
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
В первой части (https://habr.com/ru/post/589893/) мы подобрали коэффициенты (синаптические веса) для определения цифры на 13-ти сегментном индикаторе путем логических рассуждений.
В этой части продолжим постепенный переход от простого к сложному и рассмотрим простой способ автоматического подбора коэффициентов – циклический перебор
Напомним, что имеем дело с задачей классификации.
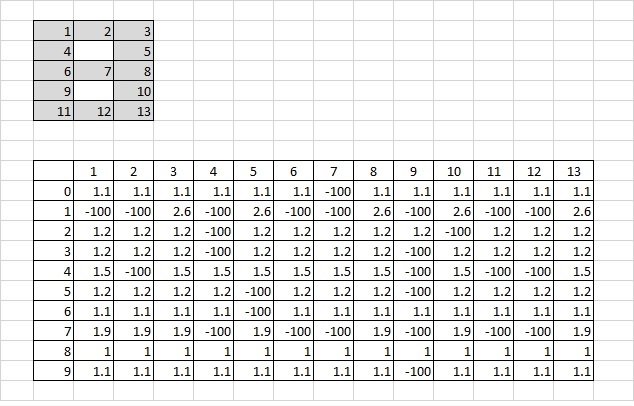
Горят сегменты на 13-ти сегментном индикаторе, нужно определить цифру.

Если сегмент горит, то его значение равно 1, а если не горит, то 0.
Таблица коэффициентов состоит из 10 строк и 13 столбцов.
Строки соответствуют цифрам от 0 до 9, столбцы – номерам сегментов индикатора.
В предыдущих частях описано, как мы заполнили коэффициенты таким образом, чтобы при построчном суммировании перемножений коэффициентов и значений сегментов (1-горит, 0-не горит) максимальная сумма была бы в строке, соответствующей горящей цифре.

Другими словами, умножаем коэффициенты на значения соответствующих сегментов (1 или 0) и складываем получающие значения построчно. В какой строке сумма максимальна, та цифра и горит.
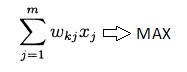
Часть 1: https://habr.com/ru/post/589893/
Часть 2: https://habr.com/ru/post/684978/
Переходим к автоматическому подбору
Начальная позиция
Подбор коэффициентов начинается с выбора начальных позиций.
Теоретически, можно начинать с того, что все коэффициенты равны 1, или все коэффициенты равны 0. В ряде случаев даже возможно все коэффициенты задать совершенно случайным образом. На данном этапе для данной задачи выбор начальной позиции совершенно не принципиален.
Самый простой и логично понятный перебор (алгоритм)
Общий алгоритм перебора коэффициентов был бы следующий:
Устанавливаем начальную позицию, считаем суммы.
Корректируем первый коэффициент, снова считаем суммы.
Корректируем следующий коэффициент и снова считаем суммы.
Последовательно корректируем все коэффициенты, каждый раз считаем суммы.
Доходим до конца и начинаем сначала – корректируем первый коэффициент и заново по кругу…
Возникают вопросы:
1. как понимать, что корректируем в правильную сторону
2. когда заканчивать
В общем случае, задача подбора коэффициентов сводится к задаче оптимизации, то есть когда нужно что-либо минимизировать или что-либо максимизировать.
Обычно максимизируют точность (правдоподобие), а минимизируют ошибку.
Если ошибка уменьшается, то это значит, что коррекции идут в правильном направлении.
Когда показатели ошибки и точности достигают заданных величин - цель достигнута.
Тут нам понадобятся логистическая функция, Softmax и One-Hot-Encoding.
Логистическая функция

График логистической функции похож на букву S.

Логистическая функция удобна тем, что все значения после обработки попадают в интервал от 0 до 1, но сравнительное соотношение не меняется, то есть чем больше аргумент, тем больше значение функции. При этом чем больше аргумент, тем значение функции ближе к 1, а чем меньше аргумент, тем значение функции ближе к нулю. Все значения после обработки как бы загоняются в единый интервал, в котором удобно сравнивать. Сравниваются уже не десятки с сотнями или тысячами, а значения между 0 и 1.
