
Утилита Webalizer и инструмент Google Analytics помогали мне много лет получать представление о том, что происходит на веб сайтах. Сейчас я понимаю, что они дают очень мало полезной информации. Имея доступ к своему файлу access.log, разобраться со статистикой очень просто и для реализации достаточно элементарных инструментов, таких как sqlite, html, языка sql и любого скриптового языка программирования.
Источником данных для Webalizer является файл access.log сервера. Так выглядят его столбики и цифры, из которых понятен лишь общий объём трафика:

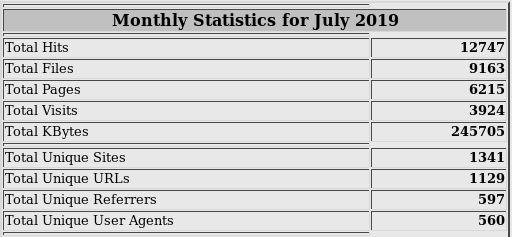
Такие инструменты, как Google Analytics собирают данные с загруженной страницы самостоятельно. Отображают нам пару диаграмм и линий, на основе которых часто сложно сделать правильные выводы. Может быть, нужно было приложить больше усилий? Не знаю.
Итак, что мне хотелось увидеть в статистике посещений сайта?
Часто трафик сайтов имеет ограничение и необоходимо видеть, сколько полезного трафика используется. Например, так:
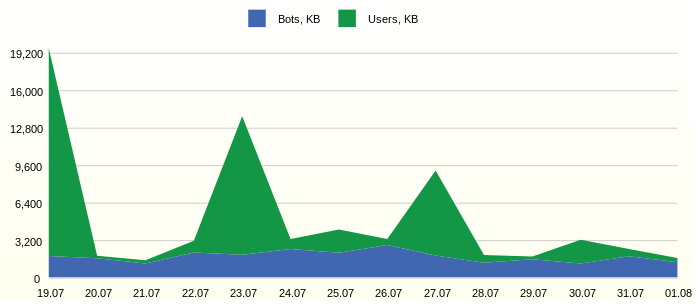
Из графика видна постоянная активность ботов. Интересно было бы детально изучить наиболее активных представителей.
Классифицируем ботов на основе информации пользовательского агента. Дополнительная статистика о дневном трафике, количестве успешных и безуспешных запросов даёт хорошее представление об активности ботов.
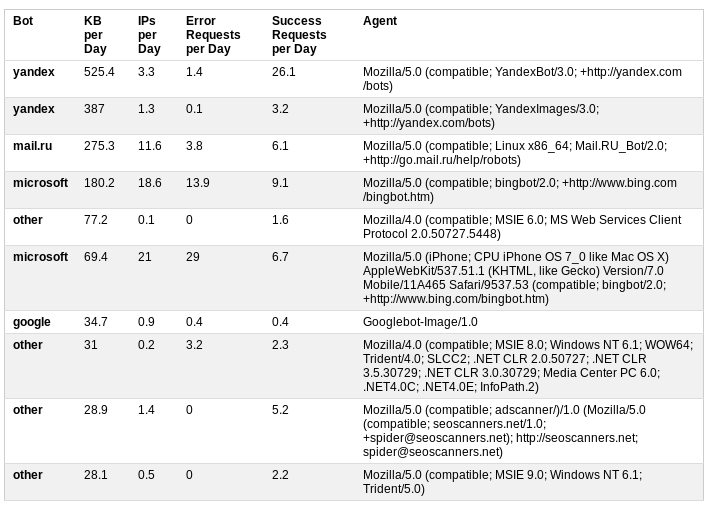
В данном случае результатом анализа стало решение об ограничении доступа к сайту путём добавления в файл robots.txt
Первые два бота исчезли из таблицы, а роботы MS подвинулись с первых строчек вниз.
В трафике видны подъёмы. Чтобы детально их исследовать, необходимо выделить время их возникновения, при этом не обязательно отображать все часы и дни измерения времени. Так будет проще найти отдельные запросы в лог файле, при необходимости детального анализа.
