
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Всем привет! После весьма продолжительного периода мы, наконец, подготовили новый релиз SiteAnalyzer, который, надеемся, оправдает ваши ожидания и станет незаменимым помощником в SEO-продвижении.

В новой версии мы реализовали несколько из наиболее востребованных пользователями функций, таких, как: скрейпинг данных (извлечение данных с сайта), проверка уникальности контента и проверка скорости загрузки страниц по Google PageSpeed. Вместе с этим было закрыто множество багов и проведен рестайлинг логотипа. Расскажем обо всем поподробнее.
Основные изменения
1. Скрейпинг данных с помощью XPath, CSS, XQuery, RegEx.
Веб-скрейпинг – это автоматизированный процесс извлечения данных с интересующих страниц сайта по определенным правилам.
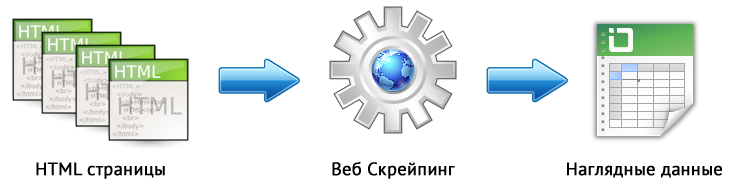
Основными способами веб-скрейпинга являются методы разбора данных используя XPath, CSS-селекторы, XQuery, RegExp и HTML templates.
- XPath представляет собой специальный язык запросов к элементам документа формата XML / XHTML. Для доступа к элементам XPath использует навигацию по DOM путем описания пути до нужного элемента на странице. С его помощью можно получить значение элемента по его порядковому номеру в документе, извлечь его текстовое содержимое или внутренний код, проверить наличие определенного элемента на странице.
- CSS-селекторы используются для поиска элемента его части (атрибут). CSS синтаксически похож на XPath, при этом в некоторых случаях CSS-локаторы работают быстрее и описываются более наглядно и кратко. Минусом CSS является то, что он работает лишь в одном направлении – вглубь документа. XPath же работает в обе стороны (например, можно искать родительский элемент по дочернему).
- XQuery имеет в качестве основы язык XPath. XQuery имитирует XML, что позволяет создавать вложенные выражения в таким способом, который невозможен в XSLT.
- RegExp – формальный язык поиска для извлечения значений из множества текстовых строк, соответствующих требуемым условиям (регулярному выражению).
- HTML templates – язык извлечения данных из HTML документов, который представляет собой комбинацию HTML-разметки для описания шаблона поиска нужного фрагмента плюс функции и операции для извлечения и преобразования данных.
Обычно при помощи скрейпинга решаются задачи, с которыми сложно справиться вручную. Это может быть извлечение описаний товаров для создании нового интернет-магазина, скрейпинг в маркетинговых исследованиях для мониторинга цен, либо для мониторинга объявлений.
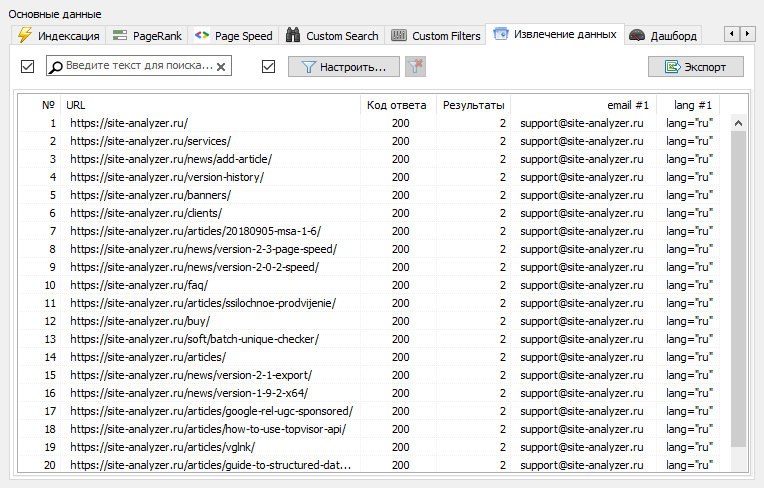
В SiteAnalyzer за настройку скрейпинга отвечает вкладка "Извлечение данных", в которой настраиваются правила извлечения. Правила можно сохранять и, при необходимости, редактировать.
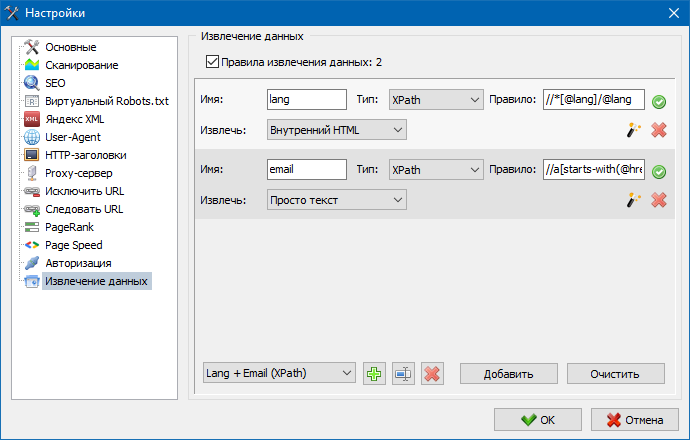
Также присутствует модуль тестирования правил. При помощи встроенного отладчика правил можно быстро и просто получить HTML-содержимое любой страницы сайта и тестировать работу запросов, после чего использовать отлаженные правила для парсинга данных в SiteAnalyzer.
После окончания извлечения данных всю собранную информацию можно экспортировать в Excel.

