
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Герои статьи для себя сделали иллюстрацию
Последние несколько месяцев оказались богаты на новости о системах искусственного интеллекта. Тематические площадки и видеохостинги заполнены контентом про ChatGPT и Midjourney; разработчики делятся примерами кода, созданного ИИ-помощником Copilot.
Да, результаты варьируются от случая к случаю, но волны хайпа оказалось достаточно, чтобы на проекты обратили внимание корпорации. Так, в Google беспокоятся, что новые языковые модели пошатнут их положение на рынке, а Microsoft планирует инвестировать $10 млрд в компанию-разработчика ChatGPT.
Новые нейросети уже находят применение в программных проектах. Их встраивают в текстовые редакторы, браузеры, облачные платформы. Но какой бы ни была модель машинного обучения, работа с ней требует вычислительных ресурсов. Поддержка таких решений может обходиться в сотни тысяч долларов ежедневно.
И в этом ключе интересно сместить акцент на более доступные «туманные вычисления».
«Туманные вычисления» — разновидность облачных вычислений, когда обработка данных происходит не в едином дата-центре, а в распределенной сети устройств. По оценкам Market Research Future, к 2030 году объем рынка fog computing должен достигнуть планки в $343 млн. Неудивительно, что появляются решения, позволяющие развернуть модели машинного обучения (МО) в формате p2p.
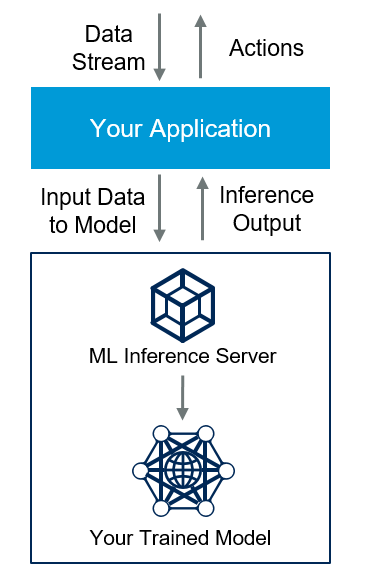
На схеме выше представлено, как обычно работает сервер для инференса моделей машинного обучения (под инференсом имеется в виду непрерывная работа какой-либо нейронной сети на конечном устройстве). Пользователи могут предоставлять друг другу ресурсы для обучения моделей МО и инференса в формате торрентов.
Иногда пользователи делятся ресурсами на благотворительных началах с целью помочь сообществу, но чаще получают разного рода бонусы и преференции. Например, ускорение вычислений и запуск моделей машинного обучения вне очереди. Многие p2p-платформы построены на базе блокчейнов, поэтому предлагают хостам вознаграждение в виде токенов.
Запуск языковых моделей в формате BitTorrent

Примером платформы, которая позволяет развернуть модель МО в формате p2p, может быть Petals. Это — open source проект для генерации текста, построенный на языковой модели BLOOM-176B. BLOOM насчитывает 176 миллиардов переменных, которые определяют, как входные данные преобразуются в желаемый результат. По этому показателю модель опередила GPT-3.
BLOOM (BigScience Large Open-science Open-access Multilingual Language Model) представляет собой авторегрессивную большую языковую модель (LLM, Large Language Models). Она умеет продолжать тексты на основе затравки — на сорока шести языках и тринадцати языках программирования. В отличие от таких известных LLM, как GPT-3 от OpenAI и LaMDA от Google, BLOOM поддерживается добровольцами и финансируется французским правительством.
Пользователи Petals загружают небольшую часть модели, а затем объединяются с людьми, обслуживающими другие части, для инференса или тонкой настройки. Инференс выполняется со скоростью ≈ 1 сек на шаг (токен), что достаточно для чат-ботов и других интерактивных приложений.
Можно ли так делать с Midjourney? Вероятно, нет. OpenAI, вопреки изначальным целям открыто работать на благо обществу, всё больше уходит в коммерческую деятельность. Однако в теории можно попробовать запустить децентрализованный проект подобно Folding@home со Stable diffusion (модель с открытыми исходниками).
Децентрализованные решения для машинного обучения