Softmax
Теперь подберем функцию таким образом, чтобы сумма значений, которые мы сравниваем, стала бы равняться 1.
Такая функция была подобрана и получила название Softmax.
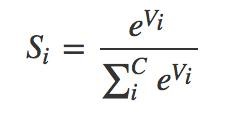
Softmax – очень распространенная функция для решения задач классификации.
Является как бы смысловым обобщением логистической функции.
Формально Softmax представляет собой отношение индекса текущего элемента к сумме индексов всех элементов (в другой формулировке - нормализует значения в вектор, следующий распределению вероятности). В определенной трактовке, Softmax преобразует значения в относительные вероятности, которые легче понимать и сравнивать. То есть так как все значения находятся между 0 и 1 и при этом сумма значений равна 1, то мы можем трактовать значения как вероятности.

Можно трактовать так: вероятность того, что мы имеем дело с первым классом, составляет 46%, со вторым классом – 34%, а с третьим – 20%. Видно, что чем больше аргумент, то тем больше вероятность. Если раньше мы сравнивали просто числа, то теперь мы сравниваем вероятности. Поначалу это кажется довольно необычным, а по мере привыкания становится даже очень простым.
Вернемся к таблице.
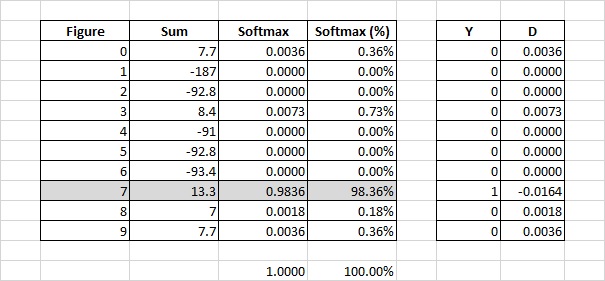
Посчитаем построчно суммы для какой-нибудь цифры с учетом текущих коэффициентов, а затем преобразуем значения сумм в каждой строке через Softmax.

Если раньше сравнивали непосредственно значения, например, 8.4 (цифра 3) и 13.3 (цифра 7) и искали максимальное, то теперь сравниваем 0.0073 (цифра 3) и 0.9836 (цифра 7). И также ищем максимальное, логика не поменялась, но теперь несколько иначе трактуем. Теперь говорим, что вероятность того, что это цифра 3 – 0,73%, а вероятность того, что это цифра 7 – 98,36%, и выбираем цифру по максимальной вероятности.
Отметим, что на этапе подбора коэффициентов мы знаем правильный ответ. Нам остается только сравнить мнение модели с правильным ответом, а для этого привести мнение модели и правильный ответ к единому формату.
One-Hot-Encoding
Обычно мы воспринимаем цифры как 0, 1, 2, 3, 4, 5, 6, 7, 8, 9.
Видоизменим их в массив длиной 10 (или 10-мерный вектор), состоящий из 0 и 1 так, чтобы индекс, имеющий значение 1, соответствовал цифре в привычном понимании.
0: Y = [1,0,0,0,0,0,0,0,0,0]
1: Y = [0,1,0,0,0,0,0,0,0,0]
2: Y = [0,0,1,0,0,0,0,0,0,0]
3: Y = [0,0,0,1,0,0,0,0,0,0].
4: Y = [0,0,0,0,1,0,0,0,0,0]
5: Y = [0,0,0,0,0,1,0,0,0,0]
6: Y = [0,0,0,0,0,0,1,0,0,0]
7: Y = [0,0,0,0,0,0,0,1,0,0]
8: Y = [0,0,0,0,0,0,0,0,1,0]
9: Y = [0,0,0,0,0,0,0,0,0,9]
Если мы возьмем, например, цифру 7 в таком коде, то в терминах предыдущего параграфа мы можем трактовать так: «Это цифра 7 с вероятностью 100%.
Теперь у нас есть два массива одинакового формата или два вектора одинаковой размерности, мы можем их сравнить и посчитать, насколько модель «ошиблась».
Под ошибкой будем понимать разницу между фактическим выходным значением и правильным ответом. Прогноз модели, что вероятность цифры 3 равна 0.0073, означает, что ошибка равна 0.0073. Предположение, что вероятность цифры 7 равна 0.9836 означает, что ошибка равна -0.0164.
