
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Не так давно я столкнулся с задачей по переходу на новую BI-систему для нашей компании. Поскольку мне пришлось погрузиться довольно глубоко и основательно в данный вопрос, я решил поделиться с уважаемым сообществом своими мыслями на этот счет.

На просторах интернета есть немало статей на эту тему, но, к моему большому удивлению, они не ответили на многие мои вопросы по выбору нужного инструмента и были несколько поверхностны. В рамках 3 недель тестирования мы опробовали 4 инструмента: Tableau, Looker, Periscope/Sisense, Mode analytics. Про эти инструменты в основном и пойдет речь в данной статье. Сразу оговорюсь, что предложенная статья — это личное мнение автора, отражающее потребности небольшой, но очень быстро растущей IT-компании :)
Сейчас на рынке BI происходят довольно интересные изменения, идёт консолидация, крупные игроки облачных технологий пытаются укрепить свои позиции путем вертикальной интеграции всех аспектов работы с данными (хранение данных, обработка, визуализация). За последние несколько месяцев произошло 5 крупных поглощений: Google купил Looker, Salesforce купил Tableau, Sisense купил Periscope Data, Logi Analytics' купил Zoomdata, Alteryx купил ClearStory Data. Не будем дальше погружаться в корпоративный мир слияний и поглощений, стоит лишь отметить, что можно ожидать дальнейших изменений как в ценовой, так и в протекционистской политике новых обладателей BI-инструментов (как недавно нас обрадовал инструмент Alooma, вскоре после покупки их компанией Google, они перестают поддерживать все источники данных, кроме Google BigQuery :) ).
Итак, начать я хотел с небольшой теоретической части, ибо куда нынче без теории. Как говорит нам Гартнер, BI система — это термин, объединяющий программные продукты, инструменты, инфраструктуру и лучшие практики, который позволяет улучшать и оптимизировать принимаемые решения [1]. Под это определение попадают в частности и хранение данных и ETL. В рамках данной статьи я предлагаю сосредоточиться на более узком сегменте, а именно на программных продуктах для визуализации и анализа данных.
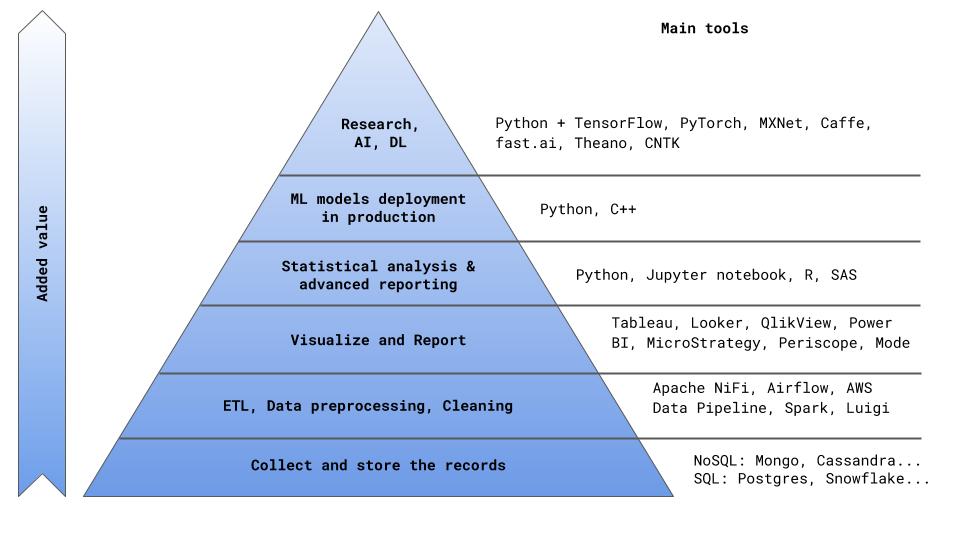
В пирамиде создания ценности для компании (я имел смелость предложить очередное изложение этой очевидной структуры на Рис. 0) инструменты BI находятся после блоков хранения записей и предварительной обработки данных (ETL).
Это важно понимать — лучшей практикой в данном случае является разделения задач ETL и BI. Помимо более прозрачного процесса работы с данными, вы также не окажетесь привязанными к одному программному решению и сможете подобрать наиболее подходящий инструмент под каждую из задач ETL и BI. При грамотно выстроенном ETL-процессе и оптимальной архитектуре таблиц данных можно в целом закрыть 80% всех насущных вопросов бизнеса без использования специального ПО. Это, конечно, потребует значительного вовлечения аналитиков и DS. Поэтому приходим к главному вопросу: а что нам, собственно, нужно в первую очередь от программного продукта BI?
Рис. 0
Ключевые критерии при выборе программного продукта BI
Как мы уже с вами поняли, все ключевые метрики и показатели деятельности компании в целом можно взять напрямую из аналитических таблиц в базе данных, предварительно подготовленных в рамках ETL-процесса (о том, как оптимально построить ETL-процесс, я расскажу в следующей статье, а пока приведу тизер, почему это так важно: по опросу Kaggle, главная сложность, с которой сталкивается половина DS — это грязные данные [2]). Основной проблемой в этом случае, очевидно, будет трудоемкость и неэффективность использования времени аналитиков. Вместо создания полноценного продукта, аналитики/DS будут все свое время готовить показатели, считать метрики, сверять расхождения в цифрах, искать ошибки в SQL-коде и заниматься прочей бесполезной деятельностью. Здесь я убежден, что главное чем должны заниматься аналитики/DS — это создание продукта, приносящего ценность компании в долгосрочной перспективе. Это может быть как расчетный/предиктивный сервис, результат которого — это часть основного продукта компании (например, алгоритм расчета стоимости/времени поездки) или, скажем, алгоритм распределения заказов по клиентам, так и полноценный аналитический отчет, выявляющий причины оттока пользователей и снижения MAU.
Поэтому основным критерием выбора аналитической системы должна быть возможность максимально разгрузить аналитиков от ad hoc-задач и текучки. Как этого можно добиться? По сути, есть два варианта: а) автоматизировать, б) делегировать. Под вторым пунктом я имею ввиду популярное нынче словосочетание Self Service — дать бизнесу возможность копаться в данных самому.
То есть, аналитики настраивают один раз программный продукт: создают кубы данных, настраивают автоматическое обновление кубов (например, каждую ночь), автоматическую отправку отчетов, готовят несколько мастер дашбордов и обучают пользователей, как пользоваться продуктом. Дальше бизнес обеспечивает свои дополнительные потребности самостоятельно, путем расчета необходимых ему показателей в различной агрегацией и фильтрацией данных с помощью простой и понятной опции drag&drop.
Помимо простоты процесса составления отчетов важна также скорость выполнения запросов. Никто не будет ждать 15 минут, пока загрузится предыдущий месяц данных или показатели для другого города. Для решения этого вопроса существует несколько общепринятых подходов. Один из них — это создание OLAP(online analytical processing) кубов данных. В OLAP кубах типы данных разделяются на измерения (dimensions) — это поля, по которым можно делать агрегации (например, город, страна, продукт, временные интервалы, тип оплаты...), и меры (measures) — это расчетные метрики для измерений (например, количество поездок, выручка, количество новых пользователей, средний чек, ...). Кубы данных — это довольно мощный инструмент, позволяющий очень быстро выдавать результат за счет предварительно агрегированных данных и рассчитанных метрик. Обратной стороной OLAP кубов является тот факт, что все данные заранее собраны и не изменяются до следующей сборки куба. Если вам понадобится агрегация данных или метрика, которая не была изначально рассчитана, или если вам необходимы более свежие данные, то куб данных надо пересоздавать [link].
Другое решение для повышения скорости работы с данными — это in-memory solutions [link]. In Memory Database (IMDB) разработана для обеспечения максимальной производительности, когда есть достаточно оперативной памяти для хранения данных. В то время как реляционные БД разработаны для обеспечения максимальной производительности, когда данные не полностью помещаются в оперативную память, и медленные операции ввода-вывода на диске должны выполняться в режиме реального времени. Многие современные инструменты объединяют оба этих решения (например, Sisense, Tableau, IBM Cognos, MicroStrategy, и др.).
До этого мы с вами говорили о простоте и удобстве использования инструментов BI для бизнес пользователей. Важно и настроить удобный процесс разработки и релиза дашбордов для аналитиков/DS. Здесь ситуация аналогична любому другому ИТ-продукту — необходим быстрый и удобный процесс развертывания (rapid deployment time), а также продуманность процесса разработки, тестирования, code review, релиза, version control, team collaboration. Все это объединяется понятием workflow.
Таким образом мы приходим к ключевым требованиям к программному продукту BI. Эти же требование легли в основу скор-карты, на основании которой мы в итоге выбрали поставщика продукта.
Таблица 1. Критерии выбора инструмента BI.
Итоговая таблица результатов голосования внутри нашей команды выглядит следующим образом:
Таблица 2. Итоги голосования по выбору инструмента BI.
Со стороны бизнес-пользователей (они тоже принимали участие в выборе продукта) голоса разделились примерно поровну между Tableau и Looker. В итоге выбор был сделан в в пользу Looker. Почему именно Looker и какие принципиальные различия между инструментами, мы сейчас обсудим.
Итак, приступим к описанию BI-инструментов.
К выбору провайдера BI инструмента необходимо подойти основательно, заручившись поддержкой со стороны бизнес пользователей и определив основные критерии выбора инструмента (желательно, в виде скор карты). Приведенные в данной статье критерии ориентированы в первую очередь на повышение эффективности работы с данными, упрощение процесса извлечения информации, повышения качества визуализации данных и снижение нагрузки на аналитиков.
На просторах интернета есть немало статей на эту тему, но, к моему большому удивлению, они не ответили на многие мои вопросы по выбору нужного инструмента и были несколько поверхностны. В рамках 3 недель тестирования мы опробовали 4 инструмента: Tableau, Looker, Periscope/Sisense, Mode analytics. Про эти инструменты в основном и пойдет речь в данной статье. Сразу оговорюсь, что предложенная статья — это личное мнение автора, отражающее потребности небольшой, но очень быстро растущей IT-компании :)
Несколько слов о рынке
Сейчас на рынке BI происходят довольно интересные изменения, идёт консолидация, крупные игроки облачных технологий пытаются укрепить свои позиции путем вертикальной интеграции всех аспектов работы с данными (хранение данных, обработка, визуализация). За последние несколько месяцев произошло 5 крупных поглощений: Google купил Looker, Salesforce купил Tableau, Sisense купил Periscope Data, Logi Analytics' купил Zoomdata, Alteryx купил ClearStory Data. Не будем дальше погружаться в корпоративный мир слияний и поглощений, стоит лишь отметить, что можно ожидать дальнейших изменений как в ценовой, так и в протекционистской политике новых обладателей BI-инструментов (как недавно нас обрадовал инструмент Alooma, вскоре после покупки их компанией Google, они перестают поддерживать все источники данных, кроме Google BigQuery :) ).
