
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Уязвимости в своём коде хочется находить как можно быстрее, а значит нужно автоматизировать этот процесс. Как именно автоматизировать поиск уязвимостей? Существует динамическое тестирование безопасности, существует статическое — и у обоих свои преимущества и недостатки. Сегодня подробно разберёмся со статическим на опыте его применения в Одноклассниках.
По каким принципам можно выбирать инструмент для статического тестирования? С какими сложностями сталкиваешься, когда уже выбрал? Как писать собственные правила анализа, расширяющие стандартную функциональность? Я занималась всеми этими вопросами — и теперь делюсь с Хабром тем, что узнала.
Речь пойдёт о Java, веб-приложениях, SonarQube и Find Security Bugs, но рассказанное применимо также для других языков и технологий.
В основу поста лёг мой доклад с конференции Heisenbug: если вам удобнее видеоформат — можете посмотреть его, если текст — читайте дальше.
План:
- Предисловие
- Теория
- Выбираем статический анализатор
- Практика
Предисловие
Очевидным способом автоматизировать тестирование безопасности веб приложений является использования сканеров уязвимостей, например OWASP ZAP или Accunetix.
Такие сканеры применяют фаззинг, что сопряжено с рядом проблем:
- Наблюдается комбинаторный взрыв количества запросов, выполняемых в ходе тестирования: умножаем количество параметров в приложении на размер списка значений для фаззинга и получаем нагрузку, которую может выдержать не каждая тестовая инфраструктура;
- Фаззер не запоминает состояние приложения и не учитывает логику его работы, и поэтому некоторые уязвимости пропускает;
- При добавлении в приложение новых форм, страниц, API требуется дополнительно обучать сканер.
В сложной системе всё это осложняет процесс тестирования безопасности, и мы обратились к статическому анализу.
Что нам было нужно?
- Дешёвое масштабирование: автоматизированный инструмент, который можно запускать часто, на большом количестве приложений, и это не будет требовать значительного количества ручного труда;
- Возможность воспользоваться уже существующими у нас знаниями о ранее найденных уязвимостях (если мы какие-то баги уже исправили, то было бы неплохо найти все похожие);
- Способ искать уязвимости не только в вебе, но и в мобильных приложениях.
С таким списком ожиданий мы попробовали внедрить у себя статический анализ.
Но прежде чем перейти к рассказу об этом посмотрим, как статический анализ может использоваться для поиска уязвимостей и насколько это укладывается в вышеперечисленные пожелания.
Теория
Идея статического анализа (применения формальных методов для анализа программы) не нова. Первый известный человечеству статический анализатор — это Lint, выпущенный в 1979 году, то есть он старше многих читателей этого текста. Lint воспринимал код как текст и искал подстроки — по сути, не отличался от grep.
По большому счету, для поиска уязвимостей статический анализ может предложить два подхода:

Первый применяется для поиска конструкций в коде, которые потенциально могут приводить к проблемам с безопасностью: вызовов небезопасного API, задепрекейченных функций, захардкоженных паролей или ключей шифрования и так далее.
Второй подход — анализ потока данных или потока управления программы. Если мы можем построить модель, описывающую в каком порядке выполняются конструкции в коде или как распространяются данные, то можем и делать утверждения об особенностях этого распространения, и таким образом находить уязвимости.
Чтобы объяснить статическому анализатору, как именно выглядит уязвимость в программе, нам нужно написать правило. Иногда статические анализаторы называют их детекторами.
Детектор формулирует требование к исходному коду (например, “строки SQL запросов не содержат изменяемых извне данных”) и используют построенные статическим анализатором модели чтобы проверить, выполняется ли это требование.
Какая информация доступна детекторам?
Во-первых, это абстрактное синтаксическое дерево (AST). AST в своих узлах содержит метаинформацию о каждом элементе программы. Это практически дерево разбора, которое строит компилятор.
