
Глубокая высокопроизводительная нейросеть для табличных данных TabNet
Введение
Глубокие нейронные сети (ГНС) стали одним из наиболее привлекательных инструментов создания систем искусственного интеллекта (СИИ), например, распознавания речи, естественного общения, компьютерного зрения [2-3] и др. В частности, благодаря автоматическому выделению ГНС важных, определяющих признаков, связей из данных. Развиваются нейросетевые архитектуры (неокогнитронные, сверточные, глубокого доверия и др.), модели и алгоритмы обучения ГНС (автокодировщики, машины Больцмана, управляемые рекуррентные и др.). ГНС трудно обучаемы,преимущественно, из-за проблем с исчезающим градиентом.
В статье рассматривается новая каноническая архитектура ГНС для табличных данных (TabNet), предназначенная для отображения «дерева решений». Цель - унаследовать преимущества иерархических методов (интерпретируемость, разреженный выбор признаков) и методов на основе ГНС (пошаговое и сквозное обучение). В частности, в TabNet рассматриваются две ключевые потребности - высокая производительность и интерпретируемость. Высокой производительности часто недостаточно - ГНС должны интерпретировать, заменять древовидные методы.
TabNet — нейросеть из полносвязных слоев с последовательным механизмом внимания, которая:
использует разреженный выбор объектов по экземплярам, полученный на основе обучающего набора данных;
создает последовательную многоступенчатую архитектуру, в которой каждый шаг принятия решения может внести свой вклад в ту часть решения, которая основана на выбранных функциях;
улучшает способность к обучению путем нелинейных преобразований выбранных функций;
имитирует ансамбль, привлекая более точные измерения и больше шагов улучшения решения.
Каждый слой данный архитектуры (рис. 1) — это шаг решения, содержащий в себе блок с полносвязными слоями для преобразования характеристик — Feature Transformer и механизм внимания для определения важности входных оригинальных характеристик.

1. Преобразователь функций
1.1. Батч-нормализация
Стек полносвязных слоев с батч-нормализацией используется для получения несмещенных выходных значения для быстрой сходимости и сглаживания оптимизируемой поверхности. Помимо настройки шага для обучения нейронной сети возникает еще одна неочевидная на первый взгляд проблема. Когда обучающей системе на вход подаются данные, имеющие разную природу (например, динамически распределенные данные), система замедляется в обучении, ей приходится долго адаптироваться. В литературе такой эффект носит название ковариационного сдвига (covariate shift).
В случае нейронных сетей такая проблема возникает на внутренних слоях. Представим, что каждый слой нейронной сети — это отдельная компонента обучающей системы. Тогда каждый слой (кроме самого первого) получает на вход данные, полученные с выхода предыдущего слоя. А так как в процессе обучения параметры сети меняются, то и распределение данных, подаваемых на вход внутренних слоев, также изменяется.
Особенно сильно такой эффект наблюдается на более глубоких слоях. Так, даже небольшие изменения на входе нейронной сети сильно влияют на последующие слои — меняется распределение на нейроны, входящие во внутренние слои сети. Установлено, что процесс обучения сходится быстрее, если предварительно нормализовать (отождествить матожидание с нулем, а дисперсии – с единицей) и декоррелировать входные данные для обучающей подсистемы. Тогда для нейронной сети хотелось бы нормализовать данные перед входом на каждый слой. Таким образом и действует метод батч-нормализации (batch normalization), предложенный в 2015 году [4].
Рассмотрим подробнее структуру батч-нормализации на примере одного внутреннего слоя.
1. Пусть нормализуемый слой имеет размерность d: x = (x1, . . . , xd). Тогда можно нормализовать k-ое измерение x по следующей формуле (для простоты все измерения нормализуются независимо):

2. Мы также должны масштабировать и сдвинуть нормализованную величину. В противном случае, лишь нормализация ограничивает репрезентативную способность слоя. Например, если нормализуется вход на сигмоиду, то на выходе будет наблюдаться близкое к линейному преобразование (так как сигмоида вида

на отрезке [−1, 1] похожа на линейную функцию).
Таким образом, нормализованная величина трансформируется в новую:

где параметры γ, β настраиваются в процессе обучения для каждой размерности.
3. Более того, аналогично, как в стохастическом градиентном спуске используются мини-батчи, можно использовать их в нормализации для оценки матожидания и дисперсии для каждого нейрона