Немного теории
Итак, начать я хотел с небольшой теоретической части, ибо куда нынче без теории. Как говорит нам Гартнер, BI система — это термин, объединяющий программные продукты, инструменты, инфраструктуру и лучшие практики, который позволяет улучшать и оптимизировать принимаемые решения [1]. Под это определение попадают в частности и хранение данных и ETL. В рамках данной статьи я предлагаю сосредоточиться на более узком сегменте, а именно на программных продуктах для визуализации и анализа данных.
В пирамиде создания ценности для компании (я имел смелость предложить очередное изложение этой очевидной структуры на Рис. 0) инструменты BI находятся после блоков хранения записей и предварительной обработки данных (ETL).
Это важно понимать — лучшей практикой в данном случае является разделения задач ETL и BI. Помимо более прозрачного процесса работы с данными, вы также не окажетесь привязанными к одному программному решению и сможете подобрать наиболее подходящий инструмент под каждую из задач ETL и BI. При грамотно выстроенном ETL-процессе и оптимальной архитектуре таблиц данных можно в целом закрыть 80% всех насущных вопросов бизнеса без использования специального ПО. Это, конечно, потребует значительного вовлечения аналитиков и DS. Поэтому приходим к главному вопросу: а что нам, собственно, нужно в первую очередь от программного продукта BI?
Рис. 0
Ключевые критерии при выборе программного продукта BI
Как мы уже с вами поняли, все ключевые метрики и показатели деятельности компании в целом можно взять напрямую из аналитических таблиц в базе данных, предварительно подготовленных в рамках ETL-процесса (о том, как оптимально построить ETL-процесс, я расскажу в следующей статье, а пока приведу тизер, почему это так важно: по опросу Kaggle, главная сложность, с которой сталкивается половина DS — это грязные данные [2]). Основной проблемой в этом случае, очевидно, будет трудоемкость и неэффективность использования времени аналитиков. Вместо создания полноценного продукта, аналитики/DS будут все свое время готовить показатели, считать метрики, сверять расхождения в цифрах, искать ошибки в SQL-коде и заниматься прочей бесполезной деятельностью. Здесь я убежден, что главное чем должны заниматься аналитики/DS — это создание продукта, приносящего ценность компании в долгосрочной перспективе. Это может быть как расчетный/предиктивный сервис, результат которого — это часть основного продукта компании (например, алгоритм расчета стоимости/времени поездки) или, скажем, алгоритм распределения заказов по клиентам, так и полноценный аналитический отчет, выявляющий причины оттока пользователей и снижения MAU.
Поэтому основным критерием выбора аналитической системы должна быть возможность максимально разгрузить аналитиков от ad hoc-задач и текучки. Как этого можно добиться? По сути, есть два варианта: а) автоматизировать, б) делегировать. Под вторым пунктом я имею ввиду популярное нынче словосочетание Self Service — дать бизнесу возможность копаться в данных самому.
То есть, аналитики настраивают один раз программный продукт: создают кубы данных, настраивают автоматическое обновление кубов (например, каждую ночь), автоматическую отправку отчетов, готовят несколько мастер дашбордов и обучают пользователей, как пользоваться продуктом. Дальше бизнес обеспечивает свои дополнительные потребности самостоятельно, путем расчета необходимых ему показателей в различной агрегацией и фильтрацией данных с помощью простой и понятной опции drag&drop.
Помимо простоты процесса составления отчетов важна также скорость выполнения запросов. Никто не будет ждать 15 минут, пока загрузится предыдущий месяц данных или показатели для другого города. Для решения этого вопроса существует несколько общепринятых подходов. Один из них — это создание OLAP(online analytical processing) кубов данных. В OLAP кубах типы данных разделяются на измерения (dimensions) — это поля, по которым можно делать агрегации (например, город, страна, продукт, временные интервалы, тип оплаты...), и меры (measures) — это расчетные метрики для измерений (например, количество поездок, выручка, количество новых пользователей, средний чек, ...). Кубы данных — это довольно мощный инструмент, позволяющий очень быстро выдавать результат за счет предварительно агрегированных данных и рассчитанных метрик. Обратной стороной OLAP кубов является тот факт, что все данные заранее собраны и не изменяются до следующей сборки куба. Если вам понадобится агрегация данных или метрика, которая не была изначально рассчитана, или если вам необходимы более свежие данные, то куб данных надо пересоздавать [link].
Другое решение для повышения скорости работы с данными — это in-memory solutions [link]. In Memory Database (IMDB) разработана для обеспечения максимальной производительности, когда есть достаточно оперативной памяти для хранения данных. В то время как реляционные БД разработаны для обеспечения максимальной производительности, когда данные не полностью помещаются в оперативную память, и медленные операции ввода-вывода на диске должны выполняться в режиме реального времени. Многие современные инструменты объединяют оба этих решения (например, Sisense, Tableau, IBM Cognos, MicroStrategy, и др.).
До этого мы с вами говорили о простоте и удобстве использования инструментов BI для бизнес пользователей. Важно и настроить удобный процесс разработки и релиза дашбордов для аналитиков/DS. Здесь ситуация аналогична любому другому ИТ-продукту — необходим быстрый и удобный процесс развертывания (rapid deployment time), а также продуманность процесса разработки, тестирования, code review, релиза, version control, team collaboration. Все это объединяется понятием workflow.
Таким образом мы приходим к ключевым требованиям к программному продукту BI. Эти же требование легли в основу скор-карты, на основании которой мы в итоге выбрали поставщика продукта.
Таблица 1. Критерии выбора инструмента BI.
| № | Требование | Описание | Значимость (min=1, max=5) |
|---|---|---|---|
| 1 | UX + drag&drop | Необходим понятный и доступный бизнес-пользователям интерфейс с возможностью drag&drop для создания отчетов | 5 |
| 2 | Data handling | Как хранятся и обрабатываются данные системой. Это те самые механики, как OLAP и in-memory solutions, о которых мы говорили выше. Чем быстрее и проще организован доступ к данным — тем лучше. | 5 |
| 3 | Workflow | Необходим быстрый и удобный процесс развертывания (rapid deployment time). Также code review, version control, development & release. | 5 |
| 4 | Visualization | Набор доступных визуализаций данных. Чем больше различный вариантов представления данных — тем лучше. | 4 |
| 5 | Support | Доступность поддержки, SLA на реагирование на запрос. | 3 |
| 6 | Statistics | Возможность использования статистических методов, интеграция с Python. | 2 |
| 7 | Price | Здесь все понятно, Лебовский :) | 4 |
Итоговая таблица результатов голосования внутри нашей команды выглядит следующим образом:
Таблица 2. Итоги голосования по выбору инструмента BI.
| № | Требование | Значимость | Tableau | Looker | Periscope | Mode |
|---|---|---|---|---|---|---|
| 1 | UX + drag&drop | 5 | 4.3 | 4.6 | 2.7 | 2.8 |
| 2 | Data handling | 5 | 4.4 | 3.5 | 3.6 | 2.3 |
| 3 | Workflow | 5 | 3.1 | 4.8 | 3.8 | 3.3 |
| 4 | Visualization | 4 | 3.8 | 3.7 | 3.4 | 2.1 |
| 5 | Support | 3 | 3.7 | 4.2 | 3.8 | 3.4 |
| 6 | Statistics | 2 | 2.3 | 2.2 | 2.5 | 2.8 |
| 7 | Price | 4 | 4 | 2 | 4 | 3 |
| Итого | 3.77 | 3.79 | 3.43 | 2.79 |
Со стороны бизнес-пользователей (они тоже принимали участие в выборе продукта) голоса разделились примерно поровну между Tableau и Looker. В итоге выбор был сделан в в пользу Looker. Почему именно Looker и какие принципиальные различия между инструментами, мы сейчас обсудим.
Детальное описание инструментов
Итак, приступим к описанию BI-инструментов.
-
Tableau
(здесь речь пойдет о расширенном пакете услуг: Tableau Online)
- UX + drag&drop.
