
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Справедливое моделирование — это область искусственного интеллекта, которая гарантирует, что на результат машинного моделирования не влияют такие защищённые атрибуты, как пол, раса, религия, сексуальная ориентация и т. д. В последнее время справедливое моделирование привлекло значительное внимание в научном сообществе и промышленности, ведь сейчас многие решения принимаются на основе результатов от моделей машинного обучения.
В мире, где люди борются за равенство, обеспечение справедливого поведения моделей должно быть главным приоритетом. Сегодня специально к старту курса «Машинное обучение» представляем вам перевод статьи, в которой показано, как с помощью Fairlearn можно выявить и решить проблему недобросовестного поведения моделей машинного обучения.

Различные организации, такие как Google, IBM и Microsoft, разработали собственные инструменты с открытым исходным кодом, которые могут использоваться для справедливого моделирования. Здесь я продемонстрирую инструмент Fairlearn, разработанный компанией Microsoft. В конце статьи статьи даётся ссылка на блокнот. Если вы хотите запустить код, я настоятельно рекомендую вам использовать его. Здесь даётся только высокоуровневый обзор кода.
Для демонстрации Fairlearn поработаем с набором данных о доходе взрослого человека. В машинном обучении этот набор используется очень часто. Обычно целевой переменной в наборе данных является переменная дохода, которая обозначает, зарабатывает ли человек более или менее 50 тысяч в год. В целях повествования я буду рассматривать другую целевую переменную. В качестве целевой переменной я возьму данные о том, выплатил ли человек кредит. Я создам эту целевую переменную очень просто. В случае если наблюдение составило более 50 k, предполагается, что он может вернуть кредит. Иначе — нет.
В базе данных содержится более 48 000 наблюдений. Для простоты я не буду делать никакого выделения переменных и просто включу в модель все переменные. Я также не буду разбивать данные на тренировочный и тестовый наборы, поскольку это только демонстрация. Однако есть один шаг, который мне нужно сделать. Некоторые из переменных в наших данных (т. е. race и gender — раса и пол) могут рассматриваться как чувствительные или защищённые признаки. Лучше не включать эти переменные в набор, потому что я не хочу, чтобы модель принимала их во внимание. Однако я сохраню их в новой переменной, потому что они понадобятся в будущем.
Удаление защищённых признаков из модели часто называют справедливостью через неосведомлённость.
Для демонстрации я буду использовать в прогнозах простой классификатор дерева принятия решений. Модель прогнозирует, сможет ли человек вернуть кредит.
Для правильной оценки работы модели необходимо знать классовый дисбаланс. В нашем случае 76 % людей не в состоянии вернуть кредит. Я не буду обучать модель с непропорционально небольшим количеством примеров основного класса или добавлять примеры в класс меньшинства, чтобы избавиться от дисбаланса этого класса.
Для выявления несправедливости в моделях машинного обучения можно использовать две стратегии:
Первый метод реализован в Fairlearn функцией group_summary_. Эта функция требует в качестве входных данных:
Эта функция возвращает три значения: общая точность (0,84), точность для женщин (0,93) и точность для мужчин (0,80). В нашем примере имеется существенная разница между точностью для мужчин и женщин, которая может быть признаком несправедливости.
Как упоминалось во втором методе, в Fairlearn также применяются более специальные метрики, которые можно использовать для оценки справедливости модели. Наиболее часто используемые показатели справедливости — демографический паритет и выравнивание шансов. Понятия описываются в этой статье. В Fairlearn эти метрики реализованы функциями
Чтобы принять решение о том, справедлива ли модель, нам необходимо определить пороговые значения этих метрик. Корпорация Майкрософт не указывала эти значения в Fairlearn. К счастью, IBM указала их в Fairness 360 tool. Вот они:
В нашем случае разница в демографическом паритете (0,15) и соотношение (0,3) указывают на несправедливость, в то время как разница в выравнивании шансов (0,08) не указывает на несправедливость. Конечно, расчёт всех этих мер для всех ваших моделей может потребовать много программирования. Вот почему Fairlearn также включает в себя дашборд FairlearnDashboard, позволяющий графически исследовать справедливость модели машинного обучения. Дашборд требует следующих входных данных:
На дашборде отображаются эти экраны:

Лендинг дашборда
После лендинга пользователь вынужден принять два решения. Сначала необходимо выбрать, какой чувствительный признак вы хотите изучить.

