяют измерять производительность программ. Речь идёт о пакете pprof.
Я не будут вдаваться в подробности использования pprof. Не думаю, что сделаю это лучше Джулии Эванс, которая написала эту замечательную статью о профилировании Go-программ с помощью pprof (если вы её не читали — я определённо рекомендую вам на неё взглянуть).
Так как HTTP-маршрутизатор во Flipt реализован с помощью go-chi/chi, мне было совсем несложно включить pprof, воспользовавшись соответствующим промежуточным обработчиком Chi.
Итак, в одном окне у меня работал Flipt, а Vegeta, заваливая Flipt запросами, работала в другом окне. Я запустил третье окно терминала для того, чтобы собрать и исследовать данные профилирования кучи:
Тут используется инструмент Google pprof, который может визуализировать данные профилирования прямо в браузере.
Сначала я проверил показатели
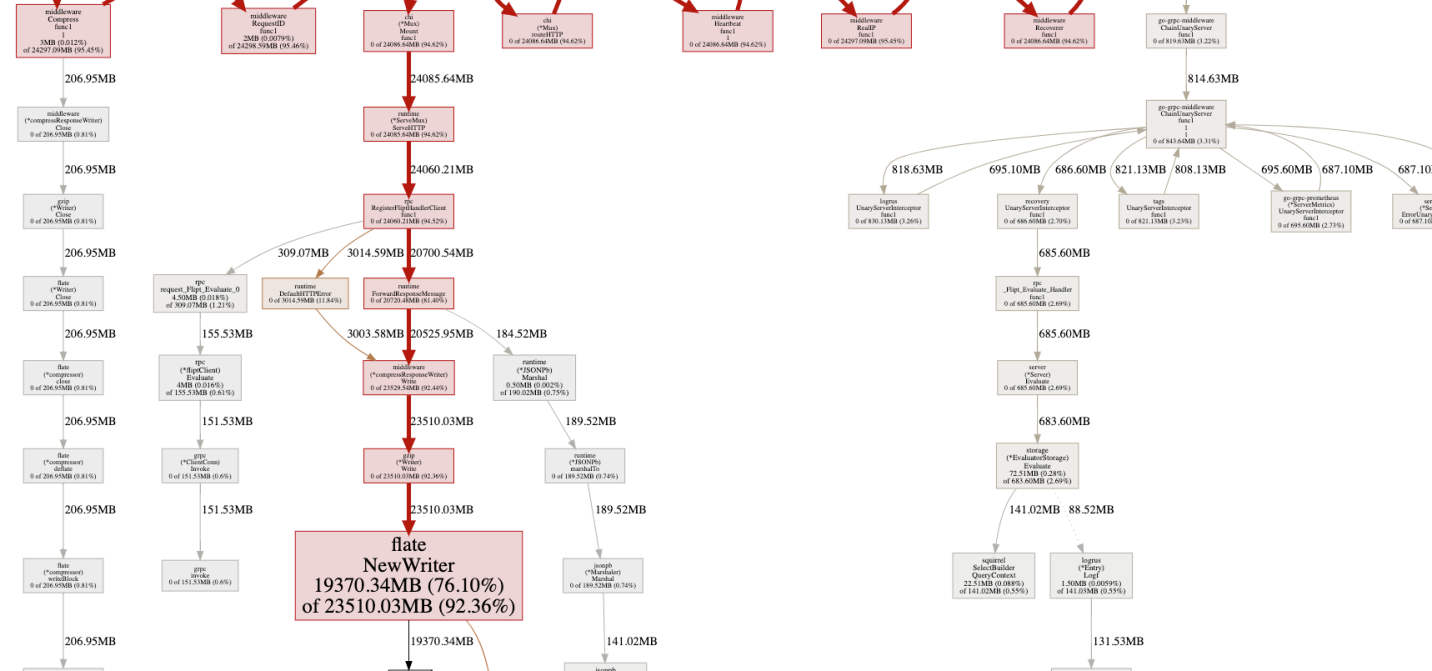
Анализ результатов профилирования (оригинал)
Возникало такое ощущение, что нечто, называемое
Я закомментировал вышеприведённую строку и снова запустил тесты. Как и следовало ожидать, огромное количество операций по выделению памяти исчезло.