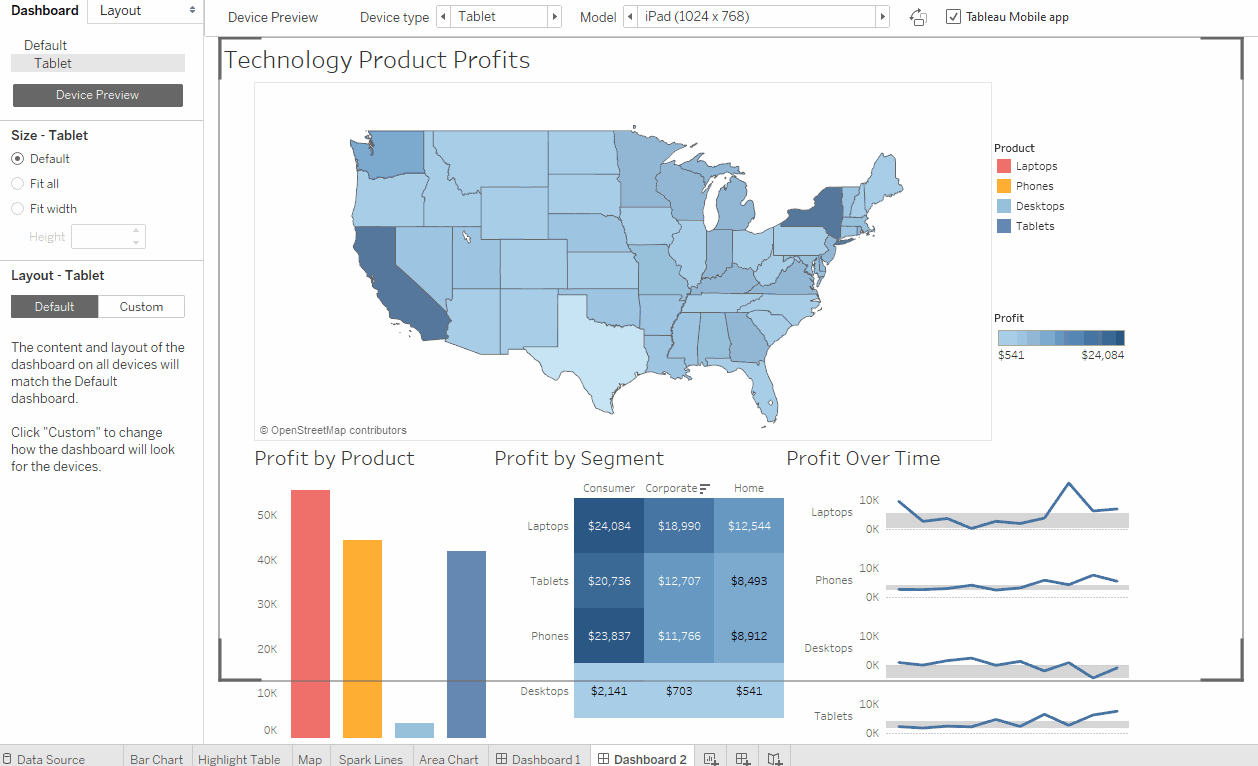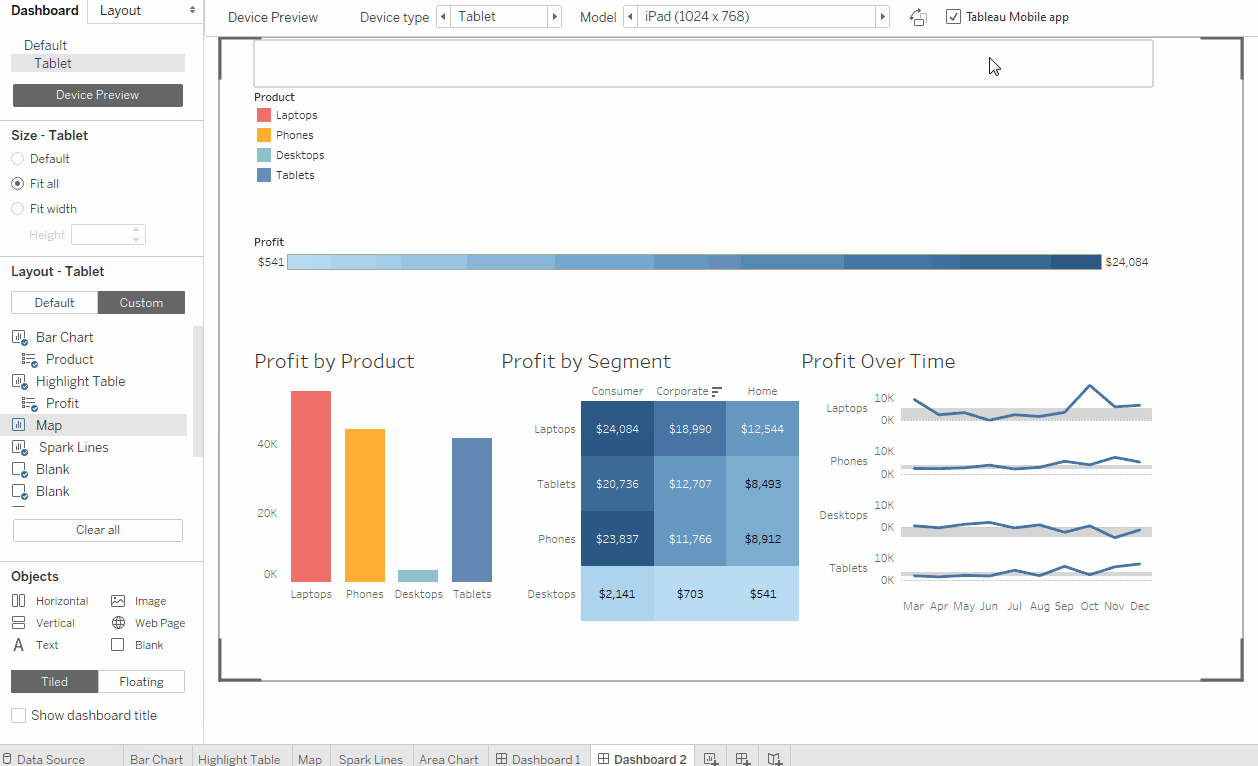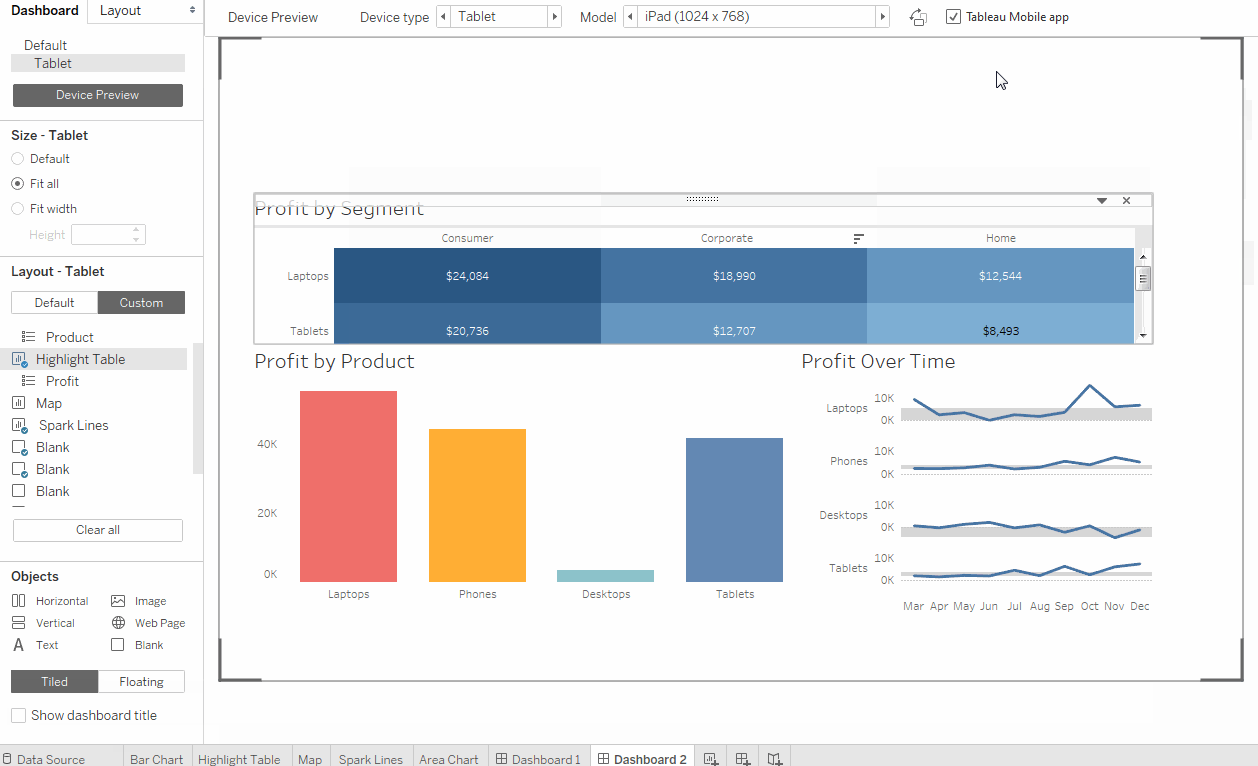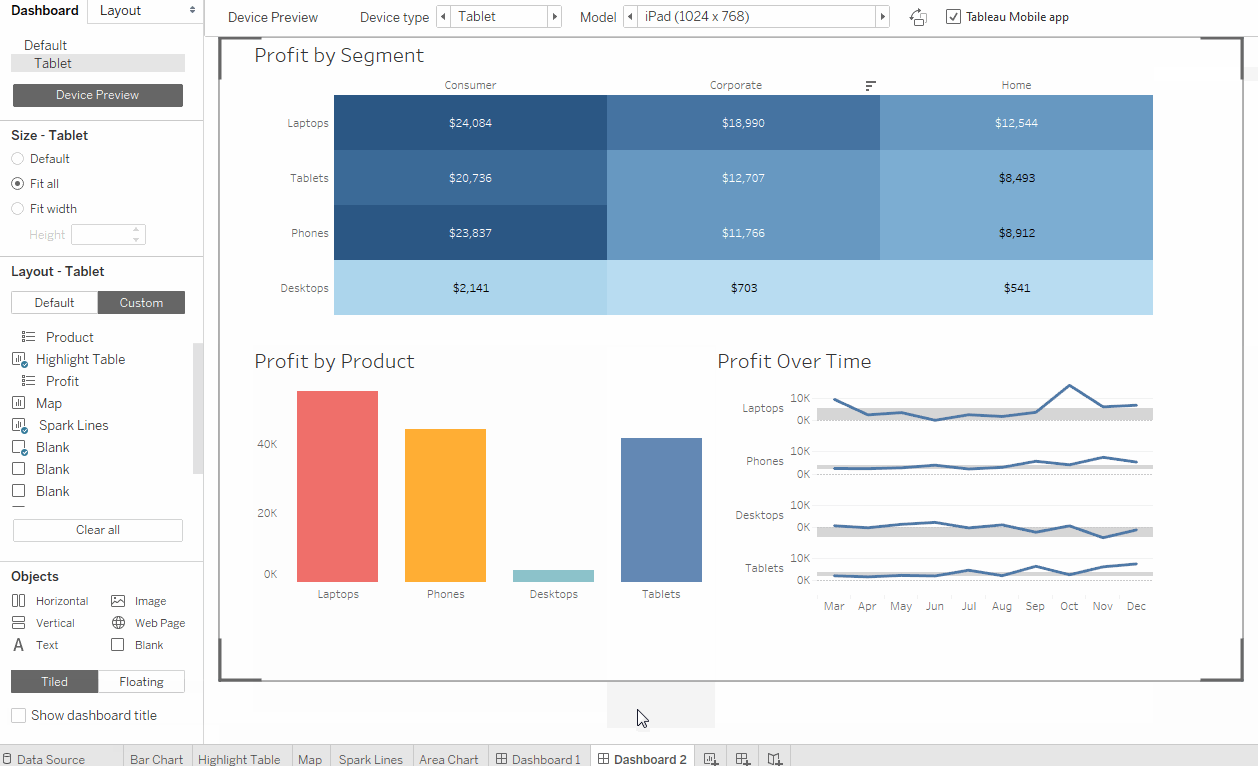
Tableau довольно старый инструмент, на рынке с 2003 года, и есть ощущение, что интерфейс с тех пор не сильно изменился. Вас могут испугать всплывающие окна и выпадающие опции в стиле Windows XP (Рис. 1, Рис. 2). Но довольно быстро можно привыкнуть и освоить базовую функциональность инструмента. Tableau многим напоминает продвинутую версию Excel, у него есть вкладки (worksheets) и дашборды (Dashboards) — объединение визуализаций, полученных на worksheets. Опция drag&drop довольно простая в использовании, легко настраиваются и меняются фильтры на графиках (Рис. 3, Рис. 4). У Tableau есть две версии услуги: Desktop и Desktop+Online. Desktop более старомодная — это, по-сути, продвинутый Excel. Online версия за период тестирования довольно часто призадумывалась и это иногда заканчивалось обновлением страницы без сохранения вашей работы.