Общая квадратическая ошибка
Общая квадратическая ошибка – сумма квадратов ошибок по каждой цифре и по каждой строке. Эту общую ошибку квадратическую ошибку и будем минимизировать.

Формулы подробнее
Ошибка в каждой строке: D = Softmax(Sum) - Y
Для каждой цифры f и строки i:
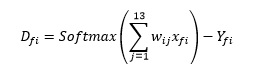
Ошибки могут иметь разные знаки, поэтому работаем с квадратами ошибок.
Суммируем квадраты ошибок для каждой цифры по каждой строке
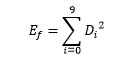
и затем суммируем получившиеся суммы квадратов ошибок по каждой цифре.

Таким образом получаем общую квадратическую ошибку модели при данном наборе коэффициентов.
Необходимо отметить, что часто величину ошибки усредняют, то есть делят на количество элементов, но так как количество элементов в данном случае величина постоянная, то на процесс оптимизации это никак не влияет. То есть можно использовать как общую квадратическую ошибку, так и среднюю.
Примечание:
Другие используемые термины для обозначения функции ошибки – функция оценки, функция потерь, эмпирический риск (кому как больше нравится).
Минимизация ошибки
Перейдем к перебору и минимизации ошибки
Зададим начальные веса, все равны 0:
K_array = np.zeros([10, 13])Зададим матрицу значений сегментов индикаторов:
X = np.array([
[1,1,1,1,1,1,0,1,1,1,1,1,1],
[0,0,1,0,1,0,0,1,0,1,0,0,1],
[1,1,1,0,1,1,1,1,1,0,1,1,1],
[1,1,1,0,1,1,1,1,0,1,1,1,1],
[1,0,1,1,1,1,1,1,0,1,0,0,1],
[1,1,1,1,0,1,1,1,0,1,1,1,1],
[1,1,1,1,0,1,1,1,1,1,1,1,1],
[1,1,1,0,1,0,0,1,0,1,0,0,1],
[1,1,1,1,1,1,1,1,1,1,1,1,1],
[1,1,1,1,1,1,1,1,0,1,1,1,1]
])Зададим массив правильных ответов:
Y = [0,1,2,3,4,5,6,7,8,9]Преобразуем правильные ответы в нужный формат (One-Hot-Encoding):
#One-Hot_Encoding
Y_cat = np.zeros([10, 10])
for k in range(10): Y_cat[k][k]=1
# В Pythor есть специальная функция. Результат Идентичный.
# import tensorflow.keras
# Y_cat = tensorflow.keras.utils.to_categorical(Y, 10)Зададим функцию Softmax:
def softmax(scores):
softmax = np.exp(scores) / np.sum(np.exp(scores))
return softmax
# В Pythor есть специальная функция. Результат Идентичный.
# from scipy.special import softmaxЗададим функцию подсчета общей квадратической ошибки:
def E():
array = np.zeros(10)
Ef = np.zeros(10)
Esum = 0
for n in range(10):
for i in range(10):
array[i] = np.dot(X[n].T, K_array[i]) # умножаем вектор X на коэффиценты в строке
array_soft = softmax(array) # преобразуем через softmax
for k in range (10):
Ef[n] += (array_soft[k]-Y_cat[n][k])**2 # суммируем квадраты ошибок в строкам
Esum += Ef[n] # суммируем квадратические ошибки по каждой цифре
return EsumЗададим функцию коррекции коэффициента:
def choice():
this_array = np.zeros(3)
this_array[0] = E()
K_array[n][k] = np.round(K_array[n][k] + lmd,2)
this_array[1] = E()
K_array[n][k] = np.round(K_array[n][k] - 2*lmd,2)
this_array[2] = E()
min = np.argmin(this_array)
if min == 0: K_array[n][k] = np.round(K_array[n][k] + lmd,2)
if min == 1: K_array[n][k] = np.round(K_array[n][k] + 2*lmd,2)
return this_arrayЗдесь нужно отдельно пояснить.
