
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Это и последующие руководства проведут вас через процесс создания решения на основе проекта Discovery.js. Наша цель — создать инспектор NPM-зависимостей, то есть интерфейс для исследования структуры node_modules.
Примечание: Discovery.js находится на ранней стадии разработки, поэтому со временем что-то будет упрощаться и становиться полезнее. Если у вас есть идеи, как можно что-то улучшить, напишите нам.
Аннотация
Ниже вы найдёте обзор ключевых концепций Discovery.js. Изучить весь код руководства можно в репозитории на GitHub, или можете попробовать как это работает онлайн.
Начальные условия
Прежде всего нам нужно выбрать проект для анализа. Это может быть свежесозданный проект или уже существующий, главное, чтобы он содержал node_modules (объект нашего анализа).
Сначала установим основной пакет discoveryjs и его консольные инструменты:
npm install @discoveryjs/discovery @discoveryjs/cliДалее запускаем сервер Discovery.js:
> npx discovery
No config is used
Models are not defined (model free mode is enabled)
Init common routes ... OK
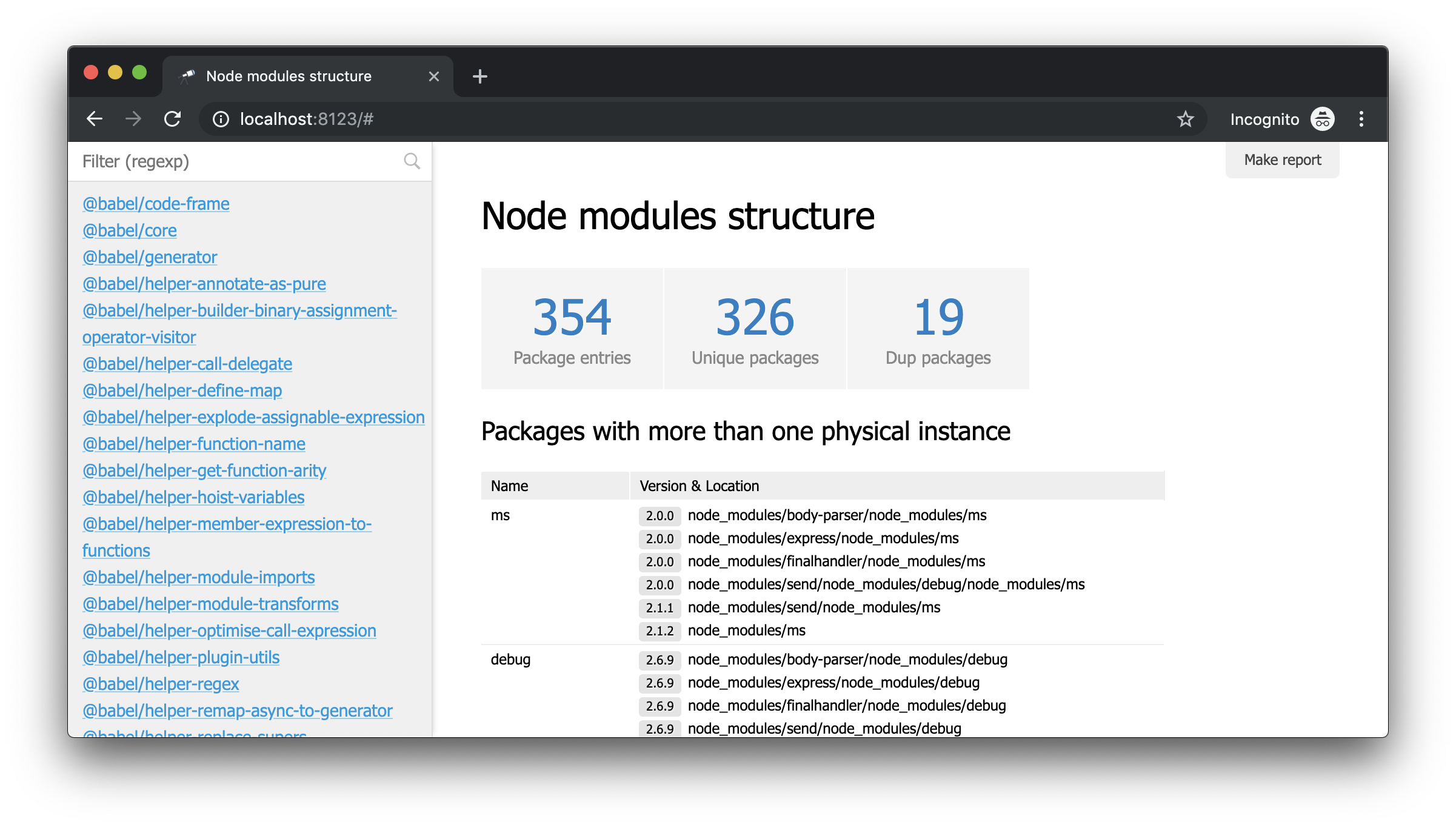
Server listen on http://localhost:8123Если открыть в браузере http://localhost:8123, то можем увидеть следующее:

Это режим без модели, то есть режим когда ничего не сконфигурировано. Но уже сейчас с помощью кнопки "Load data" можно выбрать любой JSON-файл, или просто перетащить его на страницу, и начать анализ.
Однако нам нужно нечто конкретное. В частности, нам нужно получить представление структуры node_modules. Для этого добавим конфигурацию.
Добавляем конфигурацию
Как вы могли заметить, при запуске сервера вывелось сообщение No config is used. Давайте создадим конфигурационный файл .discoveryrc.js с таким содержимым:
module.exports = {
name: 'Node modules structure',
data() {
return { hello: 'world' };
}
};Примечание: если вы создаете файл в текущей рабочей директории (то есть в корне проекта), то больше ничего не требуется. В противном случае нужно передать путь к файлу конфигурации с помощью опции --config, либо задать путь в package.json:
{
...
"discovery": "path/to/discovery/config.js",
...
}Перезапустим сервер, чтобы конфигурация была применена:
> npx discovery
Load config from .discoveryrc.js
Init single model
default
Define default routes ... OK
Cache: DISABLED
Init common routes ... OK
Server listen on http://localhost:8123Как видите, теперь созданный нами файл используется. И применяется описанная нами модель по умолчанию (Discovery может работать в режиме множества моделей, об этой возможности мы расскажем в следующих руководствах). Давайте посмотрим, что у нас изменилось в браузере:
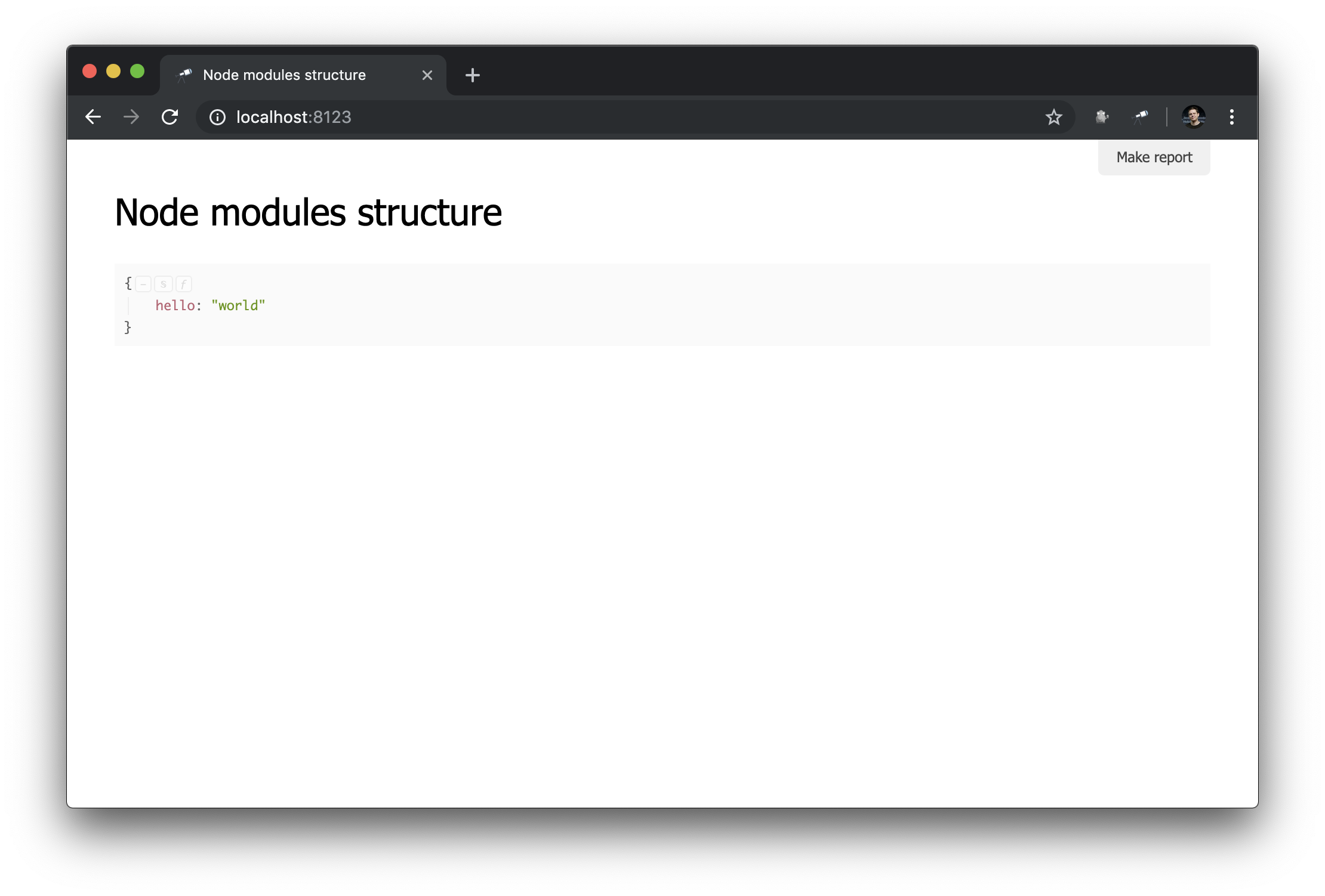
Что тут можно увидеть:
nameиспользуется в качестве заголовка страницы;- результат вызова метода
dataотображается как основное содержимое страницы.
Примечание: метод data должен возвращать данные или Promise, который разрешается в данные.Основные настройки сделаны, можно двигаться дальше.
