
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Я выложил на Github новый проект A Simple GPU Hash Table.
Это простая хэш-таблица для GPU, способная обрабатывать в секунду сотни миллионов вставок. На моём ноутбуке с NVIDIA GTX 1060 код вставляет 64 миллиона случайно сгенерированных пар ключ-значение примерно за 210 мс и удаляет 32 миллиона пар примерно за 64 мс.
То есть скорость на ноутбуке составляет примерно 300 млн вставок/сек и 500 млн удалений/сек.
Таблица написана на CUDA, хотя ту же методику можно применить к HLSL или GLSL. У реализации есть несколько ограничений, обеспечивающих высокую производительность на видеокарте:
- Обрабатываются только 32-битные ключи и такие же значения.
- Хэш-таблица имеет фиксированный размер.
- И этот размер должен быть равен двум в степени.
Для ключей и значений нужно зарезервировать простой разграничивающий маркер (в приведённом коде это 0xffffffff).
Хэш-таблица без блокировок
В хэш-таблице используется открытая адресация с линейным зондированием, то есть это просто массив пар ключ-значение, который хранится в памяти и имеет превосходную производительность кэша. Этого не скажешь о связывании в цепочку (chaining), что подразумевает поиск указателя в связанном списке. Хэш-таблица является простым массивом, хранящим элементы
KeyValue:struct KeyValue
{
uint32_t key;
uint32_t value;
};
Размер таблицы равен двойке в степени, а не простому числу, потому что для применения pow2/AND-маски достаточно одной быстрой инструкции, а оператор модуля работает гораздо медленнее. Это важно в случае линейного зондирования, поскольку при линейном поиске по таблице индекс слота должен быть обёрнут в каждый слот. И в результате добавляется стоимость операции по модулю в каждом слоте.
Таблица хранит только ключ и значение для каждого элемента, а не хэш ключа. Поскольку таблица хранит лишь 32-битные ключи, хэш вычисляется очень быстро. В приведённом коде используется хэш Murmur3, который выполняет лишь несколько сдвигов, XOR-ов и умножений.
В хэш-таблице применяется методика защиты от блокировок, которая не зависит от порядка размещения в памяти. Даже если некоторые операции записи нарушают очерёдность других таких операций, хэш-таблица всё равно сохранит корректное состояние. Об этом мы поговорим ниже. Методика отлично работает с видеокартами, в которых конкурентно выполняются тысячи потоков.
Ключи и значения в хэш-таблице инициализируются пустыми.
Код можно модифицировать, чтобы он мог обрабатывать и 64-битные ключи и значения. Для ключей требуются атомарные операции чтения, записи и сравнения с обменом (compare-and-swap). А для значений нужны атомарные операции чтения и записи. К счастью, в CUDA операции чтения-записи для 32- и 64-битных значений являются атомарными до тех пор, пока они выровнены естественным образом (см. здесь), а современные видеокарты поддерживают 64-битные атомарные операции сравнения с обменом. Конечно, при переходе на 64 бита производительность несколько снизится.
Состояние хэш-таблицы
Каждая пара ключ-значение в хэш-таблице может иметь одно из четырёх состояний:
- Ключ и значение пусты. В таком состоянии хэш-таблица инициализируется.
- Ключ был записан, а значение ещё нет. Если другой поток исполнения в этот момент считывает данные, то затем он возвращает пустое значение. Это нормально, то же самое произошло бы, если бы другой поток исполнения отработал чуть раньше, а мы говорим о конкурентной структуре данных.
- Записаны и ключ, и значение.
- Значение доступно для других потоков исполнения, а ключ — ещё нет. Такое может произойти, потому что модель программирования в CUDA подразумевает слабо упорядоченную модель памяти. Это нормально, при любом событии ключ всё ещё пустой, даже если значение таким уже не является.
Важный нюанс заключается в том, что как только ключ был записан в слот, от уже не перемещается — даже если ключ будет удалён, об этом мы поговорим ниже.
Код хэш-таблицы работает даже со слабо упорядоченными моделями памяти, в которых не известен порядок чтения и записей в память. Когда мы будем разбирать вставку, поиск и удаление в хэш-таблице, помните, что каждая пара ключ-значение находится в одном из четырёх вышеописанных состояний.