Фрагмент Java-кода в виде абстрактного синтаксического дерева будет выглядеть как-то так:

Вот некоторые правила, которые можно было бы реализовать на основе данных из AST:
— “класс, переопределяющий equals(), должен переопределить и hashCode()”;
— “строковые литералы не должны присваиваться переменным с названиями password или secret”.
Во-вторых, статические анализаторы строят граф потока управления (Control Flow Graph, CFG). CFG описывает переходы между базовыми блоками в программе, позволяя получить все возможные пути исполнения.

Граф потока управления строится на основе абстрактного синтаксического дерева. Детекторы используют CFG для проверки утверждений о порядке выполнения инструкций. Так же CFG используется для построения другой важной модели — графа потока данных, которая, в свою очередь, нужна для taint analysis.
Адекватного русского перевода этого термина, похоже, не существует, а что это такое, проще всего объяснить на примере. Вот распространенная уязвимость cross-site scripting (XSS) в самой простой реализации:
String foo = request.getParameter("foo");
response.getWriter().write(foo);В этих двух строках сервлет умудряется дать возможность атакующему выполнить произвольный JavaScript в браузере пользователя.
Что здесь происходит? Мы видим переменную «foo», которая содержит значение из параметра запроса в неизменном виде. Приложение записываем его в тело ответа. То есть, если в параметре foo передана строка, содержащая html тэги, то браузер пользователя будет интерпретировать ее как фрагмент HTML-разметки.
Taint analysis используется для того, чтобы искать подобные уязвимости: разного рода инъекции, cross site scripting, утечки персональных данных — всё, что связано с передачей параметров в программе.
Как это работает? Сначала анализатор определяет все точки, в которых в программу могут попасть данные, изменяемые извне. Их называют tainted, от английского «taint» — «портить», «заражать». В нашем примере параметр foo является tainted, потому что getParameter возвращает значение, контролируемое атакующим.

Как соответствующий детектор понимает, какие из методов могут поставлять изменяемые извне параметры? Он содержит в себе список сигнатур. Понятно, что этот список будет специфичен для языка, технологии, фреймворка. Можно рассчитывать, что статический анализатор содержит правила для стандартных или популярных API “из коробки”,. но вы можете дополнять их, если у вас есть какие-то специальные знания про ваш код.
Итак, мы нашли точку входа, которая может быть источником уязвимости. Следующий шаг — найти все попытки использовать эту переменную в потенциально небезопасных контекстах. В примере выше значение из переменной используется при формировании ответа сервера и делает приложение уязвимым к XSS; использование ее при генерации SQL-запроса означало бы всем известную SQL-инъекцию. Использование такой переменной в имени файла могло бы дать атакующему доступ к файловой системе и так далее.
Для обнаружения потенциально небезопасных вызовов детектор поступает здесь по аналогии с tainted: ищет по заранее известному списку сигнатур и обозначает как sink, от английского «просачиваться», «проникать».

И если в анализируемом приложении существует путь от tainted к sink, то можно сделать вывод о наличии потенциальной уязвимости.
Предположим, что мы исправили уязвимость и экранируем все специальные html символы впараметре foo, что делает его дальнейшее использование безопасным. На этот случай у анализатора есть ещё и список сигнатур санитайзеров — методов, которые очищают данные. Они прерывают цепочку между tainted и sink. То есть, если на пути от tainted к sink у нас встречается метод, очищающий данные, то предупреждения об уязвимости быть не должно.

Казалось бы у нас есть, всё, чтобы искать уязвимости в нашем коде.
Как всегда, всё не так просто, как выглядит. К сожалению, у статического анализа есть ряд ограничений. Два самых досадных для мира web-приложений рассмотрим ниже.
Первое — использование reflection. Reflection активно используется в Dependency Injection-фреймворках и не только, мешая статическому анализатору построить граф потока управления и, соответственно, провести taint analysis.

Понятно, почему это происходит. Cтатический анализатор не понимает, что в приведенном фрагменте кода вызывается метод bar(). Соответственно, если метод bar() включен в какой-то список сигнатур sink, то анализатор не поймет, что он был вызван.