Рис. 1
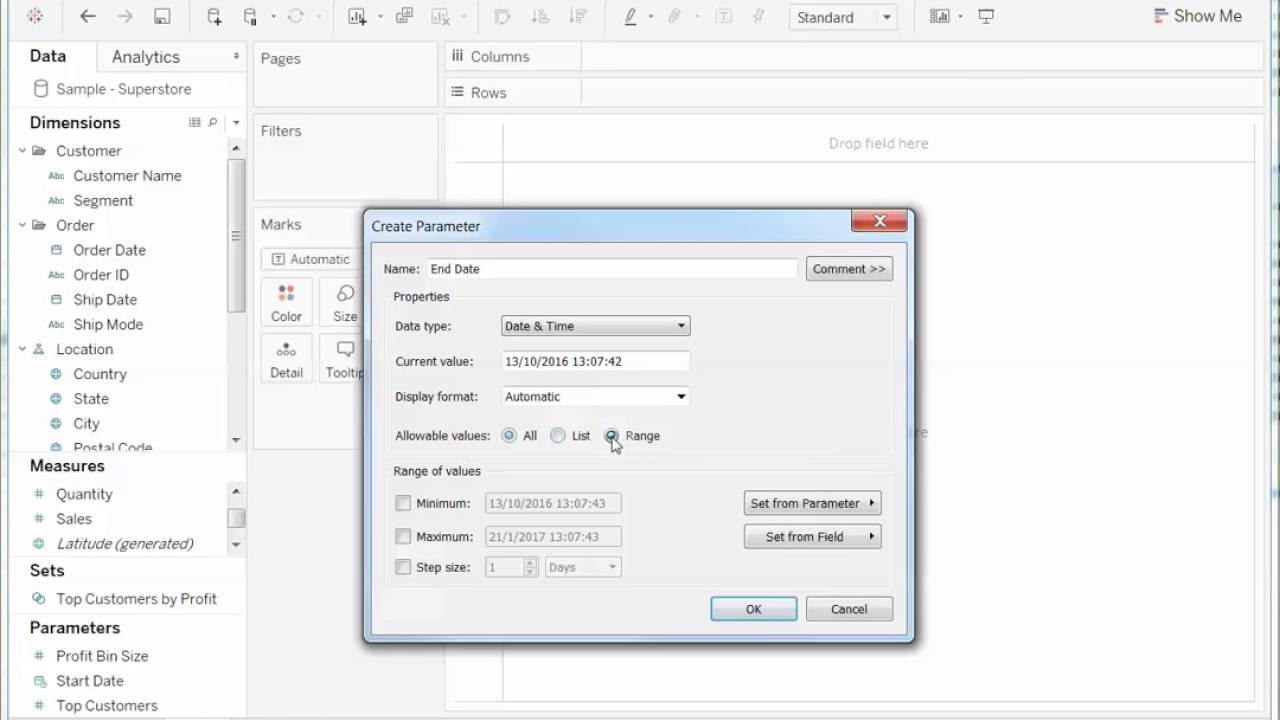
Рис. 2
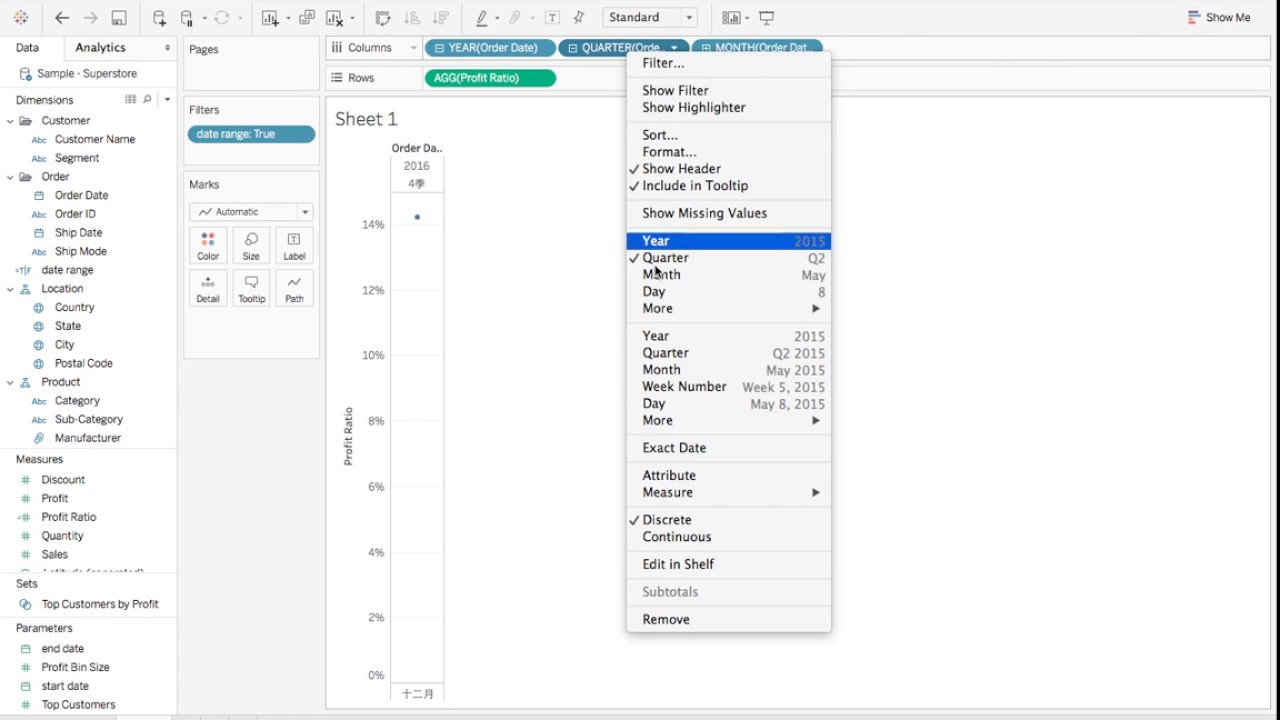
Рис. 3
Рис. 4
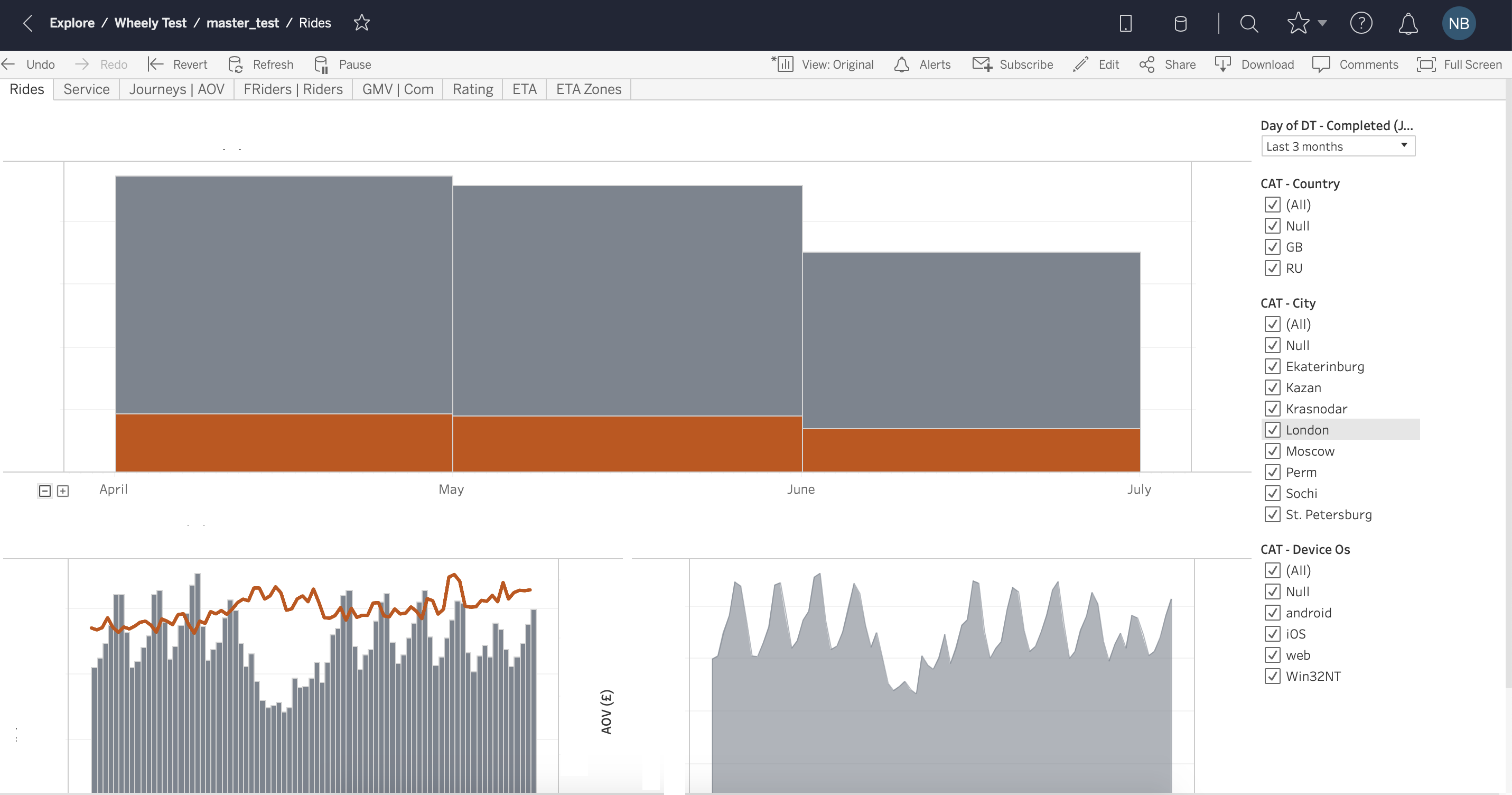
- Data handling.
Tableau очень быстро оперирует данными, изменение временного фильтра или агрегации происходит в считанные секунды даже на больших объемах данных (более 20 млн записей). Как мы уже говорили, для этого Tableau использует как OLAP кубы данных, так и in-memory data engine. Tableau заявляет, что благодаря их внутреннему in-memory решению Hyper скорость выполнения запросов повысилась в 5 раз [link].