Вставка в хэш-таблицу
CUDA-функция, которая вставляет в хэш-таблицу пары ключ-значение, выглядит так:
void gpu_hashtable_insert(KeyValue* hashtable, uint32_t key, uint32_t value)
{
uint32_t slot = hash(key);
while (true)
{
uint32_t prev = atomicCAS(&hashtable[slot].key, kEmpty, key);
if (prev == kEmpty || prev == key)
{
hashtable[slot].value = value;
break;
}
slot = (slot + 1) & (kHashTableCapacity-1);
}
}
Для вставки ключа код итерирует по массиву хэш-таблицы начиная с хэша вставляемого ключа. В каждом слоте массива выполняется атомарная операция сравнения с обменом, при которой ключ в этом слоте сравнивается с пустым. Если обнаруживается несоответствие, то ключ в слоте обновляется на вставляемый ключ, а затем возвращается оригинальный ключ слота. Если этот оригинальный ключ был пустым или соответствовал вставляемому ключу, значит код нашёл подходящий для вставки слот и вносит в слот вставляемое значение.
Если в одном вызове ядра
gpu_hashtable_insert() есть несколько элементов с одинаковым ключом, тогда любое из их значений может быть записано в слот ключа. Это считается нормальным: одна из операций записи ключа-значения в ходе вызова будет успешной, но поскольку всё это происходит параллельно в рамках нескольких потоков исполнения, то мы не можем предсказать, какая операция записи в память будет последней.Поиск в хэш-таблице
Код для поиска ключей:
uint32_t gpu_hashtable_lookup(KeyValue* hashtable, uint32_t key)
{
uint32_t slot = hash(key);
while (true)
{
if (hashtable[slot].key == key)
{
return hashtable[slot].value;
}
if (hashtable[slot].key == kEmpty)
{
return kEmpty;
}
slot = (slot + 1) & (kHashTableCapacity - 1);
}
}
Чтобы найти значение ключа, хранящегося в таблице, мы итерируем по массиву начиная с хэша искомого ключа. В каждом слоте мы проверяем, является ли ключ тем, который мы ищем, и если да, то возвращаем его значение. Также мы проверяем, является ли ключ пустым, и если да, то прерываем поиск.
Если нам не удаётся найти ключ, то код возвращает пустое значение.
Все эти операции поиска могут выполняться конкурентно в ходе вставок и удалений. Каждая пара в таблице будет иметь для потока одно из четырёх вышеописанных состояний.
Удаление в хэш-таблице
Код для удаления ключей:
void gpu_hashtable_delete(KeyValue* hashtable, uint32_t key, uint32_t value)
{
uint32_t slot = hash(key);
while (true)
{
if (hashtable[slot].key == key)
{
hashtable[slot].value = kEmpty;
return;
}
if (hashtable[slot].key == kEmpty)
{
return;
}
slot = (slot + 1) & (kHashTableCapacity - 1);
}
}
Удаление ключа выполняется необычно: мы оставляем ключ в таблице и помечаем его значение (не сам ключ) пустым. Этот код очень похож на
lookup(), за исключением того, что при обнаружении совпадения по ключу он делает его значение пустым.Как упоминалось выше, как только ключ записан в слот, он уже не перемещается. Даже при удалении элемента из таблицы ключ остаётся на месте, просто его значение становится пустым. Это означает, что нам не нужно использовать атомарную операцию записи значения слота, потому что не важно, является ли текущее значение пустым или нет — оно всё-равно станет пустым.
Изменение размера хэш-таблицы
Изменить размер хэш-таблицы можно с помощью создания более крупной таблицы и вставки в неё непустых элементов из старой таблицы. Я эту функциональность не реализовал, потому что хотел сохранить образец кода простым. Более того, в CUDA-программах выделение памяти часто выполняется в хост-коде, а не в ядре CUDA.
В статье A Lock-Free Wait-Free Hash Table описано, как изменять такую структуру данных, защищённую от блокировок.
Конкурентность
В приведённых выше фрагментах кода функции
gpu_hashtable_insert(), _lookup() и _delete() обрабатывают по одной паре ключ-значение за раз. А ниже gpu_hashtable_insert(), _lookup() и _delete() обрабатывают массив пар параллельно, каждую пару в отдельном GPU-потоке исполнения:// CPU code to invoke the CUDA kernel on the GPU
uint32_t threadblocksize = 1024;
uint32_t gridsize = (numkvs + threadblocksize - 1) / threadblocksize;
gpu_hashtable_insert_kernel<<<gridsize, threadblocksize>>>(hashtable, kvs, numkvs);
// GPU code to process numkvs key/values in parallel
void gpu_hashtable_insert_kernel(KeyValue* hashtable, const KeyValue* kvs, unsigned int numkvs)
{
unsigned int threadid = blockIdx.x*blockDim.x + threadIdx.x;
if (threadid < numkvs)
{
gpu_hashtable_insert(hashtable, kvs[threadid].key, kvs[threadid].value);
}
}
Хэш-таблица с защитой от блокировок поддерживает конкурентные вставки, поиски и удаления. Поскольку пары ключ-значение всегда находятся в одном из четырёх состояний, а ключи не перемещаются, таблица гарантирует корректность даже при одновременном использовании операций разных видов.