Эту проблему можно частично решить добавлением дополнительных правил, учитывающих особенности конкретного проекта
Другим ограничением для статического анализа является генерация исходного кода во время исполнения программы
Если мы говорим про web-приложения, то самый распространенный пример — это шаблонизаторы. В отличии от JSP, которые прекомпилируются в Java-код и могут быть проанализированы, современные шаблонизаторы — это статические HTML-файлы с возможностью включения вычисляемых выражений. Эти выражения вычисляются в рантайме и результаты подставляются в шаблон.
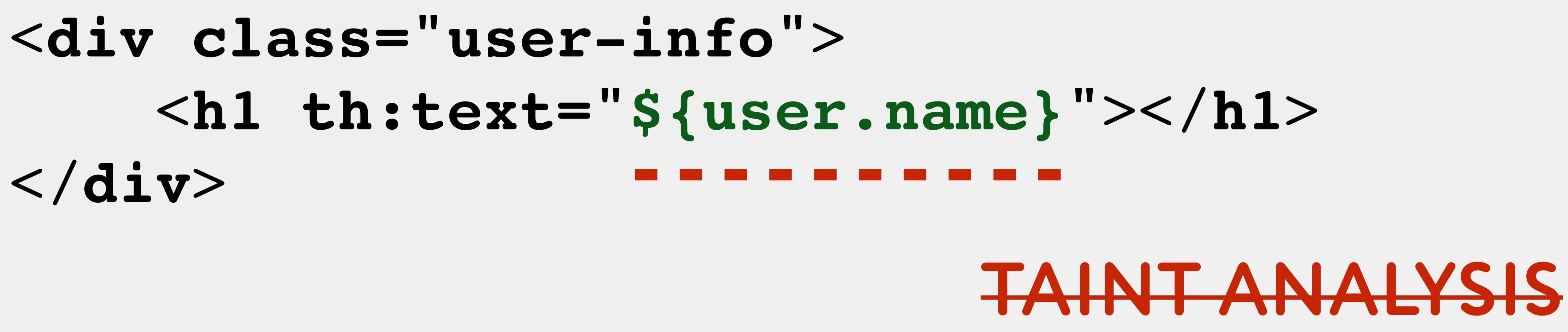
В этом случае мы не можем отследить цепочку вызовов, и taint analysis, вероятно, будет неполным.
Выбираем статический анализатор
Статических анализаторов для Java много: есть и проекты в опенсорс, и коммерческие продукты. Нужно определиться с требованиями к инструменту. Вот такие пожелания сформулировали мы:
- Первое очевидно: поддержка тех технологий, которые мы используем. В Одноклассниках мы пишем на Java, у нас есть JavaScript и TypeScript, а ещё мы хотим сканировать мобильные приложения, поэтому нужна поддержка Android-а.
- Второе: мы однозначно хотим taint analysis. Как мы только что выяснили, эта штука нужна, чтобы находить инъекции и подобные им баги, а они составляют значительную часть всех проблем.
- Мы поняли, что не ограничимся набором стандартных правил, потому что в нашем коде есть конструкции, которые статический анализатор «из коробки» не понимает, возможность кастомизации правил нам важна.
- Хотим, чтобы у разработчиков была единая «точка правды» про наш статический анализ: чтобы все использовали одну и ту же версию правил, знали статус сканирования на данный момент, видели какие из найденных ошибок являются ложными срабатываниями, а какие настоящими багами. В общем, нам нужен collaboration сервер.
- Наконец, мы хотим, чтобы добавление двух строчек кода в наш проект не повлекло необходимость переделывать всё. Если мы уже разобрали результаты сканирования на настоящие баги и ложные срабатывания, то следующее сканирование с небольшими изменениями позволяло бы переиспользовать предыдущие результаты.