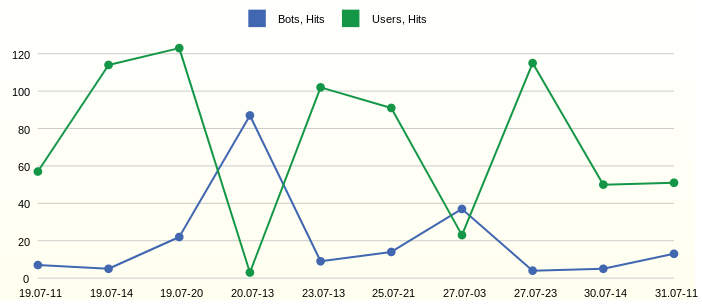
Наблюдаем самые активные часы 11, 14 и 20 первого дня на графике. А вот на следующий день в 13 часов активничали боты.
С активностью и трафиком немного разобрались. Следующим вопросом была активность самих пользователей. Для такой статистики желательны большие периоды агрегации, например, неделя
Статистика за неделю показывает, что в среднем один пользователь открывает 1,6 страниц в день. Количество запрашиваемых файлов на одного пользователя, в данном случае, зависит от добавления новых файлов на сайт.
Webalizer всегда показывал конкретные коды страниц и хотелось всегда видеть просто количество успешных запросов и ошибок.
Из графика можно увидеть много ошибок — это не существующие страницы. Результатом анализа стало добавление перенаправлений с удалённых страниц.
Для детального рассмотрения запросов можно вывести детальную статистику
В этом списке будут находиться и все прозвоны, например, запрос к /wp-login.php Путём корректировки правил переписывания запросов сервером, можно скорректировать реакцию сервера на подобные запросы и отправлять их на стартовую страницу.
Итак, несколько простых отчётов на основе файла лога сервера дают достаточно полную картину того, что происходит на сайте.
Базы данных sqlite вполне достаточно. Создадим таблицы: вспомогательную для логирования ETL процессов.

Стейдж таблицы, куда будем писать лог файлы средствами PHP.
Две таблицы агрегатов. Создадим дневную таблицу со статистикой по пользовательским агентам и статусам запросов.
По-часовую со статистикой по запросам, группам статусов и агентов.
Четыре таблицы соответсвующих измерений.
В результате, получилась следующая модель:
В случае с access.log файлом необходимо прочитать, распарсить и записать в базу все запросы. Это можно сделать либо напрямую средствами скриптового языка, либо используя средства sqlite
Формат лог файла:
Когда сырые данные находятся в базе, нужно записать в таблицы измерений ключи, которых там нет. Тогда будет возможным построение ссылки на измерения. Например, в таблице DIM_REFERRER ключём является комбинация трёх полей.
Пропагация в таблицу пользовательских агентов может содержать логику ботов, например, отрывок sql
В последнюю очередь будем грузить таблицы агрегатов, например, дневная таблица может загружаться следующим образом
База данных sqlite позволяет писать сложные запросы. WITH содержит подготовку данных и ключей. Основной запрос собирает все ссылки на измерения.
Условие не даст загрузить ещё раз историю: CAST(STG.EVENT_DT AS INTEGER) > $param_epoch_from, где параметр является результатом запроса
'SELECT COALESCE(MAX(EVENT_DT), \'3600\') AS LAST_EVENT_EPOCH FROM FCT_ACCESS_USER_AGENT_DD'
Условие загрузит только полный день: CAST(STG.EVENT_DT AS INTEGER) < strftime('%s', date('now', 'start of day'))
Подсчёт страниц или файлов осуществляется примитивным способом, поиском точки.
В сложных системах визуализации есть возможность создавать мета-модель на основе объектов базы данных, динамически управлять фильтрами и правилами агрегации. В конечном счёте, все приличные инструменты генерируют SQL запрос.
В данном примере мы создадим уже готовые SQL запросы и сохраним их в виде вью в базе данных — это и есть отчёты.
В качестве инструмента визуализации использовался Bluff: Beautiful graphs in JavaScript
Для этого потребовалось с помощью PHP пробежаться по всем репортам и сгенерировать html файл с таблицами.
Инструмент просто визуализирует таблицы результатов.
На примере веб анализа статья описывает механизмы, необходимые для построения хранилищ данных. Как видно из результатов, для глубокого анализа и визуализации данных достаточно самых простых инструментов.
В дальнейшем, на примере этого хранилища, попробуем реализовать такие структуры, как медленно изменяющиеся измерения, метаданные, уровни агрегации и интеграцию данных из разных источников.