Какой выбран чувствительный признак?
В нашем случае я буду использовать только переменную gender. Далее пользователю необходимо определить используемую метрику производительности.

Какой показатель эффективности?
Несмотря на классовый дисбаланс, я всё равно буду использовать точность как метрику производительности, так как это метрика, которую все понимают. После того как пользователь прошел по интерфейсу, модуль начинает вычислять различные метрики, которые могут использоваться для оценки справедливости модели:
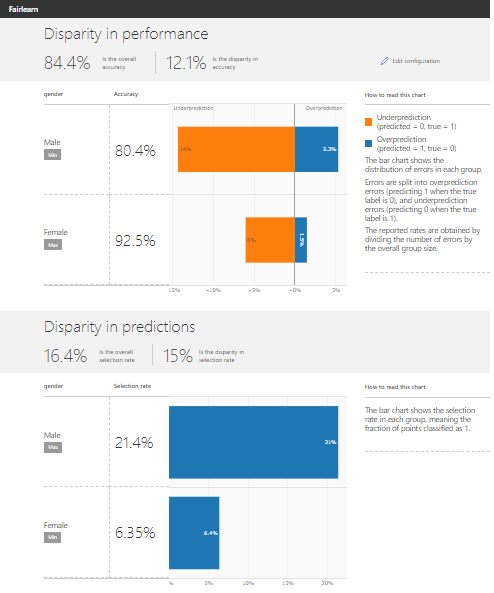
Результаты
Верхняя часть дашборда показывает диспропорции в производительности. В этой части показано, какие ошибки алгоритм допускает и для мужчин, и для женщин. На примере видно, что модель чаще недооценивает (не даёт кредит, даже если человек может вернуть деньги) мужчин, чем женщин. В нижней части дашборда показана диспропорция в прогнозах для мужчин и женщин. График показывает, что процент отбора (процент положительного прогноза или часть людей, которая получает кредит) для мужчин намного выше, чем процент отбора для женщин. Оба вышеперечисленных момента свидетельствуют о проблемах несправедливости в модели.
Как только будет выявлена несправедливость, внимание должно быть сосредоточено на избавлении от нее. Один из методов в Fairlearn — Reduction_ (редукция). Он имеет три параметра:
В Fairlearn два метода редукции:
Прогнозирование через редукцию в Fairlearn следует тому же синтаксису, что и пакет sklearn. Однако есть одна разница: чувствительные признаки должны быть переданы в метод обучения:
После того как я сгенерировал прогнозы с использованием ограничений, определённых в Fairlearn, я могу сравнивать различные модели с помощью дашборда Fairlearn. Теперь, вместо того чтобы подавать только прогнозы дерева решений, я также предоставляю ограниченные прогнозы с помощью словаря:
Теперь на дашборде отображается такой экран:
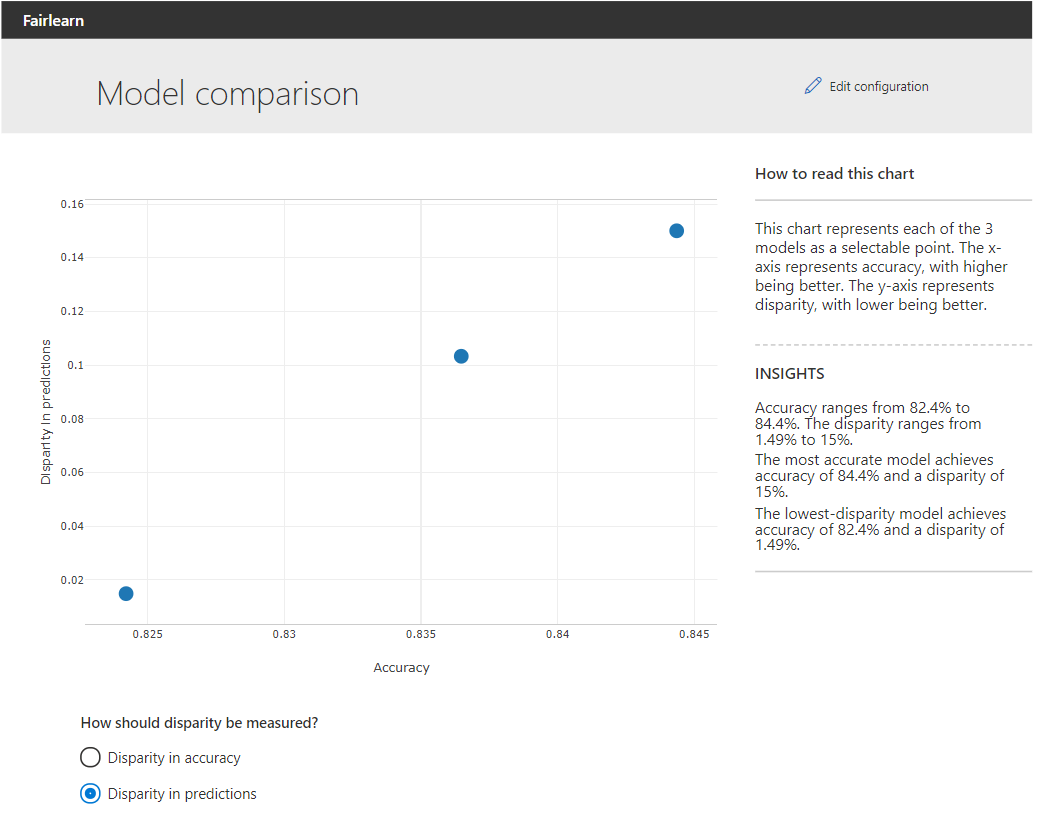
Сравнение моделей
Приведённый выше график позволяет пользователю сравнивать исходную и ограниченную модели. На оси Х указывается общая точность моделей. По оси Y даётся расхождение в прогнозах или в точности. Нажав на одну из точек, пользователь может выбрать модель для дальнейшего исследования. Когда мы на примере смотрим на диспропорции в прогнозах для модели, использующей ограничение демографического паритета, мы видим, что коэффициент отбора для мужчин и женщин примерно одинаков:
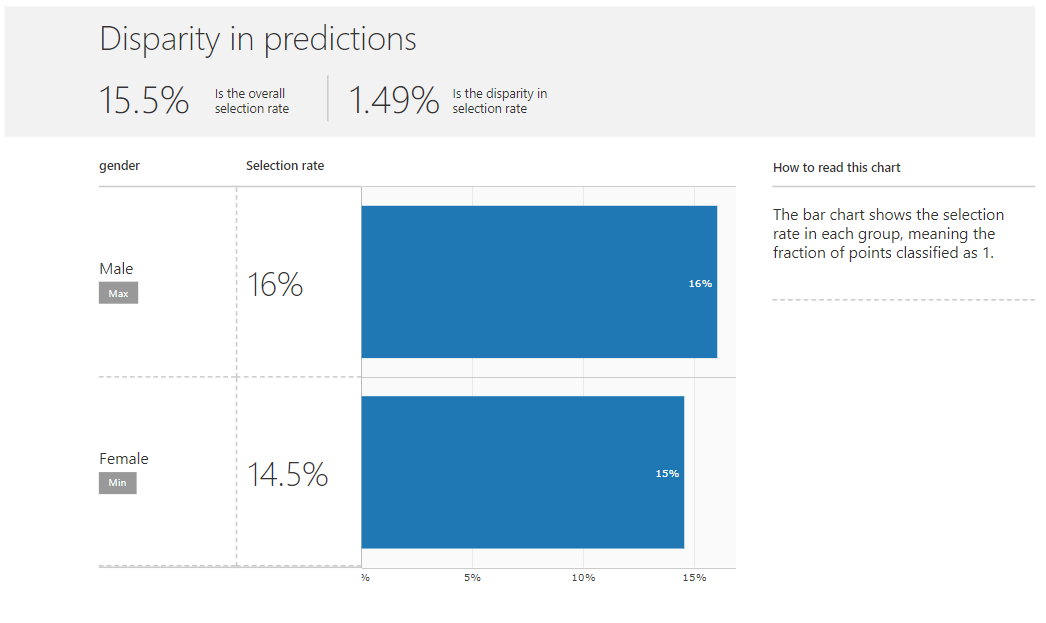
Коэффициенты отбора теперь схожи
Другой реализованный в Fairlearn для уменьшения несправедливости метод — так называемый

Результат работы оптимизатора пороговых значений
Когда результаты оптимизатора пороговых значений также передаются на дашборд, можно увидеть, что этот оптимизатор избавляется как от несоответствия в точности, так и от несоответствия в прогнозах, жертвуя лишь небольшой долей общей точности.