4. Итоговое преобразование добавляется в нейронную сеть перед нелинейной функцией активации.
В итоге батч-нормализация:
уменьшает ковариационный сдвиг во внутренних слоях нейронной сети и, следовательно, ускоряет обучение;
является дифференцируемым преобразованием, то есть для обучения сети все так же можно применять метод обратного распространения ошибки;
позволяет использовать большие шаги обучения, то есть позволяет не слишком тщательно и точно настраивать гиперпараметр шага;
не производит явную декорреляцию входных данных для различных нейронов одного слоя.
1.2. Нелинейная функция активации GLU
Авторы статьи [5] предлагают использовать Gated Linear Unit, которая была предложенная в статье для сверточной архитектуры сети, где последняя была вдохновлена архитектурой рекуррентной сети, а именно LSTM-ячейкой.
Описание метода GLU
Представляем новую модель нейронного языка, которая заменяет повторяющиеся соединения, обычно используемые в рекуррентных сетях, на ограниченные временные свертки. Модели нейронного языка дают представление H = [h0 ,..., hN] контекста для каждого слова w0, ... ,wN, чтобы можно было предсказать следующее слово P (wi |hi). Рекуррентные нейронные сети f вычисляют H с помощью рекуррентной функции hi = f(hi - 1 , wi - 1) Она по своей сути задает последовательный вычислительный процесс, который нельзя распараллелить по i (вместо этого, распараллеливание обычно выполняется над несколькими последовательностями).
Предложенный нами подход свертывает входные данные с помощью функции f для получения H = f * w и, следовательно, не использует временных зависимостей, поэтому его легче распараллелить, по отдельным словам, предложения. Этот процесс вычислит каждый контекст как вычислимую функцию от числа предшествующих слов. По сравнению с рекуррентными сетями, размер контекста конечен, в [5] продемонстрировано, что бесконечные контексты не являются необходимыми, а модели могут представлять достаточно большие контексты и хорошо работать на практике.
Рис. 2 иллюстрирует архитектуру модели. Слова представлены векторным вложением, хранящимся в таблице поиска D |V| x e, где |V| - мощность словаря (число слов), а e - размерность вложения. Входом в нашу модель является последовательность слов w0, … , wN, которые представлены вложениями слов E = [Dw0, … , DwN]. Вычисляем скрытые слои h0 , …hL как

где m, n – соответственно, количество входов и выходов характеристических карт, а k - размер патча, X ∈ R N×m - вход слоя hl (либо вложения слов, либо выходы предыдущих слоев),
изученные параметры, σ - сигмоидальная функция и ⊗ произведение матриц.
При свертке входных данных стремятся, чтобы hi не содержала информацию о следующих словах. Мы решаем эту проблему путем смещения сверточных входных данных, чтобы ядра не могли видеть будущий контекст. В частности, мы обнуляем начало последовательности элементами k-1, предполагая, что первый входной элемент - это начало маркера последовательности, который мы не предсказываем, а k - ширина ядра.