Также, подробнее рассмотрим простейший инструмент управления ETL процессами на основе одной таблицы.
Вернемся к теме измерения качества данных и автоматизации этого процесса.
Изучим проблемы технического окружения и обслуживания хранилищ данных, для чего реализуем сервер хранилища с минимальными ресурсами, например, на базе Raspberry Pi.
Источником данных для Webalizer является файл access.log сервера. Так выглядят его столбики и цифры, из которых понятен лишь общий объём трафика:
Такие инструменты, как Google Analytics собирают данные с загруженной страницы самостоятельно. Отображают нам пару диаграмм и линий, на основе которых часто сложно сделать правильные выводы. Может быть, нужно было приложить больше усилий? Не знаю.
Итак, что мне хотелось увидеть в статистике посещений сайта?
Трафик пользователей и ботов
Часто трафик сайтов имеет ограничение и необоходимо видеть, сколько полезного трафика используется. Например, так:
SQL запрос репорта
SELECT
1 as 'StackedArea: Traffic generated by Users and Bots',
strftime('%d.%m', datetime(FCT.EVENT_DT, 'unixepoch')) AS 'Day',
SUM(CASE WHEN USG.AGENT_BOT!='n.a.' THEN FCT.BYTES ELSE 0 END)/1000 AS 'Bots, KB',
SUM(CASE WHEN USG.AGENT_BOT='n.a.' THEN FCT.BYTES ELSE 0 END)/1000 AS 'Users, KB'
FROM
FCT_ACCESS_USER_AGENT_DD FCT,
DIM_USER_AGENT USG
WHERE FCT.DIM_USER_AGENT_ID=USG.DIM_USER_AGENT_ID
AND datetime(FCT.EVENT_DT, 'unixepoch') >= date('now', '-14 day')
GROUP BY strftime('%d.%m', datetime(FCT.EVENT_DT, 'unixepoch'))
ORDER BY FCT.EVENT_DTИз графика видна постоянная активность ботов. Интересно было бы детально изучить наиболее активных представителей.
Назойливые боты
Классифицируем ботов на основе информации пользовательского агента. Дополнительная статистика о дневном трафике, количестве успешных и безуспешных запросов даёт хорошее представление об активности ботов.
SQL запрос репорта
SELECT
1 AS 'Table: Annoying Bots',
MAX(USG.AGENT_BOT) AS 'Bot',
ROUND(SUM(FCT.BYTES)/1000 / 14.0, 1) AS 'KB per Day',
ROUND(SUM(FCT.IP_CNT) / 14.0, 1) AS 'IPs per Day',
ROUND(SUM(CASE WHEN STS.STATUS_GROUP IN ('Client Error', 'Server Error') THEN FCT.REQUEST_CNT / 14.0 ELSE 0 END), 1) AS 'Error Requests per Day',
ROUND(SUM(CASE WHEN STS.STATUS_GROUP IN ('Successful', 'Redirection') THEN FCT.REQUEST_CNT / 14.0 ELSE 0 END), 1) AS 'Success Requests per Day',
USG.USER_AGENT_NK AS 'Agent'
FROM FCT_ACCESS_USER_AGENT_DD FCT,
DIM_USER_AGENT USG,
DIM_HTTP_STATUS STS
WHERE FCT.DIM_USER_AGENT_ID = USG.DIM_USER_AGENT_ID
AND FCT.DIM_HTTP_STATUS_ID = STS.DIM_HTTP_STATUS_ID
AND USG.AGENT_BOT != 'n.a.'
AND datetime(FCT.EVENT_DT, 'unixepoch') >= date('now', '-14 day')
GROUP BY USG.USER_AGENT_NK
ORDER BY 3 DESC
LIMIT 10В данном случае результатом анализа стало решение об ограничении доступа к сайту путём добавления в файл robots.txt
User-agent: AhrefsBot
Disallow: /
User-agent: dotbot
Disallow: /
User-agent: bingbot
Crawl-delay: 5Первые два бота исчезли из таблицы, а роботы MS подвинулись с первых строчек вниз.
День и время наибольшей активности
В трафике видны подъёмы. Чтобы детально их исследовать, необходимо выделить время их возникновения, при этом не обязательно отображать все часы и дни измерения времени. Так будет проще найти отдельные запросы в лог файле, при необходимости детального анализа.
