
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Сегодня поговорим о NLP-методах векторизации слов - Word Embeddings. Векторы слов лежат в основе многих систем обработки естественного языка и повсеместно используются в современном мире. Рассмотрим работу Word Embeddings на примере нейронной сети Word2Vec.
В более общем смысле Word2Vec удобен для работы с категориальными признаками.
Когда мы говорим о смыслах или о лингвистике, мы имеем дело с сотнями тысяч слов-смыслов. И вот, собственно, Word2Vec и есть та самая современная технология, которая позволяет работать с такими категориальными признаками.
Для демонстрации возможностей технологии Word2Vec введем некую обучающую последовательность данных. Эта последовательность будет в виде расстояния на иерархии isa.
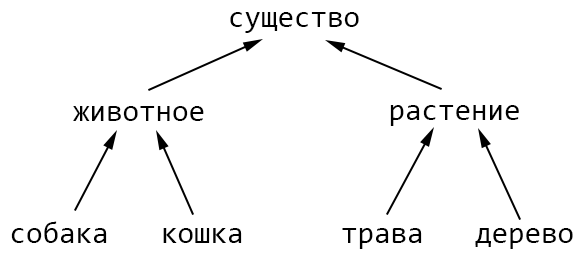
Расстояния между смыслами на графе будем вычислять, считая каждое ребро равное 1. Если нам нужно вычислить расстояние между “собакой” и “травой”, то мы пройдем по графу четыре отрезка, два отрезка вверх и два отрезка вниз. А значит, расстояние между “собакой” и “травой” будет равно четырем.
Расстояние между “собака” и “кошка” равно двум, раз поднялись вверх, и раз спустились вниз.
Чем ближе располагаются объекты на дереве к друг другу, тем ближе они семантически.
dist (собака, животное) = 1
dist (собака, кошка) = 2
dist (собака, существо) = 2
dist (собака, растение) = 3
dist (собака, дерево) = 4Естественно, особой глубины в таком семантическом расстоянии нет, для нас это просто некий удобный пример, на котором мы дальше будем работать.
И, собственно, задача будет очень простая. Мы вычислим на небольшом наборе смыслов все такие расстояния и научим нейронную сеть самостоятельно вычислять эти расстояния. Она ничего не будет знать о нашей семантической сети, просто на вход будем подавать подобные примеры, а на выходе она будет вычислять правильные расстояния.

В качестве обучающих данных у нас будет демонстрационная иерархия на 124 сущности.

Здесь корневым элементом является объект. Объект может быть вещью, существом, местом, веществом или частью. Например, вещь_рукотворная может быть инструментом. Инструмент может быть для работы или музыки. Инструмент для работы - это молоток, отвертка, пила, топор…
Таким образом организована иерархия и вычислены попарно все возможные расстояния на таком дереве. Так, как сущностей 124 штуки, расстояний получается достаточно много (а дальше увидим, сколько их) для того, чтобы вполне успешно тренировать нашу нейронную сеть.
Теперь рассмотрим, в чем, собственно проблема, почему мы говорим о векторизации слов. Дело в том, что нейронная сеть не оперирует собаками и кошками, она оперирует числами. Поэтому с таким входом “собака” - “кошка” нужно что-то делать.
Общее применение технологии Word2Vec - это работа с категориальными признаками. Если у нас есть признаки, значения категорий которых никак не упорядочены, то они требуют обработки.
Чтобы отвлечься от семантики и лингвистики, приведем отвлеченную задачу. Например, нам нужно написать нейронную сеть, которая прогнозирует отношение покупателей к выбору автомобиля. Здесь сразу виден один явный признак - это цена. Помимо него еще будет модель (BMW, Mercedes, Audi) - абсолютно никак не упорядоченные классы машин. И цвет (красный, желтый, зеленый). Вот у нас есть, как минимум, три признака. Один из них числовой, а два категориальных. С ними нужно что-то делать.
От слов всегда можно перейти к числам. В нашем случае имеются слова-смыслы, которые относятся к разным категориям, никак не упорядоченным.
[арфа, дерево, кошка, рояль, собака, трава]Расположим эти слова в трехмерном пространстве.
арфа = {0.1, 0.3, -0.5}
дерево = {-0.1, 0.2, 0.1}
собака = {-2, 1, 0.8}
...В этом трехмерном пространстве “арфа” будет иметь три вещественных числа, которые будут соответствовать ее координатам этом пространстве. “Собака” другие какие-то три числа, а “кошка” - третьи.