Контекст
Давайте посмотрим на страницу произвольного отчёта (кликнинте Make report):
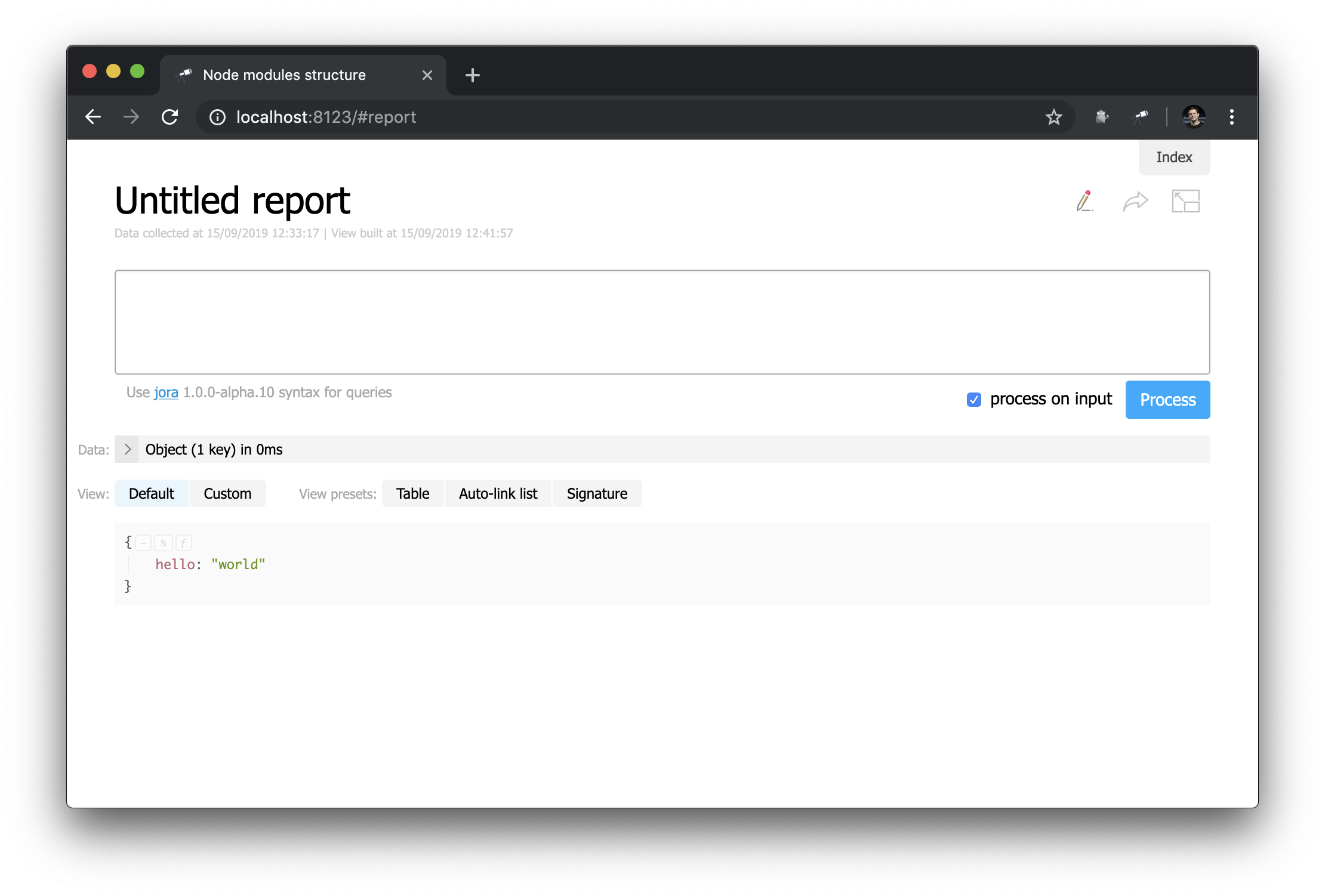
На первый взгляд, это не сильно отличается от стартовой страницы… Но здесь можно всё менять! Например, мы можем легко воссоздать вид стартовой страницы:
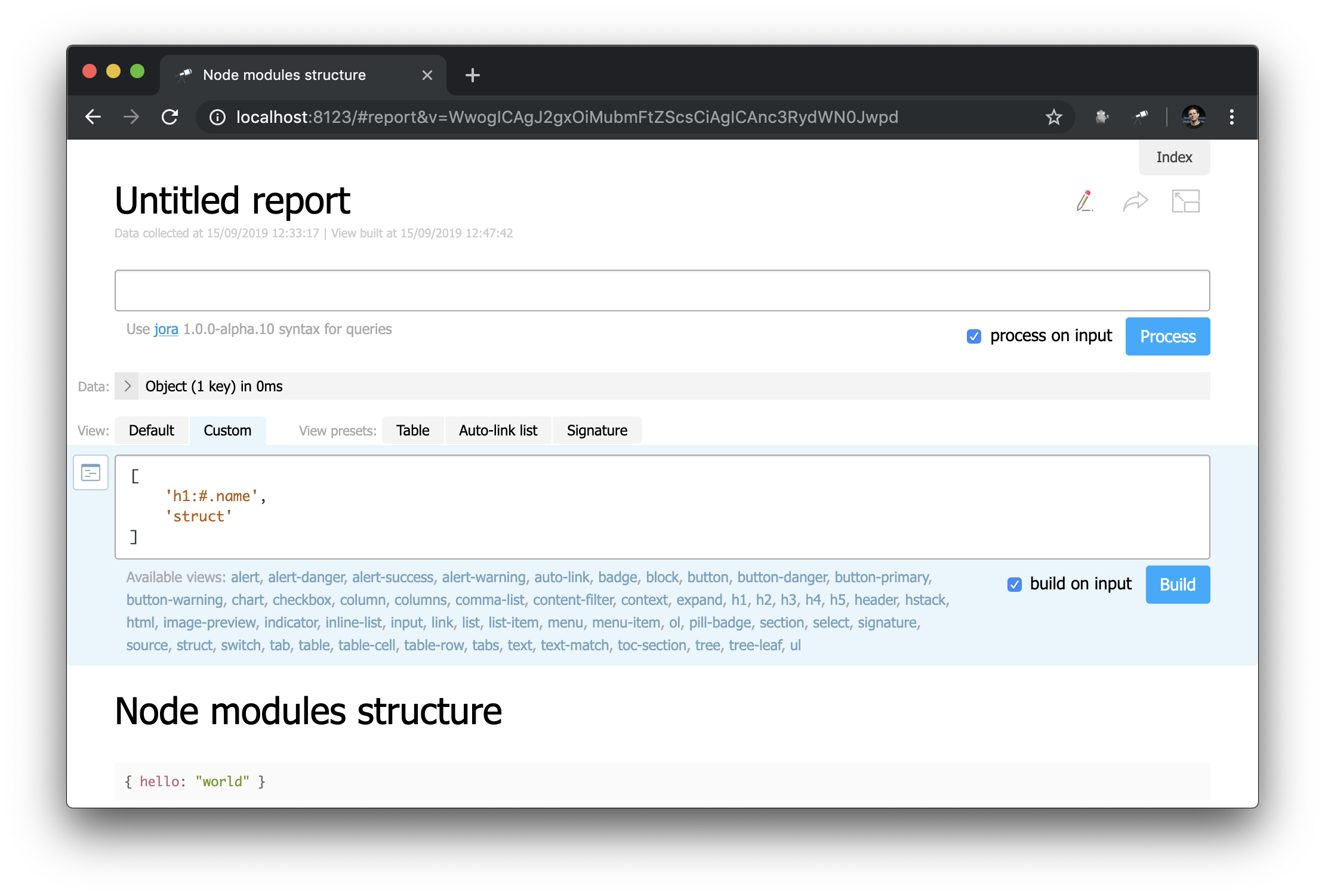
Обратите внимание, как определяется заголовок: "h1:#.name". Это заголовок первого уровня с содержимым #.name, которое является запросом Jora. # ссылается на контекст запроса. Чтобы посмотреть его содержимое, просто введите # в редакторе запроса и воспользуйтесь отображением по умолчанию:
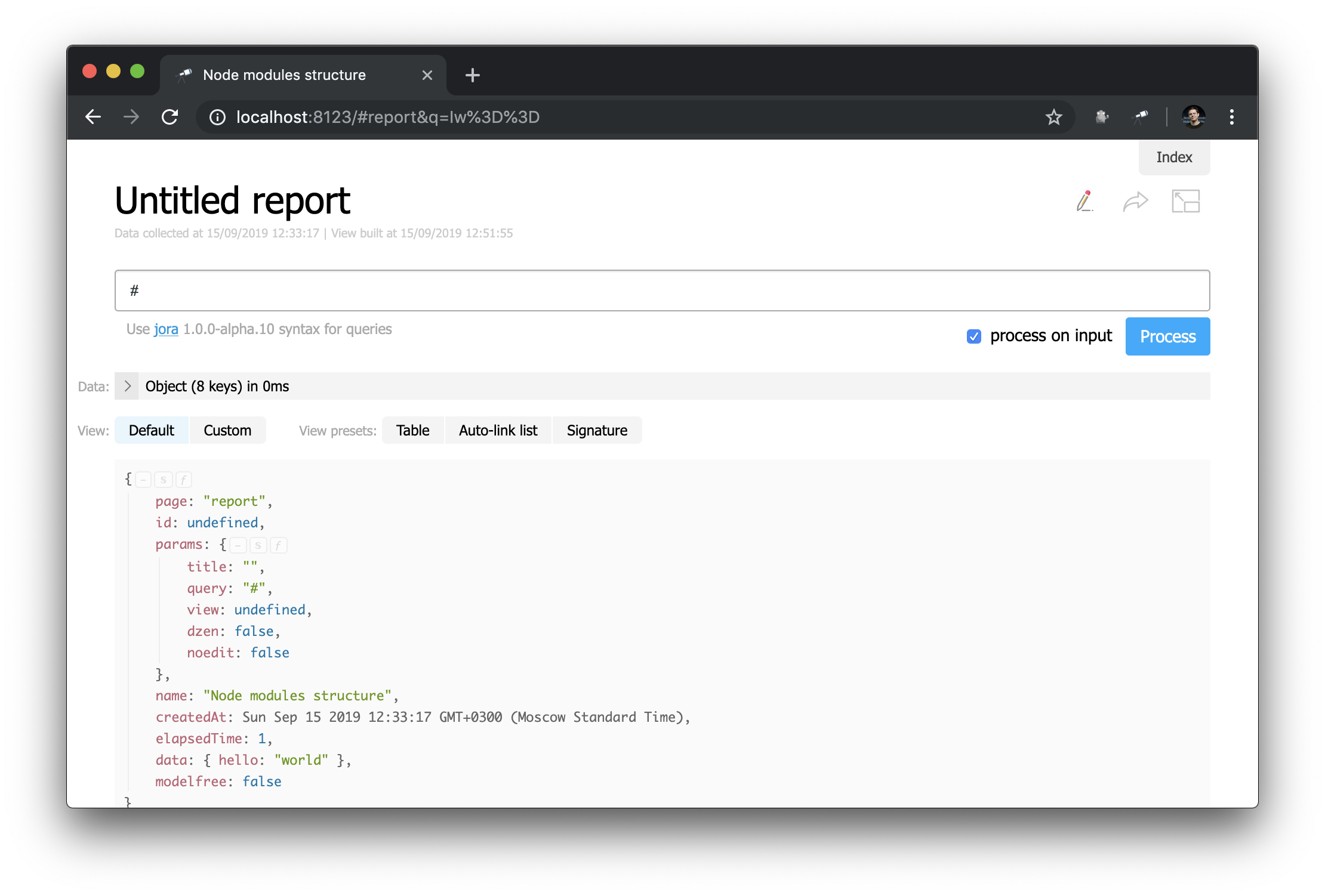
Теперь вы знаете, как можно получить ID текущей страницы, её параметры и другие полезные значения.