SQL запрос репорта
SELECT
1 AS 'Line: Day and Hour of Hits from Users and Bots',
strftime('%d.%m-%H', datetime(EVENT_DT, 'unixepoch')) AS 'Date Time',
HIB AS 'Bots, Hits',
HIU AS 'Users, Hits'
FROM (
SELECT
EVENT_DT,
SUM(CASE WHEN AGENT_BOT!='n.a.' THEN LINE_CNT ELSE 0 END) AS HIB,
SUM(CASE WHEN AGENT_BOT='n.a.' THEN LINE_CNT ELSE 0 END) AS HIU
FROM FCT_ACCESS_REQUEST_REF_HH
WHERE datetime(EVENT_DT, 'unixepoch') >= date('now', '-14 day')
GROUP BY EVENT_DT
ORDER BY SUM(LINE_CNT) DESC
LIMIT 10
) ORDER BY EVENT_DTНаблюдаем самые активные часы 11, 14 и 20 первого дня на графике. А вот на следующий день в 13 часов активничали боты.
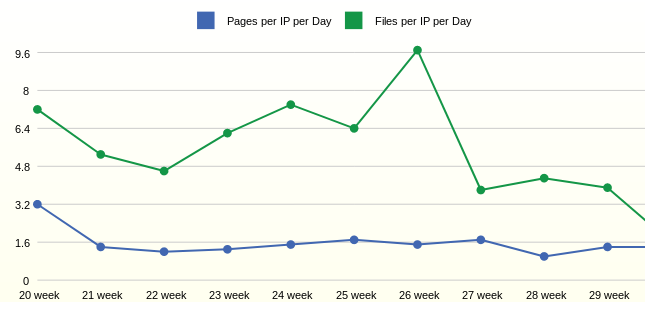
Средняя дневная активность пользователей по неделям
С активностью и трафиком немного разобрались. Следующим вопросом была активность самих пользователей. Для такой статистики желательны большие периоды агрегации, например, неделя
SQL запрос репорта
SELECT
1 as 'Line: Average Daily User Activity by Week',
strftime('%W week', datetime(FCT.EVENT_DT, 'unixepoch')) AS 'Week',
ROUND(1.0*SUM(FCT.PAGE_CNT)/SUM(FCT.IP_CNT),1) AS 'Pages per IP per Day',
ROUND(1.0*SUM(FCT.FILE_CNT)/SUM(FCT.IP_CNT),1) AS 'Files per IP per Day'
FROM
FCT_ACCESS_USER_AGENT_DD FCT,
DIM_USER_AGENT USG,
DIM_HTTP_STATUS HST
WHERE FCT.DIM_USER_AGENT_ID=USG.DIM_USER_AGENT_ID
AND FCT.DIM_HTTP_STATUS_ID = HST.DIM_HTTP_STATUS_ID
AND USG.AGENT_BOT='n.a.' /* users only */
AND HST.STATUS_GROUP IN ('Successful') /* good pages */
AND datetime(FCT.EVENT_DT, 'unixepoch') > date('now', '-3 month')
GROUP BY strftime('%W week', datetime(FCT.EVENT_DT, 'unixepoch'))
ORDER BY FCT.EVENT_DTСтатистика за неделю показывает, что в среднем один пользователь открывает 1,6 страниц в день. Количество запрашиваемых файлов на одного пользователя, в данном случае, зависит от добавления новых файлов на сайт.
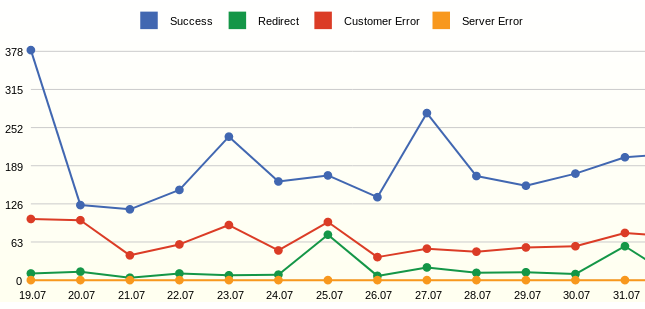
Все запросы и их статусы
Webalizer всегда показывал конкретные коды страниц и хотелось всегда видеть просто количество успешных запросов и ошибок.