Кубы данных можно настроить на локальной версии Tableau Desktop и загрузить или обновить их на сетевом сервере, в таком случае все дашборды, построенные на предыдущей версии сборки куба автоматически обновятся. Обновление кубов можно настроить автоматически, например, ночью. Все измерения и меры (dimensions and measures) задаются заранее при сборке куба и не меняются до следующей версии сборки. Вместе с использованием кубов данных в Tableau есть возможность обращаться напрямую к базе данных, это называется Live connection, в таком случае скорость будет гораздо ниже, но и данные будут более актуальные. Процесс сборки куба данных довольно простой, главное — выбрать правильные поля для сборки нескольких таблиц (joins) (Рис. 5).
Рис. 5
- Workflow.
Именно из-за этого пункта мы в дальнейшем не выбрали Tableau. По этому параметру Tableau отстал довольно сильно от индустрии и не смог предложить никаких инструментов для упрощения процесса разработки и релиза дашбордов. В Tableau не предусмотрены version control, code review, team collaboration, как и нет продуманной среды разработки и тестирования. Именно из-за это свойства компании часто отказываются от Tableau в пользу более современных инструментов. Уже при нескольких сотрудниках, участвующих в создании кубов данных и дашбордов, может возникнуть путаница — где найти последнюю версию данных, какими метриками можно пользоваться, а какими нельзя. Отсутствует целостность данных, что приводит к недоверию бизнеса к метрикам, которые он видит в системе.
- Visualization.
С точки зрения визуализации данных, Tableau весьма мощный инструмент. Можно найти чарты и графики на любой вкус и цвет (Рис. 6). Визуализация данных — страничная, как в Excel, можно переключаться между вкладками.
Рис. 6
- Support.
С точки зрения поддержки Tableau мне показался не очень клиентоориентированным, на большинство вопросов пришлось искать ответ самостоятельно. Благо у Tableau есть довольно большое community [ссылка], где можно найти ответы на большинство вопросов.
- Statistics.
В Tableau есть возможность интеграции с Python, больше деталей можно найти здесь.
- Price.
Цены довольно стандартные для рынка, можно найти на официальном сайте (цены). Цена зависит от уровня пользователя (Developer, Explorer, Viewer), описание можно найти там же (уровни пользования). При расчете 10 Developers, 25 Explorers и 100 Viewers, в год выходит $39,000/год.
- UX + drag&drop.
Looker
- UX + drag&drop.
Looker относительно молодая компания, основана в 2012 году. UX нативно понятный и простой для пользователя, drag&drop реализована удобно (Рис. 7).
Рис. 7
- Data handling.
Работа с данными в Looker заметно медленнее, чем в Tableau. Основная причина в том, что Looker делает запросы напрямую к базе данных, не создавая OLAP кубы. Как мы обсуждали в таком подходе есть свои плюсы — то, что данные всегда свежие и можно сделать любую агрегацию данных. Looker также дает инструмент для ускорения сложных запросов — Cached Queries [ссылка] — возможность кешировать запросы.
- Workflow.
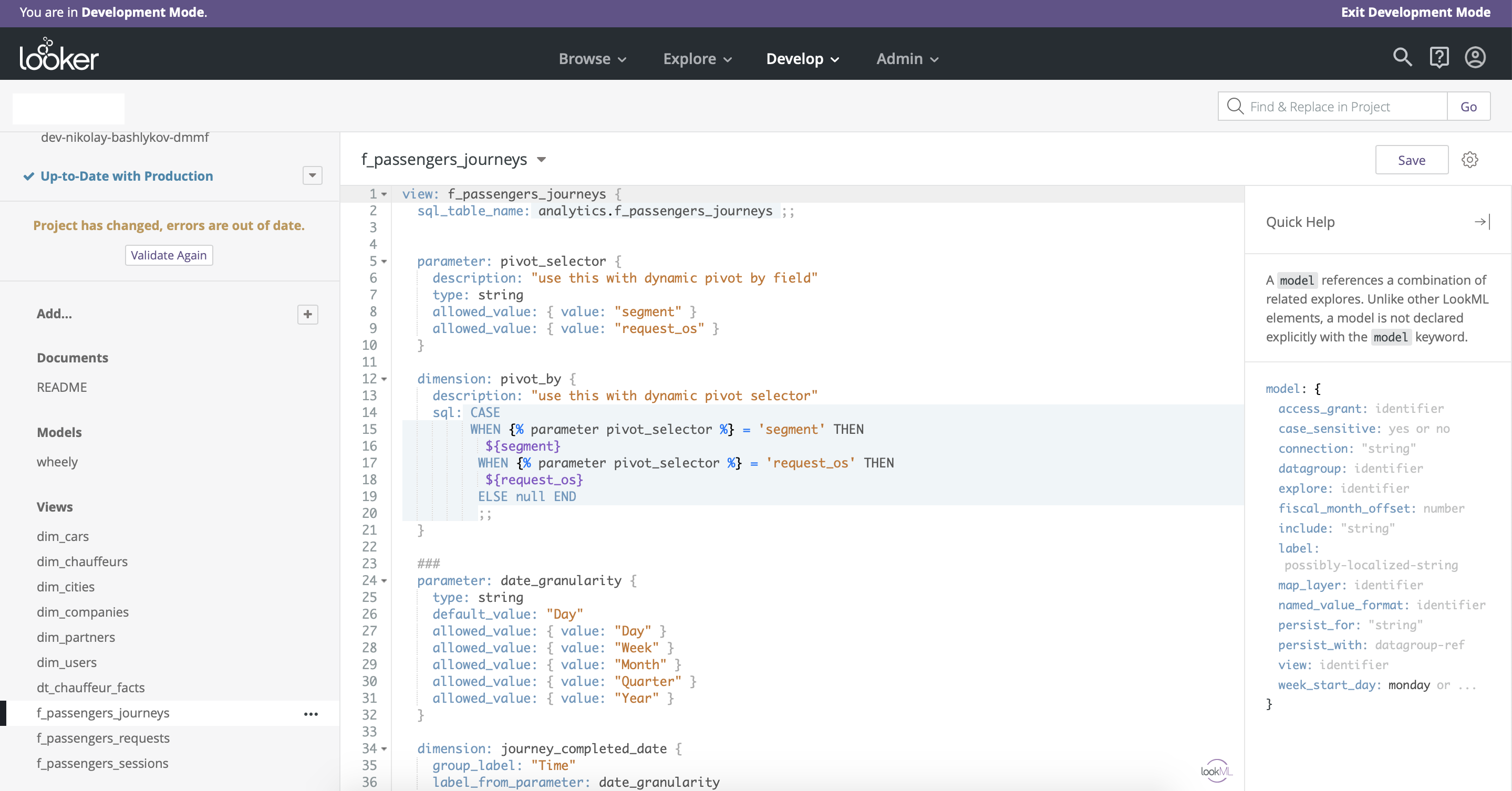
Основное преимущество Looker по сравнению со всеми BI-инструментами, которые мы тестировали — хорошо продуманный процесс разработки и релиза дашбордов. В Looker интегрирован version control c использованием github. Также хорошо разделена среда разработки (Development mode) и продуктивная среда (Рис. 8). Еще одно преимущество Looker — то, что доступ к моделированию данных остается в одних руках — есть только одна master-версия модели данных, что обеспечивает целостность.
Имеет смысл здесь также упомянуть, что у Looker есть свой аналог языка SQL c дополнительными фичами для моделирования данных — LookML. Это довольно простой и гибкий инструмент, который позволяет кастомизировать функциональность drag&drop и добавляет много новых опций (Рис. 9).
Рис. 8
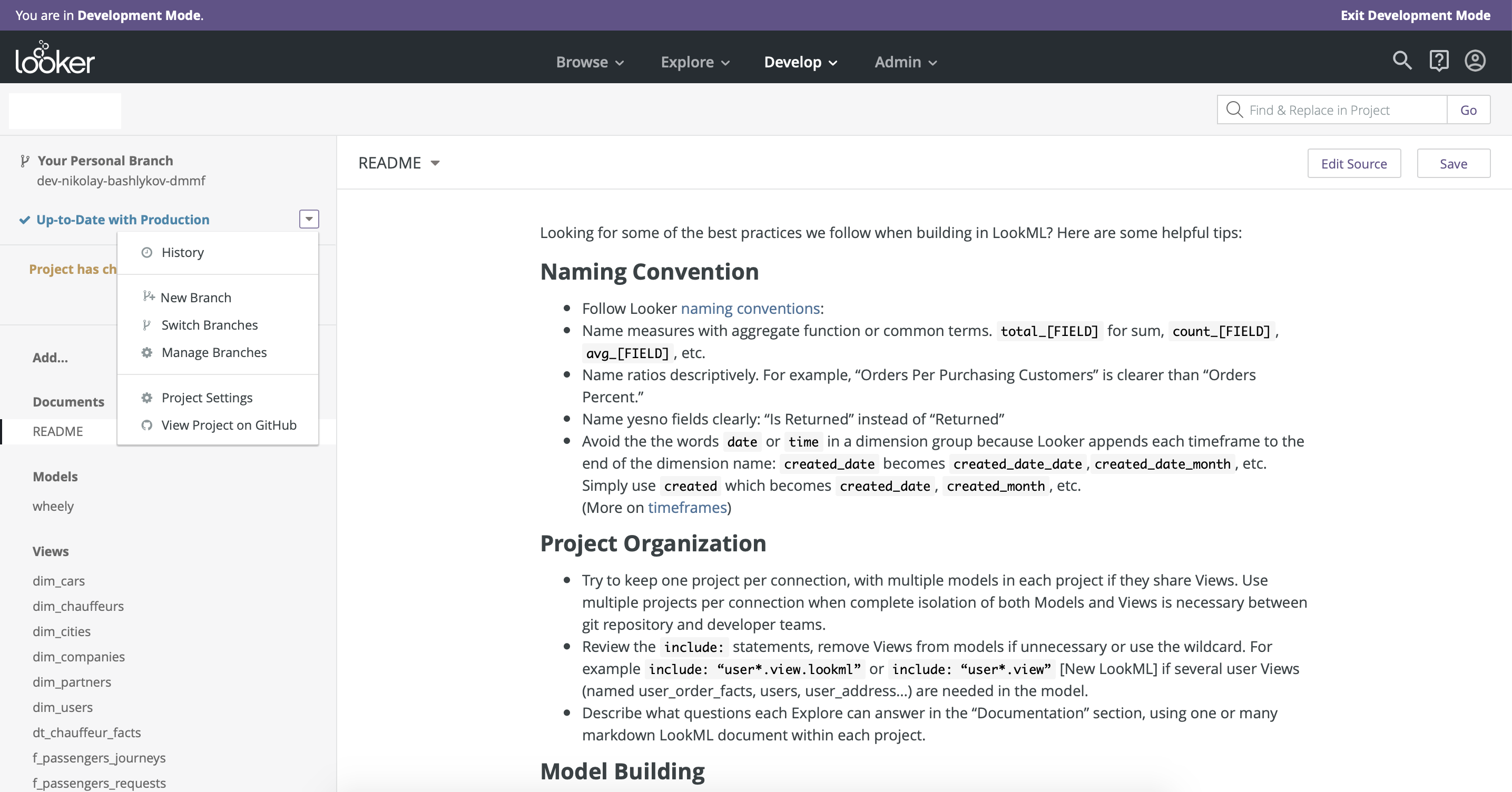
Рис. 9
- Visualization.
