


Автор статьи: Рустем Галиев
IBM Senior DevOps Engineer & Integration Architect
Привет, Хабр!
Репликация PostgreSQL с опережающей записью (WAL) — ключевая концепция в высоконагруженных архитектурах, поскольку она позволяет создавать высокодоступные и отказоустойчивые системы баз данных.
Что такое WAL?
В PostgreSQL как физическая, так и логическая репликация основана на ведении журнала с упреждающей записью (WAL).
Все изменения, внесенные в PostgreSQL каждой транзакцией, сначала сохраняются в файле журнала, а затем результат транзакции отправляется инициирующему клиенту. Файлы данных не изменяются при каждой транзакции. Это стандартный механизм для предотвращения потери данных в случае сбоя ОС, сбоя оборудования, сбоя PostgreSQL и т. д. Этот механизм называется ведением журнала с упреждающей записью, а файл журнала — журналом с упреждающей записью (WAL). Каждое изменение, которое выполняет транзакция (INSERT, UPDATE, DELETE, COMMIT), записывается в журнал в виде записи WAL. Записи WAL сначала записываются в буфер WAL в памяти. При фиксации транзакции записи записываются в файл сегмента WAL на диске.
Порядковый номер журнала (LSN — log sequence number) записи WAL представляет расположение/позицию, в которой она сохраняется в файле журнала. LSN используется как уникальный идентификатор записи WAL. Логически журнал транзакций представляет собой файл размером 2^64 байта. Таким образом, номер LSN представляет собой 64-битное число, представленное двумя 32-битными шестнадцатеричными числами, разделенными символом /.
Например:
SELECT pg_current_wal_lsn();
В случае сбоя системы база данных может восстановить совершенные транзакции из WAL. PostgreSQL начинает восстановление с последней точки REDO или контрольной точки.
Контрольная точка — это точка в журнале транзакций, в которой все файлы данных были обновлены, чтобы отразить информацию в журнале. Процесс сохранения записей WAL из файла журнала в фактические файлы данных называется контрольной точкой.
WAL-сегменты
Файлы сегментов WAL
Понимание того, что такое WAL и как управляются файлы сегментов WAL, является ключом к пониманию того, как выполняется репликация с помощью WAL. Понимание файлов сегментов WAL также является основой для понимания того, что такое слоты репликации и зачем они нужны. В PostgreSQL журнал транзакций представляет собой виртуальный файл размером 8 байт. Физически журнал разделен на файлы размером 16 МБ, каждый из которых называется сегментом WAL.
Имя файла сегмента WAL представляет собой 24-значное число со следующим правилом именования:

Например:SELECT pg_walfile_name(pg_current_wal_lsn());
Управление файлами сегментов WAL
Файлы сегментов WAL хранятся в подкаталоге pg_wal. PostgreSQL переключается на новый файл сегмента WAL при следующих условиях:
Сегмент WAL заполнен.
Выпущена функция
pg_switch_wal.Dключен режим
archive_modeи превышено время, заданное дляarchive_timeout.
Переключенные файлы WAL можно либо удалить, либо переработать, т. е. переименовать и повторно использовать в будущем. Количество файлов WAL, которые сервер будет хранить в любой момент времени, зависит от конфигурации сервера, а также от активности сервера.
Всякий раз, когда запускается контрольная точка, PostgreSQL оценивает и подготавливает количество файлов сегментов WAL, необходимых для этого цикла контрольной точки. Эта оценка делается с учетом количества файлов, использованных в предыдущих циклах контрольных точек. Они отсчитываются от сегмента, содержащего предыдущую точку REDO, и значение должно быть между min_wal_size (по умолчанию 80 МБ, т. е. 5 файлов) и max_wal_size (1 ГБ, т. е. 64 файла). При запуске контрольной точки необходимые файлы будут сохранены и переработаны, а ненужные удалены.
Конкретный пример показан на следующей диаграмме. Предполагая, что перед запуском контрольной точки есть 6 файлов, WAL_3 содержит точку REDO, и PostgreSQL оценивает, что необходимо 5 файлов. В этом случае WAL_1 будет переименован в WAL_7 для переработки, а WAL_2 будет удален.