2. Проверка уникальности контента внутри сайта.
Данный инструмент позволяет провести поиск дубликатов страниц и проверить уникальность текстов внутри сайта. Иными словами это пакетная проверка группы URL на уникальность между собой.
Это может быть полезно в случаях:
- Для поиска полных дублей страниц (например, страница с параметрами и та же самая страница, но в виде ЧПУ).
- Для поиска частичных совпадений контента (например, два рецепта борща в кулинарном блоге, которые схожи между собой на 96%, что наводит на мысль, что одну из статей лучше удалить, дабы избавиться от возможной каннибализации трафика).
- Когда на статейном сайте вы случайно написали статью по теме, которую уже писали ранее 10 лет назад. В этом случае наш инструмент также выявит дубликат такой статьи.
Принцип работы инструмента проверки уникальности контента прост: по списку URL сайта программа скачивает их содержимое, получает текстовое содержимое страницы (без блока HEAD и без HTML-тегов), а затем при помощи алгоритма шинглов сравнивает их друг с другом.

Таким образом, при помощи шинглов мы определяем уникальность страниц и можем вычислить как полные дубли страниц с 0% уникальностью, так и частичные дубли с различными степенями уникальности текстового содержимого. Программа работает с длиной шингла равной 5.
3. Проверка скорости загрузки страниц по Google PageSpeed.
Инструмент PageSpeed Insights поискового гиганта Google позволяет проверять скорость загрузки тех или иных элементов страниц, а также показывает общий бал скорости загрузки интересующих URL для десктопной и мобильной версии браузера.

Инструмент Google всем хорош, однако, имеет один существенный минус – он не позволяет создавать групповые проверки URL, что создает неудобства при проверке множества страниц вашего сайта: согласитесь, что вручную проверять скорость загрузки для 100 и более URL по одной странице муторно и может занять немало времени.
Поэтому, нами был создан модуль, позволяющий бесплатно создавать групповые проверки скорости загрузки страниц через специальный API в инструменте Google PageSpeed Insights.

Основные анализируемые параметры:
- FCP (First Contentful Paint) – время отображения первого контента.
- SI (Speed Index) – показатель того, как быстро отображается контент на странице.
- LCP (Largest Contentful Paint) – время отображения наибольшего по размеру элемента страницы.
- TTI (Time to Interactive) – время, в течение которого страница становится полностью готова к взаимодействию с пользователем.
- TBT (Total Blocking Time) – время от первой отрисовки контента до его готовности к взаимодействию с пользователем.
- CLS (Cumulative Layout Shift) – накопительный сдвиг макета. Служит для измерения визуальной стабильности страницы.
Благодаря многопоточной работе программы SiteAnalyzer, проверка сотни и более URL может занять всего несколько минут, на что в ручном режиме, через браузер, мог бы уйти день или более.
При этом, сам анализ URL происходит всего в пару кликов, после чего доступна выгрузка отчета, включающего основные характеристики проверок в удобном виде в Excel.
4. Добавлена возможность группировки проектов по папкам.
Для более удобной навигации по списку проектов была добавлена возможность группировки сайтов по папкам.

Дополнительно появилась возможность фильтрации списка проектов по названию.
5. Обновлен интерфейс настроек программы.

С расширением функционала программы нам стало "тесно" использовать табы, поэтому мы переформатировали окно настроек в более понятный и функциональный интерфейс.
Прочие изменения
- исправлен некорректный учет исключений URL
- исправлен некорректный учет глубины сканирования сайта
- восстановлено отображение редиректов для URL, импортированных из файла
- восстановлена возможность перестановки и запоминания порядка столбцов на вкладках
- восстановлен учет неканонических страниц, решена проблема с пустыми мета-тегами
- восстановлено отображение анкоров ссылок на вкладке Инфо
- ускорен импорт большого количества URL из буфера обмена
- исправлен не всегда корректный парсинг title и description
- восстановлено отображение alt и title у изображений
- исправлено зависание при переходе на вкладку "Внешние ссылки" во время сканирования проекта
- исправлена ошибка, возникающая при переключении между проектами и обновлении узлов вкладки "Статистика обхода сайта"
- исправлено некорректное определение уровня вложенности для URL с параметрами
- исправлена сортировка данных по полю HTML-hash в главной таблице
- оптимизирована работа программы с кириллическими доменами
- обновлен интерфейс настроек программы
- обновлен дизайн логотипа
Буду рад любым замечаниям и предложениям по улучшению функционала программы.