Прежде чем я принялся за поиск решения этой проблемы, мне хотелось взглянуть на эти операции выделения памяти с другой стороны и понять, как они влияют на производительность. В частности, меня интересовало их влияние на время, которое уходит у программы на сборку мусора. Я помнил, что в Go ещё есть инструмент trace, который позволяет анализировать программы во время их выполнения и собирать сведения о них за некие периоды времени. В состав данных, собираемых trace, входят такие важные показатели, как использование кучи, число выполняемых горутин, сведения о сетевых и системных запросах, и, что было для меня особенно ценным, сведения о времени, затраченном в сборщике мусора.
Для эффективного сбора сведений о работающей программе мне нужно было сократить число запросов в секунду, отправляемых приложению с помощью Vegeta, так как сервер регулярно выдавал мне ошибки
Итак, я перезапустил Vegeta такой командой:
В результате, если сравнить это с предыдущим сценарием, на сервер поступала только десятая часть запросов, но делалось это в течение более длительного периода времени. Это позволило мне собрать качественные данные о работе программы.
В ещё одном окне терминала я запустил такую команду:
В результате в моём распоряжении оказался файл с трассировочными данными, собранными за 60 секунд. Исследовать этот файл можно было с помощью такой команды:
Выполнение этой команды привело к открытию собранных сведений в браузере. Они были представлены в удобном для изучения графическом виде.
Подробности о
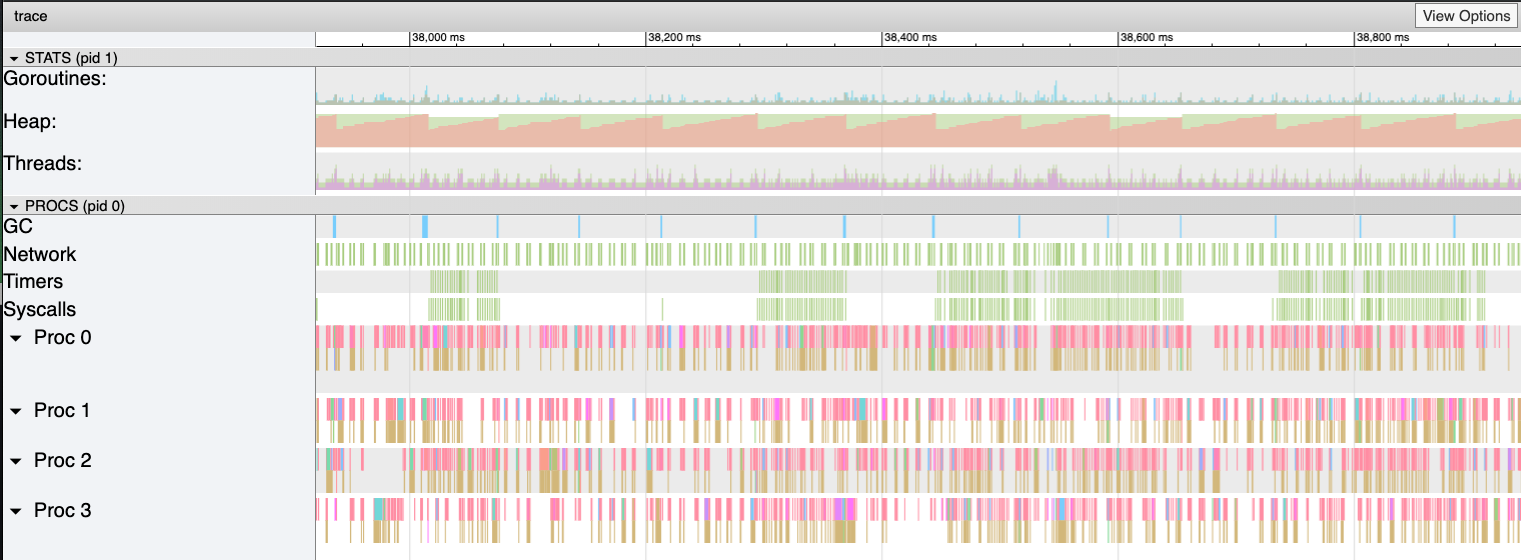
Результаты трассировки Flipt. Отчётливо виден пилообразный график выделения памяти в куче (оригинал)
На этом графике несложно заметить то, что объём памяти, выделяемой в куче, имеет тенденцию к довольно быстрому росту. При этом после роста следует резкое падение. Места падения объёма выделенной памяти — это операции по сборке мусора. Тут можно заметить и ярко выраженные синие столбцы в области GC, представляющие время, затраченное на сборку мусора.