Считаем общую квадратическую ошибку для трех вариантов:
· для текущего состояния коэффициента
· если к коэффициенту прибавить шаг lmd
· если у коэффициента вычесть шаг lmd
При каком варианте общая квадратическая ошибка минимальна, такой коэффициент и устанавливаем.
Зададим функция подсчета точности:
def correct_count():
correct = 0
for n in range(10):
array = np.zeros(10)
for k in range(10):
array[k] = np.dot(X[n].T, K_array[k]) # перемножение по каждой цифре
array_soft = softmax(array)
if np.argmax(array_soft) == Y[n]:
correct += 1
return correct/10 Зададим шаг изменения и количество полных проходов таблицы
lmd = 0.1
epochs = 10И запускаем цикл перебора коэффициентов
for N_epochs in range(epochs):
for n in range(10):
for k in range(13):
choice() # изменяем коэффициенты
E_saved = E() # запоминаем E
loss[N_epochs*10+n] = E_saved
accuracy[N_epochs*10+n] = correct_count() Результат
На выходе получаем массив коэффициентов:
(выведено в блоке для удобства восприятия по столбцам)
[[ 0.2 0.6 -0.9 1. 1. -0.4 -1. -0.4 1. 0.5 0.6 0.4 -0.9]
[-1. -1. 1. -1. 1. -1. -1. 0.6 -1. 0.5 -1. -1. 0.5]
[ 0.6 0.5 -0.6 -1. 1. 0.2 1. -1. 1. -1. 0.6 0.3 -0.6]
[ 0.1 0.9 -0.9 -1. 1. 0.7 0.9 -1. -1. 1. 0.6 0.4 -1. ]
[ 0.8 -1. 0.3 1. 0.6 0.6 0.8 -1. -1. -0.2 -1. -1. 0.5]
[ 0.2 0.6 -0.6 1. -1. 0.5 0.7 -0.9 -1. 0.9 0.6 0.3 -0.7]
[ 0.1 0.7 -0.7 1. -1. 0.2 1. -0.8 1. 0.3 0.2 0.2 -0.6]
[ 1. 1. -0.3 -1. 0.8 -1. -1. 0.4 -1. 0.5 -1. -1. 0.2]
[-0.6 0.8 -0.9 1. 1. -0.3 1. -1. 1. 0.7 0.3 0.2 -0.9]
[-0.6 0.7 -0.9 1. 1. 0. 0.9 -1. -1. 0.8 0.7 0.6 -0.8]]Можно посмотреть, как менялись величины точности и ошибки по мере прохождения перебора.
Начальная ошибка: 9.000000000000002
Начальная точность: 0.1
0: loss: 8.256888108456812 accuracy: 0.8
1: loss: 7.4035437200249845 accuracy: 0.8
2: loss: 6.515313270760133 accuracy: 0.8
3: loss: 5.655615573184693 accuracy: 0.8
4: loss: 4.889748309748125 accuracy: 0.9
5: loss: 4.243067834925036 accuracy: 0.9
6: loss: 3.6863744601447674 accuracy: 1.0
7: loss: 3.1957574183834616 accuracy: 1.0
8: loss: 2.7718738867787973 accuracy: 1.0
9: loss: 2.4043407365354073 accuracy: 1.0
Конечная ошибка: 2.4043407365354073
Конечная точность: 1.0
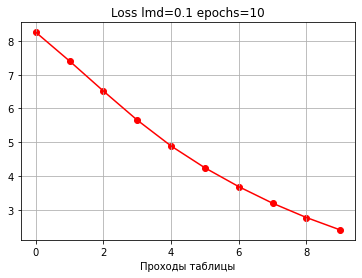
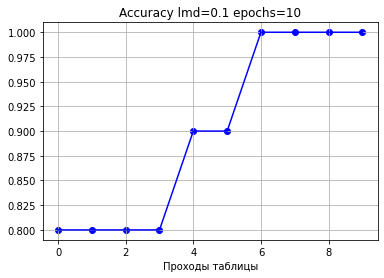
Видим, что с каждым проходом ошибка уменьшается, а точность растет.