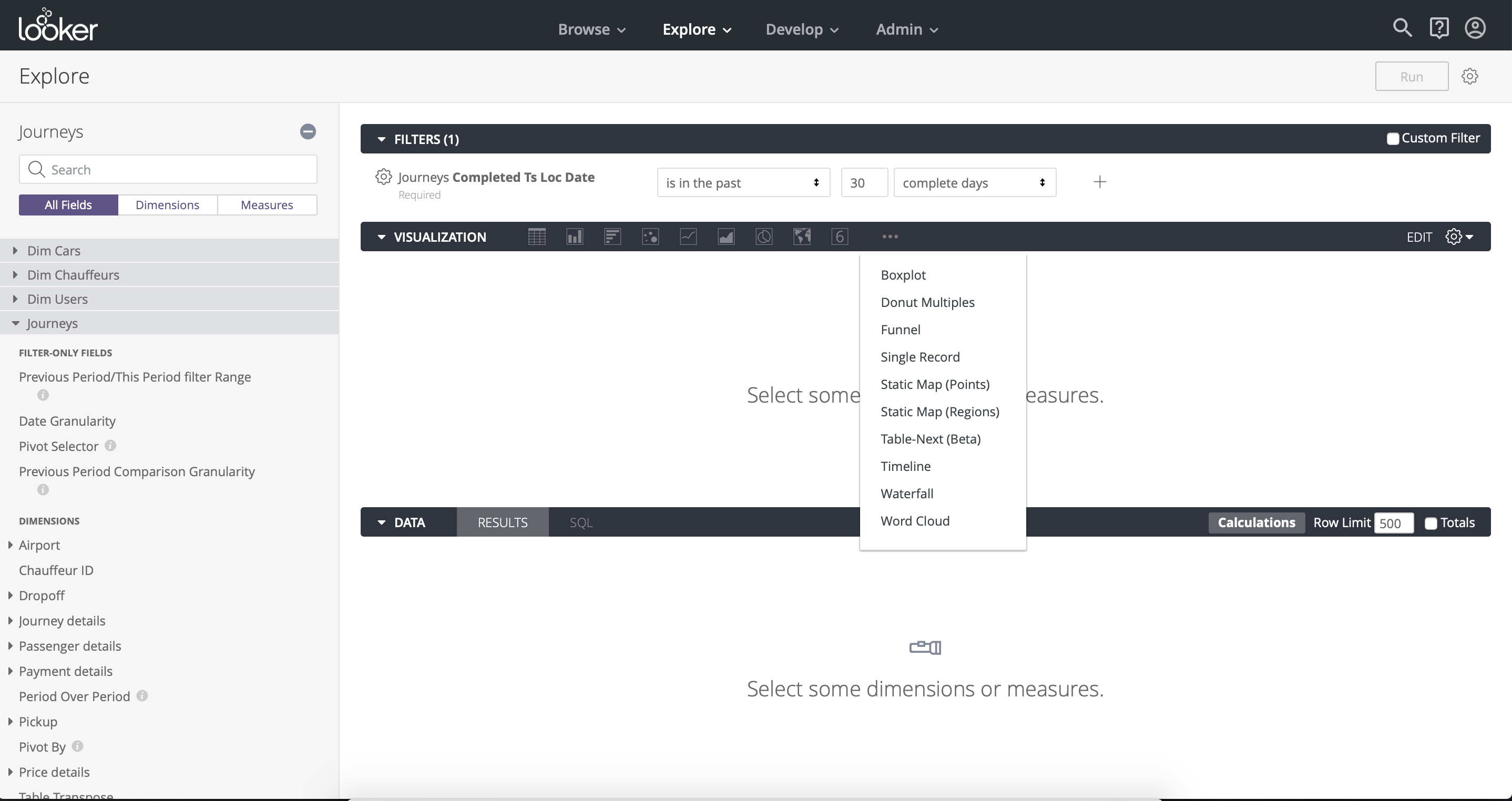
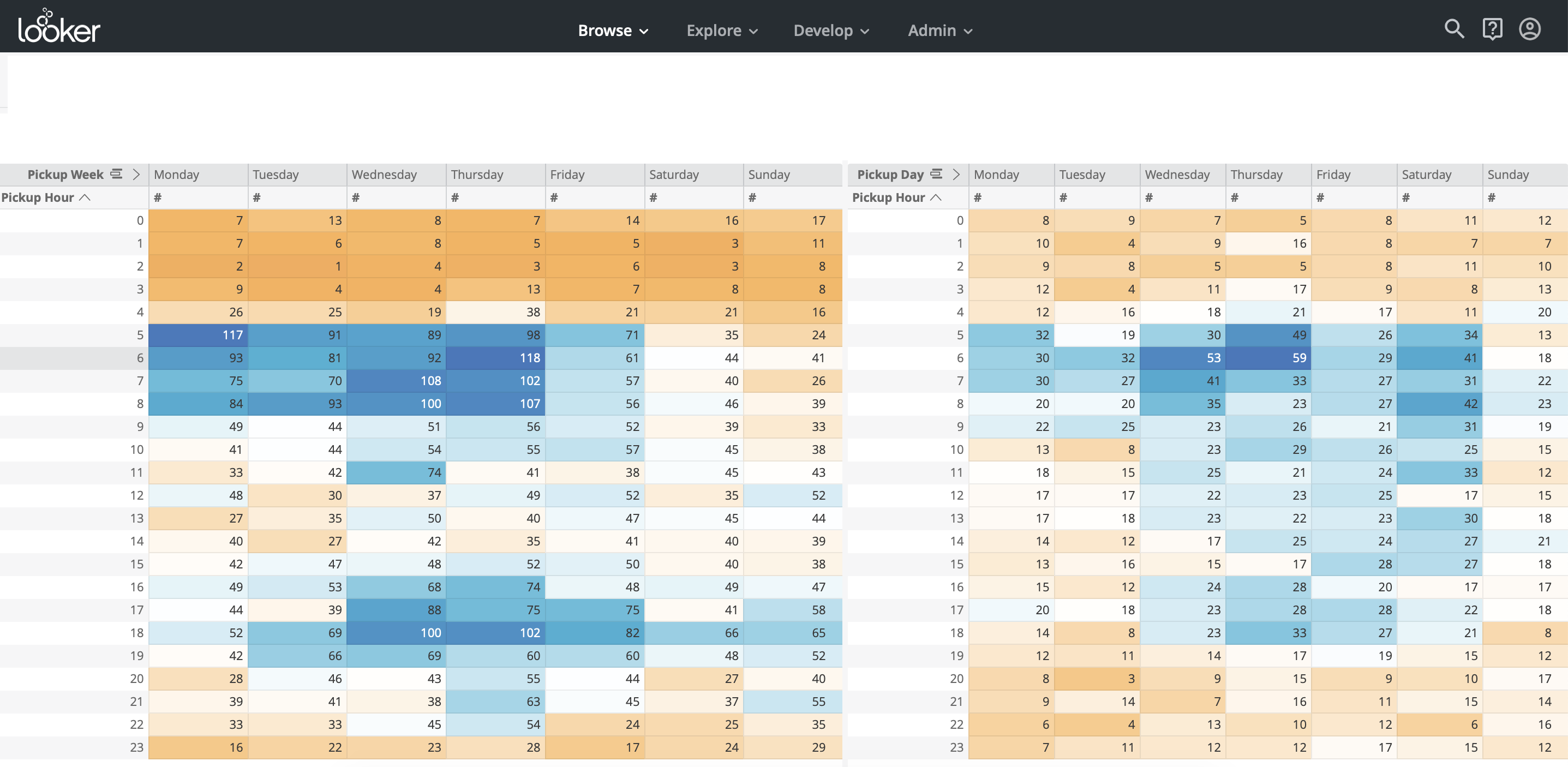
С точки зрения визуализации Looker не сильно уступает Tableau, в нем можно найти любые графики и чарты на свой вкус. Организация чартов — вертикальная, в отличие от Tableau, где организация страничная (Рис. 10, Рис. 11). Одна полезная для бизнес-пользователей функция — это drill down — возможность сегментировать выбранные данные в заранее определенных измерениях.