Теперь я собрал все необходимые мне улики «преступления» и мог приступать к поиску решения проблемы с выделением памяти.
Для того чтобы выяснить причину, по которой вызов
Добравшись до исходного кода chi/middleware/compress.go @v3.3.4, я смог найти следующий метод:
В ходе дальнейших исследований я выяснил, что метод
Мне не хотелось ни отказываться от сжатия ответов API, ни искать новый HTTP-маршрутизатор и новую библиотеку поддержки промежуточного ПО. Поэтому я, в первую очередь, решил выяснить, можно ли справиться с моей проблемой, просто обновив Chi.
Я выполнил команду
Прежде чем поставить точку в этом вопросе, я решил поискать в репозитории Chi сообщения о проблемах или PR, в которых упоминалось бы нечто вроде «compression middleware». Мне попался один PR со следующим заголовком: «Re-wrote the middleware compression library» (Переписывание промежуточной библиотеки сжатия). Автор этого PR говорил следующее: «Кроме того, тут используется sync.Pool для кодировщиков, который имеет метод Reset(io.Writer), позволяющий снизить нагрузку на память».
Вот оно! К моему счастью, что этот PR был добавлен в ветку
Обновление это, что очень меня порадовало, было обратно совместимым, его использование не потребовало изменений в коде моего приложения.
Я запустил нагрузочные тесты и профилирование ещё раз. Это позволило мне убедиться в том, что обновление Chi решило проблему.
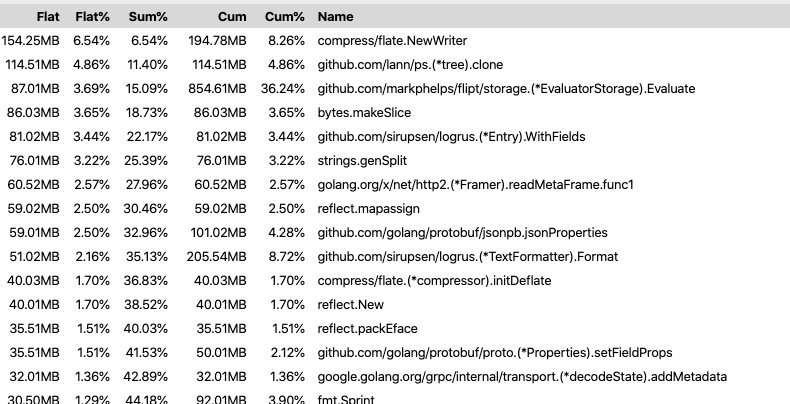
Теперь flate.NewWriter использует сотую часть от ранее использованного объёма выделяемой памяти (оригинал)
Взглянув ещё раз на результаты трассировки, я увидел, что размер кучи растёт теперь гораздо медленнее. Кроме того, уменьшилось и время, необходимое на сборку мусора.