Сбор данных
Сейчас мы используем в проекте заглушку вместо реальных данные, а нам нужны настоящие. Для этого создадим модуль и изменим значение data в конфигурации (кстати, после этих изменений перезапускать сервер не обязательно):
module.exports = {
name: 'Node modules structure',
data: require('./collect-node-modules-data')
};Содержимое collect-node-modules-data.js:
const path = require('path');
const scanFs = require('@discoveryjs/scan-fs');
module.exports = function() {
const packages = [];
return scanFs({
include: ['node_modules'],
rules: [{
test: /\/package.json$/,
extract: (file, content) => {
const pkg = JSON.parse(content);
if (pkg.name && pkg.version) {
packages.push({
name: pkg.name,
version: pkg.version,
path: path.dirname(file.filename),
dependencies: pkg.dependencies
});
}
}
}]
}).then(() => packages);
};Я использовал пакет @discoveryjs/scan-fs, который упрощает сканирование файловой системы. Пример использования пакета описан в его readme, я взял этот пример за основу и доработал как нужно. Теперь у нас есть некоторая информация о содержимом node_modules:
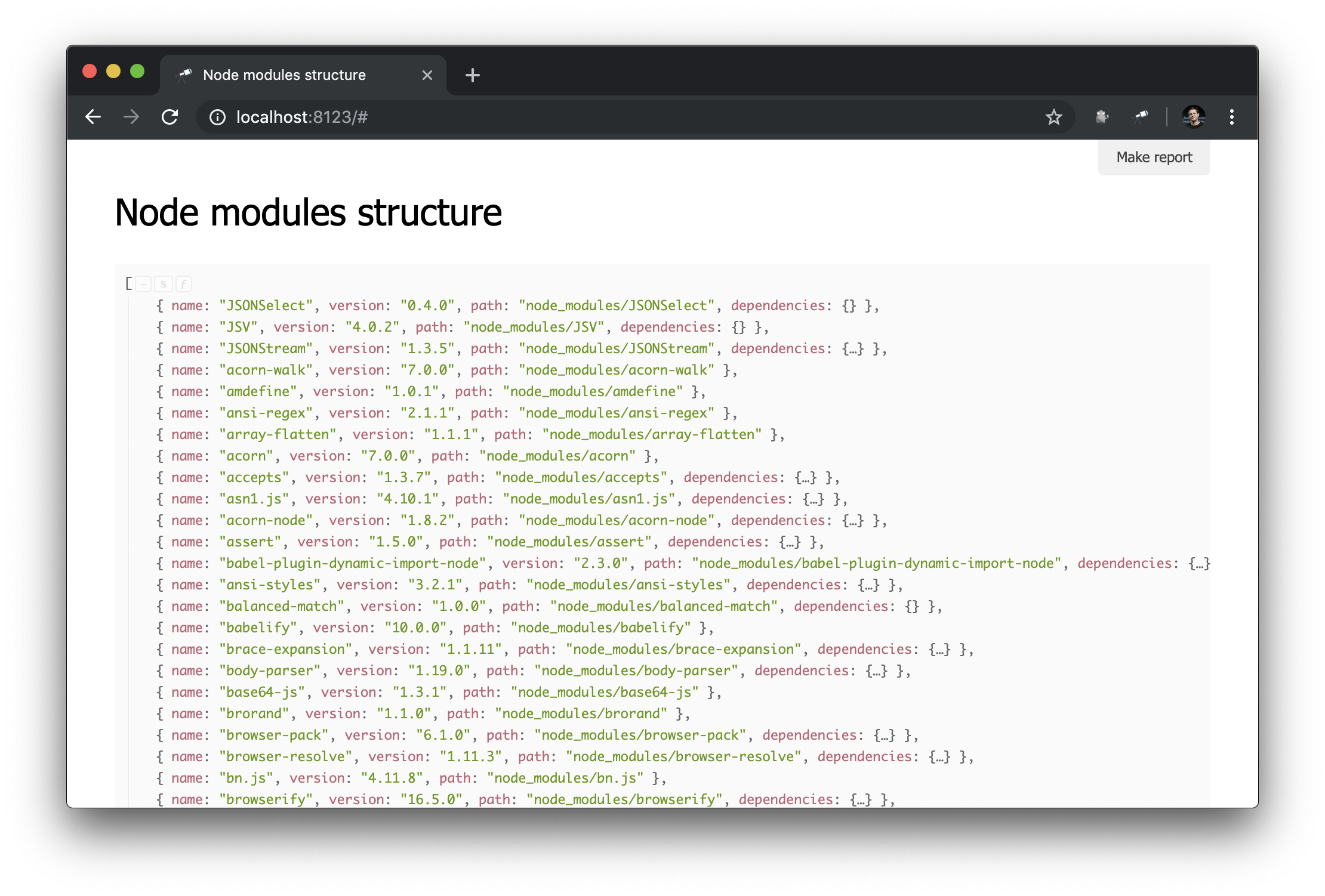
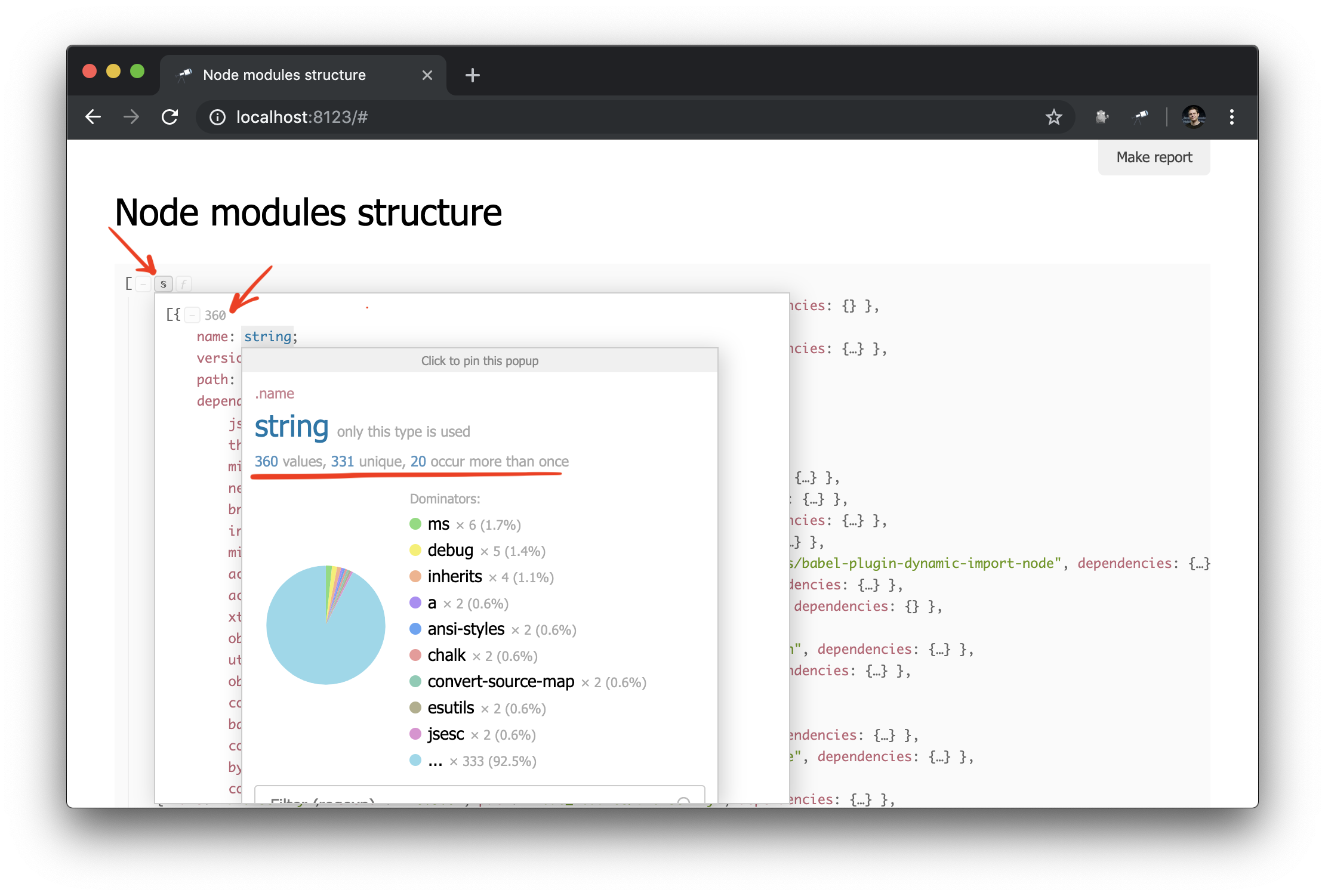
То что надо! И несмотря на то, что это обычный JSON, мы уже можем его проанализировать и сделать какие-то выводы. Например, с помощью попапа структуры данных можно выяснить количество пакетов и узнать, сколько из них имеют больше одного физического экземпляра (из-за разницы версий или проблем с их дедупликацией).