Вот такими координатами для каждой сущности мы располагаем эти слова-сущности по многомерному пространству. В таком пространстве, сущности, близкие друг другу по смыслу, будут располагаться рядом. В нашем примере “кошка” и “собака” будут размещены в одной области, “дерево” и “трава” в другой, а “арфа” и “рояль” в третьей.
Эти данные для входа в нейронную сеть уже будут более осмысленными, чем если бы они просто располагались по порядку на линейной прямой. В многомерном пространстве есть возможность группировать и кластеризовать объекты с гораздо большей свободой. Качество обучения сети значительно повысится.
Естественно, возникает вопрос, а как же эти вектора задать. Для этого и применим слой Embedding.
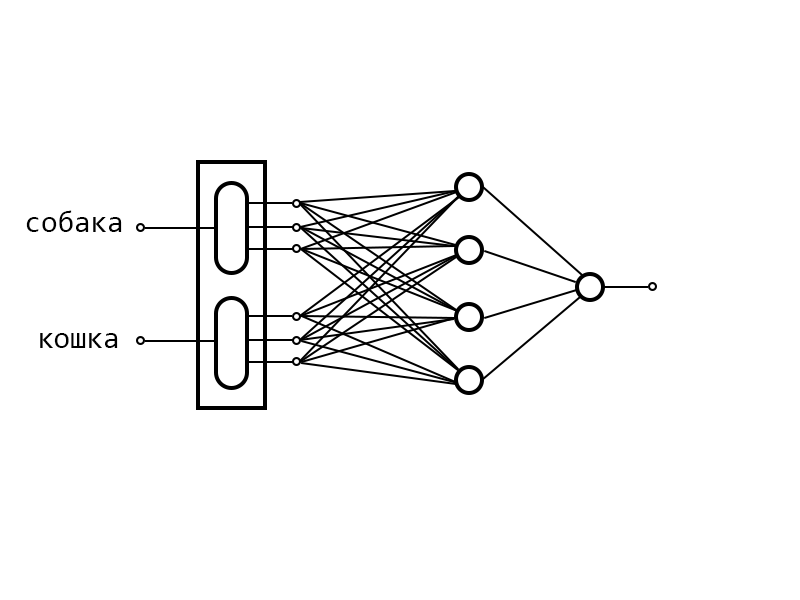
Системе сообщается список всех слов из словаря. Она под каждое слово резервирует вектор некой заранее установленной размерности и заполняет его случайными числами. Хранятся все эти числа в слое Embedding. После этого слоя располагается полносвязная нейронная сеть.
Когда мы начинаем пропускать через эту сеть наши примеры, Embedding извлекает значения компонент из вектора и подает на выход.
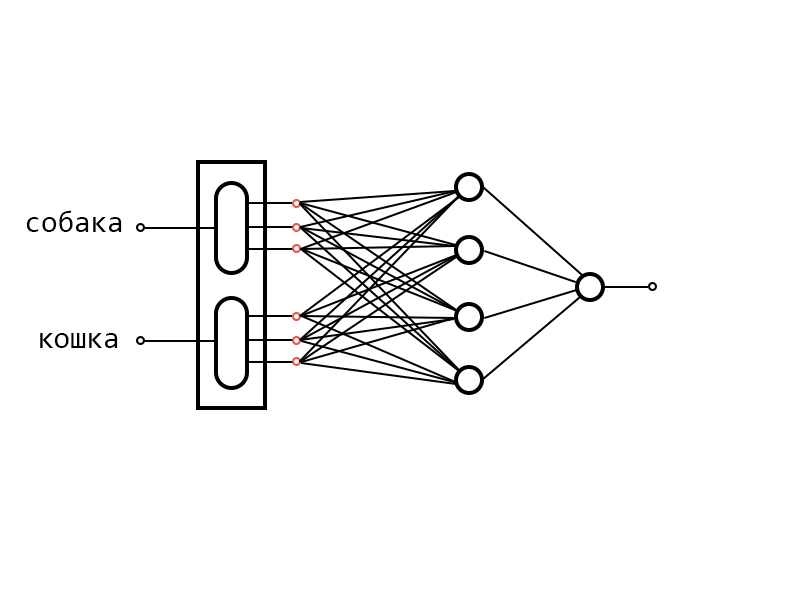
После этого идет прямое распространение, на выходе получаем ошибку и начинается обратное распространение обучения по градиенту, подправляются веса у нейронов и когда нейронная сеть добирается до векторов, которые мы вытащили из памяти, она их тоже подправляет. В нашем примере это “кошка” и собака”. Компоненты этих векторов по градиенту тоже сдвигаются.
Поступает следующий пример и компоненты векторов из этих примеров тоже сдвигаются. Например, подаем теперь на вход “собака” и “свинья”.