Рис. 10
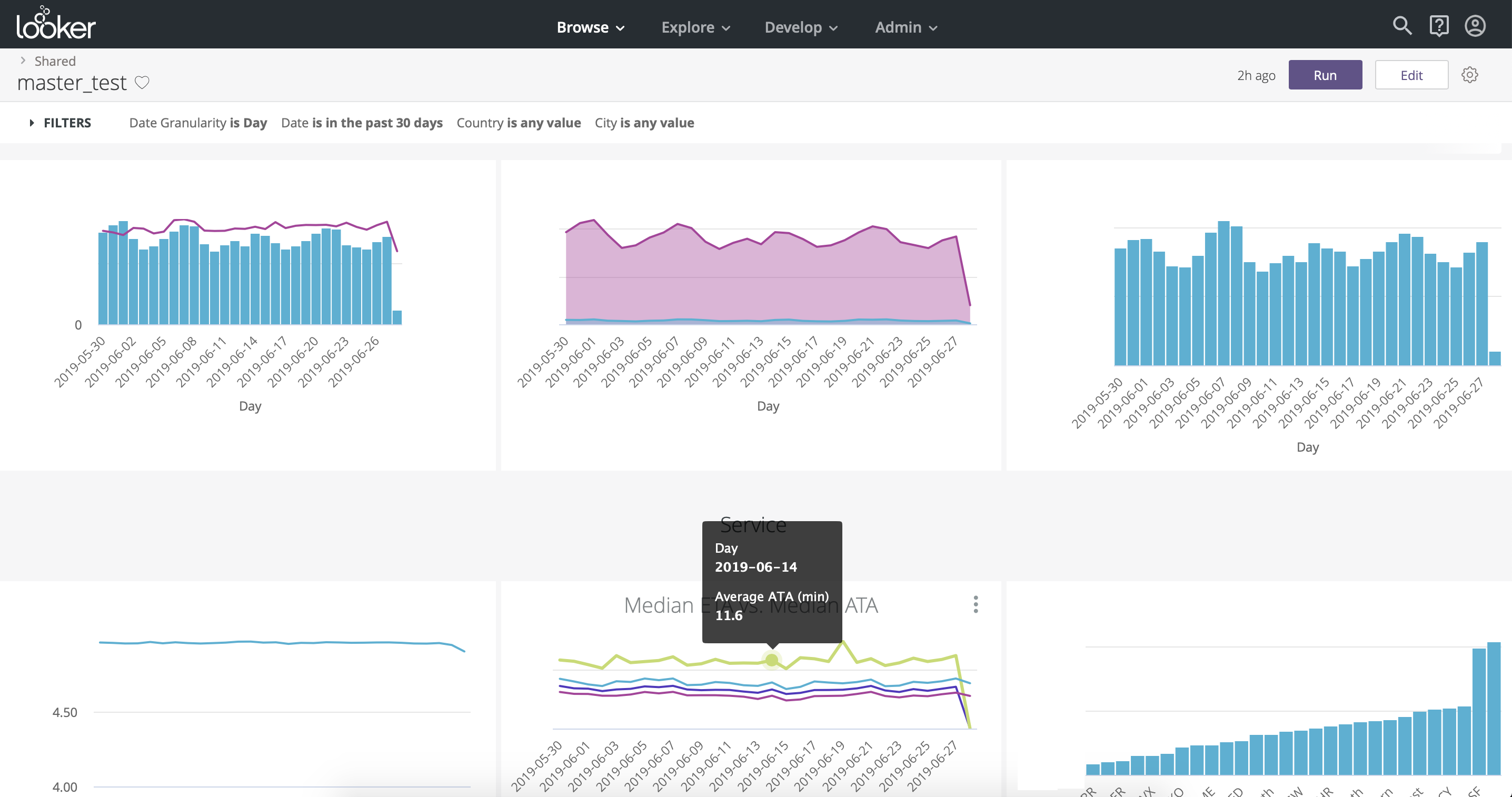
Рис. 11
- Support.
Поддержка со стороны бизнес-консультантов и технических экспертов в Looker, надо сказать удивила — мы могли назначить видеозвонок за полчаса по любому вопросу и получить полноценный ответ. Создается впечатление, что в Looker действительно дорожат клиентами и пытаются упростить им жизнь.
- Statistics.
У Looker есть API — Look API и SDK для Python, с их помощью можно из Python подключиться к Looker и загрузить необходимую информацию, дальше выполнить необходимые преобразования и статистический анализ в Python и загрузить результаты обратно в базу данных с последующим выводом на дашбордах в Looker [ссылка].
- Price.
Looker стоит значительно больше, чем Tableau, для аналогичного набора пользователей Looker вышел почти в 2 раза дороже, чем Tableau — примерно $60,000/год.
- UX + drag&drop.
Periscope
- UX + drag&drop.
Periscope довольно простой в использовании инструмент с ограниченной функциональностью. Здесь тоже есть функция drag&drop, но фильтры к разным чартам придется создавать отдельно, что неудобно (Рис. 12). Для создания чуть более сложных запросов без SQL не обойтись.
Рис. 12
- Data handling.
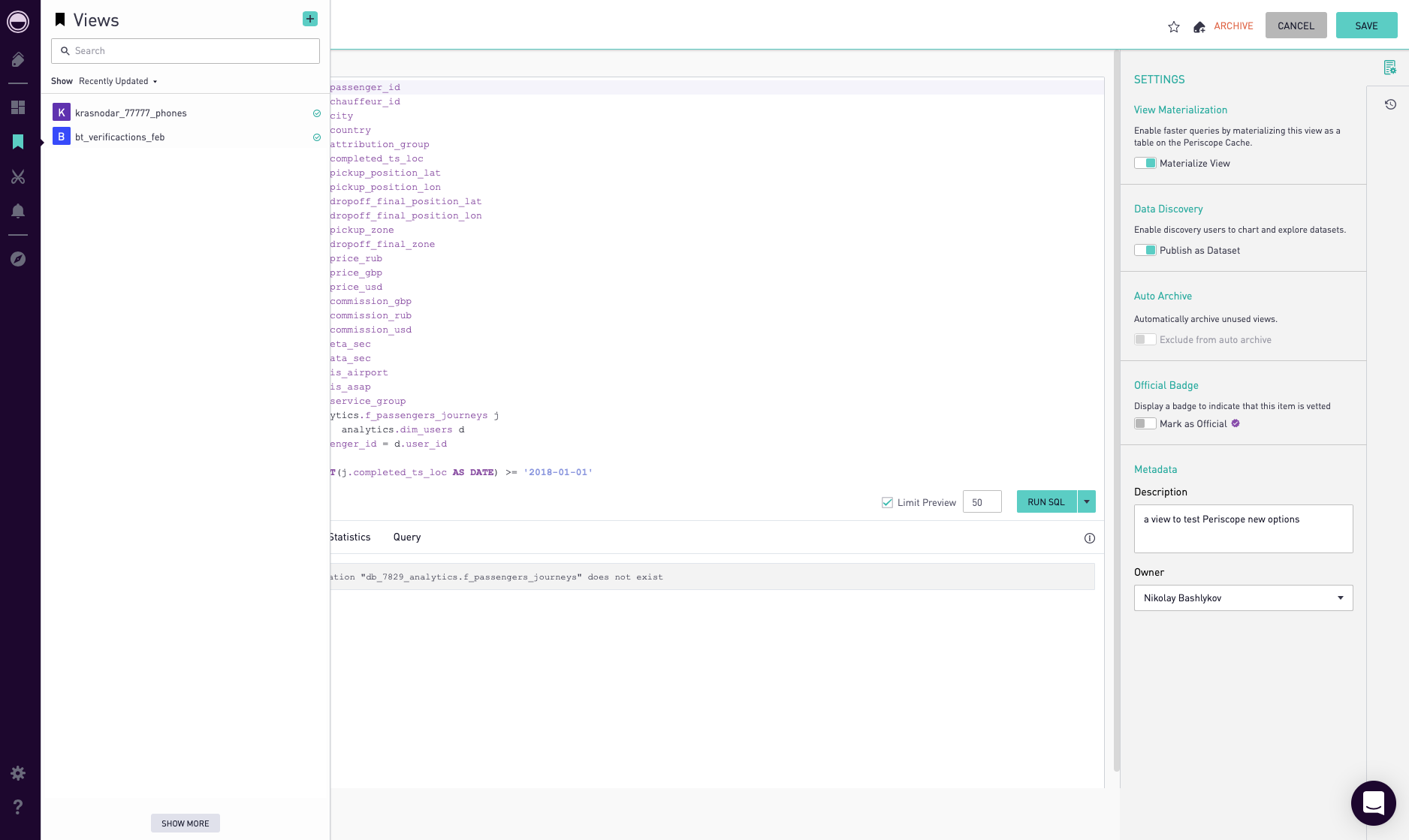
В Periscope есть что-то среднее между OLAP кубами и кэшированием запросов. В нем можно создавать Views и кешировать их. View — это любой SQL-запрос, для его кеширования необходимо нажать кнопку ‘materialize’ в настройках этого View (Рис. 13). Также можно опубликовать ‘publish’ View, чтобы можно было его использовать для целей drag&drop.
Рис. 13
- Workflow.
В Periscope Pro интегрирован version control с использованием git. Также есть возможность посмотреть историю изменения любого дашборда и откатиться на предыдущую версию.
- Visualization.
Набор графиков и чартов весьма ограничен, здесь не найти того многообразия, как в Tableau или Looker.
- Support.
Поддержка довольно оперативная, если сделать поправку, что support-центр работает по Pacific Standard Time. В течение 24 часов ответ вы точно получите.
- Statistics.
У Periscope есть интеграция с Python. Больше деталей можно найти здесь.
- Price.
Periscope Pro будет стоить примерно как Tableau: $35,000.
- UX + drag&drop.
Mode Analytics
- UX + drag&drop.
Mode — самый простой из рассмотренных инструментов. Его ключевым отличием является интегрированность с Python и возможность создавать аналитические отчеты на основе Jupyter Notebook (Рис. 14). Если у вас не выстроен процесс создания аналитических отчетов с использованием Jupyter Notebook, то данный инструмент может быть вам полезен. Mode — скорее дополнение к полноценной BI-системе, его функциональность очень ограничена, для целей создания дашбордов можно использовать таблицы не более 27 тысяч строк, что сильно ограничивает возможности инструмента (Рис. 15). В противном случае, вам необходимо писать отдельные SQL-запросы для каждого графика, чтобы агрегировать данные и получить на выходе таблицу меньшей размерности для визуализации (Рис. 16).
