
В одном проекте мы строили новую ИТ-инфраструктуру и консолидировали на нее базы данных Oracle. Базы были разных объемов и степени критичности (вплоть до Business Critical). Казалось бы, штатная задача. Но в ней таилась одна особенность, о которую мы поломали немало копий, — развертывание на VMware кластера Veritas HA.
Условия задачи
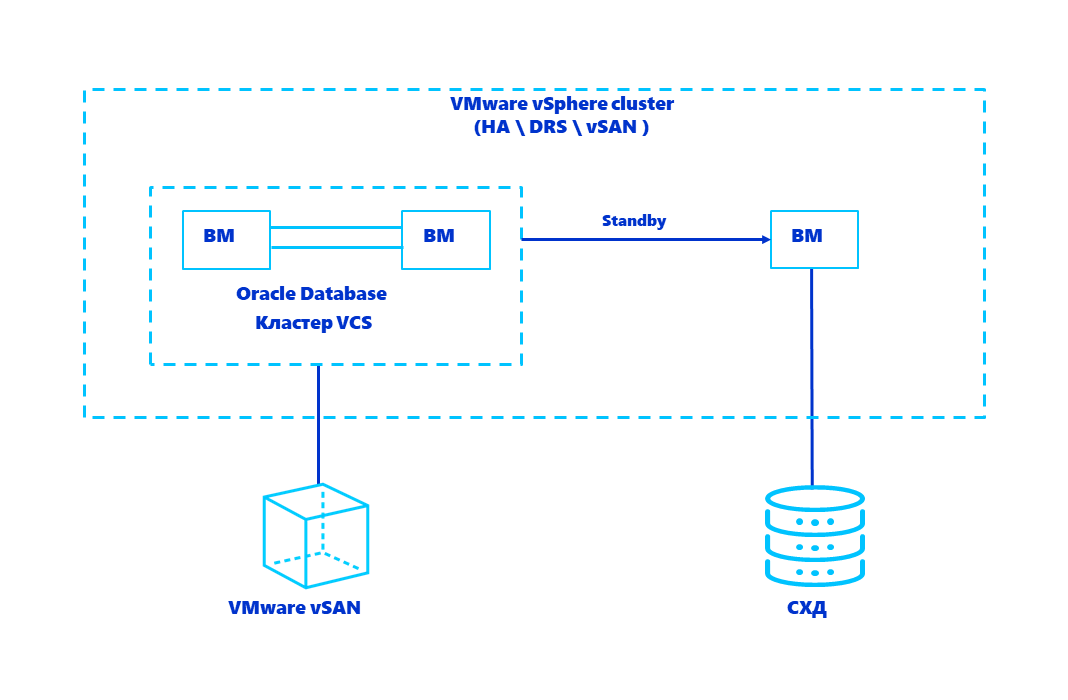
Итак, мы строили абсолютно новую ИТ-инфраструктуру на заранее выбранных нашим заказчиком решениях. Исходные условия:
БД Oracle должны запускаться в виртуальных машинах на платформе виртуализации VMware vSphere.
Данные виртуальных машин должны располагаться на двух разных хранилищах: программно-определяемой СХД VMware vSAN и отдельной внешней СХД.
Защита критичных БД Oracle должна быть обеспечена двумя эшелонами:
с помощью ПО Veritas InfoScale Availability (он же хорошо известный в Enterpise сегменте как Veritas Cluster Server);
наличием отдельной Standby копии.
Схема решения выглядит так:
Уникальность vs сложность
Остановимся чуть подробнее на обозначенных выше пунктах. Как в фильме характеры каждого персонажа вносят свой вклад в развитие сюжета, так и в нашем проекте выбор заказчика предопределил последующий накал страстей.
Oracle на VMware — можно
Очень долго компания Oracle вела негласную войну с VMware, отказываясь официально предоставлять техподдержку заказчикам, которые запускали СУБД Oracle на VMware. Наверняка администраторы СУБД Oracle знакомы со статьей в базе знаний Metalink Note 249212.1. В 2019 году политика вендора изменилась. Oracle объявил о стратегическом партнерстве с VMware и наконец начал оказывать техподдержку.
VMware vSAN
Это программно-определяемая система хранения данных от VMware. Для создания общего отказоустойчивого хранилища используются локальные диски, установленные в серверах виртуализации. Во всем мире более 30 тысяч компаний используют VMware vSAN в своих ИТ-инфраструктурах.
Veritas InfoScale Availability в виртуальных машинах
С понятными условиями разобрались. Как делать Standby и зачем он нужен — тоже все ясно. Но в условиях задачи есть суперважные базы данных, простой которых критичен. Крупные компании часто одним из инструментов защиты критически важных СУБД Oracle выбирают решение Veritas InfoScale Enterprise (он же Veritas Cluster Server). Заказчик нас попросил применить это решение, чтобы защитить самые критичные БД Oracle в виртуальных машинах.
Мы проконсультировались с Veritas и VMware и выяснили, что такие конфигурации используют несколько заказчиков в Европе, а в нашей стране подобное никто раньше не делал. Звучало как вызов!