Не смотря на то, что у нас уже есть некоторые данные, нам нужно больше деталей. Например, хорошо бы знать, в какой физический экземпляр разрешается каждая из объявленных зависимостей определенного модуля. Однако работа над улучшением извлечения данных выходит за рамки этого руководства. Поэтому мы сделаем замену на пакет @discoveryjs/node-modules (который также построен на основе @discoveryjs/scan-fs) для извлечения данных и получим необходимые подробности относительно пакетов. В результате collect-node-modules-data.js значительно упрощается:
const fetchNodeModules = require('@discoveryjs/node-modules');
module.exports = function() {
return fetchNodeModules();
};Теперь информация о node_modules выглядит так:
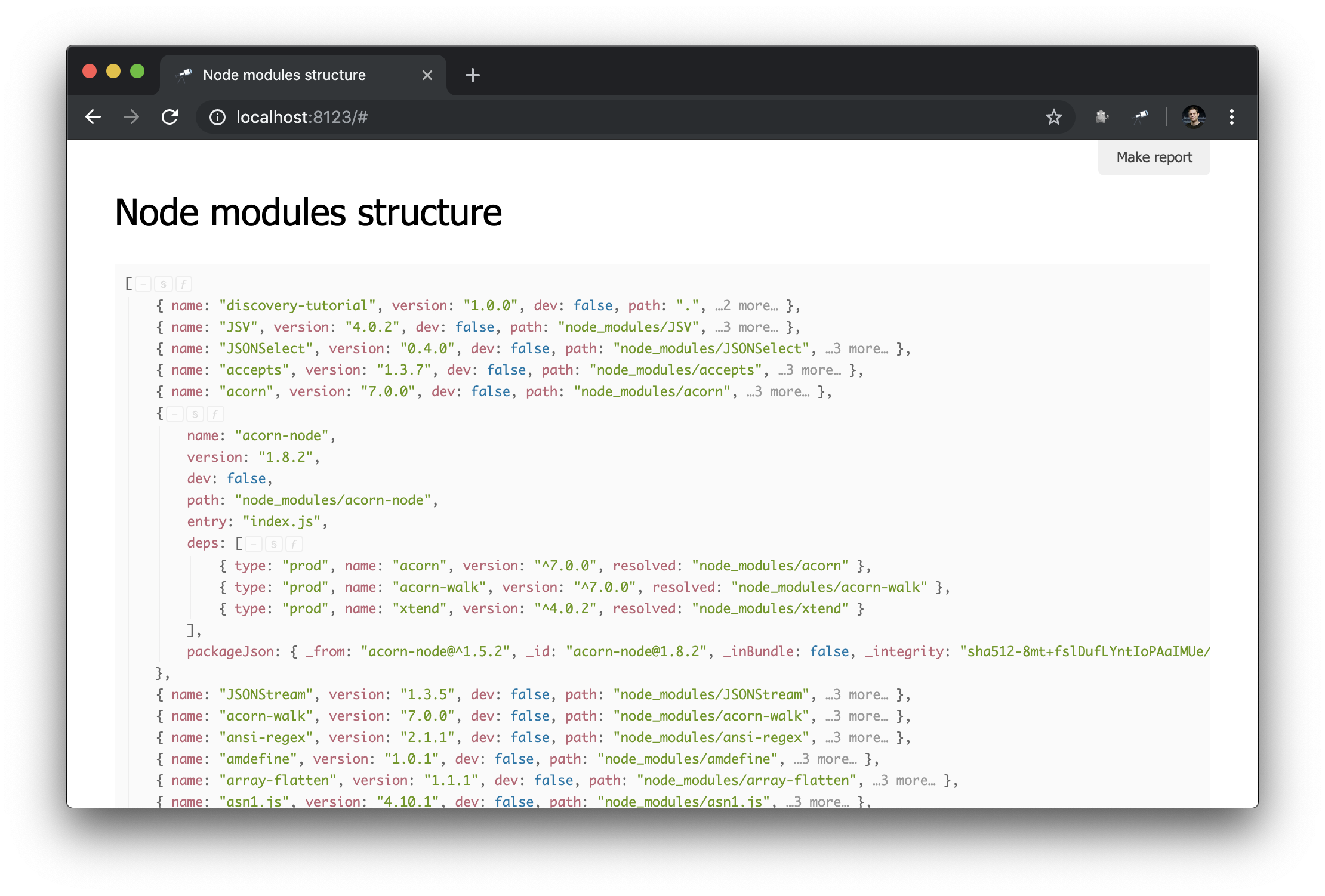
Скрипт подготовки
Как вы могли заметить, некоторые объекты описывающие пакеты содержат deps — список зависимостей. У каждой зависимости есть поле resolved, значение которого является ссылкой на физический экземпляр пакета. Такая ссылка — это значение path одного из пакетов, оно является уникальным. Для разрешения ссылки на пакет нужно использовать дополнительный код (например, #.data.pick(<path=resolved>)). И конечно же, было бы гораздо удобнее, если бы такие ссылки были бы уже разрешены в ссылки на объекты.
К сожалению, на этапе сбора данных мы не можем разрешать ссылки, поскольку это приведёт к циклическим связям, что создаст проблему передачи таких данных в виде JSON. Однако решение есть: это специальный скрипт prepare. Он определяется в конфигурации и вызывается каждый раз при назначении новых данных для экземпляра Discovery. Начнём с конфигурации:
module.exports = {
...
prepare: __dirname + '/prepare.js', // Важно: значение это строка, путь к модулю
...
};Определим prepare.js:
discovery.setPrepare(function(data) {
// делаем что-то с data и/или с экземпляром discovery
});В этом модуле мы задали функцию prepare для экземпляра Discovery. Эта функция вызывается каждый раз перед применением данных к экземпляру Discovery. Это хорошее место для того, чтобы разрешить значения в ссылки на объекты:
discovery.setPrepare(function(data) {
const packageIndex = data.reduce((map, pkg) => map.set(pkg.path, pkg), new Map());
data.forEach(pkg =>
pkg.deps.forEach(dep =>
dep.resolved = packageIndex.get(dep.resolved)
)
);
});Здесь мы создали индекс пакетов, в котором ключом является значение path пакета (уникальное). Затем мы проходим по всем пакетам и их зависимостям, и заменяем в зависимостях значение resolved ссылкой на объект пакета. Результат:
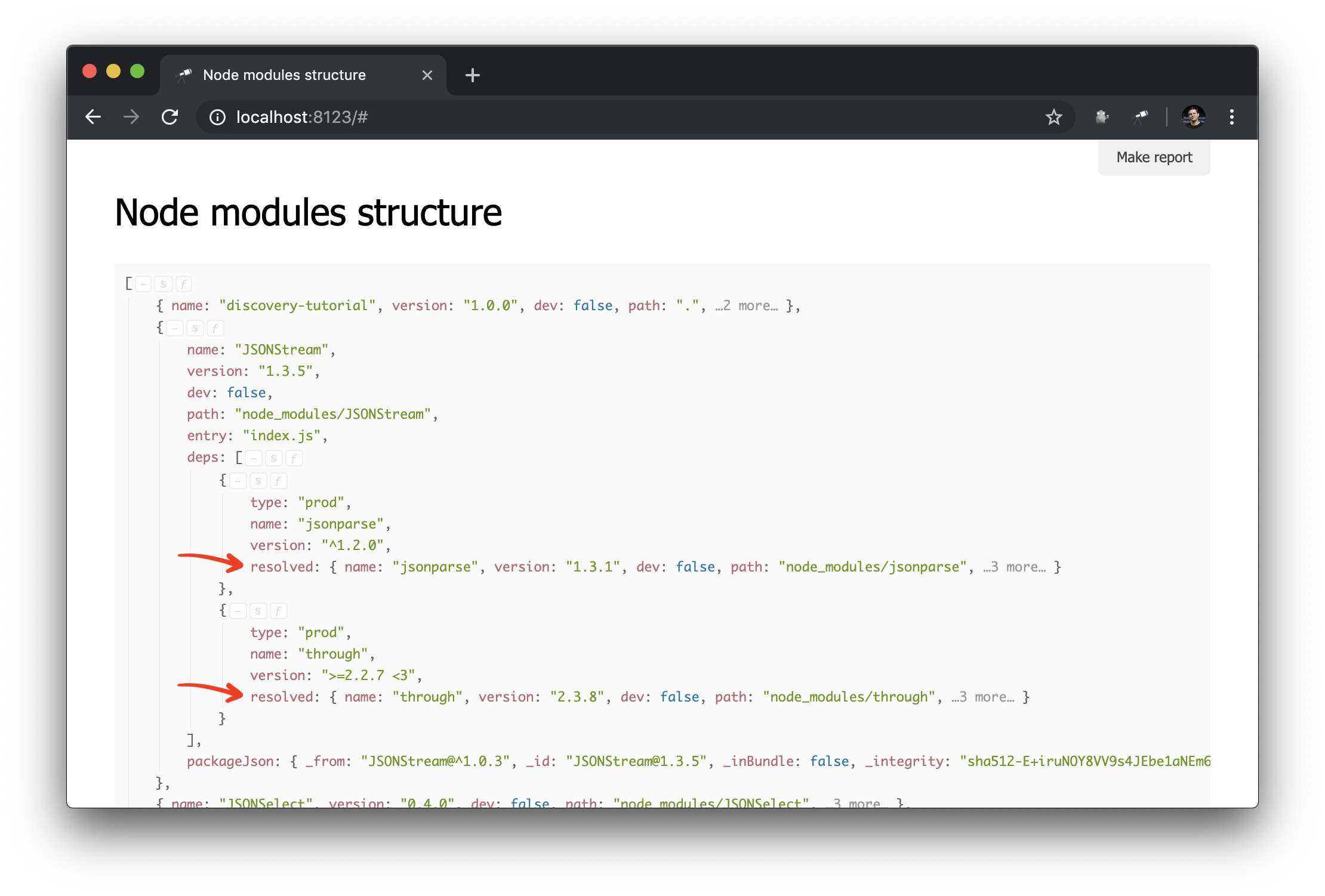
Теперь гораздо легче делать запросы к графу зависимостей. Вот так можно получить кластер зависимостей (то есть зависимости, зависимости зависимостей и т.д.) для конкретного пакета:
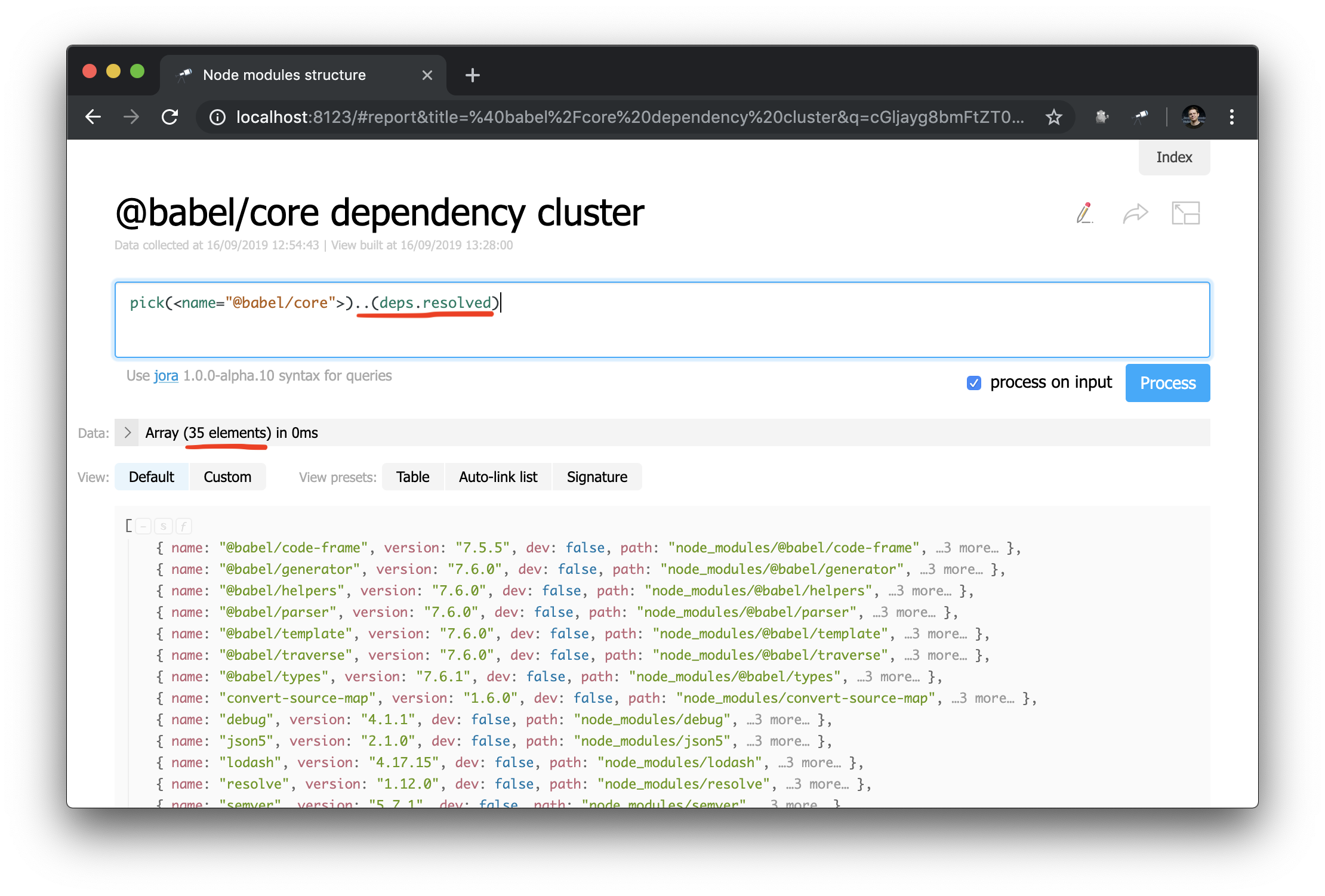
Неожиданная история успеха: изучая данные в ходе написания руководства, я обнаружил проблему в@discoveryjs/cli(с помощью запроса.[deps.[not resolved]]), у которого была опечатка в peerDependencies. Проблема немедленно была исправлена. Случай является наглядным примером, как помогают подобные инструменты.