В открытом доступе можно найти исследования, сравнивающие различные статические анализаторы. Посмотрим на одно из них, сделанное проектом OWASP (Open Web Application Security Project) в 2016-м (https://github.com/OWASP/benchmark). OWASP написал бенчмарк — приложение на Java с уязвимостями в заранее известных местах и просканировал его несколькими сканерами. Результат ниже:
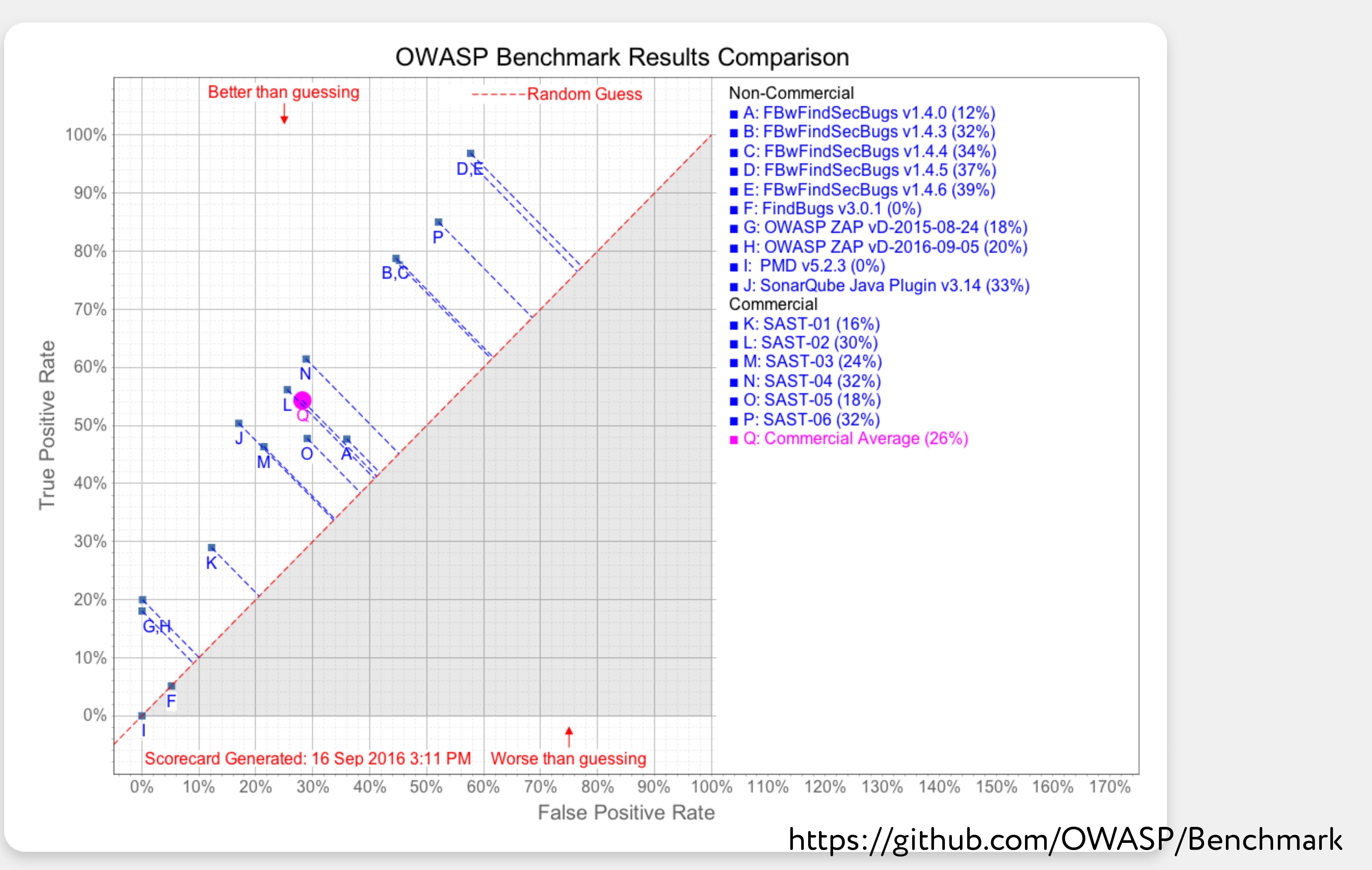
Диаграмму не назвать интуитивно понятной, но разберёмся, что здесь изображено. Красная пунктирная линия — это результат, соответствующий случайному угадыванию. Все, что выше этой линии — лучше.