Пакет Fairlearn позволяет пользователю быстро оценивать и устранять несправедливость в моделях машинного обучения. Пользователь может воспользоваться функциями, определёнными в пакете, или сделать это с помощью визуального интерфейса. Оценивая и устраняя несправедливость в моделях машинного обучения, практики могут предотвратить дискриминацию людей в своих моделях.
Ссылка на блокнот

В мире, где люди борются за равенство, обеспечение справедливого поведения моделей должно быть главным приоритетом. Сегодня специально к старту курса «Машинное обучение» представляем вам перевод статьи, в которой показано, как с помощью Fairlearn можно выявить и решить проблему недобросовестного поведения моделей машинного обучения.
Различные организации, такие как Google, IBM и Microsoft, разработали собственные инструменты с открытым исходным кодом, которые могут использоваться для справедливого моделирования. Здесь я продемонстрирую инструмент Fairlearn, разработанный компанией Microsoft. В конце статьи статьи даётся ссылка на блокнот. Если вы хотите запустить код, я настоятельно рекомендую вам использовать его. Здесь даётся только высокоуровневый обзор кода.
Данные
Для демонстрации Fairlearn поработаем с набором данных о доходе взрослого человека. В машинном обучении этот набор используется очень часто. Обычно целевой переменной в наборе данных является переменная дохода, которая обозначает, зарабатывает ли человек более или менее 50 тысяч в год. В целях повествования я буду рассматривать другую целевую переменную. В качестве целевой переменной я возьму данные о том, выплатил ли человек кредит. Я создам эту целевую переменную очень просто. В случае если наблюдение составило более 50 k, предполагается, что он может вернуть кредит. Иначе — нет.
df.loc[:, "target"] = df.income.apply(lambda x: int(x == ">50K")) # int(): Fairlearn dashboard requires integer target
df = df.drop("income", axis = 1) # drop income variable to avoid perfect prediction
Построение простой модели
В базе данных содержится более 48 000 наблюдений. Для простоты я не буду делать никакого выделения переменных и просто включу в модель все переменные. Я также не буду разбивать данные на тренировочный и тестовый наборы, поскольку это только демонстрация. Однако есть один шаг, который мне нужно сделать. Некоторые из переменных в наших данных (т. е. race и gender — раса и пол) могут рассматриваться как чувствительные или защищённые признаки. Лучше не включать эти переменные в набор, потому что я не хочу, чтобы модель принимала их во внимание. Однако я сохраню их в новой переменной, потому что они понадобятся в будущем.
race = df.pop("race") # Pop function drops and assigns at the same time
gender = df.pop("gender")Удаление защищённых признаков из модели часто называют справедливостью через неосведомлённость.
Для демонстрации я буду использовать в прогнозах простой классификатор дерева принятия решений. Модель прогнозирует, сможет ли человек вернуть кредит.
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier(minsamples_leaf=10, max_depth=4) # parameters have not been tuned
classifier.fit(df, target)
# Note that we are predicting using the same data as we used for training, this is just for the sake of example
# Never do this in real life
prediction = classifier.predict(df)
Для правильной оценки работы модели необходимо знать классовый дисбаланс. В нашем случае 76 % людей не в состоянии вернуть кредит. Я не буду обучать модель с непропорционально небольшим количеством примеров основного класса или добавлять примеры в класс меньшинства, чтобы избавиться от дисбаланса этого класса.
Выявление несправедливости в модели
Для выявления несправедливости в моделях машинного обучения можно использовать две стратегии:
- Набор данных может быть разделён на основе защищённого атрибута, а затем можно рассчитать метрики производительности для разделения (например для мужчин и женщин). Большая разница в показателях производительности может быть признаком несправедливости.
- Можно вычислить специальные метрики справедливости, такие как демографический паритет и выравнивание шансов.
Первый метод реализован в Fairlearn функцией group_summary_. Эта функция требует в качестве входных данных:
- Метрику, которую вы хотите использовать, загружаемую из sklearn.
Истинные значения.
Прогнозы вашей модели.