Выходом каждого слоя является линейная проекция X * W + b, которая модулируется элементами σ(X * V + c). Подобно LSTM, входы умножают каждый элемент матрицы X * W + b и контролируют информацию, передаваемую по иерархии. Мы называем этот управляемый механизм закрытыми линейными единицами (GLU). Укладка нескольких слоев поверх ввода E дает представление контекста для каждого слова H = hL◦. . .◦h0 (E).
Мы обращаем свертку и закрытый линейный блок (GLU) в остаточный блок предварительной активации, который соединяет выход с входом блока языкового моделирования с управляемыми сверточными сетями.
3.3 Сети LSTM
LSTM (long short-term memory, дословно – долгая краткосрочная память) — тип рекуррентной нейронной сети, способной обучаться долгосрочным зависимостям. LSTM были представлены в работе , впоследствии усовершенствованы и популяризированы другими исследователями, хорошо справляются со многими задачами и до сих пор широко применяются [5].
LSTM специально разработаны для устранения проблемы долгосрочной зависимости. Их специализация — запоминание информации в течение длительных периодов времени, поэтому их практически не нужно обучать!
Все рекуррентные нейронные сети имеют форму цепочки повторяющихся модулей нейронной сети. В стандартных РНС этот повторяющийся модуль имеет простую структуру, например, один слой tanh.
Пошаговая схема работы LSTM сети
LSTM имеет три таких гейта для контроля состояния ячейки.
Слой утраты
На первом этапе LSTM нужно решить, какую информацию мы собираемся выбросить из состояния ячейки. Это решение принимается сигмовидным слоем, называемым «слоем гейта утраты». Он получает на вход h и x и выдает число от 0 до 1 для каждого номера в состоянии ячейки C. 1 означает «полностью сохранить», а 0 — «полностью удалить».
Вернемся к нашему примеру лингвистической модели. Попытаемся предсказать следующее слово, основанное на всех предыдущих. В такой задаче состояние ячейки включает языковой род подлежащего, чтобы использовать правильные местоимения. Когда появляется новое подлежащее, уже требуется забыть род предыдущего подлежащего.
Слой сохранения
На следующем шаге нужно решить, какую новую информацию сохранить в состоянии ячейки. Разобьем процесс на две части. Сначала сигмоидный слой, называемый «слоем гейта входа», решает, какие значения требуется обновить. Затем слой tanh создает вектор новых значений -кандидатов C, которые добавляются в состояние. На следующем шаге мы объединим эти два значения для обновления состояния.
В примере нашей лингвистической модели мы хотели бы добавить род нового подлежащего в состояние ячейки, чтобы заменить им род старого.
Новое состояние
Теперь обновим предыдущее состояние ячейки для получения нового состояния C. Способ обновления выбран, теперь реализуем само обновление.
Умножим старое состояние на f, теряя информацию, которую решили забыть. Затем добавляем i*C. Это новые значения кандидатов,масштабируемые в зависимости от того, как мы решили обновить каждое значение состояния.
В случае с лингвистической моделью, мы отбросим информацию о роде старого субъекта и добавим новую информацию.
Наконец, нужно решить, что хотим получить на выходе. Результат будет являться отфильтрованным состоянием ячейки. Сначала запускаем сигмоидный слой, который решает, какие части состояния ячейки выводить. Затем пропускаем состояние ячейки через tanh (чтобы разместить все значения в интервале [-1, 1]) и умножаем его на выходной сигнал сигмовидного гейта.
Для лингвистической модели, так как сеть работала лишь с подлежащим, она может вывести информацию, относящуюся к глаголу. Например, сеть выведет информацию о том, в каком числе представлено подлежащее (единственное или множественное) для правильного спряжения глагола.
Механизм стробирования в TabNet
Gated Tanh Unit ∇[???ℎ(?) ⊗ ?(?)] = ???ℎ′(?)∇? ⊗ ?(?) + ?′(?)∇? ⊗???ℎ(?) Уменьшающие коэффициенты в виде ???ℎ′(?), ?′(?), которые могут привести к эффекту исчезающих градиентов по мере добавления слоев.
Gated Linear Unit ∇[? ⊗ ?(?)] = ∇? ⊗ ?(?) + ? ⊗ ?′(?)∇? В таком подходе перед ?(?) нет уменьшающего коэффициента, и это считается как мультипликативный skip connection, который наименее склонен к эффекту исчезающих градиентов по мере добавления слоев. Приводит к быстрой сходимости.
3.4. Операция Split:
Опишем разделение выходного тензора после Feature Transformer на две части, где размерность каждой части тензора является гиперпараметром. Смысл разделения тензора, где первая часть идет на выход и агрегируется с выходными значениями последующих шагов принятия решения сетью, а вторая часть идет на вход Attentive Transformer для формирования маски, которая будет применяться на следующем шаге принятия решения. Такая операция разделения выходного тензора позволяет на этапе пересчета градиентов для обновления весов (backpropagation) разделить веса, чтобы часть обучалась на формирование «хорошей» первой части выходного тензора, который будет являться составным элементом выхода сети на решение целевой задачи (классификации или регрессии). То есть чтобы выход сети наиболее точно отражал, аппроксимировал целевой признак задачи. А другая часть весов наиболее точно определяла бы важность характеристик, так как вторая часть тензора идет на вход Attentive Transformer для формирования маски. Таким образом, сеть разделяет "ответственность" весов, чтобы каждый учился на свою задачу, тем самым метод имеет возможность быстрее сходиться.
SPLIT
Обработка функций: Мы обрабатываем отфильтрованные объекты с помощью преобразователя (см. Рис. 1) а затем разделим выход для шага принятия решения и для последующего шага.
Для эффективного и надежного обучения с высокой производительностью, преобразователь признаков должен опираться на слои, которые совместно используются на всех этапах принятия решения (поскольку одни и те же функции вводятся на различных этапах принятия решения), а также слои, зависящие от шага принятия решения.
На рис. 3 показана реализация в виде соединения двух общих слоев и двух зависящих от принятого на шаге принятия решения слоев. За каждым слоем FC следует BN и закрытый линейный блок (GLU) , в конечном итоге связанный с нормализованным остатком нормализацией. Нормализация с √0.5 помогает стабилизировать обучение, гарантируя, что дисперсия по всей сети не изменится кардинально. Для более быстрого обучения мы стремимся к большим размерам обучающих серий. Для повышения производительности при увеличении серий все операции BN, за исключением той, которая применяется к входным функциям, реализуются в форме ложного BN с виртуальным размером серии BV и импульсом mB. Для входных признаков имеется преимущество усреднения с малой дисперсией и, следовательно, избегаем ложный BN. Наконец, применяя агрегацию, подобно дереву решений на Рис. 3, мы строим полное решение как
Мы применяем линейное отображение:
чтобы получить выходное соответствие. Для дискретных выходов мы дополнительно используем softmax во время обучения (и критерий argmax во время вывода).
4. Преобразование внимания
Необходим механизм внимания и его описание. Механизм опирается на матрицу весов (обучения), и после ее применения (линейного преобразования входных данных) результат подается в функцию Softmax, который выдает вектор вероятностей, а именно оценивает важность каждой характеристики через множитель, который взвесит входные характеристики: где вес больше, значит - это важнее, где менее важно — меньше характеристика.
Описание механизма внимания
Слой механизма внимания представляет собой обычную, чаще всего однослойную, нейронную сеть на вход которой подаются ht, t=1 …m, а также вектор d в котором содержится некий контекст, зависящий от конкретной задачи.
C вектором d будет связываться скрытое состояние di−1 предыдущей итерации декодера.
Выходом данного слоя будет являться вектор s — оценок на основании которых на скрытое состояние hi будет «обращено внимание».
Далее, для нормализации значений s используется softmax. Тогда e=softmax(s)
softmax здесь используется благодаря своим свойствам:
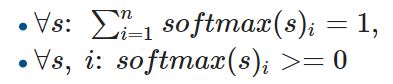
Далее считается:

Результатом работы слоя внимания является cc который, содержит в себе информацию обо всех скрытых состояниях hi пропорционально оценке ei.
Авторы статьи предлагают механизм посложнее. Общий принцип механизма внимания сохраняется, матрица весов, которая выполняет линейное преобразования над входными данными, и функция, которая вернёт те самые веса, определяющие важность характеристик. Но функция используется не Softmax, а Sparsemax. Отличие в том, что это функция выдает разреженное распределение вероятности, а именно какая-то компонента может принять значение ноль, в то время как Softmax выдает значения, всегда отличные от нуля. Это более «жесткая» функция «взвешивания» характеристик, так как можно полностью отсечь какие-то характеристики.
5. Логика вычисления SPARSEMAX
Идея состоит в том, чтобы установить вероятности наименьших значений z равными нулю и сохранить только вероятности наибольших значений z, но при этом сохранить дифференцируемость функции для обеспечения успешного применения алгоритма обратного распространения. Эта функция определяется как:

Здесь τ(z) называется пороговой функцией и определяет опорную функцию S(z), содержащую все ненулевые индексы p. Запустив его и softmax на одних и тех же значениях, мы действительно видим, что он действительно устанавливает некоторые вероятности в ноль, где softmax сохраняет их ненулевыми.
Интересно также посмотреть, насколько различны эти две функции в двумерном случае. В этом случае softmax становится сигмоидной функцией, и sparsemax может быть представлен в таком виде:
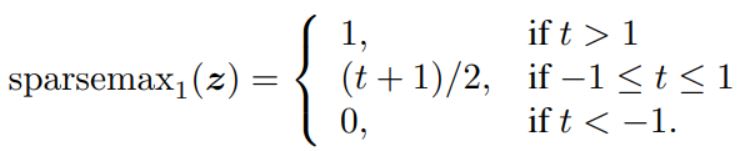
На рисунке ниже показано, чем они отличаются:

Обратите внимание, что функция sparsemax не дифференцируема везде, а где дифференцируема, вычисляется по формуле:

Здесь |S(z)| - количество элементов в опоре S(z).
Помимо выше перечисленных операций в механизме внимания, они еще учитывают то, насколько часто характеристика использовалась на предыдущих шагах, тем самым создавая дополнительный множитель, который применяется до функции Sparsemax.
Таким образом, механизм внимания модифицируется в следующее представление
6. Функция потери разреженности
Дополнительная целевая функция, которая контролирует степень разреженности маски, необходима, чтобы сеть не просто все обнуляла, а все-таки формировала наиболее точно вес каждой характеристики. Эта целевая функция суммируется с основной целевой функцией. Это значит,что при подсчете градиентов, значение данной целевой функции будет влиять на обновление весов. Но чтобы сеть больше училась на основной задаче (классификации или регрессии), в новую целевую функцию вводится множитель (гиперпараметр) так, чтобы абсолютное значение этой функции было меньше, чем значение основной функции, тем самым на обновление весов больше влияет основная целевая функция.
Выбор характеристик: Мы используем обучаемую маску
для мягкого выбора характерных признаков. Благодаря разряженному представлению наиболее заметных признаков, обучающая способность на шаге принятия решения не тратится впустую на нерелевантные признаки, и, таким образом, модель становится более эффективной для параметрической идентификации. Маскировка задается мультипликативно: M[i] · f. Мы используем дискретный преобразователь (см. Рис. 1) чтобы получить маски, используя обработанные объекты предыдущего шага, a[i − 1]:
Нормализация Sparsemax [6] улучшает разреженность путем отображения Евклидовой проекции на вероятностный симплекс, который считается превосходящим по производительности и согласуемым с целью выбора разреженной системы признаков для большинства реальных наборов данных.
Обратите внимание, что формула задает
где h[i] - обучаемая функция, показанная на Рис. 4., использующая слой FC, за которым следует BN, P[i] - корректирующий показатель предыдущего масштаба, обозначающий, насколько часто тот или иной признак был использован ранее:

где γ - параметр свободы: когда γ = 1, функция принудительно используется для использования только на одном шаге принятия решения и по мере увеличения γ, обеспечивается большая гибкость для использования функции на нескольких шагах принятия решения. P[0] инициализируется как единицы,
без каких-либо предварительных условий для маскируемых объектов. Если некоторые функции не используются (как в самообучении), соответствующие P[0] элементы обнуляются, чтобы помочь модели обучиться. Для дальнейшего контроля разреженности выбранных признаков мы предлагаем регуляризацию разреженности в виде энтропии :
где ϵ - малое положительное число для вычислительной устойчивости. Мы корректируем регуляризацию разреженности по общим потерям с коэффициентом разреженности λ, который может обеспечить благоприятное индуктивное смещение и сходимость с более высокой точностью для наборов данных, где большинство объектов избыточны.
Вывод
Данная нейронная сеть продолжает использовать полносвязные слои для табличных данных, но предлагает механизм внимания, которые позволяет интерпретировать ее результат. Но поскольку маска определяется для каждого шага и для каждого наблюдения из выборки, то получить агрегированную маску по всем шагам принятия решения можно, как сделать предлагается, но по-прежнему маска для каждого наблюдения остается своя. Как можно предложить бустинг, в статье [5] не описано, и вопрос остается открытым.
TabNet - новая архитектура глубокого обучения для обучения на табличных данных. TabNet использует механизм последовательного улучшения выбора подмножества семантически значимых функций для обработки на каждом этапе принятия решения. Выбор функций на основе экземпляров обеспечивает эффективное обучение, поскольку возможности модели полностью используются для наиболее важных (предсказательных) функций, возможности принимать более интерпретируемые решения с помощью визуализации масок выбора.
Перевод, коррекция, редактирование Гилязов Айрат, Шигапова Фирюза.
Литература
Созыкин А.В. Обзор методов обучения глубоких нейронных сетей // Вестник ЮУрГУ. Серия: Вычислительная математика и информатика. 2017. Т.6, №3. С.28–59. DOI: 10.14529/cmse170303
LeCun Y., Bengio Y., Hinton G. Deep Learning // Nature. 2015. Vol.521. Pp.436–444. DOI: 10.1038/nature14539.
Rav`ı D., Wong Ch., Deligianni F., et al. Deep Learning for Health Informatics // IEEE Journal of Biomedical and Health Informatics. 2017. Vol.21, No.1. PP.4–21. DOI: 10.1109/JBHI.2016.2636665.
Sergey Ioffe, Christian Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal // Proceedings of The 32nd International Conference on Machine Learning (2015), pp.448-456.
Sercan O. Arik, Tomas Pfister. TabNet: Attentive Interpretable Tabular Learning // ICLR 2020 Conference Blind Submission 25 Sept 2019 (modified: 24 Dec 2019). URL:https://drive.google.com/file/d/1oLQRgKygAEVRRmqCZTPwno7gyTq22wbb/view?usp=sharing
Andre F. T. Martins and Ram´on Fern´andez Astudillo. 2016. From Softmax´ to Sparsemax: A Sparse Model of Attention and Multi-Label Classification. arXiv:1602.02068.