SQL запрос репорта
SELECT
1 as 'Line: All Requests by Status',
strftime('%d.%m', datetime(FCT.EVENT_DT, 'unixepoch')) AS 'Day',
SUM(CASE WHEN STS.STATUS_GROUP='Successful' THEN FCT.REQUEST_CNT ELSE 0 END) AS 'Success',
SUM(CASE WHEN STS.STATUS_GROUP='Redirection' THEN FCT.REQUEST_CNT ELSE 0 END) AS 'Redirect',
SUM(CASE WHEN STS.STATUS_GROUP='Client Error' THEN FCT.REQUEST_CNT ELSE 0 END) AS 'Customer Error',
SUM(CASE WHEN STS.STATUS_GROUP='Server Error' THEN FCT.REQUEST_CNT ELSE 0 END) AS 'Server Error'
FROM
FCT_ACCESS_USER_AGENT_DD FCT,
DIM_HTTP_STATUS STS
WHERE FCT.DIM_HTTP_STATUS_ID=STS.DIM_HTTP_STATUS_ID
AND datetime(FCT.EVENT_DT, 'unixepoch') >= date('now', '-14 day')
GROUP BY strftime('%d.%m', datetime(FCT.EVENT_DT, 'unixepoch'))
ORDER BY FCT.EVENT_DTИз графика можно увидеть много ошибок — это не существующие страницы. Результатом анализа стало добавление перенаправлений с удалённых страниц.
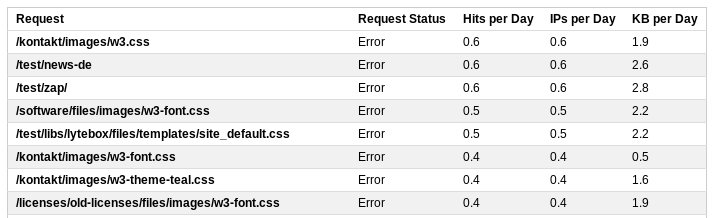
Ошибочные запросы
Для детального рассмотрения запросов можно вывести детальную статистику
SQL запрос репорта
SELECT
1 AS 'Table: Top Error Requests',
REQ.REQUEST_NK AS 'Request',
'Error' AS 'Request Status',
ROUND(SUM(FCT.LINE_CNT) / 14.0, 1) AS 'Hits per Day',
ROUND(SUM(FCT.IP_CNT) / 14.0, 1) AS 'IPs per Day',
ROUND(SUM(FCT.BYTES)/1000 / 14.0, 1) AS 'KB per Day'
FROM
FCT_ACCESS_REQUEST_REF_HH FCT,
DIM_REQUEST_V_ACT REQ
WHERE FCT.DIM_REQUEST_ID = REQ.DIM_REQUEST_ID
AND FCT.STATUS_GROUP IN ('Client Error', 'Server Error')
AND datetime(FCT.EVENT_DT, 'unixepoch') >= date('now', '-14 day')
GROUP BY REQ.REQUEST_NK
ORDER BY 4 DESC
LIMIT 20В этом списке будут находиться и все прозвоны, например, запрос к /wp-login.php Путём корректировки правил переписывания запросов сервером, можно скорректировать реакцию сервера на подобные запросы и отправлять их на стартовую страницу.
Итак, несколько простых отчётов на основе файла лога сервера дают достаточно полную картину того, что происходит на сайте.
Как получить информацию?
Базы данных sqlite вполне достаточно. Создадим таблицы: вспомогательную для логирования ETL процессов.
Стейдж таблицы, куда будем писать лог файлы средствами PHP.
Две таблицы агрегатов. Создадим дневную таблицу со статистикой по пользовательским агентам и статусам запросов.
По-часовую со статистикой по запросам, группам статусов и агентов.
Четыре таблицы соответсвующих измерений.