Чувствительные признаки.
from fairlearn.metrics import group_summary
from sklearn.metrics import accuracy_score
group_summary(accuracy_score , target, prediction, sensitive_features = gender)
Эта функция возвращает три значения: общая точность (0,84), точность для женщин (0,93) и точность для мужчин (0,80). В нашем примере имеется существенная разница между точностью для мужчин и женщин, которая может быть признаком несправедливости.
Как упоминалось во втором методе, в Fairlearn также применяются более специальные метрики, которые можно использовать для оценки справедливости модели. Наиболее часто используемые показатели справедливости — демографический паритет и выравнивание шансов. Понятия описываются в этой статье. В Fairlearn эти метрики реализованы функциями
demographic_parity_difference, demographic_parity_ratio и equalized_odds_difference:from fairlearn.metrics import demographic_parity_difference, equalized_odds_difference, demographic_parity_ratio
dpd = demographic_parity_difference(target, prediction, sensitive_features = gender)
eod = equalized_odds_difference(target, prediction, sensitive_features = gender)
dpr = demographic_parity_ratio(target, prediction, sensitive_features = gender)
print("Demographic parity difference: {}".format(round(dpd, 2)))
print("Equalized odds difference: {}".format(round(eod, 2)))
print("Demographic parity ratio: {}".format(round(dpr, 2)))
Чтобы принять решение о том, справедлива ли модель, нам необходимо определить пороговые значения этих метрик. Корпорация Майкрософт не указывала эти значения в Fairlearn. К счастью, IBM указала их в Fairness 360 tool. Вот они:
- Демографическая разница в паритете: если абсолютное значение меньше 0,1, то модель можно считать справедливой.
- Уравновешенная разница шансов: если абсолютное значение меньше 0,1, то модель можно считать справедливой.
- Разница в равных возможностях: если абсолютное значение меньше 0,1, то модель можно считать справедливой.
- Коэффициент демографического паритета: справедливость этого показателя составляет от 0,8 до 1,25.
В нашем случае разница в демографическом паритете (0,15) и соотношение (0,3) указывают на несправедливость, в то время как разница в выравнивании шансов (0,08) не указывает на несправедливость. Конечно, расчёт всех этих мер для всех ваших моделей может потребовать много программирования. Вот почему Fairlearn также включает в себя дашборд FairlearnDashboard, позволяющий графически исследовать справедливость модели машинного обучения. Дашборд требует следующих входных данных:
- Истинный результат.
- Прогноз.
- Чувствительный признаки.
- Имя чувствительного признака.
from fairlearn.widget import FairlearnDashboard
FairlearnDashboard(ytrue = target,
y_pred = prediction,
sensitivefeatures = gender,
sensitive_feature_names = ["gender"])
На дашборде отображаются эти экраны:
Лендинг дашборда
После лендинга пользователь вынужден принять два решения. Сначала необходимо выбрать, какой чувствительный признак вы хотите изучить.
Какой выбран чувствительный признак?
В нашем случае я буду использовать только переменную gender. Далее пользователю необходимо определить используемую метрику производительности.
Какой показатель эффективности?
Несмотря на классовый дисбаланс, я всё равно буду использовать точность как метрику производительности, так как это метрика, которую все понимают. После того как пользователь прошел по интерфейсу, модуль начинает вычислять различные метрики, которые могут использоваться для оценки справедливости модели:
Результаты
Верхняя часть дашборда показывает диспропорции в производительности. В этой части показано, какие ошибки алгоритм допускает и для мужчин, и для женщин. На примере видно, что модель чаще недооценивает (не даёт кредит, даже если человек может вернуть деньги) мужчин, чем женщин. В нижней части дашборда показана диспропорция в прогнозах для мужчин и женщин. График показывает, что процент отбора (процент положительного прогноза или часть людей, которая получает кредит) для мужчин намного выше, чем процент отбора для женщин. Оба вышеперечисленных момента свидетельствуют о проблемах несправедливости в модели.
Разрешаем несправедливость
Как только будет выявлена несправедливость, внимание должно быть сосредоточено на избавлении от нее. Один из методов в Fairlearn — Reduction_ (редукция). Он имеет три параметра:
- Base_estimater: функция оценки (обычно поставляется со sklearn). Здесь использовался классификатор дерева решений.
- Ограничения: ограничения в отношении справедливости, которым должна удовлетворять модель. В fairlearn мы имеем (для бинарной классификации) ограничения
DemographicParity,TruePositiveRateParity,EqualizedOddsиErrorRateParity. Это мягкие ограничения. - Чувствительные признаки: какой чувствительный признак вы хотите принять во внимание (в методе обучения).
