
Об авторе
Антон Подкопаев является постдоком в MPI-SWS, руководителем группы слабых моделей памяти в лаборатории языковых инструментов JetBrains Research и преподавателем Computer Science Center.
Еще в 1979 году Лесли Лампорт в статье «How to make a multiprocessor computer that correctly executes multiprocess programs» ввел, как следует из названия, идеализированную семантику многопоточности — модель последовательной консистентности (sequential consistency, SC). Согласно данной модели, любой результат исполнения многопоточной программы может быть получен как последовательное исполнение некоторого чередования инструкций потоков этой программы. (Предполагается, что чередование сохраняет порядок между инструкциями, относящимися к одному потоку.)
Рассмотрим следующую программу SB:
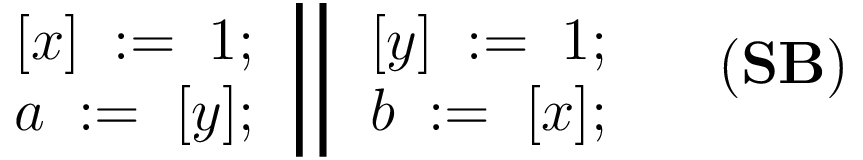
В этой программе два потока, в каждом из которых первая инструкция — инструкция записи в разделяемую локацию (x или y), а вторая — инструкция чтения из другой разделяемой локации. Для этой программы существует шесть чередований инструкций потоков:
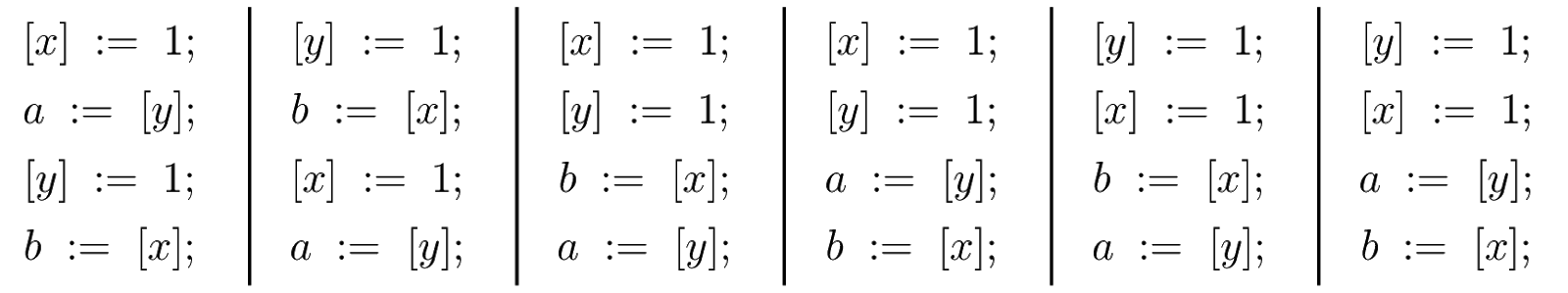
В этом и последующих примерах мы предполагаем, что разделяемые локации инициализированы значением 0. Тогда, согласно модели SC, у этой программы есть только три возможных результата исполнения: [a=1, b=0], [a=0, b=1] и [a=1, b=1].
Первый из них соответствует последовательному исполнению первого чередования инструкций, второй — второму, а третий — оставшимся четырем. Никакие другие результаты исполнения программы SB, в частности [a=0, b=0], моделью SC не допускаются.
Последнее означает, что для упрощенной версии алгоритма взаимоисключения Деккера, приведенной ниже, гарантируется корректность, т.е. нет такого исполнения данной программы, в котором обе критические секции исполняются:

Давайте проверим, что на практике все так же. Для этого мы реализуем программу
SB-impl на С++:
1: #include <thread>
2: #include <iostream>
3:
4: using namespace std;
5:
6: int x, y, a, b;
7:
8: void thread1() {
9: cout.flush();
10: x = 1;
11: a = y;
12: }
13:
14: void thread2() {
15: y = 1;
16: b = x;
17: }
18:
19: int main() {
20: int cnt = 0;
21: do {
22: a = 0; b = 0;
23: x = 0; y = 0;
24:
25: thread first(thread1);
26: thread second(thread2);
27:
28: first.join();
29: second.join();
30: cnt++;
31: } while (a != 0 || b != 0);
32: cout << cnt << endl;
33: return 0;
34: }Здесь аналог SB запускается в цикле (строки 21–31), пока не будет получен результат [a=0, b=0]. Если он будет получен, то на экране появится номер соответствующей итерации (строка 32). (Зачем в функции thread1 на строке 9 нужна команда cout.flush(), будет описано ниже.)
С точки зрения модели SC, данная программа не должна завершиться, однако если скомпилировать этот код с помощью GCC и запустить на x86-машине,
g++ -O2 -pthread sb.cpp -o sb && ./sbто можно увидеть на экране, например, 23022 или 56283 — такие результаты получил автор, запустив данный код на своем компьютере.
Это пример показывает, что идеализированная модель SC не описывает реальное положение дел. Почему так? Откуда у программы SB берется результат [a=0, b=0]? На самом деле, причины две: компиляторные и процессорные оптимизации. Так, компилятор, в нашем случае — GCC, может заметить, что инструкции в левом (аналогично и в правом) потоке программы SB независимы друг от друга, и, как следствие, может их переставить:

Для этой программы [a=0, b=0] является корректным с точки зрения модели SC. И эта перестановка действительно происходит! Для того чтобы в этом убедится, можно посмотреть на ассемблерный код, который GCC генерирует для функции
thread1:g++ -O2 -c -S sb.cpp1: ...
2: call _ZNSo5flushEv@PLT
3: movl y(%rip), %eax
4: movl $1, x(%rip)
5: movl %eax, a(%rip)
6: ...На строке 2 происходит чтение из переменной y и значение записывается в регистр
eax, на строке 3 происходит запись в переменную x значения 1, а на строке 5 значение из регистра eax записывается в переменную a.
Зачем нужен вызов функции cout.flush()
Теперь пришло время объяснить, зачем нужен вызов функции
Отметим, что
cout.flush(). Как было упомянуто ранее, поскольку запись в x и чтение из y независимы, то компилятор, в нашем случае — GCC, может принять решение их переставить. Тем не менее, он не обязан этого делать: например, GCC не проводит перестановку для функции thread2. Для того чтобы сделать перестановку, компилятор должен предположить, что код после перестановки станет более эффективным. И, как показала практика, вызов функции cout.flush() заставляет GCC считать, что инструкции стоит переставить. При этом необязательно использовать именно эту функцию — достаточно функции, вызов которой GCC не уберет как бесполезный. Так, печать не пустой строки cout << " " подойдет, а вызов арифметических функций sqrt() и abs() без использования их результата не подойдет.Отметим, что
cout.flush() не делает ничего в в программе SB-impl, хотя GCC и не может это вывести самостоятельно: cout.flush() сбрасывает буфер вывода в консоль, однако на каждом вызове cout.flush() буфер пуст, поскольку программа пишет в консоль только в конце (строка 34).Есть способ явно запретить компилятору переставлять инструкции чтения и записи в функциях
thread1 и thread2. Для этого достаточно вставить компиляторный барьер памяти asm volatile("" ::: "memory") между инструкциями (в данном случае добавление инструкции cout.flush() не меняет ничего):void thread1() {
x = 1;
asm volatile("" ::: "memory");
a = y;
}
void thread2() {
y = 1;
asm volatile("" ::: "memory");
b = x;
}Тем не менее, если запустить программу с компиляторными барьерами, то все еще можно получить результат [a=0, b=0], поскольку, как было упомянуто ранее, не только компилятор, но и процессор может быть причиной появления результатов, выходящих за пределы модели SC — результат [a=0, b=0] для программы SB не только разрешается спецификацией архитектуры x86, но и наблюдается на большинстве процессоров семейства x86.
Для того чтобы понять, как подобный результат получается на процессоре, нужно обратиться к модели памяти архитектуры, т.е. к ее формальной семантике. Модель памяти архитектуры x86 называется TSO (total store order). TSO разрешает исполнения программ, выходящие за пределы модели SC, в частности исполнение программы SB, завершающиеся с результатом [a=0, b=0]. Такие исполнения называются слабыми, как и допускающие их модели памяти. Все основные процессорные архитектуры (x86, ARM, RISC-V, POWER, SPARC) обладают именно слабыми моделями памяти.
Схематически модель TSO можно изобразить так:

В рамках этой модели потоки при выполнении инструкции записи не обновляют основную память напрямую. Вместо этого они отправляют запрос в локальный буфер записи, из которого он через некоторое время попадает в основную память. При чтении поток сначала проверяет свой буфер записи на наличие запросов к соответствующей локации и при их отсутствии обращается к основной памяти.
Рассмотрим исполнение программы SB в модели TSO, которое заканчивается с результатом [a=0, b=0]. В начале исполнения состояние программы и памяти выглядит следующим образом:

P обоих потоков показывают на первые инструкции, все локации в памяти проинициализированы 0, а регистры a и b не определены. Далее левый поток выполняет инструкцию записи в локацию x, и соответствующий запрос попадает в буфер записи:

Далее правый поток может выполнить аналогичный шаг:

Теперь правый поток выполняет инструкцию чтения из локации x. Поскольку в его буфере нет запроса на запись в эту локацию, поток получает значение из основной памяти, присваивая соответствующее значение 0 регистру b:

Аналогичным образом левый поток присваивает значение 0 регистру a:

После чего запрос из буфера левого потока попадает в память:

А за ним и запрос из буфера правого потока:

Так, в модели TSO получается слабое исполнение для программы SB. Кстати, название программы SB является аббревиатурой от store buffering — эффекта, наблюдаемого в ее слабом исполнении.
Тем не менее, существует способ запретить результат [a=0, b=0] для программы SB-impl, а значит и реализовать алгоритм Деккера на архитектуре x86. Для этого в программу нужно добавить процессорный барьер памяти mfence — специальную инструкцию x86 — которая, как и ранее использованный компиляторный барьер, запрещает GCC переставлять инструкции вокруг нее, но и дополнительно требует при своем исполнении уже на процессоре, чтобы буфер записи соответствующего потока был пуст:
void thread1() {
x = 1;
asm volatile("mfence" ::: "memory");
a = y;
}
void thread2() {
y = 1;
asm volatile("mfence" ::: "memory");
b = x;
}Так, чтение a :=[y] в левом потоке исправленной программы SB-impl может быть выполнено только после того, как запись [x] := 1 обновила основную память. Аналогичное утверждение верно для чтения b := [x] из правого потока. В итоге результат [a=0, b=0] становится невозможным.
Заключение
Мы рассмотрели пример многопоточной программы, которая может быть исполнена на архитектуре x86 неожиданным образом — продемонстрировать так называемое слабое исполнение, выходящее за пределы привычной модели SC. Это исполнение программы является результатом как компиляторных оптимизаций, так и оптимизаций используемых в процессоре семейства x86.
В дальнейшем, если тема слабых исполнений и моделей памяти вызовет интерес, автор планирует написать серию постов на эту тему.
 на рельефе с помощью MantaFlow и визуализация результатов в ParaView")