В результате, получилась следующая модель:
Модель данных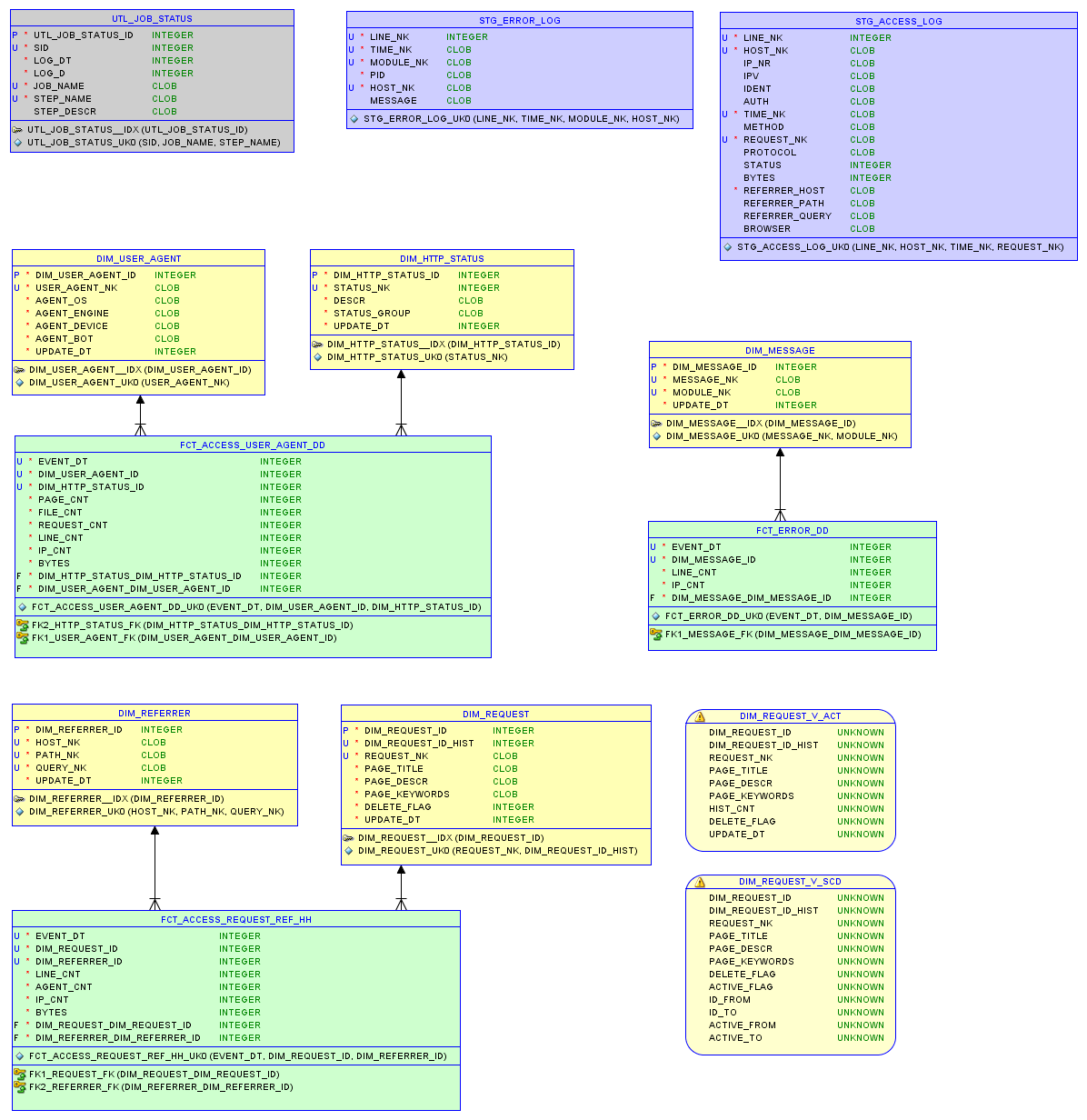
Стейдж
В случае с access.log файлом необходимо прочитать, распарсить и записать в базу все запросы. Это можно сделать либо напрямую средствами скриптового языка, либо используя средства sqlite
Формат лог файла:
//67.221.59.195 - - [28/Dec/2012:01:47:47 +0100] "GET /files/default.css HTTP/1.1" 200 1512 "https://project.edu/" "Mozilla/4.0"
//host ident auth time method request_nk protocol status bytes ref browser
$log_pattern = '/^([^ ]+) ([^ ]+) ([^ ]+) (\[[^\]]+\]) "(.*) (.*) (.*)" ([0-9\-]+) ([0-9\-]+) "(.*)" "(.*)"$/';
Пропагация ключей
Когда сырые данные находятся в базе, нужно записать в таблицы измерений ключи, которых там нет. Тогда будет возможным построение ссылки на измерения. Например, в таблице DIM_REFERRER ключём является комбинация трёх полей.