Однако если мы параллельно обрабатываем пакет из вставок и удалений, и если во входном массиве пар содержатся дублирующиеся ключи, то мы не сможем предсказать, какие пары «победят» — будут записаны в хэш-таблицу последними. Допустим, мы вызвали код вставки со входным массивом из пар
A/0 B/1 A/2 C/3 A/4. Когда код завершится, пары B/1 и C/3 гарантированно будут присутствовать в таблице, но при этом в ней окажется любая из пар A/0, A/2 или A/4. Это может быть проблемой, а может и не быть — всё зависит от применения. Вы можете заранее знать, что во входном массиве нет дублирующихся ключей, или вам может быть не важно, какое значение было записано последним.Если для вас это проблема, то нужно разделить дублирующиеся пары по разным системным CUDA-вызовам. В CUDA любая операция с вызовом ядра всегда завершается до следующего вызова ядра (по крайней мере, внутри одного потока. В разных потоках ядра исполняются параллельно). Если в приведённом выше примере вызвать одно ядро с
A/0 B/1 A/2 C/3, а другое с A/4, тогда ключ A получит значение 4.Теперь поговорим о том, должны ли функции
lookup() и delete() использовать простой (plain) или переменный (volatile) указатель на массив пар в хэш-таблице. Документация CUDA утверждает, что:Компилятор может по своему усмотрению оптимизировать операции чтения и записи в глобальную или общую память … Эти оптимизации можно отключить с помощью ключевого слова volatile: … любая ссылка на эту переменную компилируется в настоящую инструкцию чтения или записи в память.Соображения корректности не требуют применения
volatile. Если поток исполнения использует закэшированное значение из более ранней операции чтения, то это означает, что он будет использовать немного устаревшую информацию. Но всё же это информация из корректного состояния хэш-таблицы в определённый момент вызова ядра. Если вам нужно использовать самую свежую информацию, то можно применять указатель volatile, но тогда немного снизится производительность: по моим тестам — при удалении 32 млн элементов скорость снизилась с 500 млн удалений/сек до 450 млн удалений/сек.Производительность
В тесте на вставку 64 млн элементов и удаление 32 млн из них конкуренция между
std::unordered_map и хэш-таблицей для GPU фактически отсутствует: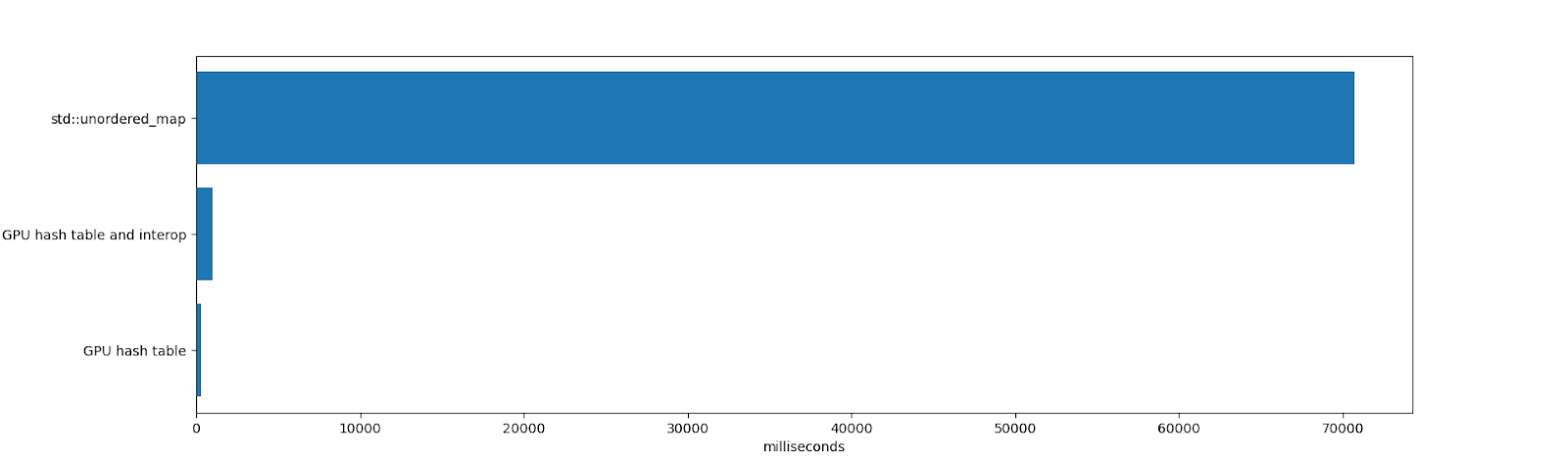
std::unordered_map потратила 70 691 мс на вставку и удаление элементов с последующим освобождением unordered_map (освобождение от миллионов элементов занимает немало времени, потому что внутри unordered_map выполняются многочисленные выделения памяти). Честно говоря, у std:unordered_map совсем другие ограничения. Это единый CPU-поток исполнения, он поддерживает ключи-значения любого размера, хорошо работает при высоких коэффициентах использования и показывает стабильную производительность после многочисленных удалений.Длительность работы хэш-таблицы для GPU и межпрограммного взаимодействия составила 984 мс. Сюда входит время, затраченное на размещение таблицы в памяти и её удаление (однократное выделение 1 Гб памяти, которое в CUDA занимает какое-то время), вставка и удаление элементов, а также итерирование по ним. Также учтены все копирования в память и из памяти видеокарты.