Также диаграмме можно заметить взаимосвязь между полнотой (сколько из всех багов было найдено) и точностью (сколько из найденного действительно является багами) анализатора. Сканеры с меньшим количеством ложных срабатываний пропускали больше багов.
Если это учесть, то мы видим, что все инструменты дают примерно одинаковый результат, нет явного лидера. У всех по-разному настроен баланс между настоящими уязвимостями и ложными срабатываниями, а в целом соотношение примерно одинаковое. Явного лидера нет, и коммерческие сканеры не показывают принципиально другие результаты по сравнению с опенсорсными.
Также OWASP протестировал один и тот же сканер Find Security Bugs с разными наборами правил, и в этом случае видно, что чем больше правил, тем больше уязвимостей обнаруживается. То есть добавление правил очевидно приносит результат.
Какой вывод мы можем сделать? Вероятно, выбор движка в статическом анализаторе не так важен для нас, как мощность набора правил и возможность дописывать детекторы под свои нужды.
Мы решили использовать опенсорсный Find Security Bugs. Это плагин для всем известного статического анализатора для Java, который раньше назывался FindBugs, а теперь называется SpotBugs. Find Security Bugs добавляет разнообразные детекторы, связанные с безопасностью, в том числе и для Android.
Также это единственный опенсорсный анализатор для Java, позволяющий добавлять свои правила taint analysis.
Всё, что связано с коллаборацией, с работой внутри команды и с серверной частью нашего инструмента, отдано SonarQube. У Find Security Bugs есть плагин для SonarQube, позволяющий загружать отчеты на сервер и управлять результатами сканирования.
Практика
Давайте попробуем применить описанное на практике. Для примера — уязвимое веб приложение на Spring и Thymeleaf.
Я специально выбрала фреймворки, которые в стандартном наборе правил Find Security Bugs не поддерживаются, чтобы мы могли написать свои детекторы. Код примеров есть на GitHub.