/* Propagate the referrer from access log */
INSERT INTO DIM_REFERRER (HOST_NK, PATH_NK, QUERY_NK, UPDATE_DT)
SELECT
CLS.HOST_NK,
CLS.PATH_NK,
CLS.QUERY_NK,
STRFTIME('%s','now') AS UPDATE_DT
FROM (
SELECT DISTINCT
REFERRER_HOST AS HOST_NK,
REFERRER_PATH AS PATH_NK,
CASE WHEN INSTR(REFERRER_QUERY,'&sid')>0 THEN SUBSTR(REFERRER_QUERY, 1, INSTR(REFERRER_QUERY,'&sid')-1) /* отрезаем sid - специфика цмс */
ELSE REFERRER_QUERY END AS QUERY_NK
FROM STG_ACCESS_LOG
) CLS
LEFT OUTER JOIN DIM_REFERRER TRG
ON (CLS.HOST_NK = TRG.HOST_NK AND CLS.PATH_NK = TRG.PATH_NK AND CLS.QUERY_NK = TRG.QUERY_NK)
WHERE TRG.DIM_REFERRER_ID IS NULLПропагация в таблицу пользовательских агентов может содержать логику ботов, например, отрывок sql
CASE
WHEN INSTR(LOWER(CLS.BROWSER),'yandex.com')>0
THEN 'yandex'
WHEN INSTR(LOWER(CLS.BROWSER),'googlebot')>0
THEN 'google'
WHEN INSTR(LOWER(CLS.BROWSER),'bingbot')>0
THEN 'microsoft'
WHEN INSTR(LOWER(CLS.BROWSER),'ahrefsbot')>0
THEN 'ahrefs'
WHEN INSTR(LOWER(CLS.BROWSER),'mj12bot')>0
THEN 'majestic-12'
WHEN INSTR(LOWER(CLS.BROWSER),'compatible')>0 OR INSTR(LOWER(CLS.BROWSER),'http')>0
OR INSTR(LOWER(CLS.BROWSER),'libwww')>0 OR INSTR(LOWER(CLS.BROWSER),'spider')>0
OR INSTR(LOWER(CLS.BROWSER),'java')>0 OR INSTR(LOWER(CLS.BROWSER),'python')>0
OR INSTR(LOWER(CLS.BROWSER),'robot')>0 OR INSTR(LOWER(CLS.BROWSER),'curl')>0 OR INSTR(LOWER(CLS.BROWSER),'wget')>0
THEN 'other'
ELSE 'n.a.' END AS AGENT_BOTТаблицы агрегатов
В последнюю очередь будем грузить таблицы агрегатов, например, дневная таблица может загружаться следующим образом
/* Load fact from access log */
INSERT INTO FCT_ACCESS_USER_AGENT_DD (EVENT_DT, DIM_USER_AGENT_ID, DIM_HTTP_STATUS_ID, PAGE_CNT, FILE_CNT, REQUEST_CNT, LINE_CNT, IP_CNT, BYTES)
WITH STG AS (
SELECT
STRFTIME( '%s', SUBSTR(TIME_NK,9,4) || '-' ||
CASE SUBSTR(TIME_NK,5,3)
WHEN 'Jan' THEN '01' WHEN 'Feb' THEN '02' WHEN 'Mar' THEN '03' WHEN 'Apr' THEN '04' WHEN 'May' THEN '05' WHEN 'Jun' THEN '06'
WHEN 'Jul' THEN '07' WHEN 'Aug' THEN '08' WHEN 'Sep' THEN '09' WHEN 'Oct' THEN '10' WHEN 'Nov' THEN '11'
ELSE '12' END || '-' || SUBSTR(TIME_NK,2,2) || ' 00:00:00' ) AS EVENT_DT,
BROWSER AS USER_AGENT_NK,
REQUEST_NK,
IP_NR,
STATUS,
LINE_NK,
BYTES
FROM STG_ACCESS_LOG
)
SELECT
CAST(STG.EVENT_DT AS INTEGER) AS EVENT_DT,
USG.DIM_USER_AGENT_ID,
HST.DIM_HTTP_STATUS_ID,
COUNT(DISTINCT (CASE WHEN INSTR(STG.REQUEST_NK,'.')=0 THEN STG.REQUEST_NK END) ) AS PAGE_CNT,
COUNT(DISTINCT (CASE WHEN INSTR(STG.REQUEST_NK,'.')>0 THEN STG.REQUEST_NK END) ) AS FILE_CNT,
COUNT(DISTINCT STG.REQUEST_NK) AS REQUEST_CNT,
COUNT(DISTINCT STG.LINE_NK) AS LINE_CNT,
COUNT(DISTINCT STG.IP_NR) AS IP_CNT,
SUM(BYTES) AS BYTES
FROM STG,
DIM_HTTP_STATUS HST,
DIM_USER_AGENT USG