Пожалуй настало время, чтобы показать на стартовой странице несколько чисел и пакеты с дублями.
Настраиваем стартовую страницу
Для начала нам нужно создать модуль страницы, например, pages/default.js. Мы используем default, поскольку это идентификатор для стартовой страницы, который мы можем переопределить (в Discovery.js можно переопределить очень многое). Начнём с чего-нибудь простого, например:
discovery.page.define('default', [
'h1:#.name',
'text:"Hello world!"'
]);Теперь в конфигурации нужно подключить модуль страницы:
module.exports = {
name: 'Node modules structure',
data: require('./collect-node-modules-data'),
view: {
assets: [
'pages/default.js' // ссылка на модуль страницы
]
}
};Проверяем в браузере:
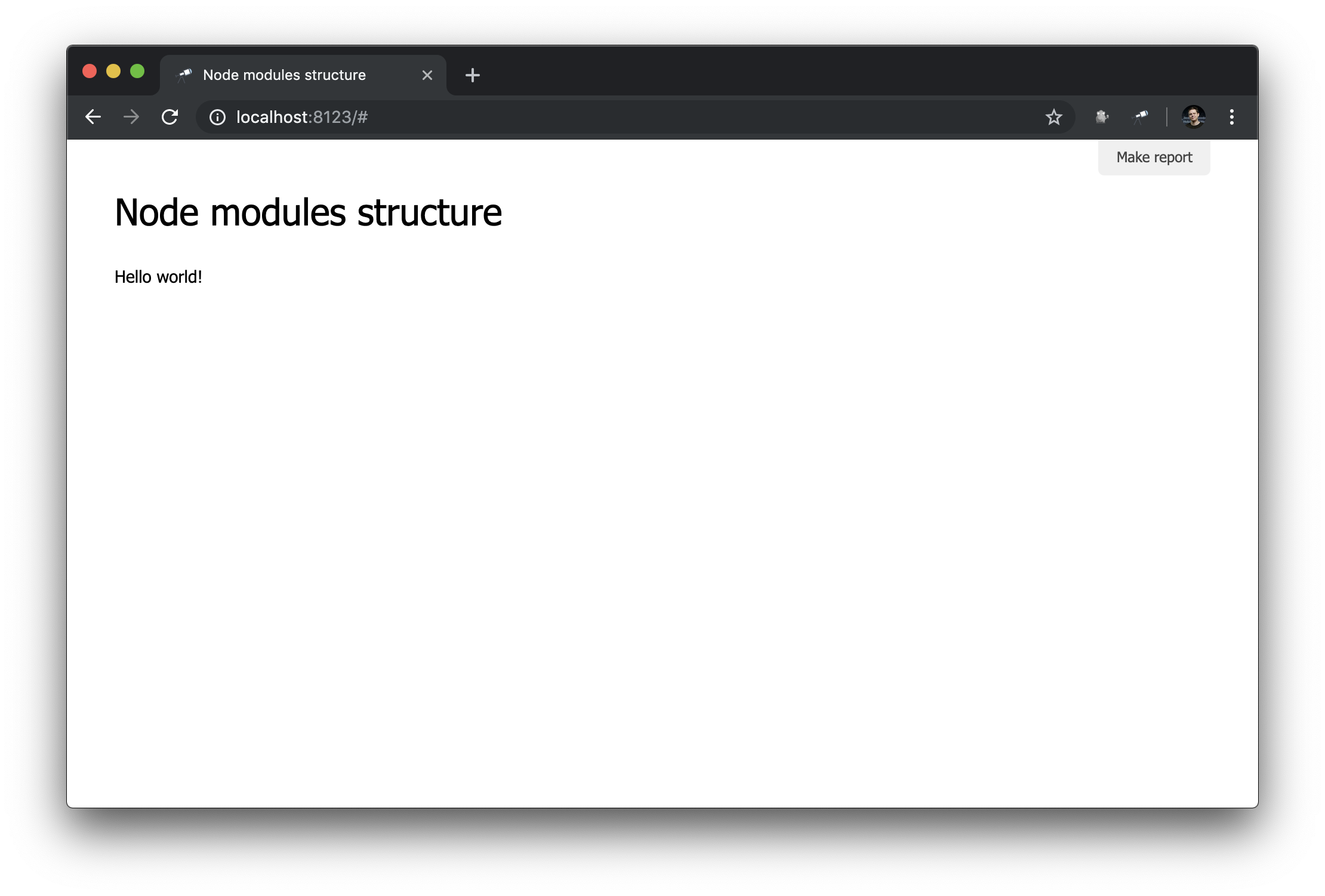
Работает!
Теперь давайте выведем какие-нибудь счётчики. Для этого внесём изменения в pages/default.js:
discovery.page.define('default', [
'h1:#.name',
{
view: 'inline-list',
item: 'indicator',
data: `[
{ label: 'Package entries', value: size() },
{ label: 'Unique packages', value: name.size() },
{ label: 'Dup packages', value: group(<name>).[value.size() > 1].size() }
]`
}
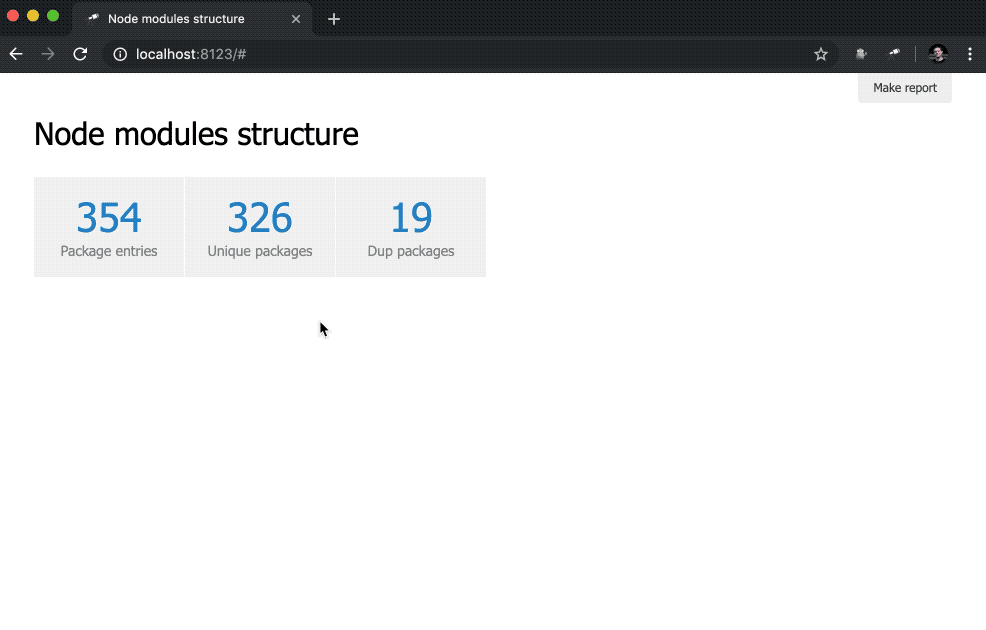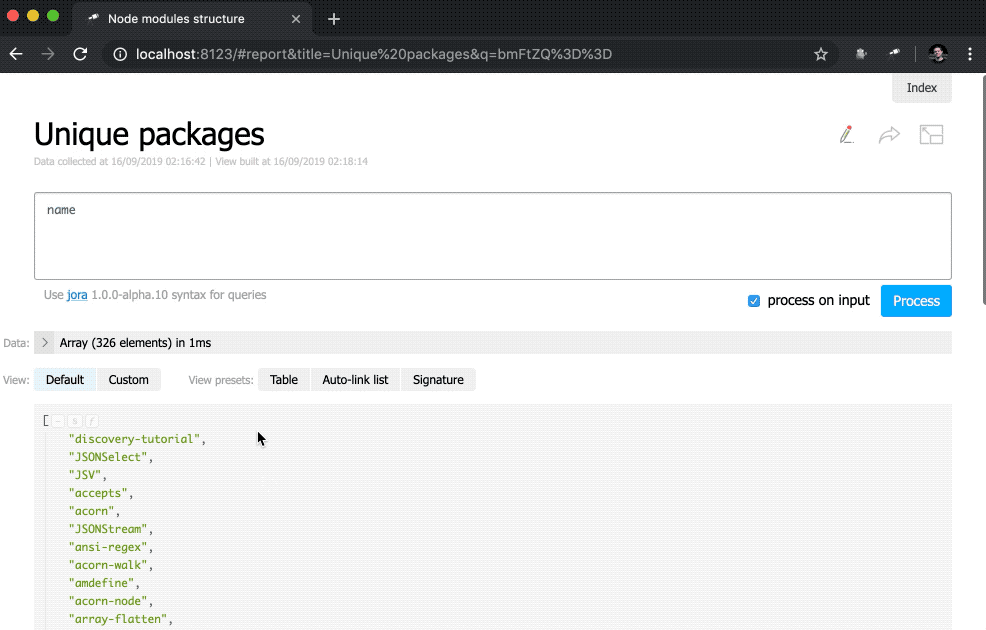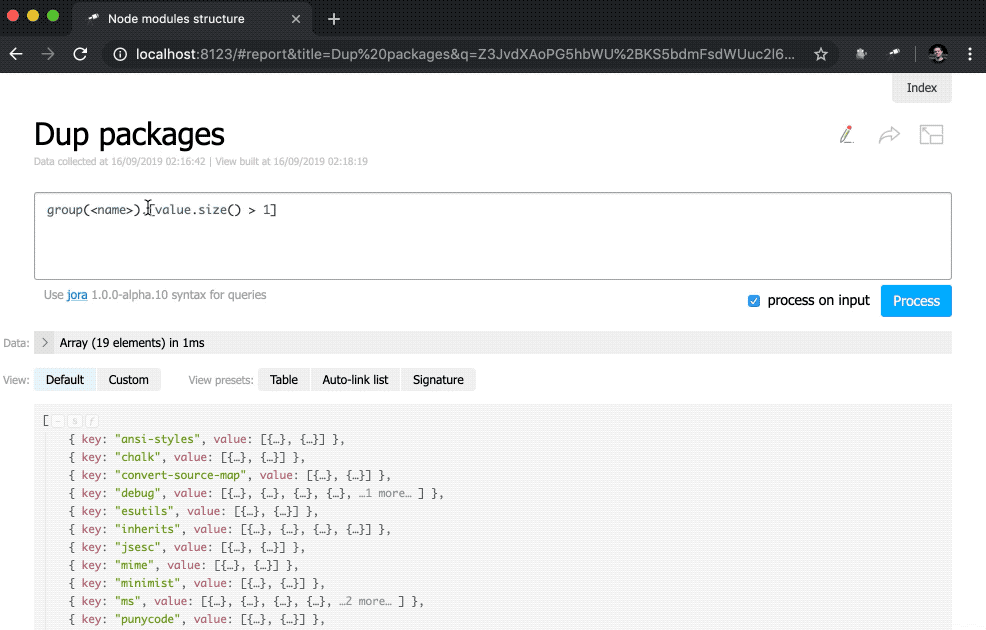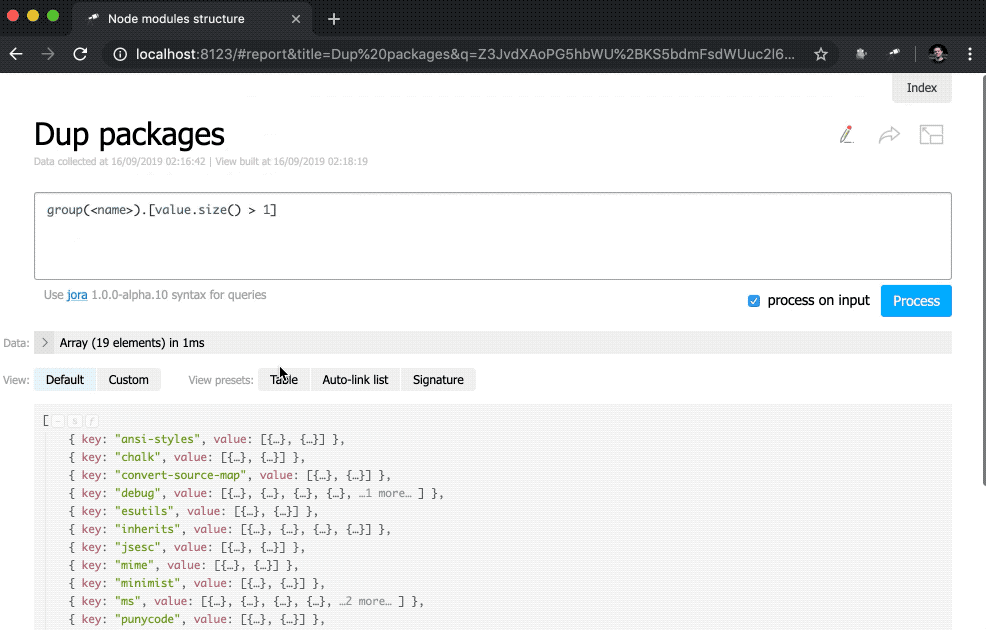
]);Здесь мы определяем инлайновый список индикаторов. В качестве значения data стоит запрос Jora, создающий массив записей. В качестве основы для запросов используется список пакетов (корень данных), так мы получили длину списка (size()), количество уникальных имен пакетов (name.size()) и количество имен пакетов, которые имеют дубли (group(<name>).[value.size() > 1].size()).
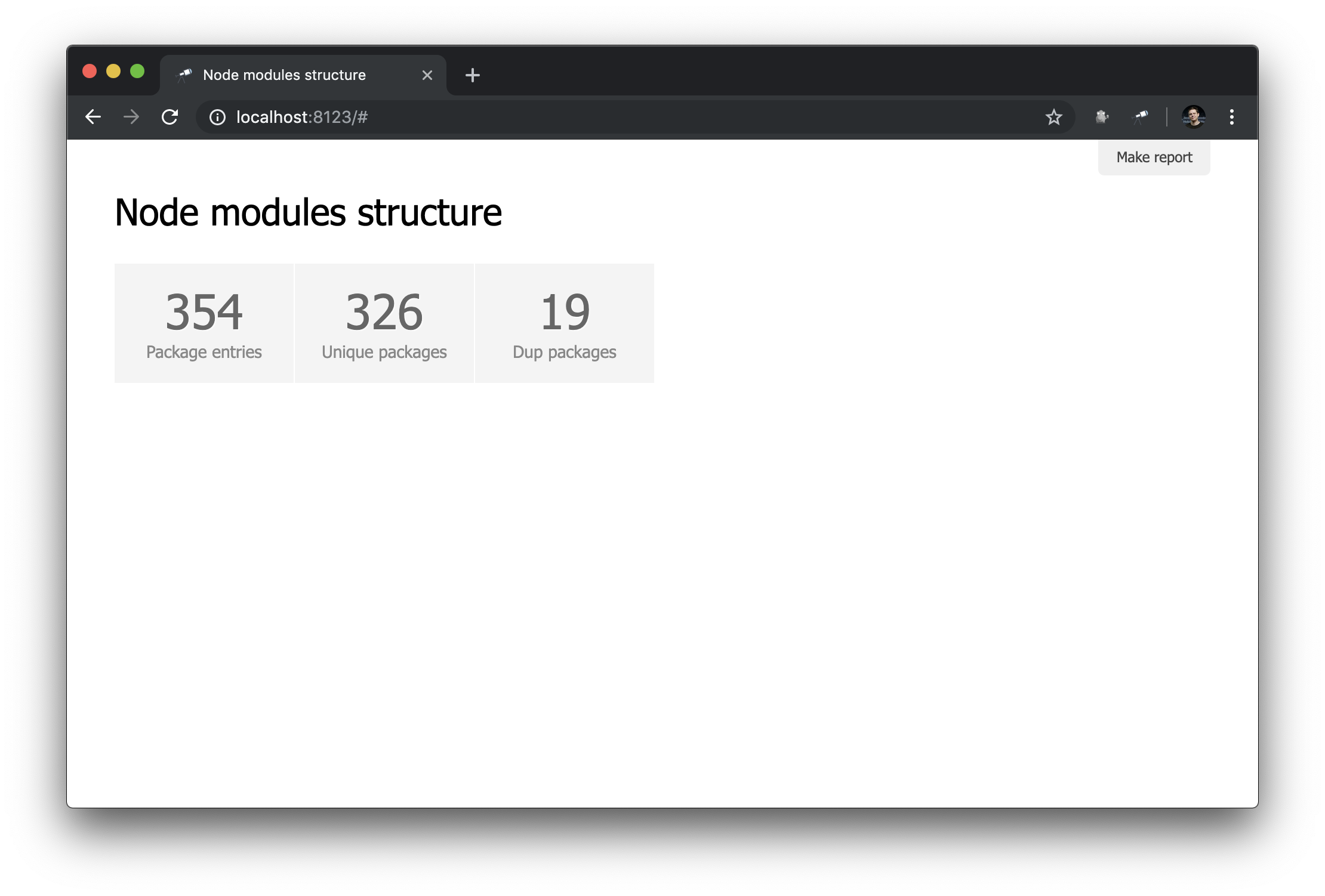
Неплохо. Тем не менее, было бы лучше кроме чисел иметь ссылки на соответствующие выборки:
discovery.page.define('default', [
'h1:#.name',
{
view: 'inline-list',
data: [