Word2Vec. Практика
Теперь перейдем к практике. Применим Word2Vec для отношения isa. Наша задача: научить сеть воспроизводить расстояния между смыслами, вычисленные на дереве отношения isa.
Мы подготовили обучающие данные в виде файла csv, Он сгенерирован на основе дерева из 124 понятий. Приведем для наглядности первые 10 строчек с расстояниями из этого файла. Всего в нем 15376 примеров (124 * 124).

На втором этапе, после загрузки мы должны закодировать эти слова целыми числами. При помощи LabelEncoder из библиотеки sklearn имена смыслов преобразуем в целые числа.
Словарь (смысл, номер) хранится в объекте le.

Создаем экземпляр LabelEncoder, помещаем в него все строки из обоих колонок. Командой fit создаем словарь и упорядочиваем по алфавиту. А с помощью команды transform возвращаем номера.
Создаются новые колонки s1 и s2, где каждой строке соответствует номер. Они приведены в таблице.
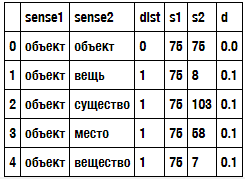
Например, “объект” имеет номер 75, а “вещь” имеет номер 8.
Также вычисляем нормированное расстояние. Для этого поделим расстояние между смыслами на максимальное значение. А максимальное значение равно 10. Это максимальное расстояние на этом дереве. Результаты отображены в колонке d.
Первые три колонки - это исходные колонки наших данных, а колонки s1, s2 и d мы будем использовать непосредственно уже в обучении. Это числовые идентификаторы слов и нормированное расстояние.
Весь наш словарь теперь выглядит так:

Те номера, которые мы видим в таблице, это просто порядковые номера элементов (начиная с нуля) в этом массиве.
Далее разбиваем данные на обучение и валидацию. Выделим 10% для валидационных данных. В результате 13838 примеров будут для обучающих данных и 1538 для валидационных.
Теперь приступим к главной части нашей работы, определяем модель. Для ее определения нам понадобится две константы. Это:
NUM_WORDS - число слов в словаре, и
VEC_DIM - размерность векторного пространства, которую мы хотим получить.
Нейронная сеть реализована в виде простой стопки, через последовательность.