WHERE STG.STATUS = HST.STATUS_NK
AND STG.USER_AGENT_NK = USG.USER_AGENT_NK
AND CAST(STG.EVENT_DT AS INTEGER) > $param_epoch_from /* load epoch date */
AND CAST(STG.EVENT_DT AS INTEGER) < strftime('%s', date('now', 'start of day'))
GROUP BY STG.EVENT_DT, HST.DIM_HTTP_STATUS_ID, USG.DIM_USER_AGENT_IDБаза данных sqlite позволяет писать сложные запросы. WITH содержит подготовку данных и ключей. Основной запрос собирает все ссылки на измерения.
Условие не даст загрузить ещё раз историю: CAST(STG.EVENT_DT AS INTEGER) > $param_epoch_from, где параметр является результатом запроса
'SELECT COALESCE(MAX(EVENT_DT), \'3600\') AS LAST_EVENT_EPOCH FROM FCT_ACCESS_USER_AGENT_DD'
Условие загрузит только полный день: CAST(STG.EVENT_DT AS INTEGER) < strftime('%s', date('now', 'start of day'))
Подсчёт страниц или файлов осуществляется примитивным способом, поиском точки.
Отчёты
В сложных системах визуализации есть возможность создавать мета-модель на основе объектов базы данных, динамически управлять фильтрами и правилами агрегации. В конечном счёте, все приличные инструменты генерируют SQL запрос.
В данном примере мы создадим уже готовые SQL запросы и сохраним их в виде вью в базе данных — это и есть отчёты.
Визуализация
В качестве инструмента визуализации использовался Bluff: Beautiful graphs in JavaScript
Для этого потребовалось с помощью PHP пробежаться по всем репортам и сгенерировать html файл с таблицами.
$sqls = array(
'SELECT * FROM RPT_ACCESS_USER_VS_BOT',
'SELECT * FROM RPT_ACCESS_ANNOYING_BOT',
'SELECT * FROM RPT_ACCESS_TOP_HOUR_HIT',
'SELECT * FROM RPT_ACCESS_USER_ACTIVE',
'SELECT * FROM RPT_ACCESS_REQUEST_STATUS',
'SELECT * FROM RPT_ACCESS_TOP_REQUEST_PAGE',
'SELECT * FROM RPT_ACCESS_TOP_REQUEST_REFERRER',
'SELECT * FROM RPT_ACCESS_NEW_REQUEST',
'SELECT * FROM RPT_ACCESS_TOP_REQUEST_SUCCESS',
'SELECT * FROM RPT_ACCESS_TOP_REQUEST_ERROR'
);Инструмент просто визуализирует таблицы результатов.
Вывод
На примере веб анализа статья описывает механизмы, необходимые для построения хранилищ данных. Как видно из результатов, для глубокого анализа и визуализации данных достаточно самых простых инструментов.
В дальнейшем, на примере этого хранилища, попробуем реализовать такие структуры, как медленно изменяющиеся измерения, метаданные, уровни агрегации и интеграцию данных из разных источников.
Также, подробнее рассмотрим простейший инструмент управления ETL процессами на основе одной таблицы.
Вернемся к теме измерения качества данных и автоматизации этого процесса.
Изучим проблемы технического окружения и обслуживания хранилищ данных, для чего реализуем сервер хранилища с минимальными ресурсами, например, на базе Raspberry Pi.
 в России на 10.01.2021")