Необходимо отметить, что даже если при изменении каждого коэффициента ошибка уменьшается, то точность не всегда растет. Встречаются случаи, когда ошибка уменьшилась, а точность тоже уменьшилась.
То есть надо понимать, что точность увеличивается как бы косвенно по мере уменьшения ошибки, поэтому недостаточно замерять только величину ошибки, надо смотреть именно на точность, то есть на тот показатель, который нам важен в конечном итоге.


Проверка, что все цифры определяются правильно
Можем запустить цикл и принудительно проверить, что все цифры определяются правильно.
# посмотрим результат
correct = 0
for n in range(10):
array = np.zeros(10)
for k in range(10):
array[k] = np.dot(X[n].T, K_array[k]) # перемножение по каждой цифре
array_soft = softmax(array)
if np.argmax(array_soft) == Y[n]: # сравниваем полученное и ожидаемое
correct += 1
print(array_soft)
print('Индекс:', np.argmax(array_soft))
print('Ожидаемая цифра:', Y[n])
print()
print('Точность:', correct/10)[9.93284557e-01 3.84798202e-21 4.11213620e-08 5.56517117e-09 9.29478238e-14 5.56517117e-09 1.65895415e-05 6.26277511e-16 6.69269870e-03 6.10295124e-06]
Индекс: 0
Ожидаемая цифра: 0
[5.60279149e-09 9.99999117e-01 9.35761471e-14 2.06115180e-09 8.31527985e-07 1.26641544e-14 1.71390692e-15 4.13993406e-08 1.02618706e-10 2.06115180e-09]
Индекс: 1
Ожидаемая цифра: 1
[8.31422839e-07 5.24221807e-22 9.99872668e-01 8.31422839e-07 6.30431392e-16 3.77465385e-11 2.26004159e-06 1.15467537e-17 1.23394090e-04 1.52280405e-08]
Индекс: 2
Ожидаемая цифра: 2
[3.03734831e-07 4.21825229e-18 1.65833599e-05 9.92914440e-01 1.01891685e-10 4.50782458e-05 3.03734831e-07 5.07288827e-12 3.33085687e-04 6.69020487e-03]
Индекс: 3
Ожидаемая цифра: 3
[1.02617070e-10 4.65880777e-15 1.26639525e-14 2.06111895e-09 9.99983178e-01 5.60270219e-09 1.02617070e-10 4.65880777e-15 1.12533282e-07 1.67014198e-05]
Индекс: 4
Ожидаемая цифра: 4
[3.01734769e-07 2.34783814e-26 1.36987373e-11 3.01734769e-07 1.01220739e-10 9.86376203e-01 6.64615058e-03 3.09636588e-17 3.30892353e-04 6.64615058e-03]
Индекс: 5
Ожидаемая цифра: 5
[4.50789195e-05 1.59247079e-28 2.04657978e-09 1.01893207e-10 3.41813631e-14 3.33090665e-04 9.92929279e-01 1.04561583e-20 6.69030486e-03 2.24434725e-06]
Индекс: 6
Ожидаемая цифра: 6
[1.52299775e-08 5.60279562e-09 1.87952854e-12 4.13993712e-08 4.13993712e-08 6.91439910e-13 4.65888547e-15 9.99999855e-01 2.78946769e-10 4.13993712e-08]
Индекс: 7
Ожидаемая цифра: 7
[6.63207336e-03 6.98398269e-23 6.04766809e-06 8.18462874e-07 1.36697220e-11 2.22481276e-06 6.63207336e-03 4.18159969e-18 9.84286959e-01 2.43980344e-03]
Индекс: 8
Ожидаемая цифра: 8
[6.09546333e-06 1.41385664e-21 5.55834308e-09 3.32801021e-04 5.55834308e-09 9.04646969e-04 6.09546333e-06 1.70031005e-15 6.68448720e-03 9.92065863e-01]
Индекс: 9
Ожидаемая цифра: 9
Точность: 1.0
Видим, что модель абсолютно корректно определяет цифры при заданном наборе сегментов.
Дополнение
Следует отметить, что первоначально шаг lmd=0.1 и количество проходов epochs=10 мы взяли наугад, как наиболее часто встречающиеся. И в данном случае 10 проходов хватило, чтобы достичь точности определения в 100%.