Работа самой хэш-таблицы заняла 271 мс. Сюда входит время, потраченное видеокартой на вставку и удаление элементов, и не учитывается время на копирование в память и итерирование по получившейся таблице. Если GPU-таблица живёт долго, или если хэш-таблица содержится целиком в памяти видеокарты (например, для создания хэш-таблицы, которая будет использоваться другим GPU-кодом, а на центральным процессором), то результат тестирования релевантен.
Хэш-таблица для видеокарты демонстрирует высокую производительность благодаря большой пропускной способности и активному распараллеливанию.
Недостатки
У архитектуры хэш-таблицы есть несколько проблем, о которых нужно помнить:
- Линейному зондированию мешает кластеризация, из-за которой ключи в таблице размещаются далеко не идеально.
- Ключи не удаляются с помощью функции
deleteи со временем загромождают таблицу.
В результате производительность хэш-таблицы может постепенно снижаться, особенно если она существует долго и в ней выполняются многочисленные вставки и удаления. Одним из способов смягчения этих недостатков является перехэширование в новую таблицу с достаточно низким коэффициентом использования и фильтрацией удалённых ключей при перехэшировании.
Чтобы проиллюстрировать описанные проблемы, использую вышеприведённый код для создания таблицы на 128 млн элементов, циклически буду вставлять 4 млн элементов, пока не заполню 124 млн слотов (коэффициент использования около 0,96). Вот таблица результатов, каждая строка — это вызов ядра CUDA со вставкой 4 млн новых элементов в одну хэш-таблицу:
| Коэффициент использования | Длительность вставки 4 194 304 элементов |
| 0,00 | 11,608448 мс (361,314798 млн ключей/сек.) |
| 0,03 | 11,751424 мс (356,918799 млн ключей/сек.) |
| 0,06 | 11,942592 мс (351,205515 млн ключей/сек.) |
| 0,09 | 12,081120 мс (347,178429 млн ключей/сек.) |
| 0,12 | 12,242560 мс (342,600233 млн ключей/сек.) |
| 0,16 | 12,396448 мс (338,347235 млн ключей/сек.) |
| 0,19 | 12,533024 мс (334,660176 млн ключей/сек.) |
| 0,22 | 12,703328 мс (330,173626 млн ключей/сек.) |
| 0,25 | 12,884512 мс (325,530693 млн ключей/сек.) |
| 0,28 | 13,033472 мс (321,810182 млн ключей/сек.) |
| 0,31 | 13,239296 мс (316,807174 млн ключей/сек.) |
| 0,34 | 13,392448 мс (313,184256 млн ключей/сек.) |
| 0,37 | 13,624000 мс (307,861434 млн ключей/сек.) |
| 0,41 | 13,875520 мс (302,280855 млн ключей/сек.) |
| 0,44 | 14,126528 мс (296,909756 млн ключей/сек.) |
| 0,47 | 14,399328 мс (291,284699 млн ключей/сек.) |
| 0,50 | 14,690304 мс (285,515123 млн ключей/сек.) |
| 0,53 | 15,039136 мс (278,892623 млн ключей/сек.) |
| 0,56 | 15,478656 мс (270,973402 млн ключей/сек.) |
| 0,59 | 15,985664 мс (262,379092 млн ключей/сек.) |
| 0,62 | 16,668673 мс (251,627968 млн ключей/сек.) |
| 0,66 | 17,587200 мс (238,486174 млн ключей/сек.) |
| 0,69 | 18,690048 мс (224,413765 млн ключей/сек.) |
| 0,72 | 20,278816 мс (206,831789 млн ключей/сек.) |
| 0,75 | 22,545408 мс (186,038058 млн ключей/сек.) |
| 0,78 | 26,053312 мс (160,989275 млн ключей/сек.) |
| 0,81 | 31,895008 мс (131,503463 млн ключей/сек.) |
| 0,84 | 42,103294 мс (99,619378 млн ключей/сек.) |
| 0,87 | 61,849056 мс (67,815164 млн ключей/сек.) |
| 0,90 | 105,695999 мс (39,682713 млн ключей/сек.) |
| 0,94 | 240,204636 мс (17,461378 млн ключей/сек.) |