{ label: 'Package entries', value: '' },
{ label: 'Unique packages', value: 'name' },
{ label: 'Dup packages', value: 'group(<name>).[value.size() > 1]' }
],
item: `indicator:{
label,
value: value.query(#.data, #).size(),
href: pageLink('report', { query: value, title: label })
}`
}
]);В первую очередь мы изменили значение data, теперь это обычный массив с некоторыми объектами. Также из запросов значений (value) убран метод size().
Помимо этого в представление indicator добавлен подзапрос. Такого вида запросы создают новый объект для каждого элемента, в котором вычисляются value и href. Для value выполняется запрос с использованием метода query(), в который данные передаются из контекста, а потом к результату запроса применяется метод size(). Для href используется метод pageLink(), который генерирует ссылку на страницу отчёта с конкретным запросом и заголовком. После всех этих изменений индикаторы стали кликабельными (обратите внимание, что их значения стали синего цвета) и более функциональными.
Чтобы сделать стартовую страницу более полезной, добавим таблицу с пакетами имеющие дубли.
discovery.page.define('default', [
// ... то же что и раньше
'h2:"Packages with more than one physical instance"',
{
view: 'table',
data: `
group(<name>)
.[value.size() > 1]
.sort(<value.size()>)
.reverse()
`,
cols: [
{ header: 'Name', content: 'text:key' },
{ header: 'Version & Location', content: {
view: 'list',
data: 'value.sort(<version>)',
item: [
'badge:version',
'text:path'
]
} }
]
}
]);Для таблицы используются те же данные, что и для индикатора Dup packages. Список пакетов был отсортирован по размеру группы в обратном порядке. Остальная настройка связана с колонками (кстати, обычно их не нужно настраивать). Для колонки Version & Location мы определили вложенный список (отсортированный по версии), в котором каждый элемент представляет собой пару из номера версии и пути к экземпляру.