Пример 1
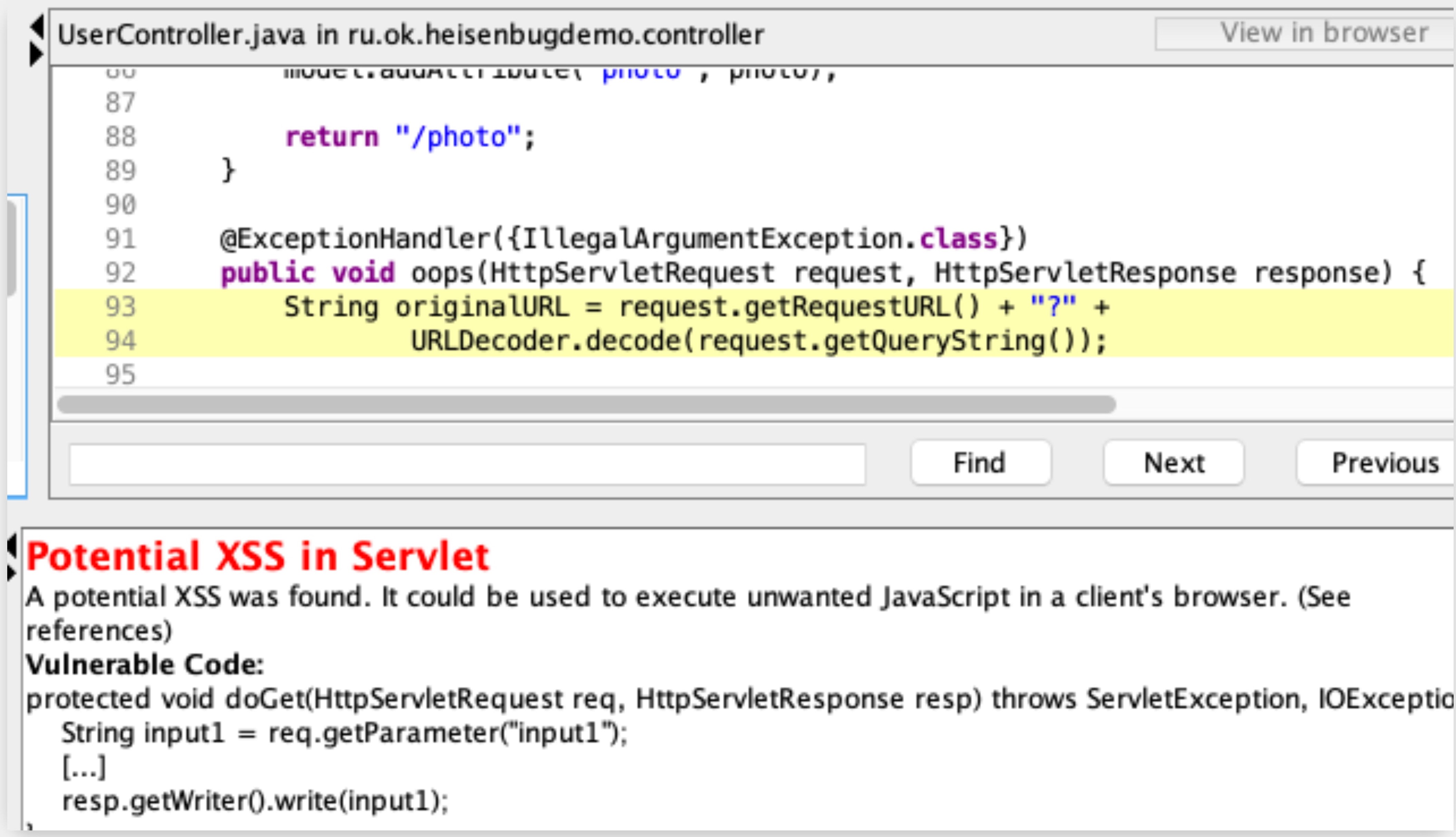
В посте уже упоминался такой баг — это XSS, использование значения из параметра запроса при формировании HTML-разметки.
@ExceptionHandler({IllegalArgumentException.class})
public void oops(HttpServletRequest request, HttpServletResponse response) {
String originalURL = request.getRequestURL() + "?" +
URLDecoder.decode(request.getQueryString());
// ...
PrintWriter writer = response.getWriter();
writer.write("<h1>Error procesing page " + originalURL + "</h1>");
writer.flush();
// …
}Мы уже знаем, как работают статические анализаторы.
originalURL будет отмечен как tainted, потому что request.getQueryString() использует значение из HttpServletRequest без предварительной проверки.
А в writer.write() у нас есть sink, потому что мы записываем “испорченное” значение в тело ответа.
Запускаем анализатор, и он готовит отчет, где действительно указано, что в этих строках содержится потенциальная уязвимость:
Пример 2
@GetMapping("/photo")
public String photo(@RequestParam("id") long id, Model model) {
Photo photo = photoRepository.findOne(id);
// …
m.addAttribute("photo", photo)
// …
return "/photo";
}
<div th:each="comment : ${photo.comments}">
<p th:utext="${comment.text}"></p>
</div>Здесь у нас Spring endpoint, который выводит пользователю фотографию с комментариями. Статический анализатор не находит проблемы. Но действительно ли всё нормально в этом коде?
На самом деле нет. Вызов photoRepository.findOne(id) может вернуть данные, содержащие пользовательский ввод, то есть это taint. Дальше эти значения используются в шаблоне небезопасным способом (th:utext выводит строку без изменений). Если в тексте комментария будут HTML-теги, они сломают разметку и будут интерпретированы браузером HTML.
Поможем Find Security Bugs найти уязвимость в этом коде.
В данном случае можно придумать два варианта детектора.