По мере роста коэффициента использования производительность снижается. Это нежелательно в большинстве случаев. Если приложение вставляет в таблице элементы, а затем отбрасывает их (например, при подсчёте слов в книге), то это не является проблемой. Но если приложение использует долгоживующую хэш-таблицу (например, в графическом редакторе для хранения непустых частей изображений, когда пользователь часто вставляет и удаляет информацию), то такое поведение может доставлять неприятности.
И измерил глубину зондирования хэш-таблицы после 64 млн вставок (коэффициент использования 0,5). Средняя глубина составила 0,4774, так что большинство ключей располагались в либо в наилучшем из возможных слотов, либо в одном слоте от лучшей позиции. Максимальная глубина зондирования была равна 60.
Затем я измерил глубину зондирования в таблице с 124 млн вставок (коэффициент использования 0,97). Средняя глубина составила уже 10,1757, а максимальная — 6474 (!!). Производительность линейного зондирования сильно падает при больших коэффициентах использования.
Лучше всего сохранять у этой хэш-таблицы низкий коэффициент использования. Но тогда мы повышаем производительность за счёт потребления памяти. К счастью, в случае с 32-битными ключами и значениями и это может быть оправдано. Если в приведённом выше примере в таблице на 128 млн элементов сохранять коэффициент использования 0,25, то мы сможем разместить в ней не больше 32 млн элементов, а остальные 96 млн слотов будут потеряны — по 8 байтов на каждую пару, 768 Мб потерянной памяти.
Обратите внимание, что речь идёт о потере памяти видеокарты, которая является более ценным ресурсом, чем системная память. Хотя большинство современных настольных видеокарт, поддерживающих CUDA, имеют не меньше 4 Гб памяти (на момент написания статьи у NVIDIA 2080 Ti есть 11 Гб), всё же терять такие объёмы будет не самым мудрым решением.
Позднее я подробнее напишу о создании хэш-таблиц для видеокарт, у которых нет проблем с глубиной зондирования, а также о способах повторного использования удалённых слотов.
Измерение глубины зондирования
Чтобы определить глубину зондирования ключа, мы можем извлечь хэш ключа (его идеальный индекс в таблице) из его фактического табличного индекса:
// get_key_index() -> index of key in hash table
uint32_t probelength = (get_key_index(key) - hash(key)) & (hashtablecapacity-1);
Из-за магии двух двоичных чисел в дополнительном коде и того факта, что ёмкость хэш-таблице равна двойке в степени, этот подход будет работать даже тогда, когда индекс ключа переносится в начало таблицы. Возьмём ключ, который хэшируется в 1, но вставлен в слот 3. Тогда для таблицы с ёмкостью 4 мы получим
(3 — 1) & 3, что эквивалентно 2.Заключение
Если у вас есть вопросы или комментарии, напишите мне в Twitter или откройте новую тему в репозитории.
Это код написан под вдохновением от прекрасных статей:
- The World’s Simplest Lock-Free Hash Table
- A Lock-Free Wait-Free Hash Table
В будущем я продолжу писать о реализациях хэш-таблиц для видеокарт и буду анализировать их производительность. В планах у меня связывание в цепочку, хэширование Робина Гуда и кукушкино хэширование с использованием атомарных операций в структурах данных, которые удобны для видеокарт.