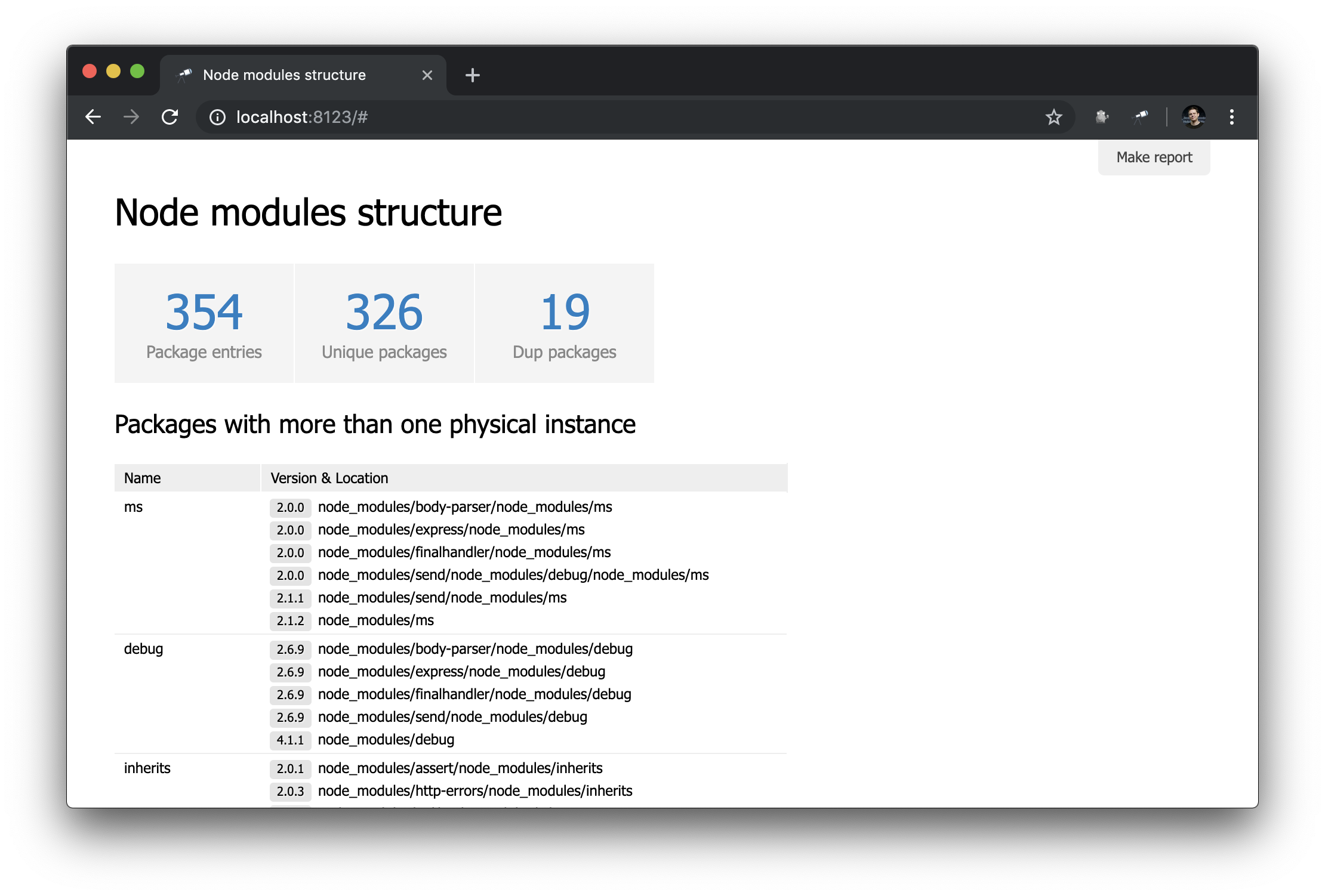
Страница пакетов
Сейчас у нас есть лишь общий обзор пакетов. Но было бы полезно иметь страницу с подробностями о конкретном пакете. Для этого создадим новый модуль pages/package.js и определим новую страницу:
discovery.page.define('package', {
view: 'context',
data: `{
name: #.id,
instances: .[name = #.id]
}`,
content: [
'h1:name',
'table:instances'
]
});В этом модуле мы определили страницу с идентификатором package. В качестве исходного представления использовался компонент context. Это невизуальный компонент, помогающий определять данные для вложенных отображений. Обратите внимание, что мы использовали #.id для получения названия пакета, которое извлекается из URL вроде такого http://localhost:8123/#package:{id}.
Не забываем включить новый модуль в конфигурацию:
module.exports = {
...
view: {
assets: [
'pages/default.js',
'pages/package.js' // вот так
]
}
};Результат в браузере:
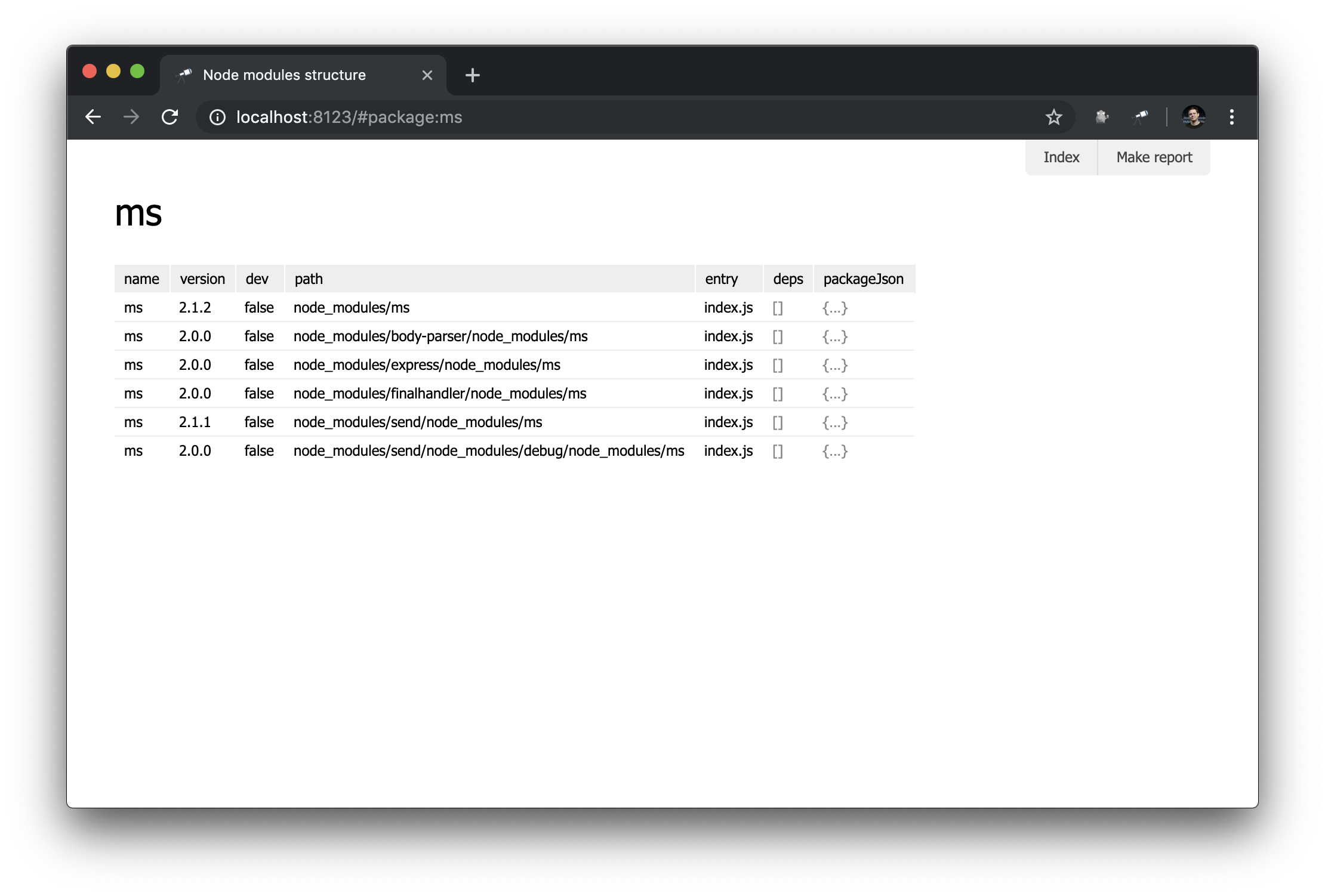
Не слишком впечатляет, но пока пойдёт. Более сложные отображения мы будем создавать в последующих руководствах.
Боковая панель
Раз у нас уже есть страница пакета, хорошо бы иметь список всех пакетов. Для этого можно определить специальное представление – sidebar, которое отображается в том случае, если его определить (по умолчанию не определено). Создадим новый модуль views/sidebar.js:
discovery.view.define('sidebar', {
view: 'list',
data: 'name.sort()',
item: 'link:{ text: $, href: pageLink("package") }'
});Теперь у нас есть список всех пакетов:
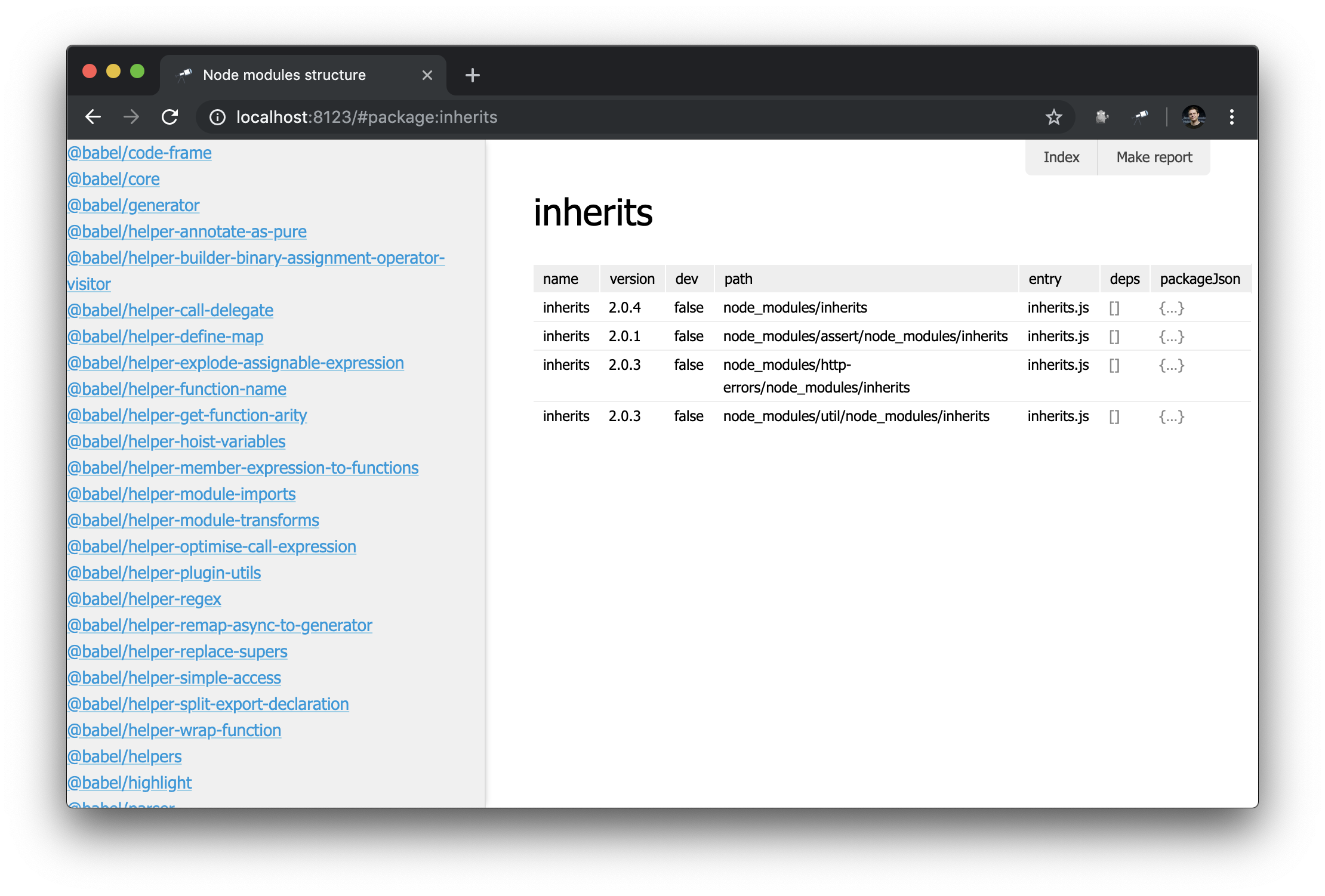
Выглядит хорошо. Но с фильтром было бы ещё лучше. Расширим определение sidebar:
discovery.view.define('sidebar', {
view: 'content-filter',
content: {
view: 'list',
data: 'name.[no #.filter or $~=#.filter].sort()',
item: {
view: 'link',
data: '{ text: $, href: pageLink("package"), match: #.filter }',
content: 'text-match'
}
}
});Здесь мы обернули список в компонент content-filter, которое преобразует вводимое значение в поле ввода в регулярное выражения (или null, если поле пустое), и сохраняет его в качестве значения filter в контексте (название можно менять опцией name). Также для фильтрации данных для списка мы применили #.filter. Наконец, мы применили отображение ссылок, чтобы подсвечивать совпадающие части с помощью text-match. Результат:

В случае, если вам не нравится оформление по умолчанию, можете настроить стили по своему желанию. Допустим, вы хотите поменять ширину боковой панели, для этого нужно создать файл стиля (скажем, views/sidebar.css):
.discovery-sidebar {
width: 300px;
}И добавить в конфигурацию ссылку на этот файл, так же как на JavaScript модули:
module.exports = {
...
view: {
assets: [
...