Еще одним проектом в этой сфере является PyGrid. Он ориентирован на дата-сайентистов и заточен под федеративное машинное обучение. В этом случае ML-модели обучаются на периферийных устройствах или серверах, работающих с локальными выборками данных.
В основе инструмента лежит библиотека PySyft. По сути, она представляет собой обертку PyTorch, Tensorflow или Keras. Структурно PyGrid содержит три компонента: Network — сетевое приложение для мониторинга и маршрутизации инструкций, Domain — приложение для хранения данных и моделей федеративного обучения и Worker — набор инстансов для вычислений.
Развиваются не только проекты для децентрализованного инференса, но и решения для распределенного обучения. Примером может быть приложение iChain, предложенное группой американских инженеров. В его основу положена технология блокчейна.
С точки зрения пользователя все довольно просто: нужно загрузить файл для МО в выделенную директорию. Далее, пользователь создает запрос на обработку и выбирает провайдера вычислительных ресурсов, а также валидатора. Последний оценивает готовый файл и передает его пользователю. С точки зрения поставщика мощностей, все еще проще — они регистрируются в сети, запускают приложение, получают задачи на обработку и вознаграждение в виде токенов.
Пользователи приложения iChain могут платить владельцам мощностей за выполнение задач машинного обучения и не переплачивать за собственные компьютеры. Приложение использует блокчейн Ethereum, который обеспечивает безопасность и децентрализацию, а также предоставляет платформу для платежных операций.
Каждому по потребностям

Stable Horde — это краудсорсинговый проект, который объединяет доброврольцев с целью создания изображений на базе Stable Diffusion. Вы «отдаете» свою видеокарту, ставите клиент, и можете бесплатно генерировать контент на «чужих» GPU.
Дополнительно, после регистрации, можно голосовать за лучшие сгенерированные изображения, и зарабатывать рейтинг, который влияет на скорость обработки ваших задач.
Другим примером может быть библиотека Hivemind, который, к слову, использует уже упомянутый Petals. Она заточена под тренировку крупных моделей на сотнях компьютеров, которые предоставляют университеты, компании и волонтеры.
Проблемы и решения для ИИ
Децентрализованные платформы могут стать недорогой, если не полностью бесплатной, альтернативой платным сервисам по генерации текста, кода и изображений.
Разумеется, у p2p платформ для обучения ML-моделей есть некоторые ограничения. Одно из них связано с информационной безопасностью. Данные модели обрабатывают десятки и сотни пользовательских устройств. Гарантировать безопасность в таких условиях сложно, поэтому распределённые платформы плохо подходят для работы с бизнес-критической или персональной информацией.
В целом можно принять меры предосторожности — зашифровать данные и использовать аналогичные механизмы шифрования для их передачи — но есть и обратная сторона медали. Сами хосты принимают чужие данные и код, поэтому берут на себя определённые риски, способные поставить их систему под удар.
Решением может быть контейнеризация — приложение помещается в контейнер, прежде чем поступить на обработку, а затем запускается в «песочнице». Даже если там будет потенциально зловредный код, у него будет меньше шансов навредить вычислительной системе хоста. Тут можно вспомнить про Kubernetes как сервис, в котором весь management plane остается в зоне ответственности облачного провайдера, что гораздо безопаснее.
Помимо политик управления данными и конфиденциальностью, стоит обратить внимание на способность алгоритмов генерировать «токсичный» контент. В p2p-среде контролировать такое поведение гораздо сложнее, по сравнению с централизованным форматом. Соответствующий дисклеймер есть даже в репозитории Petals. В остальном все зависит от разработчиков моделей машинного обучения.
Больше информации об инструментах для разработчиков
- Зачем компаниям и разработчикам базы данных в облаке: инструкция по применению
- Как прокачать разработку с помощью облачных технологий
- Лонгрид по полезному чтению в 2023 году: 39 книг, которые помогут писать красивый <код>