В Fairlearn два метода редукции:
ExponentiatedGradient или GridSearch. Я решу проблему несправедливости с помощью определённых в Fairlearn методов. В нашей реализации используется ограничение демографического паритета, а также ограничение выравнивания шансов:from fairlearn.reductions import ExponentiatedGradient, DemographicParity, EqualizedOdds
classifier = DecisionTreeClassifier(min_samples_leaf=10, max_depth=4)
dp = DemographicParity()
reduction = ExponentiatedGradient(classifier, dp)
reduction.fit(df, target, sensitive_features=gender)
prediction_dp = reduction.predict(df)
Прогнозирование через редукцию в Fairlearn следует тому же синтаксису, что и пакет sklearn. Однако есть одна разница: чувствительные признаки должны быть переданы в метод обучения:
eo = EqualizedOdds()
reduction = ExponentiatedGradient(classifier, eo)
reduction.fit(df, target, sensitive_features=gender)
prediction_eo = reduction.predict(df)
После того как я сгенерировал прогнозы с использованием ограничений, определённых в Fairlearn, я могу сравнивать различные модели с помощью дашборда Fairlearn. Теперь, вместо того чтобы подавать только прогнозы дерева решений, я также предоставляю ограниченные прогнозы с помощью словаря:
FairlearnDashboard(y_true = target,
y_pred = {"prediction_original" : prediction,
"prediction_dp": prediction_dp,
"prediction_eo": prediction_eo},
sensitive_features = gender,
sensitive_feature_names = ["gender"])
Теперь на дашборде отображается такой экран:
Сравнение моделей
Приведённый выше график позволяет пользователю сравнивать исходную и ограниченную модели. На оси Х указывается общая точность моделей. По оси Y даётся расхождение в прогнозах или в точности. Нажав на одну из точек, пользователь может выбрать модель для дальнейшего исследования. Когда мы на примере смотрим на диспропорции в прогнозах для модели, использующей ограничение демографического паритета, мы видим, что коэффициент отбора для мужчин и женщин примерно одинаков:
Коэффициенты отбора теперь схожи
Другой реализованный в Fairlearn для уменьшения несправедливости метод — так называемый
ThresholdOptimizer. Этот оптимизатор определяет оптимальный порог, используя компромисс между целями (например оптимизацию точности) и ограничение (например демографический паритет). Требуется только функция оценки. По умолчанию она имеет целью оптимизацию оценки точности, ограничением по умолчанию является DemographicParity. Подробности о настройке этих параметров здесь.Результат работы оптимизатора пороговых значений
Когда результаты оптимизатора пороговых значений также передаются на дашборд, можно увидеть, что этот оптимизатор избавляется как от несоответствия в точности, так и от несоответствия в прогнозах, жертвуя лишь небольшой долей общей точности.
Вывод
Пакет Fairlearn позволяет пользователю быстро оценивать и устранять несправедливость в моделях машинного обучения. Пользователь может воспользоваться функциями, определёнными в пакете, или сделать это с помощью визуального интерфейса. Оценивая и устраняя несправедливость в моделях машинного обучения, практики могут предотвратить дискриминацию людей в своих моделях.
Ссылка на блокнот
- Курс по Machine Learning
- Продвинутый курс «Machine Learning Pro + Deep Learning»
- Курс «Математика и Machine Learning для Data Science»
- Обучение профессии Data Science
- Обучение профессии Data Analyst
- Онлайн-буткемп по Data Analytics
- Курс «Python для веб-разработки»
Eще курсы
- Разработчик игр на Unity
- Профессия Веб-разработчик
- Профессия Java-разработчик
- Курс по JavaScript
- C++ разработчик
- Обучение профессии C#-разработчик
- Курс по аналитике данных
- Курс по DevOps
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
Рекомендуемые статьи
- Как стать Data Scientist без онлайн-курсов
- 450 бесплатных курсов от Лиги Плюща
- Как изучать Machine Learning 5 дней в неделю 9 месяцев подряд
- Сколько зарабатывает аналитик данных: обзор зарплат и вакансий в России и за рубежом в 2020
- Machine Learning и Computer Vision в добывающей промышленности