'views/sidebar.css', // в assets можно задавать и *.css тоже
'views/sidebar.js'
]
}
};Автоссылки
Последняя глава этого руководства посвящена ссылкам. Ранее, с помощью метода pageLink() мы делали ссылку на страницу пакета. Но помимо ссылки нужно еще задавать и текст ссылки. Но как бы нам делать это проще?
Чтобы упростить работу ссылками, нам нужно определить правило генерации ссылок. Это лучше сделать в скрипте prepare:
discovery.setPrepare(function(data) {
...
const packageIndex = data.reduce(
(map, item) => map
.set(item, item) // key is item itself
.set(item.name, item), // and `name` value
new Map()
);
discovery.addEntityResolver(value => {
value = packageIndex.get(value) || packageIndex.get(value.name);
if (value) {
return {
type: 'package',
id: value.name,
name: value.name
};
}
});
});Мы добавили новую карту (индекс) пакетов и использовали её для ресолвера сущностей. Ресолвер сущностей пытается, по возможности, преобразовать переданное ему значение в дескриптор сущности. Дескриптор содержит:
type— тип сущностиid— уникальная ссылка на экземпляр сущности, используемая в ссылках в качестве IDname— используется в качестве текста ссылки
Наконец, нужно присвоить этот тип определённой странице (ссылка ведь должна куда-то вести, не так ли?).
discovery.page.define('package', {
...
}, {
resolveLink: 'package' // привязываем тип сущности `package` к этой странице
});Первое следствие этих изменений заключается в том, что некоторые значения в представлении struct теперь помечаются ссылкой на страницу пакета:
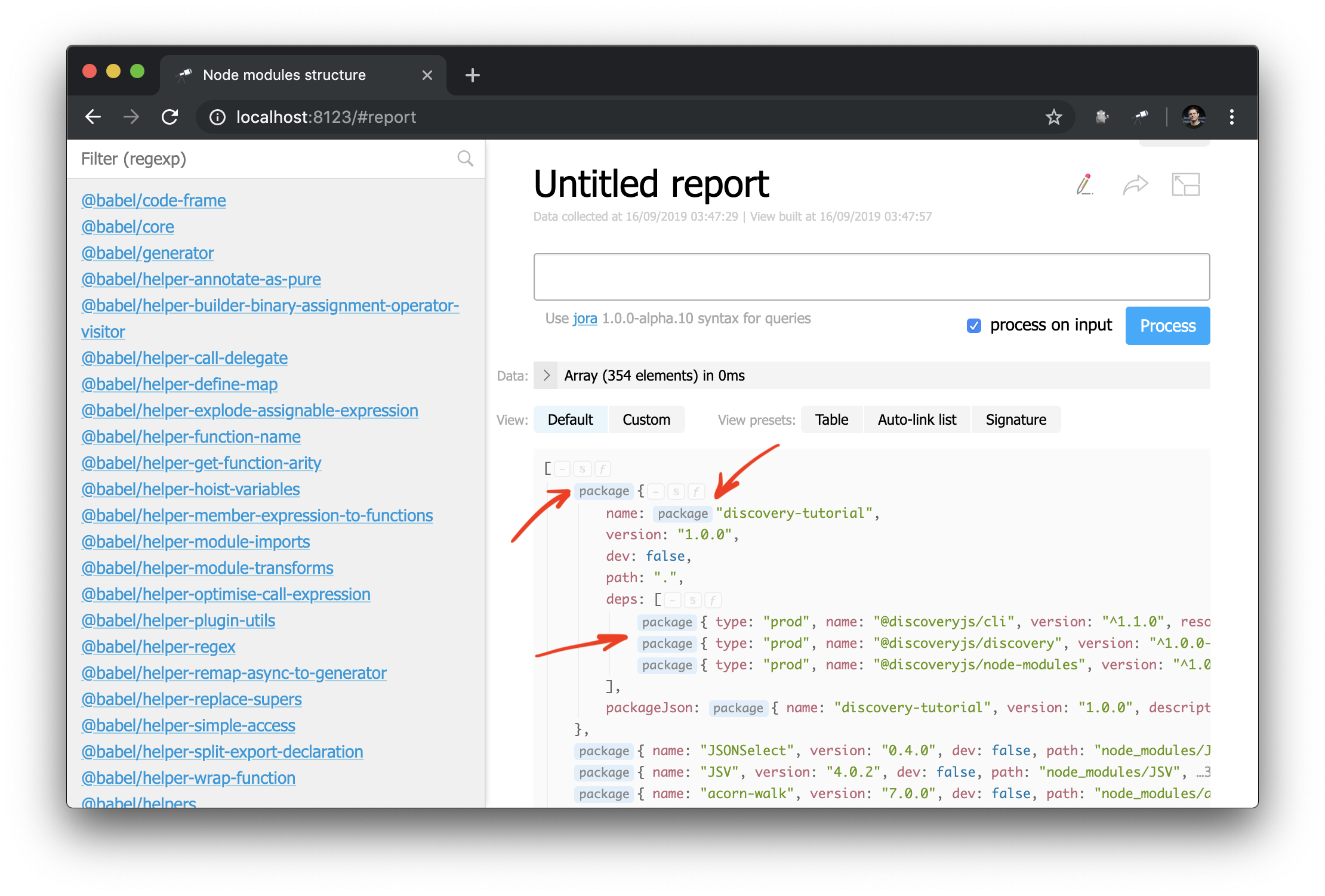
И теперь также можно применить компонент auto-link к объекту или имени пакета:
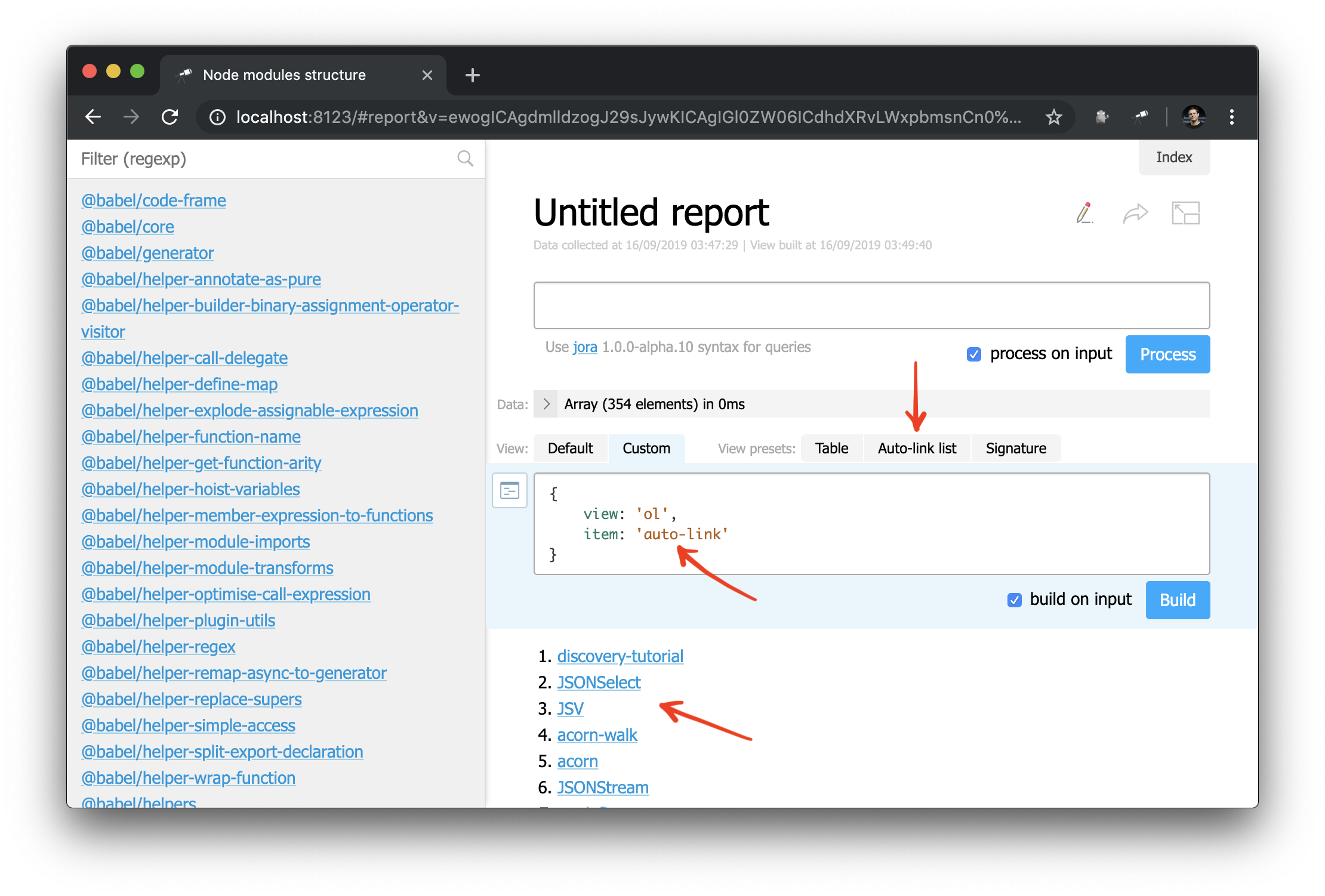
И, как пример, можно немного переработать боковую панель:
// было раньше
item: {
view: 'link',
data: '{ text: $, href: pageLink("package"), match: #.filter }',
content: 'text-match'
},
// с использованием `auto-link`
item: {
view: 'auto-link',
content: 'text-match:{ text, match: #.filter }'
}Заключение
Теперь у вас есть базовое представление о ключевых концепциях Discovery.js. В следующих руководствах мы подробнее рассмотрим затронутые темы.
Посмотреть весь исходный код руководства можно в репозитории на GitHub или попробовать как это работает онлайн.
Подписывайтесь на твиттер проекта @js_discovery, чтобы быть в курсе новостей проекта!

")