Первый: можем сказать нашему анализатору, что вообще все попытки вывести в шаблонах какой-то текст без экранирования (то есть все упоминания «ph:utext») — это потенциальные уязвимости. Мы, вероятно, найдем все уязвимости и ещё какое-то количество ложных срабатываний.
Другой способ: искать все попытки добавить непроверенные данные в контекст шаблонизатора.
Добавим правило, помечающее addAttribute() как sink, и тогда наш анализатор сможет построить цепочку вызовов от taint к sink и отследить потенциальные уязвимости.
Find Security Bugs позволяет нам задавать списки этих сигнатур в конфиг файле. Мы можем просто передать ему файл с сигнатурами этих методов. Вызов Find Security Bugs и cодержимое файла может выглядеть так:

В нижней строке описан sink — метод addAttribute(). Здесь есть полное имя класса, название метода, список аргументов, тип возвращаемого значения, а также указан номер аргумента, в который, собственно, и нельзя передавать “испорченные” значения.
Очень хорошо, что Find Security Bugs не заставляет нас писать такие строки руками, а предоставляет калькулятор, который позволяет генерировать эти сигнатуры из Java-интерфейсов.
Пример 3
@GetMapping("/photo")
public String photo(@RequestParam("id") long id, Model model) {
Photo photo = photoRepository.findOne(id);
// …
model.addAttribute("photo", photo);
return "/photo";
}У нас снова Spring endpoint, который показывает фотографию пользователю. Есть ли проблема в этом фрагменте кода?
Да! Мы забыли проверить права доступа, разрешено ли текущему пользователю просматривать фотографию. Возникает IDOR — Insecure Direct Object Reference.
Вот так выглядело бы исправление этого бага:
@GetMapping("/photo")
public String photo(@RequestParam("id") long id, Model model) {
Photo photo = photoRepository.findOne(id);
// …
User currentUser = getCurrentUser = getCurrentUser();
if (!canAccess(currentUser, author)) {
return "/error/302";
}
model.addAttribute("user", author);
model.addAttribute("photo", photo);
return "/photo";
}Вопрос: можем ли научить статический анализатор искать такие уязвимости? Недостаточный контроль доступа, кажется, тесно связан с бизнес-логикой приложения, и не получится написать универсальный детектор для подобного рода проблем. У нас нет единого способа объяснить анализатору, что такое контроль доступа и как именно он реализован в нашей системе.
Но мы можем проверить соблюдение в нашем коде определенных, оговоренных заранее правил авторизации и контроля доступа, когда мы уже знаем как они реализованы в этом конкретном приложении.
В данном случае, можно сказать «анализатор, найди, пожалуйста, все Spring endpoint-ы и проверь, что каждый из них вызывает метод canAccess(). А если не вызывает, то это и есть потенциальная уязвимость».
Давайте попробуем такое правило написать. Правило для Find Security Bugs — это программа на Java.
import edu.umd.cs.findbugs.Detector;
public class IdorDetector implements Detector {
@Override
public void vistClassContext(ClassContext classContext) {
}
@Override
public void report() {
}
}В Find Security Bugs все детекторы должны реализовывать интерфейс Detector. Библиотека содержит некоторое количество базовых детекторов, которые можно переиспользовать, но мы попробуем написать правило с нуля.
Итак, нам нужно реализовать два метода: visitClassContext(), который будет осуществлять анализ, и report(), сообщающий о проблеме, если она найдена.
Как найти баг из примера? Как сказано выше, найдём все Spring endpoint-ы и проверим, что каждый из них вызывает метод, реализующий контроль доступа:
public void visitClassContext(ClassContext classContext) {
List<Method> endpoints = findEndpoints(classContext);
for (Method m : endpoint) {
checkCanAccessCalled(classContext, m);
}Как найти все Spring endpoint-ы? А как это делает сам Spring? Найдем все методы, отмеченные соответствующими аннотациями.
