

… Работаете вы, например, над очень большим проектом. Проект реально очень большой, написан на C или C++, и его билд «с нуля» может занять несколько часов, да и сборка после каких-то фиксов или патчей тоже требует немало времени, особенно если изменения коснулись чего-то фундаментального или много где используемого. Вы запускаете компиляцию на своем десктопе, все ядра загружены, вентиляторы крутятся как бешенные, и при этом вокруг вас еще десяток машин ваших коллег, которые по сути дела простаивают. Нехорошо.
Или, например, сделали вы себе в команде билд-сервер, на который можно отправлять задачи для сборки. Но если вдруг запустить компиляцию нужно будет сразу нескольким людям, сервер захлбенется, и ждать все равно придется долго. Вы добавляете второй или даже третий билд-сервер, распределяете сервера между членами проекта, но в итоге мы можем получить аналогичную ситуацию: один сервер максимально напрягается, пытаясь прожевать одновременно несколько сборок, другие простаивают. Можно, конечно, заранее смотреть, какой из серверов менее загружен, и запускать задачу именно на нем… Но лучше все-таки автоматизировать этот процесс, а в идеале — автоматически распараллелить компиляцию, используя все доступные ресурсы.
Если даже отвлечься от суровой энтерпрайзной работы, подобные мысли могут приходить в голову и при уютном пилении какого-нибудь хобби-проекта: ваш компьютер активно что-то компилирует, а рядом лежит лаптоп с тоже мощным процессором, и было бы неплохо, поделиться с ним работой.
И в этом всём может помочь ICECC.
На хабре про него упоминали только один раз мельком в статье в блоге PVS-Studio, поэтому я решил рассказать про него поподробнее.
Где взять
Во многих дистрибутивах пакеты уже есть в репах, например в Debian:
sudo apt-get install iceccНастройка планировщика
Координатор, он же планировщик, он же scheduler. Устанавливается на одном из узлов, и занимается распределениями задач компиляции между хостами.
Редактируем конфигурационный файл icecc:
sudo nano /etc/icecc/icecc.confНас интересует параметр ICECC_NETNAME. Присвоим ему любой строковой идентификатор, который будет общим для всех узлов в нашем кластере.
ICECC_NETNAME="MYNET"Запускаем планировщик и настраиваем для него автоматический запуск при старте системы:
systemctl start icecc-schedulersystemctl enable icecc-schedulerICECC в своей работе использует порты TCP 10245 8765 8766 и UDP 8765, поэтому не забудьте разрешить их на фаерволе.
Настройка клиентов
sudo nano /etc/icecc/icecc.confНас интересуют следущие параметры
# С каким приоритетом запускать задачи компиляции. Наврядли мы хотим, чтобы чьи-нибудь чужие таски тормозили нам основную работу, поэтому ставим приоритет пониже
ICECC_NICE_LEVEL="19"# Название кластера. Должно совпадать с тем, что мы задали для scheduler'а
ICECC_NETNAME="MYNET"# Максимальное количество параллельно выполняемых процессов компиляции на узле. У меня на десктопе 8 ядер, соответственно я поставил значение 6, чтобы в случае чего остальные были свободны для основных процессов на машине
ICECC_MAX_JOBS="6"# IP-адрес планировщика. Можно его не задавать, и тогда ICECC попробует найти его с помощью броадкаста по сети — для этого и нужен был 8765 UDP порт. Однако лучше зададим адрес явно.
ICECC_SCHEDULER_HOST="192.168.0.1"# А вот с этой опцией по-аккуратнее. Она позволит быть хитрой собакой-на-сене, и не разрешать запускать на своей машине чужие задачи. Свои на чужих — можно, чужие на своей — нельзя :)
#ICECC_ALLOW_REMOTE="yes"
После этого перезапускаем демон
sudo service iceccd restartИ всё готово.
Как оно работает
Чтобы начать компилировать код не локально, а в ICECC-кластере, нужно не вызывать компилятор как обычно, а использовать соответствующий бинарь ICECC:
/usr/lib/icecc/bin/cc
/usr/lib/icecc/bin/c++Это можно явно прописать в Makefile или в генераторе-конфигураторе типа CMake, а можно, учитывая совпадающие имена бинарников, просто прописать путь к /usr/lib/icecc/bin в начало переменной окружения PATH, чтобы система обращалась туда в первую очередь, а дальше ICECC все уже разрулит сам:
export PATH=/usr/lib/icecc/bin:$PATHНу и не забываем про опцию "-j", чтобы явно указать, что мы хотим собираться не в один, а в несколько потоков.
Сам процесс же будет проходить следущим образом:
- Препроцессирование кода выполняется на локальной машине
- Сгенерированные препроцессором .i-файлы передаются на узлы кластера, выбранные планировщиком, и компилируются там
- Полученные в результате всего этого объектные файлы линкуются снова на локальной машине.
После прочтения этого может возникнуть вопрос: а что если на разных узлах кластера у нас будут разные версии компилятора, или, что еще хуже, компилятор будет как-то специфически пропатчен? Ответ на этот вопрос просто: ICECC подготавливает специальный «бандл» из всего необходимого (компилятор, стандартная библиотека, вспомогательные компоненты) и закидывает его на узлы, которые будут выполнять вашу задачу.