Первый слой - это слой Embedding, о котором мы говорили. Этому слою мы указываем количество слов в словаре, желаемую размерность и сколько входов.
Далее он разворачивается в единую монотонную последовательность вещественных чисел.
И далее идет полносвязная нейронная сеть из двух слоев на 16 и 8 нейронов. На выходе один нейрон с сигмоидом на активационной функции.
Параметры, которые располагаются в слое Embedding, это и есть те компоненты векторов, которые нейронная сеть будет учиться сдвигать в процессе обучения. Ну и естественно, одновременно с ними, смещать веса нейронов в слоях полносвязной нейронной сети.
Обучение модели происходит стандартным образом. Задаем метод для оптимизации, задаем функцию ошибки и запускаем модель на обучение.
После обучения можем посмотреть расстояния между векторами. Для примера на рисунке для неких наборов слов приведены расстояние по косинусу и обычное евклидово расстояние.
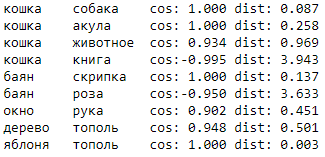
Видно, что пары “кошка” - “собака” и “кошка” - “акула” по косинусу очень близки, но в пространстве реально находятся немного отдаленно друг от друга.
А в паре “кошка” - “книга” вектора направлены в разные стороны, у них отрицательный косинус и расстояние очень большое.
Также можем вычислить ближайший смысл к вектору.
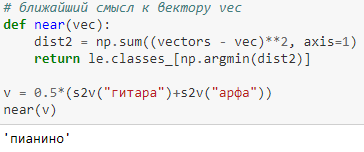
Найдем среднее между “гитара” и “арфа”. В результате получим “пианино”. Обратите внимание, получили не кошку и не собаку. А вот среднее. Рядом с гитарой и арфой находится то, на чем можно играть, а не то, что можно съесть.
Теперь о графическом представлении данного примера.
Конкретно эта задача на пятимерном пространстве имеет ошибку в 5-10 раз меньше, чем на двухмерном пространстве. Но мы намеренно используем двухмерное для наглядности результатов.
Строим график. Точки, соответствующие векторам, располагаем на плоскости. И в эти же точки помещаем метки наших классов, чтобы видеть значения точек.

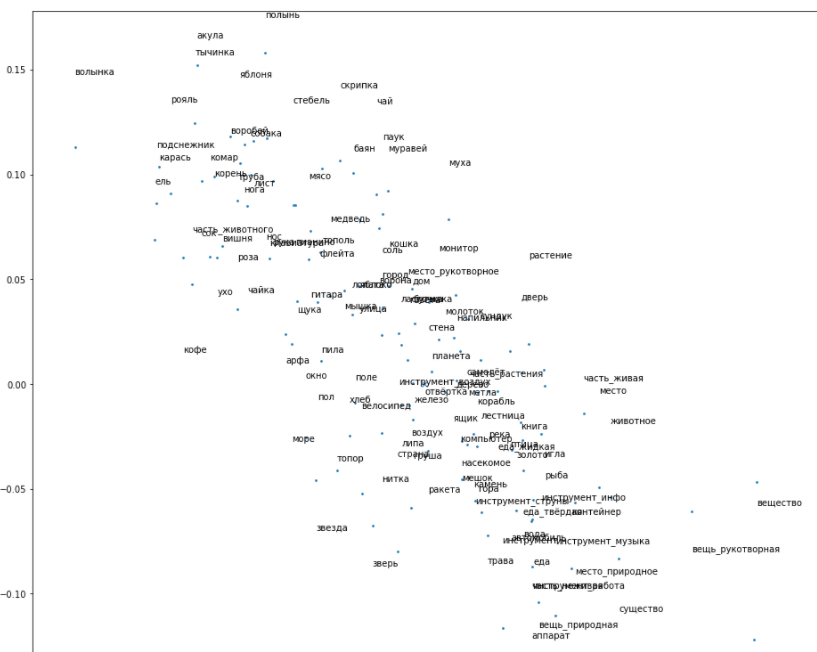
Получилась фантастически интересная вещь. В этом пространстве нейронная сеть по факту геометрически воспроизвела нашу иерархию.
Ссылки:
Весь код можно посмотреть здесь
Полная видео-лекция по теме здесь
Хорошая статья "Word2vec в картинках" на хабре