Если мы возьмем 50 проходов, то видим, что величина ошибки будет продолжать понижаться, хотя точность уже повышаться не будет, так как некуда.
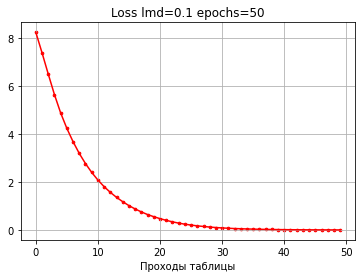
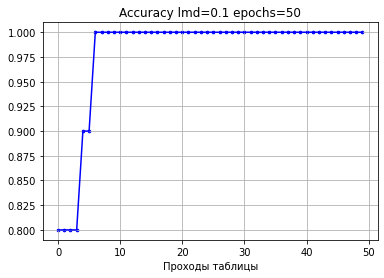
Для сравнительной демонстрации возьмем 10 проходов с шагом 1.
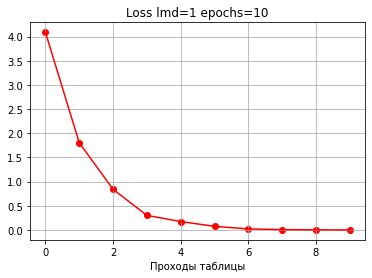
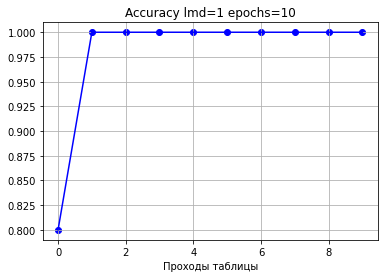
Видим, что ошибка уменьшается быстрее и точность растет быстрее, чем при шаге 1.
Уже после 2 проходов по таблице точность 100%.
И получили совсем другие коэффициенты:
[[ 0. 0. 0. 1. 0. -1. -10. 4. 3. 0. 0. 0. 0.]
[-10. -10. 10. -10. 8. -10. -9. 5. -7. 0. -8. -8. 0.]
[ 2. 0. 0. -10. 3. 0. 0. 0. 3. -10. 2. 0. 0.]
[ 2. 0. 0. -10. 4. 2. 0. -2. -10. 2. 1. 0. -1.]
[ 6. -10. 4. 2. 1. 0. 0. 0. -10. 0. -10. -10. 4.]
[ 2. 1. 0. 1. -10. 3. 1. -1. -10. 2. 0. 0. 0.]
[ 0. 0. 0. 1. -10. 3. 1. 0. 3. -1. 0. 0. 0.]
[ 8. 8. -2. -10. 1. -10. -10. 4. -10. 1. -10. -10. 2.]
[ 0. 0. 0. 1. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[ 2. 0. 0. 3. 2. -3. 1. 0. -10. 1. 0. 0. 0.]]Видим, что модель самостоятельно поставила большой отрицательный коэффициент (-10) похожим образом, где мы также закладывали большой минус (-100).
Итак, модель абсолютно корректно определяет цифры при заданном наборе сегментов.
Отметим, что здесь мы только начинали прицеливаться и брали шаг изменения и количество переборов практически наугад, примерно. При дальнейших улучшениях в программу можно установить параметры прекращения перебора. Например, чтобы программа прекращала перебор при достижении заданной величины точности или заданной величины ошибки.
Также можно добавить условия, что если ошибка не уменьшается заданное количество переходов, то увеличивать или уменьшать шаг изменения.
И конечно, сейчас у нас была простая задача - мало параметров.
В действительных проектах параметров сильно больше, и простой перебор будет вычисляться очень долго. Для ускорения расчетов применяются различные оптимизирующие алгоритмы, но уже на этом примере видно, как в принципе модель обучается - подбирает параметры..
Часть 1: https://habr.com/ru/post/589893/
Часть 2: https://habr.com/ru/post/684978/
Google Colab Resarch:
https://colab.research.google.com/drive/1wa3ha23-sX7tupHIntVG0hPXcaqJ-nR3#scrollTo=IEh3IEyC4Xiq
")

")