REQUEST_MAPPING_ANNOTATION_TYPES = Arrays.asList(
"Lorg/springframework/web/bind/annotation/GetMapping;",
"Lorg/springframework/web/bind/annotation/PostMapping;",
// …
private List<Method> findEndpoints(JavaClass javaClass) {
// …
for (Method m : javaClass.getMethods()) {
for (AnnotationEntry ae : m.getAnnotationEntries())) {
if (REQUEST_MAPPING_ANNOTATION_TYPES
.contains(ae.getAnnotationType())) {
endpoints.add(m);
}
}
}
// …Перечисляем все аннотации, которые используют Spring (их на самом деле больше, я опустила часть для краткости). Получаем от анализатора абстрактное синтаксическое дерево, в нём выбираем все методы всех классов и проверяем, есть ли в этих методах нужные аннотации. Если есть, добавляем в список для проверки.
Остаётся проверить каждый метод. Как мы это делаем? Вспоминаем о control flow graph, то есть получаем описание порядка выполнения инструкций в нашем коде.
private void checkCanAccessCalled(ClassContext classContext, Method m) {
// …
CFG cfg = classContext.getCFG(m);
for (Iterator<Location> i = cfg.locationIterator(); i.hasNext(); ) {
Instruction inst = i.next().getHandle().getInstruction();
if (inst instanceof INVOKESPECIAL) {
if (CAN_ACCESS_METHOD_NAME.equals(invoke.getMethodName(cpg)) &&
className.equals(invoke.getClassName(cpg» {
found = true;
}
}
}
// ...Получаем CFG для каждого endpoint-а и проверяем в нём каждую инструкцию. Для всех вызов методов, проверяем не совпадает ли название с искомым.
// ...
if (!found) {
bugReporter.reportBug(
new BugInstance(this, "IDOR", Priorities.NORMAL_PRIORITY)
.addClass(javaClass)
.addMethod(javaClass, method));
}
// ...Для всех endpoint, в которых его не нашли, рапортуем возможную уязвимость.
Find Security Bugs предоставляет возможность управлять приоритетами багов в отчете, делить баги на категории, указывать для каждой категории описание в свободной форме.
Всё, детектор готов. Если запустим его, то отчет действительно будет содержать уязвимый метод.
Но идеален ли наш детектор?
Кроме реальных уязвимостей, он, вероятно, будет генерировать ещё какое-то количество ложных срабатываний.
Рассмотрим примеры конструкций, которые наш детектор ошибочно примет за уязвимости:
Наследование контроллеров:
public abstract class BaseController {
protected boolean canAccess() {
return false;
}
}
public class Controller extends BaseController {
@GetMapping("foo")
public String foo() {
//…
canAccess()
//...
}Вложенные вызовы:
public class Controller {
private boolean canAccess() {
//…
}
private boolean canAccessEx() {
canAccess()
//…
}
@GetMapping("foo")
public String foo() {
//…
canAccessEx()
//…
}
}Ветвление:
public class Controller {
private boolean canAccess() {
//…
}
private boolean canAccessEx() {
if (x) {
canAccess()
} else {
//…
}
//…
}
@GetMapping("foo")
public String foo() {
//…
canAccessEx()
//…
}
}Предлагаю тебе, хабраюзер, в качестве упражнения самостоятельно исправить код детектора так, чтобы учесть приведенные выше примеры :).
Выводы
Не отменяя необходимости динамического тестирования безопасности, статический анализ позволяет быстрее и дешевле, чем динамические сканеры, находить типовые уязвимости в коде.
К сожалению, в реальном мире результаты работы сканера “из коробки” не всегда имеют ожидаемое качество, что приводит к необходимости добавления новых, специфичных для приложения, правил анализа.
Опенсорсный Find Security Bugs предоставляет и набор стандартных правил, и фреймворк для разработки собственных, что делает статическое тестирование безопасности доступным для всех проектов на Java.
Немного полезных ссылок напоследок:
- Страница OWASP о статическом анализе
- Find Security Bugs
- Руководство Find Security Bugs по написанию своего детектора
- О taint analysis в FindBugs
- Common Weakness Enumeration
- OWASP Application Security Verification Standard Project



")