Вообще у VMware vSphere есть встроенный механизм обеспечения высокой доступности виртуальных машин (vSphere HA). Он позволяет перезапустить виртуальную машину, если случился сбой гипервизора, на котором она работала. Механизм проверен годами и работает без нареканий. Зачем же тогда использовать что-то еще? vSphere HA не может обеспечить некоторые важные опции:
не проверяет статус работы приложения внутри виртуальной машины и не «умеет» реагировать на различные сбои, возникающие в гостевой ОС (например, сбой сетевого адаптера);
не отвечает за порядок старта сервисов внутри гостевой ОС и выполнение необходимых проверок в случае рестарта виртуальной машины;
всегда есть задачи по эксплуатации критичных сервисов (например, выполнение обновлений версий ПО), при исполнении которых хотелось бы минимизировать время простоя.
Получается, что повысить надежность работы приложения и его доступность можно двумя способами — на уровне приложения (если оно это умеет) и средствами кластеризации. А в отдельных случаях, как у нас — обоими сразу.
Внимание к виртуальным дискам
Чтобы создать классический отказоустойчивый кластер, данные нужно хранить на общем диске, и к нему должны иметь доступ все узлы кластера.
Если есть внешняя СХД, то для подобной конфигурации на платформе виртуализации используют RDM-диски. В случае с vSAN применяются виртуальные VMDK-диски с дополнительными настройками. По умолчанию VMware vSphere защищает данные от ошибок администратора, позволяя подключить виртуальный жесткий диск в один момент времени только к одной виртуальной машине. Чтобы обойти это ограничение, для общих виртуальных дисков надо прописать вручную параметр multi-writer.
Выключаем виртуальную машину и добавляем параметр вида scsiX:Y.sharing = "multi-writer" в конфигурационный файл. Также важно не забыть для общих дисков в этом же конфигурационном файле добавить параметр disk.EnableUUID = "TRUE" для корректной работы кластерного ПО Veritas.
Однако за высокую доступность и надежность придется заплатить существенными ограничениями, с которыми придется мириться при дальнейшей эксплуатации системы. Основные из них:
Нельзя менять размер общего диска «на лету». Для этого придется выключать оба узла кластера и только после этого производить манипуляции с диском. Пожалуй, это самая больная тема. Когда заканчивается место на диске, где лежит критичная БД, становится не до шуток.
Нельзя использовать снапшоты для общих дисков. Соответственно, нельзя будет использовать средства безагентского резервного копирования для бэкапа данных. Как следствие, технология Change Block Tracking для инкрементального резервного копирования также не поддерживается.
Без Storage vMotion миграцию общих виртуальных дисков на горячую выполнить будет невозможно.
Хорошая новость — обычный vMotion для перемещения виртуальных машин между гипервизорами успешно работает.
Дьявол в деталях
Хотим поделиться еще несколькими нюансами, не все из которых были задокументированы на момент реализации нашего проекта.
Не забудьте сконфигурировать Anti-affinity правила, чтобы оба узла виртуального кластера случайно не оказались на одном гипервизоре. Для этого потребуется лицензия VMware vSphere Enterprise Plus с ее функционалом DRS.
Даже несмотря на то, что использовать снапшоты нельзя, администраторы системы резервного копирования (СРК) могут случайно поставить на безагентский бэкап ваши виртуальные машины. Пара кликов мыши в консоли управления СРК — и кластер из двух узлов неработоспособен. Расследование инцидента показало следующее: СРК принудительно включает CBT на виртуальном диске (а как мы уже зафиксировали, данная технология не поддерживается с multi-writer диском) и при первой попытке записать что-то на виртуальный диск гипервизор сыпет ошибками. Чтобы избежать этого, мы рекомендуем:
добавить параметр
ctkDisallowed="true"(он был описан в базе знаний VMware, но по неизвестным причинам статья закрыта);
в СРК контрольно добавить в исключения общие диски узлов кластера.
Начиная с версии VMware vSphere 6.7 P01 (build 15160138) на vSAN можно не использовать общие диски в формате thick eager-zeroed. До этой версии общие диски приходилось создавать вручную из командной строки с помощью утилиты vmkfstools.
А с версии VMware vSphere 6.7 Update 3 (build 14320388) vSAN поддерживает SCSI-3 persistent резервации, но применение технологии SCSI-3 PR IO fencing с общими VMDK-дисками в Veritas Cluster не поддерживается. Для арбитража ситуации Split Brain требуется задействовать Coordination Point Server.
Что в результате?
В нашем случае получилось создать необходимую конфигурацию и выполнить все требования заказчика. Критичные базы данных Oracle получили эшелонированную защиту от различных сбоев.
Подойдет ли описанная конфигурация всем? Хм, сомневаемся. На выходе получается слоеный пирог из нескольких технологий с весомым списком ограничений при дальнейшей эксплуатации. Но с ограничениями придется смириться, если на другой чаше весов находятся драгоценные минуты простоя и огромное влияние системы на бизнес. И перед использованием подобного решения мы рекомендуем оценить все «за» и «против» в каждом отдельном случае.
Автор: Дмитрий Горохов, руководитель направления виртуализации «Инфосистемы Джет»
Роман Родин, инженер-проектировщик вычислительных комплексов «Инфосистемы Джет»