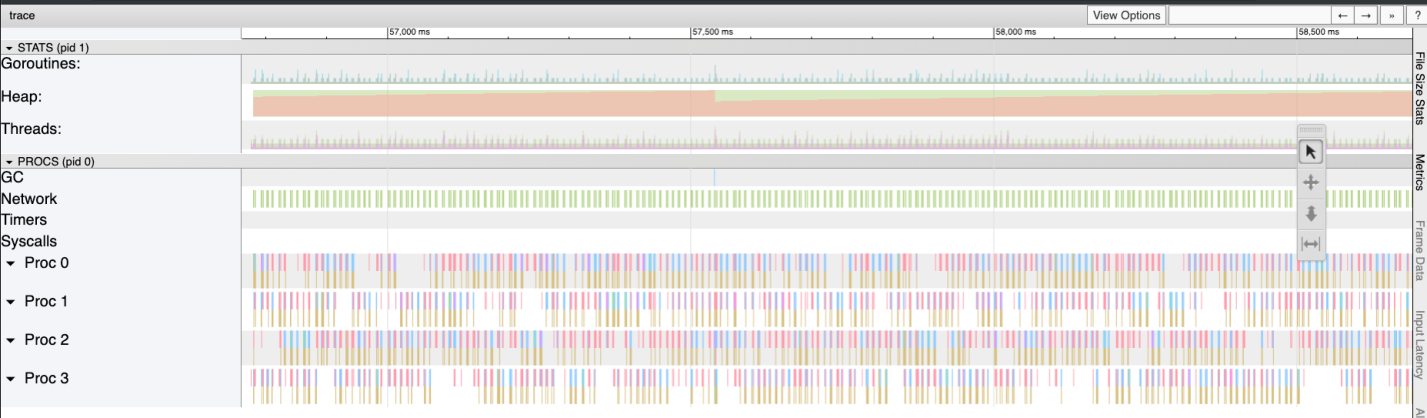
Прощай — «пила» (оригинал)
Через некоторое время я обновил репозиторий Flipt, обладая большей, чем раньше, уверенностью в том, что мой проект сможет достойно справиться с высокой нагрузкой.
Вот какие выводы я сделал после того, как мне удалось найти и устранить вышеописанные проблемы:
Уважаемые читатели! Как вы исследуете производительность своих Go-проектов?


Автор статьи, перевод которой мы публикуем, говорит, что недавно он решил заняться профилированием своего опенсорсного Go-проекта Flipt. Он хотел найти в проекте код, который можно было бы без особых усилий оптимизировать и тем самым ускорить программу. В ходе профилирования он обнаружил некоторые неожиданные проблемы в популярном проекте с открытым исходным кодом, который в приложении Flipt использовался для организации маршрутизации и поддержки промежуточного ПО. В итоге удалось снизить объём памяти, выделяемой приложением в процессе работы, в 100 раз. Это, в свою очередь, привело к уменьшению количества операций по сборке мусора и улучшило общую производительность проекта. Вот как это было.
Генерирование большого объёма трафика
Прежде чем я мог бы приступить к профилированию, я знал, что сначала мне нужно сгенерировать большой объём трафика, поступающего в приложение, что помогло бы мне увидеть некие шаблоны его поведения. Тут я сразу же столкнулся с проблемой, так как у меня нет ничего, что использовало бы Flipt в продакшне и получало бы некий объём трафика, позволяющий оценить работу проекта под нагрузкой. В результате я обнаружил отличный инструмент для нагрузочного тестирования проектов. Это — Vegeta. Авторы проекта говорят, что Vegeta — это универсальный HTTP-инструмент для нагрузочного тестирования. Этот проект родился из необходимости нагружать HTTP-сервисы большим количеством запросов, поступающих к сервисам с заданной частотой.
Проект Vegeta оказался именно тем инструментом, который был мне нужен, так как он позволял создать непрерывный поток запросов к приложению. Этими запросами можно было «обстреливать» приложение столько, сколько нужно для того, чтобы выяснить такие показатели, как выделение/использование памяти в куче, особенности работы горутин, время, затраченное на сборку мусора.
После проведения некоторых экспериментов я вышел на следующую конфигурацию запуска Vegeta:
echo 'POST http://localhost:8080/api/v1/evaluate' | vegeta attack -rate 1000 -duration 1m -body evaluate.jsonЭта команда запускает Vegeta в режиме
attack, отправляя HTTP POST-запросы REST API Flipt со скоростью 1000 запросов в секунду (а это, надо признать, серьёзная нагрузка) в течение минуты. JSON-данные, отправляемые Flipt, не особенно важны. Они нужны только для правильного формирования тела запроса. Такой запрос принимался Flipt-сервером, который мог выполнить процедуру проверки запроса.Обратите внимание на то, что сначала я решил подвергнуть испытанию конечную точку Flipt
/evaluate. Дело в том, что в ней выполняется большая часть кода, реализующего логику проекта и выполняющего «сложные» серверные вычисления. Я полагал, что анализ результатов работы этой конечной точки даст мне наиболее ценные данные о тех областях приложения, которые можно улучшить.Измерения
Теперь, когда у меня появился инструмент для генерирования достаточно большого объёма трафика, мне нужно было найти способ измерения того воздействия, которое этот трафик оказывал на работающее приложение. К счастью, в Go имеется довольно хороший стандартный набор инструментов, которые позволяют измерять производительность программ. Речь идёт о пакете pprof.