Работа с примером WAL
Использование pg_waldump
pg_waldump — это утилита, которую можно использовать для отображения записей WAL в удобочитаемой форме. В этой лабораторной работе мы будем использовать эту утилиту для отображения некоторых записей WAL.
У утилиты pg_waldump две основные цели:
Образовательная: для всех, кто пытается понять, как работает WAL в деталях.
Отладка: для тех, кто пытается отлаживать средства репликации или резервного копирования на основе потоковой передачи WAL.
Находим OID базы данныхSELECT datname, oid FROM pg_database WHERE datname = 'postgres';
Находим OID табличного пространстваSELECT spcname, oid from pg_tablespace WHERE spcname = 'pg_default';
Находим текущий WAL LSNSELECT pg_current_wal_lsn();
Создаем новую таблицуCREATE TABLE abc(a VARCHAR(10));
Находим имя файла, созданного новой таблицейSELECT pg_relation_filepath('abc');
Теперь мы вставляем новую строку во вновь созданную таблицуINSERT INTO abc VALUES('pkn');
Теперь мы выходим из клиента psql, чтобы запустить утилиту pg_waldump.\q
Мы проверяем запись WAL, созданную оператором CREATE TABLE в WAL, используя pg_waldump/usr/lib/postgresql/12/bin/pg_waldump --path=/var/lib/postgresql/12/main/pg_wal/ --rmgr=Storage --start=0/1600000 | grep CREATE >1.txt
cat 1.txt
Проверяем запись WAL, созданную оператором INSERT в WALL/usr/lib/postgresql/12/bin/pg_waldump --path=/var/lib/postgresql/12/main/pg_wal/ --rmgr=Heap --start=0/1600000 | grep INSERT+INIT > 1.txt
cat 1.txt
Непрерывное архивирование WAL
Копирование файлов WAL по мере их создания в любое место, кроме подкаталога pg_wall, с целью их архивирования называется архивированием WAL. Для архивирования скрипт, предоставленный пользователем, вызывается PostgreSQL каждый раз при создании файла WAL. Сценарий может использовать команду scp для копирования файла в одно или несколько мест. Местоположение может быть монтированием NFS. После архивации файлы сегментов WAL можно использовать для восстановления базы данных на любой указанный момент времени.
Репликация на основе доставки журналов: уровень файла
Доставка журналов — это процесс копирования файлов журналов на другой сервер PostgreSQL с целью создания другого резервного сервера путем воспроизведения файлов WAL. Этот сервер настроен на работу в режиме восстановления. Единственной целью этого сервера является применение любых новых файлов WAL по мере их поступления. Затем этот второй сервер становится горячей резервной копией основного сервера PostgreSQL, также называемого резервным. Резервный сервер также можно настроить как реплику чтения, где он также может обслуживать запросы только для чтения. Это называется горячим резервом.
Репликация на основе доставки журналов: блочный уровень
Потоковая репликация улучшает процесс доставки журналов. Вместо ожидания переключения WAL записи отправляются по мере их создания, что сокращает задержку репликации. Второе улучшение заключается в том, что резервный сервер будет подключаться к основному серверу по сети с использованием протокола репликации. Затем первичный сервер может отправлять записи WAL непосредственно через это соединение, не полагаясь на сценарии, предоставленные конечным пользователем.
Как долго основной сервер должен хранить файлы сегментов WAL?
Без каких-либо клиентов потоковой репликации сервер может отбросить/переработать файл сегмента WAL после того, как сценарий архивации сообщит об успешном выполнении (если только они не требуются для восстановления после сбоя). Однако при наличии резервных клиентов возникает проблема: сервер должен хранить файлы WAL до тех пор, пока в них нуждается самый медленный резервный клиент. Если резервный сервер, который был отключен на некоторое время, снова подключается к сети и запрашивает у основного файл WAL, которого у основного больше нет, то репликация завершается с ошибкой, подобной:
ERROR: requested WAL segment 00000001000000010000002D has already been removed
Таким образом, первичный сервер должен отслеживать, насколько он отстает от резервного и не удалять/не перерабатывать файлы WAL, которые все еще нужны резервным серверам. Эта функция обеспечивается через слоты репликации. Каждый слот репликации имеет имя, которое используется для идентификации слота. Каждый слот связан с:
Самым старым файлом сегмента WAL, требуемым потребителем слота. Файлы сегментов WAL более поздние, чем это, не удаляются/не перерабатываются во время контрольных точек.