Рис. 14
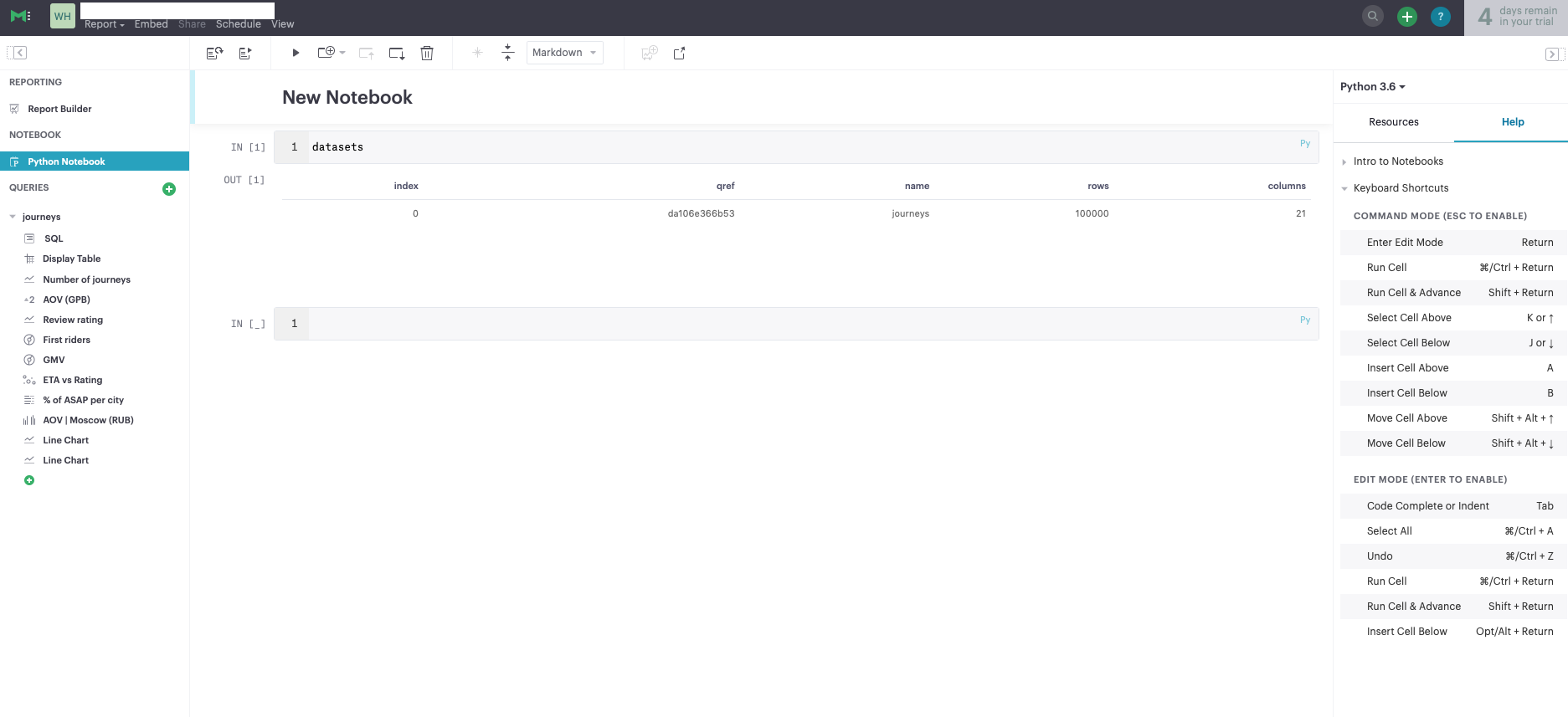
Рис. 15
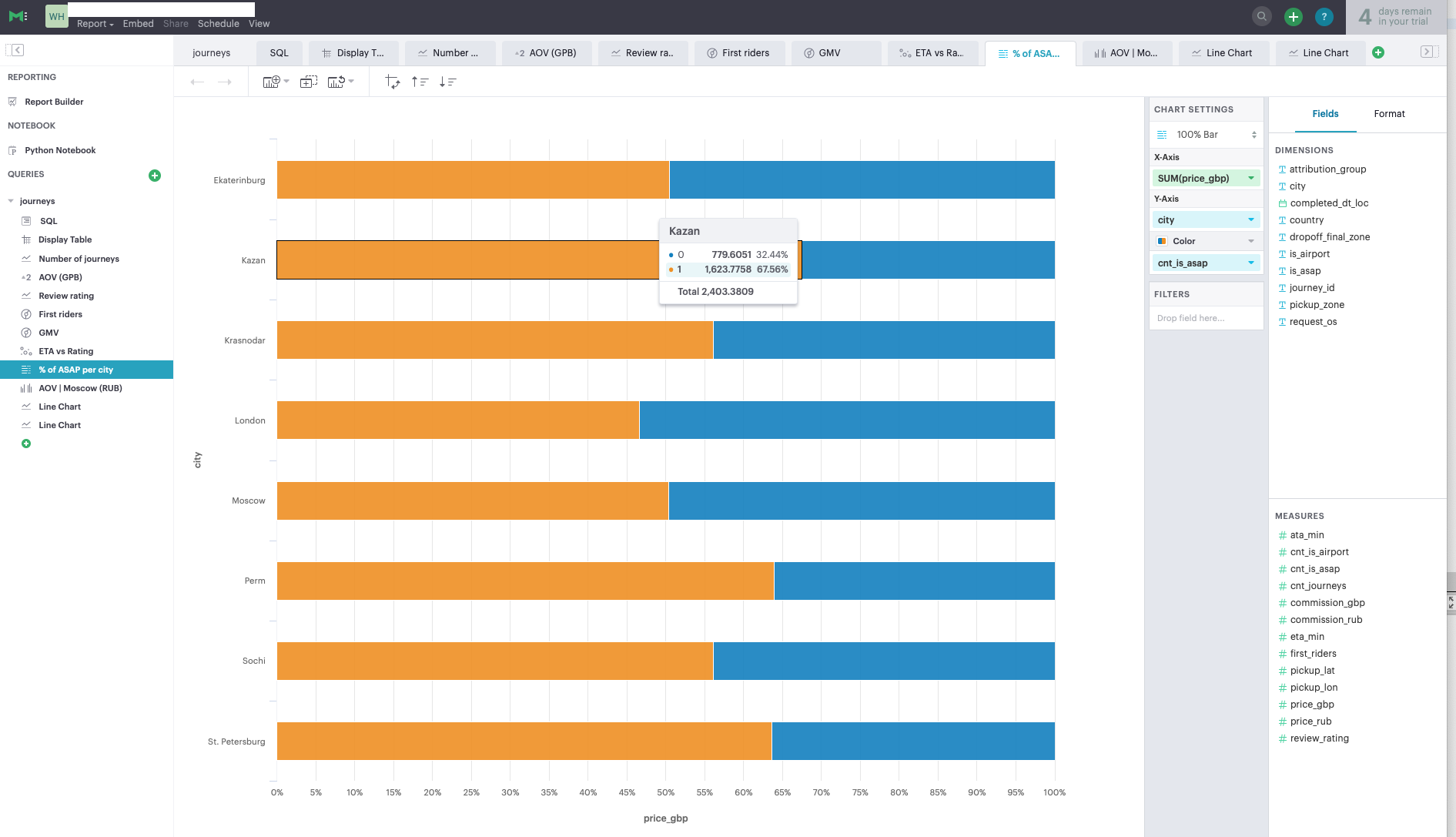
Рис. 16
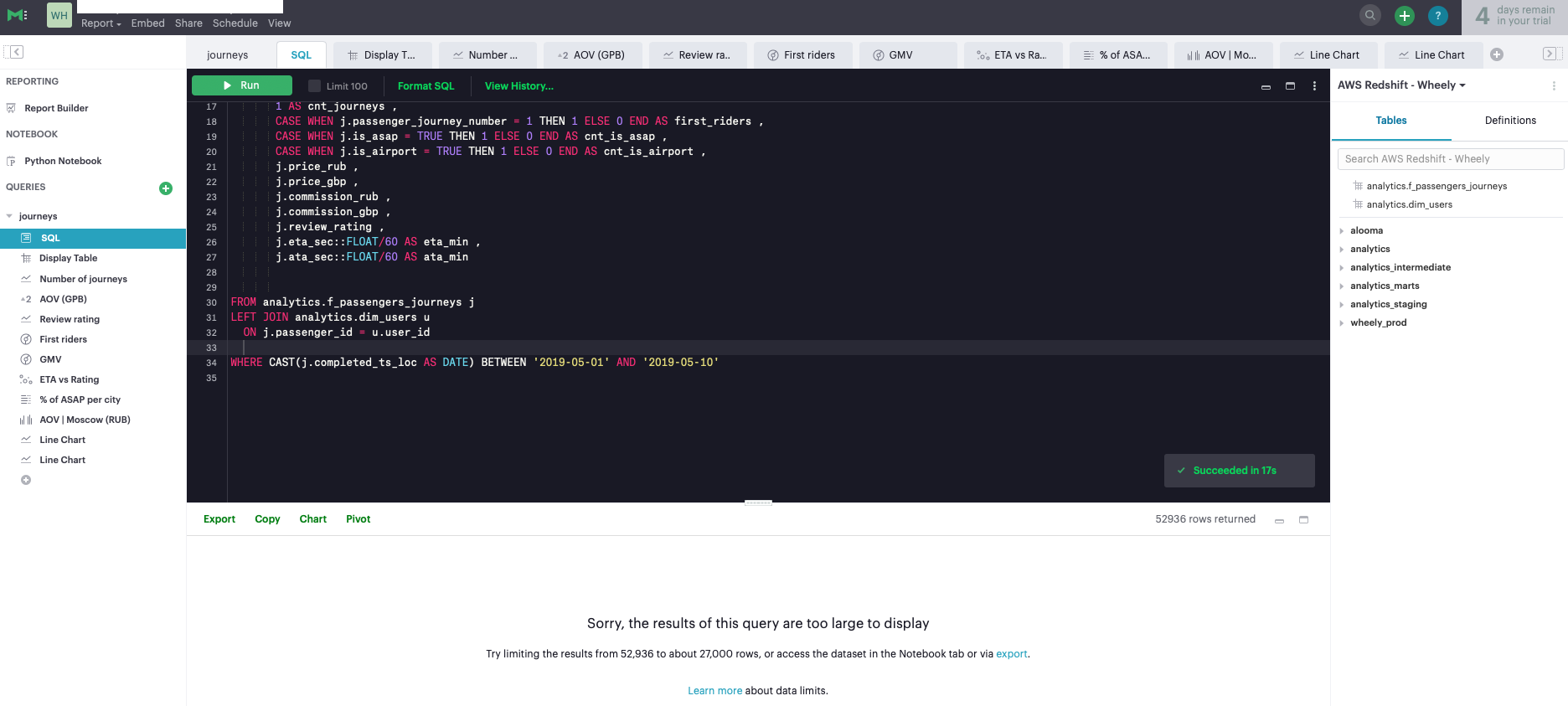
- Data handling.
В Mode как таковой data handling отсутствует. Все запросы делаются напрямую к базе данных, нет возможности кэширования основных таблиц.
- Workflow.
У Mode есть интеграция с Github, больше деталей можно найти здесь.
- Visualization.
Набор визуализаций данных весьма ограничен, есть 6-7 типов графиков.
- Support.
Во время тестового периода поддержка была достаточно оперативна.
- Statistics.
Как уже было сказано, Mode хорошо интегрирован с Python, что позволяет создавать user friendly аналитические отчеты с помощью Jupyter Notebook.
- Price.
Mode, как ни странно, стоит достаточно дорого для своих возможностей — порядка $50,000/год.
- UX + drag&drop.
Выводы
К выбору провайдера BI инструмента необходимо подойти основательно, заручившись поддержкой со стороны бизнес пользователей и определив основные критерии выбора инструмента (желательно, в виде скор карты). Приведенные в данной статье критерии ориентированы в первую очередь на повышение эффективности работы с данными, упрощение процесса извлечения информации, повышения качества визуализации данных и снижение нагрузки на аналитиков.
Источники
- Gartner, Business Intelligence — BI — Gartner IT Glossary
- Kaggle
- Tableau — Hyper
- ZDNet — Salesforce-Tableau, other BI deals flow
- Tableau website
- Looker website
- Periscope website
- Mode analytics website