Я не будут вдаваться в подробности использования pprof. Не думаю, что сделаю это лучше Джулии Эванс, которая написала эту замечательную статью о профилировании Go-программ с помощью pprof (если вы её не читали — я определённо рекомендую вам на неё взглянуть).
Так как HTTP-маршрутизатор во Flipt реализован с помощью go-chi/chi, мне было совсем несложно включить pprof, воспользовавшись соответствующим промежуточным обработчиком Chi.
Итак, в одном окне у меня работал Flipt, а Vegeta, заваливая Flipt запросами, работала в другом окне. Я запустил третье окно терминала для того, чтобы собрать и исследовать данные профилирования кучи:
pprof -http=localhost:9090 localhost:8080/debug/pprof/heapТут используется инструмент Google pprof, который может визуализировать данные профилирования прямо в браузере.
Сначала я проверил показатели
inuse_objects и inuse_space для того, чтобы понять, что происходит в куче. Однако ничего примечательного мне обнаружить не удалось. Но когда я решил взглянуть на показатели alloc_objects и alloc_space, кое-что меня насторожило.Анализ результатов профилирования (оригинал)
Возникало такое ощущение, что нечто, называемое
flate.NewWriter, выделило в течение минуты 19370 Мб памяти. А это, кстати более 19 гигабайт! Тут, явно, происходило что-то странное. Но что именно? Если всмотреться в оригинал вышеприведённой схемы, то окажется, что flate.NewWriter вызывается из кода gzip.(*Writer).Write, вызываемом, в свою очередь, из middleware.(*compressResponseWriter).Write. Я быстро понял, что происходящее не имеет ничего общего с кодом Flipt. Проблема находилась где-то в коде промежуточного обработчика Chi, используемого для сжатия ответов от API.// проблемная строка
r.Use(middleware.Compress(gzip.DefaultCompression))Я закомментировал вышеприведённую строку и снова запустил тесты. Как и следовало ожидать, огромное количество операций по выделению памяти исчезло.
Прежде чем я принялся за поиск решения этой проблемы, мне хотелось взглянуть на эти операции выделения памяти с другой стороны и понять, как они влияют на производительность. В частности, меня интересовало их влияние на время, которое уходит у программы на сборку мусора. Я помнил, что в Go ещё есть инструмент trace, который позволяет анализировать программы во время их выполнения и собирать сведения о них за некие периоды времени. В состав данных, собираемых trace, входят такие важные показатели, как использование кучи, число выполняемых горутин, сведения о сетевых и системных запросах, и, что было для меня особенно ценным, сведения о времени, затраченном в сборщике мусора.
Для эффективного сбора сведений о работающей программе мне нужно было сократить число запросов в секунду, отправляемых приложению с помощью Vegeta, так как сервер регулярно выдавал мне ошибки
socket: too many open files. Я предположил, что это так из-за того, что на моём компьютере было установлено слишком низкое значение ulimit, но мне тогда не хотелось в это углубляться.Итак, я перезапустил Vegeta такой командой:
echo 'POST http://localhost:8080/api/v1/evaluate' | vegeta attack -rate 100 -duration 2m -body evaluate.jsonВ результате, если сравнить это с предыдущим сценарием, на сервер поступала только десятая часть запросов, но делалось это в течение более длительного периода времени. Это позволило мне собрать качественные данные о работе программы.
В ещё одном окне терминала я запустил такую команду:
get 'http://localhost:8080/debug/pprof/trace?seconds=60' -O profile/traceВ результате в моём распоряжении оказался файл с трассировочными данными, собранными за 60 секунд. Исследовать этот файл можно было с помощью такой команды:
go tool trace profile/traceВыполнение этой команды привело к открытию собранных сведений в браузере. Они были представлены в удобном для изучения графическом виде.