Самым старым идентификатором транзакции, который необходимо сохранить потребителю слота. Строки, необходимые для любых транзакций позже этого, не удаляются очисткой.
PostgreSQL: логическая репликация
Физическая потоковая репликация создает побайтовую реплику первичного сервера только для чтения. Реплика содержит все базы данных, таблицы, роли, табличные пространства и т. д. оригинала. С потоковой репликацией мы получаем все или ничего. Но что, если нам нужна реплика только одной таблицы? Здесь в игру вступает логическое повторение.
Логическая репликация может воспроизводить операции DML, происходящие в подмножестве таблиц на первичном сервере, на резервном сервере следующим образом:
Логическое декодирование записей WAL.
Потоковая передача их на резервный сервер.
Применение их к таблице на резервном сервере в правильном порядке транзакций.
Логическая репликация определяет два объекта: издатель (publisher) и подписчик (subscriber).
Издатель — это узел, который определяет определенную группу таблиц (называемую публикацией), на которую может подписаться подписчик, создав подписку для получения изменений в этой конкретной группе таблиц.
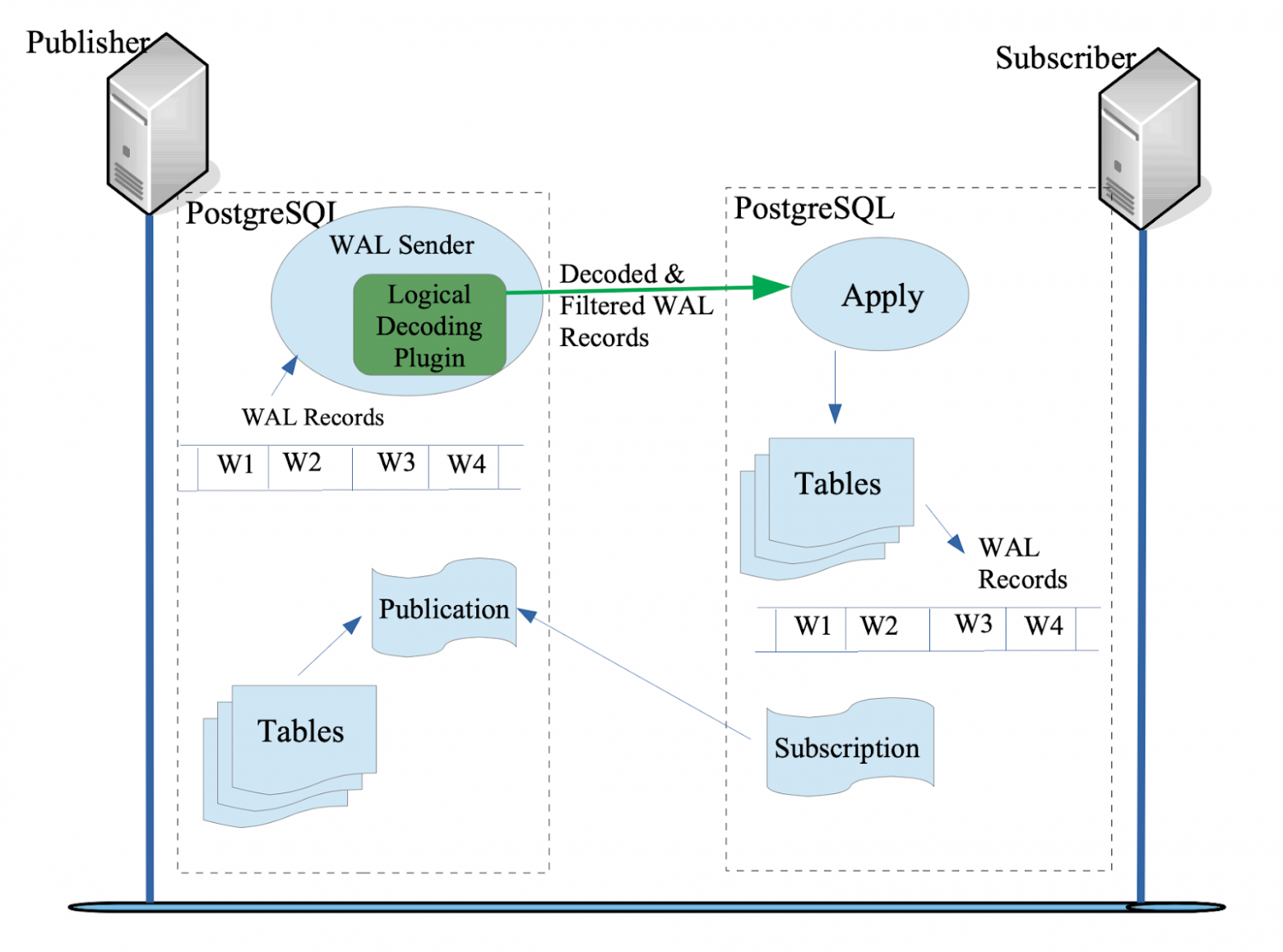
Ниже приведен пример шагов настройки для логической репликации:
Входим как пользователь postgressu - postgres
Модифицируем postgresql.conf для сервера издателя
cat >> /tmp/data_pub/postgresql.conf <<EOF
port = 6432
wal_level = logical
logging_collector = on
EOFЗапускаем сервер издателя на порту 6432/usr/lib/postgresql/12/bin/pg_ctl -D /tmp/data_pub start
Запускаем CLI-инструмент psql/usr/lib/postgresql/12/bin/psql --port=6432 --host=localhost --username=postgres --dbname=postgres
Создаем новую базуCREATE DATABASE src_db;