Поглядеть, как это происходит, и даже поучаствовать в процессе, можно командой
icecc --build-nativeКоторая выдаст нам что-то подобное:
adding file /bin/true
adding file /lib/x86_64-linux-gnu/libc.so.6
adding file /lib64/ld-linux-x86-64.so.2
adding file /usr/bin/gcc
adding file /usr/bin/g++
adding file /usr/bin/cc1=/usr/lib/gcc/x86_64-linux-gnu/7/cc1
adding file /usr/lib/x86_64-linux-gnu/libisl.so.19
adding file /usr/lib/x86_64-linux-gnu/libmpc.so.3
adding file /usr/lib/x86_64-linux-gnu/libmpfr.so.6
adding file /usr/lib/x86_64-linux-gnu/libgmp.so.10
adding file /lib/x86_64-linux-gnu/libdl.so.2
adding file /lib/x86_64-linux-gnu/libz.so.1
adding file /lib/x86_64-linux-gnu/libm.so.6
adding file /usr/bin/cc1plus=/usr/lib/gcc/x86_64-linux-gnu/7/cc1plus
adding file /usr/bin/as
adding file /usr/lib/x86_64-linux-gnu/libopcodes-2.30-system.so
adding file /usr/lib/x86_64-linux-gnu/libbfd-2.30-system.so
adding file /usr/lib/gcc/x86_64-linux-gnu/7/liblto_plugin.so
adding file /usr/bin/objcopy
adding file /etc/ld.so.conf=/tmp/icecc_ld_so_conf2sYxQI
creating 7379e30774ea2e8efcda5f7614ac2fc2.tar.gz
В итоге мы получаем файл, где есть все необходимое, и более того, в будущем, отправляя задачи на сборку, можно явно указывать, какой бандл будет использовать для компиляции.
ICECC_VERSION=<filename_of_archive_containing_your_environment>
С ICECC также возможна кросс-компиляция (когда, например, у вас узлы в кластере с разной процессорной архитектурой) и даже сборка проектов для embedded-систем. Всё это описано в документации.
Мониторинг
Если вы установили пакет icecc-monitor, то можно посмотреть, что происходит в кластере:
icemon -n MYNET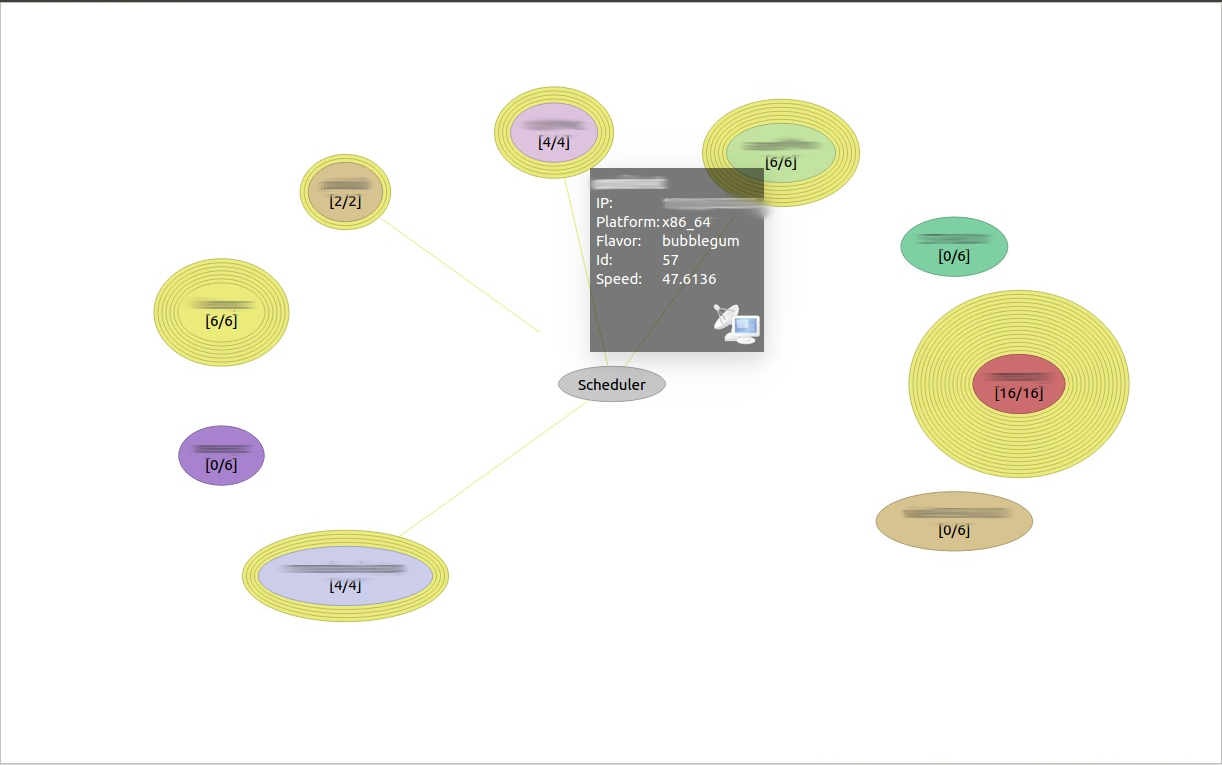
Как видно, на мнемосхеме отображаются все сборочные машины и планировщик. Каждому узлу выдается свой цвет (а поскольку другое название ICECC — icecream, то называются цвета по сортам мороженого), также, наведя курсор на узел, можно увидеть, что планировщик ICECC оценивает производительность и загруженность узла, что влияет на то, будут ли отправляться на него задачи и сколько.
Благодаря цветовой дифференциации хорошо различимо, чьи задачи компиляции сейчас выполняются ина каких конкретно нодах.
Заключение
В целом, впечатления от ICECC только положительные. Понятно, что везде есть сфоя специфика, и все зависит от конкретной кодовой базы, но в нашем случае ускорение наблюдается вполне существенное (бенчарки не проводили, все субъективно), да и иметь дело с icecc одно удовольствие — заработал он буквально с пол-пинка :)
Подробную документацию и исходники можно найти на Github проекта.


: Часть 2 — Компиляция с Emscripten")