Подробности о
go tool trace можно почитать в этом хорошем материале.Результаты трассировки Flipt. Отчётливо виден пилообразный график выделения памяти в куче (оригинал)
На этом графике несложно заметить то, что объём памяти, выделяемой в куче, имеет тенденцию к довольно быстрому росту. При этом после роста следует резкое падение. Места падения объёма выделенной памяти — это операции по сборке мусора. Тут можно заметить и ярко выраженные синие столбцы в области GC, представляющие время, затраченное на сборку мусора.
Теперь я собрал все необходимые мне улики «преступления» и мог приступать к поиску решения проблемы с выделением памяти.
Решение проблемы
Для того чтобы выяснить причину, по которой вызов
flate.NewWriter приводил к столь большому количеству операций по выделению памяти, мне нужно было взглянуть на исходный код Chi. Для того чтобы узнать о том, какую версию Chi я использую, я выполнил следующую команду:go list -m all | grep chi
github.com/go-chi/chi v3.3.4+incompatibleДобравшись до исходного кода chi/middleware/compress.go @v3.3.4, я смог найти следующий метод:
func encoderDeflate(w http.ResponseWriter, level int) io.Writer {
dw, err := flate.NewWriter(w, level)
if err != nil {
return nil
}
return dw
}В ходе дальнейших исследований я выяснил, что метод
flate.NewWriter, через промежуточный обработчик, вызывался для каждого ответа. Это соответствовало огромному количеству операций по выделению памяти, которые я видел ранее, нагружая API тысячей запросов в секунду.Мне не хотелось ни отказываться от сжатия ответов API, ни искать новый HTTP-маршрутизатор и новую библиотеку поддержки промежуточного ПО. Поэтому я, в первую очередь, решил выяснить, можно ли справиться с моей проблемой, просто обновив Chi.
Я выполнил команду
go get -u -v "github.com/go-chi/chi", обновился до версии Chi 4.0.2, но код промежуточного обработчика для сжатия данных выглядел, как мне показалось, таким же, как раньше. Когда я снова запустил тесты, проблема никуда не делась.Прежде чем поставить точку в этом вопросе, я решил поискать в репозитории Chi сообщения о проблемах или PR, в которых упоминалось бы нечто вроде «compression middleware». Мне попался один PR со следующим заголовком: «Re-wrote the middleware compression library» (Переписывание промежуточной библиотеки сжатия). Автор этого PR говорил следующее: «Кроме того, тут используется sync.Pool для кодировщиков, который имеет метод Reset(io.Writer), позволяющий снизить нагрузку на память».
Вот оно! К моему счастью, что этот PR был добавлен в ветку
master, но, так как не было создано нового релиза Chi, мне нужно было обновляться так:go get -u -v "github.com/go-chi/chi@master"Обновление это, что очень меня порадовало, было обратно совместимым, его использование не потребовало изменений в коде моего приложения.
Результаты
Я запустил нагрузочные тесты и профилирование ещё раз. Это позволило мне убедиться в том, что обновление Chi решило проблему.
Теперь flate.NewWriter использует сотую часть от ранее использованного объёма выделяемой памяти (оригинал)
Взглянув ещё раз на результаты трассировки, я увидел, что размер кучи растёт теперь гораздо медленнее. Кроме того, уменьшилось и время, необходимое на сборку мусора.
Прощай — «пила» (оригинал)
Через некоторое время я обновил репозиторий Flipt, обладая большей, чем раньше, уверенностью в том, что мой проект сможет достойно справиться с высокой нагрузкой.
Итоги
Вот какие выводы я сделал после того, как мне удалось найти и устранить вышеописанные проблемы:
- Не стоит полагаться на предположения о том, что опенсорсные библиотеки (даже популярные) были оптимизированы, или о том, что в них нет очевидных проблем.
- Невинная проблема способна привести к серьёзным последствиям, к проявлениям «эффекта домино», особенно — под большой нагрузкой.
- Если есть возможность — стоит пользоваться sync.Pool.
- Полезно держать под рукой средства для тестирования проектов под нагрузкой и для их профилирования.
- Инструментарий Go и опенсорс — это замечательно!
Уважаемые читатели! Как вы исследуете производительность своих Go-проектов?

