
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Эта маленькая заметка предназначена для начинающих разработчиков, которые хотят понять как линейные функции устроены «под капотом». Для опытных специалистов в моей заметки нет ничего нового. И так. Линейные функции применяются очень часто в самых разнообразных проектах, например, в сложных компонентах для создания отчётов или в задачах ранжирования результатов поиска. Предлагаю вместе посмотреть на то, как это работает.
Пусть существует некая функция, которая используется на портале для ранжирования популярных заметок. На вход она принимает количество просмотров документа, а возвращает некий score, по которому и происходит сортировка. При этом, у вас нет доступа к исходному коду — всё работает по принципу чёрного ящика. Необходимо вычислить формулу ранжирования. Проведём эксперимент: многократно передадим данные и запишем ответ.
Для начала есть смысл взглянуть на сами данные. Если вы отобразите массив данных с несколькими миллионами объектов, то человек не сможет всё это осмысленно прочитать. Придётся придумывать способ понятно описать его. Частая ошибка — не изучив набор данных использовать среднее значение или медиану. Подобный подход чреват серьёзным искажением реальной картины.
Попробуем преобразовать большой массив в специальную структуру данных, которая содержит описательную статистику (среднеквадратическое отклонение, максимум, минимум, среднее, медиана, нижний и верхний квартиль). Но не будем торопиться с таким решением. Есть даже известный набор данных («квартет Энскомба»), который хорошо иллюстрирует эту проблему. Очень советую про него прочитать.
В такой ситуации на помощь разработчику приходит гистограмма распределения. Она является удобным способом наглядно отобразить массив из гигантского количества измерений случайной величины. Суть очень простая: разбиваем массив на интервалы и отображаем количество элементов в каждом интервале. Визуально это выглядит следующим образом:
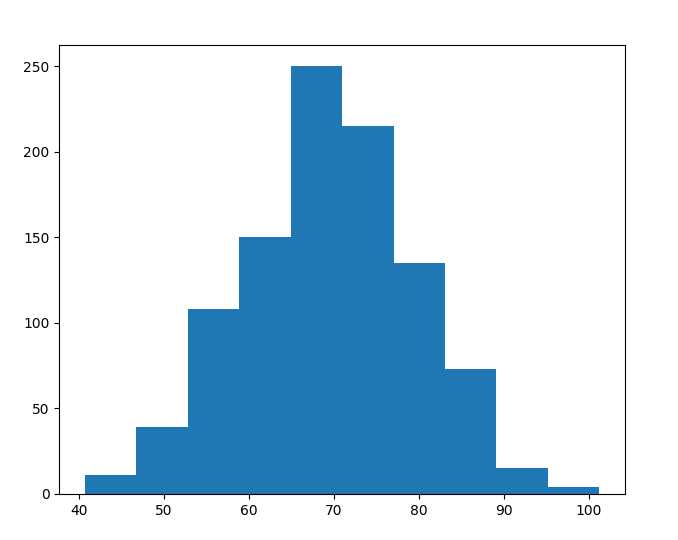
В итоге мы видим распределение случайной величины. Регулируя число интервалов можно добиться адекватного представления. Теперь нам нужен способ увидеть взаимосвязь этой случайной величины с другой. Отобразим наблюдения в виде точек на плоскости, где по оси X будет score, а по Y наш единственный предиктор (признак). И вот перед вами появляется график:

На нём показано, что обе переменных сильно коррелируют между собой, следовательно, делаем предположение о линейной зависимости (score=a+bx). А теперь самая суть, но очень кратко: простая линейная регрессия — это произведение коэффициента и признака, к которым добавляется смещение. Вот и всё. Степень линейной взаимосвязи вычисляют следующим образом:
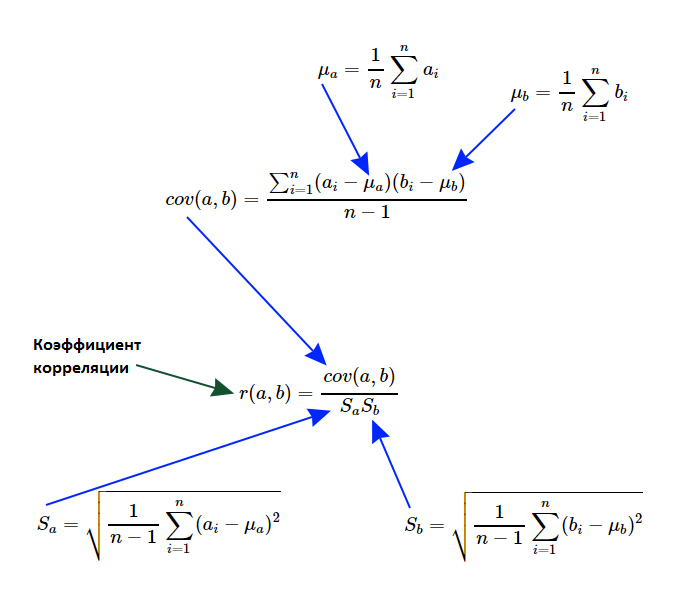
Не все точки выстроились на одну линию, что говорит нам о небольшом влиянии неизвестного фактора. Это я специально сделал, для красоты. Подобрать коэффициенты можно с помощью готовых решений, допустим, scikit-learn. Так, например, класс LinearRegression после обучения (fit) позволяет получить смещение (intercept) и массив коэффициентов (coef). Подставляем значения в формулу и проверяем результат с помощью метрик mean_absolute_error и median_absolute_error. Собственно, это и есть решение нашей задачи. В случае множества признаков суть не меняется: под капотом всё устроено аналогичным образом (смещение + скалярное произведение вектора признаков и соответствующих коэффициентов).
А теперь превратим эту функцию в классификатор, который называется логистическая регрессия. Под капотом это обычная линейная регрессия, только результат её работы передают в сигмоиду. Далее выполняется проверка «если результат больше 0.5, то класс 1, иначе класс 0». По сути, это формула гиперплоскости, разделяющей классы.
Обе упомянутые линейные модели — это очень быстрые и простые алгоритмы, которые достаточно легко внедрить в любой проект. Надеюсь, теперь стало чуть проще понять, как это устроено «под капотом». Сталкиваясь с этими алгоритмами, начинающему разработчику будет проще понять их принципы работы.