Подключаемся к новой базе\c src_db
Создаем новую таблицуCREATE TABLE t1 (id integer primary key, val text);
Создаем пользователя репликацииCREATE USER replicant WITH replication;
Мы предоставляем пользователю репликации выбор строк из таблицы t1GRANT SELECT ON t1 TO replicant;
Вставляем несколько строк в таблицу t1INSERT INTO t1 (id, val) VALUES (10, 'ten'), (20, 'twenty'), (30, 'thirty');
Создаем публикациюCREATE PUBLICATION pub1 FOR TABLE t1;
В новом терминале:
Мы входим как пользователь postgressu - postgres
Модифицируем файл postgresql.conf для сервера подписчиков
cat >> /tmp/data_sub/postgresql.conf <<EOF
port = 7432
logging_collector = on
EOFЗапускаем сервер подписчик на порту 7432/usr/lib/postgresql/12/bin/pg_ctl -D /tmp/data_sub start
Запускаем CLI-инструмент psql/usr/lib/postgresql/12/bin/psql --port=7432 --host=localhost --username=postgres --dbname=postgres
Создаем новую базуCREATE DATABASE dst_db;
Подключаемся к новой базе\c dst_db
Создаем таблицу в базеCREATE TABLE t1 (id integer primary key, val text);
Создаем подпискуCREATE SUBSCRIPTION sub1 CONNECTION 'host=localhost port=6432 dbname=src_db user=replicant' publication pub1;
Проверяем данные в подписанной таблицеSELECT * FROM t1;
Вставляем еще несколько строк в опубликованную таблицуINSERT INTO t1 (id, val) VALUES (40, 'forty'), (50, 'fifty'), (60, 'sixty');
Проверьте данные в подписанной таблицеSELECT * FROM t1;
В качестве заключения приглашаю всех на бесплатный урок, в рамках которого проанализируем, в каких единицах можно измерять нагрузку. Рассмотрим преимущества и недостатки различных подходов к масштабированию, а также проблемы высоконагруженных проектов.
Зарегистрироваться на бесплатный урок



